Skywalking
SkyWalking 是一个开源的分布式追踪系统,主要用于监控和分析分布式系统的性能和行为。它支持多种语言和框架,能够实时收集和分析服务间的调用链路数据、性能指标和日志信息,帮助开发者快速定位系统瓶颈和问题。
SkyWalking Java Agent 是 SkyWalking 提供的针对 Java 应用的自动追踪工具。它通过字节码增强技术,在不修改应用代码的情况下,自动注入追踪代码,实现对 Java 应用的性能监控和调用链追踪。Java Agent 可以与 SkyWalking OAP Server 配合,将采集到的指标、日志和调用链数据上报到后端进行分析和可视化展示,帮助开发和运维团队更好地管理和优化分布式系统。
SkyWalking KafkaMQ
SkyWalking KafkaMQ 是 SkyWalking 项目中的一个插件,用于将 SkyWalking 采集的指标、日志和调用链数据通过 Kafka 消息队列上报到 SkyWalking OAP Server。它允许 SkyWalking Java Agent 将数据发送到 Kafka 集群,再由 Kafka 消费者将数据转发到 SkyWalking OAP Server,从而实现数据的异步传输和解耦,提高系统的可扩展性和可靠性。这种架构特别适用于大规模分布式系统,能够有效减轻 OAP Server 的压力,同时确保数据的高效传输和处理。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
观测云兼容 SkyWalking 的数据,可以将 SkyWalking 的数据直接推送至观测云,或者使用 KafkaMQ 的方式消费 SkyWalking 数据上报至观测云。
实践
实践主题:SpringBoot 应用接入 SkyWalking ,并激活 SkyWalking KafkaMQ 组件上报数据至观测云。
流程
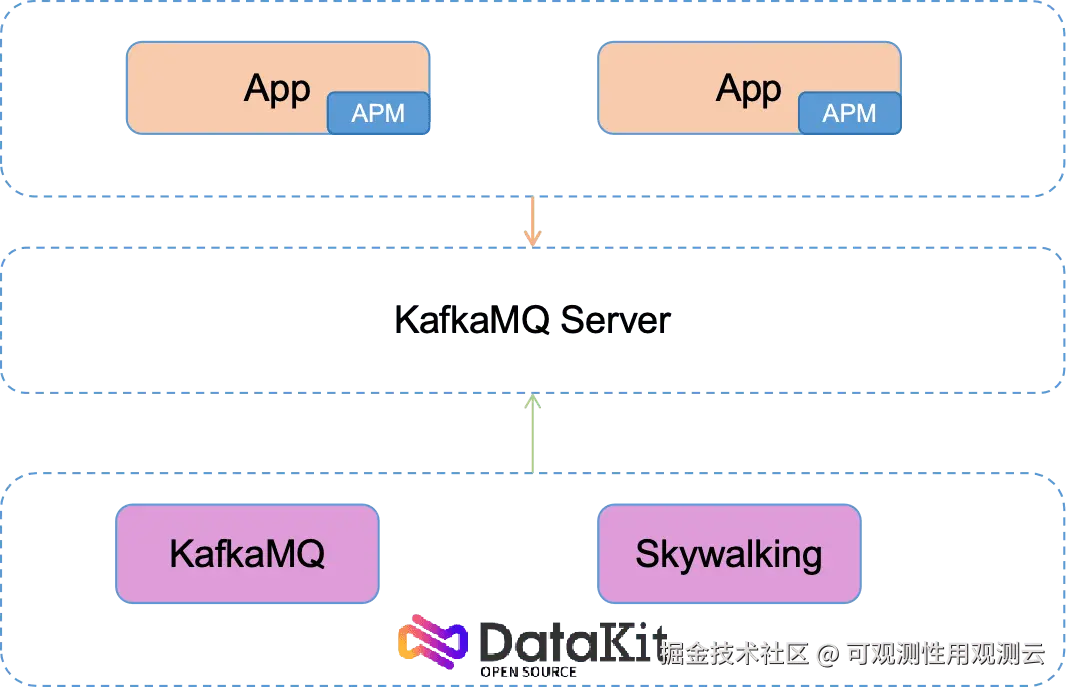
- 应用接入 SkyWalking 探针,并通过 KafkaMQ plugin 进行数据上报至 KafkaMQ Server
- KafkaMQ Server 缓存 Skywalking 数据
- DataKit 启动 KafkaMQ 采集器,消费 KafkaMQ Server 队列数据
- DataKit 启动 Skywalking 采集器, KafkaMQ 采集器消费到的数据使用 SkyWalking 采集器进行解析并推送至观测云
应用
当前主要是以 JAVA 应用为主,新增 skywalking-agent 进行自动化埋点,启动命令如下:
ini
java -javaagent:/home/liurui/agent/skywalking-agent-8.15/skywalking-agent.jar \
-Dskywalking.agent.service_name=demo-app \
-DSW_KAFKA_BOOTSTRAP_SERVERS=localhost:9092 \
-DSW_KAFKA_NAMESPACE=dev \
-jar demo-app.jar- -Dskywalking.agent.service_name: 服务名称
- -DSW_KAFKA_BOOTSTRAP_SERVERS: kafkamq server
- -DSW_KAFKA_NAMESPACE: topic 的 namespace,配置后,会影响默认的队列名称。将当前 namespace 作为前缀追加到默认队列名称上。
如需 Skywalking Kafka 插件生效,需要将 optional-reporter-plugins/kafka-reporter-plugin-xxx.jar 文件复制到 plugins 目录下,Skywalking 自动激活 Kafka 插件,并使默认的配置 collector.backend_service 失效。
访问应用产生链路信息,后续采集会用到。
采集器
DataKit 采集器目录为 /usr/local/datakit/conf.d
- 开启 KafkaMQ 采集器
bash
cd kafkamq
cp kafkamq.conf.sample kafkamq.conf调整 kafkamq.conf,内容如下:
ini
# {"version": "1.72.0", "desc": "do NOT edit this line"}
[[inputs.kafkamq]]
addrs = ["localhost:9092"]
# your kafka version:0.8.2 ~ 3.2.0
kafka_version = "2.0.0"
group_id = "datakit-group"
# consumer group partition assignment strategy (range, roundrobin, sticky)
assignor = "roundrobin"
offsets=-1
## skywalking custom
[inputs.kafkamq.skywalking]
## Required: send to datakit skywalking input.
dk_endpoint="http://localhost:9529"
thread = 8
topics = [
"skywalking-metrics",
"skywalking-profilings",
"skywalking-segments",
"skywalking-managements",
"skywalking-meters",
"skywalking-logs",
]
# 需要跟应用配置的kafka namespace 保持一致
namespace = "dev"- 开启 Skywalking 采集器
bash
cd skywalking
cp skywalking.conf.sample skywalking.conf内容不需要调整。
-
重启 DataKit
datakit service -R
效果
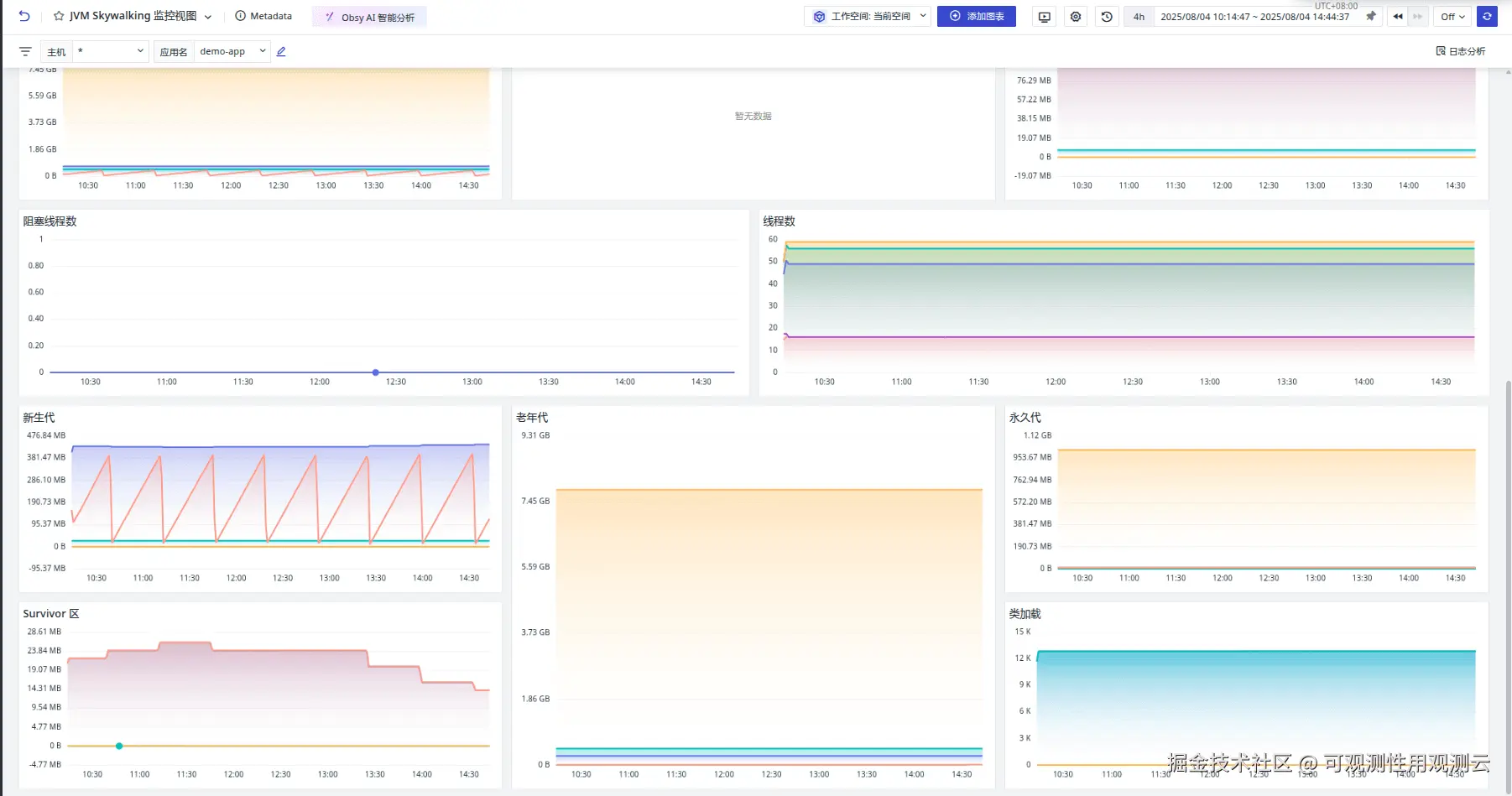
登录观测云控制台,点击「应用性能监测」 -「链路」,即可查看服务调用链情况。
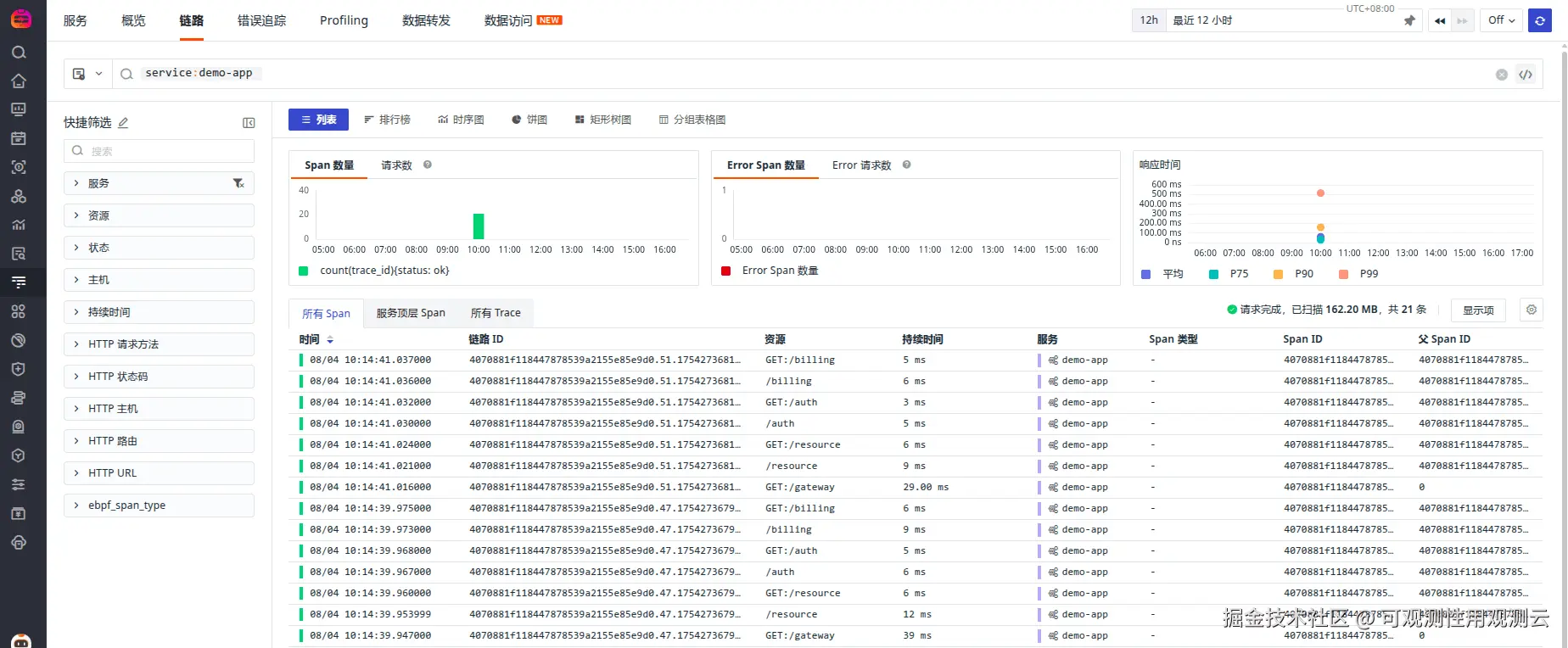
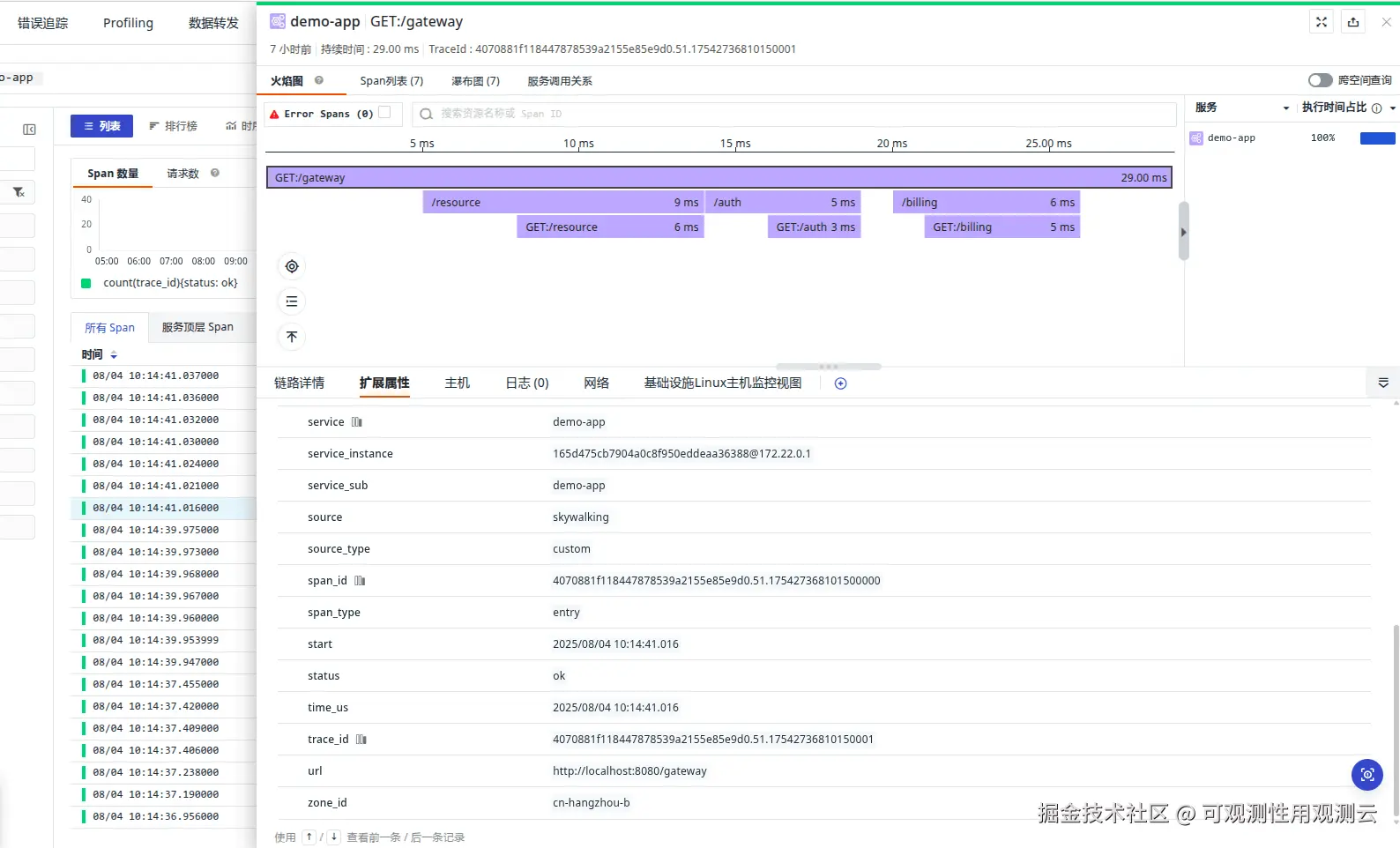
点击列表数据可以查看到每一个 trace 的 span 信息。
点击「场景」 -「新建仪表板」,输入 "JVM Skywalking", 选择 "JVM Skywalking 监控视图",点击 "确定" 即可添加视图。