一、实验目的
-
掌握使用Python编写网络爬虫的基本方法;
-
学习使用requests、BeautifulSoup和lxml等库进行网页数据抓取与解析;
-
实现对"软科中国"网站大学排名数据的自动化采集;
-
将采集的数据保存为CSV格式文件,便于后续分析使用;
-
以广东财经大学为例,查找特定大学的历年排名变化。
二、实验环境
-
操作系统:Windows
-
编程语言:Python 3.x
-
使用库:urllib, requests, time, csv, BeautifulSoup, lxml
三、实验内容与步骤
1. 网页请求模块
创建connect()函数,设置请求头模拟浏览器访问,处理可能出现的HTTP和URL错误,确保网络请求的稳定性。
python
def connect(url): #获取url
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0'}
html = requests.get(url,headers=headers)
html.encoding = "UTF-8"
except HTTPError as e:
print(e)
except URLError as e:
print('The server could not be found!')
return html2. 主爬虫函数
设计mainparse()函数,用于获取世界大学排名和中国大学排名数据:
-
使用BeautifulSoup解析HTML内容
-
定位并提取表格中的排名数据
-
每所大学对应6个数据字段
-
添加换行符便于后续数据处理
pythondef mainparse(url,year,classification):#主爬虫(获取世界大学排名与中国大学排名) text = [] html = connect(url) bs = BeautifulSoup(html.text,'html.parser') links = bs.find_all('tr') for link in links: l = link.find_all('td')#爬取标签'tr'下所有'td'标签 for i in l: text.append(i.get_text(strip=True, separator=' ')) #print(i.get_text(strip=True, separator=' ')) if(len(text)%6==0): x = text.pop() text.append(x+'\n')#每个大学对应6个数据,添加换行符,以便后续数据处理 saveinfo(text,year,classification) time.sleep(5)
3. 特定院校数据获取
实现GCparse()函数,专门抓取广东财经大学的历年排名数据:
-
使用XPath定位特定元素
-
提取排名和对应年份信息
pythondef GCparse():#通过xpath函数爬取广财历年排名 html = connect("https://www.shanghairanking.cn/institution/guangdong-university-of-finance-and-economics") selector = etree.HTML(html.text) rankingchangel = selector.xpath("//div[@class='bcur-hist']/div[@class='item-rank']/div[@class='rank']/text()") rankingchangey = selector.xpath("//div[@class='bcur-hist']/div[@class='item-rank']/div[@class='year']/text()") saveinfoGC(rankingchangel,rankingchangey) #print(rankingchangel) #print(rankingchangey)
4. 数据存储功能
创建两种数据保存函数:
-
saveinfoGC():保存广东财经大学的排名数据 -
saveinfo():保存世界和中国大学排名数据,根据不同类型设置不同的表头pythondef saveinfoGC(info1,info2):#保存数据 csvFile = open('gctext.csv','w+',encoding='utf-8',newline='') we = csv.writer(csvFile) we.writerow(('广财在财经类院校近5年排名:')) we.writerow('\n') we.writerow(info1) we.writerow('\n') we.writerow(info2) csvFile.close() def saveinfo(info,year,classification):#保存数据 year = str(year) if classification == 'arwu/': csvFile = open(year+'世界大学排名.csv','w+',encoding='utf-8',newline='') we = csv.writer(csvFile) we.writerow(('排名','学校','所属国家','国家内排名','总分','校友获奖')) else: csvFile = open(year+'中国大学排名.csv','w+',encoding='utf-8',newline='') we = csv.writer(csvFile) we.writerow(('排名','学校','所属省市','类别','总分')) we.writerow('\n') we.writerow(info) csvFile.close()
5. 主程序流程
在main()函数中:
-
设置基础URL和分类参数
-
使用循环遍历2016-2021年的排名数据
-
依次调用各爬虫函数获取数据
-
最后获取广东财经大学的特殊排名数据
pythondef main():#主函数输入相关参数并启动爬虫 url = "https://www.shanghairanking.cn/rankings/" classification = ['arwu/','bcur/']#前者对应世界排名,后者对应国内排名 for x in classification: startyear = 2016 for i in range(6):#for循环遍历2016-2021年的排名 sy = str(startyear) mainparse(url+x+sy,startyear,x) startyear = startyear + 1 GCparse() main()
四、实验结果
程序成功运行后,生成以下数据文件:
-
2016-2021年世界大学排名CSV文件(6个)
-
2016-2021年中国大学排名CSV文件(6个)
-
广东财经大学近5年排名数据CSV文件(1个)
每个CSV文件都包含完整的排名数据,结构清晰,便于后续数据分析使用。
示例(2016年世界大学排名(部分)):
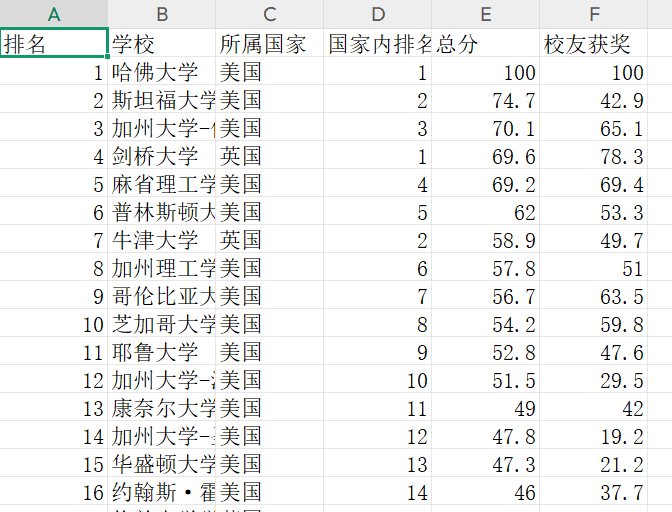
五、实验分析
技术亮点:
-
使用面向对象的编程思想,将功能模块化
-
采用异常处理机制,增强程序稳定性
-
结合BeautifulSoup和lxml两种解析方式,发挥各自优势
-
设置合理的请求间隔,避免对目标网站造成过大压力
六、实验总结
本实验成功实现了对软科中国网站大学排名数据的自动化采集,掌握了网络爬虫的基本原理和实现方法。通过本次实验,加深了对HTML解析、数据提取和存储的理解,提高了Python编程能力和实际问题解决能力。特别是针对特定院校(广东财经大学)的排名变化分析,体现了数据采集的针对性和实用性。
可改进之处:
可增加数据去重和清洗功能;
可添加进度显示功能,方便监控爬取过程;
可考虑使用数据库存储替代CSV文件;
可增加异常重试机制,提高数据完整性。