很多前端小伙伴在日常业务中很少涉及到爬虫相关的内容,觉得爬虫是后端工程师的专属技能。但实际上,爬虫技术是前端开发者应该掌握的基本技能之一。
爬虫与前端的关系
- 数据获取:前端经常需要从各种API获取数据,爬虫技术能帮你理解数据是如何被获取的
- 测试验证:爬虫可以帮你验证前端页面的数据展示是否正确
- 竞品分析:了解竞争对手的产品功能和数据展示方式
- 个人项目:想要开发一些有趣的小工具,爬虫技术必不可少
- 技术视野:掌握爬虫技术能让你对Web技术有更全面的理解
学习爬虫的好处
无论是想要开发数据可视化项目、构建个人博客系统,还是想要了解Web安全机制,爬虫技术都能给你带来意想不到的收获。让我们一起来探索这个既实用又有趣的技术领域吧!
什么是爬虫?
网络爬虫(Web Spider) 是一种自动获取网页内容的程序,它模拟浏览器行为,向网站发起请求,获取资源后分析并提取有用数据。
技术原理
从技术层面来说,爬虫通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码、JSON数据、二进制数据(图片、视频)爬取到本地,进而提取需要的数据并存储使用。
两种获取网络数据的方式
方式1:传统浏览器方式
浏览器提交请求 → 下载网页代码 → 解析成页面方式2:爬虫方式
模拟浏览器发送请求 → 获取网页代码 → 提取有用数据 → 存储到数据库或文件爬虫要做的就是方式2。
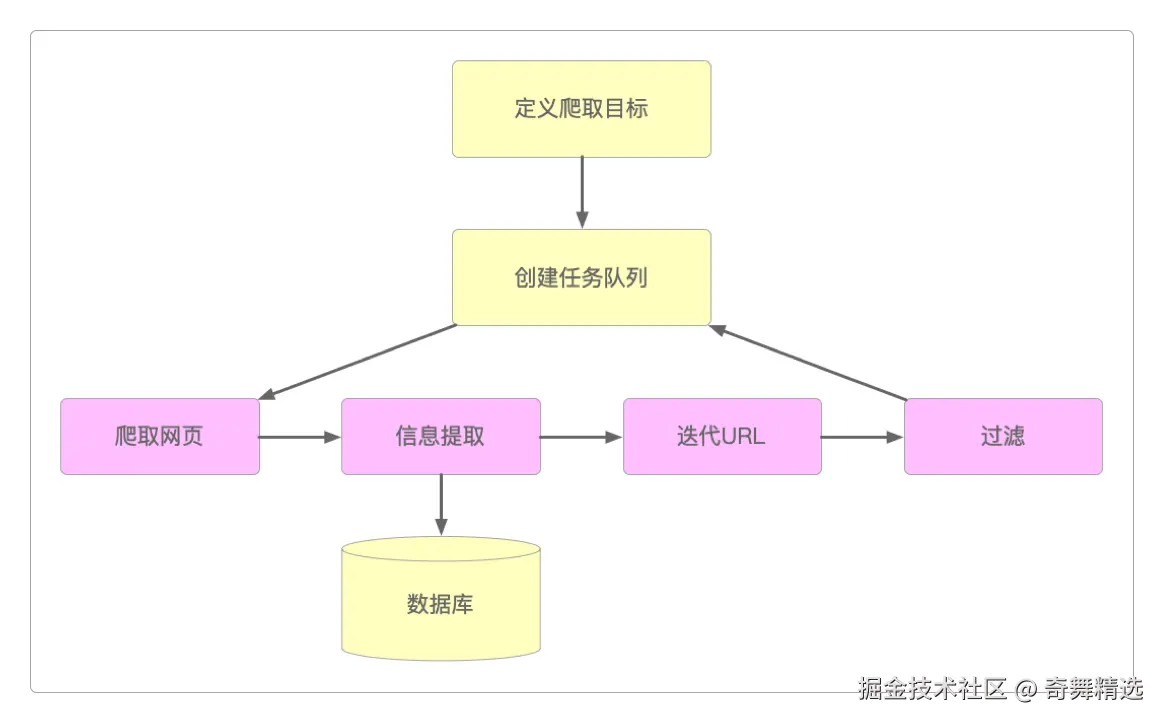
详细流程分解
发起请求
- 使用HTTP库向目标站点发起请求
- 请求包含:请求头、请求体等
获取响应内容
- 服务器正常响应时得到Response
- Response包含:HTML、JSON、图片、视频等
解析内容
- HTML数据:正则表达式、XPath、Beautiful Soup、CSS选择器
- JSON数据:JSON模块
- 二进制数据:以wb方式写入文件
保存数据
- 数据库:MySQL、MongoDB、Redis
- 文件:CSV、JSON、Excel等
流程图
编程语言环境对比
爬虫开发并不局限于单一编程语言,不同语言各有优势。虽然Python生态更丰富,但其他语言同样可以构建强大的爬虫系统。
| 特性 | Python | Node.js | Java | Go | C# |
|---|---|---|---|---|---|
| 生态丰富度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 学习曲线 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 性能表现 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 部署便利性 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 社区支持 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
Python - 全能型爬虫开发
- 适用场景:数据挖掘、学术研究、快速原型开发
- 优势:丰富的爬虫库(Scrapy、BeautifulSoup、Selenium)、数据处理能力强(Pandas、NumPy)
- 典型应用:新闻聚合、电商数据采集、社交媒体分析
- 推荐人群:数据科学家、研究人员、爬虫初学者
Node.js - 高并发网络爬虫
- 适用场景:大规模并发爬取、实时数据抓取、API密集型爬虫
- 优势:异步非阻塞I/O、事件驱动架构、丰富的HTTP客户端库
- 典型应用:实时价格监控、社交媒体流数据、高频数据采集
- 推荐人群:前端开发者、全栈工程师、需要高并发的场景
Java - 企业级爬虫系统
- 适用场景:大型分布式爬虫、企业级应用、需要高稳定性的场景
- 优势:强大的多线程支持、成熟的JVM生态、丰富的企业级框架
- 典型应用:搜索引擎爬虫、大规模数据采集、企业数据整合
- 推荐人群:企业开发者、系统架构师、需要高可靠性的场景
Go - 高性能爬虫引擎
- 适用场景:高性能爬虫、系统级爬虫、资源受限环境
- 优势:原生并发支持、内存占用低、编译型语言性能优异
- 典型应用:网络监控工具、系统级爬虫、微服务架构中的爬虫组件
- 推荐人群:系统开发者、DevOps工程师、性能敏感场景
C# - Windows生态爬虫
- 适用场景:Windows平台爬虫、.NET生态集成、桌面应用爬虫
- 优势:强大的Windows API支持、优秀的GUI开发能力、.NET生态丰富
- 典型应用:Windows应用数据提取、企业内网爬虫、桌面爬虫工具
- 推荐人群:Windows开发者、.NET开发者、企业内网应用场景
Python生态优势
python
# Python爬虫生态示例
import requests
from bs4 import BeautifulSoup
import scrapy
from selenium import webdriver
# 丰富的库支持
# - requests: HTTP请求
# - BeautifulSoup: HTML解析
# - scrapy: 爬虫框架
# - selenium: 浏览器自动化
# - pandas: 数据处理
# - numpy: 数值计算Node.js生态优势
javascript
// Node.js爬虫生态示例
const axios = require('axios');
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
const playwright = require('playwright');
// 强大的异步处理能力
// - axios: HTTP请求
// - cheerio: HTML解析
// - puppeteer: Chrome自动化
// - playwright: 多浏览器支持
浏览器自动化工具对比
| 工具名称 | 支持语言 | 特点 | 适用场景 |
|---|---|---|---|
| Puppeteer | Node.js | Chrome官方支持、功能完整 | 动态内容、SPA应用 |
| Playwright | Node.js/Python/Java/C# | 多浏览器支持、现代化API | 跨浏览器测试、企业级 |
| Selenium | Python/Java/C#/JavaScript | 成熟稳定、社区支持好 | 传统自动化、兼容性要求高 |
| Cypress | JavaScript | 前端友好、调试体验佳 | 前端测试、简单爬虫 |
Puppeteer 实战示例
Puppeteer 是Chrome官方团队开发的Node.js库,提供完整的Chrome DevTools Protocol API。
核心特性
- Chrome官方支持,功能完整
- 隐身模式,避免数据干扰
- 反检测机制,提高成功率
- 异步处理,性能优异
完整代码示例
javascript
const puppeteer = require('puppeteer');
class PuppeteerScraper {
constructor(options = {}) {
this.options = {
headless: true,
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage',
'--disable-accelerated-2d-canvas',
'--no-first-run',
'--no-zygote',
'--disable-gpu'
],
...options
};
}
async init() {
this.browser = await puppeteer.launch(this.options);
// 创建隐身模式上下文,避免数据共享干扰
this.context = await this.browser.createIncognitoBrowserContext();
// 反检测设置
await this.context.addInitScript(() => {
// 隐藏webdriver属性
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
// 修改navigator属性
const newProto = navigator.__proto__;
delete newProto.webdriver;
navigator.__proto__ = newProto;
});
return this.browser;
}
async createPage() {
const page = await this.context.newPage();
// 设置视口和用户代理
await page.setViewport({ width: 1920, height: 1080 });
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36...');
// 设置请求拦截
await page.setRequestInterception(true);
page.on('request', (req) => {
// 阻止加载图片、字体等非必要资源
if (['image', 'font', 'media'].includes(req.resourceType())) {
req.abort();
} else {
req.continue();
}
});
return page;
}
async scrape(url, selectors) {
const page = await this.createPage();
try {
await page.goto(url, { waitUntil: 'networkidle0' });
// 等待关键元素加载
if (selectors.waitFor) {
await page.waitForSelector(selectors.waitFor, { timeout: 10000 });
}
// 执行页面交互
await this.interactWithPage(page);
// 提取数据
const data = await page.evaluate((sel) => {
const result = {};
if (sel.title) {
const titleEl = document.querySelector(sel.title);
result.title = titleEl ? titleEl.textContent.trim() : '';
}
if (sel.content) {
const contentEl = document.querySelector(sel.content);
result.content = contentEl ? contentEl.textContent.trim() : '';
}
if (sel.links) {
const linkEls = document.querySelectorAll(sel.links);
result.links = Array.from(linkEls).map(el => ({
text: el.textContent.trim(),
href: el.href
}));
}
return result;
}, selectors);
return data;
} finally {
await page.close();
}
}
async interactWithPage(page) {
// 滚动页面
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
// 处理弹窗
try {
await page.click('.close-button', { timeout: 3000 });
} catch (e) {
// 弹窗不存在
}
}
async close() {
if (this.context) await this.context.close();
if (this.browser) await this.browser.close();
}
}
// 使用示例
async function example() {
const scraper = new PuppeteerScraper();
await scraper.init();
try {
const data = await scraper.scrape('https://example.com', {
waitFor: '.content',
title: 'h1',
content: '.content',
links: 'a[href]'
});
console.log('抓取结果:', data);
} finally {
await scraper.close();
}
}技术选型建议
| 项目类型 | 推荐技术栈 | 原因 |
|---|---|---|
| 快速原型 | Python + Selenium | 学习成本低、生态丰富 |
| 生产环境 | Node.js + Playwright / Puppeteer | 性能好、多浏览器支持 |
| 企业级应用 | Java + Selenium | 稳定性高、团队支持好 |
| 高性能需求 | Go + Colly | 并发能力强、资源占用低 |
法律和道德考虑
| 原则 | 说明 |
|---|---|
| 遵守robots.txt | 检查网站的爬虫协议 |
| 尊重版权 | 不抓取受版权保护的内容 |
| 遵守服务条款 | 了解目标网站使用条款 |
| 合理使用 | 不过度频繁地请求 |
反爬虫技术
智能请求头管理
javascript
class SmartHeaders {
constructor() {
this.browsers = {
chrome: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9...',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
}
};
}
getRandomHeaders() {
const browser = Object.keys(this.browsers)[
Math.floor(Math.random() * Object.keys(this.browsers).length)
];
return { ...this.browsers[browser] };
}
}代理池管理
javascript
class ProxyPool {
constructor() {
this.proxies = [];
this.currentIndex = 0;
this.failedProxies = new Map();
}
getNextProxy() {
if (this.proxies.length === 0) return null;
const proxy = this.proxies[this.currentIndex];
this.currentIndex = (this.currentIndex + 1) % this.proxies.length;
return proxy;
}
}性能优化技巧
并发控制
javascript
const { Cluster } = require('puppeteer-cluster');
(async () => {
// 创建一个具有2个并发工作器的集群
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 2,
});
// 定义任务
await cluster.task(async ({ page, data: url }) => {
await page.goto(url);
const screen = await page.screenshot();
// 存储截图或进行其他操作
});
// 队列任务
cluster.queue('http://www.google.com/');
cluster.queue('http://www.wikipedia.org/');
// 等待所有任务完成
await cluster.idle();
// 关闭集群
await cluster.close();
})();内存管理
javascript
class MemoryManager {
constructor() {
this.dataCache = new Map();
this.maxCacheSize = 1000;
}
setCache(key, value, ttl = 300000) {
if (this.dataCache.size >= this.maxCacheSize) {
this.cleanupCache();
}
this.dataCache.set(key, {
value,
timestamp: Date.now(),
ttl
});
}
}写在最后
第一次写爬虫时,我也觉得这技术很神秘。但当你成功抓取到第一个数据时,那种"原来如此"的感觉真的很棒。
开始你的爬虫之旅
- 从简单的静态页面开始
- 选择一个你熟悉的网站
- 动手写代码,不要只看不练
开始你的爬虫探索吧