大家好,我是 方圆 。分布式一致性(distributed consensus)是分布式系统中最基本的问题,它用来保证一个分布式系统的 可靠性以及容灾能力。简单来说:就是如何在多个服务器间对某一个值达成一致, 并且当达成一致之后,无论之后这些机器间发生怎样的故障,这个值能保持不变。
在文章开始前,我们先来看一下:如果在分布式系统中没有对一致性的保证会发生什么问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,"正常情况下" server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:
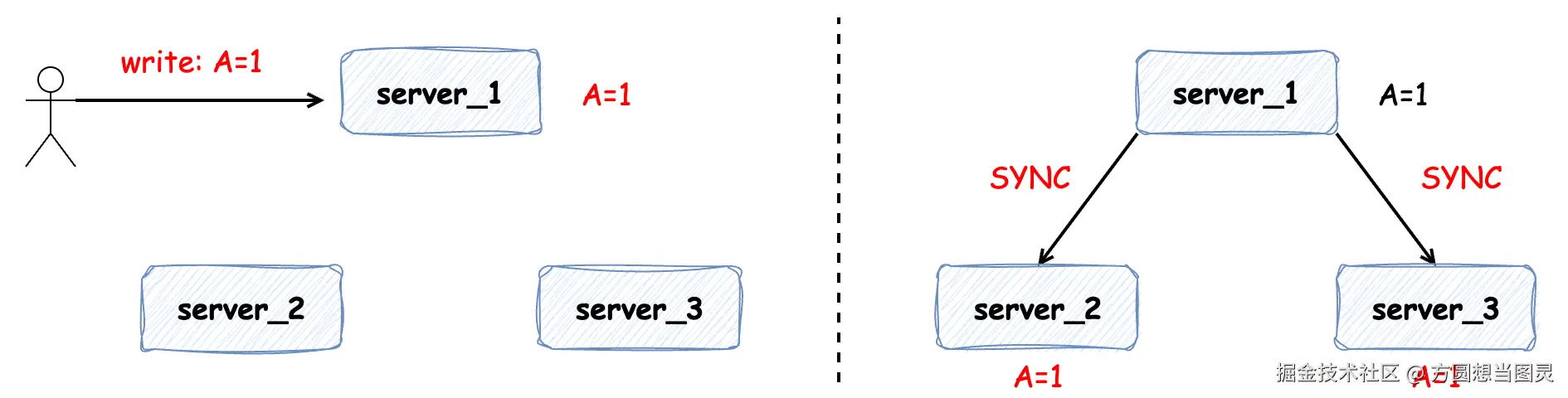
但是如果在数据变更时发生网络问题(延迟、断连和丢包等)便会出现以下情况:比如有两个写操作同时发生在 server_1 或 server_3 上,即便两个写操作有先后顺序,但可能由于网络延时导致各个服务中数据的不一致:
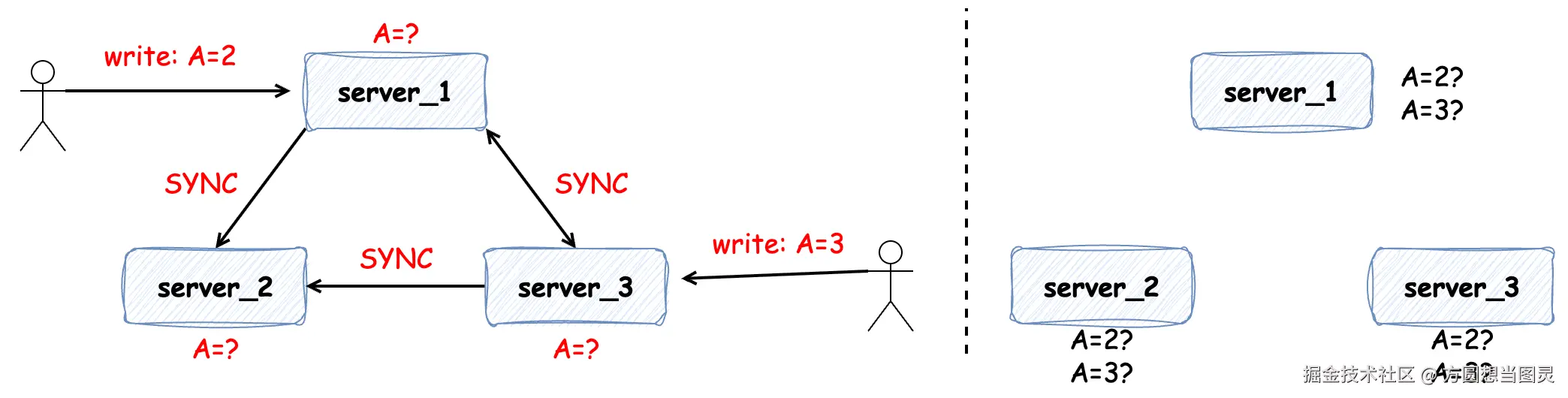
同样地情况,如果在 server_1 上发生三次写操作,在数据同步的过程中因为网络延时或网络丢包也可能会导致数据的不一致:
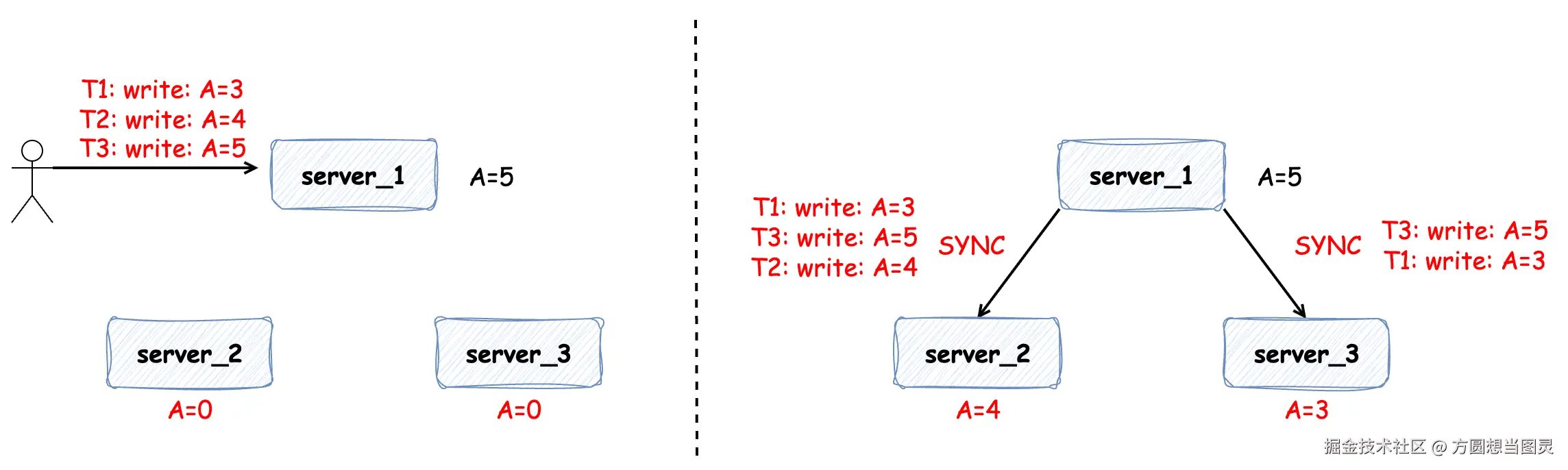
那么为了避免以上这些集群间数据不一致的问题,便需要分布式共识算法来协调一致性,本篇文章我们便对 Raft 算法进行介绍。
理解 Raft 算法
了解和学习过 Zookeeper 的同学可能听说过 Zab 算法,它用来保证 Zookeeper 中数据的最终一致性。Raft 也是一种分布式共识算法,它易于理解和实现,用于保证数据的 强一致性。
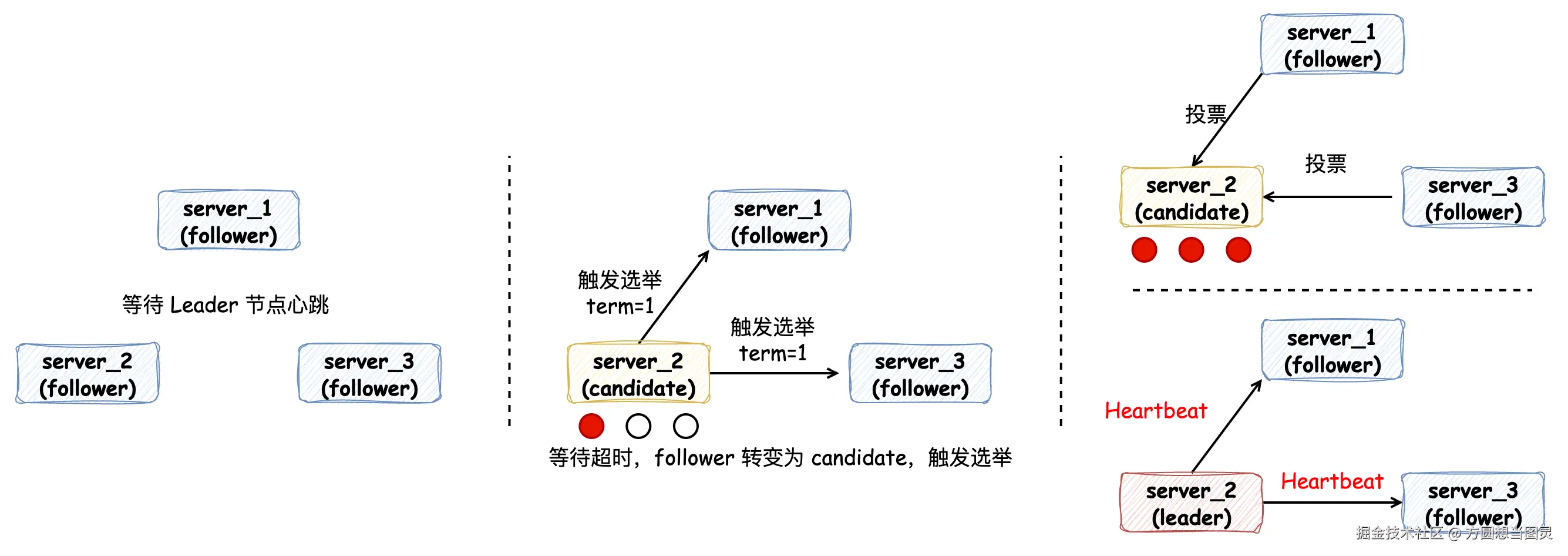
在遵循 Raft 算法的集群中,节点会有 3 种不同的角色。当集群在初始化时,每个节点的角色都是 Follower 跟随者,它们会等待来自 Leader 节点的心跳。因为此时并没有 Leader 节点,所以会等待心跳超时。等待超时的 Follower 节点会将角色转变为 Candidate 候选者,触发一次选举,触发选举时会标记 Term 任期变量,并将自己的一票投给自己,通知其他 Follower 节点发起投票。经过投票后,收到超过半数节点票数的 Candidate 节点会成为 Leader 领导者节点,其他节点为 Follower 跟随者节点,Leader 节点会不断地发送心跳给 Follower 节点来维持领导地位:
写变更请求
当发生写变更请求时,由 Leader 节点负责处理,即使是请求到 Follower 节点,也需要转发给 Leader 节点处理。当 Leader 节点接收到写请求时,它并不立即对这个请求进行处理,而是先将请求信息 按顺序追加到日志文件中(WAL: write-ahead-log),如图中标记的 log_index 表示追加到的最新一条日志的序号:
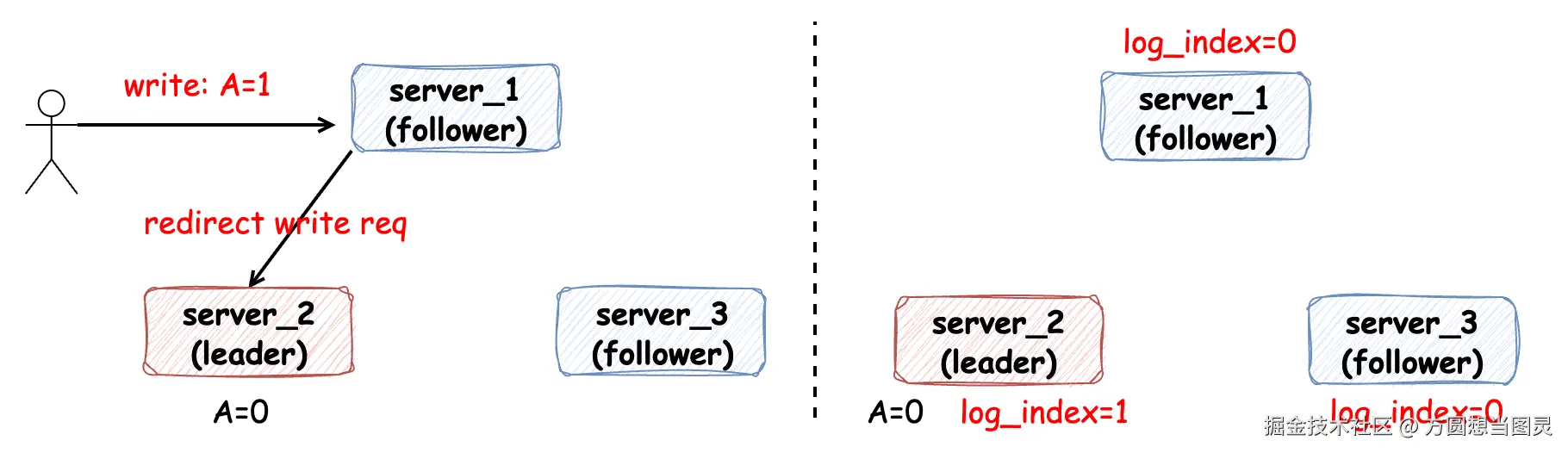
随后,Leader 节点通过 RPC 请求将日志同步到各个 Follower 节点,当超过半数节点成功将日志记录时,便认为同步成功,这时 Leader 节点会更新最新同步日志的索引 commit_index 为 1,并通过心跳下发给各个 Follower 节点:

在这个过程中可以发现 Follower 节点只是听从并响应 Leader 节点,没有任何主动性。现在已经完成了日志在集群间的同步,但是请求对变量 A 的修改还没有被应用(Apply)。Apply 是在 Raft 算法中经常出现的一个名词,Raft 算法在多数相关文章中的经常会看到 "将已提交的日志条目应用到状态机" 等类似的表述。其实 "状态机" 理解起来并不复杂,它所表达的含义其实是 业务逻辑的载体 或 业务逻辑的执行者,它的职责包括:
- 接收来自日志文件中有序的命令
- 执行具体的业务逻辑,在本次写请求中,业务逻辑指的便是变更 A 的值
- 变更应用程序的状态
- 返回执行结果
更加通俗的讲就是 让请求生效。将已经提交的日志应用到状态机是比较简单且自主的过程,各个服务实例会记录 apply_index 来标记应用索引,当 apply_index 小于 commit_index 时,那么证明日志文件中记录的请求信息还有部分没生效,所以需要按顺序应用,直到 apply_index = commit_index:
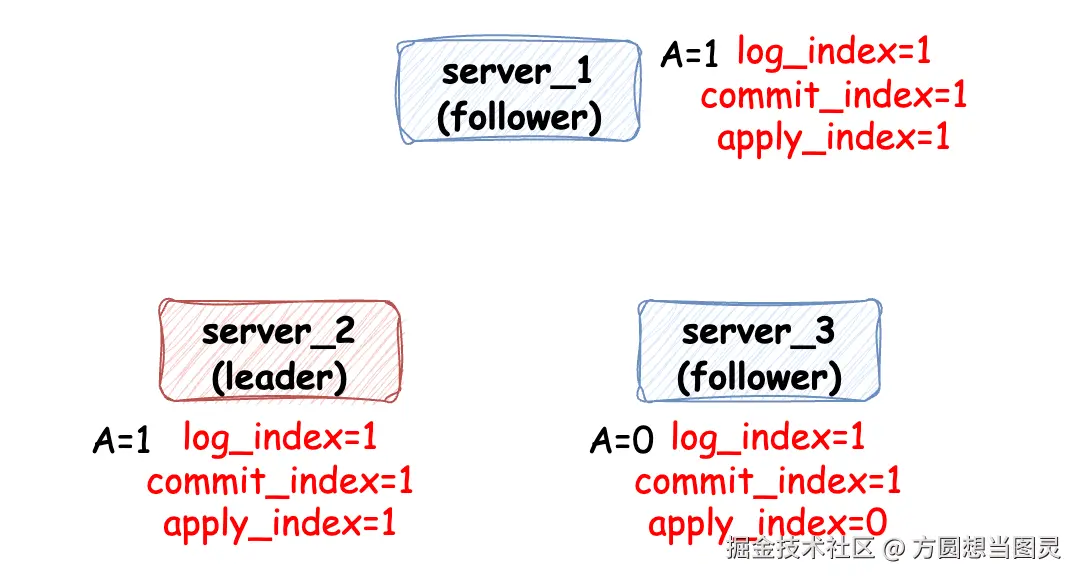
在这个过程中,我一直在强调 "按顺序",不论是日志的追加还是日志的被应用都是按顺序来的,因此才能保证数据的一致性。
读请求
Raft 集群处理读请求会保证读请求的线性一致性,所谓线性一致性读就是在 t1 的时间写入了一个值,那么在 t1 之后,读一定能读到这个值,不可能读到 t1 之前的值,在 Raft 算法中实现线性一致性读有以下两种方式:
ReadIndex Read
在这种方式下,当 Leader 节点处理读请求时:
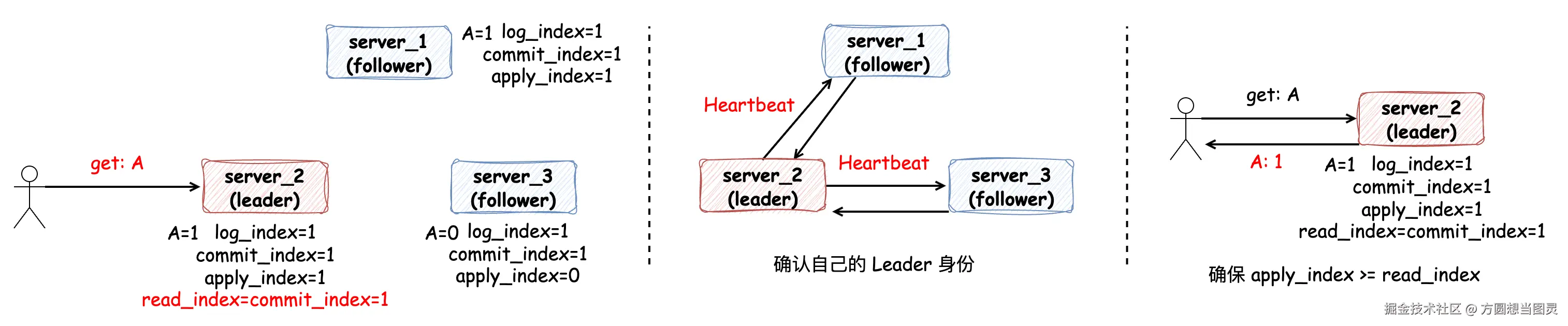
- 首先将 commit_index 记录到本地的 read_index 变量里
- 向其他节点发送一次 Heartbeat,确认自己仍然是 Leader 角色
- Leader 节点等待自己的状态机执行,直到 apply_index 超过了 read_index,这样就能够安全的提供线性一致性读了
- Leader 执行 read 请求,将结果返回
在第三步中,保证 apply_index >= read_index 是为了保证所有小于等于 read_index 的请求都已经生效。
如果是 Follower 节点处理读请求也和以上过程类似,当 Follower 节点收到读请求后,直接给 Leader 发送一个获取此时 read_index 的请求,Leader 节点仍然处理以上流程然后将 read_index 返回,此时 Follower 节点等到当前的状态机 apply_index 超过 read_index 后,就可以返回结果了。
Lease Read
因为 ReadIndex Read 需要发送一次 Heartbeat 来确认 Leader 身份,存在 RPC 请求的开销,为了进一步优化,便可以采用租约(Lease)读。租约其实指的是 Leader 节点身份的过期约定时间,所以这种读请求只针对 Leader 节点,Follower 节点没有租约的概念,它通过以下公式计算:
lease_end = current_time() + election_timeout / clock_drift_bound
其中 election_timeout 为选举的超时时间,clock_drift_bound 表示时钟漂移,指的是在分布式系统中,两个或多个节点上的时钟以不同的速率运行,导致它们之间的时间差随时间不断累积和变化(也就是分布式系统中不稳定的时钟问题)。
举个简单的例子,假如选举过期时间是 10s,时钟漂移为 1.1,那么租约过期时间为:lease_end = current_time() + 10s / 1.1 ≈ current_time() + 9s,如果在处理读请求时,在租约时间内,则无需发送 Heartbeat 来明确 Leader 身份,直接等待 apply_index >= commit_index 后返回请求结果。
脑裂问题
当集群中发生网络通讯问题时,读、写请求只能在超过半数节点的集群内生效:
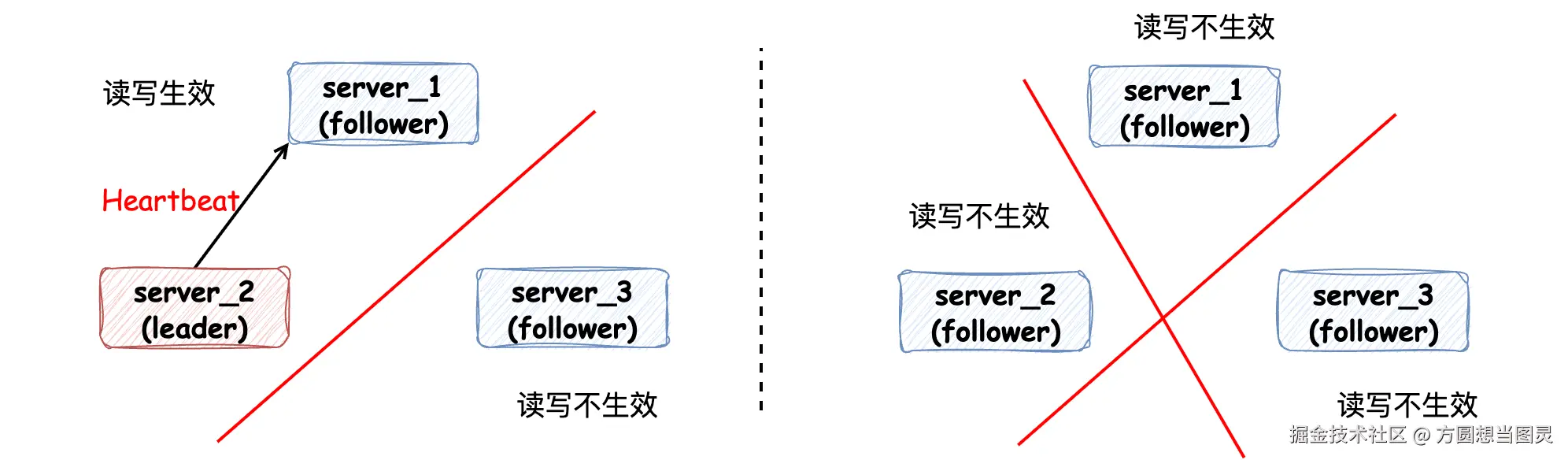
以此来解决脑裂问题,当网络问题恢复时,Follower 节点能通过 Leader 节点的日志同步重新追回期间错过的数据。此外,一般采用 Raft 算法的集群在部署的时都是 "奇数个节点",而不是偶数个节点,这其实是数学的体现,性价比更高:
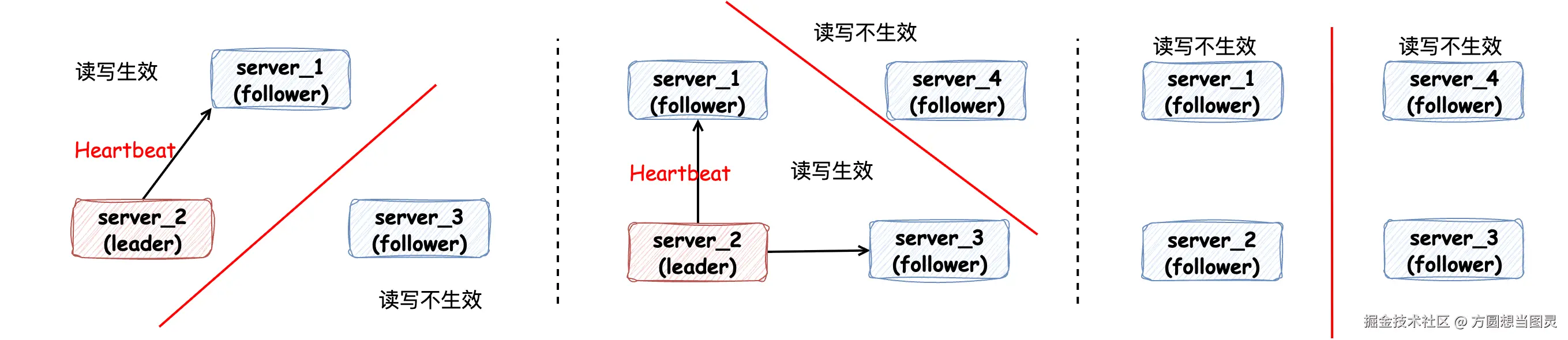
如上图所示,虽然部署 4 个节点多出一个节点,但是和 3 节点集群相比,容错能力是相同的:只能容忍 1 个节点故障。在容错能力没有被提高的情况下又花费了更多的服务器成本和运维管理成本。
Nacos 对 Raft 算法的应用
Nacos Server 在集群模式采用内嵌数据库 Derby 部署运行时,采用了 Raft 算法保证了集群的强一致性,Raft 算法的实现它使用的是 开源项目 JRaft。下面的内容我们根据源码来分析:当在 Nacos 控制台对配置进行修改时,Nacos 是如何借助 JRaft 保证数据一致性的。
如果大家感兴趣,可以去 Github-Nacos 将源码 clone 下来,Debug 调试整个流程。
配置修改流程源码分析
ConsoleConfigController#publishConfig 方法是在 Nacos 控制台修改配置的入口,承接配置变更的 POST 请求:
java
@NacosApi
@RestController
@RequestMapping("/v3/console/cs/config")
@ExtractorManager.Extractor(httpExtractor = ConfigDefaultHttpParamExtractor.class)
public class ConsoleConfigController {
private final ConfigProxy configProxy;
public ConsoleConfigController(ConfigProxy configProxy) {
this.configProxy = configProxy;
}
@PostMapping()
@Secured(action = ActionTypes.WRITE, signType = SignType.CONFIG, apiType = ApiType.CONSOLE_API)
public Result<Boolean> publishConfig(HttpServletRequest request, ConfigFormV3 configForm) throws NacosException {
// ...
return Result.success(configProxy.publishConfig(configForm, configRequestInfo));
}
}在这个方法中 configProxy 对象使用到了动态代理模式,不过这个动态代理与 Raft 算法流程无关就不多介绍了。
Nacos Server 启动时配置了内嵌(Embedded)数据库 Derby,那么请求将会被 EmbeddedConfigInfoPersistServiceImpl#updateConfigInfoCas 方法处理,在这个方法中有一个私有方法 updateConfigInfoAtomicCas 特别关键,它主要在这里封装 SQL 的参数,并生成一条 SQL 并不立即执行,而是封装到上下文 EmbeddedStorageContextHolder 中:
java
@Service("embeddedConfigInfoPersistServiceImpl")
public class EmbeddedConfigInfoPersistServiceImpl implements ConfigInfoPersistService {
private ConfigOperateResult updateConfigInfoAtomicCas(final ConfigInfo configInfo, final String srcIp,
final String srcUser, Map<String, Object> configAdvanceInfo) {
// 处理 SQL 的入参
MapperContext context = new MapperContext();
context.putUpdateParameter(FieldConstant.CONTENT, configInfo.getContent());
// ...
// 生成 SQL 而不执行(ConfigInfoMapper#updateConfigInfoAtomicCas 在接口中定义的 default 方法)
MapperResult mapperResult = configInfoMapper.updateConfigInfoAtomicCas(context);
EmbeddedStorageContextHolder.addSqlContext(Boolean.TRUE, mapperResult.getSql(),
mapperResult.getParamList().toArray());
return getConfigInfoOperateResult(configInfo.getDataId(), configInfo.getGroup(), tenantTmp);
}
}
public interface ConfigInfoMapper extends Mapper {
default MapperResult updateConfigInfoAtomicCas(MapperContext context) {
List<Object> paramList = new ArrayList<>();
// 封装 set 中的参数
paramList.add(context.getUpdateParameter(FieldConstant.CONTENT));
// ...
// 封装 where 中的参数
paramList.add(context.getWhereParameter(FieldConstant.MD5));
// ...
String sql = "UPDATE config_info SET " + "content=?, md5=?, src_ip=?, src_user=?, gmt_modified="
+ getFunction("NOW()")
+ ", app_name=?, c_desc=?, c_use=?, effect=?, type=?, c_schema=?, encrypted_data_key=? "
+ "WHERE data_id=? AND group_id=? AND tenant_id=? AND (md5=? OR md5 IS NULL OR md5='')";
return new MapperResult(sql, paramList);
}
}在这里有两个点值得注意:
- 生成 Update SQL 而不执行,却放在了上下文
EmbeddedStorageContextHolder中,它是一个ThreadLocal对象 - 生成的 SQL 使用 CAS 的策略,在 WHERE 条件中它会将前端控制台配置的 MD5 值作为条件传入,防止并发修改配置时的脏写问题
现在既然已经将变更 Derby 数据库 Update SQL 保存在了上下文中,接下来就是看它什么时候被执行了,它会继续执行到 DistributedDatabaseOperateImpl#update 方法:
java
public class DistributedDatabaseOperateImpl extends RequestProcessor4CP implements BaseDatabaseOperate {
private CPProtocol protocol;
@Override
public Boolean update(List<ModifyRequest> sqlContext, BiConsumer<Boolean, Throwable> consumer) {
try {
// 省略封装请求参数 Request 的逻辑
WriteRequest request;
if (Objects.isNull(consumer)) {
// 重要:raft 协议 write 开始执行,同步阻塞调用
Response response = this.protocol.write(request);
if (response.getSuccess()) {
return true;
}
LOGGER.error("execute sql modify operation failed : {}", response.getErrMsg());
return false;
} else {
// ...
}
return true;
} catch (TimeoutException e) {
LOGGER.error("An timeout exception occurred during the update operation");
throw new NacosRuntimeException(NacosException.SERVER_ERROR, e.toString());
} catch (Throwable e) {
LOGGER.error("An exception occurred during the update operation : {}", e);
throw new NacosRuntimeException(NacosException.SERVER_ERROR, e.toString());
}
}
}其中 Response response = this.protocol.write(request); 逻辑为执行 Raft 算法的写流程:
java
public class JRaftProtocol extends AbstractConsistencyProtocol<RaftConfig, RequestProcessor4CP>
implements CPProtocol<RaftConfig, RequestProcessor4CP> {
@Override
public Response write(WriteRequest request) throws Exception {
// 依靠 CompletableFuture 实现阻塞同步调用
CompletableFuture<Response> future = writeAsync(request);
return future.get(10_000L, TimeUnit.MILLISECONDS);
}
@Override
public CompletableFuture<Response> writeAsync(WriteRequest request) {
return raftServer.commit(request.getGroup(), request, new CompletableFuture<>());
}
}在这段逻辑中依靠 CompletableFuture 实现了同步阻塞的写调用。JRaftServer#commit 方法是处理 Raft 算法中写请求的流程:
java
public class JRaftServer {
/**
* [raft] 处理写请求,所有写操作必须通过 Leader 节点处理
*/
public CompletableFuture<Response> commit(final String group, final Message data,
final CompletableFuture<Response> future) {
LoggerUtils.printIfDebugEnabled(Loggers.RAFT, "data requested this time : {}", data);
final RaftGroupTuple tuple = findTupleByGroup(group);
if (tuple == null) {
future.completeExceptionally(new IllegalArgumentException("No corresponding Raft Group found : " + group));
return future;
}
FailoverClosureImpl closure = new FailoverClosureImpl(future);
final Node node = tuple.node;
if (node.isLeader()) {
// 当前节点是 Leader,直接应用写操作到状态机
applyOperation(node, data, closure);
} else {
// 当前节点不是 Leader,将请求转发给 Leader 处理
invokeToLeader(group, data, rpcRequestTimeoutMs, closure);
}
return future;
}
}如果是 Leader 节点的话,直接操作日志写入,在这里的逻辑都是与 JRaft 框架相关了,不过我们只需要关注与 Raft 算法有关的流程,注意注释信息:
java
public class JRaftServer {
public void applyOperation(Node node, Message data, FailoverClosure closure) {
// Task 是用户使用 jraft 最核心的类之一,用于向一个 raft 集群提交一个任务,这个任务提交到 leader,并复制到其他 follower 节点
// 通俗的理解为让 Leader 节点记录 log 日志,并同步到其他 Follower 节点
final Task task = new Task();
// done 表示任务的回调方法,在任务完成的时候,即 apply 的时候,通知此回调对象,无论成功还是失败。
task.setDone(new NacosClosure(data, status -> {
NacosClosure.NacosStatus nacosStatus = (NacosClosure.NacosStatus) status;
closure.setThrowable(nacosStatus.getThrowable());
closure.setResponse(nacosStatus.getResponse());
closure.run(nacosStatus);
}));
// add request type field at the head of task data.
byte[] requestTypeFieldBytes = new byte[2];
requestTypeFieldBytes[0] = ProtoMessageUtil.REQUEST_TYPE_FIELD_TAG;
if (data instanceof ReadRequest) {
requestTypeFieldBytes[1] = ProtoMessageUtil.REQUEST_TYPE_READ;
} else {
requestTypeFieldBytes[1] = ProtoMessageUtil.REQUEST_TYPE_WRITE;
}
// data 任务的数据,用户应当将要复制的业务数据通过一定序列化方式(比如 java/hessian2) 序列化成一个 ByteBuffer,放到 task 里
byte[] dataBytes = data.toByteArray();
task.setData((ByteBuffer) ByteBuffer.allocate(requestTypeFieldBytes.length + dataBytes.length)
.put(requestTypeFieldBytes).put(dataBytes).position(0));
// 使用 node 提交任务,node 可以为是 Raft 集群的 Leader 节点,操作 apply 方法之后表示将日志记录下来并给其他 Follower 节点同步
node.apply(task);
}
}当在 Raft 集群中有超过半数节点已经将本次任务的日志持久化后,它会自动调用 StateMachineAdapter#onApply 方法,表示将日志应用到状态机,即使写请求生效:
java
class NacosStateMachine extends StateMachineAdapter {
/**
* 最核心的方法,应用任务列表应用到状态机,任务将按照提交顺序应用。
* 请注意,当这个方法返回的时候,我们就认为这一批任务都已经成功应用到状态机上,如果你没有完全应用(比如错误、异常),
* 将会被当做一个 critical 级别的错误,报告给状态机的 StateMachineAdapter#onError 方法,错误类型为 ERROR_TYPE_STATE_MACHINE
*/
@Override
public void onApply(Iterator iter) {
int index = 0;
int applied = 0;
Message message;
NacosClosure closure = null;
try {
// 遍历处理本次应用的任务(日志)
while (iter.hasNext()) {
// 结果通过 Status 告知,Status#isOk() 告诉你成功还是失败
Status status = Status.OK();
try {
// 如果 task 没有设置 closure,那么 done 会是 null,
// 另外在 follower 节点上,done 也是 null,因为 done 不会被复制到除了 leader 节点之外的其他 raft 节点
if (iter.done() != null) {
// 获取回调函数
closure = (NacosClosure) iter.done();
// 从 Leader 节点的日志条目中获取消息
message = closure.getMessage();
} else {
// 从 Follower 节点复制的日志条目中解析消息
final ByteBuffer data = iter.getData();
message = ProtoMessageUtil.parse(data.array());
if (message instanceof ReadRequest) {
// Follower 节点忽略读请求,只处理写请求
applied++;
index++;
iter.next();
continue;
}
}
LoggerUtils.printIfDebugEnabled(Loggers.RAFT, "receive log : {}", message);
// 应用写请求到业务状态机,实现数据的持久化存储
if (message instanceof WriteRequest) {
// 使 Update SQL 执行并生效,在 Response 中返回执行结果
Response response = processor.onApply((WriteRequest) message);
// 对结果的后置处理
postProcessor(response, closure);
}
// 处理读请求(仅在 Leader 节点)
if (message instanceof ReadRequest) {
Response response = processor.onRequest((ReadRequest) message);
postProcessor(response, closure);
}
} catch (Throwable e) {
index++;
status.setError(RaftError.UNKNOWN, e.toString());
Optional.ofNullable(closure).ifPresent(closure1 -> closure1.setThrowable(e));
throw e;
} finally {
Optional.ofNullable(closure).ifPresent(closure1 -> closure1.run(status));
}
applied++;
index++;
iter.next();
}
} catch (Throwable t) {
// 状态机应用失败时进行回滚,保证数据一致性
Loggers.RAFT.error("processor : {}, stateMachine meet critical error: {}.", processor, t);
iter.setErrorAndRollback(index - applied,
new Status(RaftError.ESTATEMACHINE, "StateMachine meet critical error: %s.",
ExceptionUtil.getStackTrace(t)));
}
}
}因为将任务应用到状态机时会在 Leader 和 Follower 节点都执行,所以以上逻辑会包含针对 Leader 节点和 Follower 节点的逻辑,它会在 Response response = processor.onApply((WriteRequest) message); 逻辑中完成 Update SQL 的执行变更配置信息,通过 Response 对象来返回执行成功还是执行失败。postProcessor 方法会执行到回调函数,最终回调的逻辑如下:
java
public class FailoverClosureImpl implements FailoverClosure {
// ...
private final CompletableFuture<Response> future;
@Override
public void run(Status status) {
// 调用 CompletableFuture#complete 方法标记任务完成,同步阻塞调用恢复,并返回结果值
if (status.isOk()) {
future.complete(data);
return;
}
final Throwable throwable = this.throwable;
future.completeExceptionally(Objects.nonNull(throwable) ? new ConsistencyException(throwable.getMessage())
: new ConsistencyException("operation failure"));
}
}其中 future 字段为在执行 Raft 的写请求时保证同步阻塞调用的 CompletableFuture,如果执行成功调用 CompletableFuture#complete 方法便能让停止阻塞并返回结果,以上便是在 Nacos 集群中执行写请求的流程。
配置查询流程源码分析
在 Nacos 集群模式下使用内嵌数据库时会遵循 Raft 算法,如果要查询配置信息时它采用的是 ReadIndex Read 实现线性一致性读,我们直接分析与 Raft 相关的源码部分:
java
public class JRaftServer {
/**
* [raft] 处理读请求,使用 ReadIndex 机制保证线性一致性读
*/
CompletableFuture<Response> get(final ReadRequest request) {
final String group = request.getGroup();
CompletableFuture<Response> future = new CompletableFuture<>();
final RaftGroupTuple tuple = findTupleByGroup(group);
if (Objects.isNull(tuple)) {
future.completeExceptionally(new NoSuchRaftGroupException(group));
return future;
}
final Node node = tuple.node;
final RequestProcessor processor = tuple.processor;
try {
// 使用 ReadIndex Read 机制确保读取到的数据是最新的已提交数据
// 其中 requestContext (第一个入参)提供给用户作为请求的附加上下文,可以在 closure 里再次拿到继续处理
node.readIndex(BytesUtil.EMPTY_BYTES, new ReadIndexClosure() {
@Override
public void run(Status status, long index, byte[] reqCtx) {
// ReadIndex 成功,传入的 closure 将被调用,可以安全地从本地状态机读取数据
if (status.isOk()) {
try {
Response response = processor.onRequest(request);
future.complete(response);
} catch (Throwable t) {
MetricsMonitor.raftReadIndexFailed();
future.completeExceptionally(new ConsistencyException(
"The conformance protocol is temporarily unavailable for reading", t));
}
return;
}
MetricsMonitor.raftReadIndexFailed();
Loggers.RAFT.error("ReadIndex has error : {}, go to Leader read.", status.getErrorMsg());
MetricsMonitor.raftReadFromLeader();
// ReadIndex 失败,降级到 Leader 读取保证一致性
readFromLeader(request, future);
}
});
return future;
} catch (Throwable e) {
// ReadIndex 异常,直接从 Leader 读取
MetricsMonitor.raftReadFromLeader();
Loggers.RAFT.warn("Raft linear read failed, go to Leader read logic : {}", e.toString());
// run raft read
readFromLeader(request, future);
return future;
}
}
// raft log process
public void readFromLeader(final ReadRequest request, final CompletableFuture<Response> future) {
commit(request.getGroup(), request, future);
}
}这部分源码比较简单,因为 JRaft 框架将 ReadIndex Read 的实现封装起来了,与我们在上文中讨论的原理一致,开放出了 readIndex 方法来直接复用,注意如果在 ReadIndex 时失败,会走 Raft Log 流程来处理写请求,这个开销就相对来说比较大了。