本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
大多数团队在构建RAG系统时,会经历多轮实验,依赖多个组件如查询转换、智能路由、索引策略等。每个组件都需要独立的设置和调优,稍有不慎就会影响整体性能。今天我将深度解析从基础架构入手,逐步深入到高级优化技术,并强调端到端评估的重要性。不仅仅是简单检索+生成,而是一个自洽的生态系统,能处理复杂查询、减少噪声,并通过自我纠正机制持续优化。如果对你有所帮助,记得告诉身边有需要的朋友。
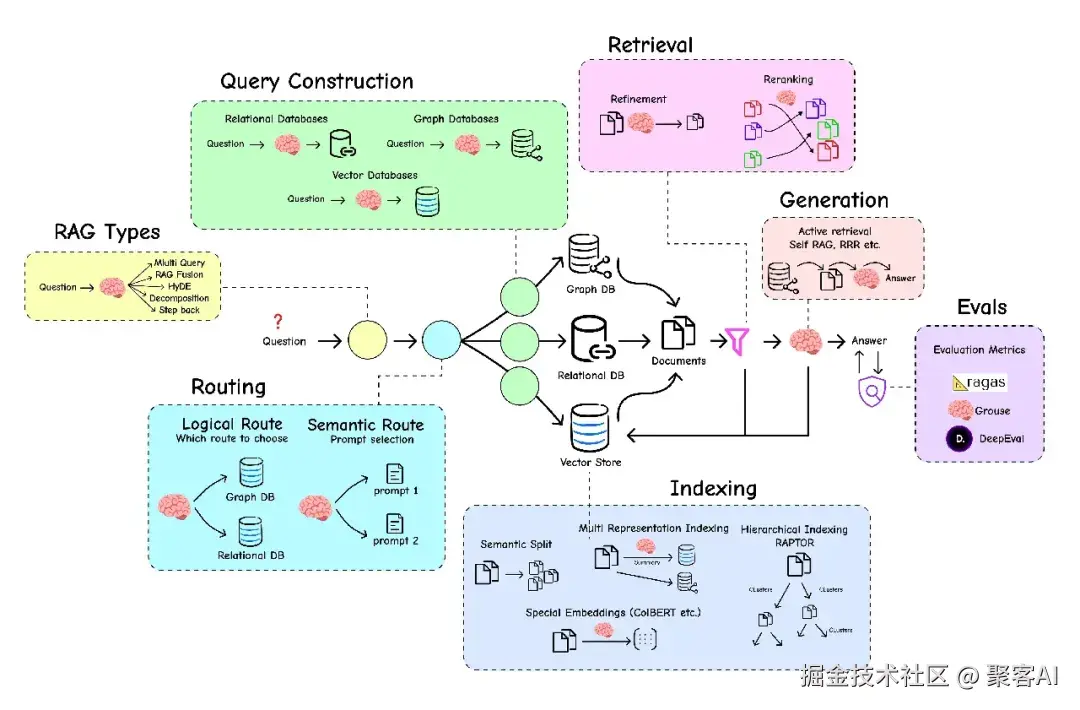
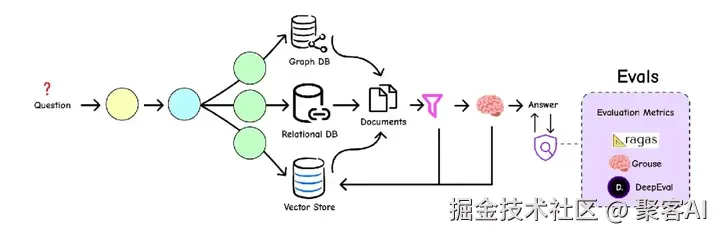
上图展示了RAG生态的关键组件:查询转换(重写问题)、智能路由(引导到正确数据源)、索引(多层次知识库)、检索与重新排序(过滤噪声)、自我纠正常态流(自我评分改进)、端到端评估(客观衡量性能)。接下来,我将分步骤解析这些核心模块。
一、基础RAG系统:索引、检索与生成
任何高级RAG系统都建立在基础流水线上。核心分为三部分:索引(结构化数据存储)、检索(搜索相关上下文)、生成(生成最终回答)。以下是一个简单实现,使用LangChain和OpenAI API。
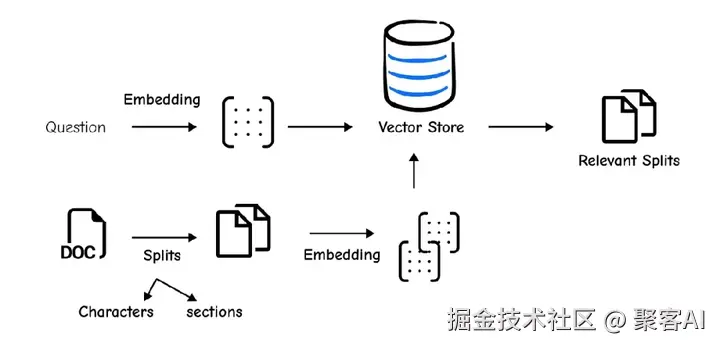
首先,索引阶段涉及加载数据、分块和嵌入。我们使用WebBaseLoader拉取内容,并通过RecursiveCharacterTextSplitter分块(1000字符块,200字符重叠)。这确保语义连贯性,同时适配LLM上下文窗口限制。
代码示例:
ini
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",))
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
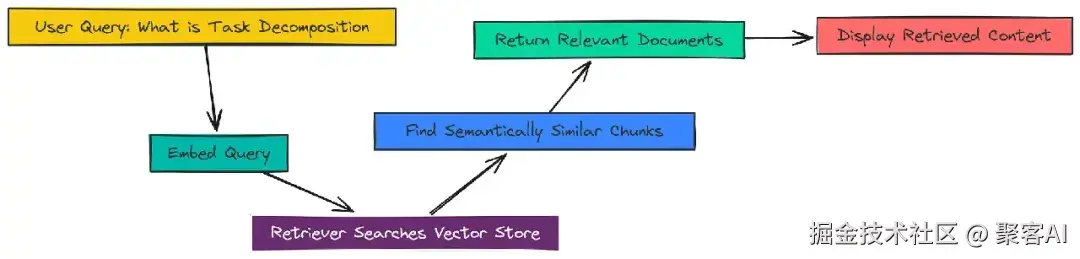
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())检索阶段将用户查询嵌入,从向量库中获取最相似块。例如,查询"What is Task Decomposition?"会拉取相关文档。
代码示例:
ini
retriever = vectorstore.as_retriever()
docs = retriever.get_relevant_documents("What is Task Decomposition?")
print(docs[0].page_content) # 输出: "Task decomposition can be done by LLM with simple prompting..."生成阶段使用LLM(如gpt-3.5-turbo)结合提示模板生成回答。我们从LangChain Hub拉取预优化提示,确保回答简洁准确。

代码示例:
python
from langchain import hub
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
prompt = hub.pull("rlm/rag-prompt") # 提示模板
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)), "question": RunnablePassthrough()}
| prompt | llm | StrOutputParser()
)
response = rag_chain.invoke("What is Task Decomposition?") # 输出: "Task decomposition breaks large tasks into smaller subgoals..."基础流水线虽简单,但易受查询模糊或词汇不匹配影响。接下来,我将介绍如何通过高级查询转换解决这些问题。
二、高级查询转换:提升检索精度
生产环境中,用户查询往往不完美------可能太具体、太宽泛或用词不当。查询转换技术重写或扩展问题,生成多视角变体,显著提高召回率。我们使用同一知识库测试这些技术。
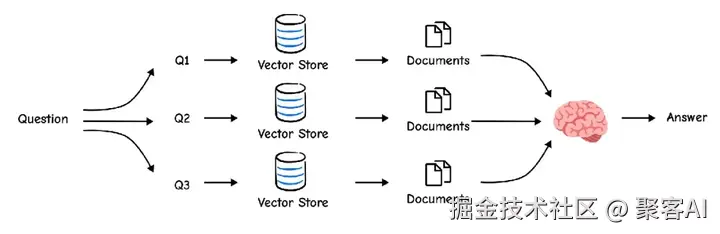
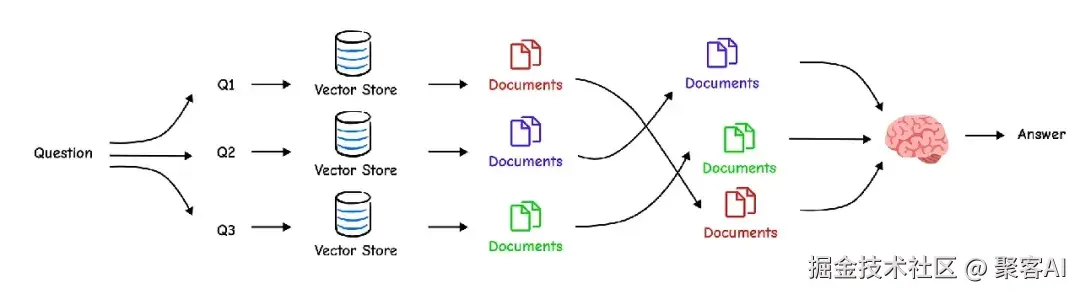
多查询生成 让LLM生成多个问题变体(例如同义词或角度扩展),合并检索结果以覆盖更广上下文。
代码示例:
ini
from langchain.prompts import ChatPromptTemplate
prompt_perspectives = ChatPromptTemplate.from_template("Generate five versions of: {question}")
generate_queries = (prompt_perspectives | ChatOpenAI() | StrOutputParser() | (lambda x: x.split("\n")))
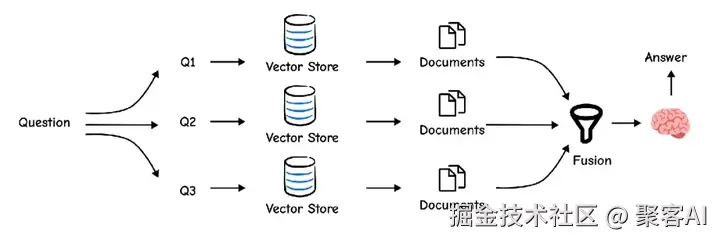
generated_queries = generate_queries.invoke({"question": "What is task decomposition?"}) # 输出: ["How can agents decompose tasks?", ...]RAG-Fusion 改进多查询,通过Reciprocal Rank Fusion(RRF)重新排序文档,优先高频高排名结果。
代码示例:
ini
def reciprocal_rank_fusion(results, k=60): # RRF实现
fused_scores = {}
for docs in results:
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
fused_scores[doc_str] = fused_scores.get(doc_str, 0) + 1 / (rank + k)
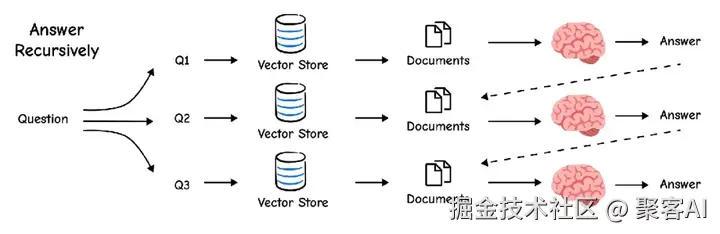
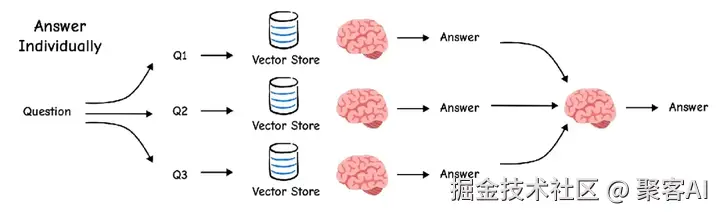
return sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)分解 将复杂问题拆解为子问题(如"LLM代理组件如何交互?" → "组件是什么?" + "如何交互?"),独立回答后综合。
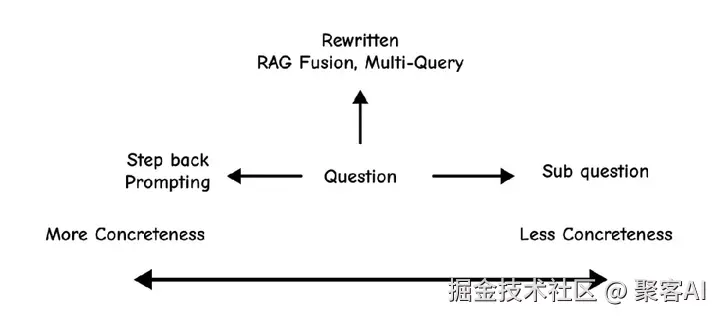
Step-Back Prompting 针对过具体查询,生成通用问题(如"The Police成员能否逮捕?" → "The Police的职责是什么?"),结合通用和具体上下文提升回答质量。
HyDE(Hypothetical Document Embeddings) 让LLM生成假设回答,基于其嵌入检索真实文档,解决词汇不匹配问题。
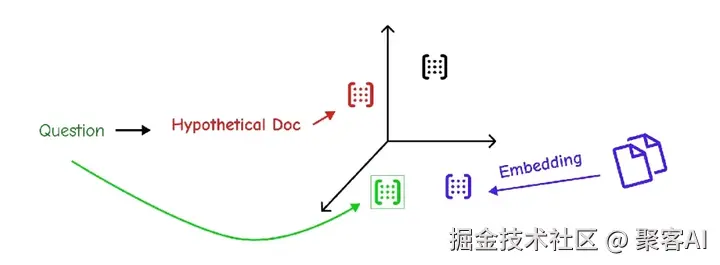
这些技术让检索更鲁棒,但现实数据源往往分散。接下来,我将展示如何通过路由和查询构建管理多源数据。
三、路由与查询构建:智能数据源管理
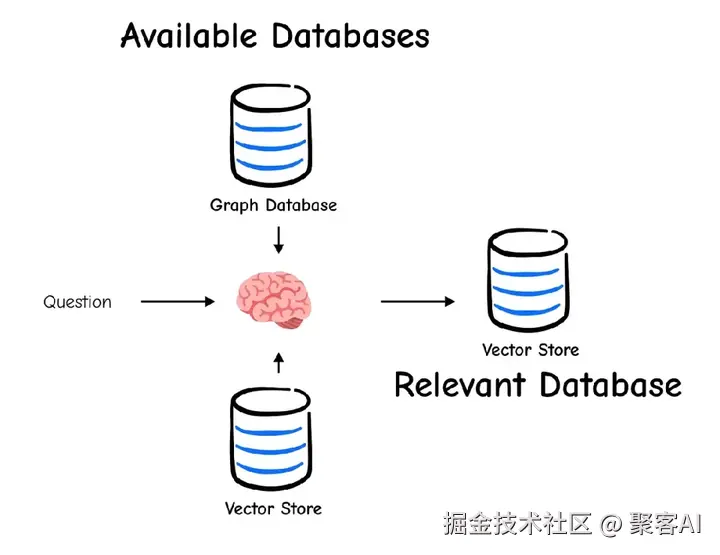
生产系统通常涉及多个数据源(如Python/JS文档、内部Wiki)。路由分析查询,将其引导到正确目标;查询结构化则利用元数据(如日期、浏览量)进行精确过滤。
逻辑路由 使用LLM和Pydantic模型分类查询(如Python问题→Python文档源)。
代码示例:
css
from langchain_core.pydantic_v1 import BaseModel, Field
class RouteQuery(BaseModel):
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(..., description="Select data source")
structured_llm = ChatOpenAI().with_structured_output(RouteQuery)
router = ChatPromptTemplate.from_messages([("system", "Route based on language"), ("human", "{question}")]) | structured_llm
result = router.invoke({"question": "Why doesn't this Python code work?"}) # 输出: datasource='python_docs'语义路由 根据问题风格(如学术vs教学)匹配专家提示,通过嵌入相似性动态选择。
代码示例:
ini
from langchain.utils.math import cosine_similarity
embeddings = OpenAIEmbeddings()
def prompt_router(input):
query_embed = embeddings.embed_query(input["query"])
prompt_embeds = embeddings.embed_documents([physics_template, math_template])
similarity = cosine_similarity([query_embed], prompt_embeds)[0]
return PromptTemplate.from_template([physics_template, math_template][similarity.argmax()])查询结构化 将自然语言问题转为带元数据过滤的查询(如"2023年发布的LangChain视频" → 日期范围过滤)。
代码示例:
ini
class TutorialSearch(BaseModel):
content_search: str = Field(..., description="Similarity search query")
earliest_publish_date: Optional[datetime.date] = Field(None, description="Earliest publish date")
query_analyzer = ChatPromptTemplate.from_messages([("system", "Convert to structured query"), ("human", "{question}")]) | structured_llm
result = query_analyzer.invoke({"question": "Videos on LangChain in 2023"}) # 输出: earliest_publish_date=2023-01-01路由确保查询高效定向,但索引策略决定知识库质量。接下来,我将探讨高级索引技术。
四、高级索引策略:平衡检索精度与上下文丰富性
传统分块面临难题:小块利于检索但缺乏上下文,大块反之。多表示索引和层次索引解决了这一矛盾。
多表示索引 为每个块生成摘要并嵌入,检索摘要后获取完整父文档。
代码示例:
scss
from langchain.retrievers.multi_vector import MultiVectorRetriever
summary_chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize: {doc}") | ChatOpenAI() | StrOutputParser()
summaries = summary_chain.batch(docs)
retriever = MultiVectorRetriever(vectorstore=Chroma(), byte_store=InMemoryByteStore(), id_key="doc_id")层次索引(RAPTOR) 构建多层摘要树(聚类块→摘要集群→更高层摘要),支持从细节到概念的检索。
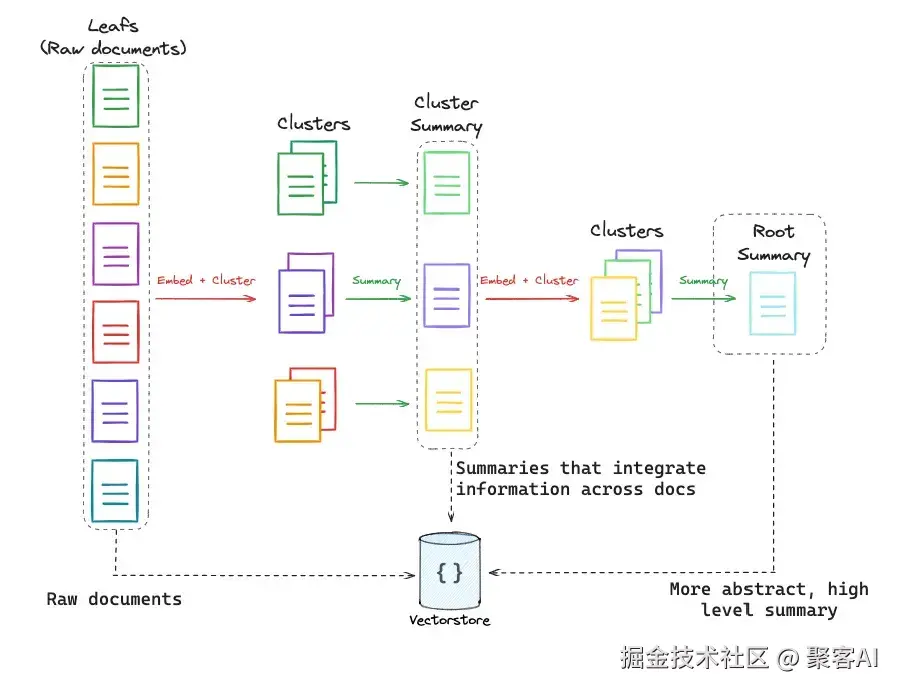
词级精度(ColBERT) 为每个词生成嵌入,通过"后期交互"提升细粒度相关性(优于传统词袋模型)。
代码示例:
ini
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
RAG.index(collection=[full_document], index_name="Miyazaki-ColBERT")
results = RAG.search(query="What studio did Miyazaki found?", k=3) # 输出: Studio Ghibli details索引优化后,检索与生成阶段需要最后的质量控制。
五、高级检索与生成:减少噪声与自我纠正
检索结果可能包含噪声,生成阶段可能产生幻觉。重新排序和自我纠正代理作为最后防线。
专用重新排序 用CohereRerank等模型对初始结果重新排序,优先高相关性文档。
代码示例:
ini
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
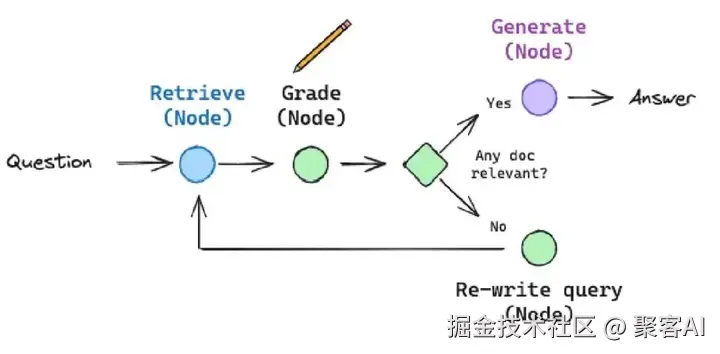
docs = compression_retriever.get_relevant_documents("Task decomposition") # 输出: Re-ranked with relevance scores自我纠正代理(CRAG/Self-RAG) 使用LangGraph构建状态机,动态评估检索质量(如不相关则触发新搜索)或回答忠实度。
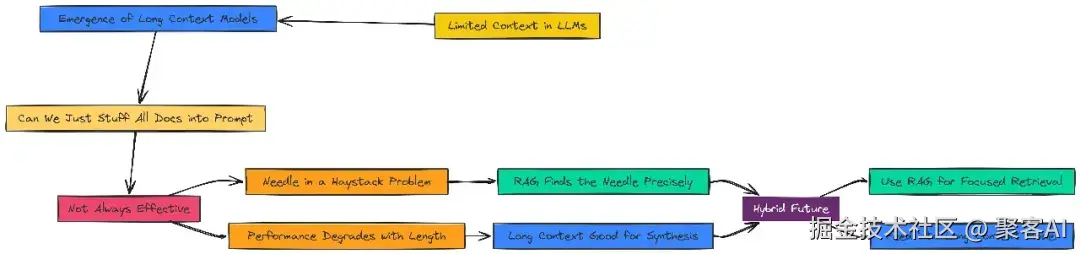
长上下文影响 虽有大窗口模型(如128k tokens),但RAG仍不可替代:它精准检索关键信息,避免"大海捞针"问题。混合方法(RAG预过滤+长上下文综合)是未来方向。
生产部署前,端到端评估是必需的。
六、端到端评估:确保生产可靠性
评估量化系统性能,核心指标包括忠实度(回答基于上下文)、正确性(对比参考答案)、上下文相关性(检索质量)。我们比较手动与框架方法。
手动评估 构建自定义链,用LLM(如gpt-4o)作为裁判评分。
代码示例(忠实度):
ini
faithfulness_prompt = PromptTemplate(input_variables=["question", "context", "generated_answer"], template="...")
faithfulness_chain = faithfulness_prompt | ChatOpenAI().with_structured_output(ResultScore)
score = faithfulness_chain.invoke({"question": "What is 3+3?", "context": "6", "generated_answer": "6"}) # 输出: 0.0 (无法从上下文推导)框架评估 使用RAGAS等工具自动化:
- deepeval:整合Correctness、FaithfulnessMetric。
- grouse:定制裁判提示。
- RAGAS:专为RAG设计,覆盖faithfulness、answer_relevancy等。
代码示例(RAGAS):
ini
from ragas import evaluate
from ragas.metrics import faithfulness, answer_correctness
dataset = Dataset.from_dict({"question": [...], "answer": [...], "contexts": [...], "ground_truth": [...]})
result = evaluate(dataset, metrics=[faithfulness, answer_correctness]) # 输出: 表格化分数作者总结
最后我们总结一下,想要构建生产级RAG系统需要分层构建:从基础流水线开始,逐步添加查询转换、路由、高级索引和自纠正机制,最后通过严格评估(如RAGAS)验证。主要包括:
- 查询转换和路由处理模糊查询和多源数据。
- 多表示索引和ColBERT平衡检索精度与上下文丰富性。
- 重新排序和自我纠正代理减少噪声和幻觉。
- 评估不是终点,而是迭代起点,确保系统在生产中可靠。
好了,今天的分享就到这里,点个小红心,我们下期见。