点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月01日更新到: Java-113 深入浅出 MySQL 扩容全攻略:触发条件、迁移方案与性能优化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- RDD的介绍
- RDD的特点、特点介绍
- Spark 编程模型的介绍

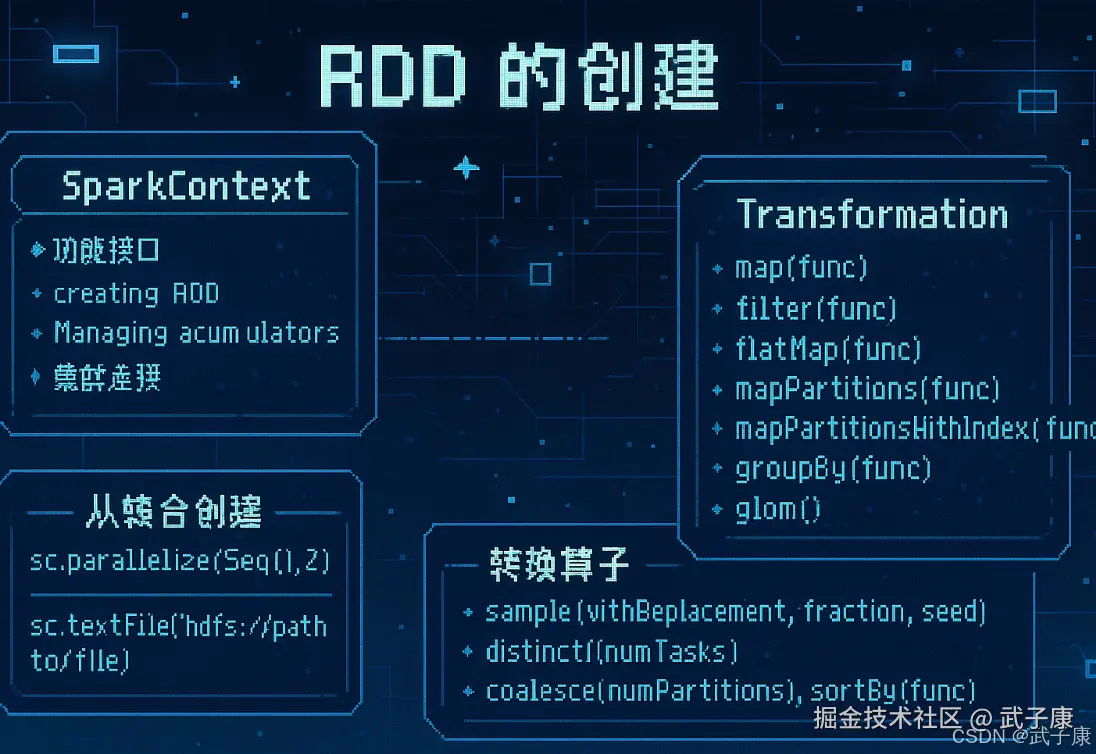
RDD 的创建
SparkContext
SparkContext是Spark应用程序的核心组件,也是编写Spark程序时需要用到的第一个类。作为Spark的主要入口点,它承担着与整个集群交互的重要职责。
核心功能与定位
-
客户端与服务端模型
- 如果把Spark集群比作服务端,那么Driver程序就是客户端,而SparkContext就是这个客户端的核心引擎
- 例如:当提交一个Spark作业时,Driver程序中的SparkContext会负责与集群管理器(如YARN、Mesos或Standalone)建立连接
-
功能接口
- SparkContext是Spark对外的统一接口,为开发者提供访问Spark各种功能的入口
- 具体功能包括:
- 创建RDD(弹性分布式数据集)
- 管理累加器(Accumulators)
- 处理广播变量(Broadcast Variables)
- 配置Spark运行参数
- 作业调度与任务分配
-
集群连接
- 负责建立与Spark集群的连接
- 管理应用程序与集群资源管理器(如YARN ResourceManager)的通信
- 示例:在初始化时会指定master URL(如spark://host:port, local等)
典型使用场景
-
RDD操作
- 通过SparkContext可以:
- 从外部存储系统(如HDFS、S3)创建RDD:
sc.textFile("hdfs://path/to/file") - 并行化集合:
sc.parallelize(Seq(1,2,3))
- 从外部存储系统(如HDFS、S3)创建RDD:
- 通过SparkContext可以:
-
共享变量管理
- 累加器(用于聚合信息):
scalaval accum = sc.longAccumulator("My Accumulator")- 广播变量(高效分发大对象):
scalaval broadcastVar = sc.broadcast(Array(1, 2, 3)) -
资源配置
- 设置应用程序配置:
scalaval conf = new SparkConf() .setAppName("MyApp") .setMaster("local[4]") val sc = new SparkContext(conf)
注意:在Spark 2.0+版本中,SparkSession已成为新的入口点,但在底层仍会创建SparkContext。对于RDD操作,仍然需要直接使用SparkContext。
从集合创建RDD
我们在集群的节点上启动 Spark-Shell 进行学习和测试
shell
spark-shell --master local[*]如果顺利启动,你就可以看到如下的画面: 
尝试运行如下的指令,感受一下
shell
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_412)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,5))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd2.getNumPartitions
res1: Int = 2
scala> rdd2.partitions.length
res2: Int = 2
scala> val rdd3 = sc.makeRDD(List(1,2,3,4,5))
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at makeRDD at <console>:24
scala> val rdd4 = sc.makeRDD(1 to 100)
rdd4: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at makeRDD at <console>:24
scala> rdd4.getNumPartitions
res3: Int = 2
scala> 对应的截图如下: 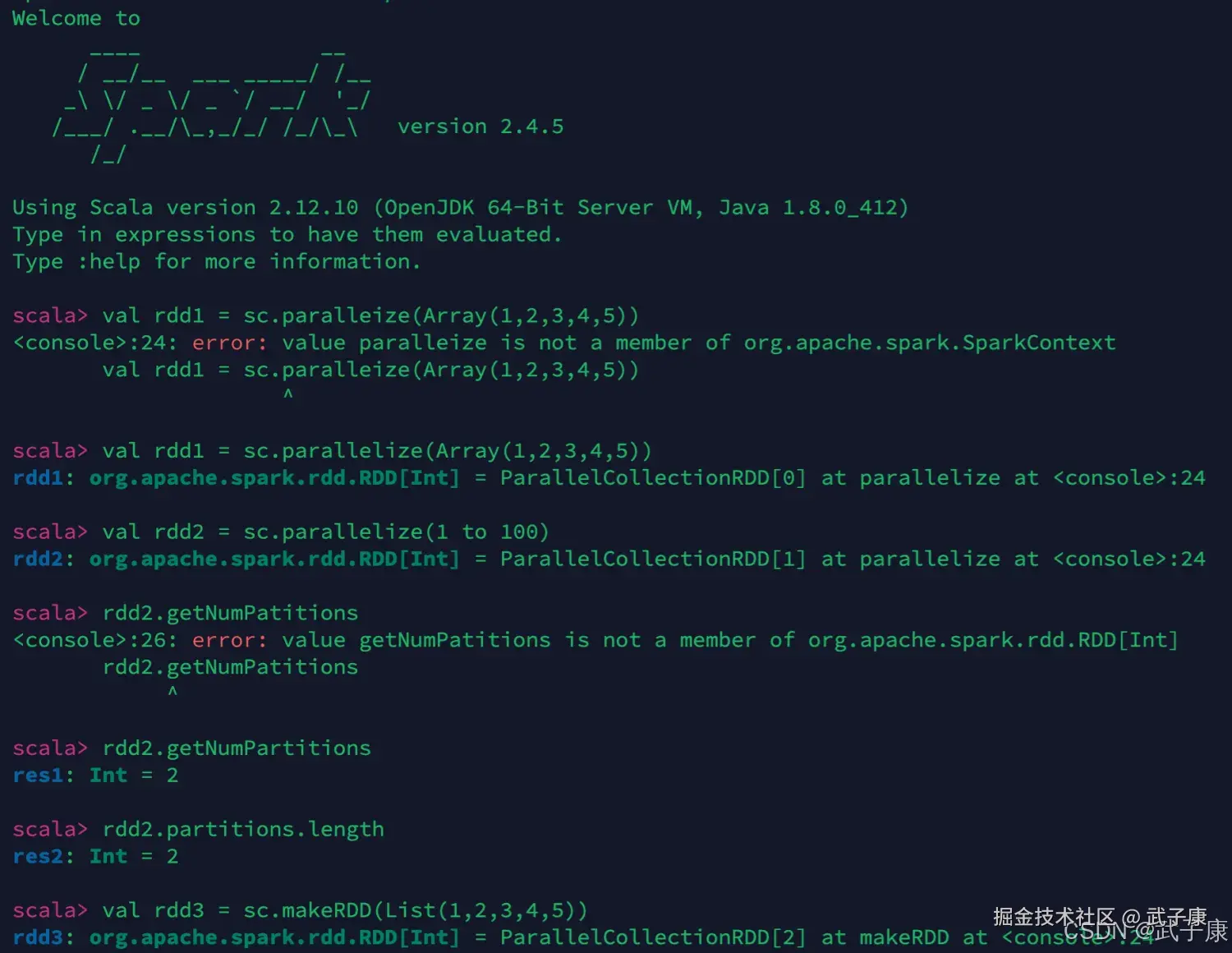
从文件系统创建RDD
用 textFile() 方法来从文件系统中加载数据创建RDD,方法将文件的URI作为参数:
- 本地文件系统
- 分布式文件系统 HDFS
- Amazon S3的地址
shell
# 本地系统 注意文件要确保存在
val lines = sc.textFile("file:///opt/wzk/1.txt")
# 从分布式文件系统加载
val lines = sc.textFile("hdfs://h121.wzk.icu:9000/wcinput/wordcount.txt")运行结果如下图所示: 
从RDD创建RDD
本质是将一个RDD转换为另一个RDD,从 Transformation
Transformation
RDD的操作算子分为两类:
- Transformation,用来对RDD进行转换,这个操作时延迟执行的(或者是Lazy),Transformation,返回一个新的RDD
- Action,用来触发RDD的计算,得到相关计算结果或者将结果保存到外部系统中,Action:返回int、double、集合(不会返回新的RDD)
每一个Transformation操作都会产生新的RDD,供给下一个"转换"使用 转换得到RDD是惰性求值,也就是说,整个转换过程只有记录了转换的轨迹,并不会发生真正的计算,只有遇到Action操作时,才会发生真正的计算,开始从学院关系(lineage)源头开始,进行物理的转换操作。
常见转换算子1
map(func)
-
功能:对RDD中的每个元素应用func函数,生成一个包含转换结果的新RDD
-
示例 :将整型RDD中的每个元素加1
scalaval rdd = sc.parallelize(List(1, 2, 3)) val mapped = rdd.map(x => x + 1) // 结果:List(2, 3, 4) -
特点:输入输出元素一一对应,不改变数据量
filter(func)
-
功能:筛选出使func返回true的元素组成新RDD
-
示例 :过滤出偶数
scalaval filtered = rdd.filter(x => x % 2 == 0) // 输入List(1,2,3),输出List(2) -
应用场景:数据清洗、异常值过滤等
flatMap(func)
-
功能:每个输入元素可映射为0或多个输出元素(返回一个序列)
-
示例 :将每行文本拆分为单词
scalaval lines = sc.parallelize(List("hello world", "hi")) val words = lines.flatMap(_.split(" ")) // 输出:List("hello", "world", "hi") -
与map区别:map保持1:1映射,flatMap允许1:N映射
mapPartitions(func)
-
功能:以分区为单位处理数据,func接收一个迭代器(代表整个分区)
-
性能优势 :适合需要初始化资源的操作(如数据库连接)
scalaval partitioned = rdd.mapPartitions(iter => { // 每个分区初始化一次数据库连接 val conn = createConnection() iter.map(x => processWithDB(x, conn)) }) -
注意事项:需确保迭代器被完全消费,否则可能导致资源泄漏
mapPartitionsWithIndex(func)
-
功能:在mapPartitions基础上增加分区索引参数
-
典型应用 :调试时查看数据分布
scalardd.mapPartitionsWithIndex((index, iter) => { println(s"Processing partition $index") iter.map(x => x * index) }) -
参数说明:func接收(Int, IteratorT) => IteratorU,第一个参数是分区索引
性能比较
| 算子 | 调用次数 | 适用场景 |
|---|---|---|
| map | N次(元素级) | 简单转换 |
| mapPartitions | M次(分区级) | 需要资源初始化的批量操作 |
| flatMap | N次 | 数据展开或过滤 |
注意:mapPartitions系列算子可能引起内存问题,因为需要将整个分区数据加载到内存。
转换算子1测试
map filter
测试如下的代码:
shell
val rdd1 = sc.parallelize(1 to 10)
val rdd2 = rdd1.map(_*2)
val rdd3 = rdd2.filter(_>10)执行结果如下图: 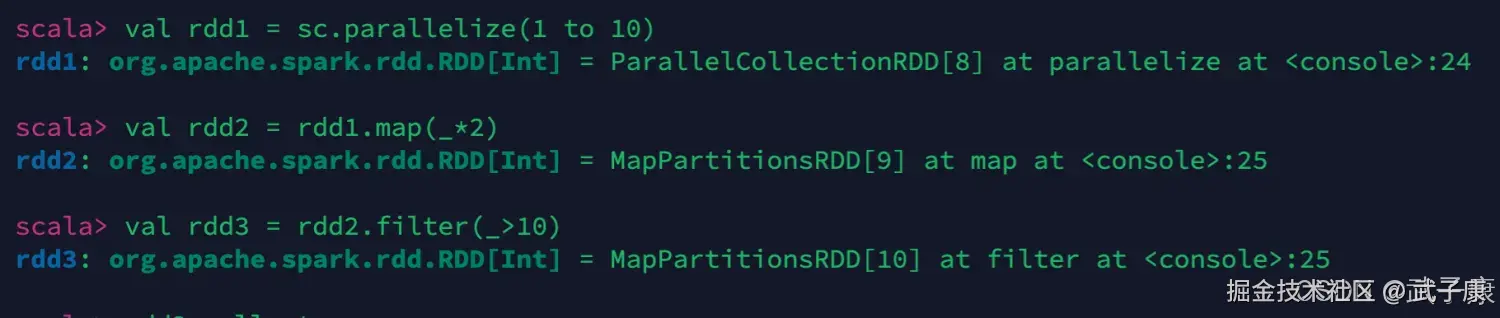 我们可以查看当前的结果,但是当前的操作都是Transformation的,并没有真正的执行。 我们需要通过 collect 触发执行,拿到最终的结果
我们可以查看当前的结果,但是当前的操作都是Transformation的,并没有真正的执行。 我们需要通过 collect 触发执行,拿到最终的结果
shell
rdd2.collect
rdd3.collect将会触发执行,可以看到结果为: 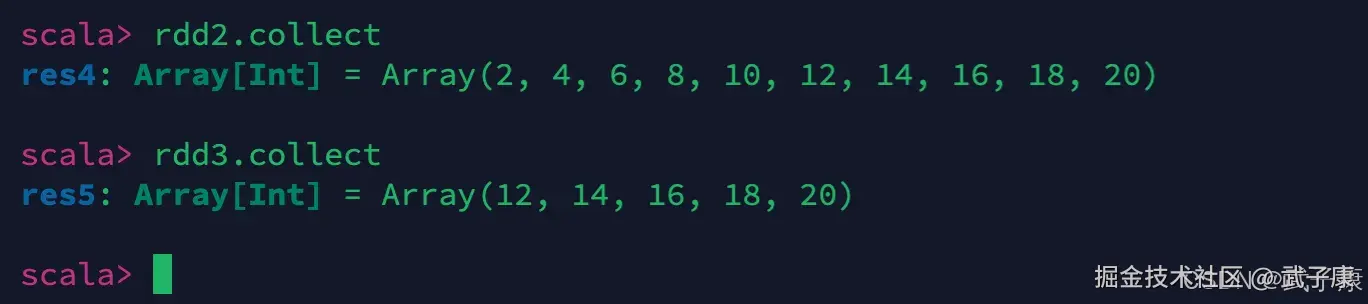
flatMap
我们从HDFS加载一个文件过来
shell
val rdd4 = sc.textFile("hdfs://h121.wzk.icu:9000/wcinput/wordcount.txt")
rdd4.collect执行结果如下图:  我们使用"a"作为分隔符,对这段内容进行分割:
我们使用"a"作为分隔符,对这段内容进行分割:
shell
rdd4.flatMap(_.split("a")).collect执行结果如下图: 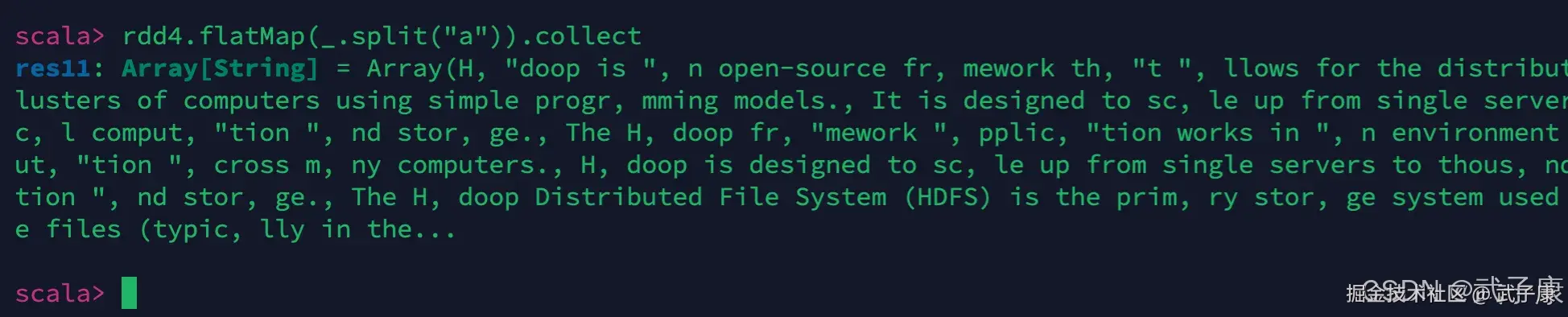
mapPartitions
shell
val rdd5 = rdd1.mapPartitions(iter => iter.map(_*2))执行结果如下 
对比 map 和 mapPartitions
上面我们用:
- rdd1.map(_*2)
- rdd1.mapPartitions(iter => iter.map(_*2))
那么这两种有什么区别呢?
- map:每次只处理一条数据
- mapPartitions:每次处理一个分区的数据,分区的数据处理完成后,数据才能释放,资源不足时容易OOM
- 当资源充足时,建议使用 mapPartitions,充分提高处理效率
常见转换算子2
- groupBy(func):按照传入函数的返回值进行分组,将key相同的值放入一个迭代器
- glom():将每一个分区形成一个数组,形成新的RDD类型RDDArray\[T]
- sample(withReplacement,fraction,seed):采样算子,以指定的随机数种子seed随机抽样出数量为fraction的数据,withReplacenent表示抽出数据是否放回,true则放回,false不放回
- distinct(numTasks):对RDD元素去重后,返回一个新的RDD,可传入numTasks参数改变RDD分区数
- coalesce(numPartitions):缩减分区数,没有shuffle
- repartition(numPartitions):增加或减少分区数,有shuffle
- sortBy(func,ascending, numTasks):使用func对数据进行处理,对处理后的结果进行排序
宽依赖的算子(shuffle):groupBy,distinct、repartition、sortBy
转换算子2测试
group by
shell
val rdd1 = sc.parallelize(1 to 10)
val group = rdd1.groupBy(_%3)
group.collect执行的结果如下图: 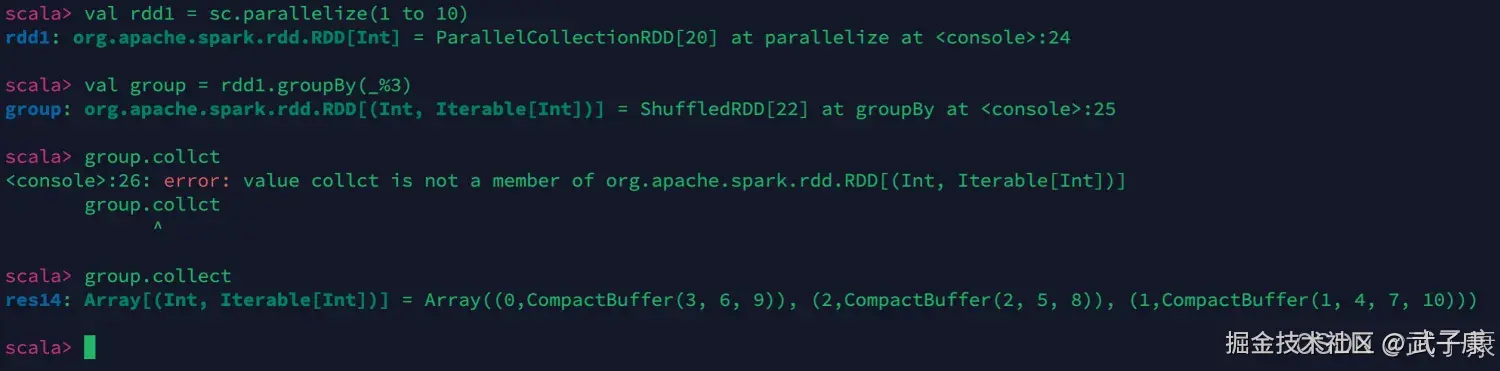
glom.map
将 RDD 中元素的每10个元素分组
shell
val rdd1 = sc.parallelize(1 to 101)
val rdd2 = rdd1.glom.map(_.sliding(10, 10).toArray)
rdd2.collect执行结果如下图: 
sample
对数据采样,fraction表示采样的百分比
shell
rdd1.sample(true, 0.2, 2).collect
rdd1.sample(false, 0.2, 2).collect
rdd1.sample(true, 0.2).collect执行结果如下图: 
distinct
对数据进行去重,我们生成一些随机数,然后对这些数值进行去重。
shell
val random = scala.util.Random
val arr = (1 to 20).map(x => random.nextInt(10))
val rdd = sc.makeRDD(arr)
rdd.distinct.collect执行结果如下图: 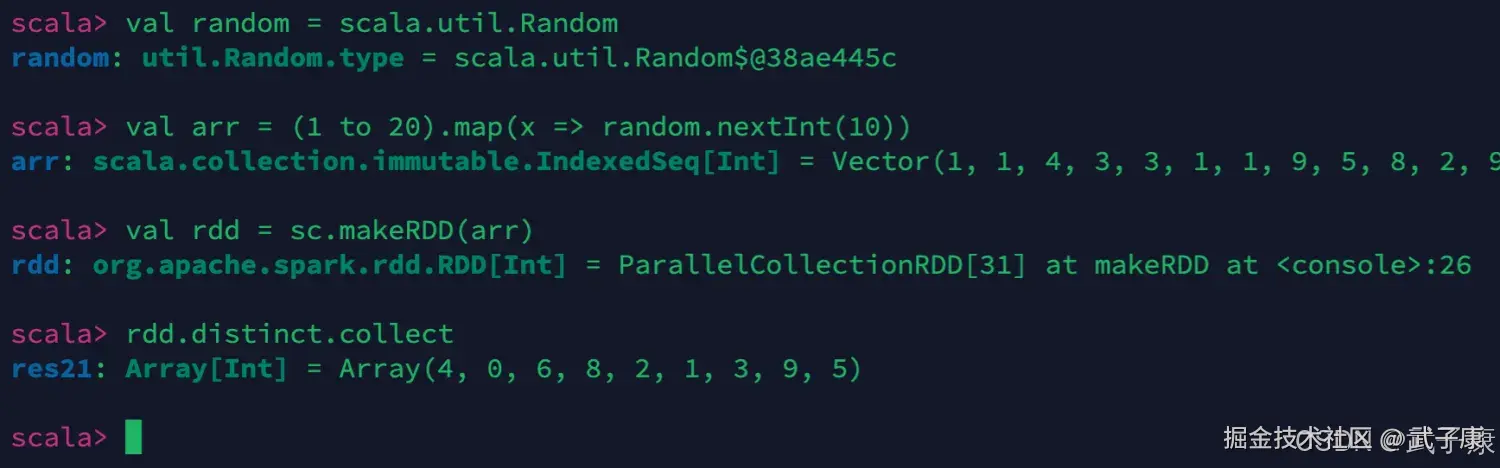
numSlices
对RDD重分区,我们需要多分一些区出来
shell
val rdd1 = sc.range(1, 1000, numSlices=10)
val rdd2 = rdd1.filter(_%2==0)
rdd2.getNumPartitions执行结果如下图: 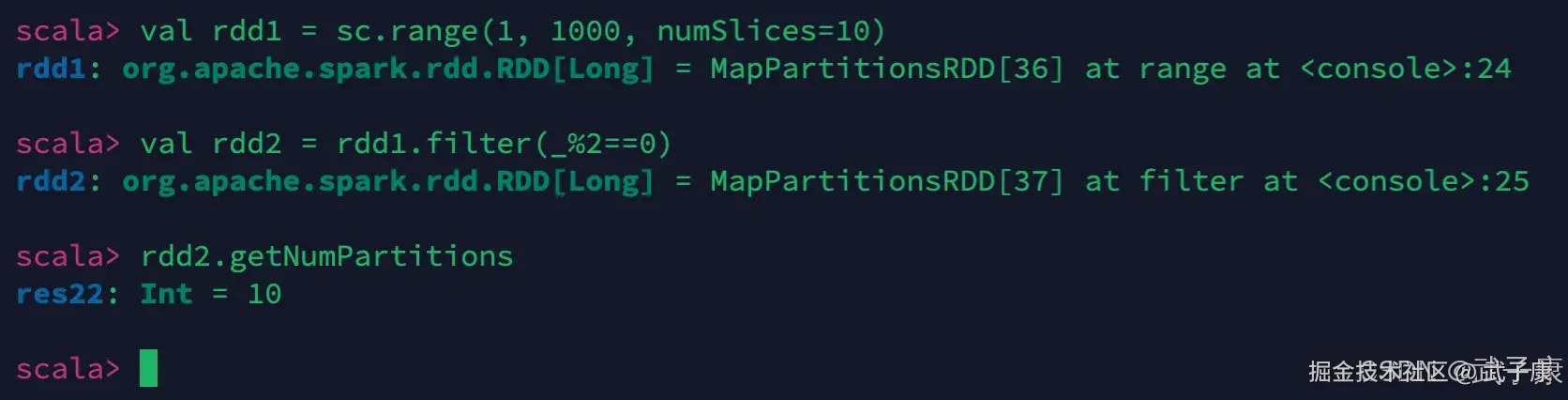
repartition & coalesce
增加或者减少分区
shell
rdd2.getNumPartitions
# repartition 是增加和缩减分区数
val rdd3 = rdd2.repartition(5)
# coalesce 是缩减分区数
val rdd4 = rdd2.coalesce(5)执行结果如下图: 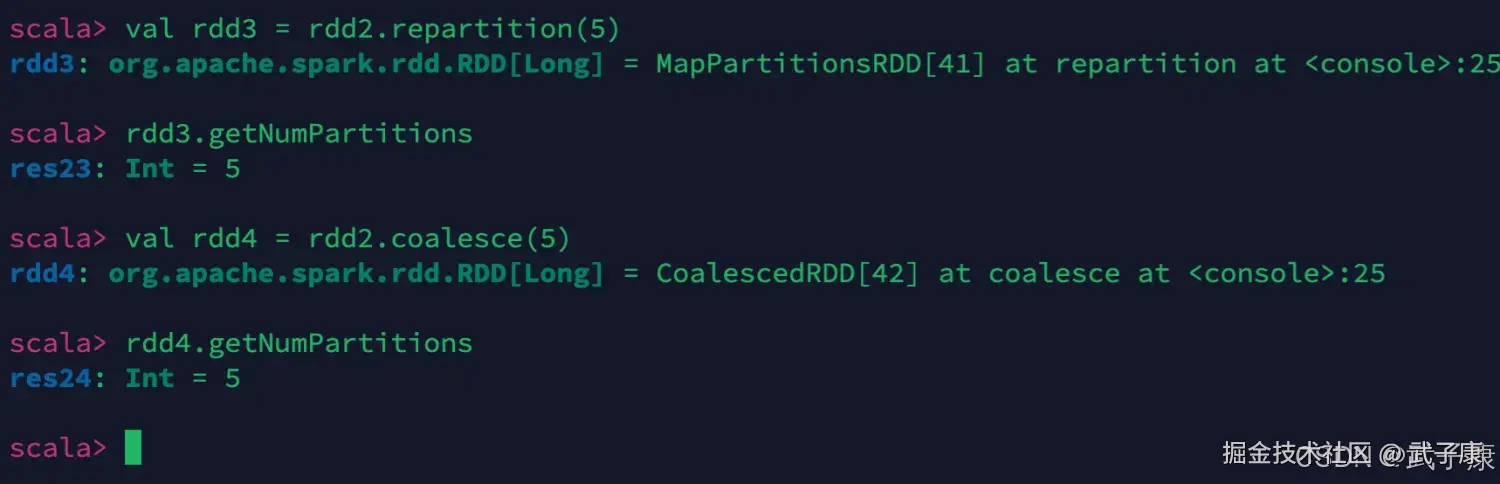
sortBy
shell
rdd.sortBy(x => x).collect
rdd.sortBy(x => x).collect执行结果如下: 
coalesce & repartition
- repartition:增大或者减少分区数,有shuffle
- coalesce:一般用于减少分区数(此时无shuffle)