前言
InnoDB 架构
MySQL 8.4 InnoDB 架构图:

主要有两大部分:
- 内存区域:存储各类缓存数据如 buffer pool、change buffer 等,缓存区存在是 InnoDB 高效的核心原因之一
- 磁盘区域:核心的数据文件、日志文件、以及性能提升所涉及的文件等
从内存到磁盘的数据互通,还有一个重要的角色:后台线程
-
后台线程的主要作用是负责刷新内存池中的的数据,保证内存缓存时最近的数据。
-
另外将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情况下 InnoDB 能恢复到正常运行状态。
内存空间
Buffer Pool
由于 CPU 速度与磁盘速度之间的鸿沟,基于磁盘的数据库系统通常使用缓存池技术来提高数据库的整体性能
Buffer Pool,即缓存池, 是 InnoDB 的内存缓存,简单来说就是一块内存区域,用于缓存表和索引数据,以提高数据访问速度。缓冲池的大小可以通过配置参数进行调整。
对于读取操作:
首先将从磁盘读取到的数据页存放在缓存池中;下一次读取相同页时,首先判断该页是否存在缓存池中;若在缓存池中,则直接使用,否则,继续从磁盘中读取数据页。
对于修改操作:
首先修改在缓存池中的页,然后再以一定的频率刷新到磁盘上。
为了提高数据库的整体性能,页更新后不一定会立即刷新至磁盘,而是通过 checkpoint 机制刷新回磁盘。
缓存池的大小直接影响着数据库的整体性能。
Change Buffer
区别于 Buffer Pool 通用的缓存(用于加速数据和索引的读取和写入),Change Buffer 则 专注于优化非唯一索引的写入性能。
Change Buffer 结构图:
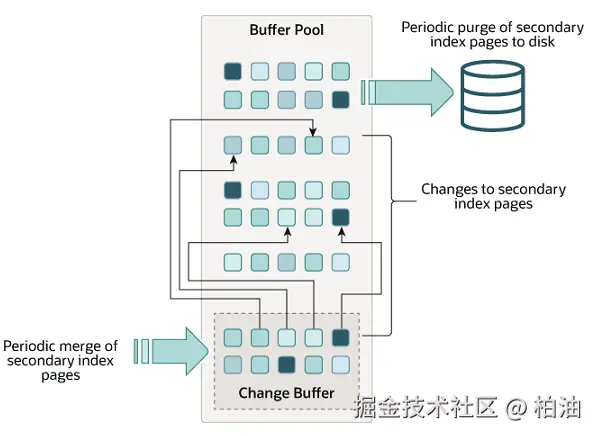
Change Buffer 是一个特殊的缓冲区,用于缓存对非唯一二级索引的修改操作(如插入、更新、删除),这些操作在磁盘上尚未更新。
作用:
- 通过将索引页的修改操作缓存在内存中,Change Buffer 减少了对磁盘的随机写入操作,从而提高了写入性能。
- 当索引页被读取到内存中时,InnoDB 会将 Change Buffer 中的修改应用到该页上
使用场景:主要用于非唯一索引,因为唯一索引需要立即检查唯一性约束,而非唯一索引则可以延迟应用
Log Buffer
Log Buffer 也是一个内存缓冲区,用于暂时存储事务的重做日志(Redo Log)记录。在事务提交时,InnoDB 会将这些日志记录写入磁盘上的重做日志文件。
作用:
- 提高事务日志写入的性能。通过在内存中缓存日志记录,减少了频繁的磁盘 I/O 操作。
- 提供事务的持久性支持。即使在系统崩溃时,重做日志也可以用于恢复未完成的事务
工作机制:
- 当事务对数据库进行修改时,相关的日志记录会首先写入 Log Buffer。
- Log Buffer 中的日志记录会定期或在事务提交时被刷新到磁盘上的重做日志文件中(如 ib_logfile0 和 ib_logfile1)。
- 刷新操作可以由以下事件触发:
- 事务提交(COMMIT)。
- Log Buffer 满。
- 定期的后台刷新操作。
Log Buffer 的大小可以通过 MySQL 配置参数 innodb_log_buffer_size 进行调整。较大的 Log Buffer 可以减少日志写入磁盘的频率,适合于长事务或批量操。
磁盘空间
InnoDB 最终的数据通过文件的信息存储在磁盘空间, 主要包括以下几种类型:
-
表空间文件(.ibd 文件) :
- 每个 InnoDB 表都有一个独立的表空间文件,默认情况下,这些文件的扩展名为 .ibd。
- 这些文件存储了表的数据和索引。
-
共享表空间文件(ibdata 文件) :
- 在使用 MySQL 的老版本或未启用独立表空间的情况下,所有表的数据和索引会存储在一个或多个共享表空间文件中,通常命名为 ibdata1、ibdata2 等。
- 这些文件也包含 InnoDB 的数据字典和其他系统信息。
-
日志文件(ib_logfile) :
- InnoDB 使用重做日志文件(redo log)来保证事务的持久性和恢复能力。
- 这些文件通常命名为 ib_logfile0、ib_logfile1 等。
-
撤销日志文件(undo log) :
- 撤销日志用于支持事务的回滚和 MVCC(多版本并发控制)。
- 在 MySQL 8.0 及更高版本中,撤销日志可以存储在独立的表空间中。
-
临时文件:
- InnoDB 可能会创建临时文件用于排序操作或其他需要临时存储的操作。
Tablespace 表空间
什么是表空间?
数据存储的顶层结构,可以看作是 InnoDB 存储引擎的最高层。所有的数据都存放在表空间中。
在默认的配置下,会有一个大小为 10MB,名为 ibdata1 的文件,即,共享表空间;默认情况下,所有数据都存放在这个表空间内。
当然,我们可以为每张表设置不同的表空间,innodb_file_per_table = 1,这样每张表内的数据可以单独存放在一个表空间内。
值得注意的是,即使启用了 innodb_file_per_table = 1,其表空间内存放的只是数据、索引和插入缓冲页;而其他类的数据,如 undo log、double write buffer 等仍然是存放在原来的共享表空间内。
细分结构:
前面讲了,表空间是顶层结构,往下继续划分 段(segment)、区(extent)、页(page)。页也称为块(block)
Index 索引文件
InnoDB 的所有数据都是存放在索引结构中,有两类索引结构:
- 主键索引:通过主键id进行索引,叶子节点存放真实的数据
- 非主键索引:除了主键索引外都是这类索引,叶子存放的是主键id。通常讲的回表就是从非主键索引检索到数据后,再回表到主键索引检索真实的数据。
Doublewrite Buffer 双写缓存
双写 是一个用于提高数据可靠性和防止数据损坏的机制。它的主要作用是在发生崩溃或系统故障时,确保数据页能够被安全地恢复。
工作原理
- 数据页准备:当 InnoDB 需要将脏页(已修改但尚未写入磁盘的数据页)从缓冲池写入磁盘时,它首先将这些页写入双写缓存。
- 写入双写缓存:双写缓存位于共享表空间中,大小通常为 2MB,分为两个部分,每部分 1MB。InnoDB 将数据页批量写入双写缓存。
- 同步写入磁盘:一旦数据页成功写入双写缓存,InnoDB 会将这些页同步写入到实际的数据文件中(如 .ibd 文件)。
- 崩溃恢复:如果在写入过程中发生崩溃,InnoDB 可以使用双写缓存中的数据页来恢复未完成的写入操作,从而防止数据页的部分写入导致的数据损坏。
优点
- 数据完整性:通过双写缓存,InnoDB 能够防止由于部分写入(Partial Page Write)导致的数据页损坏。
- 崩溃恢复:在系统崩溃后,双写缓存提供了一种机制来确保数据页的一致性和完整性。
性能影响
- 写入开销:双写缓存机制会增加一些写入操作的开销,因为每个数据页需要被写入两次(一次到双写缓存,一次到实际数据文件)。
- 性能优化:尽管有额外的写入开销,但由于双写缓存的写入是顺序的,因此对性能的影响通常是可接受的。
配置
双写缓存在 InnoDB 中默认启用,可以通过 MySQL 配置文件中的 innodb_doublewrite 参数进行控制:
Redo Log
InoDB 的重做日志(Redo Log)是一个关键的日志机制,用于确保事务的持久性和数据库的崩溃恢复能力;它记录了对数据库所做的修改,以便在系统崩溃后能够恢复未完成的事务。
作用
- 事务持久性:重做日志确保事务的持久性(即使系统崩溃),因为事务的修改在提交前会先写入重做日志。
- 崩溃恢复:在系统崩溃后,InnoDB 使用重做日志来恢复未完成的事务,确保数据库的一致性。
工作原理
- 日志写入:当事务进行修改时,InnoDB 会将这些修改记录到重做日志中,而不是立即写入磁盘上的数据文件。
- 日志刷新:在事务提交时,重做日志会被刷新到磁盘,确保事务的持久性。
- 数据页写入:脏页(已修改但尚未写入磁盘的数据页)会在稍后的时间点被写入磁盘,这种机制称为"延迟写入"。
- 崩溃恢复:如果系统崩溃,InnoDB 会在重启时读取重做日志,并重放日志中的操作以恢复数据库到一致状态。
结构
- 日志文件:重做日志由一组固定大小的日志文件组成,通常命名为 ib_logfile0、ib_logfile1 等。
- 循环写入:重做日志采用循环写入的方式,当日志文件写满时,会从头开始覆盖旧的日志记录。
Undo Logs
撤销日志(Undo Logs)是 InnoDB 存储引擎中用于支持事务回滚和多版本并发控制(MVCC)的关键机制;它记录了事务修改前的数据状态,以便在需要时能够撤销这些修改。
作用
- 事务回滚:当事务需要回滚时,撤销日志提供了恢复数据到事务开始前状态的信息。
- 多版本并发控制(MVCC) :撤销日志支持 MVCC,通过保存数据的旧版本,允许数据库在不加锁的情况下提供一致的读操作。
工作原理
- 记录旧值:当事务修改数据时,InnoDB 会在撤销日志中记录被修改数据的旧值。
- 回滚操作:如果事务需要回滚,InnoDB 使用撤销日志中的信息将数据恢复到修改前的状态。
- 一致性读:在 MVCC 中,撤销日志允许其他事务读取数据的旧版本,从而实现一致性读而不阻塞写操作。
结构
- 撤销段(Undo Segments) :撤销日志存储在撤销段中,每个段包含多个撤销日志记录。
- 撤销表空间:撤销日志可以存储在独立的撤销表空间中,以便更好地管理和优化。