本文由 简悦 SimpRead 转码, 原文地址 blog.csdn.net
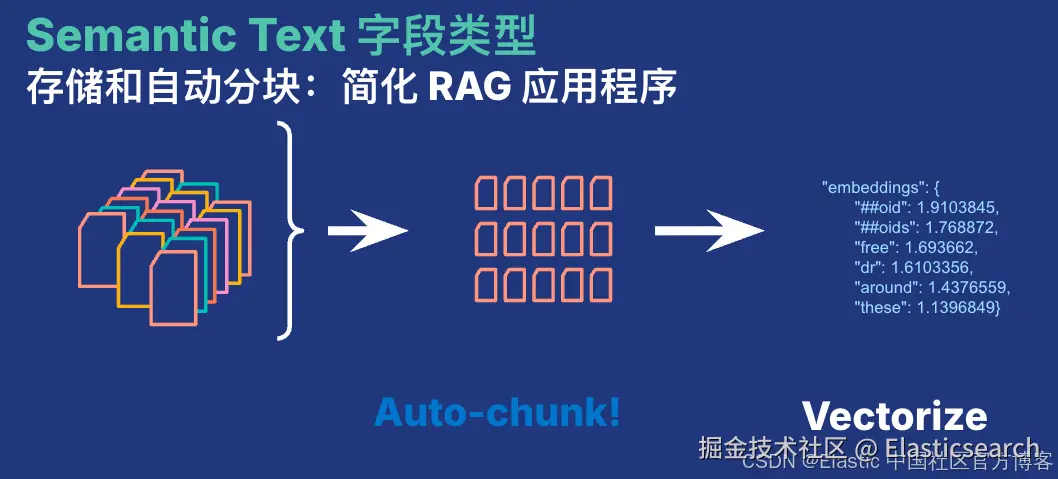
semantic_text 字段类型会使用推理端点自动为文本内容生成向量嵌入。长文本会自动被分块,以便处理更大规模的语料。它同时支持稀疏向量(sparse vector )及密集向量(dense vector)。它为我们的搜索带来极大的方便。我们无需知道这个字段是密集向量还是稀疏向量。对于它们的搜索,所有的查询语句都是一样的。
semantic_text 字段需要指定一个推理端点标识符,用于生成嵌入。你可以通过 Create inference API 来创建推理端点。这个字段类型和 semantic query 类型让你更容易在数据上执行语义搜索。semantic_text 字段也可以通过 match、sparse_vector 或 knn 查询来检索。
如果没有指定推理端点,inference_id 字段会默认使用 .elser-2-elasticsearch,这是 elasticsearch 服务预配置的端点。
使用 semantic_text 时,你不需要指定如何为数据生成嵌入,或者如何索引。推理端点会自动决定嵌入生成、索引和查询方式。
在 9.1.0 版本中,带有 semantic_text 字段并使用 dense embeddings 的新建索引会自动量化为 bbq_hnsw,只要其维度至少为 64。
安装
Elasticsearch 及 Kibana
如果你还没有安装好你自己的 Elasticsearch 及 Kibana,那么请参考如下的文章来进行安装:
在安装的时候,请参考 Elastic Stack 8.x/9.x 的安装指南来进行。在本次安装中,我将使用 Elastic Stack 9.1.2 来进行展示。
首次安装 Elasticsearch 的时候,我们可以看到如下的画面:
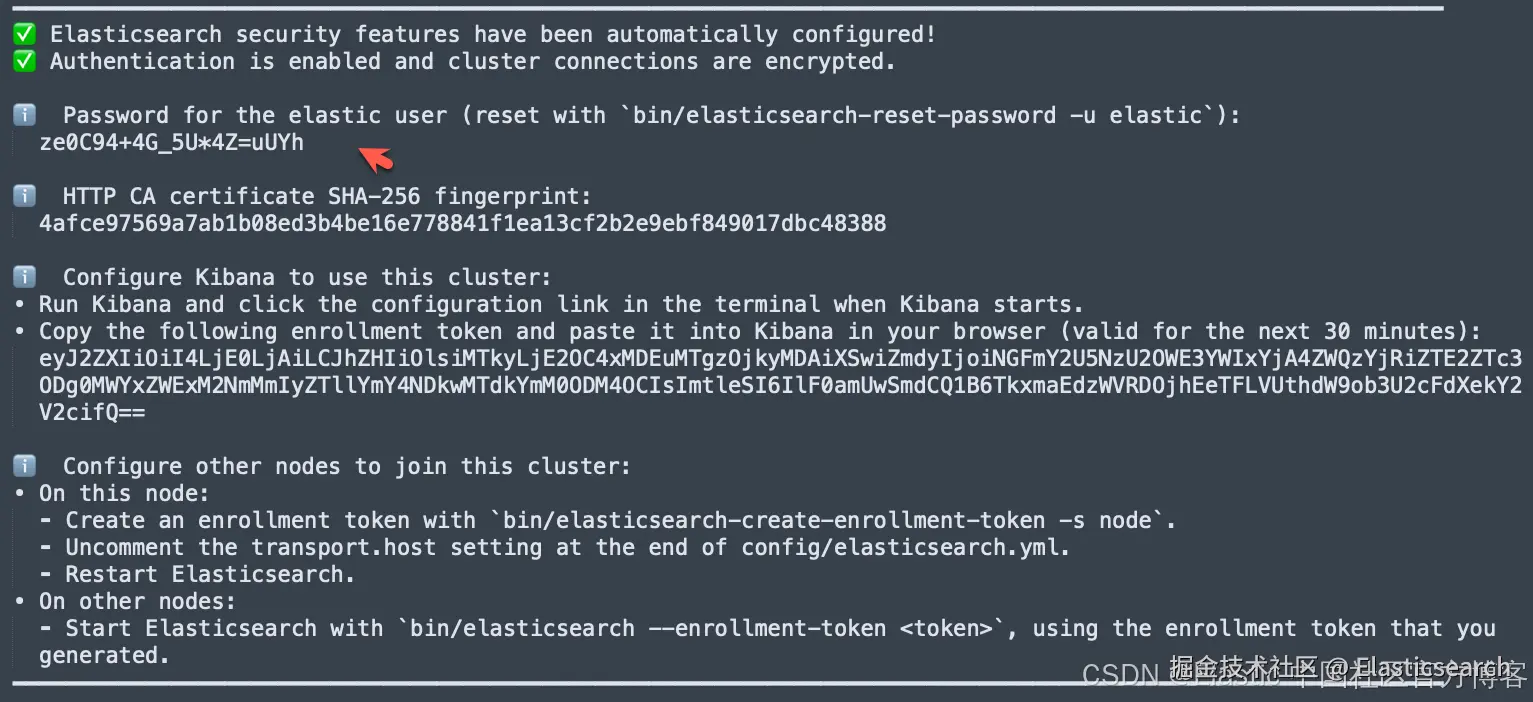
我们按照上面的链接把 Elasticsearch 及 Kibana 安装好。
下周 ELSER 及 E5 模型
在我们如下的练习中,我们将下载 Elastic 自带的模型:ELSER(稀疏向量) 及 E5(密集向量)。由于这两个嵌入模型是安装在 Elasticsearch 的机器学习节点上的,我们需要启动白金试用。特别值得指出的是:如果你不使用 Elasticsearch 机器学习节点来向量化你的语料,那么你不必启动白金试用。你可以在 Python 代码里实现数据的向量化,或者使用第三方的端点来进行向量化,而只把 Elasticsearch 当做一个向量数据库来使用!
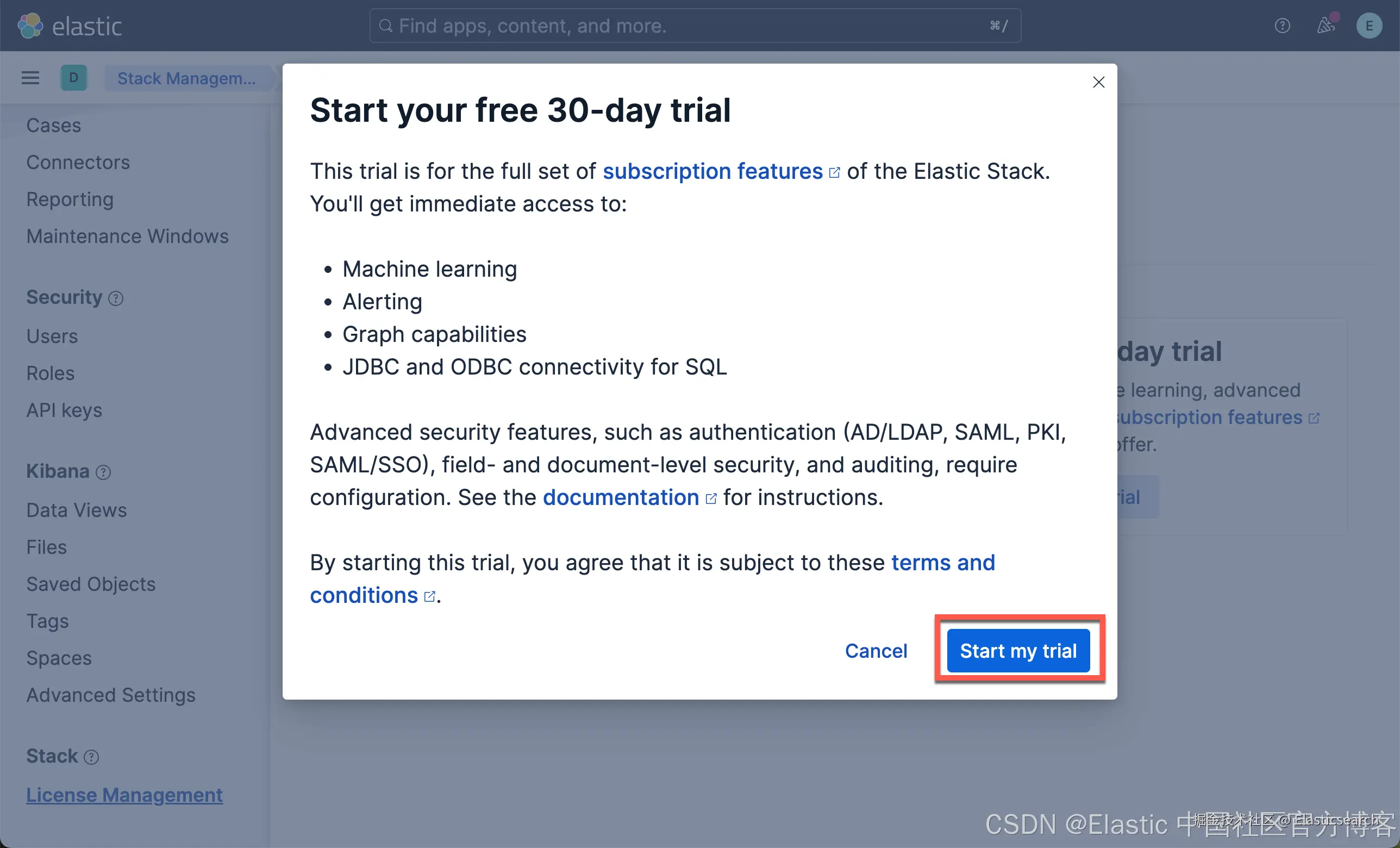
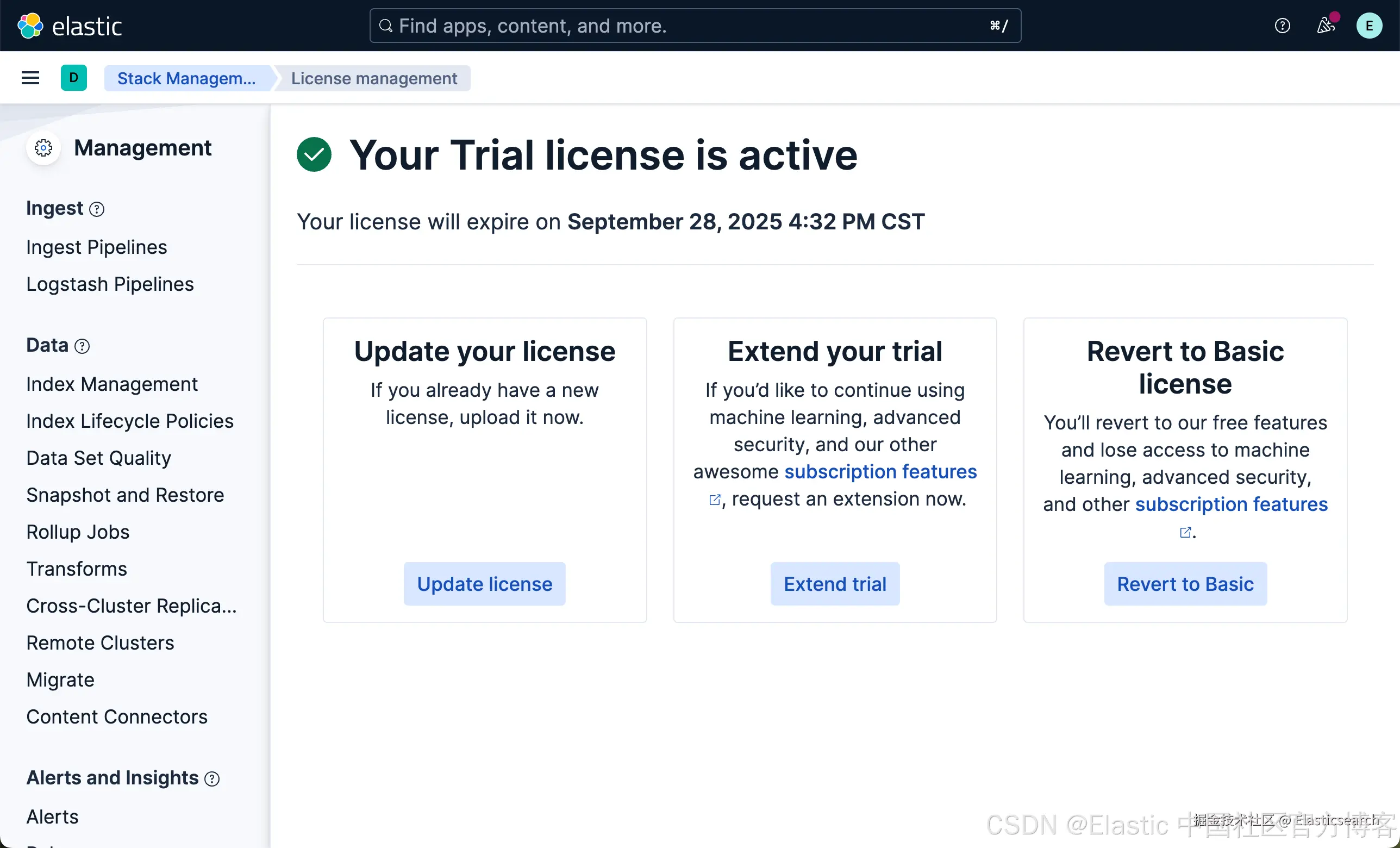
这样我们就启动了白金试用。
我们现在下载 ELSER 及 E5 嵌入模型:
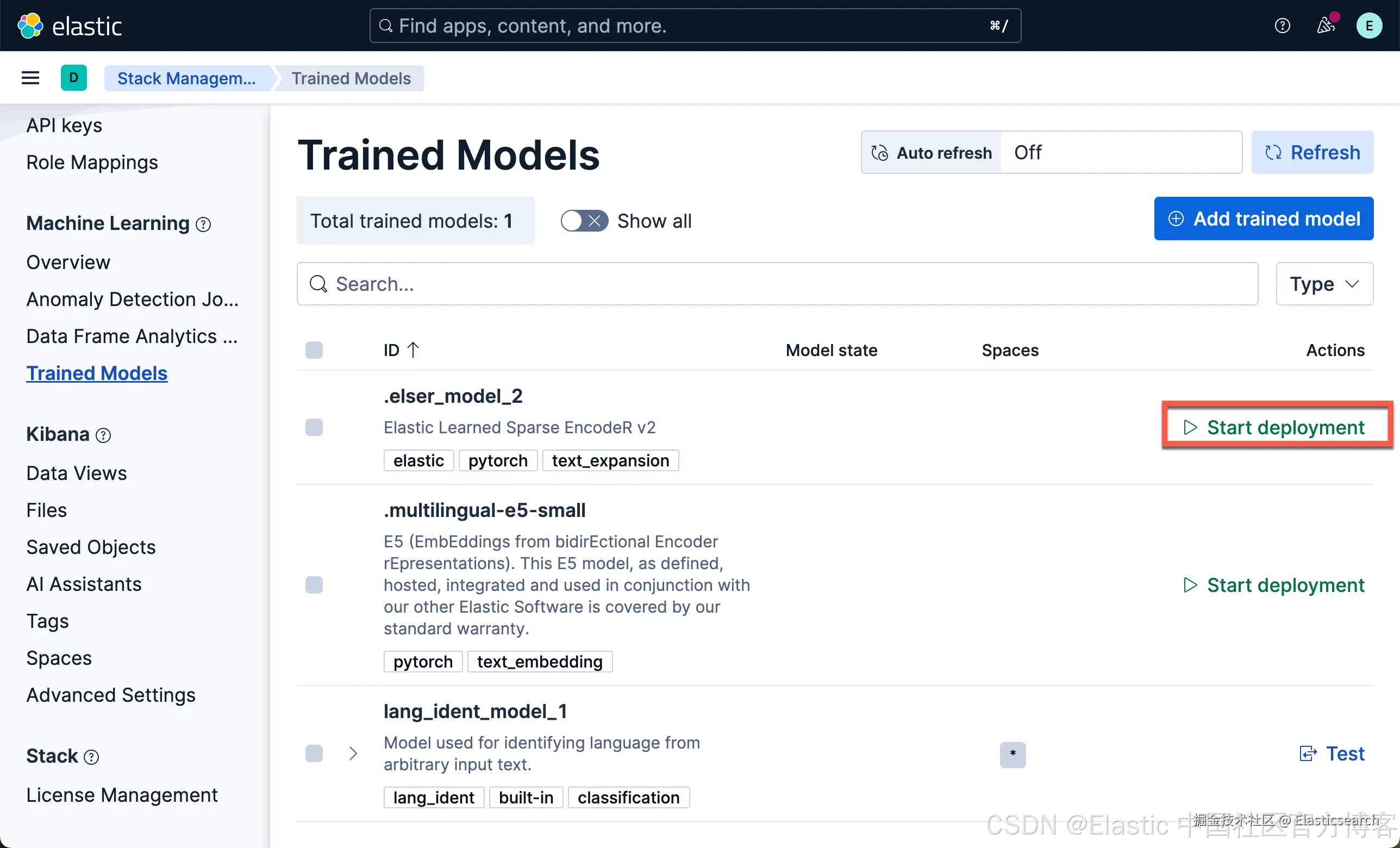
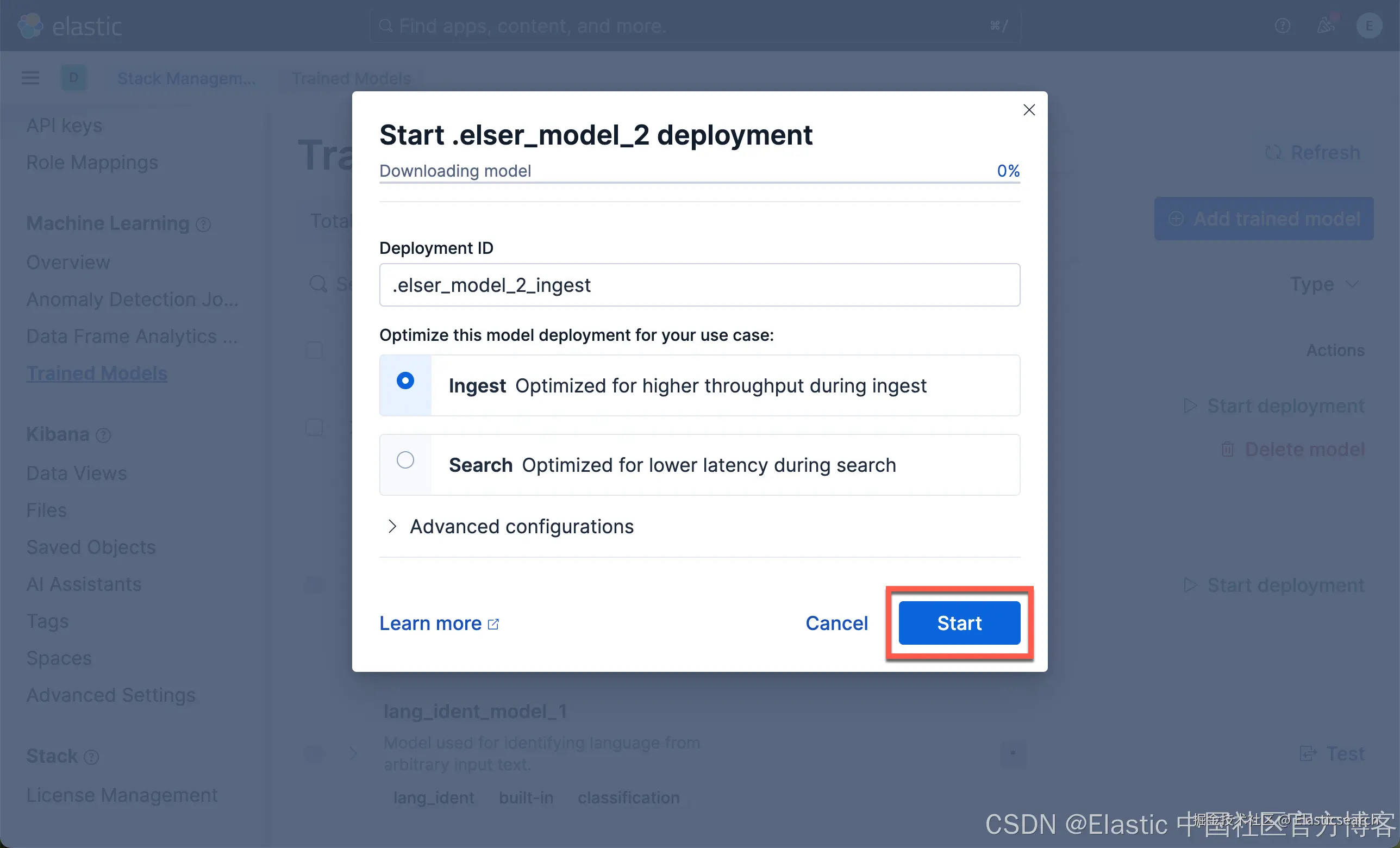
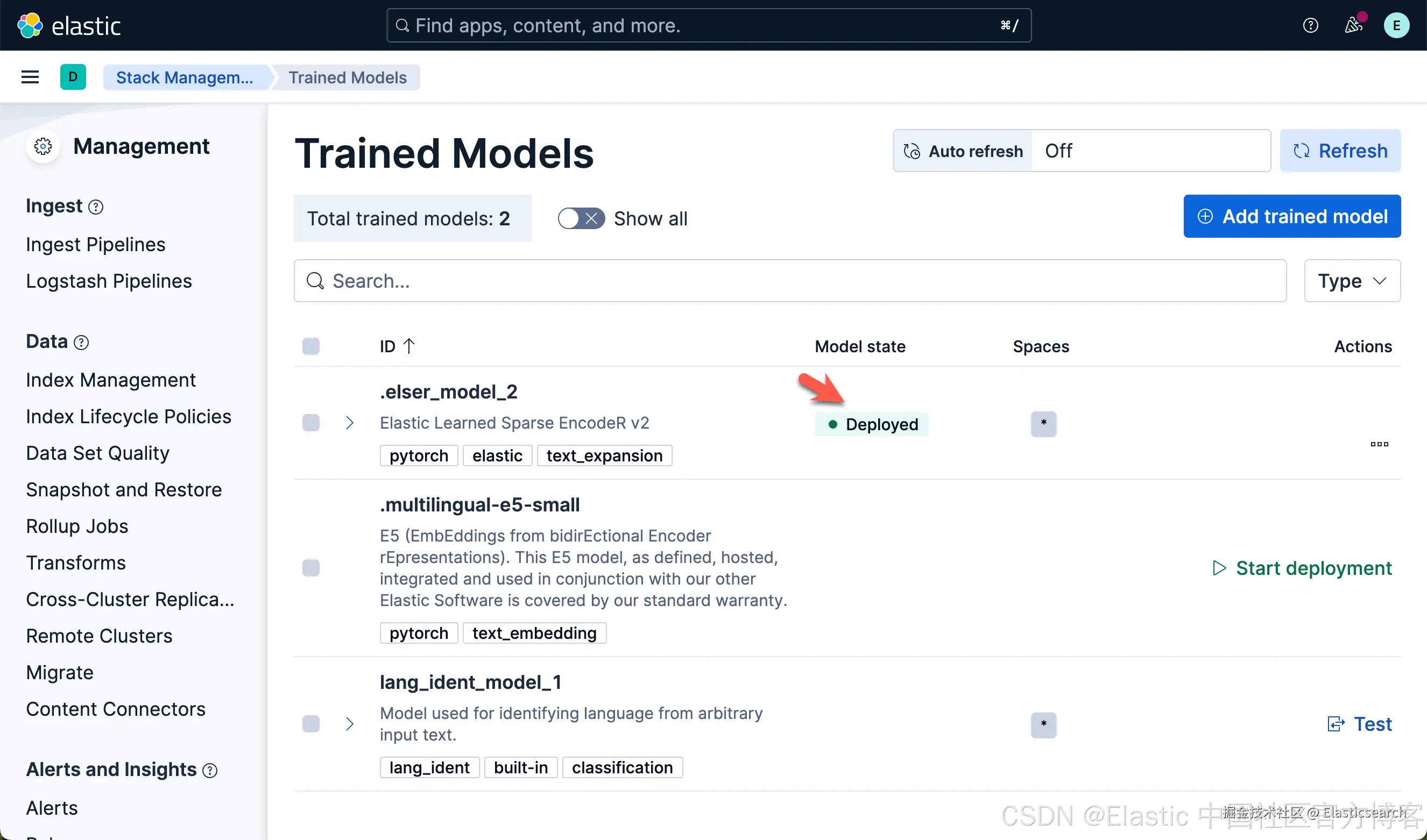
我们按照同样的方法来部署 E5 模型:
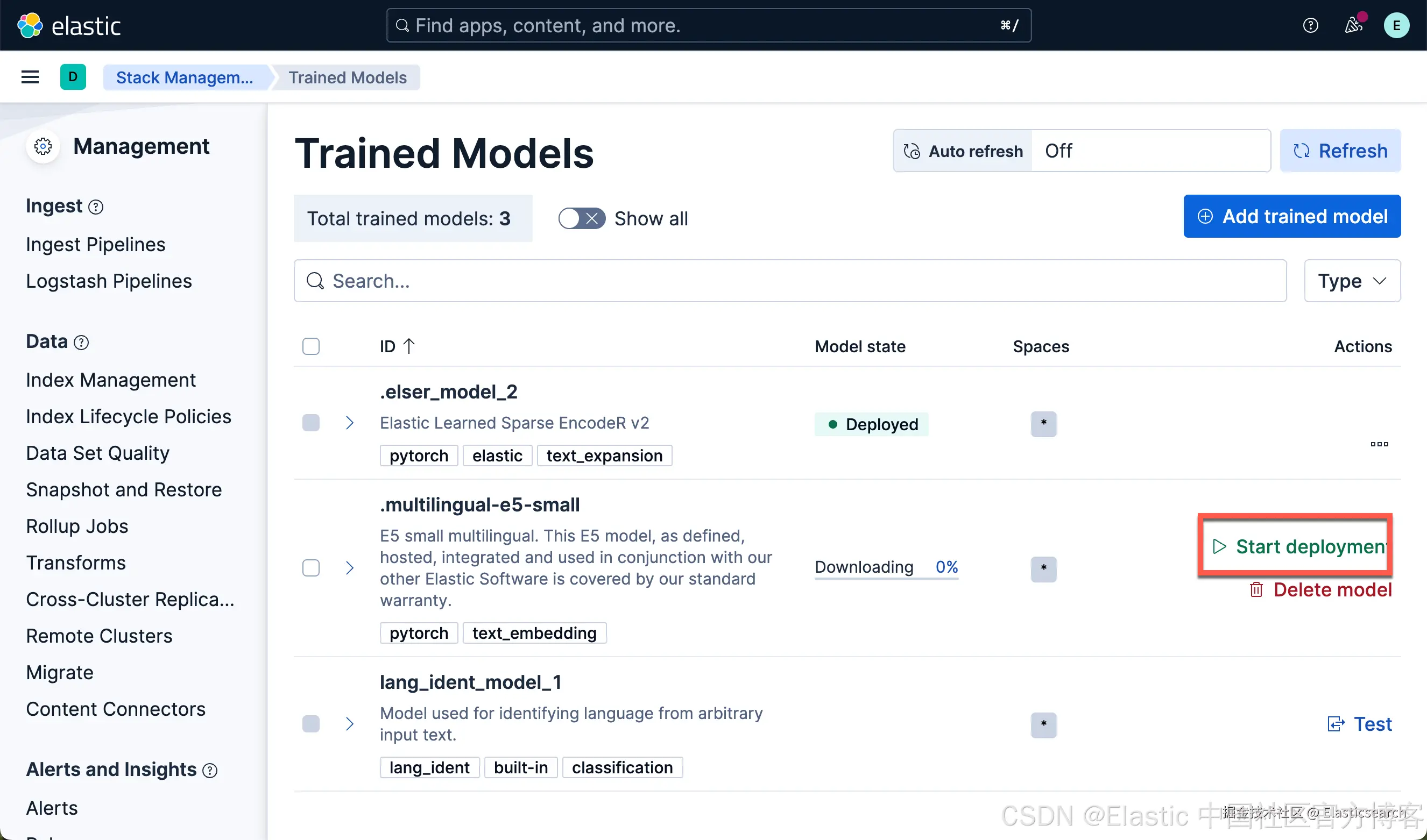
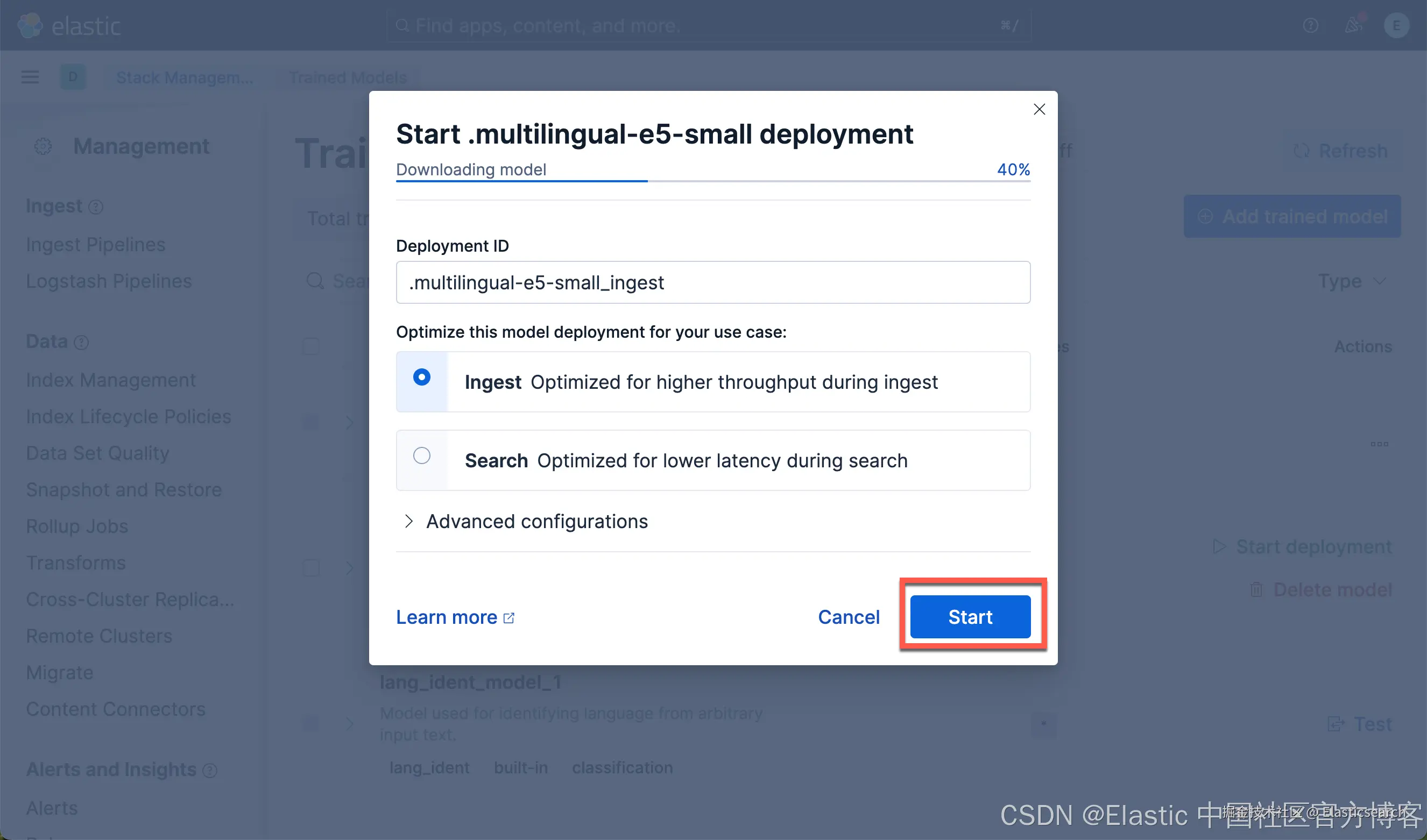
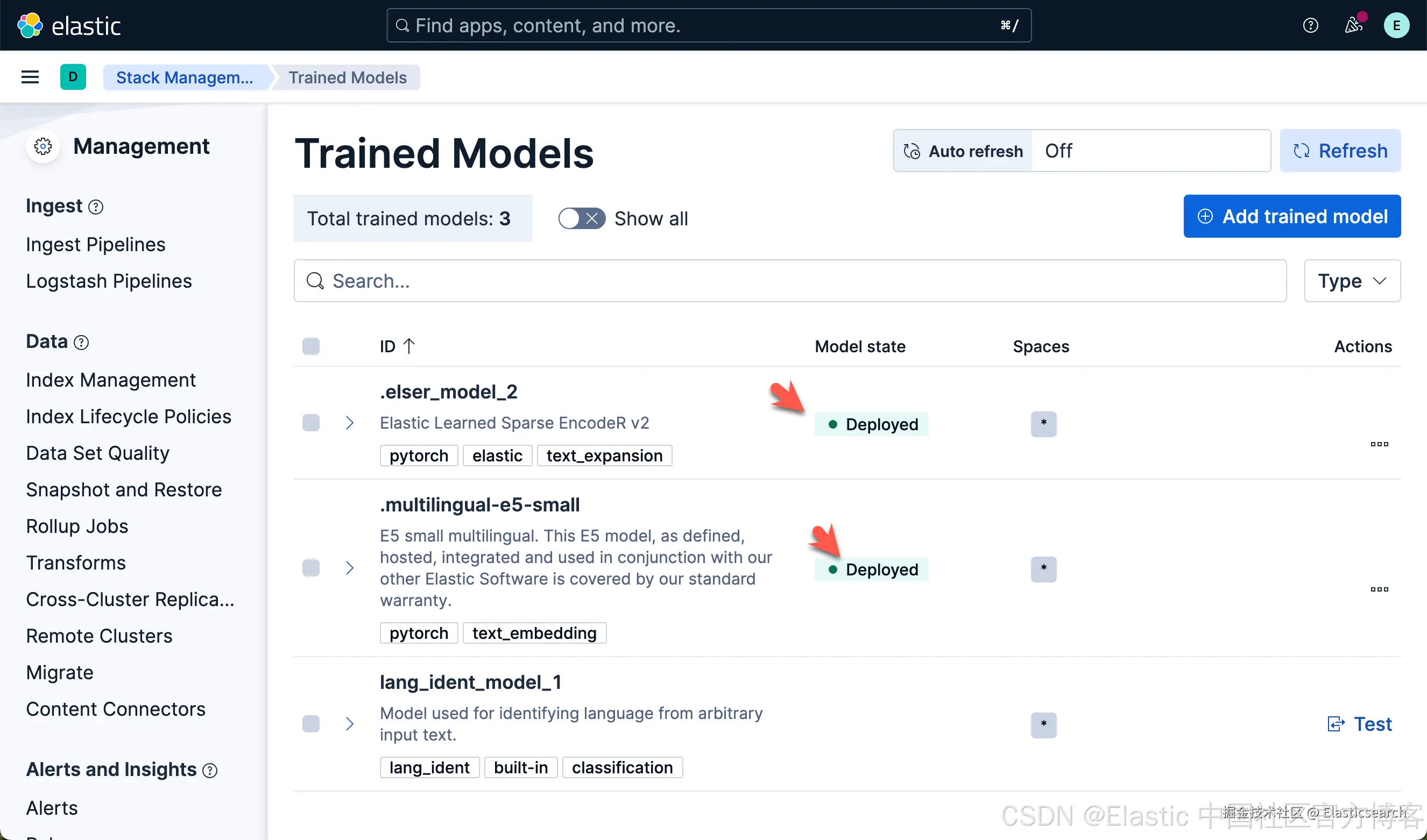
我们可以看到上面的两个模型都已经部署好了。如果你想部署其它的模型,可以参考文章 "Elasticsearch:如何部署 NLP:文本嵌入和向量搜索" 使用 eland 来上传模型。
我们可以通过如下的命令来查看已经创建好的 inference endpoints:
bash
`GET _inference/_all`AI写代码
bash
`2. "endpoints": [
3. {
4. "inference_id": ".elser-2-elasticsearch",
5. "task_type": "sparse_embedding",
6. "service": "elasticsearch",
7. "service_settings": {
8. "num_threads": 1,
9. "model_id": ".elser_model_2",
10. "adaptive_allocations": {
11. "enabled": true,
12. "min_number_of_allocations": 0,
13. "max_number_of_allocations": 32
14. }
15. },
16. "chunking_settings": {
17. "strategy": "sentence",
18. "max_chunk_size": 250,
19. "sentence_overlap": 1
20. }
21. },
22. {
23. "inference_id": ".multilingual-e5-small-elasticsearch",
24. "task_type": "text_embedding",
25. "service": "elasticsearch",
26. "service_settings": {
27. "num_threads": 1,
28. "model_id": ".multilingual-e5-small",
29. "adaptive_allocations": {
30. "enabled": true,
31. "min_number_of_allocations": 0,
32. "max_number_of_allocations": 32
33. }
34. },
35. "chunking_settings": {
36. "strategy": "sentence",
37. "max_chunk_size": 250,
38. "sentence_overlap": 1
39. }
40. },
41. {
42. "inference_id": ".rerank-v1-elasticsearch",
43. "task_type": "rerank",
44. "service": "elasticsearch",
45. "service_settings": {
46. "num_threads": 1,
47. "model_id": ".rerank-v1",
48. "adaptive_allocations": {
49. "enabled": true,
50. "min_number_of_allocations": 0,
51. "max_number_of_allocations": 32
52. }
53. },
54. "task_settings": {
55. "return_documents": true
56. }
57. },
58. {
59. "inference_id": "my-elser-model",
60. "task_type": "sparse_embedding",
61. "service": "elasticsearch",
62. "service_settings": {
63. "num_allocations": 1,
64. "num_threads": 1,
65. "model_id": ".elser_model_2"
66. },
67. "chunking_settings": {
68. "strategy": "sentence",
69. "max_chunk_size": 250,
70. "sentence_overlap": 1
71. }
72. }
73. ]
74. }`AI写代码注意 :系统帮我们创建好的 inference endpoints 是以点开始的,比如 .elser-2-elasticsearch
从上面的输出中,我们可以看到有几个已经被预置的 endpoints。我们可以使用如下的命令来创建我们自己的 endpoint:
bash
`
1. PUT _inference/text_embedding/multilingual_embeddings
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": ".multilingual-e5-small",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码在上面,我们创建了一个叫做 multilingual_embeddings 的 endpoint。如果不是特别要求,我们可以使用系统为我们提供的 .multilingual-e5-small-elasticsearch 端点。
我们可以使用如下的方法来创建一个 ESLER 的 endpoint:
bash
`
1. PUT _inference/sparse_embedding/my-elser-model
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "model_id": ".elser_model_2",
6. "num_allocations": 1,
7. "num_threads": 1
8. }
9. }
`AI写代码默认和自定义 endpoints
你可以在 semantic_text 字段中使用预配置的 endpoints,这对大多数用例很理想,或者创建自定义 endpoints 并在字段映射中引用它们。
使用默认的 ELSER endpoint
如果你使用预配置的 .elser-2-elasticsearch endpoint,你可以通过以下 API 请求设置 semantic_text:
markdown
`
1. PUT my-index-000001
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text"
7. }
8. }
9. }
10. }
`AI写代码在上面,我们没有指定任何的 inference_id,那么它使用的就是上面我们显示的 .elser-2-elasticsearch。这个是系统帮我已经创建好了的。
我们可以使用默认的 endpoints 来创建向量:
markdown
`
1. POST _inference/sparse_embedding/.elser-2-elasticsearch
2. {
3. "input": "The sky above the port was the color of television tuned to a dead channel."
4. }
`AI写代码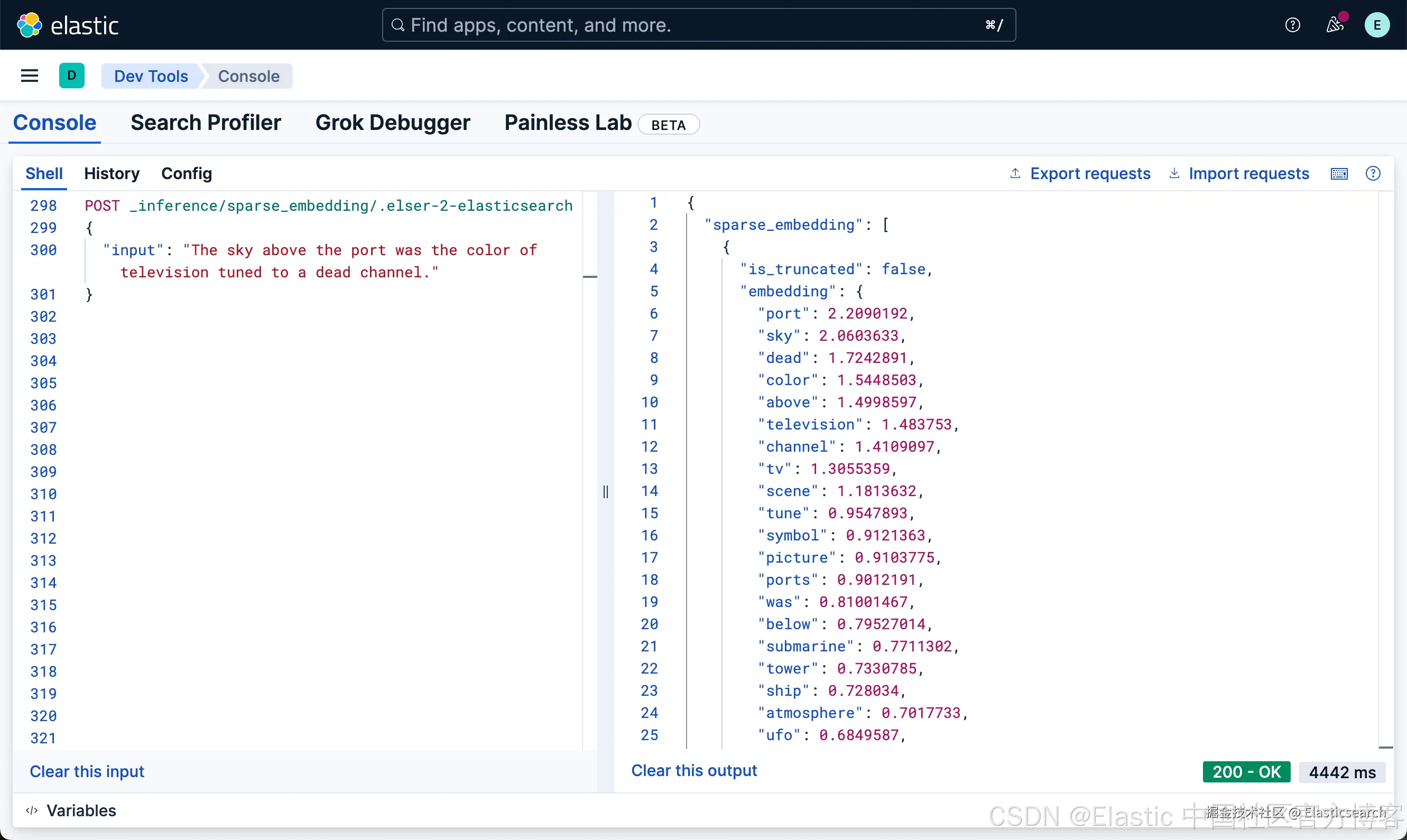
当我们向我们之前创建的索引里写入数据时,它会自动帮我们创建向量,比如:
bash
`
1. PUT my-index-000001/_doc/1
2. {
3. "inference_field": "The sky above the port was the color of television tuned to a dead channel."
4. }
`AI写代码我们针对这个索引来进行查询:
bash
`GET my-index-000001/_search`AI写代码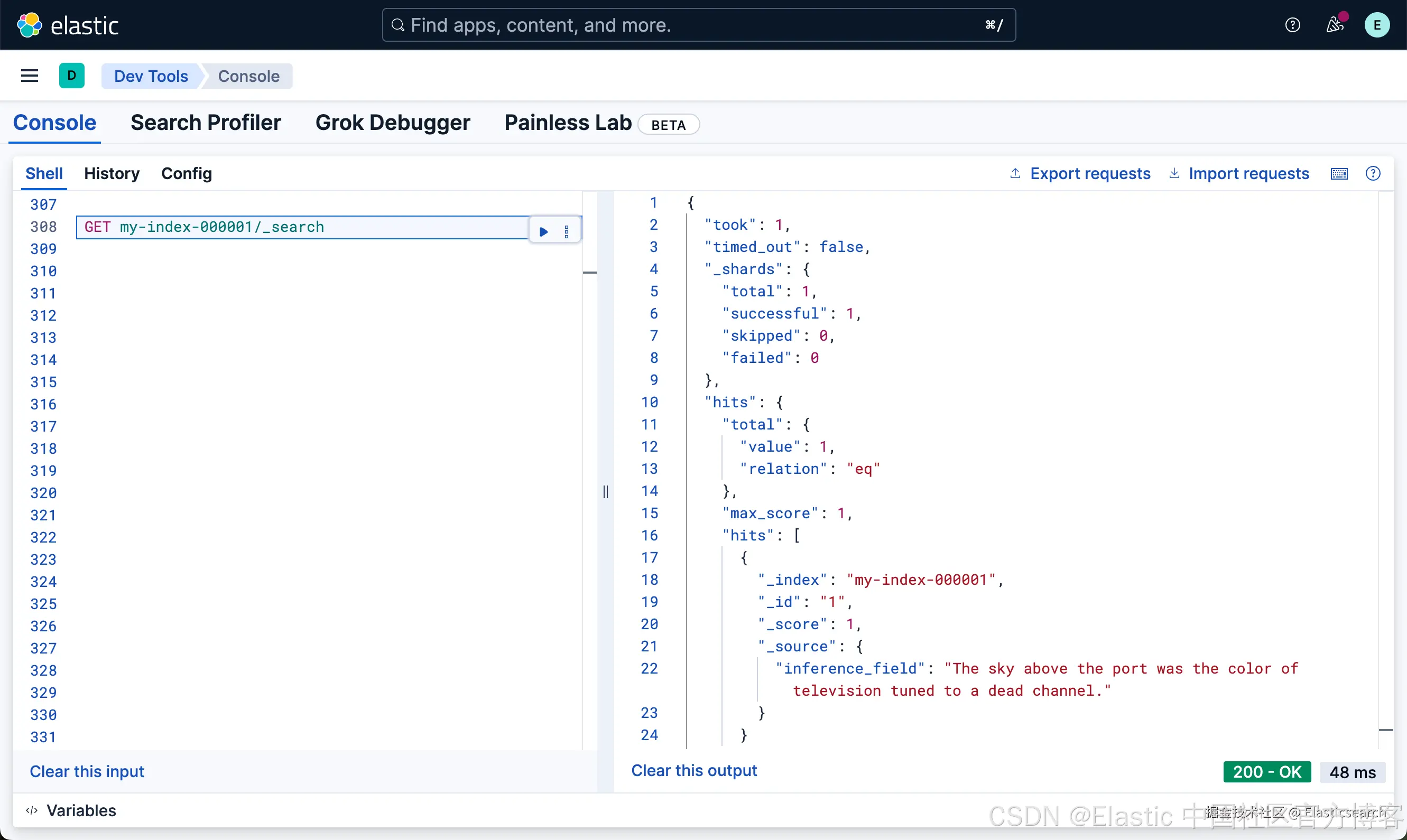
如上所示,我们并没有看在 _source 字段里到所生成的向量。这是为什么呢?这个是因为早期的版本里是含有这个向量的,但是由于它增加了存储,在之后的版本里就再没有这个向量字段了。我们可以详细地阅读这两篇文章:
那么我们该如何得到这些向量呢?我们可以使用如下的这个 API:
bash
`
1. GET my-index-000001/_search
2. {
3. "query": {
4. "semantic": {
5. "field": "inference_field",
6. "query": "what is the color of the sky above the port"
7. }
8. }
9. }
`AI写代码在 8.18 之后的版本,我们甚至直接可以使用 match 来进行代替 semantic。
bash
`
1. GET my-index-000001/_search
2. {
3. "query": {
4. "match": {
5. "inference_field": "what is the color of the sky above the port"
6. }
7. },
8. "fields": [
9. "_inference_fields"
10. ]
11. }
`AI写代码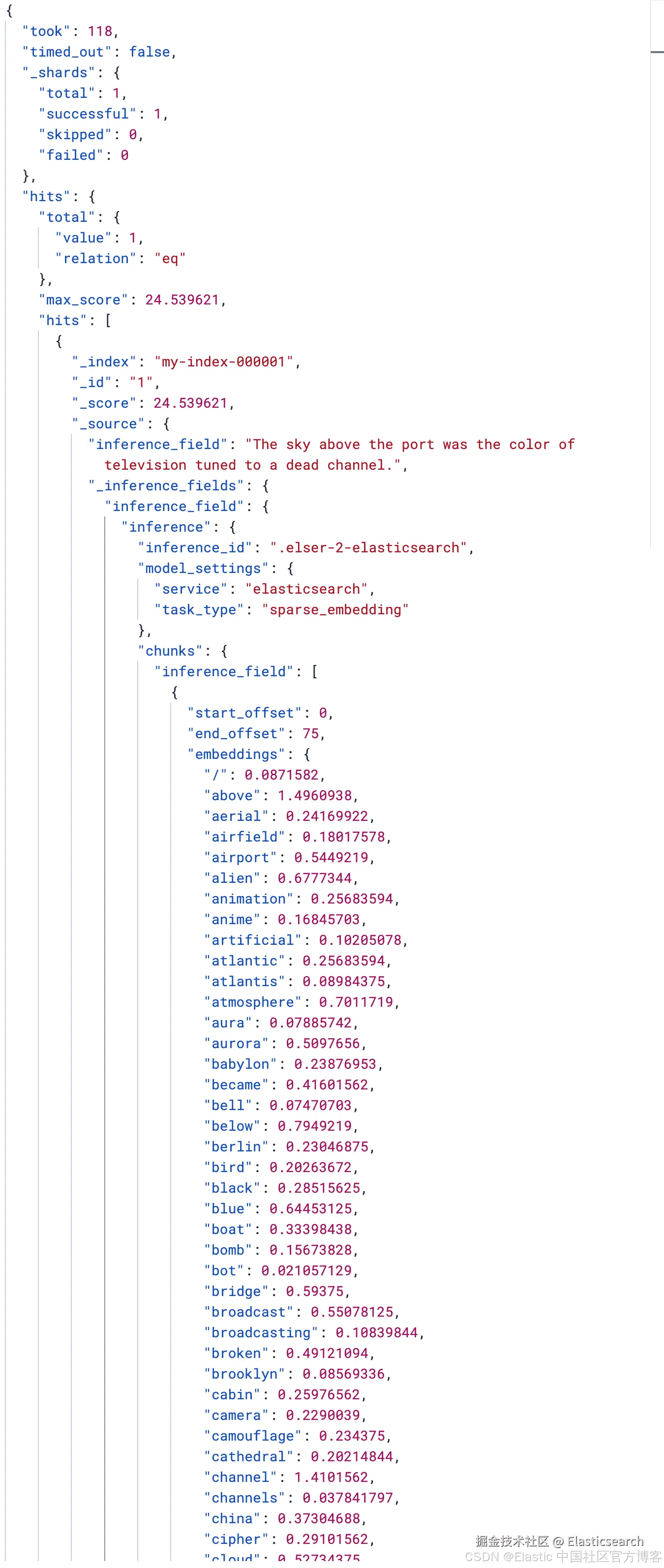
从上面的输出中,我们可以看到 chunks 下的向量。
我们也可以使用 ES|QL 来对 semantic_text 字段来进行查询:
python
`
1. POST _query?format=txt
2. {
3. "query": """
4. FROM my-index-000001 METADATA _score
5. | WHERE inference_field:"what is the color of the sky above the port"
6. | SORT _score DESC
7. """
8. }
`AI写代码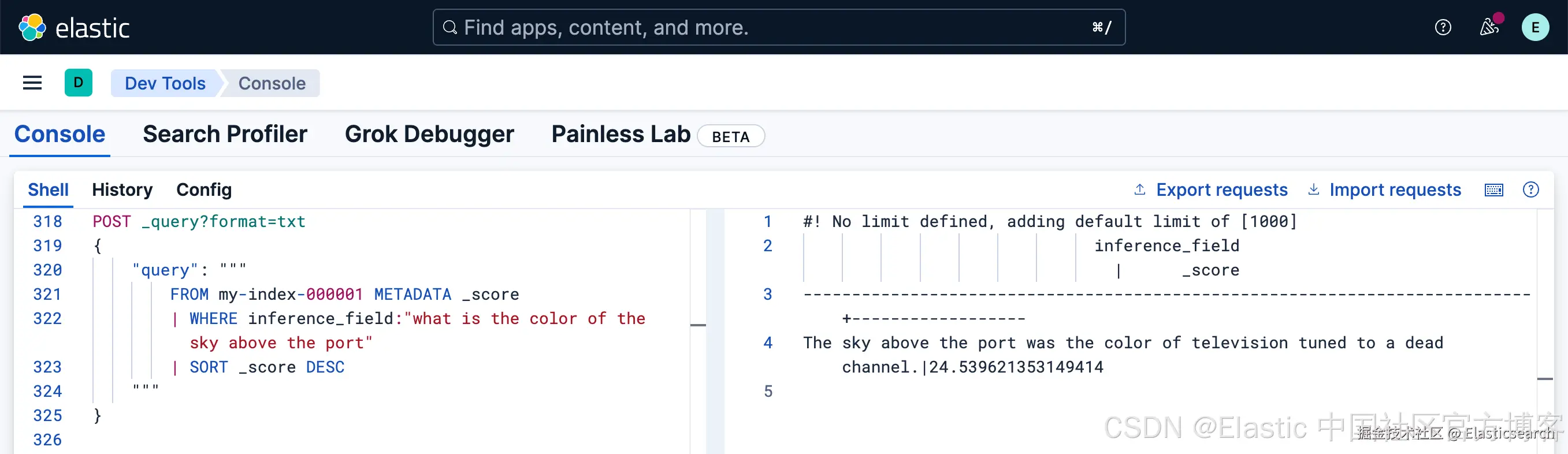
如果你想把搜索到的结果接入到 LLM 并进行推理的话,那么请相信阅读文章 "使用 ES|QL COMPLETION + 一个 LLM 在 5 分钟内编写一个 Chuck Norris 事实生成器"。
使用自定义 endpoint
要使用自定义的 inference endpoint 而不是默认的 .elser-2-elasticsearch,你必须通过 Create inference API 创建它,并在设置 semantic_text 字段类型时指定其 inference_id。
bash
`
1. PUT my-index-000002
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text",
7. "inference_id": "multilingual_embeddings" /* 1 */
8. }
9. }
10. }
11. }
`AI写代码- 用于生成 embeddings 的 inference endpoint 的 inference_id。
使用 semantic_text 的推荐方式是为 ingestion 和 search 配置专用的 inference endpoints。这可以确保 search 速度不受 ingestion 工作负载的影响,反之亦然。在为两者创建专用 inference endpoints 后,你可以在为使用 semantic_text 字段的索引设置索引映射时,通过 inference_id 和 search_inference_id 参数引用它们。
bash
`
1. PUT my-index-000003
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text",
7. "inference_id": "my-elser-endpoint-for-ingest",
8. "search_inference_id": "my-elser-endpoint-for-search"
9. }
10. }
11. }
12. }
`AI写代码在上面,我们针对 ingest 及 search 使用不同的 endpoints。这样可以确保 search 不受 ingest 工作负载的大小而影响搜索的速度。
我们下面来展示一个长字符串的搜索:
bash
`
1. PUT my-semantic-index
2. {
3. "mappings": {
4. "properties": {
5. "content": {
6. "type": "semantic_text",
7. "inference_id": "multilingual_embeddings"
8. }
9. }
10. }
11. }
`AI写代码
bash
`
1. PUT my-semantic-index/_doc/1
2. {
3. "content": "腾讯(Tencent)成立于1998年,总部位于中国深圳,是中国最具影响力的互联网和科技公司之一,也是全球领先的科技企业。腾讯最初以即时通讯工具 QQ 闻名,凭借 QQ 的即时通讯功能、社交互动以及丰富的增值服务,迅速积累了庞大的用户群体,奠定了公司在中国互联网行业的基础。随后,腾讯推出了微信(WeChat),这款集通讯、社交、支付、内容和生活服务于一体的超级应用,成为中国最普及的移动社交平台,也在全球范围内拥有亿级用户,进一步巩固了腾讯在数字生活领域的领导地位。在业务布局方面,腾讯形成了以社交和通信为核心、以数字内容、金融科技和企业服务为支撑的多元化生态体系。其数字内容业务涵盖了网络游戏、视频、音乐、文学等多个领域,其中腾讯游戏是全球最大的游戏公司之一,拥有《王者荣耀》《和平精英》等知名游戏作品,同时投资和代理了大量国内外热门游戏产品。腾讯的在线视频平台腾讯视频、在线音乐平台腾讯音乐娱乐集团,以及数字阅读平台阅文集团,也在各自领域占据重要市场份额,为用户提供丰富的娱乐和信息内容。在金融科技和商业服务方面,腾讯通过微信支付、QQ 钱包等提供移动支付、理财和消费金融服务,推动了中国移动支付的普及和电子商务的发展。此外,腾讯云(Tencent Cloud)作为公司重要的战略业务板块,为企业和开发者提供云计算、人工智能、大数据、物联网等技术服务,支持数字化转型和创新发展。腾讯还积极布局人工智能、区块链、医疗科技、教育科技等前沿科技领域,推动技术创新与应用落地。腾讯注重投资和生态建设,通过战略投资、孵化和合作,建立了涵盖社交、娱乐、金融、出行、医疗等多个领域的生态网络。腾讯投资了包括京东、美团、拼多多、滴滴出行、B站等在内的众多知名企业,形成了开放互联的产业生态,增强了公司在数字经济中的影响力和竞争力。同时,腾讯也不断推动国际化发展,参与全球科技创新和跨境合作,提升其在全球科技产业中的话语权。在企业文化方面,腾讯强调创新驱动和用户价值,以"连接一切"的使命推动技术与产品创新,注重长期战略布局和社会责任。腾讯积极参与公益事业,推动教育、环保、健康等社会项目发展,致力于技术赋能社会进步。通过持续的创新、生态建设和社会责任实践,腾讯不仅在商业上取得了巨大成功,也在社会影响力和企业责任方面树立了标杆。总体而言,腾讯凭借其强大的技术实力、多元化业务布局和创新驱动的企业文化,成为中国乃至全球科技产业的重要力量。无论是在社交、娱乐、金融科技,还是在云计算和人工智能等前沿领域,腾讯都在持续探索和发展,不断推动数字经济和数字社会的建设,为用户、合作伙伴和社会创造价值。
4. "
5. }
`AI写代码我们知道 E5 small 的最高 token 长度是 512 个 token。也就是说当我们的文本输出超过 512 时,作为 semantic_text 所定义的字段,它会自动帮我们对它进行分块。我们的分块策略有 2 种。可以阅读文章 "Elasticsearch:为推理端点配置分块设置"。
在上面,我们的输入字符长度为 1000 个,那么当我们写入这个数据时,按理应该被分为两个块。我们进行如下的搜索:
bash
`
1. GET my-semantic-index/_search
2. {
3. "query": {
4. "match": {
5. "content": "腾讯投资了哪些公司?"
6. }
7. }
8. }
`AI写代码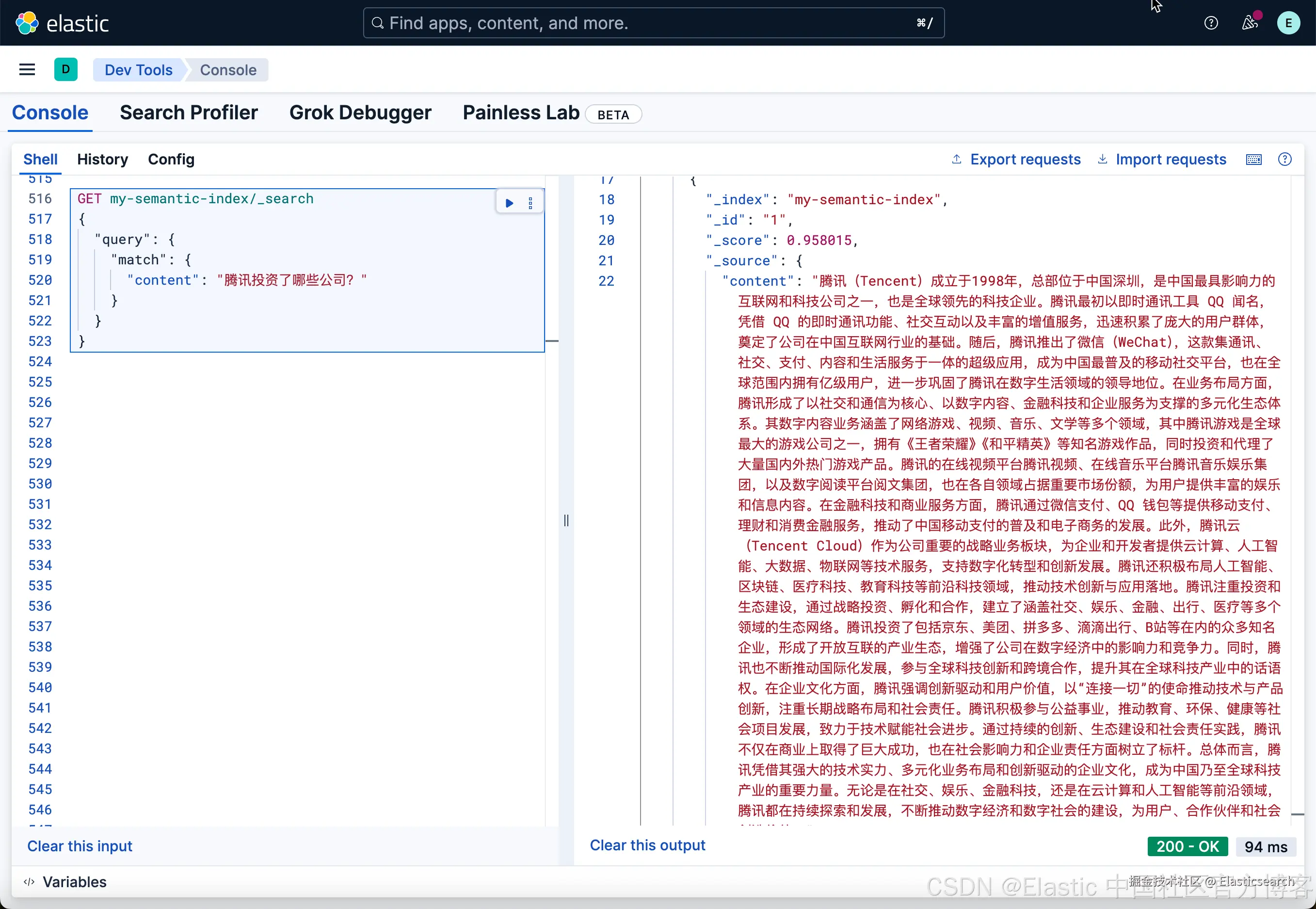
从上面的搜索结果中,我们可以看出来:它把整个的文档的内容都显示到 _source 里去了。在很多的时候,也许这个并不是我们所想要的。我们可能更希望看到是哪个 chunk 含有和我们搜索更为贴近的内容,否则把所有的内容发到 LLM,那样会增加开销。我们使用如下的查询:
bash
`
1. GET my-semantic-index/_search
2. {
3. "query": {
4. "match": {
5. "content": "腾讯投资了哪些公司?"
6. }
7. },
8. "highlight": {
9. "fields": {
10. "content": {
11. "number_of_fragments": 2,
12. "order": "score"
13. }
14. }
15. }
16. }
`AI写代码上面搜索的结果为:

在我们的搜索中,我们指名了 number_of_fragments 为 2,那么它显示了已经被分块的两个 segments。很显然第一个 chunk 更加接近我们的搜索原意。如果把第一个结果发送至 LLM,那么我们肯定可以得到我们想要的结果。当然,如果我们把 number_of_fragments 设置为 1,那么也就只有一个分块结果了。
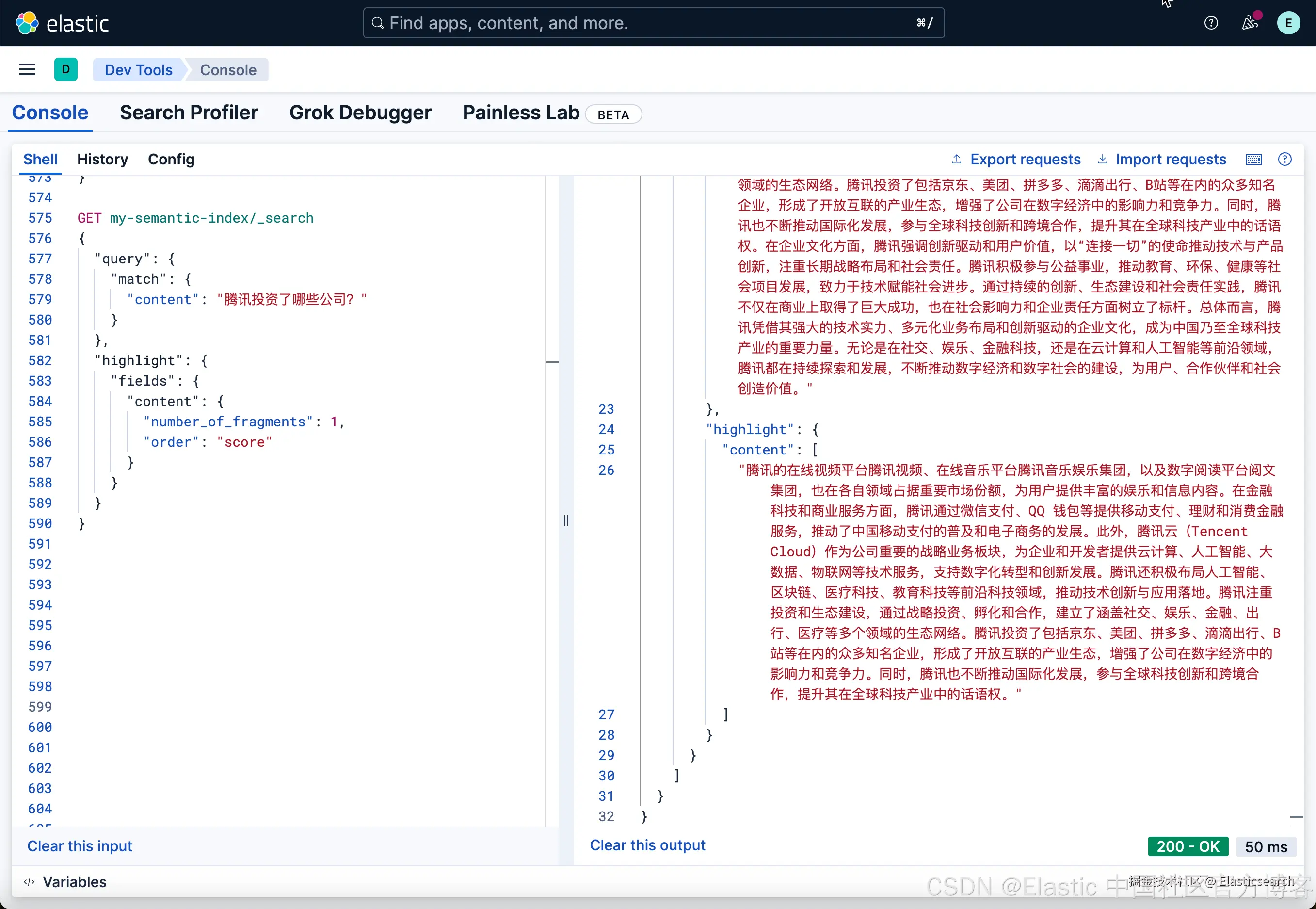
如果我们想得到这些块对应的向量,我们可以通过如下的方式来得到:
bash
`
1. GET my-semantic-index/_search
2. {
3. "query": {
4. "match": {
5. "content": "腾讯投资了哪些公司?"
6. }
7. },
8. "fields": [
9. "_inference_fields"
10. ]
11. }
`AI写代码
在未来的 9.2 版本中,Elastic 将会以更加简介的方式来展示 chunks:
bash
`
1. GET my-semantic-index/_search
2. {
3. "query": {
4. "match": {
5. "content": "腾讯投资了哪些公司?"
6. }
7. },
8. "fields": [
9. {
10. "field": "content",
11. "format": "chunks" /* 1 */
12. }
13. ]
14. }
`AI写代码- 使用 "format": "chunks" 可以将字段的文本以已索引的原始文本块形式返回。
在 EIS 上使用 ELSER
如果你使用预配置的 .elser-2-elastic endpoint,通过 Elastic Inference Service(ELSER on EIS)将 ELSER 模型作为服务使用,你可以通过以下 API 请求设置 semantic_text:
bash
`
1. PUT my-index-000001
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text",
7. "inference_id": ".elser-2-elastic"
8. }
9. }
10. }
11. }
`AI写代码注意
虽然我们鼓励进行实验,但我们不建议在此功能处于技术预览阶段时,将其用于生产用例。
semantic_text 字段参数
inference_id
(可选,字符串)用于为字段生成 embeddings 的 inference endpoint。默认使用 .elser-2-elasticsearch。此参数不可更新。使用 Create inference API 创建该 endpoint。如果指定了 search_inference_id,则该 inference endpoint 仅在索引时使用。
search_inference_id
(可选,字符串)用于在查询时生成 embeddings 的 inference endpoint。你可以通过 Update mapping API 更新此参数。使用 Create inference API 创建该 endpoint。如果未指定,将在索引和查询时使用 inference_id 定义的 inference endpoint。
index_options
Stack 9.1.0
(可选,对象)指定字段的索引选项以覆盖默认值。目前支持 dense_vector 和 sparse_vector 索引选项。对于文本 embeddings,index_options 可以匹配任何允许的 dense_vector 或 sparse_vector 索引选项。
chunking_settings
Stack 9.1.0
(可选,对象)用于将文本拆分为更小段落的设置。如果指定,这些设置将覆盖与 inference_id 关联的 Inference endpoint 中的 chunking 设置。如果更新了 chunking 设置,现有文档在重新索引前不会应用。要完全禁用 chunking,请使用 none chunking 策略。
chunking_settings 的有效值:
-
strategy
指定使用的 chunking 策略。有效值为 none、word 或 sentence。必填。
-
max_chunk_size
每个 chunk 的最大单词数。word 和 sentence 策略必填。
-
overlap
chunk 中允许的重叠单词数。不能超过 max_chunk_size 的一半。word 类型 chunking 设置必填。
-
sentence_overlap
chunk 中允许的重叠句子数。有效值为 0 或 1。sentence 类型 chunking 设置必填。
警告
使用 none chunking 策略时,如果输入超过底层模型的最大 token 限制,某些服务(如 OpenAI)可能会返回错误。相比之下,elastic 和 elasticsearch 服务会自动截断输入,以适应模型的限制。
Inference endpoint 验证
inference_id 在创建映射时不会被验证,而是在文档被写入索引时验证。当第一个文档被索引时,inference_id 将用于为字段生成底层索引结构。
Warning
删除 inference endpoint 会导致在定义了该 inference endpoint 作为 inference_id 的 semantic_text 字段的索引上,文档写入和语义查询失败。尝试删除正在 semantic_text 字段上使用的 inference endpoint 会导致错误。
文本拆分
Inference endpoints 对它们可以处理的文本量有一定限制。为了在语义搜索中使用大量文本,semantic_text 会在需要时自动生成较小的段落,称为 chunks。
每个 chunk 对应文本的一段以及从中生成的 embedding。在查询时,每个文档的单独段落会被自动搜索,并使用最相关的段落来计算分数。
chunks 以起始和结束字符偏移量存储,而不是作为单独的文本字符串。这些偏移量指向每个 chunk 在原始输入文本中的准确位置。
有关 chunking 的更多细节以及如何配置 chunking 设置,请参阅 Inference API 文档中的 配置 chunking。
参考本教程了解如何使用 semantic_text 进行语义搜索。
预拆分 - pre-chunking
你可以通过将输入作为字符串数组发送到 Elasticsearch 来进行预拆分。
例如:
bash
`
1. PUT test-index
2. {
3. "mappings": {
4. "properties": {
5. "my_semantic_field": {
6. "type": "semantic_text",
7. "chunking_settings": {
8. "strategy": "none" /* 1 */
9. }
10. }
11. }
12. }
13. }
`AI写代码- 在 my_semantic_field 上禁用 chunking。
json
`
1. PUT test-index/_doc/1
2. {
3. "my_semantic_field": ["my first chunk", "my second chunk", ...] /* 1 */
4. ...
5. }
`AI写代码- 文本已被预拆分,并以字符串数组提供。数组中的每个元素代表一个单独的 chunk,将直接发送到 inference 服务而不进行进一步拆分。
重要注意事项:
-
提供预拆分输入时,确保将 chunking 策略设置为 none,以避免额外处理。
-
每个 chunk 的大小应谨慎设置,保持在 inference 服务和底层模型的 token 限制范围内。
-
如果 chunk 超过模型的 token 限制,其行为取决于服务:
-
某些服务(如 OpenAI)会返回错误。
-
其他服务(如 elastic 和 elasticsearch)会自动截断输入。
-
检索已索引的 chunks
你可以使用 fields 参数检索由 semantic 字段的 chunking 策略生成的单个 chunks:
bash
`
1. POST test-index/_search
2. {
3. "query": {
4. "ids" : {
5. "values" : ["1"]
6. }
7. },
8. "fields": [
9. {
10. "field": "semantic_text_field",
11. "format": "chunks" /* 1 */
12. }
13. ]
14. }
`AI写代码- 使用 "format": "chunks" 将字段文本以已索引的原始文本块形式返回。
注:此功能在 9.2 版本中开始提供。
从 semantic text 中提取相关片段
你可以通过在 Search API 中使用 highlight 参数,从 semantic text 字段中提取最相关的片段。
bash
`
1. POST test-index/_search
2. {
3. "query": {
4. "match": {
5. "my_semantic_field": "Which country is Paris in?"
6. }
7. },
8. "highlight": {
9. "fields": {
10. "my_semantic_field": {
11. "number_of_fragments": 2, /* 1 */
12. "order": "score" /* 2 */
13. }
14. }
15. }
16. }
`AI写代码- 指定要返回的最大片段数。
- 设置为 score 时,将按分数对最相关的高亮片段进行排序。默认情况下,片段将按它们在字段中出现的顺序输出(order: none)。
高亮支持 semantic_text 以外的字段。然而,如果你想将高亮限制为 semantic highlighter,并在字段类型不是 semantic_text 时不返回任何片段,可以在查询中显式强制使用 semantic highlighter:
bash
`
1. PUT test-index
2. {
3. "query": {
4. "match": {
5. "my_field": "Which country is Paris in?"
6. }
7. },
8. "highlight": {
9. "fields": {
10. "my_field": {
11. "type": "semantic", /* 1 */
12. "number_of_fragments": 2,
13. "order": "score"
14. }
15. }
16. }
17. }
`AI写代码- 确保高亮仅应用于 semantic_text 字段。
要以原始索引顺序从 semantic highlighter 中检索所有片段而不进行评分,可使用 match_all 查询作为 highlight_query。这确保片段按它们在文档中出现的顺序返回:
bash
`
1. POST test-index/_search
2. {
3. "query": {
4. "ids": {
5. "values": ["1"]
6. }
7. },
8. "highlight": {
9. "fields": {
10. "my_semantic_field": {
11. "number_of_fragments": 5, /* 1 */
12. "highlight_query": { "match_all": {} }
13. }
14. }
15. }
16. }
`AI写代码- 返回前 5 个片段。增加此值以检索更多片段。
semantic_text 字段的更新和部分更新
在更新包含 semantic_text 字段的文档时,了解 inference 的触发方式很重要:
- 完整文档更新
- 当执行完整文档更新时,即使 semantic_text 字段的值未改变,所有字段也会重新运行 inference。这确保 embeddings 始终与当前文档状态一致,但可能增加写入成本。
- 使用 Bulk API 的部分更新
- 通过 Bulk API 提交且省略 semantic_text 字段的部分更新,将重用索引中存储的现有 embeddings。在这种情况下,未更新的字段不会触发 inference,这可以显著减少处理时间和成本。
- 使用 Update API 的部分更新
- 使用 Update API 并提供省略 semantic_text 字段的 doc 对象时,所有 semantic_text 字段仍会运行 inference。这意味着即使字段值未改变,embeddings 也会被重新生成。
如果想避免不必要的 inference 并保留现有 embeddings:
-
通过 Bulk API 使用部分更新。
-
在请求的 doc 对象中省略未改变的 semantic_text 字段。
自定义 semantic_text 索引
semantic_text 根据指定的 inference endpoint 使用默认的索引数据设置。它通过提供自动 inference 和专用查询,让你快速启动语义搜索,而无需提供更多细节。
使用 semantic_text 参数进行自定义
Stack 9.1.0
如果你想覆盖这些默认值并自定义 semantic_text 索引的 embeddings,可以通过修改参数实现:
-
使用 index_options 指定替代的索引选项,例如特定的 dense_vector 量化方法
-
使用 chunking_settings 覆盖与 inference endpoint 关联的 chunking 策略,或使用 none 类型完全禁用 chunking
以下是为文本 embedding endpoint 设置这些参数的示例:
bash
`
1. PUT my-index-000004
2. {
3. "mappings": {
4. "properties": {
5. "inference_field": {
6. "type": "semantic_text",
7. "inference_id": "my-text-embedding-endpoint",
8. "index_options": {
9. "dense_vector": {
10. "type": "int4_flat"
11. }
12. },
13. "chunking_settings": {
14. "type": "none"
15. }
16. }
17. }
18. }
19. }
`AI写代码semantic_text 字段的更新
对于包含 semantic_text 字段的索引,使用脚本的更新具有以下行为:
-
通过 Update API 支持。
-
不支持通过 Bulk API,并会失败。即使脚本针对的是非 semantic_text 字段,当索引包含 semantic_text 字段时,更新也会失败。
copy_to 和多字段支持
semantic_text 字段类型可以作为 copy_to 字段的目标,成为多字段结构的一部分,或在内部包含多字段。这意味着你可以使用单个字段收集其他字段的值以进行语义搜索。
例如,以下映射:
bash
`
1. PUT test-index
2. {
3. "mappings": {
4. "properties": {
5. "source_field": {
6. "type": "text",
7. "copy_to": "infer_field"
8. },
9. "infer_field": {
10. "type": "semantic_text",
11. "inference_id": ".elser-2-elasticsearch"
12. }
13. }
14. }
15. }
`AI写代码也可以声明为多字段:
bash
`
1. PUT test-index
2. {
3. "mappings": {
4. "properties": {
5. "source_field": {
6. "type": "text",
7. "fields": {
8. "infer_field": {
9. "type": "semantic_text",
10. "inference_id": ".elser-2-elasticsearch"
11. }
12. }
13. }
14. }
15. }
16. }
`AI写代码限制
semantic_text 字段类型具有以下限制:
-
目前不支持将 semantic_text 字段作为 nested 字段的元素。
-
目前不能将 semantic_text 字段设置为 dynamic templates 的一部分。
-
semantic_text 字段不支持跨集群搜索(CCS)或跨集群复制(CCR)。