目录
Redis常见的基本数据类型包括String、List、Hash、Set、ZSet;除此之外,例如BitMap、Stream也是十分常见的数据类型。
String
String是最基本的key-value结构,其中key是唯一标识,value是具体的值。
内部实现
String类型的底层数据结构主要是int和SDS。字符串对象的内部编码方式有三种:int、raw和embstr:
· 如果一个字符串对象保存的是整数值 ,并且这个值可以用long类型来表示,则字符串对象会将整个数值保存在字符串对象的ptr属性中(将void*转换成long),并将字符串对象的编码设置为int;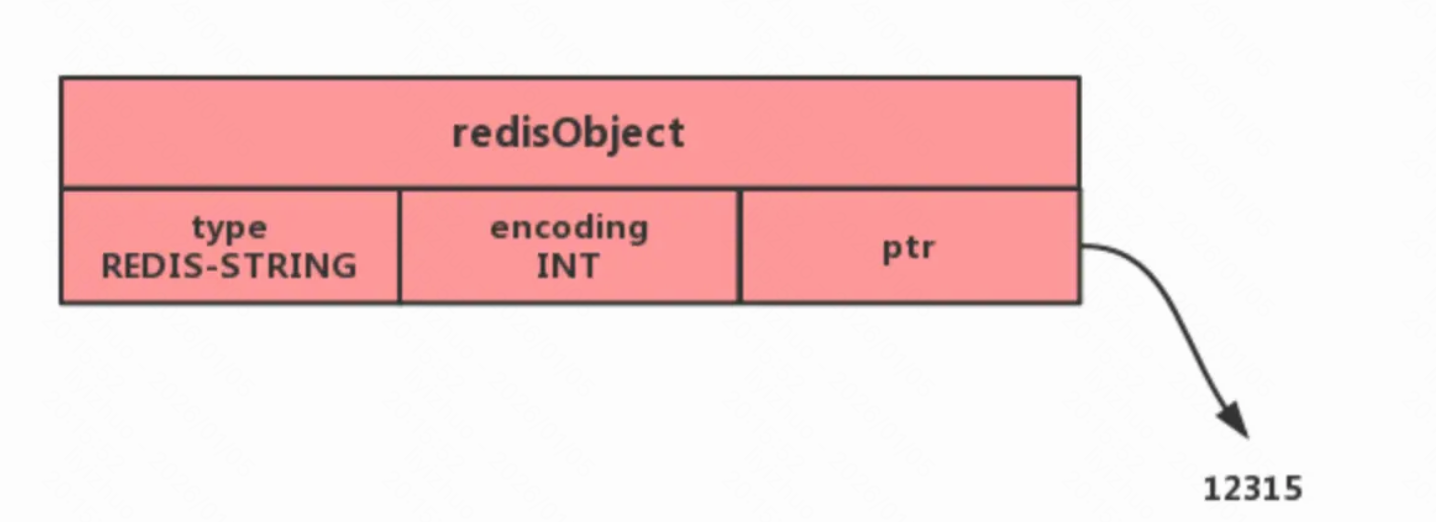
**·**如果字符串对象保存的是一个字符串,且这个字符串的长度小于等于32字节,则字符串对象会使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码方式设置为embstr,embstr是一种专门用于保存短字符串的一种优化编码方式;
**·**如果字符串对象保存的是一个字符串,且这个字符串的长度大于32字节,则字符串对象使用SDS来保存这个字符串,并将编码格式设置为raw。
这个长度在不同redis版本是不同的。在redis 2.+是32字节,redis3.0 - 4.0是39字节,redis5.0+是44字节。
embstr和raw编码格式的区别主要在于:embstr只需要分配一次内存,其会通过一次内存分配函数来分配一块连续的空间保存redisObject和SDS;而rwa编码方式会分配两次内存,来分别存储redisObject和SDS动态字符串。
很显然,embstr的优点是只需分配一次内存,也只需要释放一次内存,而且其将字符串对象所有的数据都保存在一块连续的内存,可以减少内存碎片,提高CPU缓存命中率。但其缺点embstr编码的字符串对象是只读的,不支持修改,如果修改会转换为raw编码。
raw编码可以动态修改,支持追加、截断等操作,无需重新分配RedisObject,兼容性比较好。
常用指令
# 设置 key-value
set key test
# 根据 key 获得对应的value
get key
# 判断 key 是否存在
exists key
# 返回 key 所存储的字符串值的长度
strlen key
# 删除 key 对应的值
del key
# 批量设置 key
mset key1 value1 key2 value2
# 分别获取 key1 和 key2
get key1
get key2
#批量获取 key1 和 key2
mget key1 key2
应用场景
1、做缓存:通常情况下,使用redis的String类型来作为缓存,例如在手机号登陆时,使用redis来缓存验证码,再通过EX参数给其设置验证码过期时间,例如60s过期。又例如,在项目中,使用String类型来缓存活动信息、中奖信息等;
2、实现分布式锁:key为锁,value为客户端的唯一标识。set命令有个NX参数可以实现 key不存在才插入,可以利用其来实现分布式锁,并结合EX参数来设置过期时间,防止一个服务持有分布式锁时服务挂了的情况。在释放锁时,由于首先需要判断当前客户端是否是持有锁的客户端,如果是,再删除,因此这个操作不是原子性的,可以通过Lua脚本来保证原子性。
// Lua脚本,先判断
if redis.call("get", key) == value then
return redis.call("del", key)
else
return 0;
end3、共享Session信息:在开发项目时,通常会使用Session来保存用户的会话状态,这些session信息是存储在服务端的,只适合于单系统应用,不适合微服务/分布式系统。
就比如服务器1保存的用户A的session信息,但用户A第二次访问时被分配到了服务器2,此时服务器2没有用户A的session信息,就需要重新登录,主要是因为分布式系统每次会将请求随机分配到不同的服务器。
因此,可以使用redis来存储这些session信息,进行统一的存储与管理,无论请求到哪台服务器,服务器都会去同一个redis服务器去获取相关的session信息,就可以解决分布式系统下session的存储问题。
List
List列表时简单的字符串列表,按照插入顺序排序,可以从头部或者尾部向List列表添加元素
内部实现
List类型的底层数据结构是由双向链表或压缩列表来实现的:
**·**当列表的元素个数小于512个(默认值,可以通过参数 list-max-ziplist-entries 进行配置),列表每个元素的值都小于64字节(默认值,可以通过参数 list-max-ziplist-value 来进行配置)时,redis使用压缩列表作为List类型的底层数据结构;
**·**如果列表的元素不满足上面的条件,就会使用双向链表来作为List的底层数据结构
但是在redis3.2版本之后,List数据类型底层数据结构就只由 quicklist 实现了。
常用命令
# 将一个或多个value插入到key列表的最左边,最后的值在最前面
lpush key value [value ...]
# 将一个或多个value插入到key列表的表尾
rpush key value [value ...]
# 移除并返回 key 列表的头元素
lpop key
# 移除并返回 key 列表的尾元素
rpop key
# 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始
lrange key start stop
应用场景
可以基于List来实现消息队列,一个消息队列需要满足以下条件:
1、消息的存取:
List是按照先进先出的顺序来进行数据的存取的,生产者通过LPUSH命令来向List中存放消息,消费者通过RPOP命令来从List中读取消息,满足先进先出以及消息的顺序性。
但基于LPUSH+RPOP命令实现的消息队列有一个潜在的风险点。在生产者往List写入数据时,List并不会通知消费者有新的消息写入,如果消费者想要及时处理消息,就需要在程序中不停的调用RPOP命令,但这种情况如果生产者一直没有写入消息,那消费者就会一直循环去读消息。
Redis提供了BRPOP命令,这个命令也可以称为阻塞式读取,消费者在没有读取到List中数据时,自动阻塞,直到有新的数据写入了List,才会重新开始读取新数据
2、处理重复的消息:
要保证重复的消息不会被重复消费,首先需要保证每一条消息都有一个全局唯一ID (可以通过UUID来实现);第二点就是消费者需要记录已经处理过的消息的ID,每当消费者收到一条消息时,消费者首先判断这条消息ID是否与已经消费过的消息ID是否相等,如果不相等就处理,如果相等就返不再处理。
3、保证消息的可靠性:
当消费者从List中读取一条消息后,List就不会再保留这条消息了。此时,如果消费者还没有完成这条消息的消费,出现了服务挂了的情况,那么这条消息就会丢失,服务器重启后无法重新消费这条消息。
List提供了BRPOPLPUSH命令,这个命令的作用是让消费者程序从一个List中读取消息,同时,redis会将这条消息再插入到另一个List留存。消费者基于BRPOPLPUSH命令来读取消息的话,如果出现服务挂了的情况,重启后可以从备份List中重新读取这条消息并进行处理。
总结一下,就是LPUSH和RPOP可以满足消息的存取、BRPOP可以实现阻塞式读取、通过给每条消息加上全局唯一的id以及消费者记录已经处理过的消息ID来处理重复的消息、通过BRPOPLPUSH命令来保证消息的可靠性。
Hash
Hash是一个键值对集合,其中value的形式如:vlaue={field1, value1}, ..., {fieldN, valueN},Hash非常适合于存储对象。

内部实现
Hash类型的底层数据结构是由压缩列表或哈希表实现的:
**·**如果哈希类型元素个数小于512个(默认值,可以由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可以由hash-max-ziplist-value配置)时,redis会使用压缩列表作为Hash类型的底层数据结构;
**·**如果不满足上述条件,redis就会使用哈希表作为Hash类型的底层数据结构。
在redis7.0中,压缩列表数据结构已经废弃,由listpack数据结构来实现。
常用命令
# 存储一个哈希表key的键值
hset key field value
# 获取一个哈希表key对应的field键值
hget key field
# 在一个哈希表key中存储多个键值对
hmset key field value [field vlaue...]
# 批量获取哈希表key中多个field键值
hmget key field [field ...]
# 删除哈希表key中的field键值
hdel key field [field ...]
# 返回哈希表key中的field键值
hlen key
# 获取哈希表key中所有的键值
hgetall key
# 为哈希表key中field键的值加上增量n
hincrby key field n
应用场景
**·**使用hash数据类型可以缓存类似于用户信息,订单信息等。对象里面有很多属性,使用string来存的话每次都要做json序列化,会有性能问题,使用hash进行对象存储就可以直接拿到某个属性的值。例如用户信息存储、地理位置存储等都是属于对象存储的。
· 可以使用Hash来做购物车,用户id作为key,商品id作为field,商品数量作为value,具体操作以下为例:
# 给购物车中添加商品
hset cart:{用户id} {商品id} 1
# 增加商品数量
hincrby cart:{用户id} {商品id} 1
# 统计商品总数
hlen cart:{用户id}
# 删除商品
hdel cart:{用户id} {商品id}
# 获取购物车所有商品
hgetall cart:{用户id}Set
Set类型是一个无序并唯一的键值集合,它的存储顺序不会按照插入的先后顺序进行存储。一个集合最多可以存储2^32 - 1个元素,该类型除了支持集合内的增删改查还支持多个集合取交集、并集、差集。
内部实现
Set类型的底层数据结构是由哈希表或整数集合实现的:
**·**如果集合中的元素都是整数且元素个数小于512(默认值,set-maxintset-entries 配置)个,Redis会使用整数集合作为Set类型的底层数据结构;
**·**如果集合中的元素不满足上述条件,则Redis使用哈希表作为Set类型的底层数据结构。
常用命令
集合内的增删改查
# 给集合key中存入元素,元素存在则忽略,若key不存在则新建
sadd key value value value1
# 从集合key中删除元素
srem key value
# 获取集合key中所有元素
smembers key
# 获取集合key中的元素个数
scard key
# 判断value元素是否存在于集合key中
sismember key value
# 从集合key中随机选出count个元素,元素不从key中删除
srandmemeber key count
# 从集合key中随机选出count个元素,元素从key中删除
SPOP key count集合外的交集、并集、差集
# 交集运算
sinter key key1
# 将交集结果存入新的集合
sinterstore new_key key key1
# 并集运算
sunion key key1
# 差集运算
sdiff key key1应用场景
· 点赞:利用Set结构的特性,可以实现每个用户仅允许点赞一次。例如对于文章的点赞,我们可以将文章id作为key,然后将用户id作为value,根据Set的特性,同一个key中不允许有相同的value。
我们将article:1作为key,uid:1、uid:2、uid:3作为value,当用户1、2、3分别对文章进行点赞时:
# 用户1点赞
sadd article:1 uid:1
# 用户2点赞
sadd article:1 uid:2
# 用户3点赞
sadd article:1 uid:3如果用户1取消点赞,即:
# 用户1取消点赞
srem article:1 uid:1获取文章1的所有点赞用户、以及点赞数
# 获取文章1所有的点赞用户
smembers article:1
# 获取文章1的点赞数
scard article:1判断用户1是否对该文章点赞
# 判断用户1是否点赞
sismember article:1 uid:1· 共同关注:利用Set来求交集可以实现共同关注的功能,例如用户1关注的公众号id为1、2、3,用户2关注2、3、4
实现用户关注
# 用户1关注公众号1、2、3
sadd uid:1 1 2 3
# 用户2关注公众号2、3、4
sadd uid:2 2 3 4求用户1和用户2的共同关注
# 求用户1和用户2的共同关注
sinter uid:1 uid:2给用户2推荐用户1关注的公众号
# 谁在前面返回谁的非共同value
sdiff uid:1 uid:2· 也可以使用Set类型来实现抽奖
ZSet
ZSet类型(有序集合类型)相比于Set多了一个排序属性score,对于有序集合ZSet来说,每个存储元素由两个值组成,一个是元素值,另一个就是排序值。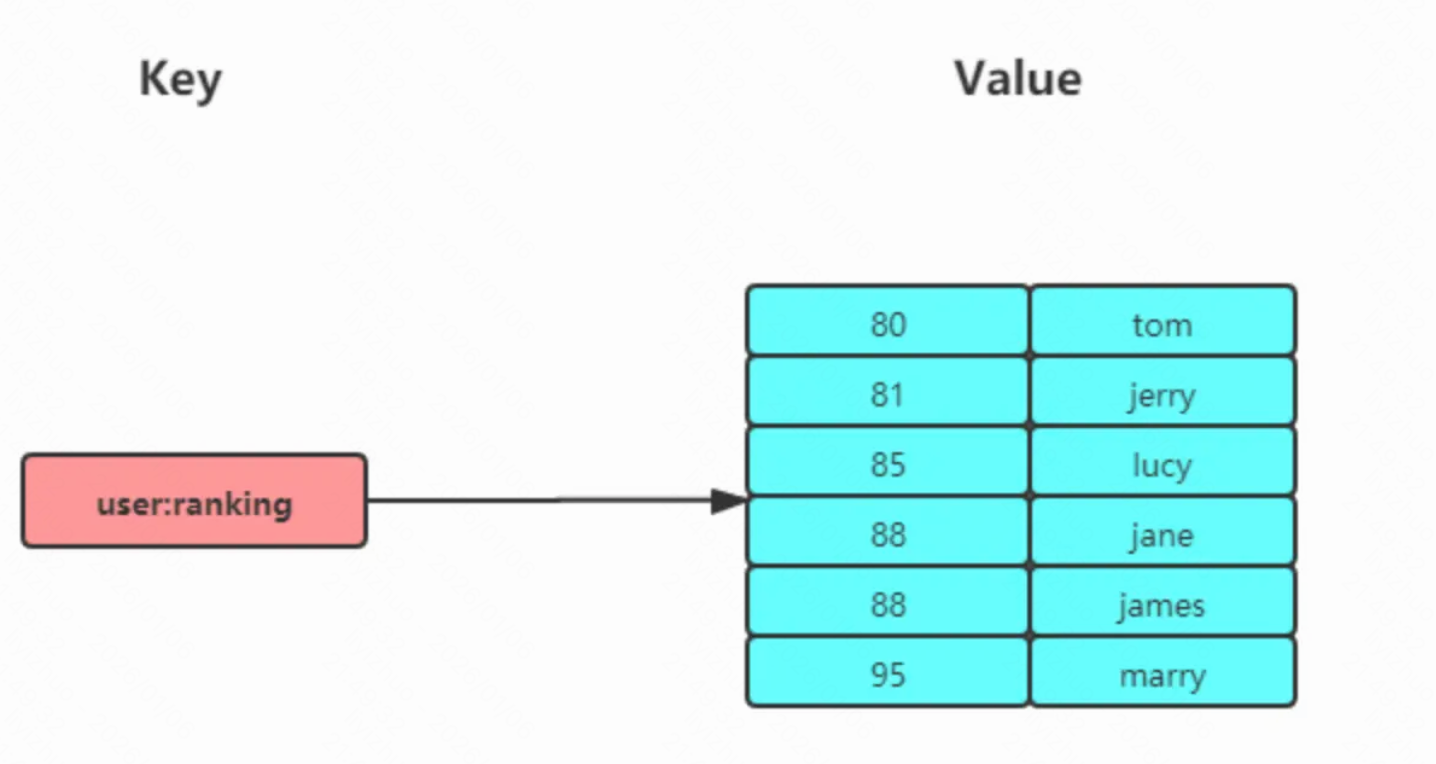
内部实现
ZSet的底层由压缩列表或跳表实现:
**·**如果有序集合的元素个数小于128个,并且每个元素的值小于64字节时,redis使用压缩列表来作为ZSet的底层存储结构;
**·**如果有序集合的元素不满足上面的条件,redis会使用跳表作为ZSet类型的底层数据结构。
在redis7.0中,压缩列表数据结构已经废弃了,由listpack数据结构实现
常用命令
# 往有序集合key中加入带分值的元素
zadd key score member
# 删除有序集合key中元素member的分值
zrem key member
# 返回有序集合key中元素member的分值
zscore key member
# 返回有序集合中key的个数
zcard key
# 给有序集合key中元素member的分值加上increment
zincrby key increment member
# 正序获取有序集合key从start到stop下标的元素
zrange key start stop withscores
# 倒序获取有序集合key从start到stop下标的元素
zrevrange key start stop withscores应用场景
· 基于ZSet实现排行榜,例如学生成绩排名榜,微信步数榜、商品销量榜等等