本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第八篇,MaxCompute Streaming Insert: 大数据数据流写业务迁移的实践与突破。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
随着大数据技术的发展,越来越多企业开始从传统数仓架构向实时处理架构转型。GoTerra公司作为一家快速发展的互联网平台,在其数据体系建设中,早期选择了 Google BigQuery 作为核心的数据存储和计算平台。在迁移 MaxCompute 的过程中,如何对迁移 GoTerra 在 Bigquery 的实时写入业务成为了整个迁移项目的关键需求。在这一过程中,MaxCompute Streaming Insert作为MaxCompute提供的流式数据写入解决方案,成为承接该需求的关键组件。本文将详细探讨MaxCompute Streaming Insert的整体架构设计、性能优势、在GoTerra迁移过程中的挑战与优化策略,并总结其带来的业务价值。
一、MaxCompute Streaming Insert整体架构概述
MaxCompute Streaming Insert 是一种面向大规模实时数据写入场景的解决方案,支持高吞吐、低延迟的数据接入能力。其架构设计充分考虑了稳定性、扩展性和易用性,适用于包括日志采集、行为埋点、IoT 数据上传等在内的多种实时数据源。 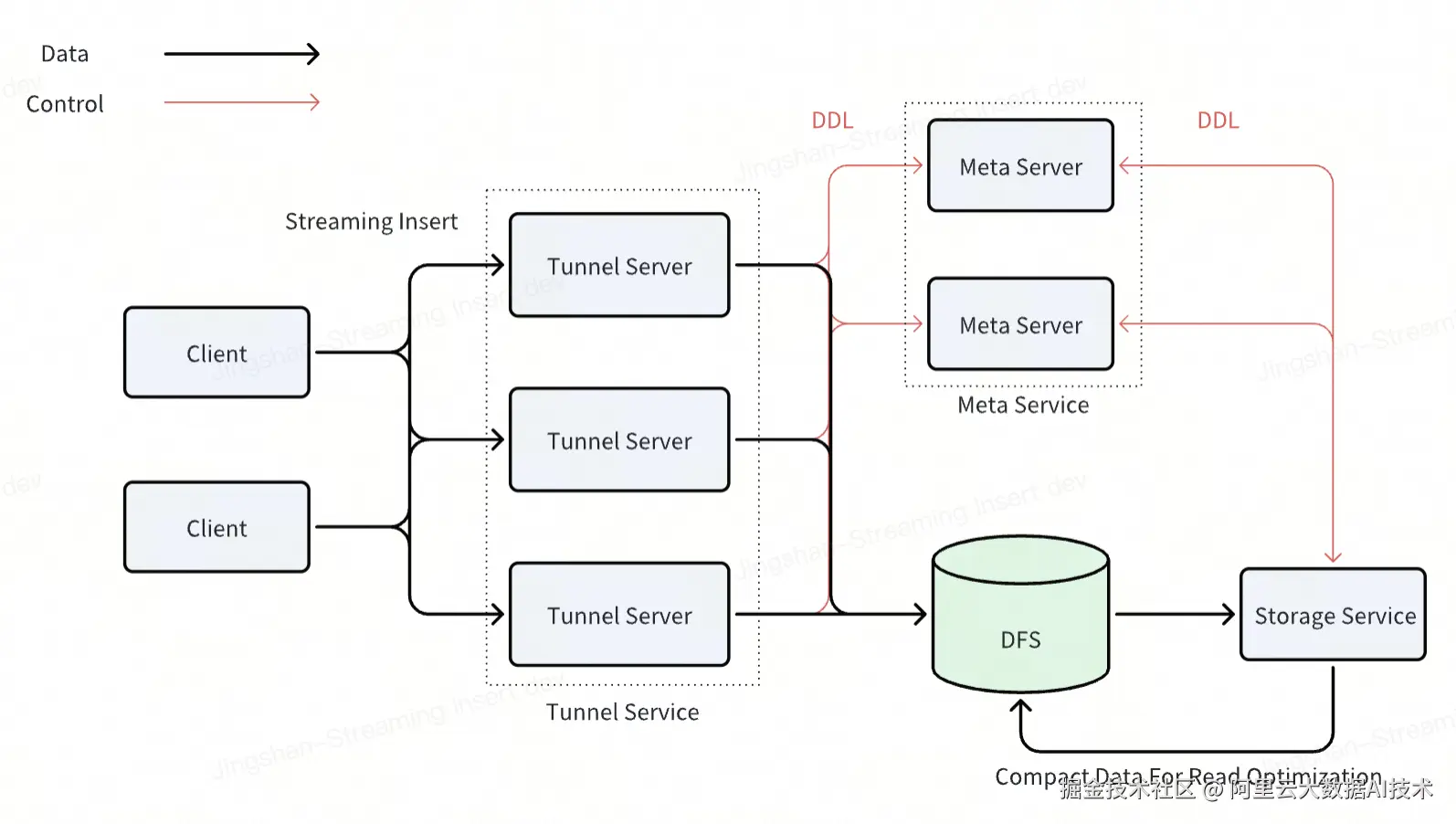
核心特性:
-
流写数据实时可见
在传统的批量导入方式中,用户需要等待数据完成分区或文件级别的提交后才能查询到新写入的数据。而MaxCompute Streaming Insert通过实时写入机制,使得新插入的数据可以立即被下游任务读取,大大提升了数据的时效性。
-
流写性能支持通过客户端并发水平扩展
MaxCompute Streaming Insert采用分布式客户端写入模型,能够根据数据流量自动调整客户端并发度,从而实现写入性能的弹性扩展。无论是在突发流量还是持续高负载情况下,都能保持稳定的写入性能。
-
避免碎片请求引发的存储碎片问题
流式写入通常会产生大量小文件或碎片数据,进而影响后续的查询效率。MaxCompute Streaming Insert通过写入行存文件格式,从源头避免了碎片文件的产生,降低了存储系统的整体压力。
-
后台Compact保障数据读取性能
MaxCompute内置的Storage Service服务会定期对表做Compaction操作,进一步减少存储层压力并提升了查询性能。这种机制尤其适用于流式写入的数据,确保流写数据在长期运行下的高效可维护性。
二、GoTerra迁移过程中遇到的挑战与MaxCompute的优化措施
尽管MaxCompute Streaming Insert具备强大的流写能力,但在实际迁移GoTerra业务的过程中,仍然面临一些复杂的挑战。这些挑战主要集中在嵌套类型支持、Schema Evolution感知机制以及系统稳定性和性能等方面。
1. 多层嵌套类型支持的挑战与优化
GoTerra在其BigQuery系统中广泛使用了嵌套数据类型(如ARRAY、RECORD等),以满足复杂业务对象的建模需求。然而,当尝试将这些数据迁移到MaxCompute时,发现写链路在处理深层嵌套结构时存在严重的性能瓶颈。
原因分析:
-
MaxCompute早期版本对嵌套类型的解析和序列化效率较低;
-
客户端SDK在处理复杂结构时存在性能瓶颈;
MaxCompute的优化方案:
-
存储团队对嵌套类型处理逻辑进行了重构和优化;
-
SDK团队针对复杂类型的API增加了性能优化的接口;
最终,经过多轮迭代优化,MaxCompute不仅解决了性能瓶颈,还实现了对50层嵌套的支持,远超BigQuery原生支持的15层嵌套限制。这为GoTerra迁移提供了坚实的技术保障。
2. Schema Evolution自动感知机制的构建
在实际业务运行中,Schema变更(如新增字段、修改字段类型等)是常态。GoTerra在迁移初期提出了一个关键诉求:希望MaxCompute Streaming Insert能够在写链路中自动感知Schema的变化,并动态更新客户端配置,避免手动干预和停机维护。
实现思路:
-
数据通道服务增加对Schema变更事件的监听与广播能力;
-
SDK内部集成Schema变化通知回调接口;
-
SDK通过数据请求的返回值,实时获取Schema状态;
-
存储层支持Schema兼容性校验,确保变更不会破坏已有数据结构。
成果体现:
通过上述机制的构建,MaxCompute Streaming Insert成功实现了Schema变更的自动感知与客户端热更新能力。GoTerra所有ODS层的实时写入任务均基于此能力实现无缝升级,极大降低了运维成本和故障风险。
3. 稳定性与性能的持续打磨
在迁移初期,MaxCompute Streaming Insert在写入Append Table 2.0时暴露出若干稳定性问题,包括写入失败率偏高、延迟波动较大等。这些问题直接影响了GoTerra对平台的信任度。
主要问题点:
-
高并发分区写入场景下出现部分请求失败;
-
存储层IO抖动或元数据服务请求延迟导致数据积压;
-
负载均衡策略不合理导致集群里产生热点机器
MaxCompute应对策略:
-
增强客户端重试机制,引入指数退避策略和断点续传功能;
-
对写入通道进行QoS分级管理,优先保障核心业务数据;
-
优化后台Compaction调度逻辑,按时间窗口+数据量双维度触发合并;
-
提供丰富的监控指标和告警机制,帮助用户实时掌握写入状态。
通过一系列改进措施,MaxCompute Streaming Insert在GoTerra的实际部署环境中逐步稳定下来,最终在两个关键指标上表现与BigQuery对齐:
-
分钟级请求成功率:超过99.9%;
-
数据投递延迟:P99请求延迟控制在1秒以内,满足实时业务需求。
三、业务价值与未来展望
MaxCompute Streaming Insert在GoTerra的ODS层数据迁移项目中发挥了至关重要的作用。它不仅成功替代了原有的BigQuery流写方案,还在多个核心维度上实现了超越。
核心业务价值体现如下:
-
统一写入入口,简化架构复杂度
GoTerra所有ODS层采集任务均通过MaxCompute Streaming Insert进行写入,形成了统一的数据接入规范,便于集中管理和运维。
-
高性能、高可用保障业务连续性
MaxCompute Streaming Insert的高吞吐能力和稳定性,支撑了GoTerra每天近60TB数据的实时写入需求,保障了核心业务的连续性和可靠性。
-
自动化Schema演化机制降低运维成本
自动感知Schema变化的能力,使GoTerra无需频繁介入Schema更新流程,显著降低了人工维护成本。
展望未来:
MaxCompute Streaming Insert在未来还将继续演进,计划在以下方向进一步拓展能力:
-
提供Exactly-Once语义保障;
-
动态分区写入支持,减少客户端开发复杂度;
结语
MaxCompute Streaming Insert凭借其先进的架构设计、强大的性能表现和灵活的扩展能力,在GoTerra的大数据业务迁移项目中展现出卓越的价值。它不仅帮助GoTerra顺利完成了从BigQuery到MaxCompute的技术平滑过渡,更为其未来的数据架构升级奠定了坚实基础。未来,随着MaxCompute生态的不断完善和技术能力的持续提升,相信其在流式数据处理领域的影响力将进一步扩大,成为更多企业实现实时数据湖仓一体化的核心基础设施。