第51届 VLDB Conference 将于9月1日至9月5日在英国伦敦召开,VLDB 作为数据库领域的顶级会议,展示当前数据库研究的前沿方向,具有广泛的国际影响力。阿里云大数据AI平台共有3篇论文被 VLDB 2025 收录,研究方向包括 Flink 2.0 存算分离、跨窗口对比学习异常检测和多模态慢查询根因排序。
一、Flink 2.0 存算分离
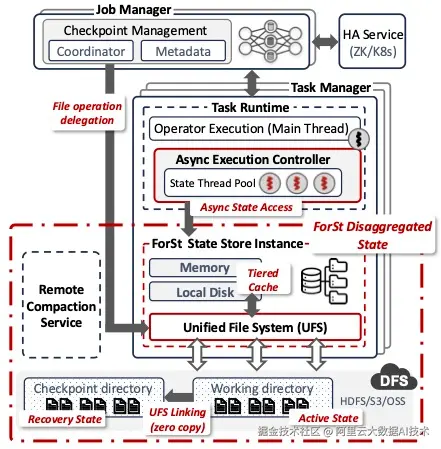
Flink 2.0 存算分离技术整体架构图
论文《Disaggregated State Management in Apache Flink® 2.0》提出并实现了全新的"解耦式状态管理架构",从根本上解决了传统存算一体架构下快照开销大、状态恢复慢、资源耦合导致成本高等长期痛点,标志着 Flink 在分布式流处理系统架构演进上的又一次重大突破,也为其全面迈向云原生时代奠定了坚实基础。
随着实时数据处理和实时 AI 应用的迅猛发展,Flink 已成为全球主流的流计算引擎。然而,在面对 TB 级状态规模时,原有状态管理机制暴露出扩展性受限、Checkpoint 占用资源高、恢复时间长等问题。
在阿里云计算平台实时计算 Flink 团队、Apache Flink 社区以及多位学术界研究人员的共同努力下,Flink 2.0 创新性地引入解耦式状态管理(Disaggregated State Management) 架构,将状态存储与计算资源分离,利用高性价比的对象存储实现状态共享与持久化,显著提升系统的可扩展性、容错效率和资源利用率。本工作两大核心技术突破为新架构提供了坚实支撑:一是统一异步执行框架(Asynchronous Execution Framework) ,支持非阻塞状态访问与并行异步操作,在降低延迟的同时保障 Exactly-Once 语义,且完全兼容 Flink 1.x 编程模型;二是全新自研的解耦式状态存储引擎 ForSt(For Streaming),通过统一的 LSM-tree 抽象融合本地与远程状态访问,实现状态副本统一管理、秒级快照生成与瞬时恢复能力,大幅提升作业稳定性与运维效率。
展望未来,希望能通过 ForSt 存储引擎的批量计算下推等能力进一步降低流计算的成本,兼具时效性和低成本的能力,开启 Flink 近实时计算的新纪元,真正做到实时计算的普惠。
论文信息:
-
标题:《Disaggregated State Management in Apache Flink® 2.0》
-
作者:Yuan Mei, Zhaoqian Lan, Lei Huang, Yanfei Lei, Han Yin, Rui Xia, Kaitian Hu, Paris Carbone, Vasiliki Kalavri, Feng Wang
了解更多请前往 mp.weixin.qq.com/s/E1mt_we0E...
二、面向Flink集群巡检的交叉对比学习异常检测
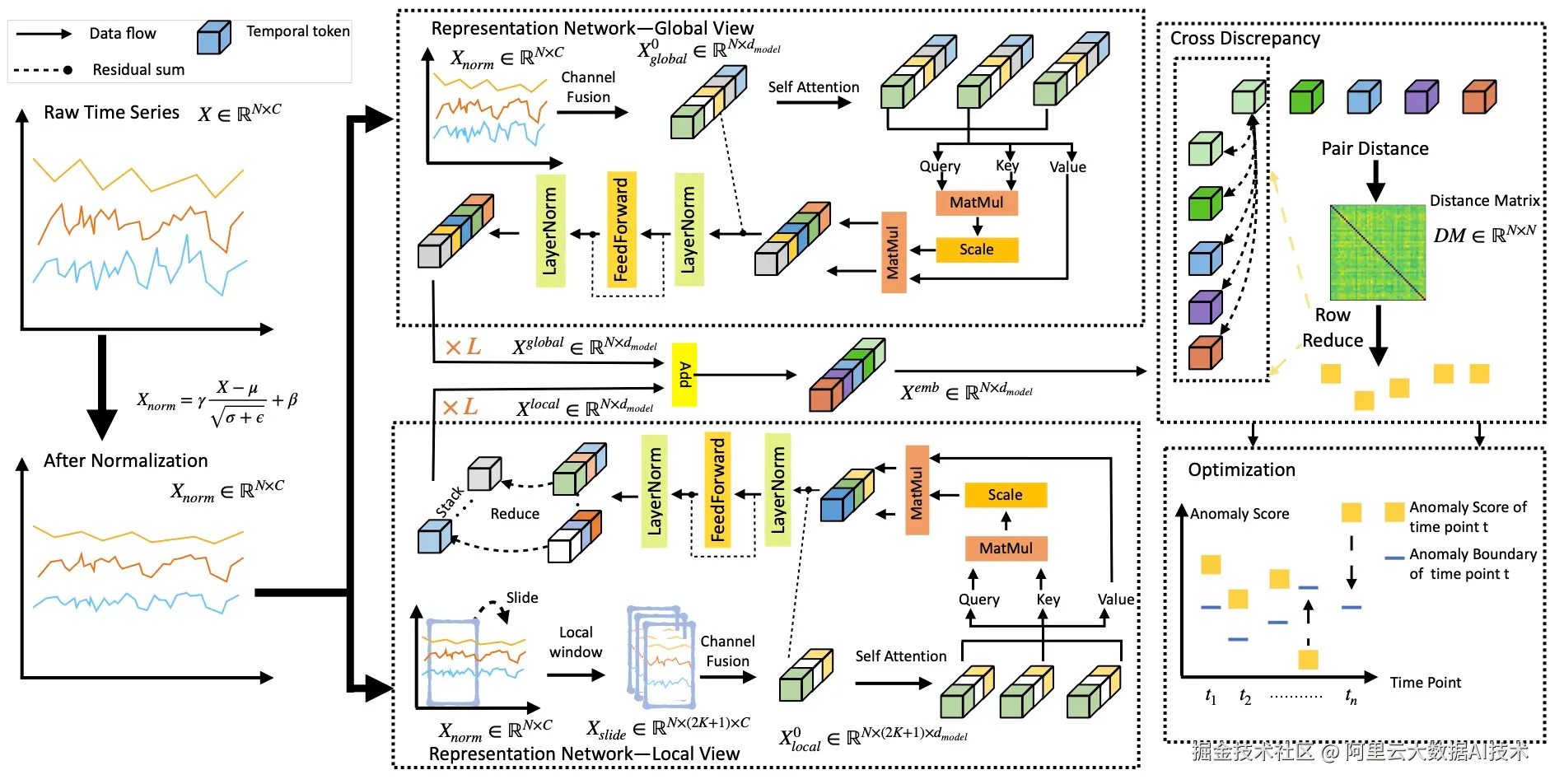
Noise Matters 技术整体架构图
论文《Noise Matters: Cross Contrastive Learning for Flink Anomaly Detection》针对 Flink 大规模流式计算集群中的"热点机器"问题,提出了一种全新的基于神经网络的无监督异常检测框架,在真实生产环境中显著提升了对复杂异常模式的识别能力,相比当前最先进的 UTAD 方法平均 F1 Score 提升达 12.1%。
Flink 集群在运行过程中常出现某些节点负载持续升高、作业延迟不断累积的现象,即"热点"问题,严重影响系统稳定性。然而,现有无监督异常检测方法在该场景下表现不佳,主要原因有两点:一是难以有效捕捉 Flink 特有的缓慢上升型或长期高水平异常;二是实际采集的训练数据中普遍存在噪声和未标注的异常,导致模型将异常模式误学为正常行为,影响检测准确性。
针对上述挑战,阿里云计算平台大数据基础工程技术团队主导,和华东师范大学数据科学与工程学院一同提出一种跨窗口的对比学习(Cross Contrastive Learning) 方法,不再依赖传统的重构误差或单时间点视图差异,而是通过注意力机制学习时间序列的全局与局部表征,并在相邻时间戳的潜在表示之间引入对比机制。当出现缓慢上升等异常趋势时,模型会放大其表示距离,从而增强对这类模式的敏感性。此外,团队还设计了一种基于异常边界的先验感知损失函数,利用归一化观测分数作为先验知识,动态调节不同时间点的优化程度------对疑似异常点限制损失下降幅度,防止其被过度拟合,从而有效缓解噪声数据对训练过程的干扰。
目前,Noise Matters 技术已经整合进了 Flink 集群智能巡检体系中,有效地帮助运维人员对集群运行健康状况进行评估,提前发现可能的风险隐患。
论文信息:
-
标题:《Noise Matters: Cross Contrastive Learning for Flink Anomaly Detection》
-
作者:Zhihao Zhuang, Yingying Zhang, Kai Zhao, Chenjuan Guo, Bin Yang, Qingsong Wen, Lunting Fan
了解更多请前往 mp.weixin.qq.com/s/2mvxOvBoN...
三、面向云计算平台的多模态慢查询根因排序
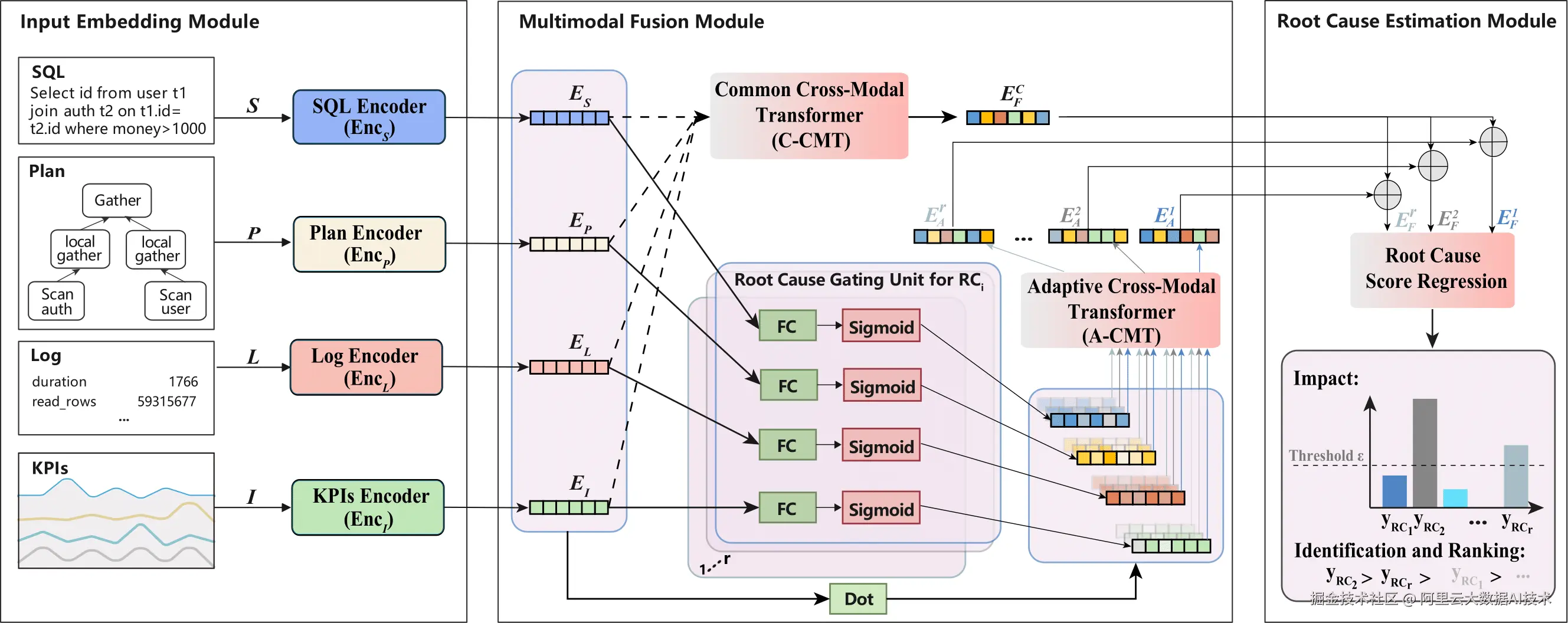
RCRank 技术整体架构图
论文《Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems 》针对云数据库 Hologres 中的慢查询问题,提出了一种多模态根因分析框架 RCRank,能够自动识别慢查询的根本原因并按其性能影响程度进行排序。相比现有最先进方法,RCRank 平均提升慢查询优化效率达 14%。
在云数据库场景中,慢查询不仅影响用户体验,还可能导致业务延迟和成本上升。尽管已有方法能识别慢查询的潜在根因类型(如索引缺失、执行计划不佳等),但仍存在两大瓶颈:一是缺乏对根因"影响程度"的量化评估,难以判断哪些根因优化后收益最大;二是依赖单一性能指标(如 CPU、内存),忽视了查询语句、执行计划、执行日志等多源信息,导致观测不完整,影响分析准确性。
为此,阿里云计算平台大数据基础工程技术团队主导,同华东师范大学数据科学与工程学院合作,提出 RCRank 框架,首次将根因影响估计与多模态融合学习相结合。系统通过规则引擎与大语言模型(LLM)协同分析,构建带有真实影响分数的根因数据集------即通过修复根因前后的执行时间差,量化其优化效果。在此基础上,模型融合查询语句、执行计划、执行日志和关键性能指标四种模态数据,利用预训练编码与交叉特征提取器实现多模态表征融合,并预测每个根因对查询性能的影响大小,最终输出可解释的根因重要性排序列表。
目前,RCRank 已具备落地能力,后续将与 Hologres 现有的实例诊断系统深度融合,助力用户快速定位高价值优化点,提升数据库运维智能化水平。
论文信息:
-
标题:《Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems》
-
作者:Biao Ouyang, Yingying Zhang, Hanyin Cheng, Yang Shu, Chenjuan Guo, Bin Yang, Qingsong Wen, Lunting Fan, Christian S. Jensen
了解更多请前往 mp.weixin.qq.com/s/3f4rUguqe...
现场交流
如您希望在 VLDB 2025 现场,与我们交流以上研究成果。请关注以下分享时间:
- Disaggregated State Management in Apache Flink® 2.0
Industry 1,Room: Moore (4F) Distributed Systems,Tue 10:45 - 12:15,Day 2 : Tuesday, Sept 2
- Noise Matters: Cross Contrastive Learning for Flink Anomaly Detection
Research 25(Time Series Data III), Room: Rutherford (4F), Day 3 : Wednesday, Sept 3, 10:45 -12:15
- RCRank: Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems
Research 59(Distributed and Streaming Data Processing), Room: Moore (4F), Day 4 : Thursday, Sept 4, 15:45 - 17:15