
🎼个人主页:【Y小夜】
😎作者简介:一位双非学校的大三学生,编程爱好者,
专注于基础和实战分享,欢迎私信咨询!
🎆入门专栏:🎇【 MySQL,Javaweb,Rust,python】
🎈热门专栏:🎊【 Springboot,Redis,Springsecurity,Docker,AI】
++感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️++

目录
🎈为什么要使用集群?
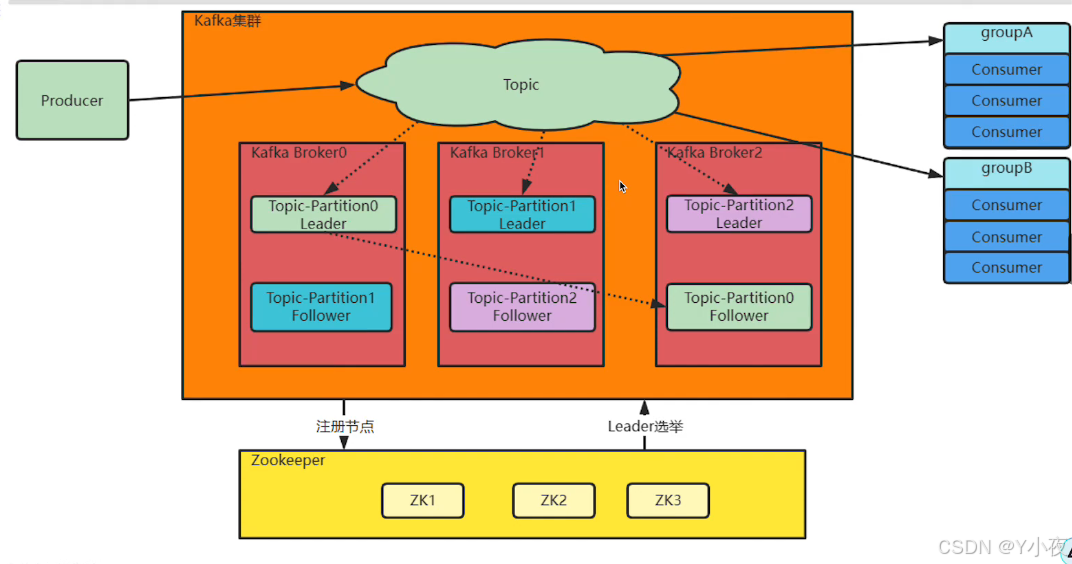
其实在单机服务下,Kafka已经具备了非常高的性能,TPS能够达到百万级,但是实际工作中使用,单机搭建的Kafka有很大的局限性。
一方面:消息太多,需要分开放
另一方面:服务不稳定,数据容易丢失

大家集群这部分我的电脑上没有多个虚拟机,所以这部分,要是需要操作的话。可以看其他博主的文章。
🎈Springboot集成Kafka
🎉引入依赖
这个依赖关系版本和下载的kafka有依赖关系,大家可以关注下。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>🎉配置
spring.kafka.bootstrap-servers=ip地址:9092
kafka.topics=test1🎉编写Kafka的配置类
java
package com.yan.kafka;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.TopicBuilder;
@Configuration
public class KafkaConfig {
@Value("${kafka.topics}")
private String topic;
@Bean
public NewTopic topic(){
return TopicBuilder.name(topic).build();
}
}🎉编写生产者配置类
java
package com.yan.kafka;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
//发送配置类
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String service;
public Map<String, Object> config(){
Map<String,Object> config=new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,service);
//进行序列化
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
return config;
}
@Bean
public ProducerFactory<String,String> producerFactory(){
return new DefaultKafkaProducerFactory<>(config());
}
@Bean
public KafkaTemplate<String,String> kafkaTemplate(){
return new KafkaTemplate<>(producerFactory());
}
}🎉编写生产者业务
java
package com.yan.kafka;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${kafka.topics}")
private String topic;
@GetMapping("/kafka")
public String sendMsg(){
for (int i = 0; i < 10; i++) {
kafkaTemplate.send(topic,"你好"+i);
}
return "success";
}
}🎉编写消费者配置类
java
package com.yan.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.*;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String service;
public Map<String, Object> config(){
Map<String,Object> config=new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,service);
//进行反序列化
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringSerializer.class);
return config;
}
@Bean
public ConsumerFactory<String,String> consumerFactory(){
return new DefaultKafkaConsumerFactory<>(config());
}
@Bean
public ConcurrentKafkaListenerContainerFactory concurrentKafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory ckcf=new ConcurrentKafkaListenerContainerFactory();
ckcf.setConsumerFactory(consumerFactory());
return ckcf;
}
}🎉编写消费者监听类
java
package com.yan.kafka;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaListeners {
@KafkaListener(topics="${kafka.topics}",groupId = "aaa")
void listener(String data){
System.out.println("收到了"+data);
}
}然后,启动程序,访问一下localhost:8080/kafka,控制台会输出:
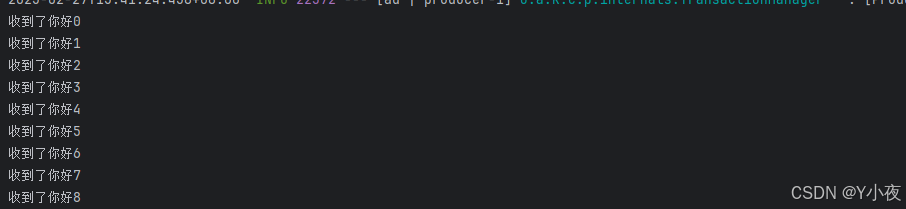
🎉报错:
下面三种图是我做的时候出现的报错。我们可以对程序做一下检测
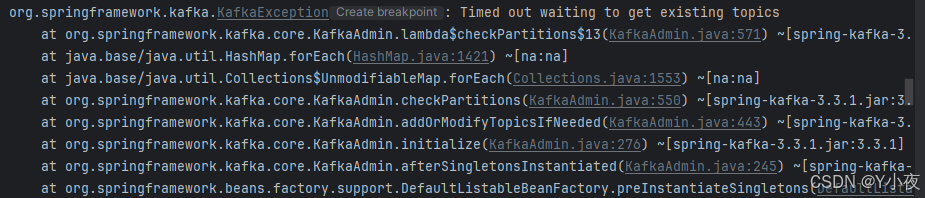

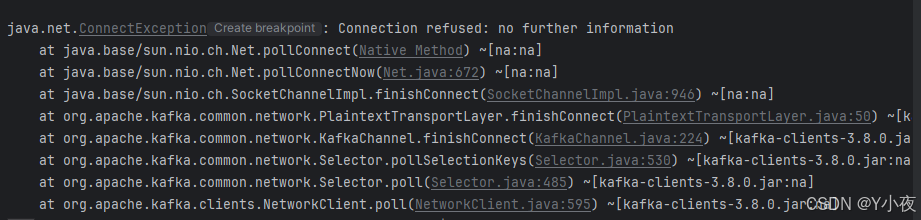
首先输入jps,看linux中kafka是否启动

如果没有启动,则需要输入命令进行启动。
然后看一下9092端口是否开放:
java
firewall-cmd --zone=public --list-ports
若没有开放,则使用命令,开放9092端口
java
firewall-cmd --zone=public --add-port=9092/tcp --permanent
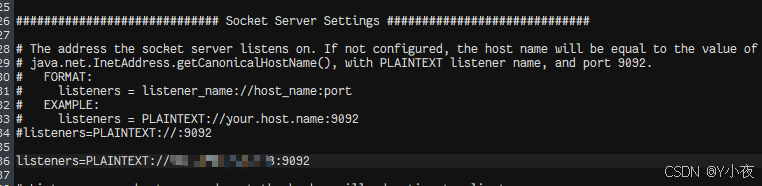
firewall-cmd --reload接着打开 /config/server.properties 文件,
java
listeners=PLAINTEXT://localhost:9092将localhost修改为kafka当前的操作系统的地址即可。
然后打开windows窗口,输入
java
telnet ip地址 9092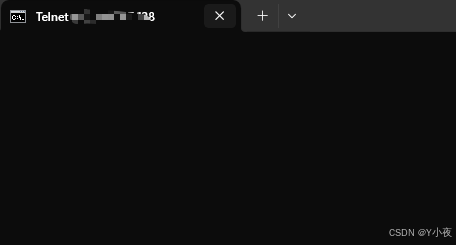
能进入的话,就说明可以连接到。
把这些修改完毕后,应该就可以顺利访问了。!!!