家人们谁懂啊!上次上线新功能,就因为没处理好 "订单创建 + 库存扣减",结果同一时间两个用户抢最后 1 件商品,直接把库存干成了 - 1... 排查到凌晨才发现:单机事务那套玩不转微服务了!
今天就从 "踩坑经历" 出发,把分布式事务、CAP 定理、Seata 这些知识点掰开揉碎讲 ------ 保证不用晦涩术语,看完就能上手!
一、先复习:单机事务是 "老熟人" ACID
咱写单体应用时,事务就是个 "靠谱管家":你让它干 "扣余额 + 生成订单",要么全成,要么全撤,绝不搞 "余额扣了订单没生成" 的骚操作。这背后就是 ACID 四兄弟:
-
A(原子性) :要么全做完,要么全回滚(比如外卖下单,不能 "付款了没接单");
-
C(一致性) :做完后数据得对(比如扣 100 余额,余额就该少 100,不能少 99);
-
I(隔离性) :两个事务别互相捣乱(你查库存的时候,我别插一腿改库存);
-
D(持久性) :做完就永久保存(订单生成了,数据库崩了重启也得在)。
但自从拆了微服务,麻烦就来了 ------ 订单在订单服务的库,库存在库存服务的库,单机事务管不了两个库啊!这就轮到分布式事务登场了。
二、分布式事务:微服务时代的 "新麻烦"
简单说,分布式事务就是 "跨服务、跨数据库" 的事务。比如用户下单的完整流程:
-
订单服务:创建订单(订单库);
-
库存服务:扣减库存(库存库);
-
支付服务:扣用户余额(用户库)。
这三步只要有一步失败,前面成功的就得回滚 ------ 总不能 "订单创建了,库存没扣,最后超卖" 吧?
但问题是:三个服务不在一个库,单机事务的 ACID 没法跨库生效。这时候就需要专门的方案来管,而聊方案前,绕不开的就是 CAP 定理。
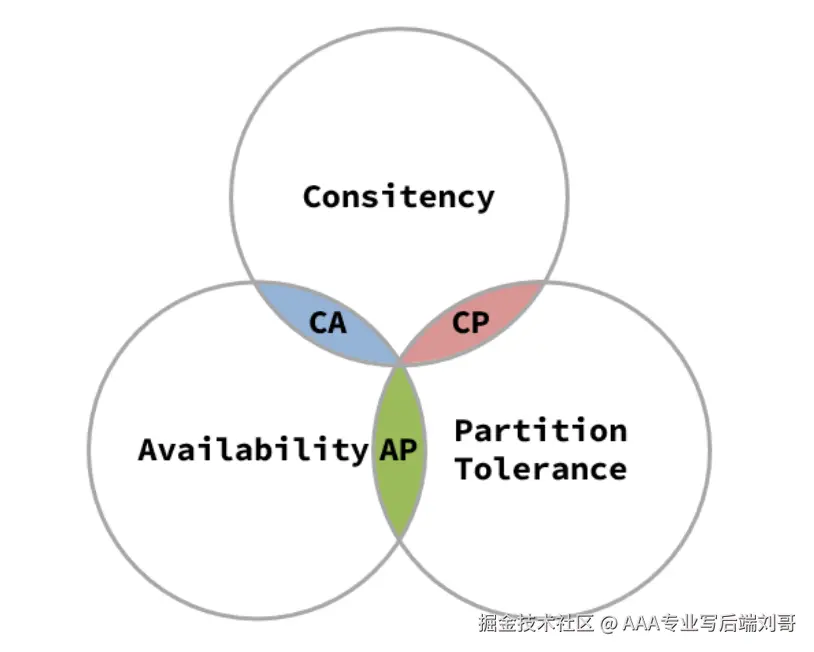
三、CAP 定理:鱼和熊掌的 "选择题"
CAP 是分布式系统的 "铁律",说的是三个特性里,你最多能同时满足两个:
-
C(一致性) :所有节点的数据得一样(比如你查库存是 10,我查也得是 10);
-
A(可用性) :不管啥情况,服务都得能响应(比如库存服务卡了,也得告诉用户 "稍等",不能直接崩);
-
P(分区容错性) :服务之间断网了(比如订单服务和库存服务连不上),系统还能跑。
为啥不能三者兼得?举个例子:
假如库存服务和订单服务断网了(触发 P):
-
要 C(一致性):就必须等网络恢复,确认库存到底剩多少,这时候服务没法响应(丢了 A);
-
要 A(可用性):就先返回 "库存充足" 让用户下单,等网络恢复再同步数据,这时候可能出现数据不一致(丢了 C)。
在分布式系统中,分区容错性(P)是必须要保证的,我们必须做出取舍 所以实际开发中,咱得根据场景选 "CP" 或 "AP":
1. CP 模式:认死 "数据一致",牺牲点可用性
适合 "数据错了比用不了更严重" 的场景,比如银行转账、库存扣减。
典型例子:ZooKeeper。它会保证所有节点数据一致,但如果主节点挂了,要等从节点选主,这期间服务不可用。
2. AP 模式:认死 "服务能用",接受暂时不一致
适合 "用不了比数据错了更严重" 的场景,比如商品列表、用户点赞。
典型例子:Eureka。服务注册信息可能暂时不一致(比如某个服务下线了,个别节点还显示在线),但永远能给你返回结果,不会卡着不动。
四、Seata 登场:分布式事务的 "救火队员"
知道了 CAP 的取舍,那具体怎么实现分布式事务?阿里开源的 Seata 就是咱后端 er 的 "神器"------ 它把复杂的分布式事务逻辑封装好,咱不用自己写一堆协调代码。
先搞懂 Seata 里的三个 "关键角色",记成 "项目组分工" 就好:
| 角色 | 作用 | 类比 |
|---|---|---|
| TM(事务管理器) | 发起和结束事务(比如订单服务说 "开始下单事务""结束事务") | 项目经理:负责启动项目、宣布项目成败 |
| RM(资源管理器) | 管理具体的数据库资源(比如库存服务负责扣库存、回滚库存) | 开发工程师:负责干具体活,听指挥回滚 |
| TC(事务协调器) | 居中协调 TM 和 RM(比如告诉库存服务 "该回滚了") | 项目协调员:盯着进度,出问题了协调大家补救 |
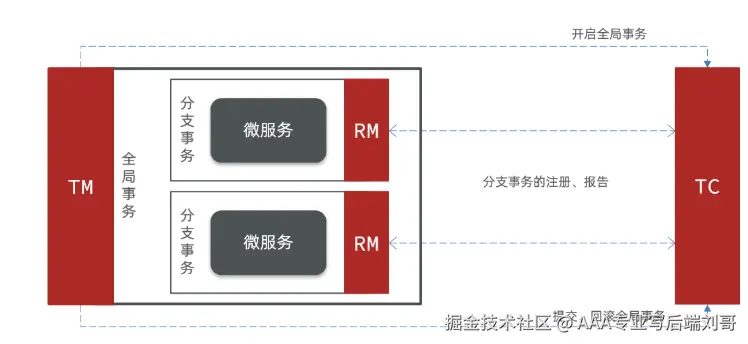
简单说:TM 喊 "开始",RM 们干活,TC 盯着,一旦有 RM 报错,TC 就让所有人回滚;全成了,TC 就宣布 "事务成了"。
五、微服务集成 Seata:手把手教你 "搭环境"
光说不练假把式,咱以 Spring Cloud 项目为例,三步集成 Seata:
1. 先装 TC(事务协调器)
- 从 Seata 官网下载压缩包(注意和 Spring Cloud 版本匹配,别踩版本坑!);
- 改配置文件
registry.conf:把注册中心改成你项目用的(比如 Nacos),让 TM/RM 能找到 TC; - 启动 TC:执行
bin/seata-server.sh(Linux)或seata-server.bat(Windows)。
2. 微服务端配置(以订单服务为例)
第一步:加依赖
xml
xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>第二步:配 application.yml
告诉服务 "TC 在哪""用什么事务模式":
yaml
yaml
seata:
tx-service-group: my_tx_group # 事务组名,要和TC配置一致
service:
vgroup-mapping:
my_tx_group: default # 映射到TC的集群名
grouplist:
default: 127.0.0.1:8091 # TC的地址和端口
registry:
type: nacos # 注册中心类型
nacos:
server-addr: 127.0.0.1:8848 # Nacos地址第三步:加注解
在事务发起的方法上(比如订单服务的 "创建订单" 方法)加@GlobalTransactional:
java
scss
@Service
public class OrderService {
// 调用库存服务、支付服务
@Autowired
private InventoryFeignClient inventoryClient;
@Autowired
private PaymentFeignClient paymentClient;
// 全局事务注解:这是TM的核心操作
@GlobalTransactional(rollbackFor = Exception.class)
public void createOrder(OrderDTO orderDTO) {
// 1. 创建订单(本地事务)
orderMapper.insert(orderDTO);
// 2. 调用库存服务扣库存(远程事务)
inventoryClient.deduct(orderDTO.getProductId(), orderDTO.getCount());
// 3. 调用支付服务扣余额(远程事务)
paymentClient.deduct(orderDTO.getUserId(), orderDTO.getAmount());
}
}搞定!这样三个服务的事务就被 Seata 管起来了。
六、Seata 事务模式:选对姿势才 "高效"
Seata 支持三种模式,各有优劣,咱按 "常用程度 + 重点掌握" 排序:
1. AT 模式:性价比之王(重点掌握!)
- 特点:弱一致、高可用、开发零侵入(咱刚才写的就是 AT 模式);
- 原理:先 "假装成功"(本地事务提交),再异步确认;如果出错,TC 会让 RM 回滚(用 undo log 日志恢复数据);
- 场景:90% 的业务场景(比如下单、支付),既不用写复杂代码,又能保证高可用;
- 小吐槽:因为是 "事后回滚",极端情况下可能有毫秒级的数据不一致,但一般业务能接受。
2. XA 模式:严谨但 "慢"
- 特点:强一致、低可用、依赖数据库支持(比如 MySQL 的 XA 协议);
- 原理:分两步走 ------ 先让所有 RM "准备好"(比如库存服务说 "我能扣库存",支付服务说 "我能扣余额"),再让所有 RM 一起提交;只要有一个 RM 说 "不行",全回滚;
- 场景:对一致性要求极高的场景(比如银行核心转账);
- 小吐槽:整个过程要等所有 RM 响应,性能差,而且数据库得支持 XA,不够灵活。
3. TCC 模式:灵活但 "麻烦"
- 特点:更高可用、完全自定义、开发成本高;
- 原理:自己写三个方法 ------Try(尝试操作,比如 "冻结库存")、Confirm(确认操作,比如 "真正扣库存")、Cancel(取消操作,比如 "解冻库存");
- 场景:特殊业务(比如跨银行转账、优惠券使用);
- 小吐槽:每个业务都要写 Try/Confirm/Cancel,代码量翻倍,还容易出 bug(比如 Cancel 没处理好导致库存冻结一辈子)。
最后:你踩过分布式事务的坑吗?
其实分布式事务没那么玄乎 ------ 记住 "CAP 取舍是前提,Seata 是工具,AT 模式先上手",大部分场景都能搞定。
你之前有没有遇到过 "库存飞了""余额扣了订单没生成" 的坑?或者用 Seata 时踩过版本兼容的雷?评论区聊聊,咱一起避坑~