题目地址:https://www.mashangpa.com/problem-detail/3/
这里作者很有意思,当我想F12调试的时候,就出现了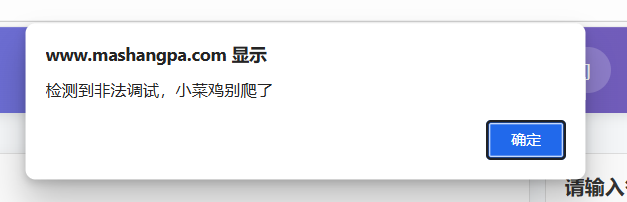
典型的JS禁用了调试工具,我们通过手动的进入浏览器-->更多工具-->开发者工具

出现了这个,一定是在强制打开后发生了什么,经过全局搜索debugger后
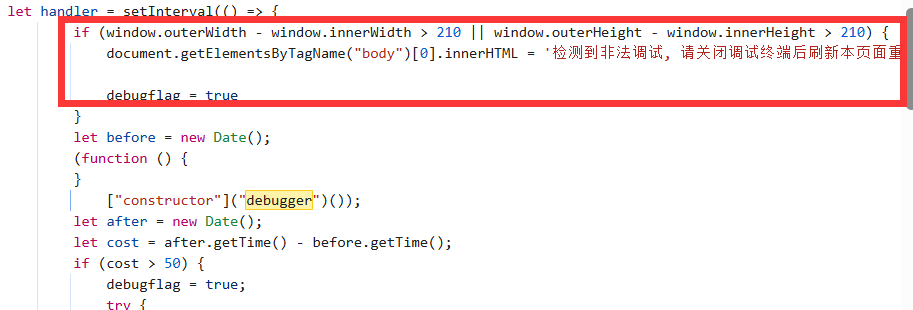
这里即使禁止了debugger,但是还是会发生页面自毁,主要因为会检测开发者工具的检测
解决办法:打开这个设备仿真(原理就是更改页面显示的大小)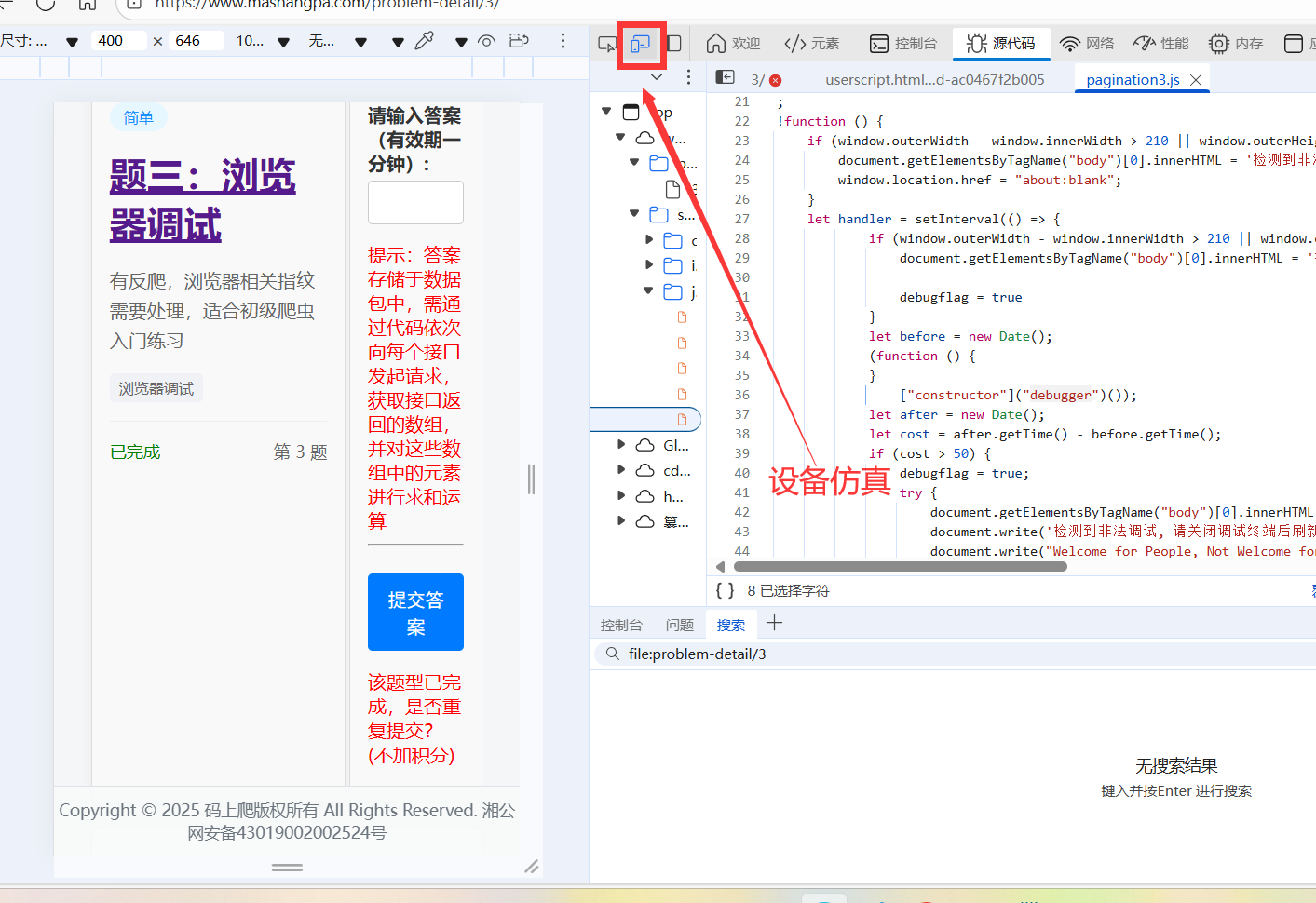
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0",
"Referer": "https://www.mashangpa.com/problem-detail/1/",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Cookie": "yours Cookie"
}
sum_all = 0
for i in range(1, 21):
url = f"https://www.mashangpa.com/api/problem-detail/3/data/?page={i}"
resp = requests.get(url, headers=headers)
# print(resp.status_code)
arr = resp.json()['current_array']
total = sum(arr)
sum_all+=total
url = f"https://www.mashangpa.com/api/problem-detail/2/data/?page=2"
resp = requests.get(url, headers=headers)
print(sum_all)