Redis技术
1. Redis简介
定义与核心特性(内存数据库、键值存储)
Redis(Remote Dictionary Server,远程字典服务)是一个开源的、基于内存的高性能键值存储数据库,由 Salvatore Sanfilippo 编写,用 ANSI C 语言开发。它支持多种数据结构,如字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等。
核心特性:
• 内存存储:Redis 的数据存储在内存中,这使得它的读写速度极快,通常能达到每秒数十万次的读写操作。
• 持久化:尽管数据存储在内存中,但 Redis 提供了多种持久化机制,如 RDB(快照)和 AOF(追加文件)方式,可以在系统故障时恢复数据。
• 原子操作:Redis 的所有操作都是原子性的,这意味着一个操作在执行过程中不会被其他操作打断,保证了数据的一致性。
• 丰富的数据类型:除了常见的键值对,Redis 还支持哈希、列表、集合、有序集合等复杂数据类型,能够满足多种复杂的业务需求。
• 支持事务:Redis 支持事务功能,可以将多个命令打包,然后一次性、顺序地执行,提高效率并保证操作的原子性。
• 高性能:由于数据存储在内存中,Redis 的读写速度非常快,通常能达到每秒数十万次的读写操作。
使用场景(缓存、会话存储、消息队列等)
- 缓存:Redis 最常见的用途是作为缓存层,减轻数据库的压力。例如,将频繁访问的数据存储在 Redis 中,当用户请求时直接从 Redis 获取,避免每次都查询数据库。
- 会话存储:在 Web 应用中,Redis 可以用来存储用户的会话信息,如用户的登录状态、购物车内容等。由于 Redis 的高性能,可以快速读取和更新会话数据。
- 消息队列:Redis 的列表数据结构可以用来实现简单的消息队列,支持发布/订阅模式,可以用于应用之间的异步通信。
- 排行榜:利用 Redis 的有序集合(sorted sets),可以快速实现排行榜功能,如游戏中的玩家积分排行榜。
- 限流:通过 Redis 的计数器功能,可以实现接口的限流,防止过多的请求对后端服务造成压力。
- 分布式锁:Redis 可以用来实现分布式锁,确保在分布式系统中对共享资源的互斥访问。
对比其他数据库(如Memcached、MySQL)
- 与 Memcached 对比:
- 数据持久化:Redis 支持数据持久化,而 Memcached 不支持。这意味着 Redis 可以在系统故障后恢复数据,而 Memcached 会丢失所有数据。
- 数据类型:Redis 支持多种数据类型(字符串、哈希、列表、集合、有序集合等),而 Memcached 只支持简单的键值对。
- 事务支持:Redis 支持事务,可以将多个命令打包执行,而 Memcached 不支持事务。
- 性能:两者都是基于内存的,性能都非常高,但在复杂数据结构的处理上,Redis 更有优势。
- 与 MySQL 对比:
-
存储介质:Redis 是基于内存的,读写速度快,但存储容量有限;MySQL 是基于磁盘的,读写速度相对较慢,但存储容量大。
-
数据模型:Redis 是键值存储,适合存储简单的键值对和复杂数据结构;MySQL 是关系型数据库,支持复杂的查询和事务,适合存储结构化数据。
-
持久化:Redis 提供多种持久化机制,但数据仍然主要存储在内存中;MySQL 是持久化存储,数据存储在磁盘上。
-
适用场景:Redis 通常用于缓存、会话存储、消息队列等高性能场景;MySQL 适用于需要复杂查询和事务支持的场景,如用户信息存储、订单管理等。
2. Redis核心数据结构
String(字符串)
基本操作 :可以存储字符串、数字等,支持直接赋值(如 SET key value)、获取值(GET key)等简单操作。
字符串常用命令
-
set key value: key为设置的键 value为设置的值 但是如果已经存在这个键 那么value将会被覆盖
get key: 获取这个键的值set name nie
OK
get name
nie
set name niehai
OK
get name
niehai -
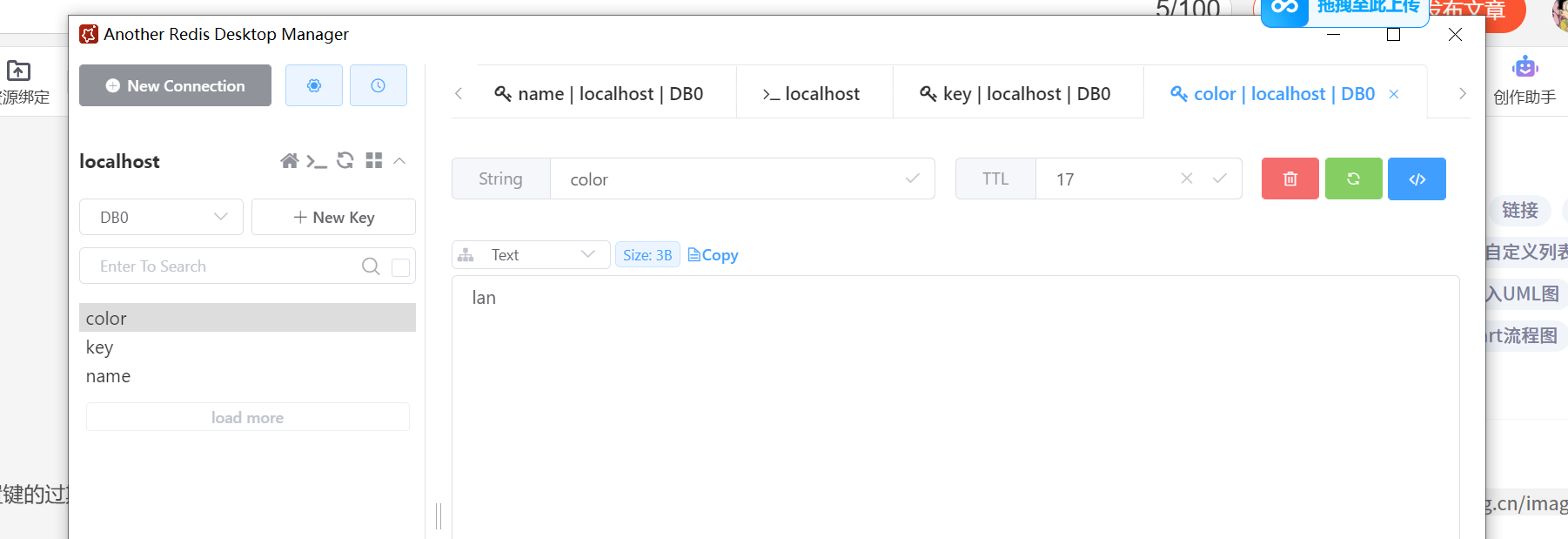
setex key seconds value: 将键key的值设置为value,并设置键的过期时间为seconds秒。SETEX是专门用于同时设置键值和过期时间的命令。
//这个TTL就是他的过期时间 过期后他就自动消失
SETEX color 20 lan
OK
-
setnx key value: 只有当键不存在时 才能设置value 如果键已存在 那么设置的value不生效
setnx color red
1
//当键color已经存在时修改失败
setnx color black
0
Hash(哈希)
存储对象属性 :适合存储对象的多个属性,如用户信息(用户名、密码、邮箱等),可使用 HSET key field value 为哈希表中的字段赋值,用 HGET key field 获取字段的值。
Hash常用命令
-
HSET KEY FIELD VALUE:
key :指定哈希表的名称,即存储多个字段 - 值对的集合的键。
field :指定哈希表中的字段名称。
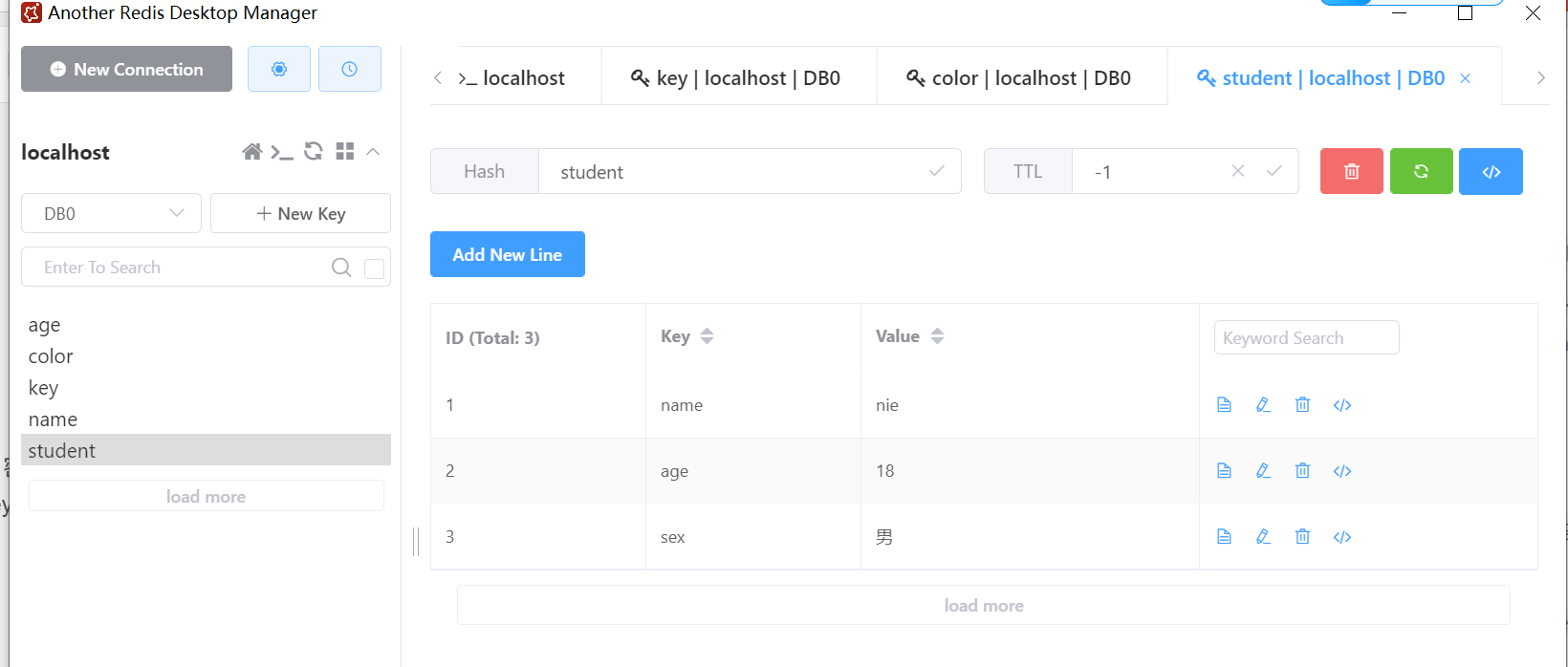
value :要设置的字段值。HSET student name nie
1
HSET student age 18
1
HSET student sex "男"
1
-
HGET KEY FIELD:获取存储在哈希表中的指定字段的值
-
HDEL KEY FIELD:删除哈希表中的指定字段
-
HKEYS key 获取哈希表中的所有字段
-
HVALS key 获取哈希表中的所有值
hkeys student
name
age
sex
HGET student name
nie
HGET student sex
男
HDEL student name
1
Hkeys student
age
sex
HVALS student
18
男
List(列表)
有序列表 :列表中的元素是按插入顺序有序排列的,支持从两端进行插入、删除和弹出操作,如 LPUSH key value(在列表头部插入元素)、RPUSH key value(在列表尾部插入元素)、LPOP key(从列表头部弹出元素)、RPOP key(从列表尾部弹出元素)。
List常用命令
-
LPUSH key value value...:把一个或多个值插入到列表头部
-
LRANGE key start stop:获取列表指定范围内的元素
-
RPOP key:删除并获取列表最后一个元素
-
LLEN key:获取列表长度
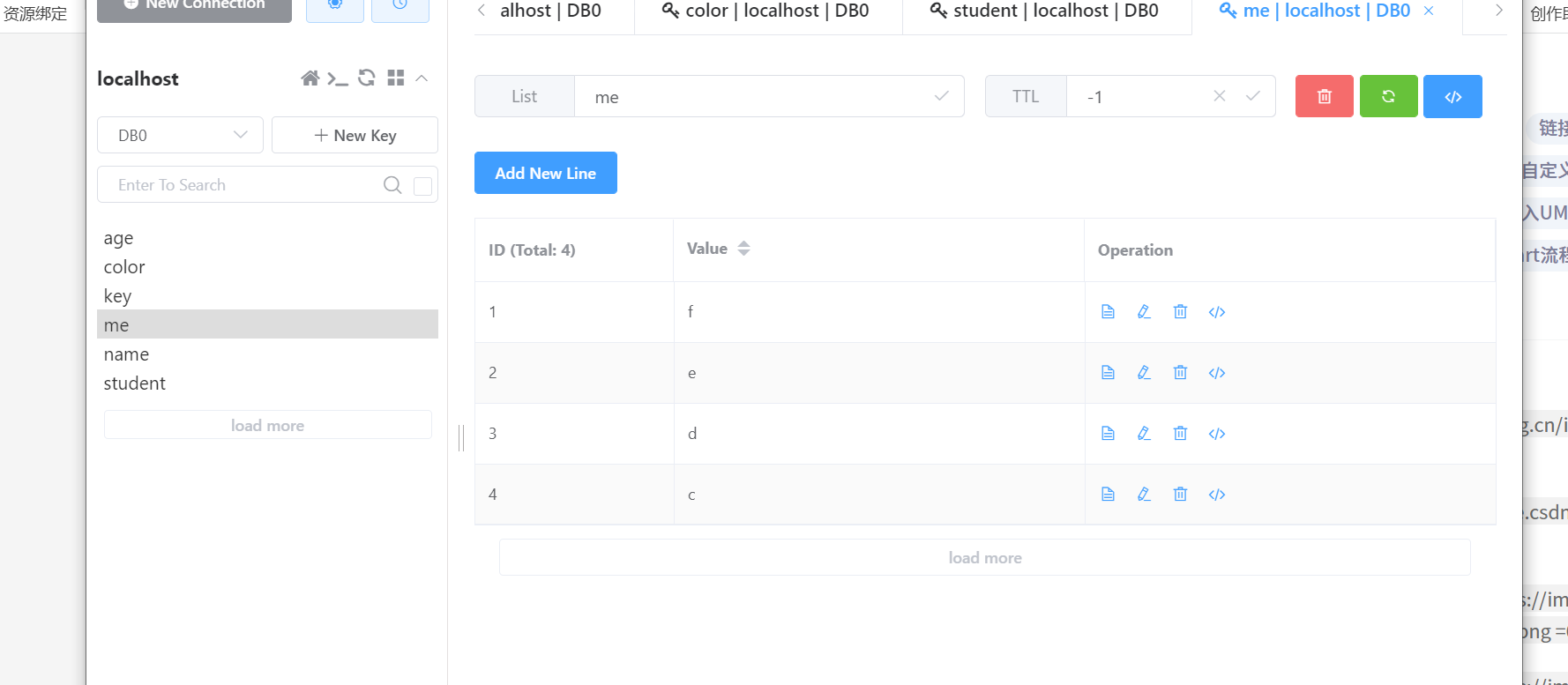
//插入是从左边插入(头部) 删除是从右边删除(尾部)
Lpush me a b c
3
Lpush me d e f
6
Lrange me 0 -1
f
e
d
c
b
a
rpop me
a
Llen me
5
rpop me
b
Llen me
4
Set(集合)
去重存储 :集合中的元素是无序且唯一的,自动去重,适用于存储不重复的元素集合,如关注的用户列表、兴趣标签等,使用 SADD key member 添加元素到集合。
Set常用命令
以下是 Redis 集合相关命令的原文介绍:
-
SADD key member1 [member2]:向集合添加一个或多个成员。 -
SMEMBERS key:返回集合中的所有成员。 -
SCARD key:获取集合的成员数。 -
SINTER key1 [key2]:返回给定所有集合的交集。 -
SUNION key1 [key2]:返回所有给定集合的并集。 -
SREM key member1 [member2]:删除集合中一个或多个成员。//创建集合set
sadd set a b c d e
5
//此时a已经存在集合里面了 所以插入不成功 因为set不能出现重复
sadd set a
0
//创建集合set1
sadd set1 a b c x y
5
//查看set里面的所有元素
smembers set
a
c
b
d
e
//查看set元素个数
scard set
5
//查看set和set1的交集
sinter set set1
a
c
b
//查看set和set的并集
sunion set set1
x
a
b
d
e
y
c
//删除set集合里面的a元素
srem set a
1
Sorted Set(有序集合)
带分数排序 :有序集合的每个元素都关联一个分数,元素会按照分数从小到大排序,若分数相同,则按字典序排序,可通过 ZADD key score member 添加元素及对应的分数。
-
ZADD key score1 member1 score2 member2:向有序集合添加一个或多个成员。
-
ZRANGE key start stop WITHSCORES:通过索引区间返回有序集合中指定区间内的成员。
-
ZINCRBY key increment member:有序集合中对指定成员的分数加上增量 increment。
-
ZREM key member member ...:移除有序集合中的一个或多个成员。
//插入有序集合zset a的分数为10.0 b的分数为10.5 c的分数为13
zadd zset 10.0 a 10.5 b 13 c
3
//插入元素e 分数为10.2
zadd zset 10.2 e
1
//查看所有元素 排序是以分数进行排序的
zrange zset 0 -1 withscores
a
10
e
10.199999999999999
b
10.5
c
13
//为指定的元素a添加6分
zincrby zset 6.0 a
16
//删除元素b
zrem zset b
1
//查看删除后并且加分后的所有元素
zrange zset 0 -1 withscores
e
10.199999999999999
c
13
a
16
HyperLogLog:
- 定义:HyperLogLog 是一个用于统计近似基数的数据结构,可以高效地统计大量数据的唯一值数量。
- 特点:
- 高效性:使用少量内存即可统计大量数据的唯一值数量。
- 近似性:统计结果是近似的,但误差范围很小。
- 使用场景:
- 独立访客统计:统计网站的独立访客数量。
- 去重统计:统计用户访问的页面数量等。
java
import redis.clients.jedis.Jedis;
public class RedisHyperLogLogDemo {
public static void main(String[] args) {
// 连接 Redis
Jedis jedis = new Jedis("localhost", 6379);
// 定义 HyperLogLog 的 key
String hllKey = "user_visits";
// 模拟添加用户访问数据(用户ID或IP)
jedis.pfadd(hllKey, "user1", "user2", "user3", "user1"); // 重复值会被去重
// 统计唯一用户数
long uniqueCount = jedis.pfcount(hllKey);
System.out.println("Estimated unique visits: " + uniqueCount); // 输出 3
// 合并多个 HyperLogLog(例如多天的数据)
String hllKeyDay2 = "user_visits_day2";
jedis.pfadd(hllKeyDay2, "user3", "user4", "user5");
jedis.pfmerge("combined_visits", hllKey, hllKeyDay2); // 合并到新 key
// 统计合并后的基数
long mergedCount = jedis.pfcount("combined_visits");
System.out.println("Merged unique visits: " + mergedCount); // 输出 5
// 关闭连接
jedis.close();
}
}pfadd(key, elements):向 HyperLogLog 添加元素(自动去重)。
pfcount(key):返回基数的估计值。
pfmerge(destKey, sourceKeys...):合并多个 HyperLogLog 到目标 key。
Bitmap:
- 定义:Bitmap 是一个位图数据结构,可以高效地存储和操作位信息。
- 特点:
- 高效存储:使用位来存储信息,占用空间小。
- 灵活操作:支持对位的设置、获取、统计等操作。
- 使用场景:
- 签到功能:实现用户签到功能,记录用户的签到状态。
- 权限管理:存储用户的权限信息,通过位图进行权限检查。
用户签到案例:
java
// 用户签到(设置某位为1)
public void signIn(Jedis jedis, String userId, int dayOfMonth) {
String key = "sign:" + userId + ":" + LocalDate.now().getMonthValue();
jedis.setbit(key, dayOfMonth - 1, true); // Redis的offset从0开始
}
// 检查是否签到
public boolean isSigned(Jedis jedis, String userId, int dayOfMonth) {
String key = "sign:" + userId + ":" + LocalDate.now().getMonthValue();
return jedis.getbit(key, dayOfMonth - 1);
}
// 统计当月签到次数
public long getSignCount(Jedis jedis, String userId) {
String key = "sign:" + userId + ":" + LocalDate.now().getMonthValue();
return jedis.bitcount(key);
}3. Redis持久化机制
Redis 提供了多种持久化机制,主要包括 RDB(快照)持久化、AOF(追加日志)持久化以及混合持久化。每种机制都有其独特的原理和配置方法,以及相应的性能和数据安全性的权衡。
RDB(快照)持久化原理与配置
原理
• 快照:RDB(Redis Database Backup)持久化通过在指定的时间间隔内创建内存数据的快照来实现数据持久化。Redis 会定期将内存中的数据集写入到磁盘上的一个 RDB 文件中。
• 触发机制:
• 手动触发:通过SAVE或BGSAVE命令手动创建 RDB 文件。
• 自动触发:根据配置文件中的save指令自动触发。例如,save 900 1表示如果 900 秒内至少有 1 个键被修改,则触发 RDB 持久化。
• 工作流程:
• Redis 主进程调用BGSAVE命令。
• 主进程 fork 出一个子进程,子进程负责将当前内存中的数据写入到临时 RDB 文件中。
• 子进程完成写入后,用临时文件替换旧的 RDB 文件。
配置
• 配置文件示例:
conf
# 自动触发 RDB 持久化的条件
save 900 1
save 300 10
save 60 10000
# RDB 文件名
dbfilename dump.rdb
# RDB 文件存储路径
dir /var/lib/redis
# 是否启用 RDB 文件压缩
rdbcompression yes
# 是否启用 RDB 文件校验
rdbchecksum yes优点
• 恢复速度快:RDB 文件是一个紧凑的二进制文件,恢复数据时速度较快。
• 备份方便:RDB 文件是一个单独的文件,方便进行备份和传输。
缺点
• 数据丢失风险:如果 Redis 服务器意外崩溃,可能会丢失最后一次快照之后的数据。
• 阻塞风险:BGSAVE操作可能会阻塞主线程,尤其是在数据集较大的情况下。
AOF(追加日志)持久化原理与配置
原理
• 命令记录:AOF(Append Only File)持久化通过记录每次写操作的命令来实现数据持久化。这些命令会追加到 AOF 文件中。
• 工作流程:
• 写操作命令被追加到 AOF 缓冲区。
• 根据配置的appendfsync策略,将 AOF 缓冲区的内容写入到磁盘。
• always:每次写操作都同步到磁盘,最安全但性能最低。
• everysec:每秒同步一次,平衡了安全性和性能。
• no:由操作系统决定何时同步,性能最高但最不安全。
配置
• 配置文件示例:
conf
# 开启 AOF 持久化
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# AOF 同步策略
appendfsync everysec
# AOF 重写配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb优点
• 数据安全性高:AOF 持久化可以记录每次写操作,即使服务器崩溃,也可以通过重放命令恢复数据。
• 可读性高:AOF 文件是纯文本格式,易于理解和编辑。
缺点
• 文件大小大:AOF 文件会随着时间增长,需要定期重写以保持文件大小。
• 恢复速度慢:AOF 文件较大,恢复数据时需要逐条执行命令,速度较慢。
混合持久化策略与性能权衡
原理
• 混合持久化:Redis 4.0 引入了混合持久化机制,结合了 RDB 和 AOF 的优点。在 AOF 重写时,先以 RDB 格式写入当前数据快照,然后再追加重写期间的新命令。
• 工作流程:
• 启动时,Redis 先加载 RDB 快照,快速恢复大部分数据。
• 然后通过 AOF 日志补全后续的写操作,确保数据的完整性。
配置
• 配置文件示例:
conf
# 开启 AOF 持久化
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# 开启混合持久化
aof-use-rdb-preamble yes
# AOF 同步策略
appendfsync everysec
# AOF 重写配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# RDB 持久化条件
save 900 1
save 300 10
save 60 10000优点
• 快速恢复:RDB 快照可以快速加载大部分数据。
• 数据完整:AOF 日志可以确保数据的完整性。
• 文件紧凑:相比纯 AOF 文件,混合持久化文件更小。
缺点
• 配置复杂:需要同时配置 RDB 和 AOF 的参数,配置较为复杂。
• 性能影响:混合持久化可能会增加 AOF 文件的大小和写入操作的复杂性,需要合理配置以平衡性能和数据安全性。
性能权衡
• RDB vs AOF:
• RDB:恢复速度快,但可能会丢失最后一次快照之后的数据。
• AOF:数据安全性高,但文件较大,恢复速度较慢。
• 混合持久化:结合了 RDB 和 AOF 的优点,提供了更快的恢复速度和更高的数据安全性,但配置复杂,可能会增加文件大小和写入操作的复杂性。
总结
• 选择持久化策略:根据具体的应用场景和需求选择合适的持久化策略。如果对数据丢失容忍度较高,可以选择 RDB;如果需要尽可能保证数据不丢失,可以选择 AOF;如果需要兼顾恢复速度和数据安全性,可以选择混合持久化。
• 合理配置:通过合理配置save和appendfsync等参数,可以在确保数据安全的同时,优化 Redis 的性能。
4. Redis高可用与集群
Redis 提供了多种高可用和分布式解决方案,主要包括主从复制、哨兵模式和 Redis Cluster。这些技术可以有效提高 Redis 的可用性、可靠性和扩展性。
主从复制(Replication)架构
原理
• 主从复制:主从复制是 Redis 高可用的基础,通过一个或多个从服务器(Slave)复制主服务器(Master)的数据来实现数据冗余。
• 工作流程:
• 全量复制:从服务器启动时,会向主服务器发送SYNC命令,主服务器会将当前内存中的数据生成一个 RDB 文件,然后将这个文件发送给从服务器,从服务器加载 RDB 文件完成全量复制。
• 增量复制:全量复制完成后,主服务器会将后续的写操作命令发送给从服务器,从服务器执行这些命令以保持数据同步。
• 部分重同步:如果从服务器与主服务器之间的连接中断,Redis 4.0 引入了部分重同步机制(PSYNC)。从服务器会记录上次复制的偏移量,连接恢复后,主服务器会从上次中断的地方继续发送数据,而不需要重新进行全量复制。
配置
• 主服务器配置:
conf
# 开启主从复制
replicaof <master_ip> <master_port>• 从服务器配置:
conf
# 设置主服务器的 IP 和端口
replicaof <master_ip> <master_port>
# 设置复制的延迟时间
repl-timeout 60
# 设置复制的缓冲区大小
repl-backlog-size 1mb优点
• 数据冗余:通过从服务器备份主服务器的数据,提高数据的可靠性。
• 读写分离:可以将读操作分发到从服务器,减轻主服务器的压力,提高系统的吞吐量。
缺点
• 单点故障:如果主服务器故障,从服务器需要手动切换为主服务器,否则数据将无法写入。
• 数据一致性:在主从复制过程中,可能会出现数据不一致的情况,尤其是在网络延迟或主服务器故障时。
哨兵(Sentinel)模式实现故障转移
原理
• 哨兵模式:哨兵(Sentinel)是 Redis 的高可用解决方案,通过多个哨兵实例监控主从服务器的运行状态,实现自动故障转移。
• 工作流程:
• 监控:哨兵会定期检查主从服务器的运行状态。
• 故障检测:如果主服务器故障,哨兵会检测到并启动故障转移。
• 选举:哨兵之间通过 Raft 算法选举出一个哨兵作为领导者。
• 故障转移:领导者哨兵会将一个从服务器提升为主服务器,并通知其他从服务器和客户端更新主服务器的地址。
配置
• 哨兵配置文件示例:
conf
# 哨兵端口
port 26379
# 监控主服务器
sentinel monitor mymaster <master_ip> <master_port> 2
# 主服务器的密码(如果有)
sentinel auth-pass mymaster <master_password>
# 从服务器的密码(如果有)
sentinel auth-pass mymaster <slave_password>
# 通知客户端主服务器变更
sentinel announce-ip <sentinel_ip>
sentinel announce-port <sentinel_port>优点
• 自动故障转移:哨兵可以自动检测主服务器故障并进行故障转移,提高系统的可用性。
• 高可用性:通过多个哨兵实例,可以避免单点故障,提高系统的可靠性。
缺点
• 配置复杂:哨兵模式的配置相对复杂,需要配置多个哨兵实例并确保它们之间的通信。
• 性能开销:哨兵模式会增加系统的复杂性和性能开销,尤其是在哨兵数量较多时。
Redis Cluster 分片与数据分布
原理
• 分片:Redis Cluster 是 Redis 的分布式解决方案,通过分片(Sharding)将数据分布到多个节点上,实现水平扩展。
• 数据分布:Redis Cluster 使用哈希槽(Hash Slot)来分布数据。总共有 16384 个哈希槽,每个节点负责一部分哈希槽。客户端根据键的哈希值计算出对应的哈希槽,然后将请求发送到对应的节点。
• 工作流程:
• 分片:启动多个 Redis 节点,每个节点负责一部分哈希槽。
• 数据分布:客户端根据键的哈希值计算出对应的哈希槽,将请求发送到对应的节点。
• 故障转移:每个主节点都有一个或多个从节点,当主节点故障时,从节点会被提升为主节点,确保数据的可用性。
配置
• 启动集群节点:
bash
redis-server redis-cluster-node.conf --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes• 创建集群:
bash
redis-cli --cluster create <node1_ip>:<node1_port> <node2_ip>:<node2_port> ... --cluster-replicas 1优点
• 水平扩展:通过分片将数据分布到多个节点上,可以有效提高系统的吞吐量和存储容量。
• 高可用性:每个主节点都有一个或多个从节点,可以实现自动故障转移,提高系统的可用性。
缺点
• 复杂性:Redis Cluster 的配置和管理相对复杂,需要多个节点和从节点。
• 性能开销:集群模式会增加网络通信和数据同步的开销,尤其是在跨机房部署时。
• 数据一致性:在集群模式下,可能会出现数据不一致的情况,尤其是在网络分区或节点故障时。
总结
• 主从复制:适用于简单的数据备份和读写分离场景,但需要手动处理主服务器故障。
• 哨兵模式:适用于需要高可用性和自动故障转移的场景,但配置复杂,性能开销较大。
• Redis Cluster:适用于需要水平扩展和高可用性的场景,但配置和管理复杂,性能开销较大。
5. Redis实战案例
- 缓存穿透/雪崩/击穿解决方案
以下是使用Java和Redis解决缓存穿透、缓存雪崩和缓存击穿问题的详细方案:
缓存穿透
- 缓存空对象
在查询数据库未找到结果时,将空对象或特殊标记存储到缓存中,避免后续重复查询数据库。
java
public Object getData(String key) {
Object value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value == null) {
// 缓存空对象,设置较短的过期时间
redisTemplate.opsForValue().set(key, "NULL", 60, TimeUnit.SECONDS);
return null;
}
redisTemplate.opsForValue().set(key, value);
}
return value;
}- 布隆过滤器
使用布隆过滤器预先存储可能存在的数据ID,查询时先通过布隆过滤器判断是否存在,从而减少对数据库的无效查询。
java
// 初始化布隆过滤器
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
1000000, // 预计插入的元素数量
0.01 // 误判率
);
// 向布隆过滤器添加数据
bloomFilter.put("key1");
bloomFilter.put("key2");
// 查询时先通过布隆过滤器判断
public Object getData(String key) {
if (!bloomFilter.mightContain(key)) {
return null; // 布隆过滤器判断不存在,直接返回
}
Object value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value != null) {
redisTemplate.opsForValue().set(key, value);
}
}
return value;
}缓存雪崩
- 设置不同的过期时间
为缓存设置随机的过期时间,避免大量缓存同时失效。
java
public Object getData(String key) {
Object value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value != null) {
// 设置随机过期时间
int expireTime = 60 + new Random().nextInt(60); // 60-119秒
redisTemplate.opsForValue().set(key, value, expireTime, TimeUnit.SECONDS);
}
}
return value;
}- 使用本地缓存兜底
使用本地缓存(如Guava Cache)作为二级缓存,当Redis缓存失效时,本地缓存可以提供临时数据。
java
// 初始化本地缓存
Cache<String, Object> localCache = CacheBuilder.newBuilder()
.maximumSize(1000) // 最大缓存数量
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.build();
public Object getData(String key) {
// 先查本地缓存
Object value = localCache.getIfPresent(key);
if (value == null) {
// 再查Redis缓存
value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value != null) {
redisTemplate.opsForValue().set(key, value);
}
}
// 将数据写入本地缓存
localCache.put(key, value);
}
return value;
}- 永不过期+后台更新
对于一些不经常更新的数据,可以设置永不过期,并在后台定时更新缓存。
java
// 后台定时更新线程
@Scheduled(fixedDelay = 30 * 60 * 1000) // 每30分钟执行
public void refreshCache() {
List<String> hotKeys = getHotKeysFromMonitor(); // 从监控系统获取热点key
for (String key : hotKeys) {
Object dbValue = queryFromDatabase(key);
redisTemplate.opsForValue().set(key, dbValue); // 不设置过期时间
}
}
// 数据访问逻辑
public Object getData(String key) {
Object value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
redisTemplate.opsForValue().set(key, value); // 永不过期写入
}
return value;
}缓存击穿
- 分布式锁+异步重建
使用分布式锁(如Redisson)确保在缓存失效时只有一个线程去查询数据库并更新缓存,其他线程等待缓存更新完成后再从缓存中获取数据。
java
// 初始化Redisson客户端
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
RedissonClient redisson = Redisson.create(config);
public Object getData(String key) {
Object value = redisTemplate.opsForValue().get(key);
if (value == null) {
RLock lock = redisson.getLock(key);
try {
if (lock.tryLock()) {
// 再次检查缓存
value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value != null) {
redisTemplate.opsForValue().set(key, value);
}
}
}
} finally {
lock.unlock();
}
}
return value;
}- 延长缓存过期时间
对于热点数据,可以适当延长缓存的过期时间,减少缓存失效的频率。
java
public Object getData(String key) {
Object value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value != null) {
// 设置较长的过期时间
redisTemplate.opsForValue().set(key, value, 24, TimeUnit.HOURS);
}
}
return value;
}- 使用多级缓存架构
结合本地缓存和Redis缓存,当Redis缓存失效时,本地缓存可以提供临时数据,同时异步更新Redis缓存。
java
// 初始化本地缓存
Cache<String, Object> localCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
public Object getData(String key) {
// 先查本地缓存
Object value = localCache.getIfPresent(key);
if (value == null) {
// 再查Redis缓存
value = redisTemplate.opsForValue().get(key);
if (value == null) {
value = queryFromDatabase(key); // 查询数据库
if (value != null) {
redisTemplate.opsForValue().set(key, value); // 更新Redis缓存
}
}
// 将数据写入本地缓存
localCache.put(key, value);
}
return value;
}分布式锁实现(Redlock算法)
依赖准备
在项目中添加Jedis依赖(Maven):
xml
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.1</version>
</dependency>核心实现代码
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.params.SetParams;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class RedLock {
private List<Jedis> jedisNodes;
private String lockKey;
private String lockValue;
private int lockTime; // 锁持有时间(毫秒)
private int retryCount; // 重试次数
private long retryDelay; // 重试间隔(毫秒)
public RedLock(List<String> redisUrls, String lockKey, int lockTime, int retryCount, long retryDelay) {
this.jedisNodes = new ArrayList<>();
for (String url : redisUrls) {
String[] parts = url.split(":");
Jedis jedis = new Jedis(parts[0], Integer.parseInt(parts[1]));
this.jedisNodes.add(jedis);
}
this.lockKey = lockKey;
this.lockTime = lockTime;
this.retryCount = retryCount;
this.retryDelay = retryDelay;
this.lockValue = UUID.randomUUID().toString();
}
public boolean lock() {
int successCount = 0;
long startTime = System.currentTimeMillis();
for (int i = 0; i < retryCount; i++) {
successCount = 0;
for (Jedis jedis : jedisNodes) {
try {
SetParams params = SetParams.setParams().nx().px(lockTime);
String result = jedis.set(lockKey, lockValue, params);
if ("OK".equals(result)) {
successCount++;
}
} catch (Exception e) {
// 节点异常,跳过
}
}
// 检查是否获得多数节点锁
if (successCount > jedisNodes.size() / 2) {
// 检查锁获取时间是否有效
long elapsed = System.currentTimeMillis() - startTime;
if (elapsed < lockTime) {
return true;
}
// 超时则释放锁
unlock();
break;
}
// 释放部分已获得的锁
for (Jedis jedis : jedisNodes) {
try {
jedis.del(lockKey);
} catch (Exception e) {
// 忽略异常
}
}
// 等待重试
try {
Thread.sleep(retryDelay);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
return false;
}
public void unlock() {
for (Jedis jedis : jedisNodes) {
try {
// 使用Lua脚本确保原子性删除
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +
"return redis.call('del', KEYS[1]) " +
"else return 0 end";
jedis.eval(script, 1, lockKey, lockValue);
} catch (Exception e) {
// 忽略异常
}
}
}
public void close() {
for (Jedis jedis : jedisNodes) {
try {
jedis.close();
} catch (Exception e) {
// 忽略异常
}
}
}
}使用示例
java
public class Main {
public static void main(String[] args) {
List<String> redisNodes = new ArrayList<>();
redisNodes.add("127.0.0.1:6379");
redisNodes.add("127.0.0.1:6380");
redisNodes.add("127.0.0.1:6381");
RedLock redLock = new RedLock(redisNodes, "my_resource", 30000, 3, 100);
try {
if (redLock.lock()) {
// 执行业务逻辑
System.out.println("Lock acquired, doing work...");
Thread.sleep(1000);
} else {
System.out.println("Failed to acquire lock");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
redLock.unlock();
redLock.close();
}
}
}关键实现说明
锁获取机制
- 尝试从多数Redis节点获取锁
- 使用SET命令的NX(不存在才设置)和PX(过期时间)选项
- 每个锁设置唯一值(UUID)用于安全释放
锁释放机制
- 使用Lua脚本确保只有锁的持有者才能释放
- 原子性检查值并删除键
- 即使部分节点不可用也能保证安全性
容错处理
- 允许部分节点失败(不超过半数)
- 自动重试机制避免瞬时故障
- 锁获取时间有效性检查
注意事项
- Redis节点应该部署在不同物理机器上
- 锁持有时间应该大于业务处理时间
- 需要合理设置重试次数和间隔
- 生产环境建议使用连接池代替直接创建Jedis实例
这个实现遵循了Redlock算法的核心原则,提供了基本的分布式锁功能。在实际生产环境中,可能需要根据具体需求进行扩展和优化。