ABP + ClickHouse 实时 OLAP:物化视图与写入聚合 ✨
版本建议 :ClickHouse 25.3+ (原生
JSON列生产可用),.NET 8,ABP 8.x/9.x,ClickHouse.Client≥ 7.x。低于 25.3 时,请用String + JSONExtract*处理 JSON。
📚 目录
- [ABP + ClickHouse 实时 OLAP:物化视图与写入聚合 ✨](#ABP + ClickHouse 实时 OLAP:物化视图与写入聚合 ✨)
-
- 1) 场景与目标 🏁 场景与目标 🏁)
- 2) 总体架构(双接入路径)🌐 总体架构(双接入路径)🌐)
- 3) 写入链路时序 ⏱️ 写入链路时序 ⏱️)
- 4) 表设计与去重策略 🧱 表设计与去重策略 🧱)
-
- [4.1 Raw 明细表(最终一致的幂等/去重)](#4.1 Raw 明细表(最终一致的幂等/去重))
- [4.2 聚合表:增量聚合(State/Merge)](#4.2 聚合表:增量聚合(State/Merge))
- [4.3 表与 MV 关系 🗺️](#4.3 表与 MV 关系 🗺️)
- 5) 冷热分层与保留策略 ❄️🔥 冷热分层与保留策略 ❄️🔥)
- 6) 管线 SQL:Kafka→Raw→聚合(双层 MV)🧩 管线 SQL:Kafka→Raw→聚合(双层 MV)🧩)
-
- [6.1 Kafka 入口 & 错误侧路](#6.1 Kafka 入口 & 错误侧路)
- [6.2 Raw 落地](#6.2 Raw 落地)
- [6.3 Raw→Agg(增量 MV)](#6.3 Raw→Agg(增量 MV))
- 7) ABP 集成(.NET,直连微批)⚙️ ABP 集成(.NET,直连微批)⚙️)
-
- [7.1 Background Worker + 有界 Channel + **连接复用** + BulkCopy](#7.1 Background Worker + 有界 Channel + 连接复用 + BulkCopy)
- 8) JSON 字段策略 📦 JSON 字段策略 📦)
- 9) 压测与观测 🧪 压测与观测 🧪)
- 10) 维护要点与常见坑 🛠️ 维护要点与常见坑 🛠️)
- 11) 与 Elasticsearch / Pinot 的选型对比 🧭 与 Elasticsearch / Pinot 的选型对比 🧭)
- 12) 去重语义一图懂 🧠 去重语义一图懂 🧠)
- 13) 可复现目录结构 📁 可复现目录结构 📁)
- 14) 快速校验 ✅ 快速校验 ✅)
1) 场景与目标 🏁
-
目标:10--100k EPS 写入、秒级出数、低成本长期留存
-
关键能力:
- 增量物化视图(MV):写入路径实时更新,下游聚合表直查
- 写入去重 :
ReplacingMergeTree基于排序键 + 版本列,合并期 去重;一致性敏感查询用FINAL兜底 - 冷热分层 :
TTL ... TO VOLUME+ 存储策略(热→温→冷→删除) - 批量化 :优先批量 INSERT;或 Kafka Engine→MV 落 MergeTree
2) 总体架构(双接入路径)🌐
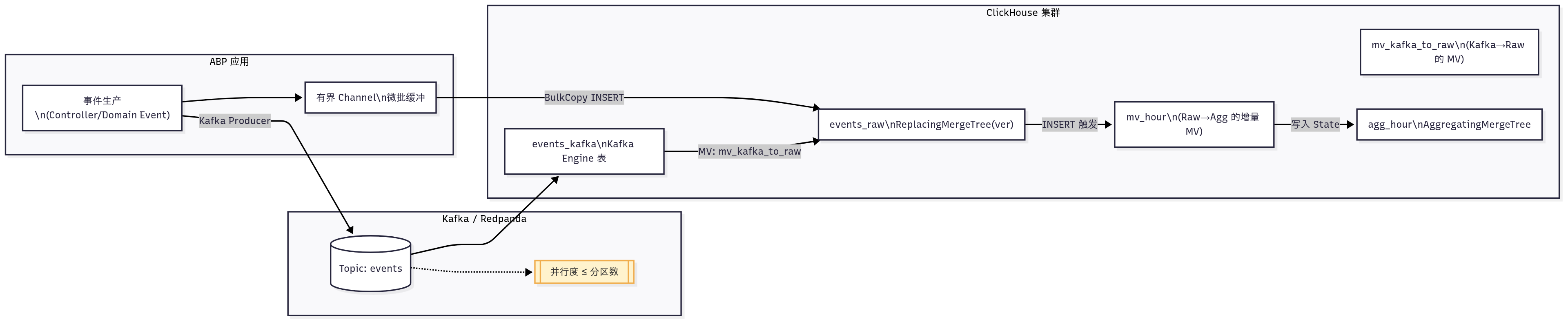
3) 写入链路时序 ⏱️
Client ABP API/Worker Kafka Topic Kafka Engine 表 events_raw mv_hour (Raw->>Agg) agg_hour POST /api/events Channel 微批聚合 (M 条/T ms) BulkCopy INSERT (批量) INSERT 触发 MV(写时) Trigger 写入聚合 State produce JSONEachRow poll 分区消息 mv_kafka_to_raw 落明细 INSERT 触发 MV(写时) Trigger 写入聚合 State alt 直连模式 Kafka 模式 Client ABP API/Worker Kafka Topic Kafka Engine 表 events_raw mv_hour (Raw->>Agg) agg_hour
4) 表设计与去重策略 🧱
4.1 Raw 明细表(最终一致的幂等/去重)
统一将高重复维度列(如租户)设为
LowCardinality(String),降低存储/加速 GROUP BY。
sql
CREATE TABLE IF NOT EXISTS rt.events_raw
(
tenant LowCardinality(String),
event_key String,
ts DateTime64(3, 'UTC'),
value Float64,
ver UInt64, -- 版本列(更大覆盖旧)
-- 25.3+ 可用 JSON;<25.3 用 String + JSONExtract*
props String
)
ENGINE = ReplacingMergeTree(ver)
PARTITION BY toYYYYMM(ts)
ORDER BY (tenant, event_key, ts)
SETTINGS index_granularity = 8192;- 去重发生在合并 (最终一致);
FINAL为关键查询兜底(有代价,慎常态化)
4.2 聚合表:增量聚合(State/Merge)
sql
CREATE TABLE IF NOT EXISTS rt.events_hourly
(
tenant LowCardinality(String),
bucket DateTime('UTC'),
c AggregateFunction(count),
s AggregateFunction(sum, Float64),
p95 AggregateFunction(quantileTDigest, Float64),
p99 AggregateFunction(quantileTDigest, Float64)
)
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(bucket)
ORDER BY (tenant, bucket);4.3 表与 MV 关系 🗺️
events_kafka (Kafka Engine) mv_kafka_to_raw events_raw (ReplacingMergeTree) mv_hour (Raw->Agg) agg_hour (AggregatingMergeTree)
5) 冷热分层与保留策略 ❄️🔥
sql
CREATE TABLE rt.events_raw ( ... )
ENGINE = ReplacingMergeTree(ver)
PARTITION BY toYYYYMM(ts)
ORDER BY (tenant, event_key, ts)
SETTINGS storage_policy = 'hot_warm_cold'
TTL ts + INTERVAL 7 DAY TO VOLUME 'warm',
ts + INTERVAL 180 DAY TO VOLUME 'cold',
ts + INTERVAL 365 DAY DELETE;
-- 策略变更后可强制一次
ALTER TABLE rt.events_raw MATERIALIZE TTL;
-- 观测策略与迁移
SELECT policy_name, volumes FROM system.storage_policies;
SELECT name, disk_name, path FROM system.parts
WHERE database='rt' AND table='events_raw' AND active;TTL 生命周期
HOT (SSD)
0-7d WARM (HDD)
7-180d COLD (HDD/S3)
>180d DELETE
6) 管线 SQL:Kafka→Raw→聚合(双层 MV)🧩
6.1 Kafka 入口 & 错误侧路
sql
CREATE TABLE ingest.events_kafka
(
tenant String,
event_key String,
ts DateTime64(3, 'UTC'),
value Float64,
ver UInt64
)
ENGINE = Kafka
SETTINGS
kafka_broker_list='kafka:9092',
kafka_topic_list='events',
kafka_group_name='abp-events',
kafka_format='JSONEachRow',
kafka_num_consumers=4,
kafka_handle_error_mode='stream';
-- 仅解析失败时,虚拟列 _raw_message/_error 有值
CREATE TABLE ingest.events_dlq
(
ts DateTime DEFAULT now(),
_error String,
_raw String
) ENGINE=MergeTree ORDER BY ts;
CREATE MATERIALIZED VIEW ingest.mv_events_dlq TO ingest.events_dlq AS
SELECT now(), _error, _raw_message
FROM ingest.events_kafka
WHERE length(_error) > 0;⚠️ Kafka Engine 大多设置/模式需 DROP/CREATE 入口表后生效(下游 MV/目标表可复用);注意消费组 offset 管理。
6.2 Raw 落地
sql
CREATE TABLE rt.events_raw
(
tenant LowCardinality(String),
event_key String,
ts DateTime64(3,'UTC'),
value Float64,
ver UInt64,
props String
) ENGINE=ReplacingMergeTree(ver)
ORDER BY (tenant,event_key,ts)
PARTITION BY toYYYYMM(ts);
CREATE MATERIALIZED VIEW ingest.mv_kafka_to_raw
TO rt.events_raw AS
SELECT tenant, event_key, ts, value, ver, '' AS props
FROM ingest.events_kafka
WHERE length(_error)=0;6.3 Raw→Agg(增量 MV)
sql
CREATE TABLE rt.events_hourly
(
tenant LowCardinality(String),
bucket DateTime('UTC'),
c AggregateFunction(count),
s AggregateFunction(sum, Float64),
p95 AggregateFunction(quantileTDigest, Float64),
p99 AggregateFunction(quantileTDigest, Float64)
) ENGINE=AggregatingMergeTree()
ORDER BY (tenant,bucket)
PARTITION BY toYYYYMM(bucket);
CREATE MATERIALIZED VIEW rt.mv_hour TO rt.events_hourly AS
SELECT
tenant,
toStartOfHour(ts) AS bucket,
countState() AS c,
sumState(value) AS s,
quantileTDigestState(0.95)(value) AS p95,
quantileTDigestState(0.99)(value) AS p99
FROM rt.events_raw
GROUP BY tenant, bucket;查询端(合并状态):
sql
SELECT tenant, bucket,
countMerge(c) AS cnt,
sumMerge(s) AS total,
quantileTDigestMerge(0.95)(p95) AS p95,
quantileTDigestMerge(0.99)(p99) AS p99
FROM rt.events_hourly
WHERE tenant='t1'
AND bucket >= now() - INTERVAL 24 HOUR
GROUP BY tenant, bucket
ORDER BY bucket;7) ABP 集成(.NET,直连微批)⚙️
7.1 Background Worker + 有界 Channel + 连接复用 + BulkCopy
csharp
// modules/Abp.Analytics.Pipeline/ClickHouseWriteWorker.cs
using System.Data;
using System.Threading.Channels;
using Volo.Abp.BackgroundWorkers;
using Volo.Abp.DependencyInjection;
using ClickHouse.Client.ADO;
using ClickHouse.Client.Copy;
public sealed class ClickHouseWriteWorker
: AsyncPeriodicBackgroundWorkerBase, ISingletonDependency
{
private readonly Channel<EventRow> _channel;
private readonly string _conn;
private ClickHouseConnection? _con;
public ClickHouseWriteWorker(AbpAsyncTimer timer, IConfiguration cfg)
: base(timer)
{
_channel = Channel.CreateBounded<EventRow>(
new BoundedChannelOptions(100_000){ FullMode = BoundedChannelFullMode.Wait });
_conn = cfg.GetConnectionString("ClickHouse")!;
Timer.Period = 50; // 每 50ms 检查一次
}
public bool TryEnqueue(EventRow row) => _channel.Writer.TryWrite(row);
protected override async Task DoWorkAsync(PeriodicBackgroundWorkerContext ctx)
{
// 连接复用,降低建连/握手开销
_con ??= new ClickHouseConnection(_conn);
if (_con.State != ConnectionState.Open)
await _con.OpenAsync(ctx.CancellationToken);
var batch = new List<object[]>(capacity: 5000);
while (batch.Count < 5000 && _channel.Reader.TryRead(out var r))
batch.Add(new object[]{ r.Tenant, r.Key, r.Ts, r.Value, r.Ver, r.Payload });
if (batch.Count == 0) return;
using var bc = new ClickHouseBulkCopy(_con)
{
DestinationTableName = "rt.events_raw",
BatchSize = 5000,
MaxDegreeOfParallelism = 2
};
await bc.WriteToServerAsync(batch, ctx.CancellationToken);
}
}
public record EventRow(string Tenant, string Key, DateTime Ts, double Value, ulong Ver, string Payload);
csharp
// 模块注册
[DependsOn(typeof(AbpBackgroundWorkersModule))]
public class AnalyticsPipelineModule : AbpModule
{
public override void OnApplicationInitialization(ApplicationInitializationContext context)
{
var worker = context.ServiceProvider.GetRequiredService<ClickHouseWriteWorker>();
context.AddBackgroundWorkerAsync(worker);
}
}建议:对
TryEnqueue的失败计数、批量写成功率、Flush 周期、队列深度做指标上报(Prometheus/Grafana)。
8) JSON 字段策略 📦
- 25.3+ :
props JSON(半结构化/动态 schema 更友好) - <25.3 :
props String+JSONExtract*;高频路径可做物化列或宽表化,减少运行期开销
9) 压测与观测 🧪
-
写入压测:1k/5k/10k EPS;批大小 500/2k/5k;对比直连 BulkCopy 与 Kafka Engine
-
查询压测 :近 24h 小时桶 p50/p95/p99(
quantileTDigest*) -
系统表与日志:
- Kafka 消费:
system.kafka_consumers(滞后、分区、group) - 合并/分片:
system.merges、system.parts、system.part_log - 视图链路:开启
log_query_views=1后读system.query_views_log - 异步插入(若用):
system.asynchronous_insert_log - 分层策略:
system.storage_policies、system.moves - 如需,
SYSTEM FLUSH LOGS强刷日志表落盘
- Kafka 消费:
10) 维护要点与常见坑 🛠️
- MV 去重 × Async Insert :部分版本默认拒绝
async_insert=1与deduplicate_blocks_in_dependent_materialized_views=1同开;优先客户端微批。 - Kafka 表 DDL/Setting 变更 :通常需 DROP/CREATE 入口表(MV/目标表保留即可续跑);记得处理 offset。
- ReplacingMergeTree 一致性 :合并期去重;关键报表按主键过滤 +
FINAL兜底,避免常态FINAL。 - TTL/分层 :策略名/卷名与服务器
storage_configuration保持一致;策略变更后ALTER TABLE ... MATERIALIZE TTL,并观测system.parts的disk_name。
11) 与 Elasticsearch / Pinot 的选型对比 🧭
| 维度 | ClickHouse | Elasticsearch | Apache Pinot |
|---|---|---|---|
| 实时聚合 | 列存 + 增量 MV,超强扫描/聚合 | 聚合可用但偏搜索场景 | Kafka 实时 Upsert/Partial Upsert、在线聚合低延迟 |
| 去重/更新 | Replacing/Collapsing、插入幂等 | 文档覆盖更新、ILM | Upsert 一等公民 |
| 分层/留存 | TTL + Storage Policy | ILM:Hot/Warm/Cold | 历史归档需额外设计 |
| 查询生态 | 标准 SQL | DSL/SQL、全文强 | SQL 方言,面向看板/指标强 |
粗结论:数值聚合为主、SQL 复杂 → ClickHouse;强 UGC 搜索/相关性 → Elasticsearch;极低延迟 + Kafka 一体化 → Pinot。
12) 去重语义一图懂 🧠
后台合并(merge) 查询(无 FINAL)
可能含旧版本 查询(FINAL)
读时去重 Inserted Merged QueryResult QueryFinal
13) 可复现目录结构 📁
abp-clickhouse-rt-olap/
modules/Abp.Analytics.Pipeline/ # ABP 模块 & ClickHouseWriteWorker(直连微批)
deploy/clickhouse/
init.sql # 建表/MV/TTL/策略 SQL
config.d/storage.xml # 存储策略 (示例)
scripts/bench/
gen-events.cs # 数据生成/压测
queries.sql # p50/p95/p99 查询
dashboards/
grafana.json # 看板 (可选)
docs/
decision-matrix.md # 选型与结论14) 快速校验 ✅
建表 + MV(简版)
sql
CREATE TABLE IF NOT EXISTS rt.events_raw
(
tenant LowCardinality(String),
event_key String,
ts DateTime64(3,'UTC'),
value Float64,
ver UInt64,
props String
) ENGINE=ReplacingMergeTree(ver)
ORDER BY (tenant,event_key,ts)
PARTITION BY toYYYYMM(ts);
CREATE TABLE IF NOT EXISTS rt.events_hourly
(
tenant LowCardinality(String),
bucket DateTime('UTC'),
c AggregateFunction(count),
s AggregateFunction(sum, Float64),
p95 AggregateFunction(quantileTDigest, Float64),
p99 AggregateFunction(quantileTDigest, Float64)
) ENGINE=AggregatingMergeTree()
ORDER BY (tenant,bucket)
PARTITION BY toYYYYMM(bucket);
CREATE MATERIALIZED VIEW IF NOT EXISTS rt.mv_hour
TO rt.events_hourly AS
SELECT tenant, toStartOfHour(ts) AS bucket,
countState() AS c, sumState(value) AS s,
quantileTDigestState(0.95)(value) AS p95,
quantileTDigestState(0.99)(value) AS p99
FROM rt.events_raw
GROUP BY tenant, bucket;
-- 示例查询
SELECT tenant, bucket,
countMerge(c) AS cnt,
sumMerge(s) AS total,
quantileTDigestMerge(0.95)(p95) AS p95,
quantileTDigestMerge(0.99)(p99) AS p99
FROM rt.events_hourly
WHERE tenant='t1'
AND bucket >= now() - INTERVAL 24 HOUR
GROUP BY tenant, bucket
ORDER BY bucket;