一、实验准备
明确集群角色与网络规划
实验环境的节点分工是后续所有操作的基础,需先明确每个节点的核心作用,避免资源混乱或网络不通导致部署失败:
-
k8s-master(192.168.67.100)
- Kubernetes 控制平面,负责集群资源调度、API 管理(如创建 StatefulSet、Service 等),是整个集群的 "大脑"。
-
k8s-node1(192.168.67.10)
-
k8s-node2(192.168.67.20)
- Kubernetes 工作节点,实际运行 Redis Pod、Proxy Pod 等业务容器,承担数据存储和计算任务。
-
harbor-nfs(192.168.67.123)
- 双重角色 ------① 提供 NFS 共享存储,用于 Redis 数据持久化(避免 Pod 删除后数据丢失);② 作为私有镜像仓库(Harbor),存储 Redis、Redis Proxy、RedisInsight 等镜像,避免依赖外部仓库(如 Docker Hub)的网络波动。
为什么这样规划?
-
分离控制平面与工作节点:避免 master 节点因运行业务容器导致资源不足,保证集群调度稳定。
-
独立 NFS 存储节点:Redis 集群需要持久化存储(如 AOF 文件、集群配置文件 nodes.conf),NFS 是跨节点共享存储的低成本方案,适合中小规模集群;同时集成 Harbor 可统一管理私有镜像,提高拉取效率和安全性。
二、搭建 nfs 共享目录
为 Redis 提供持久化存储基础
Redis 集群是有状态应用,数据(如键值对、集群槽位配置)必须持久化到外部存储,否则 Pod 重启 / 重建后数据会丢失。NFS 的核心作用是提供跨 K8s 节点的共享存储,让所有 Redis Pod 能访问统一的数据目录。
2.1.部署 NFS 服务端
NFS 主机(192.168.67.123)操作:
bash
dnf install nfs-utils -y
systemctl enable --now nfs-server.service
vim /etc/exports
###########
/nfsdata *(rw,sync,no_root_squash) # 配置 NFS 共享目录:定义哪些目录可被哪些客户端访问及权限
###########
exportfs -rv # 重新加载 NFS 配置:让 /etc/exports 的修改生效
showmount -e # 验证共享是否成功:查看当前 NFS 服务暴露的共享目录
关键配置解析:
-
**/nfsdata:**要共享的本地目录,后续 Redis 数据会存储到这里。
-
***:**允许所有客户端访问(实验环境简化配置,生产环境建议指定 K8s 节点 IP 段,如 192.168.67.0/24,提高安全性)。
-
**rw:**客户端对共享目录有读写权限(Redis 需要写入数据,只读权限会导致启动失败)。
-
**sync:**数据同步写入磁盘(而非缓存到内存),避免服务器断电导致数据丢失(牺牲少量性能换数据安全性)。
-
**no_root_squash:**客户端的 root 用户在共享目录下仍拥有 root 权限(Redis 容器默认用 root 启动,若开启 root_squash 会导致权限不足,无法写入数据)。
2.2.部署 NFS 客户端
所有 K8s 集群主机(master、node1、node2)操作:
bash
dnf install nfs-utils -y
showmount -e 192.168.67.123 # 验证能否访问 NFS 服务端的共享目录:确保网络通畅、权限正常为什么要在 K8s 节点安装客户端?
K8s 的 Pod 挂载 NFS 存储时,实际是通过节点的 NFS 客户端将共享目录挂载到 Pod 内部,若节点未安装客户端,会导致挂载失败,Redis Pod 无法启动。
三、基于 k8s 配置 redis 集群
从动态存储到集群初始化
这部分是核心流程,需按 "动态存储供应 → 配置管理 → 有状态部署 → 集群初始化" 的顺序操作,核心目标是实现:① 数据持久化(动态 PV/PVC);② 节点高可用(3 主 3 从);③ 网络可发现(Headless Service)。
3.1.创建 SA 并授权
为 NFS Provisioner 赋予权限
K8s 中,Pod 默认使用 default ServiceAccount(SA),但该 SA 权限极低,无法创建 PV、管理 StorageClass 等资源。而 NFS Provisioner(动态存储供应器) 需要动态创建 PV,必须赋予它足够的权限。
bash
vim provisionerPrivilege.yml
##########
# 1. 创建独立命名空间:将 NFS Provisioner 资源与其他应用隔离,方便管理
apiVersion: v1
kind: Namespace
metadata:
name: nfs-provisioner
---
# 2. 创建专用 SA:用于运行 NFS Provisioner Pod,避免使用 default SA 权限混乱
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner-svc
namespace: nfs-provisioner
---
# 3. 创建 ClusterRole:定义 Provisioner 需要的集群级权限(跨命名空间生效)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: nfs-clusterrole
rules:
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- watch
- create
- delete
- apiGroups:
- ""
resources:
- persistentvolumeclaims
verbs:
- get
- list
- watch
- update
- apiGroups:
- "storage.k8s.io"
resources:
- storageclasses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- update
- patch
---
# 4. 绑定 ClusterRole 到 SA:让 SA 拥有 ClusterRole 定义的权限
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-clusterrolebinding
subjects:
- kind: ServiceAccount
name: nfs-provisioner-svc
namespace: nfs-provisioner
roleRef:
kind: ClusterRole
name: nfs-clusterrole
apiGroup: rbac.authorization.k8s.io
---
# 5. 创建 Role:定义 Provisioner 在自身命名空间内的权限(leader 选举)
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-elector
namespace: nfs-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"] # 用于多实例 Provisioner 的 leader 选举
---
# 6. 绑定 Role 到 SA:让 SA 拥有 leader 选举权限
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-electorbinding
namespace: nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner-svc
namespace: nfs-provisioner
roleRef:
kind: Role
name: leader-elector
apiGroup: rbac.authorization.k8s.io
##########
bash
kubectl apply -f provisionerPrivilege.yml # 应用配置并验证 SA 是否创建成功
kubectl -n nfs-provisioner get serviceaccounts
3.2.部署 NFS Provisioner
实现动态存储供应
手动创建 PV 效率低(尤其集群规模大时),NFS Provisioner 的核心作用是:用户只需创建 PVC(存储请求),Provisioner 自动创建 PV 并关联 NFS 共享目录,大幅降低运维成本。
bash
vim nfs-provioner.yml
###########
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nfs-provisioner
name: nfs-provisioner
namespace: nfs-provisioner
spec:
replicas: 2 # 部署 2 个实例,实现 Provisioner 自身高可用
selector:
matchLabels:
app: nfs-provisioner
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccountName: nfs-provisioner-svc # 使用前面创建的专用 SA
containers:
- image: sig-storage/nfs-subdir-external-provisioner:v4.0.2 # K8s 官方维护的 NFS 动态供应器镜像
name: nfs-subdir-external-provisioner
volumeMounts:
- name: nfs-root
mountPath: /persistentvolumes # 将 NFS 共享目录挂载到容器内,用于创建 PV 数据目录
env:
- name: PROVISIONER_NAME # 标识当前 Provisioner,后续 StorageClass 需指定此名称
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER # NFS 服务端 IP(即 harbor-nfs 节点)
value: 192.168.67.123
- name: NFS_PATH # NFS 服务端共享目录(与 /etc/exports 配置一致)
value: /nfsdata
volumes:
- name: nfs-root # 定义 NFS 卷,关联服务端共享目录
nfs:
server: 192.168.67.123
path: /nfsdata
###########
bash
kubectl apply -f nfs-provioner.yml # 应用配置并验证 Provisioner Pod 是否正常运行(需处于 Running 状态)
kubectl -n nfs-provisioner get pods
关键配置解析:
-
replicas:2:Provisioner 是动态存储的核心组件,单实例故障会导致无法创建新 PV,因此部署 2 个实例实现高可用(通过 leader 选举确保只有一个实例工作)。
-
volumeMounts:将 NFS 共享目录 /nfsdata 挂载到容器的 /persistentvolumes,后续 Provisioner 为 PVC 创建 PV 时,会在 /nfsdata 下生成独立子目录(如 redis-cluster-redis-cluster-data-redis-cluster-0),每个 PV 对应一个子目录,实现数据隔离。
-
PROVISIONER_NAME:必须与后续 StorageClass 的 provisioner 字段一致,否则 StorageClass 无法找到对应的 Provisioner,动态供应失败。
3.3.创建 StorageClass
定义动态 PV 的 "模板"
StorageClass 是动态存储的 "规则模板",用于指定 PV 的创建策略(如存储类型、清理策略),用户创建 PVC 时只需关联该 StorageClass,即可自动生成符合规则的 PV。
bash
vim storageclass.yml
#########
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storageclass # StorageClass 名称,后续 PVC 需指定此名称
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # 关联前面的 Provisioner
parameters:
archiveOnDelete: "false" # 删除 PVC 时,是否归档 NFS 目录(false=直接删除,避免残留数据;true=改名归档,用于数据恢复)
#########
bash
kubectl apply -f storageclass.yml # 应用配置并清理旧 StorageClass(避免同名冲突)
kubectl delete storageclasses.storage.k8s.io nfs-client
为什么需要 StorageClass?
-
统一 PV 配置:避免用户创建 PVC 时手动指定 PV 的存储类型、权限等,减少配置错误。
-
支持多存储类型:若集群有多种存储(如 NFS、Ceph),可创建多个 StorageClass,用户按需选择(如 Redis 用 NFS,数据库用 Ceph)。
-
archiveOnDelete: "false":实验环境中,删除 PVC 后通常不需要保留数据,设为 false 可自动清理 NFS 目录,避免磁盘空间浪费;生产环境若需数据备份,可设为 true。
3.4.创建 Redis 命名空间
隔离 Redis 相关资源
bash
vim namespace.yml
########
apiVersion: v1
kind: Namespace
metadata:
name: redis-cluster # Redis 集群专属命名空间
########
bash
kubectl apply -f namespace.yml # 应用配置并验证
kubectl get namespaces | grep redis
命名空间的核心作用:
-
资源隔离:将 Redis 的 Pod、Service、ConfigMap 等资源集中在 redis-cluster 命名空间,避免与 NFS Provisioner、其他应用(如 MySQL)的资源混淆,方便后续管理(如批量删除、权限控制)。
-
权限控制:可针对命名空间设置 RBAC 权限,例如只允许特定 SA 操作 redis-cluster 命名空间的资源,提高安全性。
3.5.创建 Redis 配置 ConfigMap
统一管理集群配置
Redis 集群需要统一的配置(如开启集群模式、持久化策略、密码),将配置文件放入 ConfigMap,可实现 "配置与容器分离"------ 修改配置时无需重建镜像,只需更新 ConfigMap 并重启 Pod。
bash
vim redis.conf
###########
protected-mode no
appendonly yes
dir /data
port 6379
cluster-enabled yes
cluster-config-file /data/nodes.conf
clueter-node-timeout 5000
masterauth openlab
requirepass openlab
############
bash
kubectl create configmap redis-config --from-file=redis.conf -n redis-cluster --dry-run=client -o yaml > configmap-redis.yml
vim configmap-redis.yml
#############
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-config # ConfigMap 名称,后续 StatefulSet 需引用
namespace: redis-cluster
data:
redis.conf: | # 将上面编写的 redis.conf 内容填入
protected-mode no
appendonly yes
dir /data
port 6379
cluster-enabled yes
cluster-config-file /data/nodes.conf
cluster-node-timeout 5000
masterauth openlab
requirepass openlab
#############
bash
kubectl apply -f configmap-redis.yml # 应用配置并验证 ConfigMap 是否创建成功
kubectl -n redis-cluster get configmaps
关键配置解析:
-
appendonly yes:Redis 持久化有两种方式 ------RDB(定时快照)和 AOF(实时日志)。开启 AOF 可确保 "每一次写操作都被记录",即使服务器断电,数据丢失风险极低,适合 Redis 集群的生产环境。
-
cluster-config-file /data/nodes.conf:nodes.conf 是 Redis 集群的核心配置文件,记录了所有节点的 IP、端口、槽位分配等信息,必须存储在持久化目录 /data(挂载 PVC),否则 Pod 重建后会丢失集群信息,导致集群崩溃。
-
masterauth 与 requirepass:两者都设为 openlab,确保:① 从节点连接主节点时需验证密码(防止未授权从节点加入);② 客户端访问 Redis 时需验证密码(防止未授权读写)。
3.6.创建 Headless Service
实现 Redis 节点间网络发现
Redis 集群的节点需要互相通信(如主从同步、槽位迁移),但 Pod 的 IP 是动态变化的(重启后 IP 会变),因此需要 Headless Service(无头服务) 提供固定的 DNS 域名,让节点通过域名访问,而非依赖动态 IP。
bash
vim headless.yml
##########
apiVersion: v1
kind: Service
metadata:
labels:
app: headless-redis
name: headless-redis # Service 名称,后续 StatefulSet 需引用
namespace: redis-cluster
spec:
clusterIP: None # Headless Service 的核心标识:无 ClusterIP,仅提供 DNS 解析
selector:
app.kubernetes.io/name: redis-cluster # 匹配 Redis Pod 的标签,确保 DNS 解析到正确的 Pod
type: ClusterIP
ports:
- port: 6379 # Service 暴露的端口
targetPort: 6379 # 转发到 Pod 的端口(与 Redis 监听端口一致)
##########
bash
kubectl apply -f headless.yml # 应用配置并验证 Service 是否创建成功
kubectl -n redis-cluster get service
Headless Service 与普通 Service 的区别:
| 特性 | 普通 Service(ClusterIP 类型) | Headless Service(clusterIP: None) |
|---|---|---|
| ClusterIP | 有(集群内唯一虚拟 IP) | 无 |
| 访问方式 | 通过 ClusterIP:Port 访问 | 通过 Pod DNS 域名访问 |
| 负载均衡 | 自动负载均衡到后端 Pod | 不提供负载均衡,仅解析 Pod 域名 |
| 适用场景 | 客户端访问无状态应用 | 有状态应用节点间通信(如 Redis 集群) |
为什么 Redis 集群需要 Headless Service? Redis 集群的节点需要知道其他节点的 "固定标识"(如主节点地址),若用普通 Service,客户端只能通过 ClusterIP 访问,无法直接定位到具体节点;而 Headless Service 会为每个 Pod 生成固定的 DNS 域名(格式:<pod-name>.<service-name>.<namespace>.svc.cluster.local,如 redis-cluster-0.headless-redis.redis-cluster.svc.cluster.local),节点可通过域名永久访问其他节点,即使 Pod IP 变化。
3.7.创建 StatefulSet
部署高可用 Redis 集群
Redis 集群是有状态应用 (需要固定的名称、存储、网络标识),而 Deployment 适合无状态应用(Pod 名称随机、存储共享),因此必须用 StatefulSet 部署,确保:① 每个 Pod 有固定名称(如 redis-cluster-0 到 redis-cluster-5);② 每个 Pod 有独立的 PVC(数据隔离);③ 每个 Pod 有固定 DNS 域名(通过 Headless Service)。
bash
vim statefulset.yml
##########
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: redis-cluster
name: redis-cluster # StatefulSet 名称
namespace: redis-cluster
spec:
serviceName: headless-redis # 关联 Headless Service,用于生成 Pod DNS 域名
replicas: 6 # 3 主 3 从(Redis 集群最小高可用配置:主节点数≥3,每个主节点至少 1 个从节点)
selector:
matchLabels:
app.kubernetes.io/name: redis-cluster # 匹配 Pod 标签
updateStrategy:
type: RollingUpdate # 滚动更新:避免更新时集群整体不可用
rollingUpdate:
partition: 1 # 先更新从节点(索引 1、3、5),再更新主节点(索引 0、2、4),降低风险
template:
metadata:
labels:
app.kubernetes.io/name: redis-cluster # Pod 标签,与 Headless Service 的 selector 匹配
spec:
# 反亲和性配置:避免多个 Redis Pod 调度到同一 K8s 节点,提高高可用
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 权重越高,调度器越优先满足
podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/name: redis-cluster
topologyKey: kubernetes.io/hostname # 按主机名隔离(同一主机不调度多个 Redis Pod)
containers:
- image: redis/redis:7.2.6 # Redis 稳定版本(避免使用 latest,版本不固定)
name: redis
command: ["redis-server"] # 启动命令
args:
- "/etc/redis/redis.conf" # 加载 ConfigMap 中的配置文件
- "--protected-mode"
- "no" # 再次确认关闭保护模式(防止配置文件未生效)
- "--cluster-announce-ip"
- "$(POD_IP)" # 声明当前 Pod 的 IP(Redis 集群需要节点向其他节点报告自己的 IP)
env:
- name: POD_IP # 通过 K8s downward API 获取当前 Pod 的 IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- name: redis
containerPort: 6379 # Redis 监听端口
protocol: TCP
volumeMounts:
- name: config # 挂载 ConfigMap 中的 redis.conf 到 /etc/redis
mountPath: /etc/redis
- name: redis-cluster-data # 挂载 PVC 到 /data,用于持久化数据
mountPath: /data
resources:
limits: # 资源上限:避免 Redis 占用过多资源,影响其他应用
cpu: '2'
memory: 4Gi
requests: # 资源请求:确保调度器为 Redis 分配足够资源
cpu: 50m
memory: 200Mi
volumes:
- name: config # 引用前面创建的 ConfigMap
configMap:
name: redis-config
items:
- key: redis.conf # ConfigMap 中的配置项名称
path: redis.conf # 挂载到容器内的路径(与 args 中的配置文件路径一致)
# PVC 模板:StatefulSet 会为每个 Pod 自动创建一个 PVC(名称格式:redis-cluster-data-<pod-name>)
volumeClaimTemplates:
- metadata:
name: redis-cluster-data # PVC 名称,与 volumeMounts 中的 name 一致
spec:
accessModes: ["ReadWriteOnce"] # 访问模式:只能被一个 Pod 挂载读写(Redis 数据目录不允许共享)
storageClassName: "nfs-storageclass" # 关联前面创建的 StorageClass,实现动态 PV
resources:
requests:
storage: 5Gi # 每个 Pod 请求 5Gi 存储(满足 Redis 数据存储需求)
##########
bash
kubectl apply -f statefulset.yml # 应用配置并验证 Redis Pod 是否正常运行(需 6 个 Pod 均处于 Running 状态)
kubectl -n redis-cluster get pods
StatefulSet 关键配置解析:
-
**replicas:6:**Redis 集群需要至少 3 个主节点(才能分配 16384 个槽位,确保数据分片),每个主节点 1 个从节点(主节点故障时,从节点可升级为主节点),因此共 6 个 Pod。
-
**updateStrategy.rollingUpdate.partition:1:**滚动更新时,先更新索引 ≥1 的 Pod(从节点:redis-cluster-1、3、5),再更新索引 = 0 的主节点,避免主节点同时更新导致集群不可用。
-
**podAntiAffinity:**反亲和性配置,确保 Redis Pod 分散在不同 K8s 节点(如 redis-cluster-0 在 node1,redis-cluster-1 在 node2),若某个 K8s 节点宕机,仅影响该节点上的 1-2 个 Pod,其他节点的 Pod 仍可正常工作,提高集群容错性。
-
**--cluster-announce-ip $(POD_IP):**Redis 集群节点需要向其他节点报告自己的 IP,若不配置此参数,节点可能会用容器内部的虚拟 IP(如 127.0.0.1),导致其他节点无法连接。通过 downward API 获取 Pod 的真实 IP(如 10.244.104.40),确保节点间通信正常。
-
**volumeClaimTemplates:**StatefulSet 的核心特性,为每个 Pod 自动创建独立的 PVC,且 PVC 名称与 Pod 名称绑定(如 redis-cluster-data-redis-cluster-0 对应 redis-cluster-0),即使 Pod 重建,PVC 仍存在,数据不会丢失。
3.8.初始化 Redis 集群
分配槽位与主从关系
此时 6 个 Redis Pod 已启动,但尚未组成集群(每个 Pod 都是独立的实例),需执行 redis-cli --cluster create 命令初始化集群,自动分配槽位和主从关系。
bash
[root@master redis]# kubectl exec -it pod/redis-cluster-0 -n redis-cluster -- redis-cli -a openlab --cluster create --cluster-replicas 1 $(kubectl get pod -n redis-cluster -o jsonpath='{range.items[*]}{.status.podIP}:6379 {end}') # 进入任意一个 Redis Pod(如 redis-cluster-0),执行集群初始化命令
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 10.244.104.42:6379 to 10.244.104.40:6379
Adding replica 10.244.166.178:6379 to 10.244.166.176:6379
Adding replica 10.244.166.177:6379 to 10.244.104.41:6379
M: 909686a57ae0c96cd13cfd22975510618f62cfb3 10.244.104.40:6379
slots:[0-5460] (5461 slots) master
M: 41aff067129235c7929415c2d17f199d19d4f3b1 10.244.166.176:6379
slots:[5461-10922] (5462 slots) master
M: 960f133a20493412f84fb6906de1b0655d3ed8ff 10.244.104.41:6379
slots:[10923-16383] (5461 slots) master
S: 6d7df83c82bcc2b5780e2d90378620a35194127a 10.244.166.177:6379
replicates 960f133a20493412f84fb6906de1b0655d3ed8ff
S: e1fe297ae9249758477ce339eb0dabd83a8bf314 10.244.104.42:6379
replicates 909686a57ae0c96cd13cfd22975510618f62cfb3
S: a56a452a028d941fa2eb0c5e120fc77bbdf50f76 10.244.166.178:6379
replicates 41aff067129235c7929415c2d17f199d19d4f3b1
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 10.244.104.40:6379)
M: 909686a57ae0c96cd13cfd22975510618f62cfb3 10.244.104.40:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: e1fe297ae9249758477ce339eb0dabd83a8bf314 10.244.104.42:6379
slots: (0 slots) slave
replicates 909686a57ae0c96cd13cfd22975510618f62cfb3
S: a56a452a028d941fa2eb0c5e120fc77bbdf50f76 10.244.166.178:6379
slots: (0 slots) slave
replicates 41aff067129235c7929415c2d17f199d19d4f3b1
M: 41aff067129235c7929415c2d17f199d19d4f3b1 10.244.166.176:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 960f133a20493412f84fb6906de1b0655d3ed8ff 10.244.104.41:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 6d7df83c82bcc2b5780e2d90378620a35194127a 10.244.166.177:6379
slots: (0 slots) slave
replicates 960f133a20493412f84fb6906de1b0655d3ed8ff
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.命令解析:
-
**kubectl exec -it:**进入 Pod 的交互式终端。
-
**redis-cli -a openlab:**用密码 openlab 连接 Redis(对应 requirepass openlab)。
-
**--cluster create:**创建 Redis 集群。
-
**--cluster-replicas 1:**指定每个主节点有 1 个从节点(6 个 Pod 会分成 3 主 3 从)。
-
**$(kubectl get pod ...):**通过 jsonpath 自动获取所有 Redis Pod 的 IP:6379,避免手动输入(减少错误)。
初始化过程关键输出解析:
-
**槽位分配:**3 个主节点分别负责 16384 个槽位的 1/3:
-
主节点 1:Slots 0 - 5460
-
主节点 2:Slots 5461 - 10922
-
主节点 3:Slots 10923 - 16383
-
(Redis 集群通过槽位分片存储数据,Key 会通过哈希算法映射到某个槽位,再由对应主节点存储)。
-
-
**主从关联:**自动将 3 个从节点分别关联到 3 个主节点(如从节点 10.244.104.42 关联主节点 10.244.104.40)。
-
**最终验证:**输出 OK All 16384 slots covered 表示所有槽位已分配,集群初始化成功。
查看集群状态 ok

四、构建 Redis Cluster Proxy
解决客户端兼容性与外部访问问题
Redis 集群要求客户端支持 MOVED/ASK 重定向协议(如 redis-cli -c),但很多旧客户端(如早期 Java 客户端)或简单应用不支持;同时 K8s 外部客户端无法直接访问 Pod 的动态 IP。Redis Cluster Proxy 作为中间层,可解决这些问题。
4.1.Proxy 核心价值
让集群 "像单机一样易用"
| 问题场景 | 传统方案痛点 | Proxy 解决方案 |
|---|---|---|
| 客户端不支持集群协议 | 连接后报错 MOVED,无法读写数据 |
Proxy 自动处理重定向,客户端像访问单机 Redis 一样操作(无需改代码) |
| K8s 外部客户端访问 | 无法直接访问 Pod 动态 IP,NodePort 暴露后仍需处理重定向 | Proxy 通过 LoadBalancer 暴露,外部客户端只需连接 Proxy IP:Port |
跨槽操作(如 MGET key1 key2) |
报错 CROSSSLOT,需客户端拆分命令 |
Proxy 自动拆分命令到不同节点,合并结果返回(需开启 --enable-cross-slot) |
| 客户端连接数过多 | 每个客户端需连接所有主节点,资源消耗大 | Proxy 维护共享连接池,连接数降低 90%+ |
4.2.编译 Proxy 镜像
适配实验环境
Redis Cluster Proxy 官方镜像可能存在版本兼容问题,因此手动编译并推到私有 Harbor 仓库:
bash
mkdir foo
cd foo/
git config --global user.name 'jjdjr01' # 配置 Git 身份(克隆需身份验证)
git config --global user.email '13303836+jjdjr01@user.noreply.gitee.com'
git clone https://gitee.com/mirrors_RedisLabs/redis-cluster-proxy.git # 国内镜像仓库,拉取更快
bash
# 修复编译错误(部分版本存在 sds.h/sds.c 语法问题,需修改代码适配 GCC 编译)
vim redis-cluster-proxy/src/sds.h # 按实际报错修改(如补充头文件、调整变量定义)
vim redis-cluster-proxy/src/sds.c # 同上
多阶构建:基于基础镜像:centos:stream9
bash
# 打包源码(方便 Docker 构建时复制)
tar czf redis-cluster-proxy.tar.gz redis-cluster-proxy
bash
# 编写多阶段 Dockerfile(减小镜像体积:编译阶段用带工具的镜像,运行阶段用干净镜像)
vim dockerfile
##########
# 第一阶段:编译 Proxy(builder 阶段)
FROM reg.zyz.org/library/centos:stream9 AS builder
ADD redis-cluster-proxy.tar.gz /mnt # 将源码复制到容器内
WORKDIR /mnt/redis-cluster-proxy
# 安装编译依赖(gcc 编译器、make 构建工具、git 版本控制)
RUN yum clean all && yum makecache && \
yum install -y gcc make git && \
make PREFIX=/opt/proxy install # 编译并安装到 /opt/proxy
# 第二阶段:运行 Proxy(干净镜像,仅包含编译结果)
FROM reg.zyz.org/library/centos:stream9
COPY --from=builder /opt/proxy/bin/redis-cluster-proxy /usr/local/bin/ # 复制编译好的二进制文件
EXPOSE 7777 # Proxy 默认端口
# 启动命令:加载 /etc/proxy/proxy.conf 配置文件
ENTRYPOINT ["/usr/local/bin/redis-cluster-proxy", "-c", "/etc/proxy/proxy.conf"]
##########
bash
docker build -t redis-cluster-proxy:v1 . # 构建镜像并推到私有 Harbor 仓库(方便 K8s 拉取)
docker tag redis-cluster-proxy:v1 reg.zyz.org/library/redis-cluster-proxy:v1
docker push reg.zyz.org/library/redis-cluster-proxy:v1多阶段构建优势:
-
编译阶段(builder)包含 GCC、Make 等工具,镜像体积大(约几百 MB),但仅用于编译;
-
运行阶段仅包含 Proxy 二进制文件和基础系统,镜像体积小(约几十 MB),启动更快,占用资源更少。
4.3.部署 Proxy 到 K8s
高可用 + 外部访问
创建 Proxy 配置 ConfigMap
Proxy 需要知道 Redis 集群节点的地址,将配置放入 ConfigMap,方便修改:
bash
vim configmap-redis-cluster-proxy.yml
###########
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-proxy # ConfigMap 名称
namespace: redis-cluster
data:
proxy.conf: | # Proxy 核心配置
# Redis 集群节点地址(用 Headless Service 域名,避免 Pod IP 变化)
cluster redis-cluster-0.headless-redis.redis-cluster.svc.cluster.local:6379
cluster redis-cluster-1.headless-redis.redis-cluster.svc.cluster.local:6379
cluster redis-cluster-2.headless-redis.redis-cluster.svc.cluster.local:6379
cluster redis-cluster-3.headless-redis.redis-cluster.svc.cluster.local:6379
cluster redis-cluster-4.headless-redis.redis-cluster.svc.cluster.local:6379
cluster redis-cluster-5.headless-redis.redis-cluster.svc.cluster.local:6379
bind 0.0.0.0 # 允许所有地址访问 Proxy
port 7777 # Proxy 监听端口
threads 3 # 处理请求的线程数(根据 CPU 核心数调整,提高并发)
daemonize no # 不后台运行(K8s 需前台运行,方便管理进程)
enable-cross-slot yes # 允许跨槽操作(如 MGET 多个不同槽的 Key)
auth openlab # Redis 集群密码(对应 requirepass openlab)
log-level error # 日志级别:仅输出错误日志,减少日志量
###########
bash
kubectl apply -f configmap-redis-cluster-proxy.yml # 应用配置并验证
kubectl -n redis-cluster get configmaps
创建 Proxy Deployment:高可用部署
bash
vim dep-redis-cluster-proxy.yml
##########
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-proxy # Deployment 名称
namespace: redis-cluster
spec:
replicas: 2 # 2 个实例,实现 Proxy 高可用(避免单实例故障导致外部无法访问)
selector:
matchLabels:
app: redis-proxy # 匹配 Pod 标签
template:
metadata:
labels:
app: redis-proxy
spec:
containers:
- name: redis-proxy
image: library/redis-cluster-proxy:v1 # 私有仓库镜像(若 Harbor 有前缀,需补全如 reg.zyz.org/library/...)
imagePullPolicy: IfNotPresent # 本地有镜像则不拉取,加快启动
command: ["/usr/local/bin/redis-cluster-proxy"] # 启动命令(与 Dockerfile ENTRYPOINT 一致,可覆盖)
args:
- -c
- /etc/proxy/proxy.conf # 加载 ConfigMap 中的配置文件
ports:
- name: redis-7777
containerPort: 7777 # Proxy 监听端口
protocol: TCP
volumeMounts:
- name: cluster-proxy-v # 挂载 ConfigMap 到 /etc/proxy
mountPath: /etc/proxy
volumes:
- name: cluster-proxy-v
configMap:
name: cluster-proxy # 引用前面创建的 ConfigMap
items:
- key: proxy.conf
path: proxy.conf # 挂载路径(与 args 中的配置文件路径一致)
##########
bash
kubectl apply -f dep-redis-cluster-proxy.yml # 应用配置并验证 Proxy Pod 是否正常运行
kubectl -n redis-cluster get pods
创建 LoadBalancer Service:暴露 Proxy 供外部访问
K8s 外部客户端(如本地电脑、其他服务器)无法直接访问 Pod IP,需通过 LoadBalancer 类型的 Service 暴露 Proxy(生产环境可用云厂商的 LoadBalancer,实验环境可用 MetalLB 模拟):
bash
vim loadbalancer.yml
###########
apiVersion: v1
kind: Service
metadata:
labels:
app: redis-cluster-proxy
name: cluster-proxy # Service 名称
namespace: redis-cluster
spec:
ports:
- port: 6379 # Service 暴露的端口(与 Redis 默认端口一致,方便客户端使用)
protocol: TCP
targetPort: 7777 # 转发到 Proxy Pod 的 777 端口
selector:
app: redis-proxy # 匹配 Proxy Pod 标签
type: LoadBalancer # 类型为 LoadBalancer,自动分配外部 IP
###########
bash
kubectl apply -f loadbalancer.yml # 应用配置并查看 Service(重点看 EXTERNAL-IP,即外部客户端访问的 IP)
kubectl -n redis-cluster get service
五、测试
验证集群可用性、性能与故障切换
5.1.基础读写测试
验证 Proxy 与集群通信正常
bash
# 方式 1:本地安装 Redis 客户端测试
dnf install redis -y
redis-cli -h 192.168.67.154 -p 6379 -a openlab # 192.168.67.154 是 Proxy Service 的 EXTERNAL-IP
set age 20 # 写数据
get age # 读数据(若返回 20,说明读写正常)
测试目的:验证 Proxy 能正确转发客户端请求到 Redis 集群,且集群能正常读写数据。
5.2.性能测试
用 redis-benchmark 评估吞吐量与延迟
redis-benchmark 是 Redis 自带的性能测试工具,可模拟多客户端并发请求,评估集群性能:
测试 PING 命令(基础连通性与延迟)
关键输出:throughput summary(吞吐量,如 5263.16 requests per second)、latency summary(延迟,如 avg 2.884ms)
bash
root@2d8d4fc5b23a:/data# redis-benchmark -h 192.168.67.154 -p 6379 -n 100 -c 20
WARNING: Could not fetch server CONFIG
====== PING_INLINE ======
100 requests completed in 0.02 seconds
20 parallel clients
3 bytes payload
keep alive: 1
multi-thread: no
Latency by percentile distribution:
0.000% <= 0.735 milliseconds (cumulative count 2)
50.000% <= 1.575 milliseconds (cumulative count 50)
75.000% <= 3.071 milliseconds (cumulative count 75)
87.500% <= 8.039 milliseconds (cumulative count 88)
93.750% <= 9.055 milliseconds (cumulative count 94)
96.875% <= 9.839 milliseconds (cumulative count 97)
98.438% <= 10.055 milliseconds (cumulative count 99)
99.219% <= 10.255 milliseconds (cumulative count 100)
100.000% <= 10.255 milliseconds (cumulative count 100)
Cumulative distribution of latencies:
0.000% <= 0.103 milliseconds (cumulative count 0)
5.000% <= 0.807 milliseconds (cumulative count 5)
12.000% <= 0.903 milliseconds (cumulative count 12)
15.000% <= 1.007 milliseconds (cumulative count 15)
16.000% <= 1.103 milliseconds (cumulative count 16)
21.000% <= 1.207 milliseconds (cumulative count 21)
28.000% <= 1.303 milliseconds (cumulative count 28)
36.000% <= 1.407 milliseconds (cumulative count 36)
45.000% <= 1.503 milliseconds (cumulative count 45)
52.000% <= 1.607 milliseconds (cumulative count 52)
55.000% <= 1.703 milliseconds (cumulative count 55)
59.000% <= 1.807 milliseconds (cumulative count 59)
60.000% <= 1.903 milliseconds (cumulative count 60)
65.000% <= 2.007 milliseconds (cumulative count 65)
66.000% <= 2.103 milliseconds (cumulative count 66)
75.000% <= 3.103 milliseconds (cumulative count 75)
80.000% <= 4.103 milliseconds (cumulative count 80)
83.000% <= 5.103 milliseconds (cumulative count 83)
85.000% <= 6.103 milliseconds (cumulative count 85)
86.000% <= 7.103 milliseconds (cumulative count 86)
88.000% <= 8.103 milliseconds (cumulative count 88)
94.000% <= 9.103 milliseconds (cumulative count 94)
99.000% <= 10.103 milliseconds (cumulative count 99)
100.000% <= 11.103 milliseconds (cumulative count 100)
Summary:
throughput summary: 5263.16 requests per second
latency summary (msec):
avg min p50 p95 p99 max
2.884 0.728 1.575 9.527 10.055 10.255测试 SET 命令(写操作性能)
关键输出:SET 命令吞吐量(如 3703.70 requests per second),延迟略高于 PING(因需写磁盘)
bash
root@2d8d4fc5b23a:/data# redis-benchmark -h 192.168.67.154 -t set -n 1000 -r 100
WARNING: Could not fetch server CONFIG
====== SET ======
1000 requests completed in 0.27 seconds
50 parallel clients
3 bytes payload
keep alive: 1
multi-thread: no
Latency by percentile distribution:
0.000% <= 0.735 milliseconds (cumulative count 1)
50.000% <= 5.615 milliseconds (cumulative count 500)
75.000% <= 9.391 milliseconds (cumulative count 750)
87.500% <= 17.519 milliseconds (cumulative count 875)
93.750% <= 43.903 milliseconds (cumulative count 938)
96.875% <= 68.159 milliseconds (cumulative count 969)
98.438% <= 161.791 milliseconds (cumulative count 985)
99.219% <= 194.303 milliseconds (cumulative count 993)
99.609% <= 228.223 milliseconds (cumulative count 997)
99.805% <= 230.911 milliseconds (cumulative count 999)
99.902% <= 231.039 milliseconds (cumulative count 1000)
100.000% <= 231.039 milliseconds (cumulative count 1000)
Cumulative distribution of latencies:
0.000% <= 0.103 milliseconds (cumulative count 0)
0.300% <= 0.807 milliseconds (cumulative count 3)
0.600% <= 0.903 milliseconds (cumulative count 6)
0.800% <= 1.007 milliseconds (cumulative count 8)
1.400% <= 1.103 milliseconds (cumulative count 14)
2.000% <= 1.207 milliseconds (cumulative count 20)
3.000% <= 1.303 milliseconds (cumulative count 30)
4.000% <= 1.407 milliseconds (cumulative count 40)
5.200% <= 1.503 milliseconds (cumulative count 52)
7.100% <= 1.607 milliseconds (cumulative count 71)
8.400% <= 1.703 milliseconds (cumulative count 84)
9.100% <= 1.807 milliseconds (cumulative count 91)
10.100% <= 1.903 milliseconds (cumulative count 101)
11.100% <= 2.007 milliseconds (cumulative count 111)
12.200% <= 2.103 milliseconds (cumulative count 122)
26.000% <= 3.103 milliseconds (cumulative count 260)
36.900% <= 4.103 milliseconds (cumulative count 369)
45.600% <= 5.103 milliseconds (cumulative count 456)
55.400% <= 6.103 milliseconds (cumulative count 554)
62.700% <= 7.103 milliseconds (cumulative count 627)
69.100% <= 8.103 milliseconds (cumulative count 691)
74.100% <= 9.103 milliseconds (cumulative count 741)
77.000% <= 10.103 milliseconds (cumulative count 770)
79.800% <= 11.103 milliseconds (cumulative count 798)
82.000% <= 12.103 milliseconds (cumulative count 820)
83.900% <= 13.103 milliseconds (cumulative count 839)
85.100% <= 14.103 milliseconds (cumulative count 851)
85.900% <= 15.103 milliseconds (cumulative count 859)
86.600% <= 16.103 milliseconds (cumulative count 866)
87.100% <= 17.103 milliseconds (cumulative count 871)
88.100% <= 18.111 milliseconds (cumulative count 881)
89.300% <= 19.103 milliseconds (cumulative count 893)
89.900% <= 20.111 milliseconds (cumulative count 899)
90.600% <= 21.103 milliseconds (cumulative count 906)
91.000% <= 22.111 milliseconds (cumulative count 910)
91.400% <= 23.103 milliseconds (cumulative count 914)
92.300% <= 24.111 milliseconds (cumulative count 923)
92.600% <= 25.103 milliseconds (cumulative count 926)
92.900% <= 26.111 milliseconds (cumulative count 929)
93.000% <= 27.103 milliseconds (cumulative count 930)
93.200% <= 28.111 milliseconds (cumulative count 932)
93.300% <= 29.103 milliseconds (cumulative count 933)
93.600% <= 30.111 milliseconds (cumulative count 936)
93.700% <= 42.111 milliseconds (cumulative count 937)
93.900% <= 44.127 milliseconds (cumulative count 939)
94.000% <= 45.119 milliseconds (cumulative count 940)
94.200% <= 48.127 milliseconds (cumulative count 942)
94.600% <= 49.119 milliseconds (cumulative count 946)
94.700% <= 50.111 milliseconds (cumulative count 947)
94.900% <= 51.103 milliseconds (cumulative count 949)
95.000% <= 54.111 milliseconds (cumulative count 950)
95.500% <= 55.103 milliseconds (cumulative count 955)
95.700% <= 57.119 milliseconds (cumulative count 957)
95.900% <= 58.111 milliseconds (cumulative count 959)
96.000% <= 60.127 milliseconds (cumulative count 960)
96.400% <= 61.119 milliseconds (cumulative count 964)
96.900% <= 68.159 milliseconds (cumulative count 969)
97.000% <= 75.135 milliseconds (cumulative count 970)
97.100% <= 82.111 milliseconds (cumulative count 971)
97.200% <= 88.127 milliseconds (cumulative count 972)
97.300% <= 89.151 milliseconds (cumulative count 973)
97.400% <= 90.111 milliseconds (cumulative count 974)
97.500% <= 102.143 milliseconds (cumulative count 975)
97.600% <= 103.103 milliseconds (cumulative count 976)
97.700% <= 104.127 milliseconds (cumulative count 977)
97.800% <= 105.151 milliseconds (cumulative count 978)
97.900% <= 127.103 milliseconds (cumulative count 979)
98.000% <= 139.135 milliseconds (cumulative count 980)
98.100% <= 142.207 milliseconds (cumulative count 981)
98.200% <= 144.127 milliseconds (cumulative count 982)
98.300% <= 152.191 milliseconds (cumulative count 983)
98.400% <= 153.215 milliseconds (cumulative count 984)
98.500% <= 162.175 milliseconds (cumulative count 985)
98.600% <= 166.143 milliseconds (cumulative count 986)
98.700% <= 178.175 milliseconds (cumulative count 987)
98.800% <= 179.199 milliseconds (cumulative count 988)
99.000% <= 193.151 milliseconds (cumulative count 990)
99.200% <= 194.175 milliseconds (cumulative count 992)
99.400% <= 195.199 milliseconds (cumulative count 994)
99.500% <= 226.175 milliseconds (cumulative count 995)
99.600% <= 227.199 milliseconds (cumulative count 996)
99.700% <= 228.223 milliseconds (cumulative count 997)
99.800% <= 229.119 milliseconds (cumulative count 998)
100.000% <= 231.167 milliseconds (cumulative count 1000)
Summary:
throughput summary: 3703.70 requests per second
latency summary (msec):
avg min p50 p95 p99 max
12.955 0.728 5.615 53.631 192.767 231.039性能指标解读:
-
吞吐量:单位时间内处理的请求数(越高越好),实验环境中 3000-5000 req/s 属于正常范围(生产环境可通过增加 Redis 节点、优化资源配置进一步提升)。
-
延迟:处理单个请求的时间(越低越好),实验环境中 avg < 20ms 属于正常范围,若延迟过高,需检查 NFS 存储性能、K8s 节点资源是否充足。
5.3.故障切换测试:验证集群高可用
Redis 集群的核心优势是 "主节点故障后,从节点自动升级为主节点,保证服务不中断",需验证此功能:
查看初始集群状态
bash
kubectl exec -it pod/redis-cluster-0 -n redis-cluster -- redis-cli -a openlab --cluster check $(kubectl get pod -l app.kubernetes.io/name=redis-cluster -n redis-cluster -o jsonpath='{.items[0].status.podIP}:6379') # 记录主节点 IP 与对应的从节点(如主节点 10.244.104.40,从节点 10.244.104.42)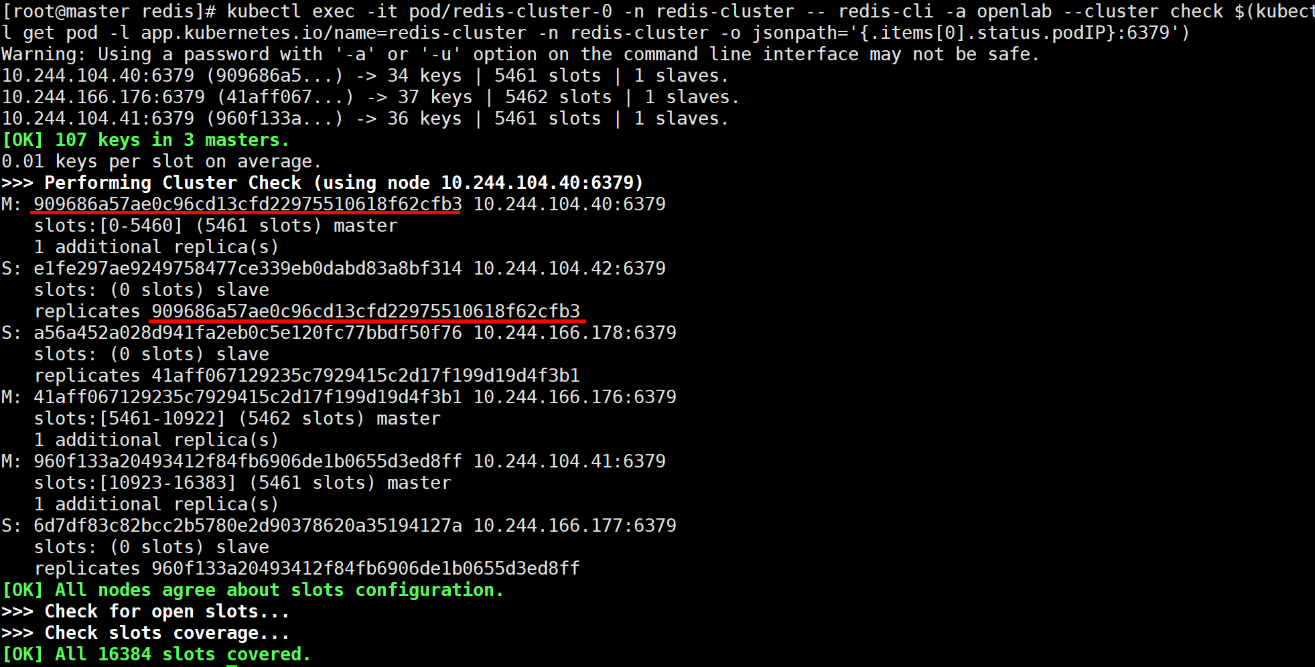
删除从节点 Pod,验证自动重建
bash
kubectl -n redis-cluster get pods -o wide
bash
# 删除一个从节点(如 redis-cluster-4)
kubectl -n redis-cluster delete pods redis-cluster-4
# 查看 Pod 状态:StatefulSet 会自动重建 redis-cluster-4(约 10-20 秒)
kubectl -n redis-cluster get pods -o wide
bash
# 再次检查集群状态:新重建的 redis-cluster-4 会自动加入集群,成为原主节点的从节点
kubectl exec -it pod/redis-cluster-0 -n redis-cluster -- redis-cli -a openlab --cluster check $(kubectl get pod -l app.kubernetes.io/name=redis-cluster -n redis-cluster -o jsonpath='{.items[0].status.podIP}:6379')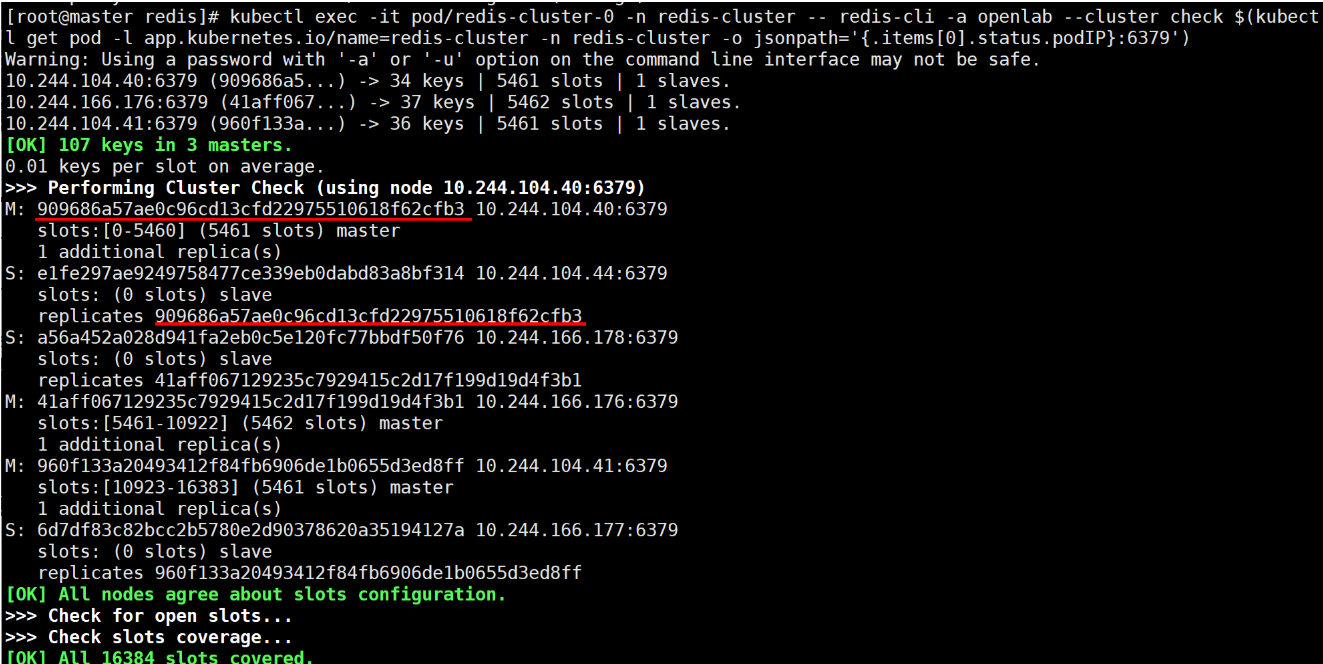
删除主节点 Pod,验证故障切换
bash
kubectl -n redis-cluster get pods -o wide
bash
# 删除一个主节点(如 redis-cluster-0,对应主节点 10.244.104.40)
kubectl -n redis-cluster delete pods redis-cluster-0
# 查看 Pod 状态:redis-cluster-0 会自动重建,同时原从节点(如 10.244.104.42)会升级为主节点
kubectl -n redis-cluster get pods -o wide
bash
# 检查集群状态:
# 1. 原从节点已升级为主节点,接管原主节点的槽位(0-5460);
# 2. 重建后的 redis-cluster-0 成为新主节点的从节点;
# 3. 所有 16384 个槽位仍覆盖完整,集群正常提供服务。
kubectl exec -it pod/redis-cluster-1 -n redis-cluster -- redis-cli -a openlab --cluster check $(kubectl get pod -l app.kubernetes.io/name=redis-cluster -n redis-cluster -o jsonpath='{.items[1].status.podIP}:6379')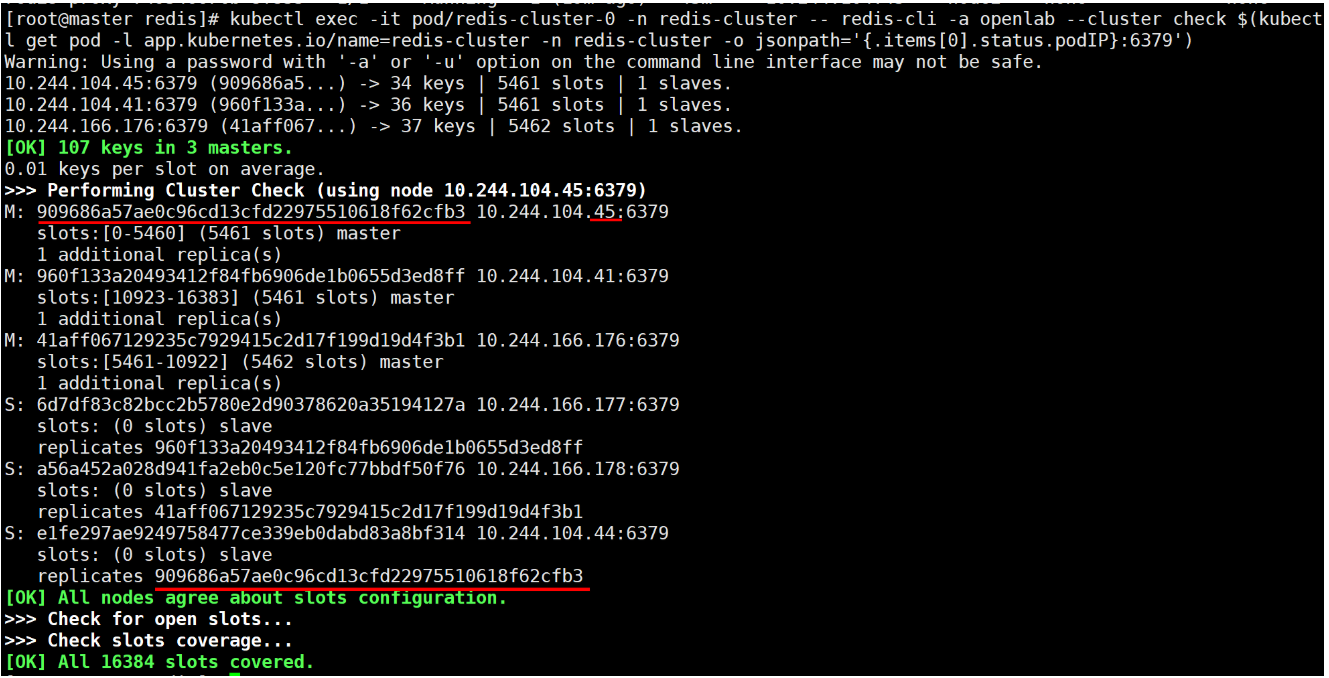
故障切换核心逻辑:
-
主节点故障(如 Pod 被删除),集群内其他节点检测到该节点超时(cluster-node-timeout 5000);
-
该主节点的从节点发起选举,投票成为新主节点;
-
新主节点接管原主节点的所有槽位,继续提供服务;
-
StatefulSet 重建原主节点 Pod,新 Pod 启动后自动成为新主节点的从节点,恢复 3 主 3 从架构。
六、Redis 集群图形化管理工具 RedisInsight
命令行管理 Redis 集群效率低,RedisInsight 是 Redis 官方推出的图形化工具,支持查看集群状态、数据、执行命令、分析性能,大幅降低运维成本。
6.1.部署 RedisInsight 到 K8s
bash
# 拉取镜像并推到私有 Harbor(避免外部仓库依赖)
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/redislabs/redisinsight:2.56
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/redislabs/redisinsight:2.56 reg.zyz.org/redislabs/redisinsight:2.56
docker push reg.zyz.org/redislabs/redisinsight:2.56 编写部署文件(Deployment + Service)
bash
vim dep-RedisInsight.yml
############
# Deployment:部署 RedisInsight
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: redisinsight
name: redisinsight
namespace: redis-cluster
spec:
replicas: 1 # 图形化工具无需多实例(数据存储在本地,多实例会导致配置不同步)
selector:
matchLabels:
app.kubernetes.io/name: redisinsight
template:
metadata:
labels:
app.kubernetes.io/name: redisinsight
spec:
containers:
- image: redislabs/redisinsight:2.56 # 私有仓库镜像(需补全前缀)
name: redisinsight
ports:
- name: redisinsight
containerPort: 5540 # RedisInsight 默认端口
protocol: TCP
resources:
limits: # 资源上限
cpu: "2"
memory: 2Gi
requests: # 资源请求
cpu: 100m
memory: 500Mi
---
# Service:暴露 RedisInsight 供外部访问(LoadBalancer 类型)
apiVersion: v1
kind: Service
metadata:
name: redisinsight-svc
namespace: redis-cluster
labels:
app.kubernetes.io/name: redisinsight
spec:
type: LoadBalancer
ports:
- name: redisinsight
protocol: TCP
port: 8080 # 暴露 8080 端口(方便浏览器访问,无需记 5540)
targetPort: 5540 # 转发到 Pod 的 5540 端口
selector:
app.kubernetes.io/name: redisinsight
############
bash
# 应用配置并验证
kubectl apply -f dep-RedisInsight.yml
kubectl -n redis-cluster get pods
kubectl -n redis-cluster get service # 查看 EXTERNAL-IP(如 192.168.67.155)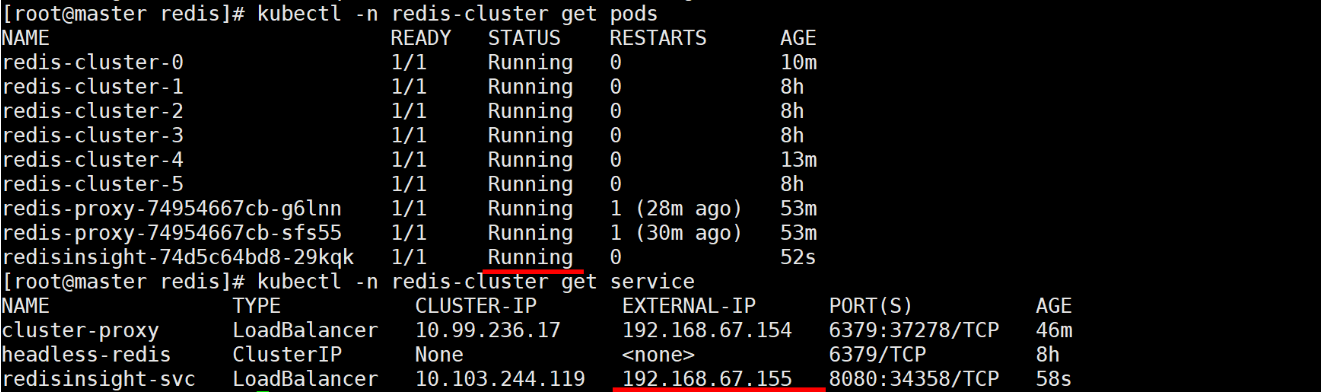
6.2.访问与使用 RedisInsight
- 访问界面 :打开浏览器,输入 http://<EXTERNAL-IP>:8080(如 http://192.168.67.155:8080),按提示完成初始化(设置密码)。
-
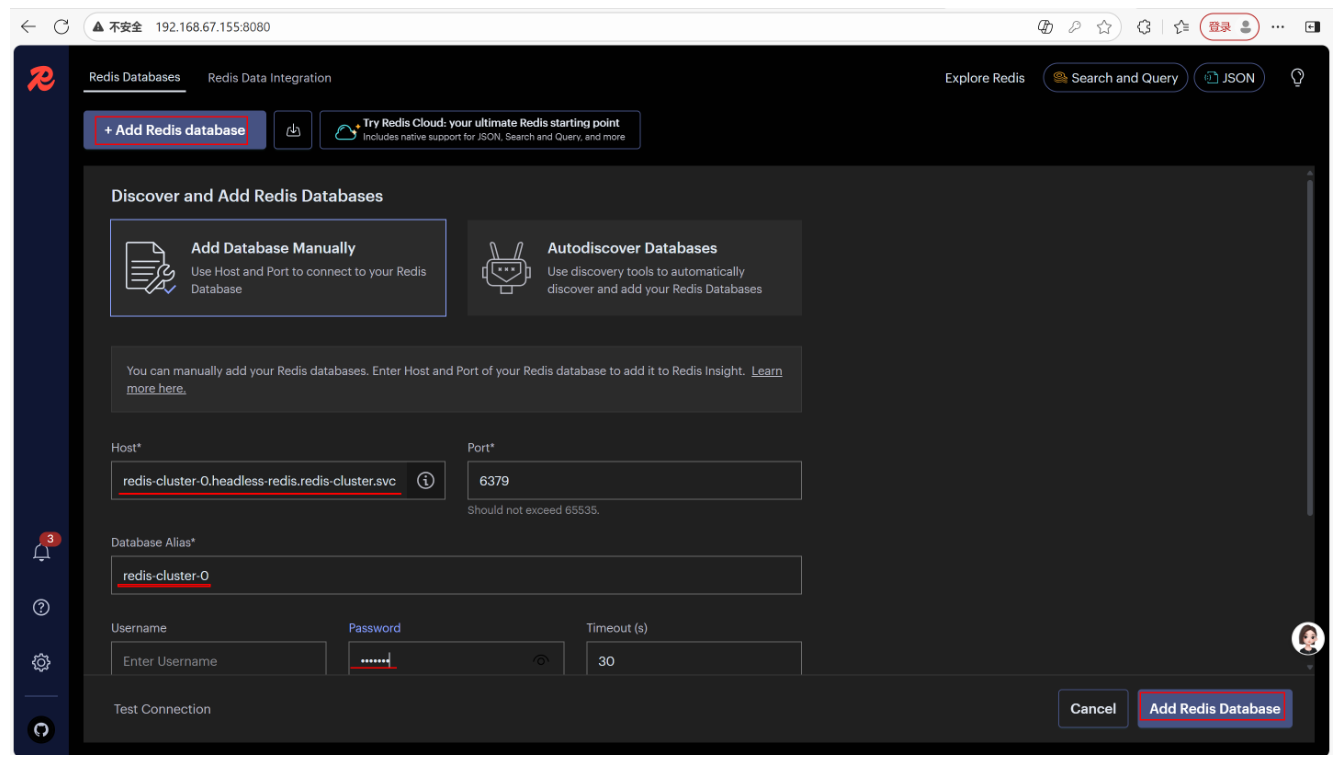
添加 Redis 集群:
-
点击 "Add Redis Database",选择 "Redis Cluster"。
-
输入任意一个 Redis 节点的地址(如 redis-cluster-0.headless-redis.redis-cluster.svc.cluster.local:6379),密码 openlab。
-
点击 "Add",RedisInsight 会自动发现所有集群节点。
-
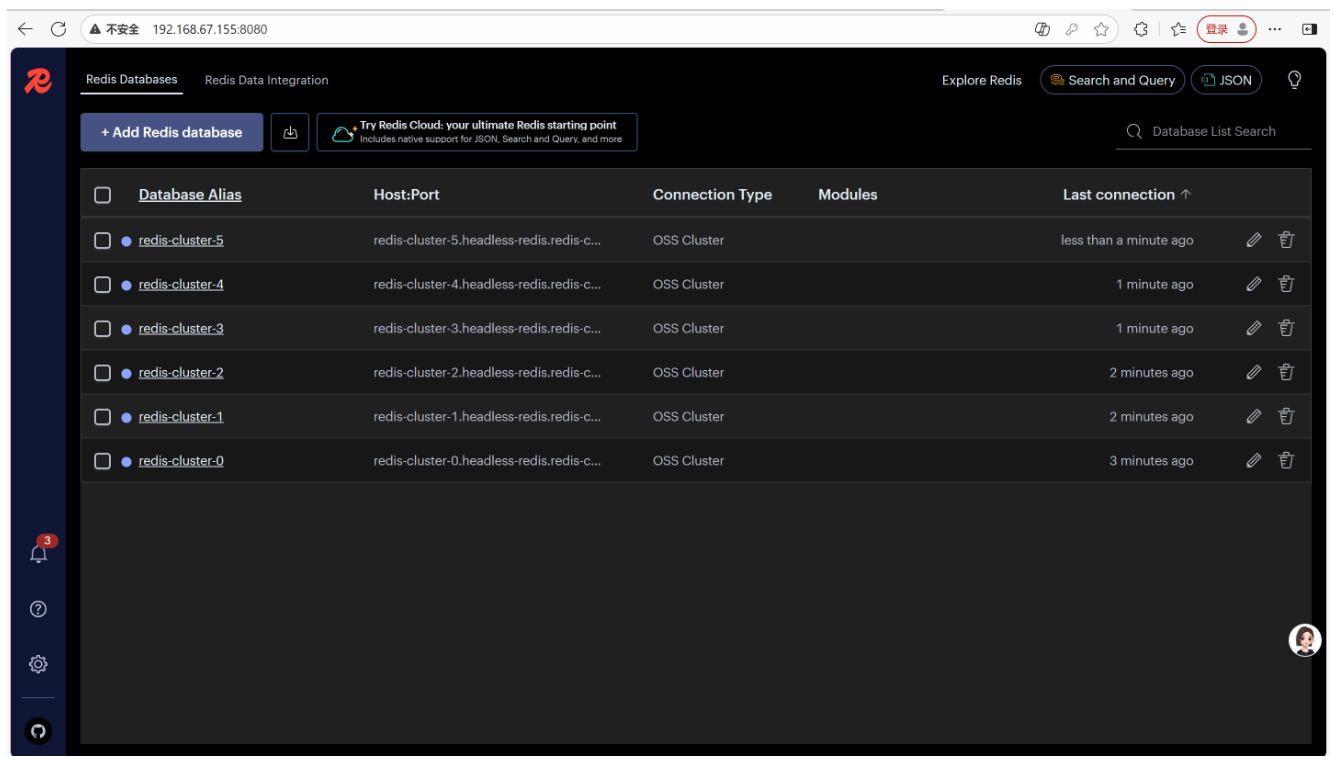
然后直接点击我们的数据库名称,就可以查看里面所有的数据,右上角可以添加数据
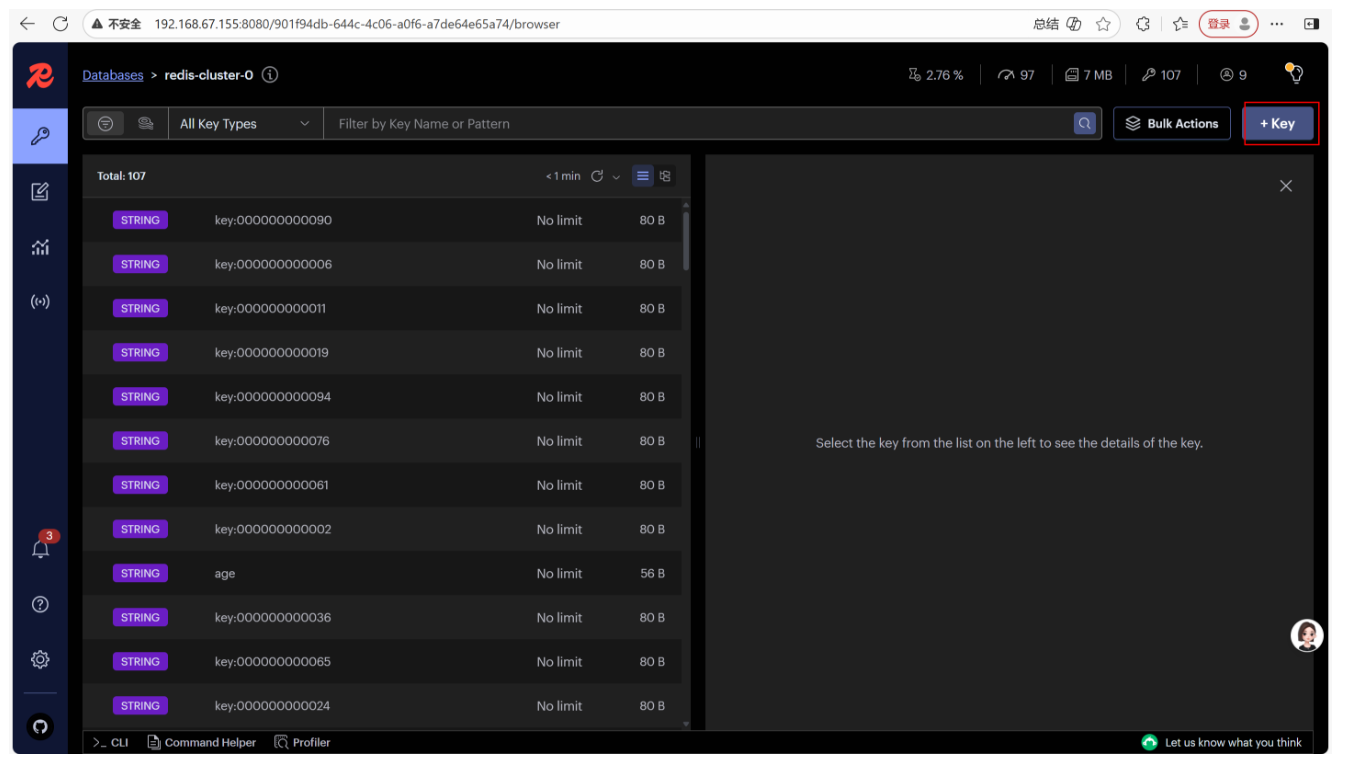
核心功能使用:
-
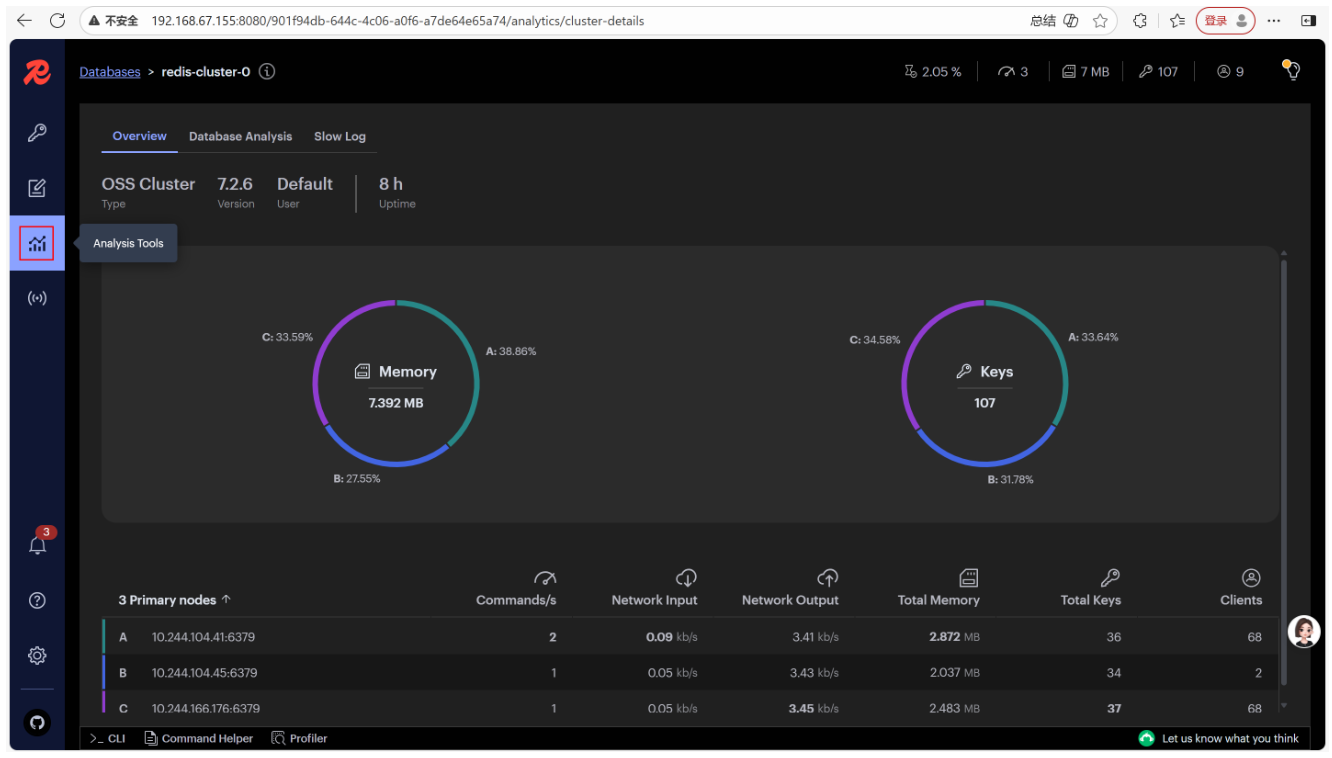
Cluster View:查看集群拓扑(主从关系、槽位分布)。
-
Browser:可视化查看 / 编辑 Key-Value 数据。
-
Workbench:执行 Redis 命令(如 cluster info、set key value)。
-
Analysis Tools:分析集群性能(如内存使用、命令执行频率)。
七、总结
实验核心成果与生产环境优化建议
7.1.实验核心成果
-
构建了 3 主 3 从 Redis 集群,实现数据分片与高可用(主节点故障后从节点自动切换)。
-
实现 动态存储供应(NFS Provisioner + StorageClass),用户无需手动创建 PV,降低运维成本。
-
部署 Redis Cluster Proxy,解决客户端兼容性问题,K8s 外部客户端可无感知访问集群。
-
提供 图形化管理工具(RedisInsight),简化集群监控与运维。
7.2.生产环境优化建议
-
存储优化:实验用 NFS,生产环境建议用性能更好的分布式存储(如 Ceph、GlusterFS),避免 NFS 成为性能瓶颈。
-
安全优化:
-
关闭 no_root_squash,改用 root_squash 并为 Redis 配置专用用户,降低权限风险。
-
为 Redis 密码、Proxy 配置等敏感信息使用 Secret(而非 ConfigMap),避免明文存储。
-
-
性能优化:
-
调整 Redis 配置(如 maxmemory-policy、hash-max-ziplist-entries),优化内存使用。
-
增加 Proxy 实例数(replicas:3),并配置 HPA(Horizontal Pod Autoscaler),根据请求量自动扩缩容。
-
-
监控告警:集成 Prometheus + Grafana 监控 Redis 集群(如槽位覆盖率、主从同步延迟、内存使用率),设置告警(如主节点故障、内存使用率超 90%)。