1 Spring Data ElasticSearch 介绍
-
Spring Data Elasticsearch 是基于 Spring Data API 构建的框架,它的核心作用是简化 Elasticsearch 的操作------将 Elasticsearch 原始的客户端 API 进行封装,为 Elasticsearch 项目提供集成搜索引擎的能力;
-
它的关键功能包括:
-
以**POJO(Plain Old Java Object,普通 Java 对象)**为中心的模型,实现与 Elasticsearch 交互文档的便捷操作;
-
帮助开发者轻松编写存储索引库的数据访问层,降低 Elasticsearch 数据操作的技术门槛;
-
-
2 SpringBoot 整合 Spring Data ElasticSearch
2.1 版本选型
-
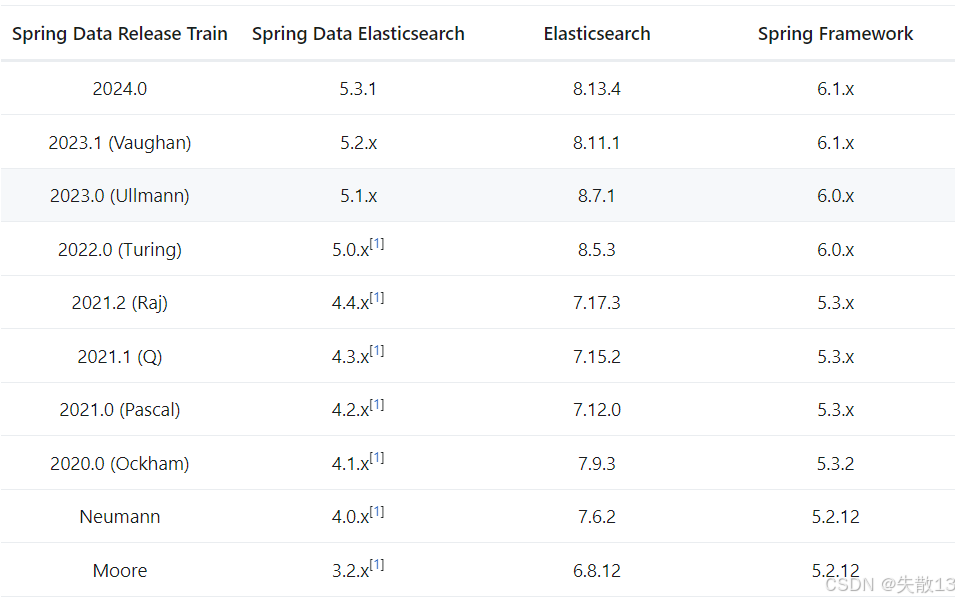
ElasticSearch 8.14.x 对应依赖 Spring Data Elasticsearch 5.3.x,对应Spring6.1.x,Spring Boot版本可以选择3.3.x;
2.2 引入依赖
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>-
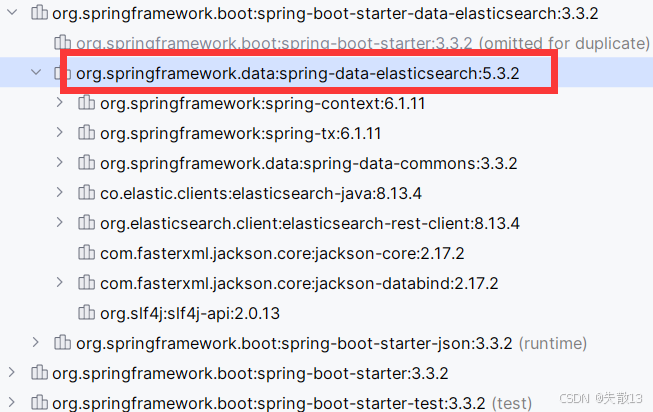
如果 SpringBoot 版本选择的是3.3.2,那么对应的 Spring Data ElasticSearch 为5.3.2;
2.3 配置 ElasticSearch
-
SpringBoot中有两种配置 ElasticSearch 的方式,选择一种即可;
-
方式1:
yaml文件配置yamlspring: elasticsearch: uris: http://localhost:9200 connection-timeout: 3s -
方式2:
@Configuration配置java@Configuration public class MyESClientConfig extends ElasticsearchConfiguration { @Override public ClientConfiguration clientConfiguration() { return ClientConfiguration.builder().connectedTo("localhost:9200").build(); } }
2.4 Java代码实现
2.4.1 方式1:ElasticsearchRepository
-
ElasticsearchRepository是 Spring Data Elasticsearch 中的核心接口,用于简化 Elasticsearch 集群的CRUD(增删改查)操作及高级搜索功能集成 。它采用声明式编程模型,让开发者无需直接编写复杂的 REST API 调用代码,即可完成数据持久化操作; -
创建实体类:
java@Data @AllArgsConstructor @NoArgsConstructor @Document(indexName = "employees") public class Employee { @Id private Long id; @Field(type= FieldType.Keyword) private String name; private int sex; private int age; @Field(type= FieldType.Text,analyzer="ik_max_word") private String address; private String remark; } -
实现 ElasticsearchRepository 接口(EmployeeRepository)
java@Repository // 标记该接口为数据访问层组件,让 Spring 能够扫描并管理 public interface EmployeeRepository extends ElasticsearchRepository<Employee, Long> { // 自定义查询方法。Spring Data支持方法名语义解析,只需按规则命名(如findBy+字段名),框架会自动生成对应的查询逻辑 List<Employee> findByName(String name); } -
测试:
java@Autowired EmployeeRepository employeeRepository; @Test public void testDocument() { Employee employee = new Employee(10L, "fox666", 1, 32, "长沙麓谷", "java architect"); //插入文档 employeeRepository.save(employee); //根据id查询 Optional<Employee> result = employeeRepository.findById(10L); if (!result.isEmpty()){ log.info(String.valueOf(result.get())); } //根据name查询 List<Employee> list = employeeRepository.findByName("fox666"); if(!list.isEmpty()){ log.info(String.valueOf(list.get(0))); } }
2.4.2 方式2:ElasticsearchTemplate
2.4.2.1 概述
-
ElasticsearchTemplate是 Spring Data Elasticsearch 提供的模板类 ,封装了操作 Elasticsearch 的便捷方法,覆盖索引管理、文档CRUD、高级查询等底层操作和高级功能,让开发者无需直接处理 Elasticsearch 的 REST API 细节;java@Autowired ElasticsearchTemplate elasticsearchTemplate; -
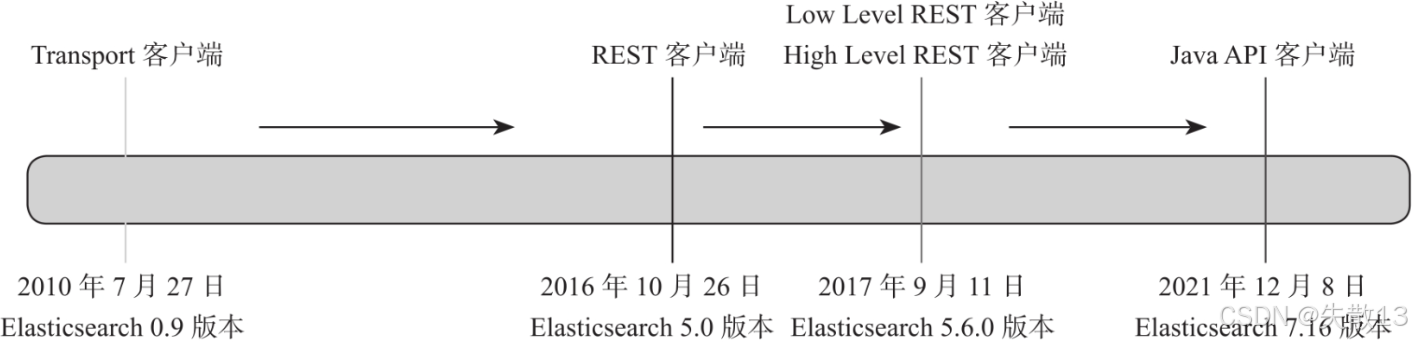
ElasticSearch 客户端演进历史
-
Transport 客户端:基于 Elasticsearch 0.9 版本(2010年),是早期的客户端方案,后来因性能和兼容性问题被弃用;
-
REST 客户端:
- Low Level REST 客户端:Elasticsearch 5.0 版本(2016年)推出,提供基础的 HTTP 级 REST 通信;
- High Level REST 客户端(
RestHighLevelClient):Elasticsearch 5.6.0 版本(2017年)推出,对 Low Level 客户端封装,支持更易用的 API,但从 Java Rest Client 7.15.0 版本开始被官方标记为废弃;
-
Java API 客户端(
ElasticsearchClient) :Elasticsearch 7.16 版本(2021年)推出,是官方推荐的新客户端。Spring Data Elasticsearch 对其进一步封装,形成了新的ElasticsearchTemplate;
-
2.4.2.1 索引操作
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testCreateIndex(){
// 检查索引是否存在
boolean exist = elasticsearchTemplate.indexOps(Employee.class).exists();
// 若索引存在,则删除
if(exist){
elasticsearchTemplate.indexOps(Employee.class).delete();
}
// 创建索引
// 配置settings
Map<String, Object> settings = new HashMap<>();
settings.put("number_of_shards",1); // 配置索引的分片数,影响索引的性能
settings.put("number_of_replicas",1); // 配置索引的副本数,影响索引的高可用性
// 配置mapping
String json = "{\n" +
" \"properties\": {\n" +
" \"_class\": {\n" +
" \"type\": \"text\",\n" +
" \"fields\": {\n" +
" \"keyword\": {\n" +
" \"type\": \"keyword\",\n" +
" \"ignore_above\": 256\n" +
" }\n" +
" }\n" +
" },\n" +
" \"address\": {\n" +
" \"type\": \"text\",\n" +
" \"fields\": {\n" +
" \"keyword\": {\n" +
" \"type\": \"keyword\"\n" +
" }\n" +
" },\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"age\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"id\": {\n" +
" \"type\": \"long\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"remark\": {\n" +
" \"type\": \"text\",\n" +
" \"fields\": {\n" +
" \"keyword\": {\n" +
" \"type\": \"keyword\"\n" +
" }\n" +
" },\n" +
" \"analyzer\": \"ik_smart\"\n" +
" },\n" +
" \"sex\": {\n" +
" \"type\": \"integer\"\n" +
" }\n" +
" }\n" +
" }";
Document mapping = Document.parse(json);
// 创建索引
elasticsearchTemplate.indexOps(Employee.class).create(settings,mapping);
// 查看索引mappings信息
Map<String, Object> mappings = elasticsearchTemplate.indexOps(Employee.class).getMapping();
log.info(mappings.toString());
}2.4.2.3 批量文档插入
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testBulkBatchInsert(){
// 构建 Employee 数据列表
List<Employee> employees = new ArrayList<>();
employees.add(new Employee(2L,"张三",1,25,"广州天河公园","java developer"));
employees.add(new Employee(3L,"李四",1,28,"广州荔湾大厦","java assistant"));
employees.add(new Employee(4L,"小红",0,26,"广州白云山公园","php developer"));
// 通过 IndexQuery 封装每条数据的 ID 和 JSON 内容
List<IndexQuery> bulkInsert = new ArrayList<>();
for (Employee employee : employees) {
IndexQuery indexQuery = new IndexQuery();
indexQuery.setId(String.valueOf(employee.getId()));
String json = JSONObject.toJSONString(employee);
indexQuery.setSource(json);
bulkInsert.add(indexQuery);
}
// 调用 elasticsearchTemplate.bulkIndex() 实现批量插入,提升大数据量下的写入效率
elasticsearchTemplate.bulkIndex(bulkInsert,Employee.class);
}2.4.2.4 文档CRUD
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testDocument(){
// 删除文档:调用 delete() 根据 ID 删除指定文档
elasticsearchTemplate.delete(String.valueOf(12L),Employee.class);
// 插入文档:调用 save() 插入单条 Employee 文档
Employee employee = new Employee(12L,"张三三",1,25,"广州天河公园","java developer");
elasticsearchTemplate.save(employee);
// 查询文档:调用 get() 根据 ID 查询文档并打印结果
Employee emp = elasticsearchTemplate.get(String.valueOf(12L),Employee.class);
log.info(String.valueOf(emp));
}2.4.2.5 精确查询
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testQueryDocument(){
// 条件查询:查询姓名为张三的员工信息
/*
GET /employee/_search
{
"query": {
"term": {
"name": {
"value": "张三"
}
}
}
}
*/
// 方式1:直接编写 JSON 格式的查询语句
// Query query = new StringQuery("{\n" +
// " \"term\": {\n" +
// " \"name\": {\n" +
// " \"value\": \"张三\"\n" +
// " }\n" +
// " }\n" +
// " }");
// 方式2:通过编程式 API 构建查询,可读性更强
Query query = NativeQuery.builder()
.withQuery(q -> q.term(
t -> t.field("name").value("张三")))
.build();
SearchHits<Employee> search = elasticsearchTemplate.search(query, Employee.class);
// 调用 search() 执行查询
List<SearchHit<Employee>> searchHits = search.getSearchHits();
// 解析返回的 SearchHits 结果
for (SearchHit hit: searchHits){
log.info("返回结果:"+hit.toString());
}
}2.4.2.6 分词匹配查询
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testMatchQueryDocument(){
// 条件查询:查询地址中至少匹配"广州""公园"两个词的员工
/*
GET /employee/_search
{
"query": {
"match": {
"address": {
"query": "广州公园",
"minimum_should_match": 2
}
}
}
}*/
// 方式1:直接编写 JSON 格式的查询语句
// Query query = new StringQuery("{\n" +
// " \"match\": {\n" +
// " \"address\": {\n" +
// " \"query\": \"广州公园\",\n" +
// " \"minimum_should_match\": 2\n" +
// " }\n" +
// " }\n" +
// " }");
// 方式2:通过编程式 API 构建查询,可读性更强
Query query = NativeQuery.builder()
.withQuery(q -> q.match(
m -> m.field("address").query("广州公园")
.minimumShouldMatch("2"))) // 通过 minimumShouldMatch 配置最少匹配词数,满足模糊查询的业务场景
.build();
SearchHits<Employee> search = elasticsearchTemplate.search(query, Employee.class);
List<SearchHit<Employee>> searchHits = search.getSearchHits();
for (SearchHit hit: searchHits){
log.info("返回结果:"+hit.toString());
}
}2.4.2.7 分页、排序、高亮查询
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testQueryDocument3(){
// 分页排序高亮:结合分页、排序、高亮实现复杂查询,查询 remark 中含 "JAVA" 的员工,按年龄倒序取前 3 条,并对匹配内容高亮显示
/*
GET /employee/_search
{
"from": 0,
"size": 3,
"query": {
"match": {
"remark": {
"query": "JAVA"
}
}
},
"highlight": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["<font/>"],
"require_field_match": "false",
"fields": {
"*":{}
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
*/
//第一步:构建查询语句
Query query = new StringQuery("{\n" +
" \"match\": {\n" +
" \"remark\": {\n" +
" \"query\": \"JAVA\"\n" +
" }\n" +
" }\n" +
" }");
// 分页:通过 PageRequest.of(0, 3) 配置页码和每页条数
query.setPageable(PageRequest.of(0, 3));
// 排序:通过 Sort.by(Order.desc("age")) 按年龄倒序
query.addSort(Sort.by(Order.desc("age")));
// 高亮:通过 HighlightParameters 配置高亮标签(如 <font color='red'>)和作用字段,让匹配结果更直观
HighlightField highlightField = new HighlightField("*");
HighlightParameters highlightParameters = new HighlightParameters.HighlightParametersBuilder()
.withPreTags("<font color='red'>")
.withPostTags("<font/>")
.withRequireFieldMatch(false)
.build();
Highlight highlight = new Highlight(highlightParameters,Arrays.asList(highlightField));
HighlightQuery highlightQuery = new HighlightQuery(highlight,Employee.class);
query.setHighlightQuery(highlightQuery);
SearchHits<Employee> search = elasticsearchTemplate.search(query, Employee.class);
List<SearchHit<Employee>> searchHits = search.getSearchHits();
for (SearchHit hit: searchHits){
log.info("返回结果:"+hit.toString());
}
}2.4.2.8 布尔查询
java
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testBoolQueryDocument(){
// 实现 bool 查询(多条件组合),查询地址含 "广州" 且 remark 含 "java" 的员工
// must 子句表示"必须同时满足",同样支持 StringQuery 和 NativeQuery 两种构建方式,满足多条件组合的复杂业务查询场景
/*
GET /employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "广州"
}
},{
"match": {
"remark": "java"
}
}
]
}
}
}
*/
// 方式1:直接编写 JSON 格式的查询语句
// Query query = new StringQuery("{\n" +
// " \"bool\": {\n" +
// " \"must\": [\n" +
// " {\n" +
// " \"match\": {\n" +
// " \"address\": \"广州\"\n" +
// " }\n" +
// " },{\n" +
// " \"match\": {\n" +
// " \"remark\": \"java\"\n" +
// " }\n" +
// " }\n" +
// " ]\n" +
// " }\n" +
// " }");
// 方式2:通过编程式 API 构建查询,可读性更强
Query query = NativeQuery.builder()
.withQuery(q -> q.bool(
m -> m.must(
QueryBuilders.match( q1 -> q1.field("address").query("广州")),
QueryBuilders.match( q2 -> q2.field("remark").query("java"))
)))
.build();
SearchHits<Employee> search = elasticsearchTemplate.search(query, Employee.class);
List<SearchHit<Employee>> searchHits = search.getSearchHits();
for (SearchHit hit: searchHits){
log.info("返回结果:"+hit.toString());
}
}2.4.3 使用ElasticsearchClient
2.4.3.1 概述
-
ElasticsearchClient是 Elasticsearch 7.16+ 版本推出的官方推荐客户端 ,替代了 deprecated 的RestHighLevelClient,提供类型安全的 API 设计,支持链式调用构建请求,更贴合 Elasticsearch 的 DSL 语法;@Autowired ElasticsearchTemplate elasticsearchTemplate;
2.4.3.2 索引操作
java
@Autowired
ElasticsearchClient elasticsearchClient;
String indexName = "employee_demo";
@Test
public void testCreateIndex() throws IOException {
// 检查索引是否存在
BooleanResponse exist = elasticsearchClient.indices().exists(e->e.index(indexName));
// 若索引存在,则删除
if(exist.value()){
elasticsearchClient.indices().delete(d->d.index(indexName));
}
// 创建索引
elasticsearchClient.indices().create(c->c.index(indexName) // 指定索引名
// 配置索引的分片数和副本数
.settings(s->s.numberOfShards("1").numberOfReplicas("1"))
// name 字段为 keyword 类型(不分词,适合精确匹配)
.mappings(m-> m.properties("name", p->p.keyword(k->k))
// sex 字段为 long 类型(整数存储)
.properties("sex", p->p.long_(l->l))
// address字段为text 类型,使用ik_max_word中文分词器(最大化分词,适合全文检索)
.properties("address", p->p.text(t->t.analyzer("ik_max_word")))
)
);
// 查询索引
GetIndexResponse getIndexResponse = elasticsearchClient.indices().get(g -> g.index(indexName));
log.info(getIndexResponse.result().toString());
}2.4.3.3 批量插入文档
java
// 使用 BulkOperation 封装多条文档操作,通过 elasticsearchClient.bulk(...) 一次性提交,提升大量数据写入效率
@Autowired
ElasticsearchClient elasticsearchClient;
String indexName = "employee_demo";
@Test
public void testBulkBatchInsert() throws IOException {
// 构建 Employee 实体列表(含 id、name、sex 等字段)
List<Employee> employees = new ArrayList<>();
employees.add(new Employee(2L,"张三",1,25,"广州天河公园","java developer"));
employees.add(new Employee(3L,"李四",1,28,"广州荔湾大厦","java assistant"));
employees.add(new Employee(4L,"小红",0,26,"广州白云山公园","php developer"));
// 为每个实体创建 BulkOperation:
// 通过 BulkOperation.Builder().create(...) 定义 "创建文档" 操作
// 指定文档 ID 和实体对象(document(employee) 自动序列化实体为 JSON
List<IndexQuery> bulkInsert = new ArrayList<>();
for (Employee employee : employees) {
IndexQuery indexQuery = new IndexQuery();
indexQuery.setId(String.valueOf(employee.getId()));
String json = JSONObject.toJSONString(employee);
indexQuery.setSource(json);
bulkInsert.add(indexQuery);
}
List<BulkOperation> list = new ArrayList<>();
for (Employee employee : employees) {
BulkOperation bulkOperation = new BulkOperation.Builder()
.create(c->c.id(String.valueOf(employee.getId()))
.document(employee)
)
.build();
list.add(bulkOperation);
}
// 执行批量插入,operations(list) 传入批量操作列表。
elasticsearchClient.bulk(b->b.index(indexName).operations(list));
}2.4.3.4 单文档插入
java
@Autowired
ElasticsearchClient elasticsearchClient;
String indexName = "employee_demo";
@Test
public void testDocument() throws IOException {
Employee employee = new Employee(12L,"张三三",1,25,"广州天河公园","java developer");
// 通过 IndexRequest 构建插入请求,指定索引名、文档 ID 和实体对象,调用 elasticsearchClient.index(request) 执行插入
IndexRequest<Employee> request =
// 链式配置请求参数,document(employee) 自动将实体序列化为 Elasticsearch 文档
IndexRequest.of(i -> i
.index(indexName)
.id(employee.getId().toString())
.document(employee)
);
IndexResponse response = elasticsearchClient.index(request);
log.info("response:"+response);
}2.4.3.5 单条件查询
java
@Autowired
ElasticsearchClient elasticsearchClient;
String indexName = "employee_demo";
@Test
public void testQuery() throws IOException {
// 构建 SearchRequest:通过 SearchRequest.of(s -> s.index(indexName).query(...)) 配置查询索引和查询条件
SearchRequest searchRequest = SearchRequest.of(s -> s
.index(indexName)
// 定义查询逻辑:对 name 字段执行 match 匹配(因 name 是 keyword 类型,实际等价于精确匹配)
.query(q -> q.match(m -> m.field("name").query("张三三"))
));
log.info("构建的DSL语句:"+ searchRequest.toString());
SearchResponse<Employee> searchResponse = elasticsearchClient.search(searchRequest, Employee.class);
// 通过 hits().hits() 获取命中的文档列表,Hit::source 提取文档源数据(自动反序列化为 Employee 对象)
List<Hit<Employee>> hits = searchResponse.hits().hits();
hits.stream().map(Hit::source).forEach(employee -> {
log.info("员工信息:"+employee);
});
}2.4.3.6 布尔组合查询
- 实现 bool 多条件查询 :查询
address含"广州"且remark含"java"的文档,对应 Elasticsearch 的 bool-must 逻辑(所有条件必须满足)。 - 步骤解析:
- 构建
BoolQuery:通过BoolQuery.Builder()创建布尔查询构建器,调用must(...)方法添加子查询(每个must对应一个条件):must(m->m.match(q->q.field("address").query("广州"))):address字段匹配"广州"。must(m->m.match(q->q.field("remark").query("java"))):remark字段匹配"java"。
- 构建
SearchRequest:将布尔查询设置为查询条件(query(q->q.bool(boolQueryBuilder.build())))。 - 执行查询并解析:同单条件查询,提取
hit.source()得到匹配的Employee实体。
- 构建
java
@Autowired
ElasticsearchClient elasticsearchClient;
@Test
public void testBoolQueryDocument() throws IOException {
// 条件查询:查询 address 含 "广州" 且 remark 含 "java" 的文档,对应 Elasticsearch 的 bool-must 逻辑(所有条件必须满足)
/*
GET /employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "广州"
}
},{
"match": {
"remark": "java"
}
}
]
}
}
}
*/
// 构建 BoolQuery:通过 BoolQuery.Builder() 创建布尔查询构建器,调用 must(...) 方法添加子查询(每个 must 对应一个条件)
BoolQuery.Builder boolQueryBuilder = new BoolQuery.Builder();
boolQueryBuilder.must(m->m.match(q->q.field("address").query("广州"))) // address 字段匹配 "广州"
.must(m->m.match(q->q.field("remark").query("java"))); // remark 字段匹配 "java"
// 构建 SearchRequest
SearchRequest searchRequest = new SearchRequest.Builder()
.index("employee")
.query(q->q.bool(boolQueryBuilder.build())) // 将布尔查询设置为查询条件
.build();
// 执行查询
SearchResponse<Employee> searchResponse = elasticsearchClient.search(searchRequest, Employee.class);
// 解析
List<Hit<Employee>> list = searchResponse.hits().hits();
for(Hit<Employee> hit: list){
log.info(String.valueOf(hit.source()));
}
}