一、人工智能三大概念
-
人工智能(AI)
-
定义:使用计算机模拟或代替人类智能的研究领域
-
目标:像人类一样思考(理性推理)、行动(决策执行)
-
别名:仿智
-
-
机器学习(ML)
-
定义:从数据中自动学习规律(模型),并用模型预测新数据
-
核心:基于模型自动学习(非人工规则编程)
-
示例:房价预测模型
y = ax + b(a、b为模型参数)
-
-
深度学习(DL)
-
定义:模拟人脑神经元的深度神经网络,通过多层结构学习复杂规律
-
特点:从机器学习发展而来,适合图像、语音等复杂任务
-
-
三者关系
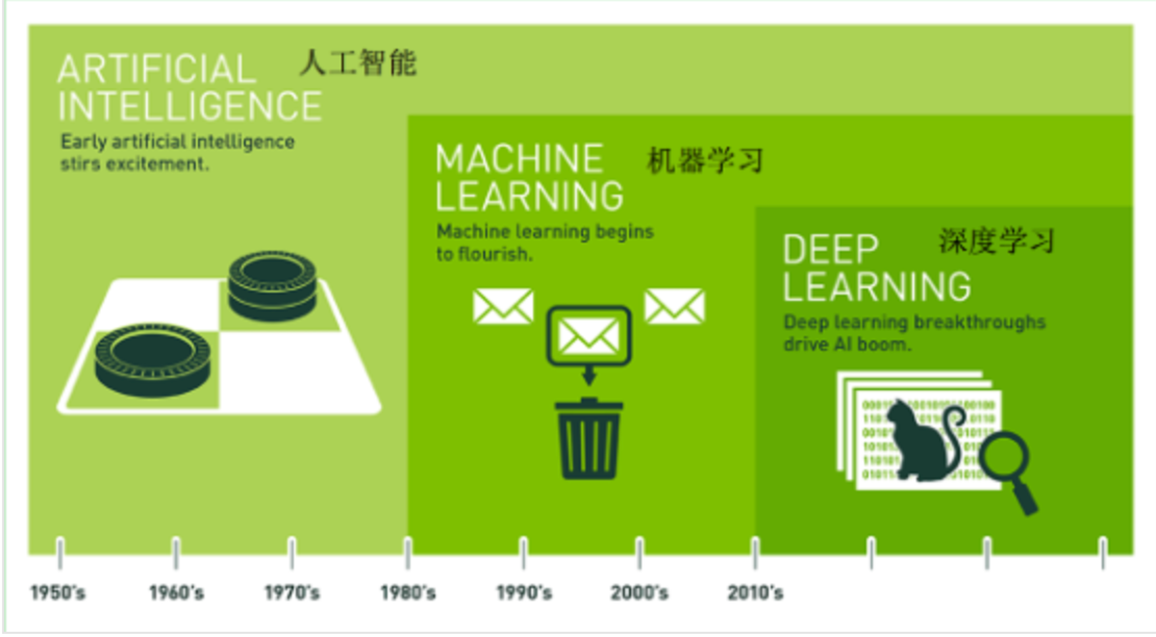
机器学习是实现人工智能的一种途径,深度学习是机器学习的一种方法
二、机器学习的应用领域与发展史
应用领域
-
计算机视觉(CV):图像/视频理解(如人脸识别)
-
自然语言处理(NLP):文本分析、机器翻译
-
数据挖掘:从大数据中发现隐藏规律
发展史
-
1956年:AI元年
-
2012年:AlexNet引爆深度学习(CV领域)
-
2017年:Transformer框架推动NLP发展
-
2022年:ChatGPT开启AIGC时代
三要素
-
数据:模型训练的基础
-
算法:解决问题的数学方法
-
算力:硬件支持(CPU/GPU/TPU)
-
CPU:适合I/O密集型任务
-
GPU:适合计算密集型任务(如神经网络训练)
-
三、机器学习常用术语
| 术语 | 说明 | 示例 |
|---|---|---|
| 样本 | 数据集中的一行数据(一条记录) | 西瓜数据集中的一条 |
| 特征 | 描述样本的属性(一列数据) | 西瓜的色泽、根蒂 |
| 标签 | 待预测的目标值 | 西瓜是否是好瓜(0/1) |
| 训练集 | 用于训练模型的数据(70-80%) | x_train, y_train |
| 测试集 | 用于评估模型的数据(20-30%) | x_test, y_test |
四、机器学习算法分类
1. 监督学习(数据含标签)
-
回归:预测连续值(如房价)
-
分类:预测离散类别(如是否垃圾邮件)
2. 无监督学习(数据无标签)
- 聚类:按样本相似性分组(如用户分群)
3. 半监督学习
- 少量标注数据 + 大量未标注数据,降低标注成本
4. 强化学习
-
智能体通过环境交互获取奖励(如AlphaGo、自动驾驶)
-
四要素:Agent, Environment, Action, Reward
五、机器学习建模流程 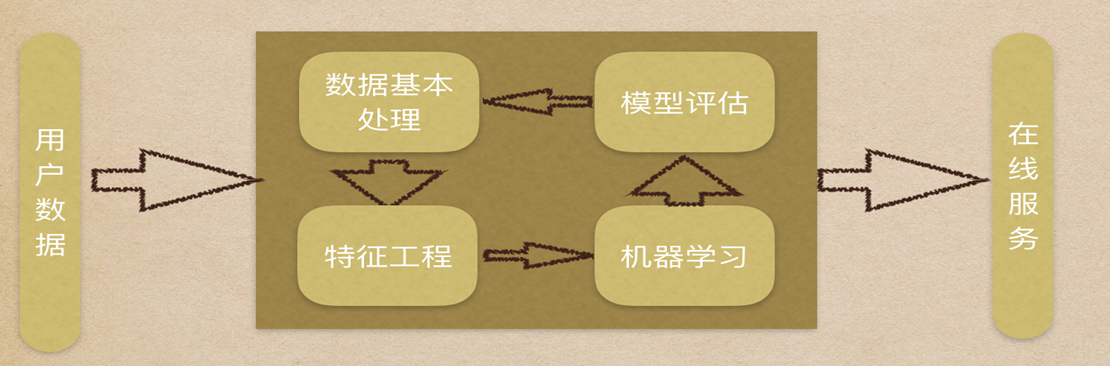
-
数据预处理:处理缺失值、异常值
-
特征工程(核心耗时步骤):
- 特征提取 → 特征预处理 → 特征降维 → 特征选择 → 特征组合
-
模型训练:选择算法(如线性回归、决策树)
-
模型评估:
-
回归:均方误差(MSE)
-
分类:准确率、召回率
-
六、特征工程详解
目标:提升模型效果,是影响模型上限的关键
原则:数据和特征 > 模型算法
| 步骤 | 作用 |
|---|---|
| 特征提取 | 从原始数据构造特征向量(如文本转词向量) |
| 特征预处理 | 标准化/归一化,消除特征量纲影响(如MinMax缩放) |
| 特征降维 | 降低特征维度,保留主要信息(如PCA) |
| 特征选择 | 筛选与任务相关的特征子集(不修改原始数据) |
| 特征组合 | 合并特征(如乘法/加法),增强表达能力(如组合"面积×位置"预测房价) |
七、模型拟合问题
| 问题 | 表现 | 原因 | 解决方案 |
|---|---|---|---|
| 欠拟合 | 训练集和测试集效果均差 | 模型过于简单 | 增加特征、增强模型复杂度 |
| 过拟合 | 训练集效果好,测试集效果差 | 模型复杂/数据噪声多 | 简化模型、正则化、增加数据量 |
核心概念
-
泛化能力 :模型在新数据上的表现(最终目标)
-
奥卡姆剃刀原则:相同效果下,选择更简单的模型
八、开发环境
-
工具 :
scikit-learn(Python库)-
特点:
-
基于NumPy/SciPy/matplotlib
-
开源,支持分类/回归/聚类等算法
-
-
安装:
pip install scikit-learn
-
关键总结
-
学习方式:
- 规则编程(人工定义逻辑) → 机器学习(自动学习模型)
-
核心链路:
数据 → 特征工程 → 模型训练 → 评估优化 -
避坑指南:
-
优先解决特征工程,再优化模型
-
模型选择:简单模型优先,避免过拟合
-