前言
本章将分析broker处理ProduceRequest发送消息请求:
1)不同配置情况下的broker线程模型;
2)broker通讯层细节;
3)broker反序列化ProduceRequest;
4)ProduceRequest处理流程:如何落盘,索引的生成时机,acks=-1的处理方式;
5)broker数据目录的组织形式:checkpoint、log、segment。
6)broker异常停机如何恢复数据;
注:
1)基于kafka2.6,未引入KRaft;
2)更多HA相关逻辑(Follower复制、HW高水位)后续章节分析,点到为止;
一、线程模型
1-1、默认模型
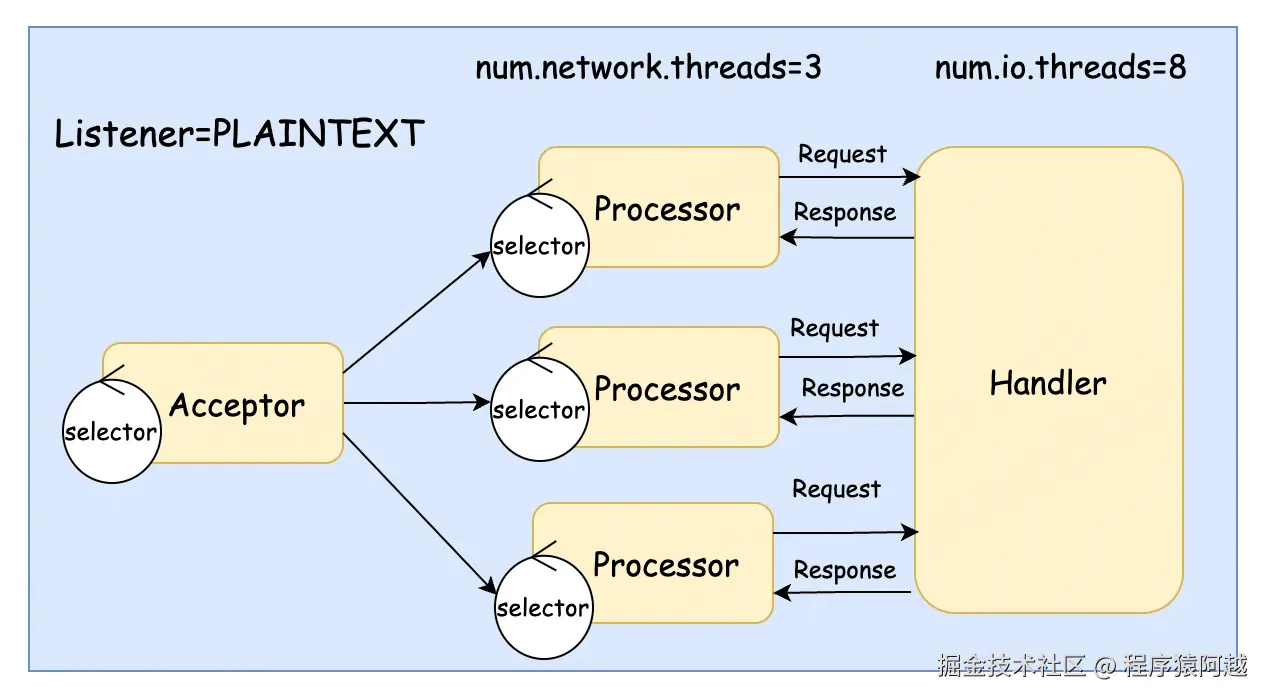
默认的broker线程模型如下:
1)1个Acceptor负责接收socket:Acceptor#run;
2)3个Processor负责处理socket读写:Processor#run,可以通过num.network.threads配置;
3)8个Handler负责处理业务:KafkaRequestHandler#run,可以通过num.io.threads配置;
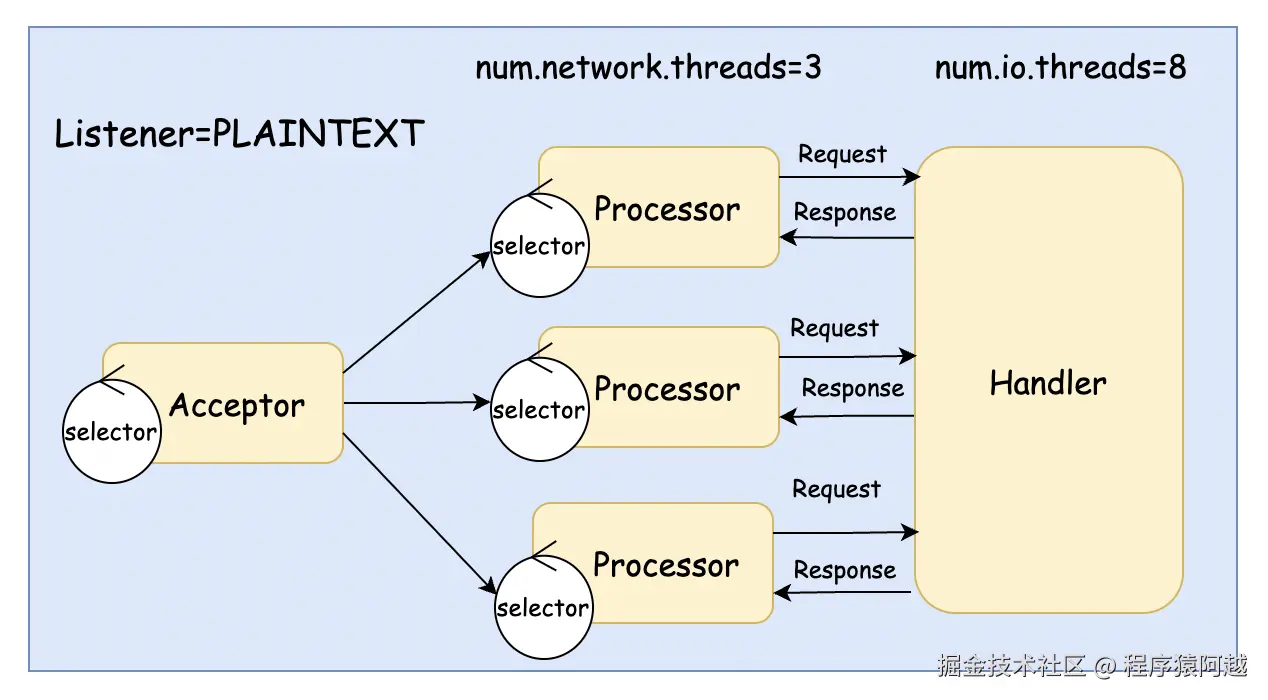
在默认配置下,用户外部请求和broker内部请求处理在同一个线程池里处理,会相互影响。
1-2、分离controller请求和其他请求
server.properties:通过配置多Listener将Controller请求和其他请求分离。
properties
listeners=CLIENT://:9092,CONTROL://:9192
advertised.listeners=CLIENT://localhost:9092,CONTROL://localhost:9192
control.plane.listener.name=CONTROL
inter.broker.listener.name=CLIENT
listener.security.protocol.map=CLIENT:PLAINTEXT,CONTROL:PLAINTEXTcontroller的Listener特点是:只有一个Processor线程和一个Handler线程。
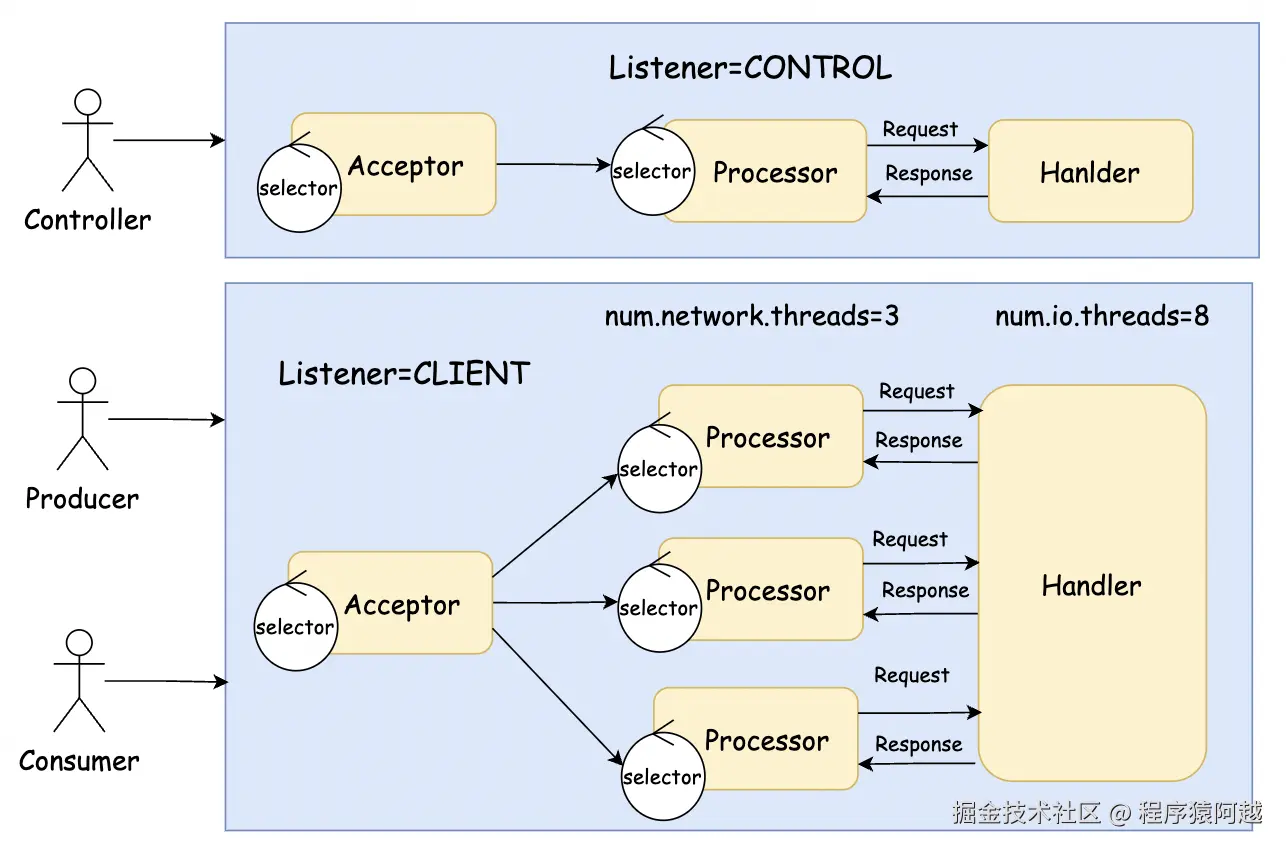
SocketServer#startup:根据配置创建控制面和数据面。
Scala
def startup(startProcessingRequests: Boolean = true): Unit = {
this.synchronized {
connectionQuotas = new ConnectionQuotas(config, time)
// 创建控制面Listener(默认无)
createControlPlaneAcceptorAndProcessor(config.controlPlaneListener)
// 创建数据面Listener,创建processor(s),启动acceptor(打开socket)
createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, config.dataPlaneListeners)
if (startProcessingRequests) {
this.startProcessingRequests()
}
}
}1-3、分离client请求和broker内部请求
非controller场景下,broker之间会建立连接,比如数据复制。
server.properties:再配置一个Listener用于BROKER内部请求。
properties
listeners=CLIENT://:9092,CONTROL://:9192,BROKER://:9292
advertised.listeners=CLIENT://localhost:9092,CONTROL://localhost:9192,BROKER://localhost:9292
control.plane.listener.name=CONTROL
inter.broker.listener.name=BROKER
listener.security.protocol.map=CLIENT:PLAINTEXT,CONTROL:PLAINTEXT,BROKER:PLAINTEXT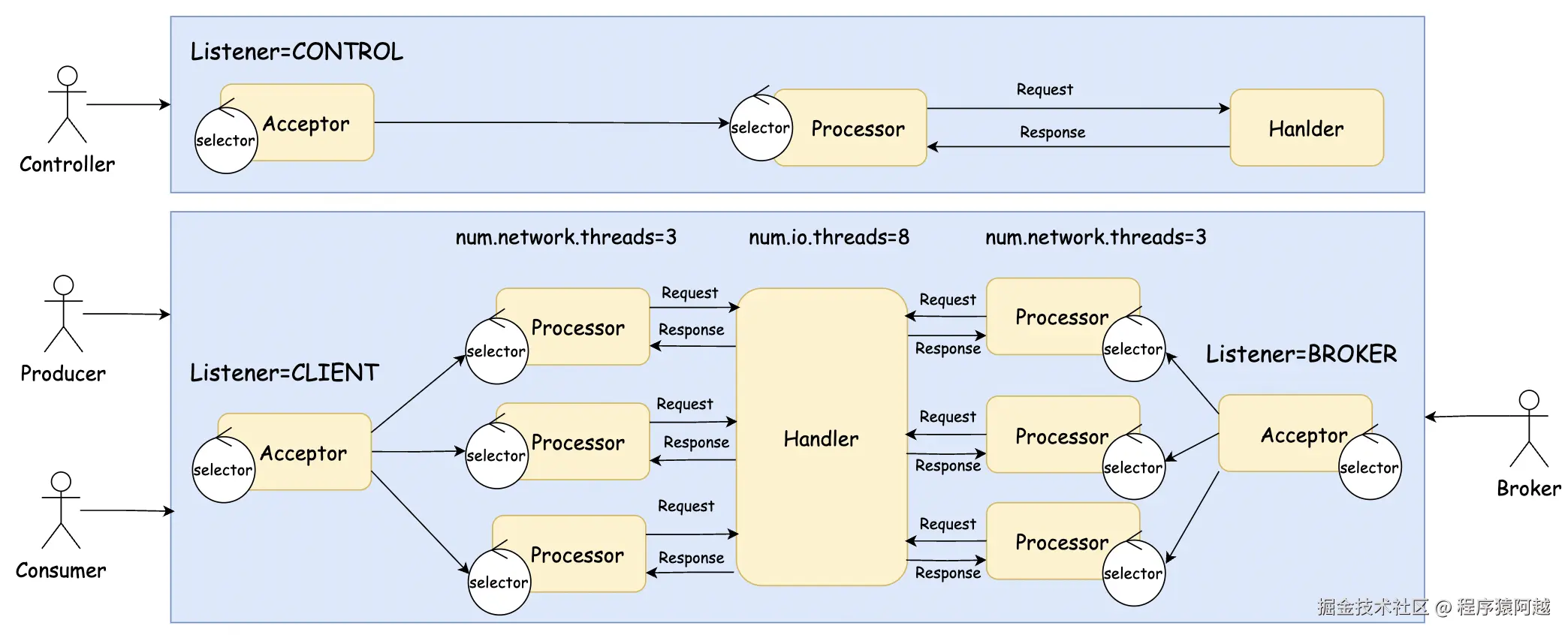
KafkaServer#startup:dataPlaneRequestHandlerPool是server级别的,broker和client会共享handler线程池处理请求。
Java
def startup(): Unit = {
// 数据面 处理请求的线程池 num.io.threads=8
dataPlaneRequestHandlerPool =
new KafkaRequestHandlerPool(config.numIoThreads)
}二、通讯层细节
2-1、主流程
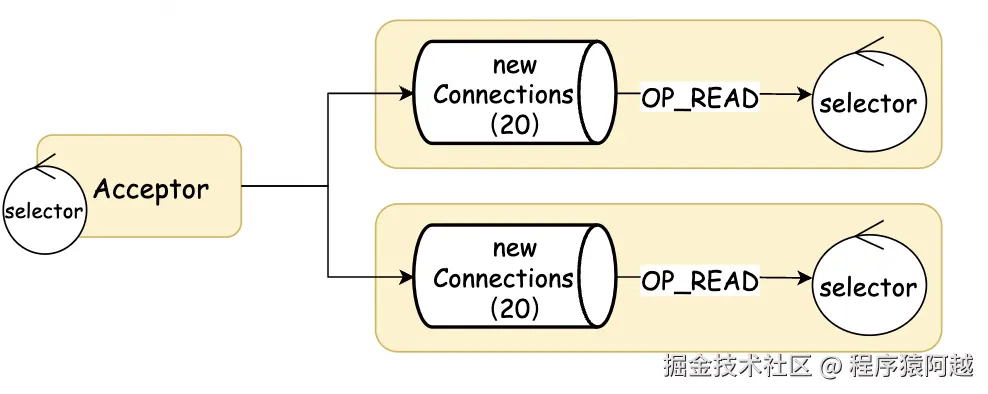
Acceptor#run:一个Listener一个Acceptor,监听OP_ACCEPT事件,新建立SocketChannel轮询选择Processor,放入Processor.newConnections阻塞队列,如果所有队列都满了,则阻塞acceptor线程。
Scala
def run(): Unit = {
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
startupComplete()
var currentProcessorIndex = 0
while (isRunning) {
val ready = nioSelector.select(500)
if (ready > 0) {
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
val key = iter.next
iter.remove()
if (key.isAcceptable) {
accept(key).foreach { socketChannel =>
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
retriesLeft -= 1
// round-robin选processor
processor = synchronized {
currentProcessorIndex = currentProcessorIndex % processors.length
processors(currentProcessorIndex)
}
currentProcessorIndex += 1
// 放入对应processor的newConnections队列
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))
}
}
}
}
}
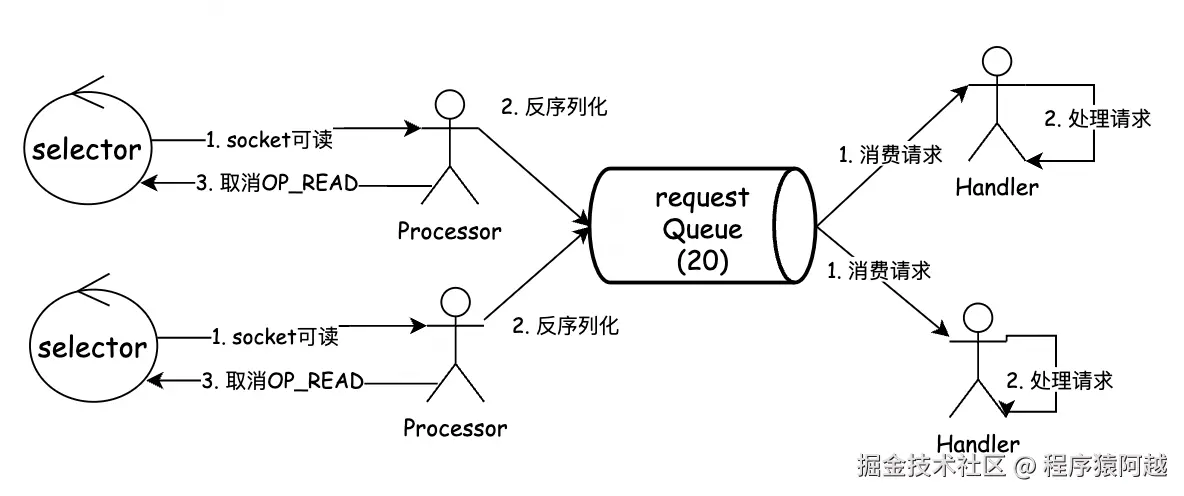
}Processor#run:从正常一个请求的处理时序上来说如下,保证同一个客户端的请求和响应有序。
1)configureNewConnections:processor将新socketChannel注册到自己的selector上,标记OP_READ,封装为KafkaChannel;
2)poll:发现通道可读,读请求到KafkaChannel.Receive;
3)processCompletedReceives:反序列化Receive为Request,放到requestQueue 阻塞队列,取消OP_READ(同一个通道,响应之前不会处理后续请求);
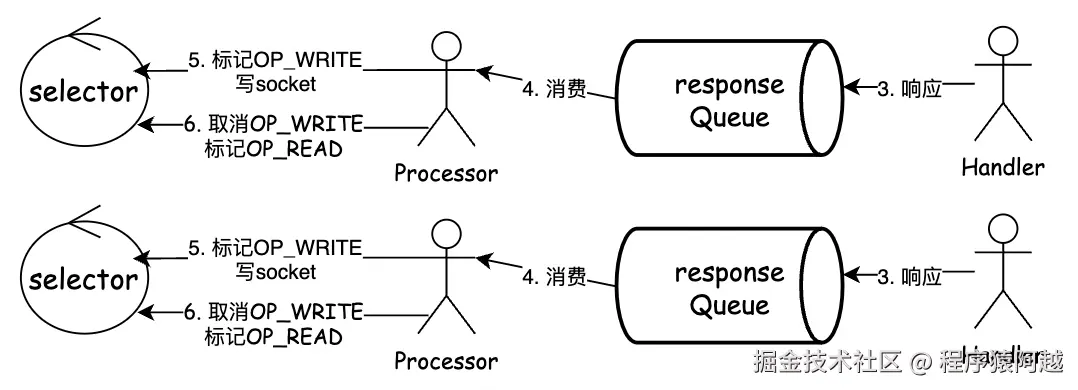
4)KafkaRequestHandler#run:n个handler线程从requestQueue 消费Request,执行业务,将响应Response投递到responseQueue;
5)processNewResponses:processor消费responseQueue ,缓存到KafkaChannel.Send,标记OP_WRITE;
6)poll:发现通道可写,将KafkaChannel.Send写入socket,取消OP_WRITE;
7)processCompletedSends:遍历本轮响应的response,执行对应callback,重新标记OP_READ(同一个通道,响应完成才能读下一个请求);
Scala
private val newConnections =
new ArrayBlockingQueue[SocketChannel](20)
private val responseQueue =
new LinkedBlockingDeque[RequestChannel.Response]()
override def run(): Unit = {
startupComplete()
while (isRunning) {
// 注册新连接:从 newConnections(20) 拉取acceptor接入的连接,封装为KafkaChannel,加到selector里OP_READ
configureNewConnections()
// 处理响应:从 responseQueue(无限) 拉取Response放到对应KafkaChannel缓存的Send里,标记OP_WRITE
processNewResponses()
// 同客户端,对每个KafkaChannel执行io读写,写入到Send对端,从对端读取Receive
poll()
// 处理请求:遍历KafkaChannel.Receive,反序列化为Request,放到requestQueue(20),mute标记channel不可读
processCompletedReceives()
// 本轮响应:回调对应Response的callback,unmute标记channel可读
processCompletedSends()
processDisconnected()
closeExcessConnections()
}
}
// kafka.server.KafkaRequestHandler#run
def run(): Unit = {
while (!stopped) {
// 全局公用一个requestChannel包装了requestQueue(20)
val req = requestChannel.receiveRequest(300)
req match {
case request: RequestChannel.Request =>
try {
apis.handle(request)
}
}
}
}接受请求:如果控制面和数据面分离,全局会有两个requestQueue,否则全局只有一个。
回复响应:每个processor有一个responseQueue,handler需要通过请求上下文拿到需要发送response的对应processor。
KafkaRequestHandler#run:handler线程消费requestQueue,调用KafkaApis执行请求。
Scala
// RequestChannel持有requestQueue
class KafkaRequestHandler(...
// requestQueue
val requestChannel: RequestChannel,
// api处理入口
apis: KafkaApis) extends Runnable {
def run(): Unit = {
while (!stopped) {
val req = requestChannel.receiveRequest(300)
req match {
case request: RequestChannel.Request =>
request.requestDequeueTimeNanos = endTime
apis.handle(request)
}
}
}
}KafkaApis#handle:业务处理流程。
Scala
def handle(request: RequestChannel.Request): Unit = {
request.header.apiKey match {
case ApiKeys.PRODUCE => handleProduceRequest(request)
//...
}
}2-2、粘包拆包
Kafka通讯层是自己实现的,需要先要解决粘包拆包问题。
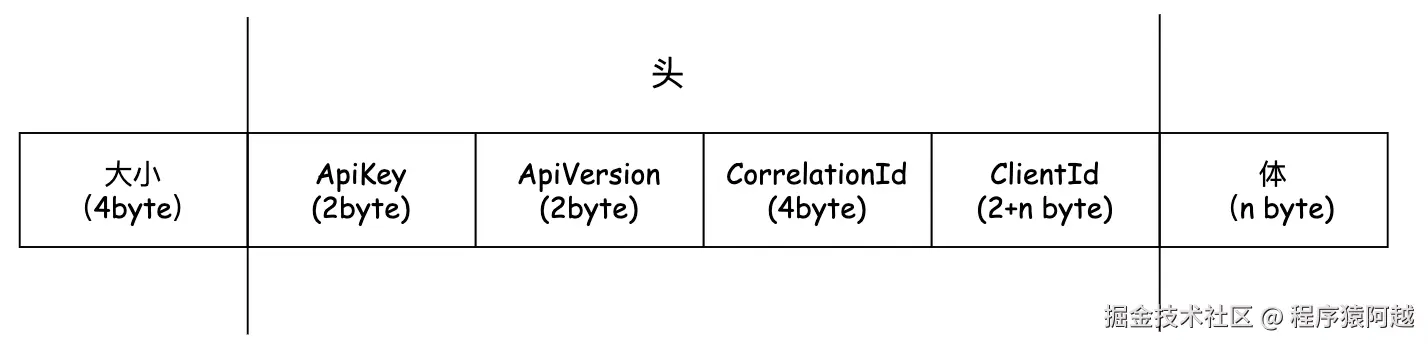
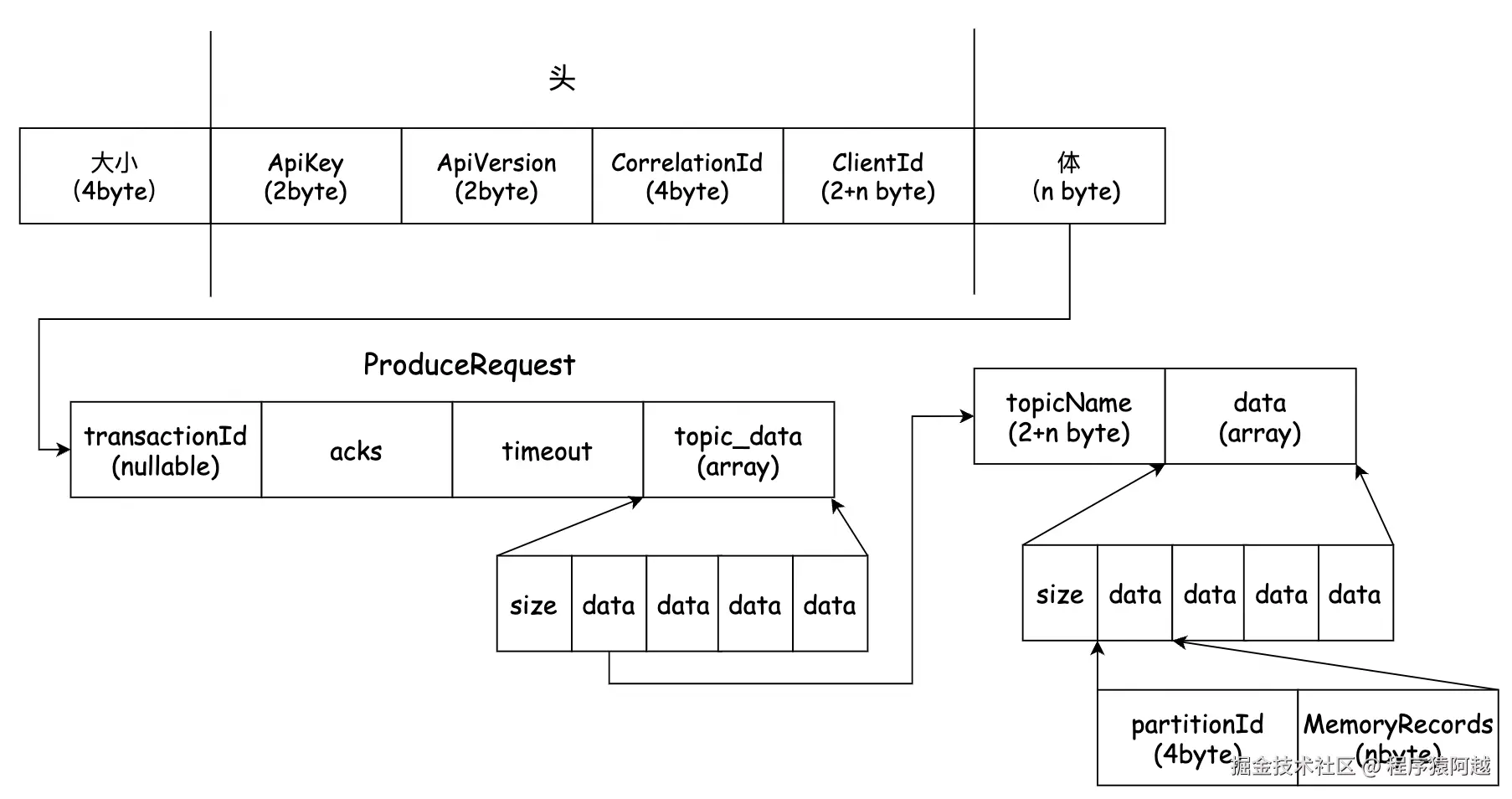
一个kafka报文分为三部分:
1)报文大小:4byte,通讯层通过NetworkSend封装整个报文;
2)头:RequestHeaderData,包含4个属性:ApiKey-请求类型,如ProduceRequest=0;ApiVersion-请求版本定义,根据不同的版本可以做兼容处理;CorrelationId-请求ID,用于请求响应关联,每个客户端控制自增;ClientId-客户端id,string,需要2byte标记clientId长度;
3)体:如ProduceRequest,自行定义Schema;
Selector#attemptRead:读socket。
Java
private void attemptRead(KafkaChannel channel) throws IOException {
String nodeId = channel.id();
// 读socket
long bytesReceived = channel.read();
if (bytesReceived != 0) {
long currentTimeMs = time.milliseconds();
sensors.recordBytesReceived(nodeId, bytesReceived, currentTimeMs);
madeReadProgressLastPoll = true;
// 判断是否读到了完整的报文
NetworkReceive receive = channel.maybeCompleteReceive();
if (receive != null) {
// 如果是的话才加入completedReceives队列
addToCompletedReceives(channel, receive, currentTimeMs);
}
}
}NetworkReceive#readFrom:每次select读socket到channel的Receive里,先读4个byte的报文长度,再读报文,读报文不会超过报文长度。
Java
// 报文长度
private final ByteBuffer size;
// 报文(头+体)
private ByteBuffer buffer;
public long readFrom(ScatteringByteChannel channel) throws IOException {
int read = 0;
if (size.hasRemaining()) {
// 还没读到报文长度,先要确定报文长度
int bytesRead = channel.read(size);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
if (!size.hasRemaining()) {
// 读完报文长度,知道buffer要分配多大
size.rewind();
int receiveSize = size.getInt();
if (receiveSize < 0)
throw new InvalidReceiveException();
if (maxSize != UNLIMITED && receiveSize > maxSize)
throw new InvalidReceiveException();
requestedBufferSize = receiveSize;
if (receiveSize == 0) {
buffer = EMPTY_BUFFER;
}
}
}
if (buffer == null && requestedBufferSize != -1) {
buffer = memoryPool.tryAllocate(requestedBufferSize);
}
if (buffer != null) {
// 读完报文长度,读报文
int bytesRead = channel.read(buffer);
read += bytesRead;
}
return read;
}KafkaChannel#maybeCompleteReceive:如果Receive的size和buffer都写满了,代表读到了完整的报文,可以加入completedReceives,供应用层处理。
Java
public NetworkReceive maybeCompleteReceive() {
if (receive != null && receive.complete()) {
// 如果读到了完整的报文,则返回,加入completedReceives
receive.payload().rewind();
NetworkReceive result = receive;
receive = null;
return result;
}
return null;
}
// NetworkReceive#complete
// 报文长度
private final ByteBuffer size;
// 报文(头+体)
private ByteBuffer buffer;
public boolean complete() {
return !size.hasRemaining() && buffer != null && !buffer.hasRemaining();
}三、反序列化细节
ProduceRequest到broker反序列化,是Kafka实现端到端压缩(生产侧压缩,broker不动,消费侧解压)的第一步。
Processor#processCompletedReceives:这里已经读到了完整报文,可以先反序列化报文头得知是ProduceRequest,然后反序列化ProduceRequest。
Scala
private def processCompletedReceives(): Unit = {
selector.completedReceives.forEach { receive =>
try {
openOrClosingChannel(receive.source) match {
case Some(channel) =>
// 1. 反序列化报文头
val header = RequestHeader.parse(receive.payload)
val connectionId = receive.source
// 2. 构建上下文
val context = new RequestContext(...)
// 3. 反序列化报文体
val req = new RequestChannel.Request(...)
// 4. 放到requestQueue
requestChannel.sendRequest(req)
// channel取消OP_READ
selector.mute(connectionId)
handleChannelMuteEvent(connectionId, ChannelMuteEvent.REQUEST_RECEIVED)
}
}
}
selector.clearCompletedReceives()
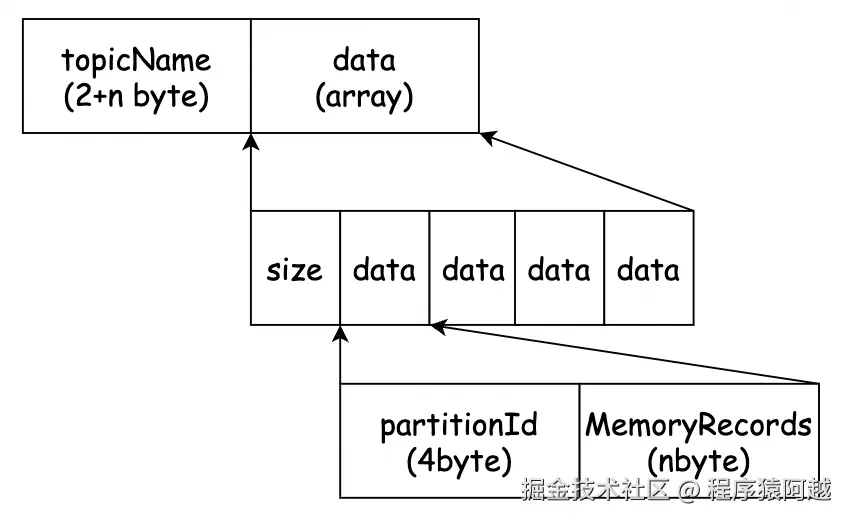
}ProduceRequest:
1)transactionId:事务id,非事务生产者为null;
2)acks:0-不需要响应;1-只需要leader写入成功就ack;-1/all-等待ISR全部写入成功ack;
3)timeout:等待响应的超时时间;
4)topic_data:n个topic的消息;
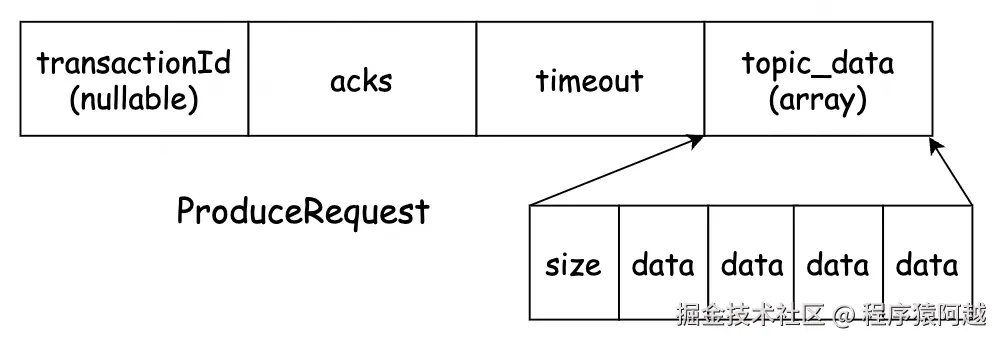
每个topic_data包含n个分区的消息批次(每个分区只有一个批次),最终反序列化为n个分区的MemoryRecords,这和客户端消息批次模型完全一致。
回顾客户端。
RecordAccumulator#append:客户端在生产者线程中,累积器通过MemoryRecordsBuilder构建消息批次。
Java
public RecordAppendResult append(...) throws InterruptedException {
// Step4,创建新批次,并写入消息
MemoryRecordsBuilder recordsBuilder =
recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);
}MemoryRecordsBuilder#close:客户端在Sender线程中从累积器拉取批次后关闭,一个批次一个MemoryRecords。
Java
public class MemoryRecordsBuilder {
private MemoryRecords builtRecords = null;
// sender线程从累积器拉取消息批次后,执行close,生成
public void close() {
// Sender线程写批次头
writeDefaultBatchHeader();
ByteBuffer buffer = buffer().duplicate();
buffer.flip();
buffer.position(initialPosition);
// 构建为MemoryRecords
builtRecords = MemoryRecords.readableRecords(buffer.slice());
}
}MemoryRecords只会包含一个批次的buffer。
Java
public class MemoryRecords extends AbstractRecords {
private final ByteBuffer buffer;
private MemoryRecords(ByteBuffer buffer) {
this.buffer = buffer;
}
public static MemoryRecords readableRecords(ByteBuffer buffer) {
return new MemoryRecords(buffer);
}
}RequestContext#parseRequest:回到broker侧,将buffer按照api版本定义的Schema反序列化为Struct,最后封装为Request对象返回。
Java
public RequestAndSize parseRequest(ByteBuffer buffer) {
ApiKeys apiKey = header.apiKey();
short apiVersion = header.apiVersion();
// buffer->Schema定义的Struct结构,完成反序列化
Struct struct = apiKey.parseRequest(apiVersion, buffer);
// 封装为对象
AbstractRequest body = AbstractRequest.parseRequest(apiKey, apiVersion, struct);
return new RequestAndSize(body, struct.sizeOf());
}
// AbstractRequest#parseRequest
public static AbstractRequest parseRequest(ApiKeys apiKey,
short apiVersion,
Struct struct) {
switch (apiKey) {
case PRODUCE:
return new ProduceRequest(struct, apiVersion);
}
}
public ProduceRequest(Struct struct, short version) {
//...
for (Object topicDataObj : struct.getArray("topic_data")) {
Struct topicData = (Struct) topicDataObj;
String topic = topicData.get("topic");
for (Object partitionResponseObj : topicData.getArray("data")) {
Struct partitionResponse = (Struct) partitionResponseObj;
int partition = partitionResponse.get("partition");
MemoryRecords records = (MemoryRecords) partitionResponse.getRecords("record_set");
setFlags(records);
partitionRecords.put(new TopicPartition(topic, partition), records);
}
}
// ...
}Type#RECORDS:反序列化消息批次,直接用buffer构造了MemoryRecords,这和生产者侧完全一致,完成端到端压缩的第一步。
Java
public static final DocumentedType RECORDS = new DocumentedType() {
public MemoryRecords read(ByteBuffer buffer) {
ByteBuffer recordsBuffer = (ByteBuffer) NULLABLE_BYTES.read(buffer);
return MemoryRecords.readableRecords(recordsBuffer);
}
}
// MemoryRecords#readableRecords
public static MemoryRecords readableRecords(ByteBuffer buffer) {
return new MemoryRecords(buffer);
}ProduceRequest中,1个分区对应1个MemoryRecords对应1个DefaultRecordBatch消息批次。
DefaultRecordBatch消息批次格式如下,通过buffer可以直接读取。
Shell
* BaseOffset => Int64
* Length => Int32
* PartitionLeaderEpoch => Int32
* Magic => Int8
* CRC => Uint32
* Attributes => Int16
* LastOffsetDelta => Int32
* FirstTimestamp => Int64
* MaxTimestamp => Int64
* ProducerId => Int64
* ProducerEpoch => Int16
* BaseSequence => Int32
* Records => [Record]每个RecordBatch批次包含n个DefaultRecord消息。
Shell
* Length => Varint
* Attributes => Int8
* TimestampDelta => Varlong
* OffsetDelta => Varint
* Key => Bytes
* Value => Bytes
* Headers => [HeaderKey HeaderValue]
* HeaderKey => String
* HeaderValue => Bytes四、写消息
4-1、KafkaApis
KafkaApis#handleProduceRequest:ProduceRequest校验。
注意:
1-发送消息阶段不会处理自动创建topic逻辑,元数据查询请求会自动创建topic,见MetadataRequestData#allowAutoTopicCreation;
2-MemoryRecords包含所有分区批次需要经过校验,将buffer封装为一个RecordBatchIterator迭代器读取数据;
Scala
def handleProduceRequest(request: RequestChannel.Request): Unit = {
val produceRequest = request.body[ProduceRequest]
// ...
// 分区-批次
val produceRecords = produceRequest.partitionRecordsOrFail.asScala
// 校验通过的分区批次
val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()
for ((topicPartition, memoryRecords) <- produceRecords) {
if (!authorizedTopics.contains(topicPartition.topic))
// 无权限
unauthorizedTopicResponses += topicPartition -> new PartitionResponse(Errors.TOPIC_AUTHORIZATION_FAILED)
else if (!metadataCache.contains(topicPartition))
// topic不存在
nonExistingTopicResponses += topicPartition -> new PartitionResponse(Errors.UNKNOWN_TOPIC_OR_PARTITION)
else
// 批次数据校验
try {
ProduceRequest.validateRecords(request.header.apiVersion, memoryRecords)
authorizedRequestInfo += (topicPartition -> memoryRecords)
} catch {
case e: ApiException =>
invalidRequestResponses += topicPartition -> new PartitionResponse(Errors.forException(e))
}
}
// 发送响应回调方法定义
def sendResponseCallback(responseStatus: Map[TopicPartition, PartitionResponse]): Unit = {
// 发送响应
// ...
if (produceRequest.acks == 0) {
if (errorInResponse) {
// 如果acks=0,但是发生错误,会关闭连接
closeConnection(request, new ProduceResponse(mergedResponseStatus.asJava).errorCounts)
} else {
// 不回复响应 仅标记channel OP_READ重新可读
sendNoOpResponseExemptThrottle(request)
}
}
}
if (authorizedRequestInfo.isEmpty)
// 没有校验通过的分区批次,直接响应
sendResponseCallback(Map.empty)
else {
val internalTopicsAllowed = request.header.clientId == AdminUtils.AdminClientId
// 写消息
replicaManager.appendRecords(
timeout = produceRequest.timeout.toLong,
requiredAcks = produceRequest.acks,
internalTopicsAllowed = internalTopicsAllowed,
origin = AppendOrigin.Client,
entriesPerPartition = authorizedRequestInfo,
responseCallback = sendResponseCallback,
recordConversionStatsCallback = processingStatsCallback)
produceRequest.clearPartitionRecords()
}
}
// ProduceRequest
public static void validateRecords(short version, MemoryRecords records) {
if (version >= 3) {
Iterator<MutableRecordBatch> iterator = records.batches().iterator();
if (!iterator.hasNext())
// 空批次
throw new InvalidRecordException();
MutableRecordBatch entry = iterator.next();
if (entry.magic() != RecordBatch.MAGIC_VALUE_V2)
throw new InvalidRecordException();
if (version < 7 && entry.compressionType() == CompressionType.ZSTD) {
// 压缩算法校验
throw new UnsupportedCompressionTypeException();
}
// 一个分区的MemoryRecords只有一个批次
if (iterator.hasNext())
throw new InvalidRecordException();
}
}4-2、ReplicaManager
ReplicaManager#appendRecords:leader写消息,对于ack=-1要提交延迟任务,在延迟时间内分区满足ack条件,则正常响应,否则响应Timeout异常。
Scala
def appendRecords(timeout: Long,
requiredAcks: Short,
internalTopicsAllowed: Boolean,
origin: AppendOrigin,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
responseCallback: Map[TopicPartition, PartitionResponse] => Unit,
delayedProduceLock: Option[Lock] = None,
recordConversionStatsCallback: Map[TopicPartition, RecordConversionStats] => Unit = _ => ()): Unit = {
if (isValidRequiredAcks(requiredAcks)) {
val sTime = time.milliseconds
// 1. leader写消息
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
origin, entriesPerPartition, requiredAcks)
// 分区 - ProducePartitionStatus(response)
val produceStatus = localProduceResults.map { case (topicPartition, result) =>
topicPartition ->
ProducePartitionStatus(
result.info.lastOffset + 1,
new PartitionResponse(...))
}
recordConversionStatsCallback(localProduceResults.map { case (k, v) => k -> v.info.recordConversionStats })
if (delayedProduceRequestRequired(requiredAcks, entriesPerPartition, localProduceResults)) {
// 2. acks=-1 要等待isr写入ok
// 提交延迟任务,延迟时间等于ProduceRequest.timeout,超时未完成的分区返回超时异常
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
val producerRequestKeys = entriesPerPartition.keys.map(TopicPartitionOperationKey(_)).toSeq
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
} else {
// ack不为-1,执行responseCallback...
}
} else {
// 非法ack参数,执行responseCallback...
}
}ReplicaManager#appendToLocalLog:内部topic拒绝处理,循环所有分区,根据TopicPartition找到内存Partition对象。
Scala
private def appendToLocalLog(internalTopicsAllowed: Boolean,
origin: AppendOrigin,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {
entriesPerPartition.map { case (topicPartition, records) =>
if (Topic.isInternal(topicPartition.topic) && !internalTopicsAllowed) {
// 内部topic只能admin_client来处理
// 内部topic包含__consumer_offsets、__transaction_state
(topicPartition, LogAppendResult(
LogAppendInfo.UnknownLogAppendInfo,
Some(new InvalidTopicException())))
} else {
try {
// 找到Partition对象,执行appendRecordsToLeader
val partition = getPartitionOrException(topicPartition)
val info = partition.appendRecordsToLeader(records, origin, requiredAcks)
(topicPartition, LogAppendResult(info))
} catch {
// 异常返回
}
}
}
}4-3、Partition
Partition#appendRecordsToLeader:partition这层处理Leader和Isr相关逻辑。
1)加leaderAndIsr读锁,处理期间leader和isr不发生变化;
2)leaderLogIfLocal,确认自己仍然是分区leader,拿到Log对象;
3)当acks=-1(all)时,确认当前isr列表大小≥最小isr大小要求,默认min.insync.replicas=1,只要leader在isr中就可以;
4)调用Log将消息写入底层存储;
5)写入后尝试增加高水位HW;
Scala
var log: Option[Log] = None
def leaderLogIfLocal: Option[Log] = {
log.filter(_ => isLeader)
}
def appendRecordsToLeader(records: MemoryRecords, origin: AppendOrigin, requiredAcks: Int): LogAppendInfo = {
// leaderAndIsr读锁(leaderAndIsr在锁内不能被controller更新)
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
// leaderLogIfLocal 拿Log对象
leaderLogIfLocal match {
case Some(leaderLog) =>
// 自己还是leader
// min.insync.replicas=1
val minIsr = leaderLog.config.minInSyncReplicas
// isr列表大小
val inSyncSize = inSyncReplicaIds.size
// 如果acks=-1/all,但是isr小于min.insync.replicas,则报错
// 但是默认min.insync.replicas=1,leader副本一定在isr里,所以不会报错
if (inSyncSize < minIsr && requiredAcks == -1) {
throw new NotEnoughReplicasException()
}
// leader写 Log#appendAsLeader
val info = leaderLog.appendAsLeader(records, leaderEpoch = this.leaderEpoch, origin,
interBrokerProtocolVersion)
// 尝试增加HW高水位
(info, maybeIncrementLeaderHW(leaderLog))
case None =>
// 自己已经不是leader
throw new NotLeaderOrFollowerException()
}
}
if (leaderHWIncremented)
// HW=min(所有副本的LEO),如果HW增加
// 在acks=-1的情况下,可能可以直接响应客户端的ProduceRequest
tryCompleteDelayedRequests()
else {
delayedOperations.checkAndCompleteFetch()
}
info
}Partition#maybeIncrementLeaderHW:高水位HW=min(ISR副本的LEO,与leader的LEO延迟在30s内的副本的LEO) 。LEO(Log End Offset)就是这里的logEndOffsetMetadata.messageOffset,LEO=副本已写入消息的逻辑offset+1(在Log写消息的时候会更新)。
Scala
private def maybeIncrementLeaderHW(leaderLog: Log, curTime: Long = time.milliseconds): Boolean = {
inReadLock(leaderIsrUpdateLock) {
// 将当前leader的LEO作为基准
var newHighWatermark = leaderLog.logEndOffsetMetadata
remoteReplicasMap.values.foreach { replica =>
// 取所有符合要求的副本的LEO的最小值
if (replica.logEndOffsetMetadata.messageOffset
< newHighWatermark.messageOffset &&
// 参与评选的副本要求
// 上次追上leader的LEO的时间小于30s(replica.lag.time.max.ms)
//|| ISR列表中的副本
(curTime - replica.lastCaughtUpTimeMs <= replicaLagTimeMaxMs
|| inSyncReplicaIds.contains(replica.brokerId))) {
newHighWatermark = replica.logEndOffsetMetadata
}
}
// 调用Log尝试增加HW
leaderLog.maybeIncrementHighWatermark(newHighWatermark) match {
case Some(oldHighWatermark) =>
// 如果返回老的HW,代表HW增加
true
case None =>
false
}
}
}
// Log#maybeIncrementHighWatermark
def maybeIncrementHighWatermark(newHighWatermark: LogOffsetMetadata): Option[LogOffsetMetadata] = {
if (newHighWatermark.messageOffset > logEndOffset)
// HW超过目前写入最大offset
throw new IllegalArgumentException()
lock.synchronized {
val oldHighWatermark = fetchHighWatermarkMetadata
if (oldHighWatermark.messageOffset < newHighWatermark.messageOffset ||
(oldHighWatermark.messageOffset == newHighWatermark.messageOffset
&& oldHighWatermark.onOlderSegment(newHighWatermark))) {
updateHighWatermarkMetadata(newHighWatermark)
Some(oldHighWatermark)
} else {
None
}
}
}如当前分区的3副本都在ISR中,LEO情况如下:1)Leader:LEO=100;2)Follower1:LEO=95;3)Follower2:LEO=93。那么HW=93。消费者只能消费[0,93)偏移量之内的消息,如果2个Follower宕机则需要从93开始同步消息(如果replication-offset-checkpoint检查点持久化了93,否则可能更小)。
Log#updateHighWatermarkMetadata:更新HW,HW缓存在Log里。
Scala
private var highWatermarkMetadata: LogOffsetMetadata
private def updateHighWatermarkMetadata(newHighWatermark: LogOffsetMetadata): Unit = {
lock synchronized {
highWatermarkMetadata = newHighWatermark
//...
}
}一个broker的所有HW会持久化到replication-offset-checkpoint文件中。
所有checkpoint类型的文件格式都类似,如recovery-point-offset-checkpoint。
Scala
0 // checkpoint格式版本
3 // 下面有几行
Topic2 2 13160 // topic名 分区 HW
Test1 0 2424
Test1 1 2533ReplicaManager#becomeLeaderOrFollower:当broker首次收到controller下发的LeaderAndIsr请求后,开启HW定时持久化。
Scala
def becomeLeaderOrFollower(
leaderAndIsrRequest: LeaderAndIsrRequest): LeaderAndIsrResponse = {
// ...
// 开启highwatermark-checkpoint持久化
startHighWatermarkCheckPointThread()
}
def startHighWatermarkCheckPointThread(): Unit = {
if (highWatermarkCheckPointThreadStarted.compareAndSet(false, true))
scheduler.schedule("highwatermark-checkpoint",
// runnable
checkpointHighWatermarks _,
// replica.high.watermark.checkpoint.interval.ms=5000
period = config.replicaHighWatermarkCheckpointIntervalMs,
unit = TimeUnit.MILLISECONDS)
}Partition#createLog:在Log对象被创建时(比如重启),会读取checkpoint,将HW恢复到内存。
Scala
private[cluster] def createLog(isNew: Boolean, isFutureReplica: Boolean, offsetCheckpoints: OffsetCheckpoints): Log = {
def updateHighWatermark(log: Log) = {
val checkpointHighWatermark = offsetCheckpoints.fetch(log.parentDir, topicPartition).getOrElse {
0L
}
// 从checkpoint恢复HW
val initialHighWatermark = log.updateHighWatermark(checkpointHighWatermark)
}
logManager.initializingLog(topicPartition)
var maybeLog: Option[Log] = None
try {
// 创建Log
val log = logManager.getOrCreateLog(topicPartition, () => fetchLogConfig, isNew, isFutureReplica)
maybeLog = Some(log)
// 恢复HW
updateHighWatermark(log)
log
} finally {
logManager.finishedInitializingLog(topicPartition, maybeLog, () => fetchLogConfig)
}
}4-4、Log
4-4-1、文件系统中的组织形式
server.properties配置log.dirs设置kafka的数据存储目录。
properties
log.dirs=/path/to/data数据目录下存在如下文件:
Shell
tree -a
.
├── .kafka_cleanshutdown
├── .lock
├── Test1-0
│ ├── 00000000000000000000.index
│ ├── 00000000000000000000.log
│ ├── 00000000000000000000.timeindex
│ ├── 00000000000000001872.index
│ ├── 00000000000000001872.log
│ ├── 00000000000000001872.timeindex
│ └── leader-epoch-checkpoint
├── cleaner-offset-checkpoint
├── log-start-offset-checkpoint
├── meta.properties
├── recovery-point-offset-checkpoint
└── replication-offset-checkpoint1)数据目录下的唯一目录={Topic}-{PartitionId},如Test1-0,存储了每个分区的数据。
每个分区的数据由多个Segment 组成,如0000是第一个segment,1872是第二个segment,文件名是该segment的起始offset,如0000存储了offset=[0,1872)共1872条消息。
每个Segment由4个文件构成:
a)log:消息数据文件;
b)index:offset索引文件,key=相对offset(相对于segment的起始offset),value=消息在log的写入位置;
c)timeindex:时间索引文件,key=时间戳,value=相对offset;
d)txnindex:中断事务索引文件;(以后再看)
leader-epoch-checkpoint:对于每个分区,记录每个leader任期的offset范围,用于保证多个分区副本的最终一致性(segment截断),比如下面这个文件:epoch=0,offset=[0,1500);epoch=1,offset=[1500,3200)。
Plain
0 // 版本号
3 // 条目数量
0 0 // epoch 起始offset
1 1500 // epoch 起始offset
2 3200 // epoch 起始offset2)meta.properties:数据和broker+cluster的关联关系。
properties
broker.id=111
version=0
cluster.id=nshQP6WtTre4ECTCd5YLBQ3)checkpoint
数据目录下的所有checkpoint文件的格式相同,记录每个分区不同业务的offset进度。
Plain
0 // 版本号
2 // 条目数量
Test1 0 2856 // topic 分区id offset
Test1 1 1111 // topic 分区id offsetrecovery-point-offset-checkpoint:offset=消息刷盘进度。
replication-offset-checkpoint:offset=高水位HW。
log-start-offset-checkpoint:offset=Log Start Offset,起始offset,当发生数据清理的时候,这里有数据。
cleaner-offset-checkpoint :offset=压缩topic分区的处理进度。
4)kafka_cleanshutdown :broker正常关闭标记文件,如果不存在,代表kafka进程异常关闭,重启后需要从recovery-point-offset-checkpoint开始,读取log判断具体刷盘情况恢复。
5)lock:文件锁,一个数据目录同时只能有一个进程访问。
4-4-2、Log
在内存中,LogManager管理了多个分区下的Log对象。
Scala
class LogManager(...) extends Logging with KafkaMetricsGroup {
// 分区 - Log对象
private val currentLogs = new Pool[TopicPartition, Log]()
}一个Log管理一个topic分区下的数据和各种offset。
Scala
class Log {
// 数据根目录
@volatile private var _parentDir: String = dir.getParent
// 上次刷盘时间
private val lastFlushedTime = new AtomicLong(time.milliseconds)
// LogEndOffset LEO
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
// 事务相关
@volatile private var firstUnstableOffsetMetadata: Option[LogOffsetMetadata] = None
// 高水位 HW
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)
// segment的起始offset(文件名) - segment
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
def addSegment(segment: LogSegment): LogSegment =
this.segments.put(segment.baseOffset, segment)
}Log#append:写Log主流程如下。
Scala
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
assignOffsets/*true*/: Boolean,
leaderEpoch: Int,
ignoreRecordSize/*false*/: Boolean): LogAppendInfo = {
// 1. 校验,转换LogAppendInfo
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize)
var validRecords = trimInvalidBytes(records, appendInfo)
// log级别锁,同一个分区不能并发写
lock synchronized {
checkIfMemoryMappedBufferClosed()
if (assignOffsets) {
// 正常生产者发送消息,需要为消息分配offset=LEO=已写入的offset+1
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = Some(offset.value)
val now = time.milliseconds
// 继续校验组装appendInfo
val validateAndOffsetAssignResult = try {
LogValidator.validateMessagesAndAssignOffsets(validRecords,
topicPartition,
offset,
time,
now,...)
} catch {
case e: IOException =>
throw new KafkaException()
}
validRecords = validateAndOffsetAssignResult.validatedRecords
// 该批消息的最大时间戳
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
// 该批消息的最大时间戳对应的offset
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
// validateMessagesAndAssignOffsets会修改offset=LEO+这批消息的数量
// 该批消息的最后一个消息的offset
appendInfo.lastOffset = offset.value - 1
} else {
// follower从leader拉来的消息,不需要做上面的处理
// ...
}
// 2. 处理segment滚动
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
// 3. 写segment
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// 4. 更新LEO,下次append的批次的offset从这里开始
updateLogEndOffset(appendInfo.lastOffset + 1)
// 5. 刷盘逻辑,flush.messages=Long.MAX_VALUE,配置成1则每次append都fsync
if (unflushedMessages >= config.flushInterval)
flush()
appendInfo
}
}Step1,校验批次消息组装LogAppendInfo。
组装LogAppendInfo如下,LogAppendInfo中的部分信息会作为ProduceResponse返回客户端,比如firstOffset ,生产者可以通过firstOffset+批次中的消息偏移量得到发送的消息对应服务端的实际offset。
Scala
case class LogAppendInfo(
// 该批消息第一个offset=当前LEO(Log End Offset)
var firstOffset: Option[Long],
// 该批消息第一个offset=当前LEO + 消息数量 - 1
var lastOffset: Long,
// 该批消息的最大时间戳(创建时间)
var maxTimestamp: Long,
// maxTimestamp对应的offset
var offsetOfMaxTimestamp: Long,
// -1
var logAppendTime: Long,
// 该批消息写入时,Log的StartOffset
var logStartOffset: Long,
...)MemoryRecords 封装了多个批次,但是一个分区下只有一个批次,DefaultRecordBatch代表一个批次。
在客户端侧,批次的baseOffset(在LogAppendInfo里就是firstOffset)被设置为0,在校验阶段broker会通过setLastOffset设置真实的baseOffset。
baseOffset=批次起始offset,lastOffsetDelta=批次结束offset-批次起始offset+1=最后一条消息在本批次中的offset。
Java
public interface MutableRecordBatch/*可变批次*/ extends RecordBatch {
void setLastOffset(long offset);
void setMaxTimestamp(TimestampType timestampType, long maxTimestamp);
void setPartitionLeaderEpoch(int epoch);
}
// DefaultRecordBatch实现MutableRecordBatch
DefaultRecordBatch(ByteBuffer buffer) {
this.buffer = buffer;
}
public void setLastOffset(long offset) {
buffer.putLong(BASE_OFFSET_OFFSET/*0*/, offset - lastOffsetDelta());
}
private int lastOffsetDelta() {
return buffer.getInt(LAST_OFFSET_DELTA_OFFSET/*23*/);
}Step2,Log#maybeRoll处理Segment滚动逻辑。
Scala
private def maybeRoll(messagesSize: Int, appendInfo: LogAppendInfo): LogSegment = {
val segment = activeSegment // 当前正在写入的segment
val now = time.milliseconds
val maxTimestampInMessages = appendInfo.maxTimestamp
val maxOffsetInMessages = appendInfo.lastOffset
// 判读是否需要滚动
if (segment.shouldRoll(RollParams(config, appendInfo, messagesSize, now))){
appendInfo.firstOffset match {
// 创建新segment,这批消息的起始offset=文件名
case Some(firstOffset) => roll(Some(firstOffset))
}
} else {
segment
}
}LogSegment#shouldRoll:
滚动条件1-log容量不足,segment.bytes=1G;
滚动条件2-log有写入,且最后一条写入时间超过segment.ms=7天,rollJitterMs是个随机数,防止惊群,多个分区同时触发roll;
滚动条件3-offset或time索引写满,segment.index.bytes=10M;
Scala
def shouldRoll(rollParams: RollParams): Boolean = {
val reachedRollMs = timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) >
rollParams.maxSegmentMs - rollJitterMs
// log大小 > segment.bytes(1g) - 本批消息大小 --- 放不下了
size > rollParams.maxSegmentBytes - rollParams.messagesSize ||
// log有写入,且超过segment.ms(7天)
(size > 0 && reachedRollMs) ||
// 索引写满
offsetIndex.isFull || timeIndex.isFull || !canConvertToRelativeOffset(rollParams.maxOffsetInMessages)
}Step3,写segment后面看。
Step4,更新LEO,下次append的批次的offset从这里开始。
Scala
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
private def updateLogEndOffset(offset: Long): Unit = {
nextOffsetMetadata = LogOffsetMetadata(offset, activeSegment.baseOffset, activeSegment.size)
if (highWatermark >= offset) {
updateHighWatermarkMetadata(nextOffsetMetadata)
}
if (this.recoveryPoint > offset) {
this.recoveryPoint = offset
}
}Step5,Step3写segment只到pagecache,刷盘逻辑在这里控制。
recoveryPoint=刷盘进度=已刷盘offset+1;logEndOffset=写入进度=已写入offset+1;unflushedMessages=待刷盘的消息数量。
当unflushedMessages≥flush.messages时,触发一次刷盘。但是flush.messages默认配置为Long.MAX_VALUE,不会根据未刷盘消息数量触发刷盘。如果要同步刷盘,可以将flush.messages设置为1。
Scala
def unflushedMessages: Long = this.logEndOffset - this.recoveryPoint
if (unflushedMessages >= config.flushInterval)
flush()刷盘时机还有三处:
1)Log#roll:创建新segment时,异步将老segment刷盘;
2)LogManager#flushDirtyLogs:后台定时任务,每隔log.flush.scheduler.interval.ms =Long.MAX_VALUE跑一次,检测所有log是否需要刷盘,刷盘间隔=flush.ms=Long.MAX_VALUE,所以默认情况下没有定时刷盘逻辑;
3)LogManager#shutdown:broker正常停机;
Log#flush:可以指定位点,将[刷盘进度recoveryPoint,指定位点)间的数据刷盘,最后更新内存的刷盘进度。
Scala
def flush(): Unit = flush(this.logEndOffset)
def flush(offset: Long): Unit = {
if (offset <= this.recoveryPoint)
return
for (segment <- logSegments(this.recoveryPoint, offset))
segment.flush()
lock synchronized {
checkIfMemoryMappedBufferClosed()
if (offset > this.recoveryPoint) {
this.recoveryPoint = offset
lastFlushedTime.set(time.milliseconds)
}
}
}Segment#flush:刷盘包含Segment下的所有类型文件,包括数据和索引。
Scala
def flush(): Unit = {
LogFlushStats.logFlushTimer.time {
log.flush() // .log
offsetIndex.flush() // .index
timeIndex.flush() // .timeindex
txnIndex.flush() // .txnindex
}
}LogManager#startup:刷盘进度每隔log.flush.offset.checkpoint.interval.ms=60s从内存recoveryPoint持久化到recovery-point-offset-checkpoint文件。
如何使用刷盘进度,在第五节。
Scala
def startup(): Unit = {
scheduler.schedule("kafka-recovery-point-checkpoint",
checkpointLogRecoveryOffsets _,
delay = InitialTaskDelayMs,
// log.flush.offset.checkpoint.interval.ms=60000
period = flushRecoveryOffsetCheckpointMs,
TimeUnit.MILLISECONDS)
}4-4-3、Segment
LogSegment管理一个分区下的数据文件。
Scala
class LogSegment private[log] (
// .log
val log: FileRecords,
// .index
val lazyOffsetIndex: LazyIndex[OffsetIndex],
// .timeindex
val lazyTimeIndex: LazyIndex[TimeIndex],
// .txnindex
val txnIndex: TransactionIndex,
// 当前segment的起始offset,文件名
val baseOffset: Long,
// 索引建立间隔byte
val indexIntervalBytes: Int,
// 随机数,防止惊群,多分区同时roll segment
val rollJitterMs: Long,
val time: Time) extends Logging {
def offsetIndex: OffsetIndex = lazyOffsetIndex.get
def timeIndex: TimeIndex = lazyTimeIndex.get
}LogSegment#append:将消息写入log和索引。
索引建立间隔为log.index.interval.bytes=4096,即每4k生成一条索引。
Scala
def append(largestOffset: Long,
largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long,
records: MemoryRecords): Unit = {
// 当前log的大小
val physicalPosition = log.sizeInBytes()
// 顺序写.log文件
val appendedBytes = log.append(records)
if (largestTimestamp > maxTimestampSoFar) {
// 当前segment的最大时间戳
maxTimestampSoFar = largestTimestamp
// 当前segment的最大时间戳对应的offset
offsetOfMaxTimestampSoFar = shallowOffsetOfMaxTimestamp
}
// mmap写.index和.timestamp文件
// log.index.interval.bytes=4096 每4k生成索引
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
// 最大offset -> 在log中的物理位置(注意是写log前的位置)
offsetIndex.append(largestOffset, physicalPosition)
// 最大时间戳 -> 对应的offset
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}FileRecords#append:将批次buffer直接顺序写入底层FileChannel。
从客户端压缩到服务端写log数据,中间没有额外的转换,端到端压缩完成第一步(生产者到broker)。
Java
private final FileChannel channel;
private final AtomicInteger size;
public int append(MemoryRecords records) throws IOException {
int written = records.writeFullyTo(channel);
size.getAndAdd(written);
return written;
}
// MemoryRecords
private final ByteBuffer buffer;
public int writeFullyTo(GatheringByteChannel channel) throws IOException {
buffer.mark();
int written = 0;
while (written < sizeInBytes())
written += channel.write(buffer);
buffer.reset();
return written;
}offset索引和时间索引都继承自AbstractIndex。索引文件都是定长(maxIndexSize)文件,通过mmap读写。
Scala
abstract class AbstractIndex(@volatile private var _file: File,
// segment起始offset,文件名
val baseOffset: Long,
// segment.index.bytes=10M
val maxIndexSize: Int = -1,
val writable: Boolean)
// mmap
protected var mmap: MappedByteBuffer = {
val newlyCreated = file.createNewFile()
val raf = if (writable) new RandomAccessFile(file, "rw")
else new RandomAccessFile(file, "r")
try {
_length = raf.length()
val idx = {
if (writable)
raf.getChannel.map(FileChannel.MapMode.READ_WRITE, 0, _length)
else
raf.getChannel.map(FileChannel.MapMode.READ_ONLY, 0, _length)
}
if(newlyCreated)
idx.position(0)
else
idx.position(roundDownToExactMultiple(idx.limit(), entrySize))
idx
} finally {
CoreUtils.swallow(raf.close(), AbstractIndex)
}
}
// 总共能容纳的索引数量
private[this] var _maxEntries: Int = mmap.limit() / entrySize
// 当前索引数量
protected var _entries: Int = mmap.position() / entrySize
}区别是两个索引的内存不同。
Scala
class OffsetIndex extends AbstractIndex {
override def entrySize = 8
}
class TimeIndex extends AbstractIndex {
override def entrySize = 12
}OffsetIndex#append:offset索引,记录相对offset→segment的物理位置。
offset占用8byte,相对offset=offset-segment起始offset占用4byte。
Scala
def append(offset: Long, position: Int): Unit = {
inLock(lock) {
// offset - baseOffset(segment的起始offset)
mmap.putInt(relativeOffset(offset))
// segment的log的物理位置
mmap.putInt(position)
_entries += 1
_lastOffset = offset
}
}TimeIndex#maybeAppend:时间索引,记录消息创建时间戳→相对offset。
所以通过时间搜索数据,需要走两次索引(时间索引和offset索引)。
Scala
def maybeAppend(timestamp: Long, offset: Long, skipFullCheck: Boolean = false): Unit = {
inLock(lock) {
mmap.putLong(timestamp)
mmap.putInt(relativeOffset(offset))
_entries += 1
_lastEntry = TimestampOffset(timestamp, offset)
}
}4-5、acks=-1
Partition#appendRecordsToLeader:acks=-1的情况下,如果写log完成且HW增加,可能可以直接响应客户端。
Scala
def appendRecordsToLeader(records: MemoryRecords, origin: AppendOrigin, requiredAcks: Int): LogAppendInfo = {
// 校验 当前ISR列表大小 >= min.insync.replicas=1
// ...
// leader写 Log#appendAsLeader
val info = leaderLog.appendAsLeader(records, leaderEpoch = this.leaderEpoch, origin,
interBrokerProtocolVersion)
// 尝试增加HW高水位
(info, maybeIncrementLeaderHW(leaderLog))
if (leaderHWIncremented)
// HW=min(所有副本的LEO),如果HW增加
// 在acks=-1的情况下,可能可以直接响应客户端的ProduceRequest
tryCompleteDelayedRequests()
info
}DelayedProduce#tryComplete:尝试完成ProduceRequest,响应客户端。
Scala
override def tryComplete(): Boolean = {
// 循环检查ProduceRequest里的所有分区
produceMetadata.produceStatus.foreach { case (topicPartition, status) =>
// 如果该分区还是acksPending,代表没满足acks=-1,需要判断
if (status.acksPending) {
val (hasEnough, error) = replicaManager.getPartitionOrError(topicPartition) match {
case Left(err) =>
// 当前节点非leader
(false, err)
case Right(partition) =>
// 当前节点还是leader,校验是否已经满足acks=-1
partition.checkEnoughReplicasReachOffset(status.requiredOffset)
}
if (error != Errors.NONE || hasEnough) {
// 有异常 || 满足acks=-1
status.acksPending = false
status.responseStatus.error = error
}
}
}
if (!produceMetadata.produceStatus.values.exists(_.acksPending)) {
// 所有分区都满足acks=-1,响应客户端
forceComplete()
} else
false
}
// 响应客户端
override def onComplete(): Unit = {
val responseStatus = produceMetadata.produceStatus.map { case (k, status) => k -> status.responseStatus }
responseCallback(responseStatus)
}Partition#checkEnoughReplicasReachOffset:针对一个分区,判断是否可以响应客户端。
requiredOffset为本次ProduceRequest在Leader这里的写入进度。
当 高水位HW≥本次的写入进度 则可以响应客户端,如果min.insync.replicas(1)≤ISR列表响应成功,反之响应异常。
因为HW=min(所有ISR的LEO),所以需要所有ISR内的副本追上本次ProduceRequest对应leader写入的offset,该分区才能响应客户端。如果中间ISR列表发生变化,导致小于min.insync.replicas要求,会响应失败。
Scala
def checkEnoughReplicasReachOffset(requiredOffset: Long): (Boolean, Errors) = {
leaderLogIfLocal match {
case Some(leaderLog) =>
// 当前的ISR列表
val curInSyncReplicaIds = inSyncReplicaIds
// min.insync.replicas=1
val minIsr = leaderLog.config.minInSyncReplicas
// HW >= 本次ProduceRequest在leader的写入进度offset
if (leaderLog.highWatermark >= requiredOffset) {
if (minIsr <= curInSyncReplicaIds.size)
// min.insync.replicas <= 当前的ISR列表大小,该分区处理完毕
(true, Errors.NONE)
else
// min.insync.replicas > 当前ISR列表,该分区处理完毕,返回异常
(true, Errors.NOT_ENOUGH_REPLICAS_AFTER_APPEND)
} else
(false, Errors.NONE)
case None =>
// 不是leader了
(false, Errors.NOT_LEADER_OR_FOLLOWER)
}
}DelayedProduce在构造的时候会把所有分区标记为超时,如果到时间未满足acks=-1,相关分区返回客户端超时异常。
Scala
class DelayedProduce {
produceMetadata.produceStatus.foreach { case (topicPartition, status) =>
if (status.responseStatus.error == Errors.NONE) {
status.acksPending = true
// 先标记为超时,如果在ProduceRequest.timeout里没达成acks=-1条件,
// 则响应客户端超时异常
status.responseStatus.error = Errors.REQUEST_TIMED_OUT
} else {
status.acksPending = false
}
}4-6、增加HW的场景
如果一个分区只有一个leader副本,那么在写入之后就会立即增加高水位。
上文已经解释了HW=min(ISR副本的LEO,与leader的LEO延迟在30s(replica.lag.time.max.ms)内的副本的LEO)。这里分析HW增加的场景,目的是补充触发响应客户端的逻辑(acks=-1情况下),后续章节分析副本数据同步再详细分析HW。
其他增加HW的场景有。
case1:follower主动追上leader。
Partition#updateFollowerFetchState:follower来leader拉消息,leader根据拉消息的结果,判断HW是否增加。
Scala
def updateFollowerFetchState(followerId: Int,
followerFetchOffsetMetadata: LogOffsetMetadata,
followerStartOffset: Long,
followerFetchTimeMs: Long,
leaderEndOffset: Long): Boolean = {
getReplica(followerId) match {
case Some(followerReplica) =>
val leaderHWIncremented = if (prevFollowerEndOffset != followerReplica.logEndOffset) {
// follower的LEO发生改变,判断是否需要增加HW,上文已经看了逻辑
leaderLogIfLocal.exists(leaderLog => maybeIncrementLeaderHW(leaderLog, followerFetchTimeMs))
} else {
false
}
if (leaderLWIncremented || leaderHWIncremented)
// 如果HW增加,尝试完成ProduceRequest延迟任务
tryCompleteDelayedRequests()
true
}
}case2:isr列表收缩,比如收缩到1只剩leader,导致HW增加。
关于isr收缩后续章节在继续讨论。
Partition#makeLeader:比如老leader下线,新leader上线,此时ISR只有leader。
Scala
def makeLeader(partitionState: LeaderAndIsrPartitionState,
highWatermarkCheckpoints: OffsetCheckpoints): Boolean = {
val (leaderHWIncremented, isNewLeader) =
inWriteLock(leaderIsrUpdateLock) {
/// ...
(maybeIncrementLeaderHW(leaderLog), isNewLeader)
}
if (leaderHWIncremented)
// 如果HW增加,尝试完成ProduceRequest延迟任务
tryCompleteDelayedRequests()
isNewLeader
}ReplicaManager#startup:定时15秒,扫描所有leader分区,判断isr收缩。
Scala
def startup(): Unit = {
// 每replica.lag.time.max.ms=30000/2=15秒跑一次,校验是否需要收缩isr
scheduler.schedule("isr-expiration",
maybeShrinkIsr _,
period = config.replicaLagTimeMaxMs / 2,
unit = TimeUnit.MILLISECONDS)
}五、Log关闭与恢复
broker数据以log维度刷盘,包括数据和索引。默认情况下kafka只写pagecache,由操作系统自行刷盘。可选择开启刷盘策略(下面这些配置都是Long.MAX_VALUE):
1)定时刷盘:后台每log.flush.scheduler.interval.ms 检测一次所有log是否需要刷盘,log刷盘间隔=flush.ms;
2)定量刷盘:写消息的时候,如果 累积待刷盘消息数量≥flush.messages,则触发同步刷盘;
LogManager#shutdown:如果broker正常shutdown,最终会触发所有数据刷盘,并创建kafka_cleanshutdown文件。
Scala
def shutdown(): Unit = {
// log列表
val logsInDir = localLogsByDir.getOrElse(dir.toString, Map()).values
// 所有log执行flush刷盘(未刷盘的segment数据和索引)
val jobsForDir = logsInDir.map { log =>
val runnable: Runnable = () => {
log.flush()
log.close()
}
runnable
}
// 提交到线程池执行log.flush
jobs(dir) = jobsForDir.map(pool.submit).toSeq
// 等待所有log完成flush
for ((dir, dirJobs) <- jobs) {
dirJobs.foreach(_.get)
// recovery-point-offset-checkpoint刷盘
checkpointRecoveryOffsetsAndCleanSnapshot(dir, localLogsByDir.getOrElse(dir.toString, Map()).values.toSeq)
// log-start-offset-checkpoint刷盘
// 只有log被清理过(手动或自动),才会记录logStartOffset的checkpoint
checkpointLogStartOffsetsInDir(dir)
// 创建.kafka_cleanshutdown文件,表示所有log数据都正常刷盘,log数据完整
CoreUtils.swallow(Files.createFile(new File(dir, Log.CleanShutdownFile).toPath), this)
}如果broker异常关闭,则无法保证log数据的完整性(比如一个批次消息未完整刷盘需要截断、数据刷盘了但是索引没刷盘),真实的LEO等位点信息也无法确定。
LogManager#loadLogs:broker在启动阶段,如果不存.kafka_cleanshutdown文件,则进入恢复状态。
Scala
val cleanShutdownFile = new File(dir, Log.CleanShutdownFile)
if (cleanShutdownFile.exists) {
info(s"Skipping recovery for all logs in $logDirAbsolutePath since clean shutdown file was found")
} else {
info(s"Attempting recovery for all logs in $logDirAbsolutePath since no clean shutdown file was found")
brokerState.newState(RecoveringFromUncleanShutdown)
}为了在broker重启时快速恢复数据完整性,使用recovery-point-offset-checkpoint记录每个分区的刷盘位置,避免重启时全量扫描所有segment。
LogManager#loadLogs:读取checkpoint并加载所有Log。
Scala
private def loadLogs(): Unit = {
// 读取recovery-point-offset-checkpoint
var recoveryPoints = Map[TopicPartition, Long]()
recoveryPoints = this.recoveryPointCheckpoints(dir).read
// 读取log-start-offset-checkpoint
var logStartOffsets = Map[TopicPartition, Long]()
logStartOffsets = this.logStartOffsetCheckpoints(dir).read
// 列举数据目录下所有的目录即为不同分区的log
val logsToLoad = Option(dir.listFiles)
.getOrElse(Array.empty).filter(_.isDirectory)
// 执行loadLog
val jobsForDir = logsToLoad.map { logDir =>
val runnable: Runnable = () => {
val log = loadLog(logDir, recoveryPoints, logStartOffsets)
}
runnable
}
jobs(cleanShutdownFile) = jobsForDir.map(pool.submit)
// 删除.kafka_cleanshutdown
cleanShutdownFile.delete()
}LogManager#loadLog:加载单个Log。
Scala
private def loadLog(logDir: File,
recoveryPoints: Map[TopicPartition, Long],
logStartOffsets: Map[TopicPartition, Long]): Log = {
val topicPartition = Log.parseTopicPartitionName(logDir)
val config = topicConfigs.getOrElse(topicPartition.topic, currentDefaultConfig)
// 获取该分区的recoveryPoint和logStartOffset
val logRecoveryPoint = recoveryPoints.getOrElse(topicPartition, 0L)
val logStartOffset = logStartOffsets.getOrElse(topicPartition, 0L)
// 创建log
val log = Log(
dir = logDir,
config = config,
logStartOffset = logStartOffset,
recoveryPoint = logRecoveryPoint,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,
time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel)
if (logDir.getName.endsWith(Log.DeleteDirSuffix)) {
// -delete结尾,是需要删除的,忽略
addLogToBeDeleted(log)
} else {
// ...
// 分区->log的映射关系
this.currentLogs.put(topicPartition, log)
}
log
}Log初始化:加载所有Segment,根据Segment恢复LEO。
根据LEO和LogStartOffset修正leaderEpoch和startOffset的关系。(以后再看)
Scala
class Log(@volatile private var _dir: File,
@volatile var config: LogConfig,
@volatile var logStartOffset: Long,
@volatile var recoveryPoint: Long,...) {
// LEO
private var nextOffsetMetadata: LogOffsetMetadata = _
// leaderEpoch -> 开始offset
var leaderEpochCache: Option[LeaderEpochFileCache]
locally {
Files.createDirectories(dir.toPath)
// 读取leader-epoch-checkpoint加载到内存
initializeLeaderEpochCache()
// 加载Segment,根据Segment实际情况,恢复LEO(LogEndOffset)
val nextOffset = loadSegments()
// LEO加载到内存
nextOffsetMetadata = LogOffsetMetadata(nextOffset,
activeSegment.baseOffset, activeSegment.size)
// 根据LEO,截断leaderEpoch->startOffset关系
leaderEpochCache.foreach(_.
truncateFromEnd(nextOffsetMetadata.messageOffset))
// LogStartOffset = max(checkpoint[partition],Segment的第一个offset)
updateLogStartOffset(math.max(logStartOffset, segments.firstEntry.getValue.baseOffset))
// 根据Log Start Offset,截断leaderEpoch->startOffset关系
leaderEpochCache.foreach(_.truncateFromStart(logStartOffset))
}
}Log#loadSegments:加载segment并恢复。
Scala
private def loadSegments(): Long = {
retryOnOffsetOverflow {
logSegments.foreach(_.close())
segments.clear()
// 加载segment文件信息到内存
loadSegmentFiles()
}
if (!dir.getAbsolutePath.endsWith(Log.DeleteDirSuffix)) {
val nextOffset = retryOnOffsetOverflow {
// 恢复log
recoverLog()
}
activeSegment.resizeIndexes(config.maxIndexSize)
nextOffset
}
}Log#loadSegmentFiles:Step1,循环Log目录下的所有文件,组装为LogSegment。
Scala
// segment起始offset(文件名) -> segment
private val segments: ConcurrentNavigableMap[Long, LogSegment]
def addSegment(segment: LogSegment): LogSegment =
this.segments.put(segment.baseOffset, segment)
private def loadSegmentFiles(): Unit = {
for (file <- dir.listFiles.sortBy(_.getName) if file.isFile) {
if (isIndexFile(file)) {
// 三种索引文件,校验数据文件.log存在,否则删除
val offset = offsetFromFile(file)
val logFile = Log.logFile(dir, offset)
if (!logFile.exists) {
Files.deleteIfExists(file.toPath)
}
} else if (isLogFile(file)) {
// 根据文件名获取起始offset
val baseOffset = offsetFromFile(file)
val timeIndexFileNewlyCreated = !Log.timeIndexFile(dir, baseOffset).exists()
// .log数据文件,封装为LogSegment
val segment = LogSegment.open(dir = dir,
baseOffset = baseOffset,
config,
time = time,
fileAlreadyExists = true)
// 加入segments这个map
addSegment(segment)
}
}
}
object LogSegment {
def open(...): LogSegment = {
new LogSegment(
// .log
FileRecords.open(Log.logFile(dir, baseOffset, fileSuffix), fileAlreadyExists, initFileSize, preallocate),
// 3个索引
LazyIndex.forOffset(Log.offsetIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),
LazyIndex.forTime(Log.timeIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),
new TransactionIndex(baseOffset, Log.transactionIndexFile(dir, baseOffset, fileSuffix)),
// 起始offset
baseOffset,...)
}
}Log#recoverLog:Step2,没有.kafka_cleanshutdown文件,根据recovery-point-offfset-checkpoint中记录的刷盘进度,找到所有未刷盘的segment,迭代这些segment找到真实的刷盘进度。
Scala
private def recoverLog(): Long = {
if (!hasCleanShutdownFile) {
// 没有.kafka_cleanshutdown文件,根据recoveryPoint找未刷盘的segment
val unflushed = logSegments(this.recoveryPoint, Long.MaxValue).iterator
var truncated = false
// 迭代所有未刷盘segment
while (unflushed.hasNext && !truncated) {
val segment = unflushed.next
val truncatedBytes =
try {
// 处理segment
recoverSegment(segment, leaderEpochCache)
} catch {
case _: InvalidOffsetException =>
val startOffset = segment.baseOffset
segment.truncateTo(startOffset)
}
// 如果当前segment数据不完整,这个segment之后的segment直接删除
if (truncatedBytes > 0) {
removeAndDeleteSegments(unflushed.toList, asyncDelete = true)
truncated = true
}
}
}
// ...
// 刷盘进度为LEO
recoveryPoint = activeSegment.readNextOffset
recoveryPoint
}
def logSegments(from: Long, to: Long): Iterable[LogSegment] = {
lock synchronized {
// segments的map的key是segment的起始offset(文件名),
// 找recoverPoint所在segment及其之后的segment
val view = Option(segments.floorKey(from)).map { floor =>
segments.subMap(floor, to)
}.getOrElse(segments.headMap(to))
view.values.asScala
}
}LogSegment#recover:Segment恢复需要迭代(FileRecords#batchIterator)读取所有批次消息,计算每个批次的crc校验和,并重建索引。如果遇到数据损坏,向后截断错误数据,结束当前Log的恢复。
如果删除了recovery-point-offset-checkpoint,这个恢复过程将相当耗时。
Scala
def recover(producerStateManager: ProducerStateManager,
leaderEpochCache: Option[LeaderEpochFileCache] = None): Int = {
// 清空索引
offsetIndex.reset()
timeIndex.reset()
txnIndex.reset()
var validBytes = 0
var lastIndexEntry = 0
maxTimestampSoFar = RecordBatch.NO_TIMESTAMP
try {
// 迭代segment里的每个批次buffer
for (batch <- log.batches.asScala) {
// crc校验批次数据完整
batch.ensureValid()
ensureOffsetInRange(batch.lastOffset)
if (batch.maxTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = batch.maxTimestamp
offsetOfMaxTimestampSoFar = batch.lastOffset
}
// 4k建立一次索引
if (validBytes - lastIndexEntry > indexIntervalBytes) {
offsetIndex.append(batch.lastOffset, validBytes)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
lastIndexEntry = validBytes
}
// 完整数据大小 += 本批次数据大小
validBytes += batch.sizeInBytes()
// ...
}
} catch {
// 批次数据异常或crc校验没过,结束批次迭代
case e@ (_: CorruptRecordException | _: InvalidRecordException) =>
warn()
}
// 截断大小 = .log文件大小 - 完整数据大小
val truncated = log.sizeInBytes - validBytes
// 截断.log和索引(索引要截断是因为这个segment可能不是最后一个segment)
log.truncateTo(validBytes)
offsetIndex.trimToValidSize()
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar, skipFullCheck = true)
timeIndex.trimToValidSize()
truncated
}总结
线程模型
broker有多种线程模型:默认情况、控制面与数据面分离、客户端与broker内部请求分离。
对于生产者发送消息,ProduceRequest都在一个num.io.threads=8的公共业务线程池里处理。
通讯层
在通讯层,一个客户端连接上只会同时处理一个请求,当一个请求处理完毕响应客户端后,才能读取通道上的下一个请求做处理。
请求:
响应:
反序列化
反序列化方面,buffer转Struct转ProduceRequest,最终批次模型同客户端,都是MemoryRecords,里面是个buffer。
从反序列化到最后落盘会修改buffer里的数据(比如baseOffset会从0修改为实际在broker侧该消息的offset),但是不会再分配任何多余buffer处理消息批次,MemoryRecords中的buffer就是最后落盘的字节。
生产消息请求处理
ProduceRequest处理上可以分为三步:写Log、处理HW、处理响应。
首先了解broker数据目录的组织形式。
Shell
tree -a
.
├── .kafka_cleanshutdown
├── .lock
├── Test1-0
│ ├── 00000000000000000000.index
│ ├── 00000000000000000000.log
│ ├── 00000000000000000000.timeindex
│ ├── 00000000000000001872.index
│ ├── 00000000000000001872.log
│ ├── 00000000000000001872.timeindex
│ └── leader-epoch-checkpoint
├── cleaner-offset-checkpoint
├── log-start-offset-checkpoint
├── meta.properties
├── recovery-point-offset-checkpoint
└── replication-offset-checkpoint1)数据目录下的唯一目录={Topic}-{PartitionId},如Test1-0,存储了每个分区的数据,称为Log。
Log数据由多个Segment 组成,如0000是第一个segment,1872是第二个segment,文件名是该segment的起始offset,如0000存储了offset=[0,1872)共1872条消息。
每个Segment由4个文件构成:
a)log:消息数据文件,追加写,大小超过segment.bytes=1G触发滚动;
b)index:offset索引文件,通过mmap读写,大小=segment.index.bytes=10M,key=相对segment起始offset的offset(4byte),value=消息在log的写入位置(4byte);
c)timeindex:时间索引文件,通过mmap读写,大小=segment.index.bytes=10M,key=时间戳(8byte),value=相对segment起始offset的offset(4byte);
d)txnindex:中断事务索引文件;
leader-epoch-checkpoint:对于每个分区,记录每个leader任期的起始offset。
2)meta.properties:数据和broker+cluster的关联关系。
3)checkpoint:记录每个分区不同业务的offset进度。
recovery-point-offset-checkpoint:offset=消息刷盘进度,log.flush.offset.checkpoint.interval.ms=60秒刷盘一次。
replication-offset-checkpoint:offset=高水位HW,replica.high.watermark.checkpoint.interval.ms=5秒刷盘一次。
log-start-offset-checkpoint:offset=Log Start Offset,log.flush.start.offset.checkpoint.interval.ms=60秒刷盘一次。
cleaner-offset-checkpoint :offset=压缩topic分区的处理进度。
4)kafka_cleanshutdown:broker正常关闭标记文件,如果不存在,代表kafka进程异常关闭。
5)lock:文件锁,一个数据目录同时只能有一个进程访问。
Step1,循环所有分区写Log:
1)获取LeaderAndIsr读锁,校验自己是leader,如果分区副本数小于min.insync.replicas(默认1)则拒绝写入;
2)获取Log锁,分区不能并发写;
3)批次的起始offset=当前LEO;
4)处理Segment滚动:如果log数据文件满了 或 索引文件满了 或 超过segment.ms=7天没写入,创建新Segment,起始offset=当前LEO;
5)写Segment,只写pagecache,将MemoryRecords追加写log,mmap写offset和时间索引,每log.index.interval.bytes=4k消息数据生成一条offset和时间索引**;**
6)更新LEO=下次写入的offset=当前写入offset+1;
Step2,尝试增加HW高水位=min(满足条件的副本的LEO),满足以下任一条件的副本参与计算:
1)ISR内的副本;
2)上次与leader的LEO的同步时间在replica.lag.time.max.ms=30s内的副本;
增加HW的场景:只有leader一个副本、ISR收缩、follower追上leader。
Step3,处理响应。
如果acks=1,直接响应;如果acks=-1,需要等到ProduceRequest中所有分区的HW≥本次写入批次的最后一个offset+1(当时的LEO) ,才能响应客户端。HW满足条件后,判断分区副本数≥min.insync.replicas响应成功,否则响应NotEnoughReplicasAfterAppendException。
Log恢复
默认情况下,broker写log(数据和索引)只会写pagecache,由操作系统自动刷盘。
可选择开启刷盘策略(下面这些配置都是Long.MAX_VALUE):
1)定时刷盘:后台每log.flush.scheduler.interval.ms 检测一次所有log是否需要刷盘,log刷盘间隔=flush.ms;
2)定量刷盘:写消息的时候,如果 累积待刷盘消息数量≥flush.messages,则触发同步刷盘;
如果broker正常停机,会将所有数据刷盘,并在数据目录下保存.kafka_cleanshutdown文件。
当broker重启后,如果判断.kafka_cleanshutdown不存在,则需要校验数据完整性。
如果遍历所有Log的Segment将非常耗时,所以kafka将所有分区的刷盘进度保存在recovery-point-offset-checkpoint中(内存中为每个Log的recoverPoint)。
恢复阶段,对于每个分区Log,从checkpoint记录的recoverPoint刷盘进度offset开始,找到相关的segment。从前往后遍历所有消息批次,一边遍历还需要一边重新建立offset和时间索引,直到找到损坏的数据(比如少批次头、crc校验不通过等)向后截断,最终segment的结束offset+1成为LEO。