前言:高可用不是选项,而是底线
什么是 RTO?
在深入讨论技术细节之前,我们需要先对齐一个核心指标:RTO (Recovery Time Objective,恢复时间目标)。
在分布式系统的语境下,RTO 并不是一个抽象的 SLA 数字,而是一个倒计时的秒表。它指的是从故障发生的那一刻起,到系统完全恢复服务能力所允许消耗的最长时间。对于运维团队来说,RTO 就是从"系统报警"到"业务止损"之间的生死时速。
为什么 Kafka 的 RTO 至关重要?
在当今的架构中,Apache Kafka 已经成为了基础设施的"中枢神经"。它不再仅仅是日志管道,而是承载了关键业务链路的命脉。
试想一个典型的反欺诈场景: 用户的行为日志通过 Kafka 实时流向风控系统。当检测到异常登录时,系统必须在毫秒级内下发拦截指令。 如果此时 Kafka 集群因节点故障陷入不可用状态,RTO 的每一秒钟都意味着一个巨大"盲区"。在这几秒甚至几十秒的时间里,用户的账户暴露于盗取风险之中,而系统却处于失明状态。
因此,Kafka 的高可用性不仅关乎系统稳定性,更直接关联业务安全与客户信任。我们能否让这个"盲区"缩得更短一点?如何在节点故障时,让 Kafka 快速复活?
答案简单得令人意外:有时候,只需要改动一行配置,就能让 RTO 缩短一半。
一行配置:request.timeout.ms = 15000
在优化 Kafka RTO 时,常见的误区是过度关注服务端的副本调度策略。然而,真正决定客户端感知恢复速度的,往往是客户端配置中一个常被忽视的参数:request.timeout.ms。
Partition 容灾的基准线:三个核心配置
调整request.timeout.ms参数之前,我们需要先厘清一个核心前提:集群必须具备在故障发生时完成 Leader 切换的基础能力。如果故障导致 Partition 直接不可用,讨论 RTO 优化便失去了意义。Kafka 的 Partition 能否在 Broker 故障后成功执行故障转移,取决于以下三个配置的协同:
-
replication.factor:副本总数(例如 3) -
min.insync.replicas(简称 minISR):写入成功所需的最小同步副本数(例如 2) -
unclean.leader.election.enable:是否允许非 ISR 副本成为 Leader(默认 false)
只有当 ISR 列表中的 Replica 数量大于 minISR 时,集群才具备在单点故障下维持写入的能力。但在满足了"能恢复"的前提后,为什么恢复速度依然不理想?这需要我们深入分析服务端与客户端之间的时间差。
RTO 瓶颈分析:服务端与客户端的时间差
在满足上述可用性前提的情况下,当一台 Broker 宕机时,RTO 的长短取决于服务端恢复与客户端感知之间的时间差。
服务端视角:10秒内的快速恢复
服务端基于 Controller 的故障检测机制,恢复流程十分高效:
-
检测阶段: 故障 Broker 停止发送心跳。若连续
broker.session.timeout.ms(默认 10s)未收到心跳,Controller 将其标记为 Fenced。 -
恢复阶段: Controller 立即触发 Leader 选举,将 Partition Leader 切换至 ISR 中的其他存活副本。
结论: 从服务端状态来看,Partition 的服务能力在 10秒 内即可恢复。
客户端视角:Metadata 刷新滞后
然而,客户端并不会立即感知到 Leader 的变更。它仍会向旧的 Leader 地址发送请求,直到请求超时。
此时,request.timeout.ms(默认 30,000ms)成为了瓶颈:
-
客户端会持续等待当前请求的响应,直到 30秒 超时。
-
仅当超时发生后,客户端才会主动刷新 Metadata(获取最新 Leader 信息)并进行重试。
**结论:**这意味着,尽管服务端在第 10 秒已完成恢复,客户端仍需额外等待 20 秒才能从错误状态中恢复写入。
优化方案:对齐故障检测窗口
上述分析揭示了 RTO 偏高的根本原因:客户端的超时配置与服务端的故障检测窗口不匹配。
**优化建议:**将客户端的 request.timeout.ms 从默认的 30s 调整为 15s。
-
机制: 客户端将在 15 秒内触发超时并刷新 Metadata。这与 Controller 约 10 秒的故障检测时间更加契合(预留 5 秒缓冲)。
-
收益: 这一微小的配置变更,可将单节点故障场景下的 RTO 从 30s 降低至约 15s------缩短了 50% 的恢复时间 。
Apache Kafka RTO 推演:从理论到现实
上一节中,我们通过调整 request.timeout.ms 成功将单节点故障下的 RTO 缩短了 50%。这一优化在日常运维中极具价值,但必须指出,它的有效性建立在一个严格的边界条件之上:集群必须处于可恢复状态,即故障仅限于单节点范围。
然而,在分布式系统的设计中,我们必须评估更严苛的场景。随着业务增长驱动集群规模扩大,概率法则将不可避免地挑战系统的可用性极限。为了量化这一风险,我们基于真实的 SLA 数据构建了一个概率模型,重点考察由 Broker 故障主导的 RTO 变化。
基于 SLA 的故障概率建模
以 AWS EC2 标准实例为例,其 SLA 承诺 99.5% 的月度可用性。据此推算,单台计算实例的年均预期不可用时间约为:
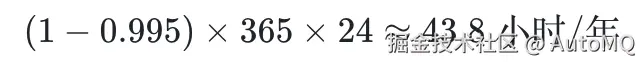
基于此数据,我们设定一个标准的生产级 Kafka 集群配置:replication.factor=3,min.insync.replicas=2,且 unclean.leader.election.enable=false。在此配置下,我们将推演不同规模集群发生"单点故障"与"双节点并发故障"的概率差异。
集群规模
同时宕机数
发生概率(近似)
RTO
3 Broker
1 台
0.005 * (0.995 ^ 2) * 3 ~= 1.5%
-
0.005:宕机概率
-
0.995 ^ 2:剩余两个节点都未宕机概率
30s
3 Broker
>= 2 台
1 - 0.005 * (0.995 ^ 2) * 3 - (0.995 ^ 3) ~= 0.007%
-
0.005 * (0.995 ^ 2) * 3:只宕机一台概率
-
99.5% ^ 3:所有节点都未宕机概率
不可用
9 Broker
1 台
4.3%
30s
9 Broker
>= 2 台
0.09%
不可用
30 Broker
1 台
12.9%
30s
30 Broker
>= 2 台
1%
不可用
100 Broker
1 台
30.4%
30s
100 Broker
>= 2 台
8.98%
不可用
表 1:不同集群规模下的故障概率推演
故障模式分化:自动恢复 vs. 服务中断
从概率模型中可以观察到,随着节点数的增加,系统将面临两种截然不同的故障模式,其 RTO 表现存在本质差异:
- 模式一:单节点故障(可自动恢复)
在 replication.factor=3 且 min.insync.replicas=2 的典型配置下,ISR(In-Sync Replicas)中通常至少有 2 个副本保持同步。当一台 Broker 宕机时,Controller 能迅速将 Partition Leader 切换至 ISR 中的其他存活副本,服务在 10 秒内即可恢复。客户端在 request.timeout.ms=30s 内通过内置重试机制重新发送请求即可成功,上层业务不会收到异常,仅感知到短暂的发送延迟抖动。
趋势: 随着集群扩大,此类故障频率会上升,但属于系统设计预期的"可控噪音",不影响服务连续性。
- 模式二:多节点并发故障(服务阻断)
即使 ISR 中原本有 3 个同步副本,只要同时宕机 ≥2 台,剩余 ISR 副本数将低于min.insync.replicas=2 的阈值。此时,即便成功选举出新 Leader,生产者写入仍会因副本不足而被拒绝,返回 NOT_ENOUGH_REPLICAS 错误。系统进入持续不可用状态,直到足够多的 Broker 恢复、ISR 重新满足 minISR 要求为止。RTO 不再由配置决定,而是等于实际节点恢复时间(可能长达数小时)。
趋势: 客户端将向上抛出超时或写入失败异常,直接影响业务连续性。
规模化带来的风险质变
数据表明,当集群规模达到 30 节点时,量变引发了质变。"多点并发故障"的年发生概率逼近 1%。
从工程视角审视,1% 的概率对应着 每年约 87 小时的潜在服务完全不可用时间。对于金融交易、核心风控等对 SLA 要求极高的业务场景,这是无法通过运维手段规避的系统性风险。在存算耦合的架构限制下,通过配置优化 RTO 存在明显的天花板。当集群规模扩大时,多点故障的概率将击穿配置优化的防线,导致业务连续性面临严峻挑战。
终极解法:基于存算分离架构的确定性 RTO
传统 Kafka 在 RTO 上的瓶颈,归根结底源于其存算****耦合的架构设计。在传统架构中,Broker 既是计算节点,又是数据的物理持有者。这种耦合导致了节点即数据的约束:一旦节点故障,不仅服务中断,更可能因 ISR 副本不足而陷入写入阻塞。
要突破这一物理限制,需要架构层面的范式转移。以 AutoMQ 为代表的存算分离 架构,通过将全量数据卸载至高可用对象存储(如 AWS S3),使 Broker 蜕变为完全无状态的计算单元。这一设计彻底解耦了 RTO 与故障规模的关联,通过重构容灾恢复流程,带来两个根本性优势:
-
任意存活节点均可接管任意 Partition;
-
RTO 与故障节点数量解耦,趋于恒定。
AutoMQ 容灾恢复机制解构
为了理解这种架构如何实现秒级恢复,我们需要深入故障发生的微观现场。在存算分离架构下,容灾恢复不再依赖缓慢的数据搬迁或副本同步,而是转变为快速的元数据接管。AutoMQ 的容灾恢复流程包含以下四个关键环节:
1.前提:数据的全局可见性
由于所有日志数据均存储在共享的对象存储中,任何 Broker 都能随时访问任意 Partition 的完整数据。这意味着,无论多少节点同时宕机,只要集群中存在至少一个存活 Broker,Partition 就具备被立即恢复的条件------无需等待副本同步,也无需担心 ISR 缩减。
2.触发:轻量级 Leader 切换
故障检测机制: 沿用Apache Kafka 机制。Controller 在 broker.session.timeout.ms=10s 内未收到心跳后,将故障 Broker 标记为 Fenced。
Leader **切换逻辑:**差异在于 ISR 管理。AutoMQ 的 ISR 中仅包含当前 Leader(因数据不依赖本地副本同步),因此 Controller 无需协调多个副本状态。一旦原 Leader 被 Fenced,Controller 可立即指定任意存活 Broker 作为 Partition 的新 Leader,并更新 ISR 为该节点。
3.保障:ConfirmWAL 的接管与一致性
AutoMQ 的写入流程在将数据持久化到 ConfirmWAL(基于对象存储的预写日志抽象)后即返回成功。为保证数据紧凑与可读性,系统会定期(每 20 秒或累计 500 MiB)触发 Commit,Commit 会将数据规整后上传到对象存储,并将结果元数据记录到 KRaft 日志中。
当原节点被 Fenced 后,Controller 会额外指派一个存活 Broker 接管其未完成的 ConfirmWAL Commit 任务。当完成 ConfirmWAL 的 Commit 后,对象的元数据通过 KRaft 对集群所有节点都可见,被切换 Leader 的 Partition 才可以被顺利打开。得益于对象存储的高吞吐与并行能力,该过程通常 < 5 秒 即可完成,确保数据一致性不受影响。
4.恢复:基于 Checkpoint 的秒级重建
新当选的 Broker 通过 KRaft 感知到自己需负责某 Partition 后,会立即从对象存储中加载该 Partition 的 Segment 元数据,并从 UNCLEAN_SHUTDOWN 状态启动恢复流程。
得益于 AutoMQ 对 Partition 状态的定期 Checkpoint 优化,恢复过程只需重放最后一个 LogSegment 后面一小段的数据用于恢复索引(Apache Kafka UNCLEAN_SHUTDOWN 需要重放整个 LogSegment),通常 < 5 秒 即可完成,对外提供读写服务。
结论:RTO 与集群规模解耦
综合上述流程,AutoMQ 在单点或多点故障场景下,端到端 RTO 始终稳定在小于 30 秒区间。
更重要的是,这一 RTO 表现不随集群规模扩大而恶化。即使在 30 节点甚至百节点集群中,"同时宕机 ≥2 台"不再意味着业务中断,而是被系统自动、快速地恢复。
结语:从"参数调优"到"架构演进"
request.timeout.ms=15000 这一行看似微小的配置调整,成本极低,却能有效消除单节点故障下的客户端滞后,将 RTO 缩短约 50%。对于所有运行在存算耦合架构下的存量 Kafka 集群,这是一项值得立即执行的优化。
然而,作为架构师,我们也必须正视配置优化的物理边界。
随着集群规模的扩大,多节点并发故障的概率呈指数级上升。在传统的存算耦合架构中,依赖本地副本同步的 ISR 机制存在固有的可用性天花板。一旦突破这一防线,RTO 将不再由软件参数决定,而是由硬件恢复时间甚至人工干预速度主导。
真正的突破,在于架构范式的跃迁。
AutoMQ 通过存算分离 架构,将数据持久化卸载至高可用的对象存储(如 S3),使 Broker 彻底转变为无状态的计算单元 。这一设计不仅解除了 Partition 恢复对副本同步的依赖,更实现了 RTO 与故障规模的解耦------无论是一台还是多台 Broker 宕机,服务均能在 30 秒内 实现确定性恢复。
从"调一行配置"到"换一种架构",这并非非此即彼的选择,而是技术演进的自然路径:用配置优化守住当下的 SLA**,用架构演进赢得未来的确定性。**