1 深度分页概述
-
深度分页 是指在处理大数据集查询时,用户尝试访问多页数据中较后面的页面时遇到的性能问题。例如:尝试访问排序后的数据列表的第1000页或更后面的页面时,数据库需要先跳过前面数十万条记录,这一过程涉及大量数据扫描和排序,会极大增加数据库查询负载,成为性能瓶颈;
-
Elasticsearch 的分页查询流程大致分为以下三步:
-
步骤1:数据存储在各个分片(shard)中,协调节点将查询请求转发给各个节点;各个节点执行搜索后,将排序后的前N条数据返回给协调节点;
-
步骤2:协调节点汇总各个分片返回的数据,再次排序,最终返回前N条数据给客户端;
-
步骤3:这个流程会导致深度分页问题------翻页越多,性能越差,甚至导致ES出现OOM(内存溢出);
-
-
在分布式系统中,对结果排序的成本随分页的深度成指数上升;
-
以"从10万名高考生中查询成绩为10001-10100位的100名考生信息"为例:
-
数据分片情况:假设数据分为5个分片(shard 0~shard 4),每个分片存储2万条文档(docs);
-
查询过程:为了获取第10001-10100位的考生,ES需要在每个分片上都查询出前10100条数据 ,然后将这些分片的结果汇总到协调节点,进行二次排序后,才能筛选出目标的100条数据;
-
性能问题:二次排序过程发生在JVM堆内存(heap)中。单次查询的数据量取决于"查询的是第几条数据"而非"查询了几条数据"------比如查第10001-10100条,却要先取出前10100条做二次排序。因此,查询的排序越靠后,堆内存压力越大,越容易触发OOM;频繁的深分页查询还会导致频繁的FullGC(全量垃圾回收),进一步影响性能;
-
-
ES为避免用户因不了解内部原理而误操作,设置了一个阈值
max_result_window,默认值为10000。其作用是保护堆内存不被错误操作导致溢出,限制了默认情况下分页查询能获取的最大数据范围。
2 深度分页不推荐使用from+size
-
在Elasticsearch中,分页查询通过
from和size两个参数实现:-
from:指定从结果集中的第几条数据开始返回(类似"起始偏移量"); -
size:指定返回数据的数量(类似"每页条数");
-
-
例:查询第一页5条数据的请求如下
jsonGET /employee/_search { "query": { "match_all": {} }, "from": 0, "size": 5 } -
深度分页的限制
-
当
from + size超过max_result_window(默认值为10000)时,会触发报错。例如from=10000,size=1时,from+size=10001超过阈值,报错信息为"from + size must be less than or equal to [10000] but was [10001]";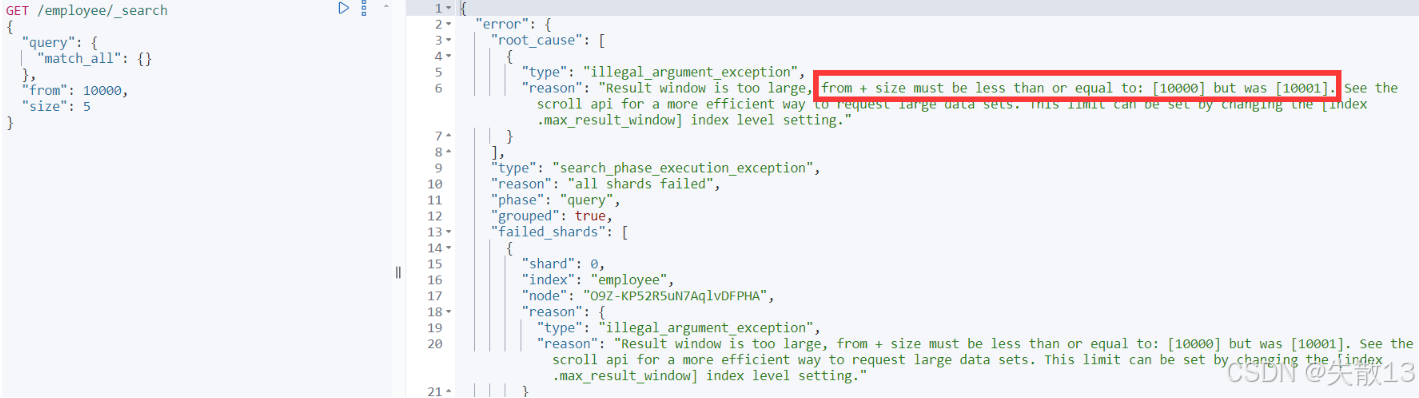
-
这是因为Elasticsearch通过
index.max_result_window限制最大分页窗口,避免因大数据量召回导致系统性能崩溃;
-
-
针对
from+size深度分页的限制,有两种可行方案:-
方案一 :对于大型数据集,采用
scroll API召回数据(后续会详细分析); -
方案二 :调大
index.max_result_window的默认值。示例代码如下:jsonPUT /employee/_settings { "index.max_result_window": 20000 }
-
-
from+size的优缺点-
优点 :支持随机翻页(如直接跳转到第5页);
-
缺点:
- 受限于
max_result_window设置,无法无限制翻页; - 存在深度分页问题,越往后翻页性能越慢;
- 受限于
-
-
from+size的适用场景-
适合小型数据集 ,或从大数据集中返回
Top N(N≤10000)结果集的业务场景; -
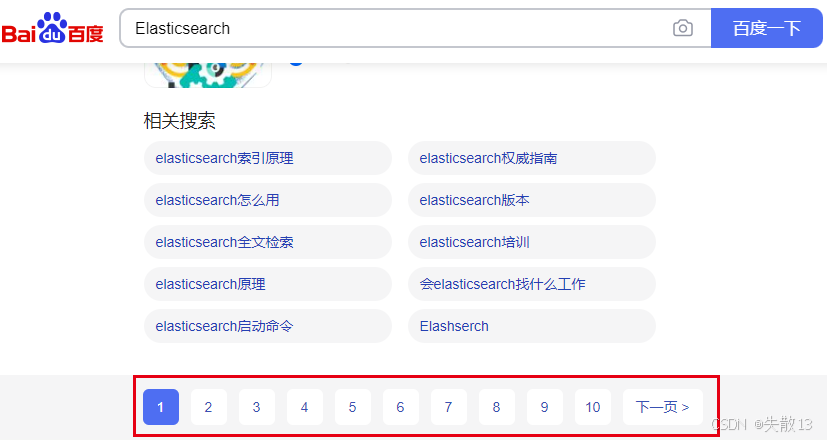
适合主流PC搜索引擎中支持随机跳转分页的场景(如百度搜索结果的多页随机跳转);
-
-
官方明确建议:避免使用
from+size过度分页或一次请求太多结果。核心原因是:搜索请求跨多个分片时,每个分片需加载"命中内容+先前页面的命中内容"到内存,分页越多,内存和CPU使用率越显著,易导致性能下降甚至节点故障。
3 深度分页问题的常见解决方案
3.1 尝试避免使用深度分页
-
解决深度分页问题的最佳办法是从业务层面避免深度分页。例如全球主流搜索引擎(谷歌、百度)和电商平台(淘宝),都通过功能限制或结果截断的方式,减少用户对深度分页的使用;
-
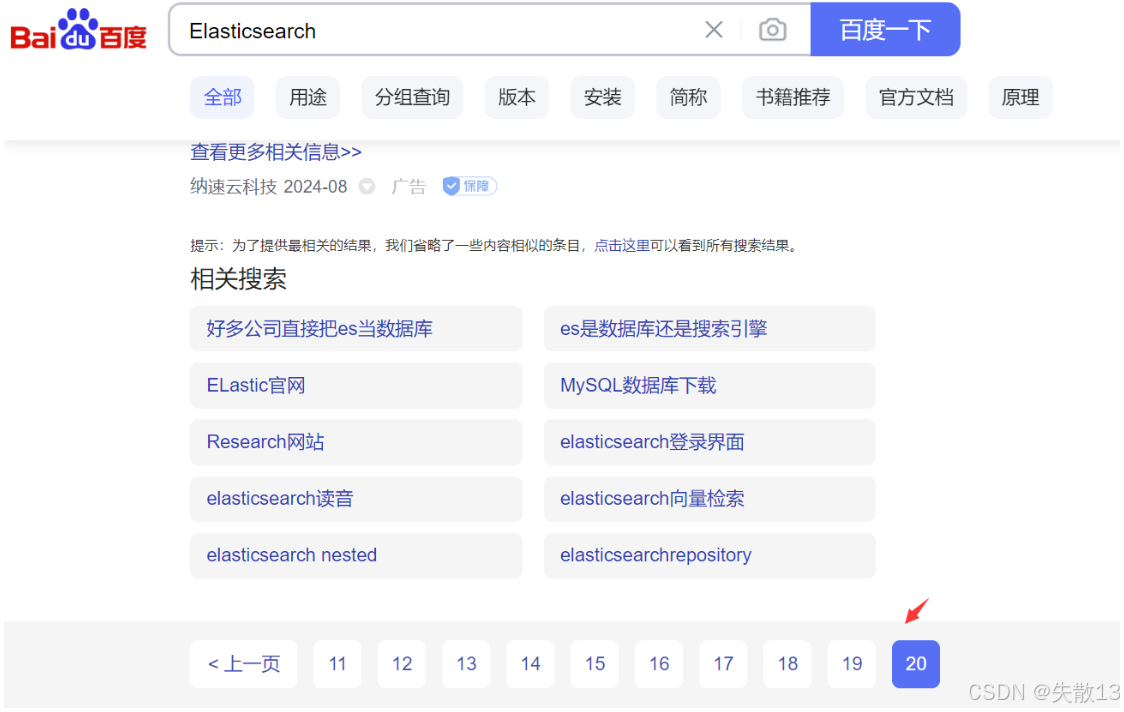
例1:百度在搜索结果分页条中删除了"跳页"功能(仅保留"下一页"和前几页的有限跳转),且对极深分页进行限制。例如搜索"Elasticsearch"时,翻到第20页后就无法再继续往下翻,以此避免用户触发深度分页检索,从源头降低系统性能压力;
-
例2:淘宝虽未删除"跳页"功能,但对商品搜索结果的分页深度做了限制------仅展示前100页的数据 。这一逻辑和Elasticsearch中
max_result_window的作用本质一致,都是通过限制分页深度,避免因深度分页导致的系统资源过度消耗;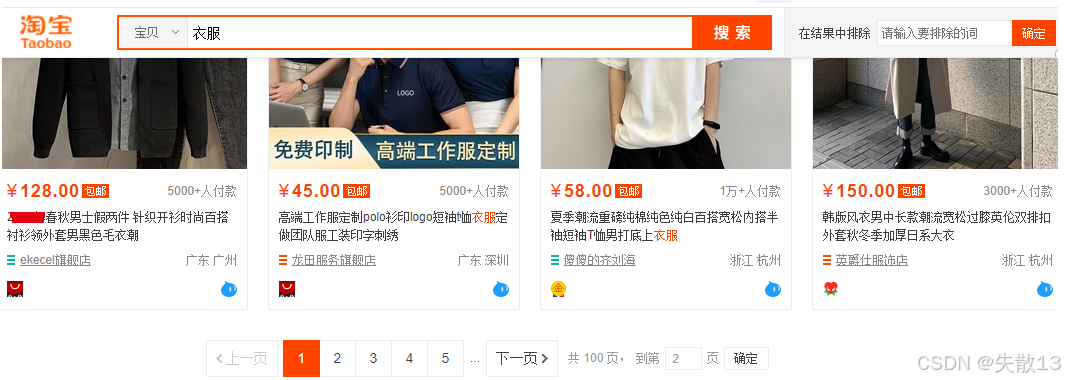
-
例3:手机端APP(如各类内容、电商APP)普遍采用**"下拉加载更多"的交互形式**,连分页条都没有,用户只能逐次"下一页"式加载,从交互层面避免了深度跳页带来的性能问题。
3.2 Scroll Search(滚动查询)
3.2.1 概述
-
Scroll API 可从单个搜索请求中检索大量结果(甚至所有结果),工作方式类似传统数据库的游标(cursor) 。但需注意,scroll滚动遍历查询是非实时的,数据量大时响应时间可能较长;
官方文档:Paginate search results \| Elasticsearch Guide [8.14 | Elastic](https://www.elastic.co/guide/en/elasticsearch/reference/8.14/paginate-search-results.html#scroll-search-results);
-
ES7之后,官方不再建议使用scroll API进行深度分页 。若需分页检索超过 Top 10,000+ 结果,推荐使用
search_after参数配合时间点(PIT);
3.2.2 实现步骤
-
第一次进行Scroll查询 :指定检索语句的同时,设置
scroll上下文保留时间。此时返回的结果是"初始搜索请求时索引的快照",后续对文档的增删改仅影响之后的搜索请求;-
以Kibana航班测试数据集为例:
jsonGET /kibana_sample_data_flights/_search?scroll=5m { "query": { "term": { "OriginWeather": "Sunny" } }, "size": 100 }-
scroll=5m:表示游标查询窗口保留5分钟(即快照结果的缓存有效时间); -
size=100:表示单次返回100条数据;
-
-
返回结果:
-
-
向后翻页 :持续获取数据。通过上一次请求返回的
_scroll_id,继续发起请求获取后续数据,直到没有结果返回为止:-
例:
jsonGET /_search/scroll { "scroll": "5m", "scroll_id": "上一次请求返回的_scroll_id的值" } -
多次执行该操作,直到无数据返回,即可完成全量数据遍历。这种方式限制了单次内存消耗,更安全高效;
-
-
删除游标scroll :scroll超时后会自动删除上下文,但为了避免资源浪费,不再使用时应主动删除scroll上下文;
jsonDELETE /_search/scroll { "scroll_id": "需要删除的_scroll_id的值" }
3.2.3 优缺点与适用场景
-
优点:支持全量遍历 ,是检索大量文档的重要方法(但单次遍历的
size值不能超过max_result_window的大小); -
缺点:
-
响应是非实时的;
-
保留上下文需要足够的堆内存空间;
-
需要通过更多网络请求才能获取所有结果;
-
-
适用场景:
-
大量文档检索:需检索大量文档(甚至全量召回数据)时,scroll查询是良好选择;
-
大量文档的数据处理:适合对大量文档进行数据处理(如索引迁移、数据导入其他技术栈)。
-
-
注意:
-
ES7.x之后不建议使用scroll API进行深度分页;
-
若需分页检索并获取超过10000条结果,推荐使用
search_after参数配合时间点(PIT)。
-
3.3 search_after查询
3.3.1 概述
-
search_after查询的核心逻辑是以前一页结果的排序值作为参照点,进而检索与该参照点相邻的下一页匹配数据。这种方式在处理大规模数据分页时更高效实用; -
使用
search_after的前提是:后续多个请求需返回与第一次查询相同的排序结果序列。即便后续有新数据写入,也不会影响原有结果的结构; -
scroll API 适用于高效的深度滚动,但滚动上下文成本高昂,不建议将其用于实时用户请求。而
search_after参数通过提供一个活动光标来规避这个问题,这样可以使用上一页的结果来帮助检索下一页;官方文档:Paginate search results \| Elasticsearch Guide [8.14 | Elastic](https://www.elastic.co/guide/en/elasticsearch/reference/8.14/paginate-search-results.html#search-after);
-
为保障搜索过程中数据的一致性,
search_after需结合PIT(时间点) 功能实现。PIT是Elasticsearch 7.10版本后新增的特性,用于保存特定时间点的索引状态(轻量级视图)。
3.3.2 实现步骤
-
获取索引的PIT:
-
使用
search_after需要具有相同査询和排序值的多个搜索请求。如果在这些请求之间发生刷新,结果的顺序可能会发生变化,从而导致跨页面的结果不一致。为防止出现这种情况,可以创建一个时间点(PIT)以保留搜索中的当前索引状态; -
例:
jsonPOST /kibana_sample_data_flights/_pit?keep_alive=5m-
keep_alive=5m:表示PIT的保留时间为5分钟,超时后Elasticsearch会删除该视图并报错(如search_context_missing_exception); -
返回结果:会生成一个
id(即PIT的唯一标识);
-
-
-
根据PIT首次查询
-
基于PIT创建基础查询,设置分页条件(查询、排序、分页大小等);
-
示例代码:
jsonGET /_search { "query": { "term": { "OriginWeather": "Sunny" } }, "pit": { "id": "第一步返回的PIT id", "keep_alive": "1m" }, "size": 10, "sort": [ { "timestamp": "asc" } ] } -
响应结果中,每个文档的最后会包含排序值+决胜字段(tiebreaker):
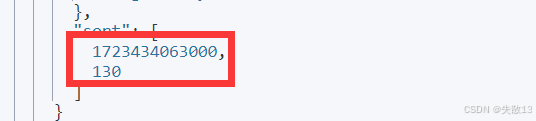
- 排序值:如上图示例代码的返回结果中的
1723434063000(对应sort指定的字段值); - 决胜字段(tiebreaker):如上图示例代码的返回结果中的
130,是文档的唯一标识,确保分页无丢失或重复;
- 排序值:如上图示例代码的返回结果中的
-
-
根据
search_after和PIT实现后续翻页-
以上一页最后一个文档的
sort字段值(含tiebreaker)作为search_after参数,结合PIT进行后续分页; -
示例代码:
jsonGET /_search { "query": { "term": { "OriginWeather": "Sunny" } }, "pit": { "id": "PIT id", "keep_alive": "5m" }, "size": 10, "sort": [ { "timestamp": "asc" } ], "search_after": [1723434063000, 130] } -
特点:仅支持向后翻页,不支持随机跳页;
-
-
优点:不严格受制于
max_result_window,可无限向后翻页(单次请求size仍受max_result_window限制,但总结果集可超过该阈值); -
缺点:仅支持向后翻页,不支持随机翻页,更适合手机端"下拉加载"类场景(如今日头条的分页搜索)。
4 ES的三种分页方式总结
| 分页方式 | 性能 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| from + size | 低 | 支持随机翻页 | 受制于max_result_window设置,不能无限制翻页;存在深度翻页问题,越往后翻页越慢 |
需要随机跳转不同页(PC端主流搜索引擎);在10000条数据之内分页显示 |
| scroll | 中 | 支持全量遍历,但单次遍历的size值不能超过max_result_window的大小 |
响应是非实时的;保留上下文需要具有足够的堆内存空间;需要通过更多的网络请求才能获取所有结果 | 需要遍历全量数据 |
| search_after | 高 | 不严格受制于max_result_window,可以无限地往后翻页 |
只支持向后翻页,不支持随机翻页 | 仅需要向后翻页;超过10000条数据,需要分页 |