PyTorch生成式人工智能(29)------基于Transformer生成音乐
-
- [0. 前言](#0. 前言)
- [1. 音乐 Transformer 简介](#1. 音乐 Transformer 简介)
-
- [1.1 基于演奏的音乐表示](#1.1 基于演奏的音乐表示)
- [1.2 音乐 Transformer 架构](#1.2 音乐 Transformer 架构)
- [1.3 训练音乐 Transformer 流程](#1.3 训练音乐 Transformer 流程)
- [2. 音乐片段分词](#2. 音乐片段分词)
-
- [2.1 下载训练数据](#2.1 下载训练数据)
- [2.2 MIDI 文件分词](#2.2 MIDI 文件分词)
- [2.3 准备训练数据](#2.3 准备训练数据)
- [3. 构建音乐生成 Transformer](#3. 构建音乐生成 Transformer)
-
- [3.1 音乐 Transformer 超参数](#3.1 音乐 Transformer 超参数)
- [3.2 构建音乐Transformer](#3.2 构建音乐Transformer)
- [4 训练和使用音乐Transformer](#4 训练和使用音乐Transformer)
-
- [4.1 训练音乐Transformer](#4.1 训练音乐Transformer)
- [4.2 使用训练好的 Transformer 生成音乐](#4.2 使用训练好的 Transformer 生成音乐)
- 小结
- 系列链接
0. 前言
我们已经学习了如何使用 MuseGAN 生成逼真的多音轨音乐。MuseGAN 将一段音乐视为一个类似图像的多维对象,并生成与训练数据集中相似的音乐作品。在本节中,将采另一种方法来创作音乐,将音乐视为一系列音乐事件。具体来说,将开发一个类似 GPT 的模型,基于序列中所有先前事件来预测下一个音乐事件。本节将创建的音乐 Transformer 拥有 2016 万个参数,足以捕捉不同音符在音乐作品中的长期关系,同时也可以在合理的时间内完成训练。
我们将使用 Maestro 钢琴音乐作为训练数据,MIDI 文件转换为音音符序列,类似于自然语言处理 (Natural Language Processing, NLP) 中的原始文本数据。接着,将这些音符拆分为小片段,称为音乐事件,这类似于 NLP 中的词元 (token)。由于神经网络只能接受数值输入,需要把每个唯一事件词元映射到一个索引。这样,训练数据中的音乐片段就被转换为一系列索引,用于输入神经网络。
经过训练的音乐 Transformer 能够生成逼真的音乐,模仿训练数据集中的风格。此外,与 MuseGAN 生成的音乐不同,我们可以通过调整温度参数来缩放预测的对数 (logits) 值,学习控制音乐创作的新颖性,类似于控制生成文本的新颖性。
1. 音乐 Transformer 简介
音乐 Transformer 将最初为 NLP 任务设计的 Transformer 架构扩展到了音乐生成领域。音乐 Transformer 通过从庞大的音乐数据集中学习,生成一系列音乐音符。该模型的训练目标是理解训练数据中不同音乐元素之间的模式、结构和关系,基于先前的音乐事件,预测序列中的下一个音乐事件。
训练音乐 Transformer 的一个关键步骤是如何将音乐表示为一系列独特的音乐事件,类似于 NLP 中的词元。在 MuseGAN 中,将一段音乐表示为一个 4D 对象。在本节中,将介绍一种不同的音乐表示方法------基于演奏的音乐表示法,具体是通过控制信息和力度值来表示。基于此,将把一段音乐转换为四种类型的音乐事件:音符开始 (note-on)、音符结束 (note-off)、时间偏移 (time-shift) 和力度 (velocity)。
Note-on 表示一个音符的开始,指定音符的音高;Note-off 表示音符的结束,指示乐器停止演奏该音符;Time-shift 表示两个音乐事件之间的时间间隔;Velocity 表示音符的演奏力度,数值越大表示音符的声音越强、越响。每种类型的音乐事件都有不同的值。每个独特事件被映射到一个不同的索引,有效地将一段音乐转换为一系列索引。然后,将应用 GPT 模型,创建一个仅包含解码器的音乐 Transformer,来预测序列中的下一个音乐事件。
1.1 基于演奏的音乐表示
基于演奏的音乐表示通常通过 MIDI 格式来实现,MIDI 通过控制信息和力度值捕捉音乐表演的细微差别。在 MIDI 中,音乐音符通过 note-on 和 note-off 消息来表示,这些消息包含每个音符的音高和力度信息。
音高值的范围是从 0 到 127,每个值对应于一个音阶中的半音。例如,音高值 60 对应于 C4 音符,而音高值 74 对应于 D5 音符。力度值的范围也是从 0 到 127,表示音符的动态特征,值越高表示演奏越响亮或越有力。通过结合这些控制信息和力度值,MIDI 序列可以捕捉音乐的表现细节。为了说明如何通过控制信息和力度值来表示一段音乐,考虑以下五个音符:

这是训练数据集中一段音乐的前五个音符。第一个音符的时间戳大约是 1.03 秒,音高值为 74 (D5) 的音符以 86 的力度开始演奏。观察第二个音符,可以推断出大约 0.01 秒后(因为时间戳是 1.04 秒),音高值为 38 的音符以 77 的力度开始演奏,依此类推。
这些音符类似于 NLP 中的原始文本,不能直接将它们输入到音乐 Transformer 中来训练模型。首先需要对音符进行分词,然后将分词结果(词元)转换为索引,才能将其输入模型。
为了对音乐音符进行分词,我们将使用 0.01 秒的增量来表示音乐,从而减少音乐片段中的时间步数。此外,我们将控制信息与力度值分开,并将它们视为音乐片段的不同元素。具体来说,我们将使用 note-on、note-off、time-shift 和 velocity 事件的组合来表示音乐。完成这些操作后,上述的五个音乐音符可以表示为以下事件:
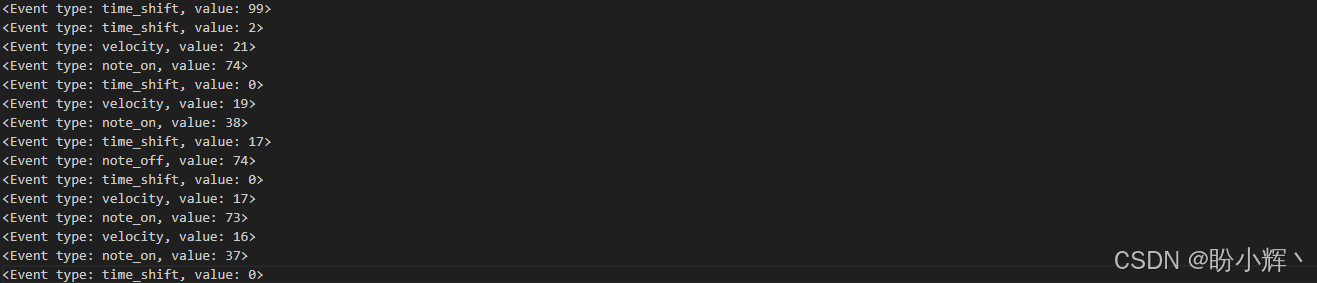
我们将以 0.01 秒为单位来计量时间偏移,并将时间偏移从 0.01 秒到 1 秒划分为 100 个不同的值进行分词处理。如果时间偏移超过 1 秒,可以使用多个时间偏移词元来表示。例如,前两个词元都是时间偏移词元,值分别为 99 和 2,分别表示 1 秒和 0.03 秒的时间间隔,与第一个音符的时间戳 1.0326 秒相匹配。
力度是一种独立的音乐事件类型。我们将力度值划分为 32 个等间距的区间,将原始力度值(范围从 0 到 127)转换为 32 个值之一(范围从 0 到 31)。因此第一个音符的原始力度值 86 表示为力度事件值为 21。
下表展示了四种不同类型的分词事件的含义、它们的取值范围以及每个事件词元的意义:
| 事件词元类型 | 事件词元取值范围 | 时间次元含义 |
|---|---|---|
| note_on | 0--127 | 在某个音高值上开始播放,例如,note_on 值为 74 表示开始播放音符 D5 |
| note_off | 0--127 | 释放某个音符,例如,note_off 值为 60 表示停止播放音符 C4 |
| time_shift | 0--99 | 时间偏移值是 0.01 秒的增量,例如,0 表示 0.01 秒,2 表示 0.03 秒,99 表示 1 秒 |
| velocity | 0--31 | 原始力度值被划分为 32 个区间 (bin),并采用区间值作为代表,例如,原始l力度值为 86 对应的标记化值为 21 |
与 NLP 中的方法类似,我们将把每个独特词元转换为索引,以便将数据输入神经网络。根据上表,共有 128 个独特的音符开始事件词元、128 个音符结束事件词元、32 个力度事件词元和 100 个时间偏移事件词元,总计 128 + 128 + 32 + 100 = 388 个独特词元。因此,我们根据下表中的映射关系,将这 388 个独特词元转换为从 0 到 387 的索引。
| 词元类型 | 索引范围 | 事件词元转换为索引 | 索引转换为词元索引 |
|---|---|---|---|
| note_on | 0--127 | note_on 词元的值,例如,值为 74 的 note_on 词元会被赋予索引值 74 | 如果索引范围是 0 到 127,将词元类型设置为 note_on,值设置为索引值,例如,索引值 63 被映射为值为 63 的 note_on 词元 |
| note_off | 128--255 | 128 加上 note_off 词元的值,例如,值为 60 的 note_off 词元会被赋予索引值 188 (128 + 60 = 188) | 如果索引范围是 128 到 255,将词元类型设置为 note_off,值设置为索引减去 128,例如,索引值 180 被映射为值为 52 的 note_off 词元 |
| time_shift | 256--355 | 256 加上 time_shift 词元的值,例如,值为 16 的 time_shift 词元会被赋予索引值 272 (256 + 16 = 272) | 如果索引范围是 256 到 355,将词元类型设置为 time_shift,值设置为索引减去 256,例如,索引值 288 被映射为值为 32 的 time_shift 词元 |
| velocity | 356--387 | 356 加上 velocity 词元的值,例如,值为 21 的 velocity 词元会被赋予索引值 377 (356 + 21 = 377) | 如果索引范围是 356 到 387,将词元类型设置为 velocity,值设置为索引减去 356,例如,索引值 380 被映射为值为 24 的 velocity 词元 |
使用这种词元到索引的映射,可以把每段音乐转换为索引序列。我们对训练数据集中的所有音乐片段应用这种转换,并使用生成的索引序列来训练我们的音乐 Transformer。训练完成后,我们将使用 Transformer 生成索引序列形式的音乐。最后一步是将该序列转换回 MIDI 格式,以便可以在计算机上播放。
1.2 音乐 Transformer 架构
音乐生成模型基于音乐序列中先前的事件词元来生成后续的事件词元。因此,我们将为音乐生成任务构建一个仅解码器 Transformer。音乐 Transformer 利用自注意力机制捕捉音乐作品中不同音乐事件之间的长期依赖关系,从而生成连贯且逼真的音乐。尽管我们的音乐 Transformer 与 GPT 模型的大小不同,但其核心架构是相同的,遵循与 GPT-2 模型相同的结构设计,但其规模较小。
具体来说,我们的音乐 Transformer 包含 6 个解码器层,每个解码器层的嵌入维度为 512,这意味着每个词元在词嵌入之后由一个 512 维的向量表示。使用嵌入层来学习序列中不同位置的位置编码,因此,序列中的每个位置也由一个 512 维的向量表示。为了计算因果自注意力,我们使用 8 个并行的注意力头来捕捉序列中词元含义的不同方面,每个注意力头的维度为 512/8=64。
我们的音乐 Transformer 模型词汇量为 390 (包含 388 个不同的事件词元,加上一个表示序列结束的词元和一个用于填充较短序列的词元)。因此,我们可以将音乐 Transformer 中的最大序列长度设置为 2,048,这对于捕捉音乐序列中音符的长期依赖关系至关重要。下图展示了我们在本节中创建的音乐 Transformer 的架构,以及训练数据在训练过程中通过模型时的大小。
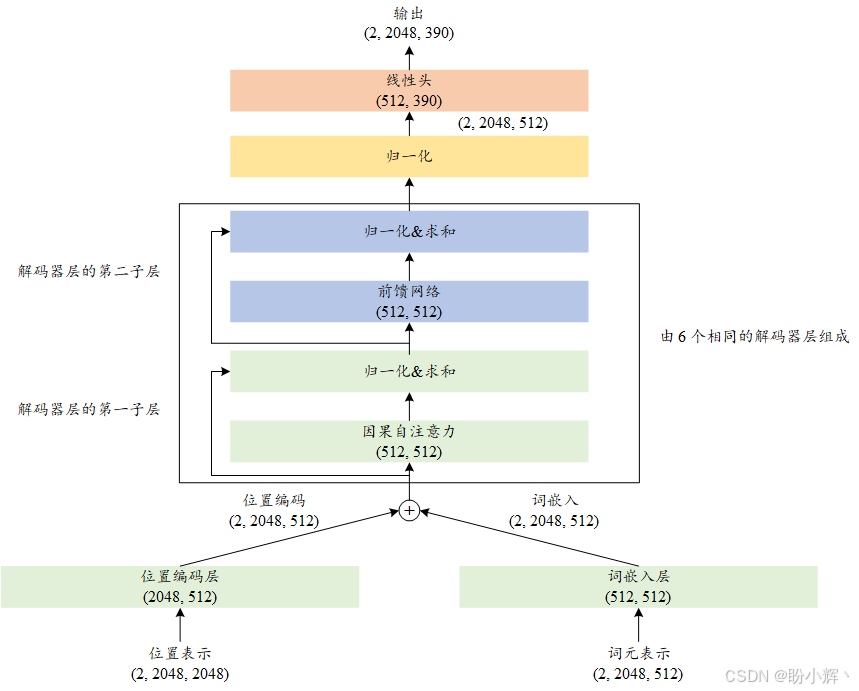
我们构建的音乐 Transformer 的输入嵌入是输入序列的词嵌入和位置编码的总和。然后,这个输入嵌入依次通过六个解码器块。每个解码器层由两个子层组成:一个因果自注意力层和一个前馈网络。此外,我们对每个子层应用层归一化和残差连接,以增强模型的稳定性和学习能力。
经过解码器层后,输出会进行层归一化,然后送入到一个线性层。我们模型的输出数目与词汇表中独特音乐事件词元的数量相对应,即 390。模型的输出是下一个音乐事件词元的 logits。之后,我们将对这些 logits 应用 softmax 函数,以获得所有可能事件词元的概率分布。该模型旨在基于当前词元和音乐序列中的所有先前词元来预测下一个事件词元,从而生成连贯且具有乐感的序列。
1.3 训练音乐 Transformer 流程
模型生成的音乐风格受到用于训练的音乐作品的影响。我们将使用 Google Magenta 的钢琴演奏数据来训练我们的模型。下图展示了训练 Transformer 进行音乐生成的步骤。
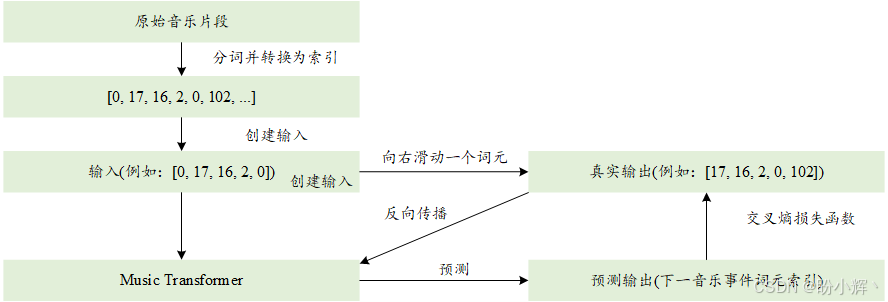
我们首先将训练集中的 MIDI 文件转换为音乐音符序列。然后,我们通过将这些音符进一步转换为 388 个独特事件词元之一来进行分词。分词后,我们为每个词元分配一个唯一的索引(即一个整数),将训练集中的音乐作品转换为整数序列。
接下来,我们通过将这些整数序列分割成长度相等的子序列来将其转化为训练数据。每个序列的最大长度为 2,048 个索引,这些序列构成了模型的输入特征 (x),我们将输入序列窗口向右滑动一个索引,并将其作为训练数据中的输出 (y)。使我们的模型根据当前词元和所有先前词元预测序列中的下一个音乐词元。
输入和输出对构成了音乐 Transformer 的训练数据 (x, y)。在训练过程中,遍历训练数据。在前向传播中,将输入序列 x 输入到音乐 Transformer 中。然后,音乐 Transformer 根据模型中的当前参数进行预测。通过将预测的下一个词元与真实输出进行比较,计算交叉熵损失。最后,使用优化器调整音乐 Transformer 中的参数。模型本质上是在执行一个多类别分类问题:它从词汇表中的所有独特音乐词元中预测下一个词元。多次重复以上过程,每次迭代后,模型的参数将被调整,以改进对下一个词元的预测。
2. 音乐片段分词
首先使用基于演奏的表示方法来将音乐作品表示为音符,把这些音符划分为一系列事件,类似于 NLP 中的词元。每个独特事件将分配一个不同的索引。利用这种映射关系,我们将把训练数据集中的所有音乐作品转换为索引序列。
接下来,我们将把这些索引序列标准化为固定长度,并将其作为特征输入 (x)。通过将窗口向右移动一个索引,生成相应的输出序列 (y)。然后,把输入-输出对 (x, y) 分成批数据。
由于我们需要使用 pretty_midi 和 music21 库来处理 MIDI 文件,因此首先进行安装:
python
$ pip install pretty_midi music212.1 下载训练数据
(1) 从 MAESTRO 数据集获取钢琴演奏数据,下载 ZIP 文件。下载完成后,解压文件并将解压出来的文件夹 /maestro-v2.0.0/ 移动到 ./files/ 目录中。maestro-v2.0.0 文件夹中包含 4 个文件以及 10 个子文件夹。每个子文件夹包含超过 100 个 MIDI 文件。
(2) 将 MIDI 文件划分为训练集、验证集和测试集。首先,在 ·./files/maestro-v2.0.0/· 文件夹内创建三个子文件夹:
python
import os
os.makedirs("files/maestro-v2.0.0/train", exist_ok=True)
os.makedirs("files/maestro-v2.0.0/val", exist_ok=True)
os.makedirs("files/maestro-v2.0.0/test", exist_ok=True)(3) 为了方便处理 MIDI 文件,编写 processor.py 文件,将 MIDI 文件转换为索引序列,或反之将索引序列转换为 MIDI 文件。为了使我们能够专注于开发、训练和使用音乐 Transformer,而不需要被音乐格式转换的细节困扰,可以直接下载 processor.py 文件。
(4) ./maestro-v2.0.0/ 文件夹中的 maestro-v2.0.0.json 文件包含所有 MIDI 文件的名称及其指定的子集(训练集、验证集或测试集)。根据这些信息,我们将把 MIDI 文件划分到三个相应的子文件夹中:
python
import json
import pickle
from processor import encode_midi
file="files/maestro-v2.0.0/maestro-v2.0.0.json"
with open(file,"r") as fb:
# 加载 JSON 文件
maestro_json=json.load(fb)
# 遍历训练数据中的所有文件
for x in maestro_json:
mid=rf'files/maestro-v2.0.0/{x["midi_filename"]}'
# 根据 JSON 文件中的指令,将文件放入训练、验证或测试子文件夹
split_type = x["split"]
f_name = mid.split("/")[-1] + ".pickle"
if(split_type == "train"):
o_file = rf'files/maestro-v2.0.0/train/{f_name}'
elif(split_type == "validation"):
o_file = rf'files/maestro-v2.0.0/val/{f_name}'
elif(split_type == "test"):
o_file = rf'files/maestro-v2.0.0/test/{f_name}'
prepped = encode_midi(mid)
with open(o_file,"wb") as f:
pickle.dump(prepped, f)
# 验证每个文件夹中的文件数量:
train_size=len(os.listdir('files/maestro-v2.0.0/train'))
print(f"there are {train_size} files in the train set")
val_size=len(os.listdir('files/maestro-v2.0.0/val'))
print(f"there are {val_size} files in the validation set")
test_size=len(os.listdir('files/maestro-v2.0.0/test'))
print(f"there are {test_size} files in the test set")输出结果如下所示:
shell
there are 967 files in the train set
there are 137 files in the validation set
there are 178 files in the test set2.2 MIDI 文件分词
(1) 将每个 MIDI 文件表示为一系列的音符:
python
import pickle
from processor import encode_midi
import pretty_midi
from processor import (_control_preprocess,
_note_preprocess,_divide_note,
_make_time_sift_events,_snote2events)
# 从训练集中选择一个 MIDI 文件
file='MIDI-Unprocessed_Chamber1_MID--AUDIO_07_R3_2018_wav--2'
name=rf'files/maestro-v2.0.0/2018/{file}.midi'
events=[]
notes=[]
# convert song to an easily-manipulable format
song=pretty_midi.PrettyMIDI(name)
for inst in song.instruments:
inst_notes=inst.notes
ctrls=_control_preprocess([ctrl for ctrl in
inst.control_changes if ctrl.number == 64])
# 从音乐中提取音乐事件
notes += _note_preprocess(ctrls, inst_notes)
# 将所有音乐事件放入列表 dnotes 中
dnotes = _divide_note(notes)
dnotes.sort(key=lambda x: x.time)
for i in range(5):
print(dnotes[i]) 我们从训练数据集中选择了一个 MIDI 文件,并使用 processor.py 模块将其转换为一系列音符。输出结果如下所示:

可以看到,输出中的时间表示是连续的。某些音符同时包含 note_on 和 velocity 属性,由于时间表示的连续性,这会导致大量独特的音乐事件,从而使分词过程变得复杂。此外,不同的 note_on 和 velocity 值的组合非常庞大,这会导致词汇表大小过大,使训练变得不切实际。
(2) 为了解决这个问题并减少词汇表的大小,我们进一步将这些音符转换为词元事件:
python
cur_time = 0
cur_vel = 0
for snote in dnotes:
# 对时间进行离散化,以减少唯一事件的数量
events += _make_time_sift_events(prev_time=cur_time,
post_time=snote.time)
# 将音符转换为事件
events += _snote2events(snote=snote, prev_vel=cur_vel)
cur_time = snote.time
cur_vel = snote.velocity
indexes=[e.to_int() for e in events]
# 打印出前 15 个事件
for i in range(15):
print(events[i])输出结果如下:
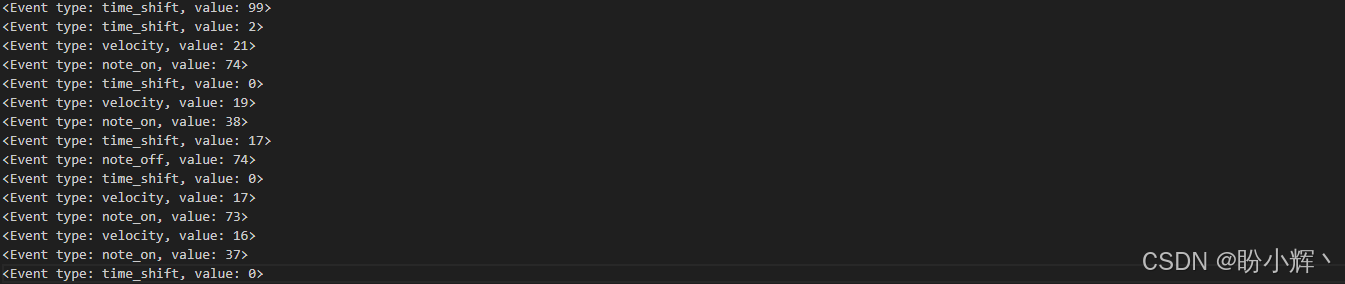
现在,音乐作品由四种类型的事件表示:note-on (音符开始)、note-off (音符结束)、time-shift (时间偏移)和 velocity (力度)。每种事件类型包含不同的值,最终共有 388 个独特事件,将 MIDI 文件转换为这些独特事件的序列。
2.3 准备训练数据
(1) 定义 create_xys() 函数准备训练数据,以便用于训练音乐 Transformer:
python
import torch,os,pickle
max_seq=2048
def create_xys(folder):
files=[os.path.join(folder,f) for f in os.listdir(folder)]
xys=[]
for f in files:
with open(f,"rb") as fb:
music=pickle.load(fb)
music=torch.LongTensor(music)
# 创建 (x, y) 序列,序列长度为 2,048 个索引,并将索引 399 设置为填充索引
x=torch.full((max_seq,),389, dtype=torch.long)
y=torch.full((max_seq,),389, dtype=torch.long)
length=len(music)
if length<=max_seq:
print(length)
# 使用最多 2,048 个索引的序列作为输入
x[:length]=music
# 将窗口向右滑动一个索引,并将其作为输出
y[:length-1]=music[1:]
# 将结束索引设置为 388
y[length-1]=388
else:
x=music[:max_seq]
y=music[1:max_seq+1]
xys.append((x,y))
return xys遍历下载的训练数据集中的所有音乐作品。如果一首音乐作品的长度超过 2,048 个索引,我们将使用前 2,048 个索引作为输入 (x)。对于输出 (y),我们将使用从第二个位置到第 2,049 个位置的索引。如果音乐作品的长度小于或等于 2,048 个索引,我们将使用索引 389 对序列进行填充,以确保 x 和 y 都是 2,048 个索引的长度。另外,我们使用索引 388 来标记序列 y 的结束。
共有 388 个独特事件标记,索引范围为 0 到 387。由于我们使用 388 来标记序列 y 的结束,使用 389 来填充序列,因此共有 390 个独特索引,范围从 0 到 389。
(2) 对训练子集应用 create_xys() 函数:
python
trainfolder='files/maestro-v2.0.0/train'
train=create_xys(trainfolder)输出结果如下所示:
shell
1771
5
15
586
1643输出表明,在训练子集中的 967 首音乐作品中,只有 5 首的长度少于 2,048 个索引。
(3) 对验证集和测试集应用 create_xys() 函数:
python
valfolder='files/maestro-v2.0.0/val'
testfolder='files/maestro-v2.0.0/test'
print("processing the validation set")
val=create_xys(valfolder)
print("processing the test set")
test=create_xys(testfolder)输出结果如下所示:
shell
processing the validation set
processing the test set
1837(4) 打印出一个验证子集中的文件:
python
val1, _ = val[0]
print(val1.shape)
print(val1)输出结果如下所示:
shell
torch.Size([2048])
tensor([350, 364, 52, ..., 67, 301, 370])验证集中第一个输入-输出对的 x 序列的长度为 2,048 个索引,使用模块 processor.py 来解码该序列为 MIDI 文件,用于进行播放:
python
from processor import decode_midi
file_path="files/val1.midi"
decode_midi(val1.cpu().numpy(), file_path=file_path)(5) 最后,创建数据加载器,以便将数据按批次提供给模型训练:
python
from torch.utils.data import DataLoader
batch_size=2
trainloader=DataLoader(train,batch_size=batch_size,
shuffle=True)3. 构建音乐生成 Transformer
训练数据准备完毕后,我们将从零开始构建一个用于音乐生成的 GPT 模型,该模型的架构将类似于GPT-2XL 模型。像所有的 Transformer 一样,我们的音乐 Transformer 也使用自注意力机制来捕捉序列中不同元素之间的关系。因此,我们在模块 util.py 中定义 CausalSelfAttention() 类。将前馈网络与因果自注意力子层结合,形成一个解码器块(即解码器层)。对每个子层应用层归一化和残差连接,以提高稳定性和性能。为此,在模块 util.py 中定义 Block() 类来创建解码器块。接着,将六个解码器块堆叠在一起,形成我们音乐 Transformer 的主体。限于篇幅,模块 util.py可以直接进行下载。
3.1 音乐 Transformer 超参数
(1) 使用 Config() 类来存储所有在音乐 Transformer 中使用的超参数:
python
from torch import nn
class Config():
def __init__(self):
self.n_layer = 6
self.n_head = 8
self.n_embd = 512
self.vocab_size = 390
self.block_size = 2048
self.embd_pdrop = 0.1
self.resid_pdrop = 0.1
self.attn_pdrop = 0.1
config=Config()
device="cuda" if torch.cuda.is_available() else "cpu"将 n_layer 属性设置为 6,表示我们的音乐 Transformer 包含 6 个解码器层;n_head 属性设置为 8,意味着在计算因果自注意力时,我们将查询 Q、键 K 和值 V 向量划分为 8 个并行的注意力头;n_embd 属性设置为 512,表示嵌入维度为 512:每个事件词元将由一个包含 512 个值的向量表示;vocab_size 属性由词汇表中独特词元的数量决定,值为 390,包括 388 个独特事件词元,1 个词元来表示序列的结束,1 个·词元来填充较短的序列,以确保所有序列的长度都是 2,048;block_size 属性设置为 2,048,表示输入序列的最大词元数为 2,048;将 dropout 率设置为 0.1。
3.2 构建音乐Transformer
(1) 通过实例化 Model() 类来创建我们的音乐 Transformer:
python
from util import Model
model=Model(config)
model.to(device)
num=sum(p.numel() for p in model.transformer.parameters())
print("number of parameters: %.2fM" % (num/1e6,))
print(model)输出结果如下所示:
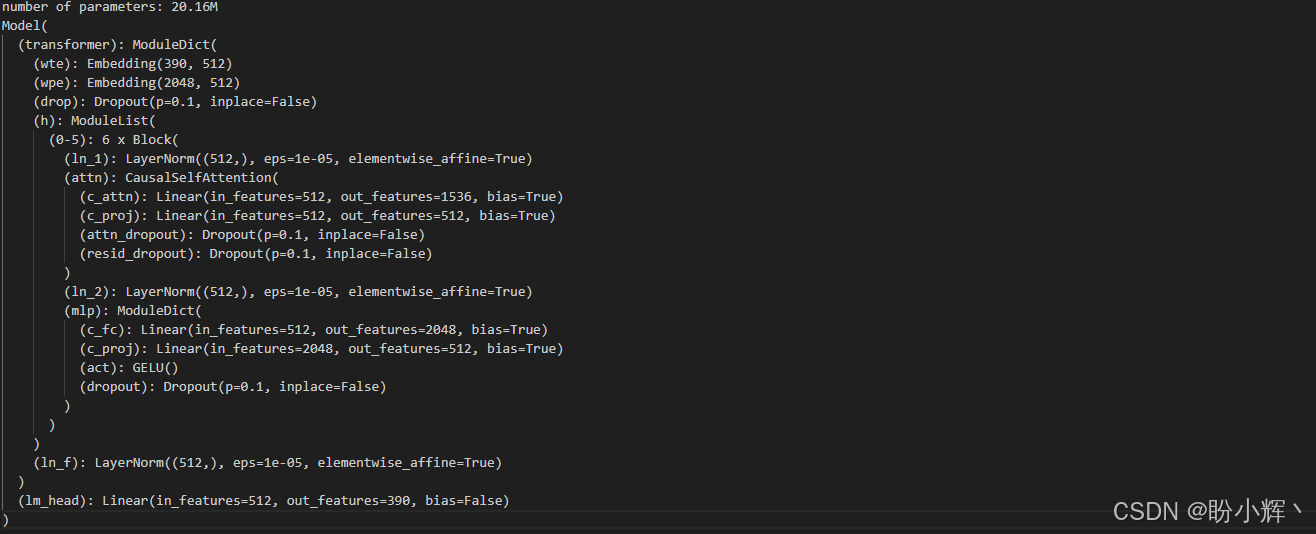
我们的音乐 Transformer 包含 2016 万个参数,这个数字远小于 GPT-2XL,后者有超过 15 亿个参数。尽管存在差异,但这两个模型都基于仅解码器的 Transformer 架构,不同之处仅在于超参数,如嵌入维度、解码器层数、词汇表大小等。
4 训练和使用音乐Transformer
在本节中,将使用准备好的训练数据来训练构建的音乐 Transformer,训练模型 100 个 epoch。模型训练完成后,我们将以索引序列的形式为其提供输入提示。然后,使用训练好的音乐 Transformer 生成下一个索引,将新索引添加到提示中,更新后的提示再次输入模型进行下一次预测。反复进行以上过程,直到序列达到指定长度。我们也可以通过应用不同的温度参数来控制音乐作品的创意性。
4.1 训练音乐Transformer
(1) 使用 Adam 优化器进行训练。由于我们的音乐 Transformer 本质上是在执行一个多类别分类任务,使用交叉熵损失作为损失函数:
python
lr=0.0001
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func=torch.nn.CrossEntropyLoss(ignore_index=389)上述损失函数中的 ignore_index=389 参数指示程序在目标序列(即序列 y)中遇到索引 389 时忽略它,因为该索引仅用于填充目的,并不表示音乐作品中的任何特定事件词元。
(2) 训练模型 100 个 epoch:
python
model.train()
for i in range(1,101):
tloss = 0.
# 遍历所有训练数据批次
for idx, (x,y) in enumerate(trainloader):
x,y=x.to(device),y.to(device)
output = model(x)
# 将模型预测与实际输出进行比较
loss=loss_func(output.view(-1,output.size(-1)),
y.view(-1))
optimizer.zero_grad()
loss.backward()
# 将梯度范数裁剪为 1
nn.utils.clip_grad_norm_(model.parameters(),1)
# 调整模型参数
optimizer.step()
tloss += loss.item()
print(f'epoch {i} loss {tloss/(idx+1)}')
# 保存训练完成的模型
torch.save(model.state_dict(),f'files/musicTrans.pth') 4.2 使用训练好的 Transformer 生成音乐
(1) 训练音乐 Transformer 模型完成后,可以进行音乐生成。与文本生成过程类似,音乐生成从将一个索引序列(表示事件词元)作为提示输入模型开始。我们从测试集随机选择一首音乐作品,并使用前 250 个音乐事件作为提示:
python
from processor import decode_midi
prompt, _ = test[42]
prompt = prompt.to(device)
len_prompt=250
file_path = "files/prompt.midi"
decode_midi(prompt[:len_prompt].cpu().numpy(),
file_path=file_path)我们仅保留前 250 个音乐事件,稍后将把它们输入训练好的模型,以预测接下来的音乐事件。为了进行比较,我们将提示保存为 MIDI 文件 prompt.midi。
(2) 为了简化音乐生成过程,定义 sample() 函数,使用温度 (temperature) 参数调节生成音乐的新颖性。该函数接受一个索引序列作为输入,表示一段短的音乐片段。然后,它迭代地预测并将新索引附加到序列中,直到达到指定长度 seq_length:
python
softmax=torch.nn.Softmax(dim=-1)
def sample(prompt,seq_length=1000,temperature=1):
gen_seq=torch.full((1,seq_length),389,dtype=torch.long).to(device)
idx=len(prompt)
gen_seq[..., :idx]=prompt.type(torch.long).to(device)
# 生成新的索引,直到序列达到指定长度
while(idx < seq_length):
# 将预测结果除以 temperature 参数,然后对 logits 应用 softmax 函数
y=softmax(model(gen_seq[..., :idx])/temperature)[...,:388]
probs=y[:, idx-1, :]
distrib=torch.distributions.categorical.Categorical(probs=probs)
# 从预测的概率分布中采样,以生成新的索引
next_token=distrib.sample()
gen_seq[:, idx]=next_token
idx+=1
# 输出整个序列
return gen_seq[:, :idx](3) 将训练好的权重加载到模型中:
python
model.load_state_dict(torch.load("files/musicTrans.pth", weights_only=False))
model.eval()(4) 调用 sample() 函数生成一段音乐:
python
from processor import encode_midi
file_path = "files/prompt.midi"
prompt = torch.tensor(encode_midi(file_path))
generated_music=sample(prompt, seq_length=1000)使用来自 processor.py 模块的 encode_midi() 函数,将 MIDI 文件 prompt.midi 转换为一个索引序列。然后,将这个序列作为提示输入到 sample() 函数中,生成一段由 1,000 个索引组成的音乐。
(5) 最后,将生成的索引序列转换为 MIDI 格式:
python
music_data = generated_music[0].cpu().numpy()
file_path = 'files/musicTrans.midi'
decode_midi(music_data, file_path=file_path)使用 processor.py 模块中的 decode_midi() 函数,将生成的索引序列转换为 MIDI 文件 musicTrans.midi 并保存。输出结果如下所示:
shell
info removed pitch: 73
info removed pitch: 60
info removed pitch: 80
info removed pitch: 39在生成的音乐中,可能会出现需要移除某些音符的情况。例如,如果生成的音乐尝试结束音符 52,但音符 52 最初并未开始,那么我们就无法结束它。因此,我们需要移除这些音符。
(6) 可以通过将 temperature 参数设置为大于 1 的值来增加音乐的新颖性:
python
file_path = "files/prompt.midi"
prompt = torch.tensor(encode_midi(file_path))
generated_music=sample(prompt, seq_length=1000,temperature=1.5)
music_data = generated_music[0].cpu().numpy()
file_path = 'files/musicHiTemp.midi'
decode_midi(music_data, file_path=file_path)小结
- 基于演奏的音乐表示法使我们能够将一段音乐表示为音符序列,这些音符包括控制信息和力度值,这些音符可以进一步简化为四种音乐事件:音符开始 (
note-on)、音符结束 (note-off)、时间偏移 (time-shift) 和力度 (velocity)。每种事件类型可以取不同的值。因此,我们可以将一段音乐转换为词元序列,再将其转换为索引序列 - 音乐
Transformer采用了最初为NLP任务设计的Transformer架构,并将其调整用于音乐生成。这个模型的设计目标是通过从大量现有音乐数据集中学习,生成音符序列。通过识别训练数据中各种音乐元素的模式、结构和关系,来预测序列中的下一个音符
系列链接
PyTorch生成式人工智能实战:从零打造创意引擎
PyTorch生成式人工智能(1)------神经网络与模型训练过程详解
PyTorch生成式人工智能(2)------PyTorch基础
PyTorch生成式人工智能(3)------使用PyTorch构建神经网络
PyTorch生成式人工智能(4)------卷积神经网络详解
PyTorch生成式人工智能(5)------分类任务详解
PyTorch生成式人工智能(6)------生成模型(Generative Model)详解
PyTorch生成式人工智能(7)------生成对抗网络实践详解
PyTorch生成式人工智能(8)------深度卷积生成对抗网络
PyTorch生成式人工智能(9)------Pix2Pix详解与实现
PyTorch生成式人工智能(10)------CyclelGAN详解与实现
PyTorch生成式人工智能(11)------神经风格迁移
PyTorch生成式人工智能(12)------StyleGAN详解与实现
PyTorch生成式人工智能(13)------WGAN详解与实现
PyTorch生成式人工智能(14)------条件生成对抗网络(conditional GAN,cGAN)
PyTorch生成式人工智能(15)------自注意力生成对抗网络(Self-Attention GAN, SAGAN)
PyTorch生成式人工智能(16)------自编码器(AutoEncoder)详解
PyTorch生成式人工智能(17)------变分自编码器详解与实现
PyTorch生成式人工智能(18)------循环神经网络详解与实现
PyTorch生成式人工智能(19)------自回归模型详解与实现
PyTorch生成式人工智能(20)------像素卷积神经网络(PixelCNN)
PyTorch生成式人工智能(21)------归一化流模型(Normalizing Flow Model)
PyTorch生成式人工智能(22)------GLOW详解与实现
PyTorch生成式人工智能(23)------能量模型(Energy-Based Model)
PyTorch生成式人工智能(24)------使用PyTorch构建Transformer模型
PyTorch生成式人工智能(25)------基于Transformer实现机器翻译
PyTorch生成式人工智能(26)------使用PyTorch构建GPT模型
PyTorch生成式人工智能(27)------从零开始训练GPT模型
PyTorch生成式人工智能(28)------MuseGAN详解与实现