Java函数式编程之【流(Stream)性能优化】
- 一、流(Stream)性能优化的预备知识
- 二、流(Stream)的性能优化策略
-
- (一)选择合适的Stream(流)类型
-
- 1,优先使用基本数据类型流(避免装箱/拆箱开销)
- [2,正确选择 顺序流(stream) 或 并行流(parallelStream)](#2,正确选择 顺序流(stream) 或 并行流(parallelStream))
- (二)中间操作的优化
- (三)终端操作的优化
- (四)正确使用并行流(parallelStream)
- 三、总结:流(Stream)性能优化的工作流程
一、流(Stream)性能优化的预备知识
我们先来详细探讨一下基于 Java Stream API 的函数式编程时性能调优相关的一些基础知识。
(一)并行与并发的区别
在Java函数式编程中编写并行程序很容易,要优化Java Stream程序的性能首先要搞清楚并行和并发的概念。
并发 (Concurrency):多个任务在同一时间段内执行,但不一定是同时执行。例如:可在单核CPU上并发运行多个线程。其执行方式是通过时间片轮转,进行任务切换实现。
在单核CPU上的并发执行,逻辑上是"同时"执行,实质是串行轮流执行的。
并行 (Parallelism):多个任务同时执行,但需要有多核或多处理器硬件支持。例如:多核CPU同时处理多个不同任务。
(二)Stream操作特性分类
我们先来了解一下Stream操作分类,因为弄清Stream操作分类对大数据的高效迭代处理的性能优化有很大帮助。
中间操作和终止操作是Stream API中的关键概念。中间操作又可以细分为无状态(Stateless)操作和有状态(Stateful)操作;终结操作又可细分为短路(Short-circuiting)操作和非短路(Unshort-circuiting)操作。
- 中间操作:又称为装饰操作,它的输入是一个Stream,操作后返回一个新的Stream。
中间操作只对操作进行了声明,它会把Stream从一种流(Stream)转换为另一种流,中间操作都是惰性的,它们不会立即执行。例如,filter(), map() 和 sorted() 等方法都属于中间操作,它们会返回一个新的Stream实例。中间操作可以链接在一起,形成一个链式调用,成为Stream处理管道的组成部分。
无状态(Stateless)操作和有状态(Stateful)操作:
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。
1,常见无状态(Stateless)的中间操作有:filter() 、map()、 flatMap()、 peek()
2,常见有状态(Stateful)的中间操作有:distinct() 、sorted()、 limit() 、skip()
- 终止操作:又称为终端操作,终止操作将触发了整个流(Stream)的计算过程,得到操作结果。
终止操作则是主动求值操作。终止操作会触发整个Stream处理管道的执行。例如,collect(), forEach(), reduce() 等方法都是终止操作。
当终止操作被调用时,所有的中间操作将按序执行,最终得到操作结果。
短路(Short-circuiting)操作和非短路(Unshort-circuiting)操作:
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。
短路(Short-circuiting): anyMatch()、 allMatch()、 findFirst()、 findAny()、 noneMatch()
非短路(Unshort-circuiting)操作:forEachOrdered()、toArray()、reduce()、collect()、max()、min()、count()
(三)Stream流管道的相关知识
函数式编程的一个流管道(Stream pipeline),包括Stream的创建(由数据源创建Stream)、0个或n个Stream的中间操作和一个Stream的终止操作。
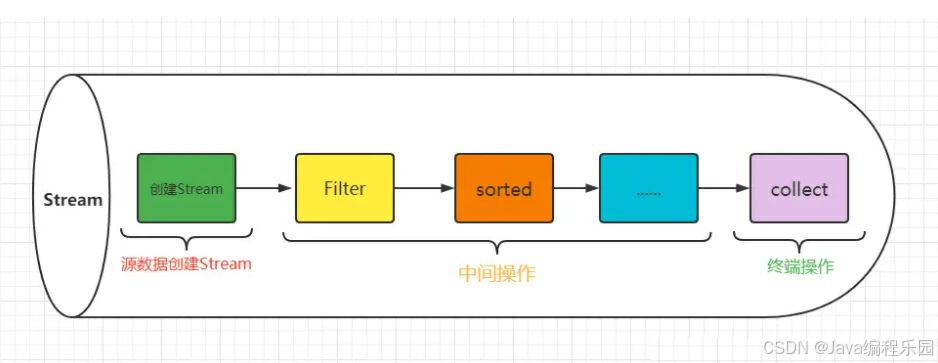
如果不了解 流(Stream) 函数式编程的内部机制,就写不错高性能的程序。只有了解了流管道(Stream pipeline)的执行过程,我们才能更好地优化Stream的性能。
我们先来梳理一下 Stream API 是由哪些主要接口和类组合而成的呢?BaseStream 和 Stream 是最顶端的接口类。
- BaseStream接口主要定义了流的基本方法,例如,iterator()、spliterator()、isParallel()等;
- Stream接口则定义了一些流的常用操作方法,例如,filter()、map()、mapToLong()、flatMap()和collect()等。
- ReferencePipeline是一个抽象类,他通过定义内部类组装了各种流的操作。它定义了Head、StatelessOp、StatefulOp三个内部类,实现了BaseStream与Stream的接口,继承了它们的方法。
- Sink接口则定义了每个Stream操作之间关系的协议,它包含begin()、end()、cancellationRequested()、accpet()四个方法。ReferencePipeline最终会将整个Stream流操作组装成一个调用链,而这条调用链上的各个Stream操作的上下关系就是通过Sink接口协议来定义实现的。
Stream操作的链接调用
一个流管道(Stream pipeline)可由Stream的各种操作组合而成,并最终由终止操作完成数据处理。
在JDK中每次的中间操作会用阶段(Stage)命名。
流管道的链接调用结构通常是由ReferencePipeline类实现的,前文已介绍过ReferencePipeline包含了Head、StatelessOp、StatefulOp三种内部类。
来看一个简单的示例:
cpp
package stream;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
public class StreamDemo {
public static void main(String[] args) {
//字符串的"+"操作 //字符串拼接
List<String> names = Arrays.asList("Bob","John","Mary");
Optional<String> str = names.stream()
.filter(e->e.length()>=4)
.reduce((s1,s2)->s1+s2);
System.out.println("拼接结果:"+str.orElse(""));
}
}Head类主要用来定义数据源操作,在初次调用names.stream()方法时,会初次加载Head对象,此时为加载数据源操作;接着加载的是中间操作,分别为无状态中间操作StatelessOp对象和有状态操作StatefulOp对象,此时的Stage并没有执行,而是通过AbstractPipeline生成了一个中间操作Stage链表;当我们调用终止操作时,会生成一个最终的Stage,通过这个Stage触发之前的中间操作,从最后一个Stage开始,递归产生一个Sink链。
二、流(Stream)的性能优化策略
(一)选择合适的Stream(流)类型
1,优先使用基本数据类型流(避免装箱/拆箱开销)
这是最立竿见影的优化策略之一。因为 Stream<Integer> 、Stream<Long> 、Stream<Double> 等都属于对象流 Stream<T> 。Integer 、Long 和 Double 都是基本数据类型的包装类,包装类型的对象流 Stream<T> 会带来巨大的 装箱(Boxing) 和 拆箱(Unboxing) 开销。
将基本数据类型(如 int、long或double)转换为数值的包装类型(如 Integer、Long和Double)称为装箱操作;反之称为拆箱操作。
对于大数据的数值运算,装箱和拆箱的计算开销,以及包装类型占用的额外存储空间,会明显降低程序的运算速度。
优化策略: 在大数据的数值计算和数理统计场景,对于 int, long, 和 double 等基本数据类型,应优先使用基本数据类型流 IntStream, LongStream 和 DoubleStream,以避免装箱和拆箱的开销。
这些流有一个最常用的汇总统计SummaryStatistics()方法,这个方法可得到一组统计数据:元素个数、汇总值、最大值、最小值和平均值。
Java语言为基本数据类型流专门内置了一些实用的方法:例如,都有内置的规约操作,包括average、count、max、min、sum。
这些方法都直接在原始数据类型上操作,避免了包装类的装箱和拆箱开销。
当数据源为大数据的列表 List<Integer> 时的情形:
cpp
// 低效 - 存在装箱开销
List<Integer> numbers = ...;
int sum = numbers.stream()
.reduce(0, Integer::sum);
// 高效 - 使用 IntStream
int sum = numbers.stream()
.mapToInt(Integer::intValue) // 转换为 IntStream
.sum(); // 直接在 int 上操作更进一步 : 如果数据源本身是基本数据类型的数组的情形,可直接使用 Arrays.stream() 创建Stream<Integer> 流:
cpp
int[] intArray = ...;
IntStream intStream = Arrays.stream(intArray);装箱和不装箱的性能比较测试例程:
cpp
public static void 装箱与不装箱Test() {
// 装箱版本测试
long startTime = System.currentTimeMillis();
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10_000_000; i++) {
list.add(i);
}
long sum = 0;
for (Integer num : list) {
sum += num;
}
long endTime = System.currentTimeMillis();
long boxedTime = endTime - startTime;
// 原始数据类型版本测试
startTime = System.currentTimeMillis();
int[] array = new int[10_000_000];
for (int i = 0; i < array.length; i++) {
array[i] = i;
}
sum = 0;
for (int num : array) {
sum += num;
}
endTime = System.currentTimeMillis();
long primitiveTime = endTime - startTime;
System.out.println("装箱版本耗时: " + boxedTime + "ms");
System.out.println("原始数据类型版本耗时: " + primitiveTime + "ms");
}装箱与不装箱的测试结果:
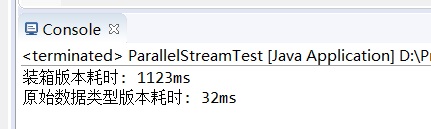
在大数据计算密集型任务中,避免装箱操作通常可以获大幅的性能提升,同时减少内存使用和GC压力。
2,正确选择 顺序流(stream) 或 并行流(parallelStream)
顺序流或并行流 :根据数据集大小和是否对元素顺序敏感选择顺序流stream()或并行流parallelStream()。小规模数据集或顺序敏感的操作适合顺序流;大规模数据集且能接受非确定性结果时适合并行流。

下面来看一个小规模数据集,我们分别使用基本数据类型流、顺序流装箱和并行流装箱进行比较测试:
cpp
package stream;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class StreamTest {
public static void primitive() { //基本数据类型流(顺序流)
long start = System.currentTimeMillis();
long sum = IntStream.range(1, 10_000)
.sum();
long duration = System.currentTimeMillis() - start;
System.out.println("基本类型流求和结果: " + sum + ", 耗时: " + duration + "ms");
}
public static void boxed() { //顺序流装箱
long start = System.currentTimeMillis();
List<Integer> numbers = IntStream.range(1, 10_000).boxed().collect(Collectors.toList());
int sum = numbers.stream()
.mapToInt(Integer::intValue)
.sum();
long duration = System.currentTimeMillis() - start;
System.out.println("顺序流求和结果: " + sum + ", 耗时: " + duration + "ms");
}
public static void parallel() { //并行流装箱
long start = System.currentTimeMillis();
List<Integer> numbers = IntStream.range(1, 10_000).boxed().collect(Collectors.toList());
int sum = numbers.parallelStream()
.mapToInt(Integer::intValue)
.sum();
long duration = System.currentTimeMillis() - start;
System.out.println("并行流求和结果: " + sum + ", 耗时: " + duration + "ms");
}
public static void main(String[] args) {
primitive();
boxed();
parallel();
}
}小规模数据集,我们分别使用基本数据类型流、顺序流装箱和并行流装箱进行比较测试。
预期结果是耗时从小到大。但是令人遗憾的是,测试并未得到预期的结果。
如果调整代码顺序会得到完全不同的测试结果。测试顺序严重影响结果。
原因是:Java 的 JIT(即时编译器)需要时间来优化代码。先执行的代码都会因为JIT还没有充分优化而变慢。
- 先执行的代码:承担 JIT 编译的开销。
- 后执行的代码:享受已经优化好的代码。
解决方案:正确的性能测试方法是使用专业的基准测试工具,如JMH(Java Microbenchmark Harness)。
下面这个示例,试图演示在数值运算场景中,基本数据类型流LongStream 比对象流Stream有更好的效率。
使用专业的基准测试工具(如 JMH),才能得到准确的结果。你会发现 LongStream 确实比 Stream 快 2-5 倍。
cpp
package stream;
import java.util.Random;
import java.util.stream.LongStream;
import java.util.stream.Stream;
public class BOxUnboxingComparison {
private static final int DATA_SIZE = 10_000;
private static final Random RANDOM1 = new Random(42);
private static final Random RANDOM2 = new Random(42);
public static void main(String[] args) {
// 测试1: 基本的统计操作
System.out.println("=== 基本统计操作性能测试 ===");
/***对象流Stream(Long),数据计算时需要拆箱***/
long startTime = System.nanoTime();
long boxedSum = Stream.generate(() -> Math.abs(RANDOM1.nextLong()) % 100)
.limit(DATA_SIZE)
.mapToLong(Long::longValue) // 必须拆箱才能计算
.sum();
long boxedTime = System.nanoTime() - startTime;
/***基本数据类型流LongStream,数据计算时无须拆箱***/
startTime = System.nanoTime();
long primSum = LongStream.generate(() -> Math.abs(RANDOM2.nextLong()) % 100)
.limit(DATA_SIZE)
.sum();
long primTime = System.nanoTime() - startTime;
printResults("求和", primTime, boxedTime, primSum, boxedSum);
// 测试2: 过滤和聚合操作
System.out.println("\n=== 过滤和聚合操作性能测试 ===");
/***对象流Stream(Long),数据计算时需要拆箱***/
startTime = System.nanoTime();
double boxedAvg = Stream.generate(() -> Math.abs(RANDOM1.nextLong()) % 100)
.limit(DATA_SIZE)
.filter(x -> x > 50) // 过滤(自动拆箱比较)
.mapToLong(Long::longValue) // 必须拆箱
.average()
.orElse(0);
boxedTime = System.nanoTime() - startTime;
/***基本数据类型流LongStream,数据计算时无须拆箱***/
startTime = System.nanoTime();
double primAvg = LongStream.generate(() -> Math.abs(RANDOM2.nextLong()) % 100)
.limit(DATA_SIZE)
.filter(x -> x > 50) // 过滤
.average() // 计算平均值
.orElse(0);
primTime = System.nanoTime() - startTime;
printResults("平均值", primTime, boxedTime, primAvg, boxedAvg);
}
private static void printResults(String operation, long primitiveTime, long boxedTime,
Object primitiveResult, Object boxedResult) {
System.out.printf("LongStream - 耗时: %8d ns, 结果: %s%n", primitiveTime, primitiveResult);
System.out.printf("Stream<Long> - 耗时: %8d ns, 结果: %s%n", boxedTime, boxedResult);
System.out.printf("性能差距: %.2f 倍%n", (double) boxedTime / primitiveTime);
}
}(二)中间操作的优化
每个中间操作都可能涉及到对元素的复制和创建新的Stream对象。合理配置中间操作可优化Stream的性能。
- 使用 distinct() 删除重复元素
如果 stream 中可能包含重复元素,可使用 distinct() 操作将其删除,防止无效处理以提高性能。
cpp
List<Integer> list = Arrays.asList(1, 2, 3, 3, 4, 5, 5);
list.stream().distinct().forEach(System.out::println);- 合理配置 limit() 防止无效处理
示例:
cpp
// 生成斐波那契数列但只取前10个
Stream.iterate(new int[]{0, 1}, fib -> new int[]{fib[1], fib[0] + fib[1]})
.limit(10) // 限制器
.map(fib -> fib[0])
.forEach(System.out::println);- 谨慎使用 sorted()
sorted()操作可能很昂贵,尤其是对于大数据流(large streams)。请谨慎使用,只有在必要时才使用。如果知道输入数据已经排序,可以跳过此操作。
- 选择正确的中间操作顺序。需要数据过滤的场景,尽早使用filter()
中间操作的顺序对性能有巨大影响,尤其是 filter() 和 map() 的顺序。
优化策略 :
合理配置map()和filter()的组合。先过滤filter(),后映射map(): 尽可能早地使用 filter() 筛选掉不需要处理的元素。这会使后续所有操作(map, sorted, collect 等)的数据量变小。
示例:
cpp
var list = Arrays.asList(1, 2, 3, 4, 5,8,16,18);
var filteredList = list.stream()
.filter(i -> i % 2 == 0)
.map(i -> i * 2)
.collect(Collectors.toList());上面这个示例"在 map() 之前使用 filter()"可过滤掉一大半的元素,大大减少了map()操作的工作量。
避免在中间操作中执行昂贵操作: 如果 map 中包含一个昂贵的方法调用,确保它只在必要的元素上执行(即先被 filter 处理过的)。
cpp
// 低效的中间操作顺序
List<String> names = list.stream()
.map(e -> expensiveOperation(e)) // 对所有元素执行昂贵操作
.filter(s -> s.length() > 3)
.collect(Collectors.toList());
// 高效的中间操作顺序 - 优先过滤
List<String> names = list.stream()
.filter(e -> e.length() > 3) // 先减少数量
.map(e -> expensiveOperation(e)) // 只对过滤后的元素执行
.collect(Collectors.toList());再来看另一个典型示例:
cpp
// 目标:获取所有字符串长度的平方,且只保留大于10的结果
// 低效:先map所有,再filter
List<Integer> lengthsSquared = words.stream()
.map(String::length) // 所有元素都被映射
.map(len -> len * len) // 所有元素再次被映射
.filter(sq -> sq > 10) // 最后过滤掉大部分
.collect(Collectors.toList());
// 更高效:合并map和filter,但逻辑稍复杂
// (有时无法避免,但这里可以优化)
// 最优:合并map操作,并尽早filter
List<Integer> lengthsSquared = words.stream()
.map(String::length) // 先map一次
.filter(len -> len > 3) // 尽早过滤:因为如果length<=3,平方肯定<=9,不会大于10
.map(len -> len * len) // 只为剩余的元素进行平方计算
.collect(Collectors.toList());- 适当合并中间操作减少Stream内部迭代次数
1,多个可合并的映射(map)操作 合并为一个操作
将多个可合并的映射(map)操作合并为一个,从而减少Stream管道中需要执行的迭代次数和中间对象的创建。
经典示例:处理字符串列表,假设我们有一个字符串列表,我们需要:
(1)将每个字符串转换为大写。
(2)反转每个字符串。
(3)获取每个字符串的前3个字符。
低效做法 :使用多个连续的 map 操作。
在这个算法中,Stream管道内部发生了3次完整的迭代,并创建了2个中间的Stream元素集合。
cpp
//优化前的低效算法:
List<String> words = Arrays.asList("hello", "world", "java", "stream");
List<String> result = words.stream()
.map(String::toUpperCase) // 第一次迭代:生成新流 ["HELLO", "WORLD", "JAVA", "STREAM"]
.map(s -> new StringBuilder(s).reverse().toString()) // 第二次迭代:生成新流 ["OLLEH", "DLROW", "AVAJ", "MAERTS"]
.map(s -> s.substring(0, Math.min(3, s.length()))) // 第三次迭代:生成新流 ["OLL", "DLR", "AVA", "MAE"]
.collect(Collectors.toList());
System.out.println(result); // 输出: [OLL, DLR, AVA, MAE]高效做法 :将多个连续的 map 操作合并为一个。
"合并中间操作"最经典的体现就是将多个连续的 map 操作合并为一个,这是提升Stream性能最简单有效的方法之一。
cpp
//优化后的高效算法:
List<String> words = Arrays.asList("hello", "world", "java", "stream");
List<String> result = words.stream()
.map(s -> { // 只进行一次映射操作,将所有转换逻辑合并
String upper = s.toUpperCase();
String reversed = new StringBuilder(upper).reverse().toString();
return reversed.substring(0, Math.min(3, reversed.length()));
})
.collect(Collectors.toList());
System.out.println(result); // 输出: [OLL, DLR, AVA, MAE]2,多个连续的 filter() 操作合并。
经典示例:筛选用户列表
合并多个filter操作是一个非常重要且常见的优化策略。它的核心思想是:通过逻辑运算符将多个过滤条件合并为一个filter,减少Stream管道中的阶段数量和 predicate(断言)的执行次数。
假设我们有一个User对象列表,我们需要筛选出同时满足以下条件的用户:
(1), 年龄大于等于18岁(成年人)
(2), 年龄小于65岁(未退休)
(3), 账户状态是激活的(ACTIVE)
(4), 登录次数大于0(活跃用户)
低效算法: 使用多个连续的 filter() 操作
在这个算法中,数据仿佛要"过四道筛子":
cpp
// 优化前的低效算法
List<User> users = // ... 获取用户列表
List<User> filteredUsers = users.stream()
.filter(user -> user.getAge() >= 18) // 第一轮过滤:检查条件1
.filter(user -> user.getAge() < 65) // 第二轮过滤:检查条件2
.filter(user -> user.getStatus() == User.Status.ACTIVE) // 第三轮过滤:检查条件3
.filter(user -> user.getLoginCount() > 0) // 第四轮过滤:检查条件4
.collect(Collectors.toList());高效做法:合并 filter() 操作
cpp
// 第一次优化后的算法
List<User> users = // ... 获取用户列表
List<User> filteredUsers = users.stream()
.filter(user -> user.getAge() >= 18
&& user.getAge() < 65
&& user.getStatus() == User.Status.ACTIVE
&& user.getLoginCount() > 0)
.collect(Collectors.toList());其实,在本例中还可以继续进行优化。
利用逻辑运算的短路(Short-Circuit)评估: 这也是一个关键的优化点。Java中的逻辑运算符 && (AND) 和 || (OR) 是短路的。
1)、对于 逻辑运算符 && (AND) :如果第一个条件为 false ,整个表达式的结果立即确定为 false ,后续条件将不再被计算。
在本例中,如果一个用户年龄是17岁(user.getAge() >= 18 为 false),JVM会立即跳过对其退休状态、账户状态和登录次数的检查。这节省了3次方法调用和比较操作。
将最可能失败或计算成本最低的条件放在&&的最左边,可以最大化短路优化带来的收益。
合并后,条件的顺序变得很重要,因为它直接影响短路评估的效果。
进一步优化策略:
-
- 将最可能使条件失败的条件放在前面。 如果90%的用户都是非活跃的,那么先检查loginCount > 0就能最快地淘汰大部分元素。
-
- 将计算成本最低的条件放在前面。 比较年龄(基本类型比较)的成本远低于从数据库或网络获取状态(假设getStatus()很昂贵)。先进行廉价的检查,可以避免对即将被淘汰的元素执行昂贵的操作。
优化合并filter()操作的最终版本:
cpp
//优化合并filter()操作的最终版本
List<User> users = // ... 获取用户列表
List<User> filteredUsers = users.stream()
.filter(user -> user.getLoginCount() > 0 // 成本低,可能淘汰很多用户
&& user.getAge() >= 18 // 成本低
&& user.getAge() < 65 // 成本低
&& user.getStatus() == User.Status.ACTIVE) // 可能成本最高(例如涉及数据库查询),放在最后注意事项: 如果某个昂贵条件是独立的,无法通过短路避免,有时将其单独放在一个filter里并在前面使用更廉价的条件过滤可能更优,但这需要具体分析。通常,合并filter并利用短路特性来调整过滤条件顺序是最佳实践。
2)、对于 逻辑运算符 || (OR) :如果第一个条件为 true ,整个表达式立即为 true ,后续条件不再计算。
请看一个 逻辑运算符 **|| (OR)**逻辑连接的filter() 操作合并为一个操作的示例:
cpp
// 多个filter() 合并 和 优化 示例
List<User> users = // ... 获取用户列表
// 未合并为一个filter (OR 逻辑)的原始状态
List<User> filteredUsers = users.stream()
.filter(user -> user.getTotalSpending() > 1000)
.filter(user -> user.getYearsAsMember() > 5)
...
// 简单合并为一个filter (OR 逻辑)
List<User> filteredUsers = users.stream()
.filter(user -> user.getTotalSpending() > 1000 || user.getYearsAsMember() > 5)
...
// 优化后: 优化策略:将更可能为true或成本更低的条件放在||前面
List<User> filteredUsers = users.stream()
.filter(user -> user.getYearsAsMember() > 5 || user.getTotalSpending() > 1000)
...结论: 可将多个连续的、用 && (AND) 或 || (OR) 逻辑连接的filter() 操作合并为一个,并利用短路评估来排序条件,是减少不必要的计算、提升Stream性能的经典且高效的手段。在编写Stream代码时,应有意识地检查是否存在可合并的filter()操作。
额外的好处: Stream API需要为每个中间操作维护一个调用栈。减少中间操作的数量使得整个流水线更简单,JIT编译器也可能更容易对其进行优化。
(三)终端操作的优化
- 选择高效的终端操作
不同的终端操作有不同的性能特征。优化策略:
(1)、anyMatch/allMatch/noneMatch 是短路(short-circuiting)操作,一旦找到答案就会停止处理,性能通常很好。
(2)、findFirst 在并行流中需要协调,可能会有一定开销。如果顺序不重要,findAny 在并行流中限制更少,性能可能更高。
(3)、count 对于 SIZED 流(如从 List 创建的流)来说非常高效。否则,它需要遍历所有元素。
(4)、collect 的性能取决于你使用的收集器。Collectors.toList() 通常很高效。Collectors.groupingBy 和 Collectors.toMap 的成本较高,需要注意。
流管道(Stream pipeline)中的操作应该都是无副作用的。
例如:在中间操作中修改外部状态会导致并发问题(尤其在并行流中)和不可预测的行为。
终端操作也应该是无副作用的。应优先使用收集器(Collectors) 而不是在 forEach 中修改外部集合。forEach 应仅用于消费最终结果,而不是处理过程。请看示例:
cpp
// 错误 - 在 forEach 中修改外部集合(非线程安全)
List<String> result = new ArrayList<>();
stream.filter(...)
.forEach(e -> result.add(e)); // 在并行流中会崩溃
// 正确 - 使用收集器
List<String> result = stream.filter(...)
.collect(Collectors.toList()); // 线程安全且高效- 利用短路操作提高效率
诸如 findFirst(),findAny() 和 anyMatch() 等短路操作,在找到符合条件或不符合条件时就会立即返回,不处理整个流。利用这些操作可以提高性能。
cpp
/***权限检查短路***/
List<Permission> userPermissions = getUserPermissions(userId);
// 检查用户是否有管理员权限
boolean isAdmin = userPermissions.stream()
.anyMatch(p -> p.getType() == PermissionType.ADMIN); // 找到第一个管理员权限就返回
// 比收集到列表再判断更高效
/***验证输入数据***/
List<String> inputs = getInputs();
// 验证所有输入是否有效(遇到第一个无效就停止)
boolean allValid = inputs.stream()
.peek(input -> System.out.println("Validating: " + input))
.allMatch(this::isValidInput);(四)正确使用并行流(parallelStream)
Java的Stream API 支持并行流(parallelStream)操作,可以利用多个处理器阵列或多核处理器并行处理数据。
并行流操作通过将数据分割成多个子集,然后并行处理,最终合并结果。
并行流(parallelStream)可以在处理大量数据时提供更好的性能,但也会带来额外开销和竞争条件。谨慎使用parallelStream,并需要考虑数据规模、操作复杂程度和可用处理器数量等因素。
并行操作引入了线程管理的开销和线程间协调开销。如果使用不当,也可能引起线程管理的开销增加。例如:在处理 IO 密集型任务或数据量小的场景,并行流可能因线程管理和线程间协调的开销反而更慢。
当调用 stream().parallel() 或 parallelStream() 时进行并行处理时,Java 会将数据分割成多个子集,由 ForkJoinPool 分配线程并行处理。这种机制在处理"大数据集、CPU 密集型操作"时优势明显,比如统计分析、数据汇总,以及排序、过滤、聚合等操作。
并行流需要有硬件支持:多个处理器或多核处理器的系统
并行流 (parallelStream) 可以将工作负载分配到多个 CPU 核心上,但并非万能药。错误使用会导致更差的性能(线程上下文切换开销)甚至错误结果。
优化策略:
使用工具测量,不要凭猜测: 始终使用类似 JMH 的工具进行基准测试,比较并行和串行流的性能。并行化的开销(拆分、协调、合并)只有在数据量足够大、计算足够密集时才能被抵消。
并行流(parallelStream)适用场景:
- 大数据,大规模数据源(例如,数十万以上元素)。
- 每个元素的处理是计算密集型(CPU-intensive)的,而不是 I/O 密集型(如网络请求、文件读写)。
- 数据源易于拆分:ArrayList、数组、IntStream.range() 等支持随机访问的数据源拆分效率极高。而 LinkedList、Stream.iterate() 则难以有效拆分。
- 操作是无状态且无关联的(如 map, filter),合并操作成本低(如 reduce 的合并器)。
不适合的场景:
- 数据量小。
- 操作是 I/O 密集型(线程会大部分时间在等待,浪费资源,应使用专门的异步 API如 CompletableFuture)。
- 操作有状态或有副作用(如 sorted, distinct, limit 在并行流中代价更高,因为需要协调)。
- 使用了有状态的 Lambda 表达式或阻塞操作。
示例:
cpp
List<String> hugeList = ...;
// 好的并行用例:大数据集,计算密集型操作
long count = hugeList.parallelStream()
.filter(s -> s.length() > 10) // 无状态
.count(); // 简单合并
// 坏的并行用例:小数据集
long count = smallList.parallelStream() // 开销大于收益
.count();三、总结:流(Stream)性能优化的工作流程
-
首先,写出正确、清晰的程序代码: 不要过早优化。先使用 Stream API 实现正确的逻辑。
-
基准测试: 使用 JMH (Java Microbenchmark Harness) 等工具来识别真正的性能瓶颈。不要靠猜测。
-
应用调优策略进行性能优化:
第一步: 检查是否能优先使用基本数据类型流 (IntStream 等)。
第二步: 中间操作的优化,检查中间操作顺序,例如确保尽早过滤 (filter)。
第三步: 评估是否适合并行化 (parallelStream),并进行测试。
第四步(高级): 检查终端操作和收集器,必要时考虑自定义。
再次测量: 每次优化后都进行基准测试,确认优化确实有效。
通过遵循这些策略,才能最大限度地发挥 Java Stream API 函数式编程的威力,同时保持代码的高性能。