自己的原文哦~https://blog.51cto.com/whaosoft/11793894
#DRAMA
首个基于Mamba的端到端运动规划器
运动规划是一项具有挑战性的任务,在高度动态和复杂的环境中生成安全可行的轨迹,形成自动驾驶汽车的核心能力。在本文中,我们提出了DRAMA,这是第一个基于Mamba的自动驾驶端到端运动规划器。DRAMA融合了相机、特征空间中的LiDAR鸟瞰图图像以及自我状态信息,以生成一系列未来的自我轨迹。与传统的基于变换器的方法不同,DRAMA能够实现计算强度较低的注意力复杂度,从而显示出处理日益复杂的场景的潜力。DRAMA利用我们的Mamba融合模块,高效地融合了相机和激光雷达的功能。此外,我们引入了一个Mamba Transformer解码器,可以提高整体规划性能。该模块普遍适用于任何基于Transformer的模型,特别是对于具有长序列输入的任务。我们还引入了一种新的特征状态丢弃,在不增加训练和推理时间的情况下提高了规划器的鲁棒性。大量的实验结果表明,与基线Transfuser相比,DRAMA在NAVSIM数据集上实现了更高的精度,参数少,计算成本低。
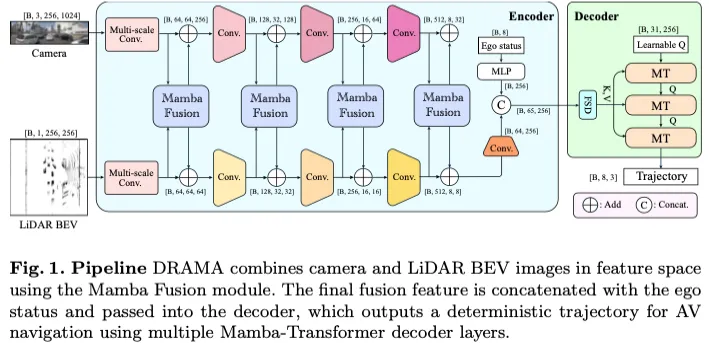
总结来说,本文的主要贡献如下:
- 我们介绍了一种名为DRAMA的Mamba嵌入式编码器-解码器架构,其中包括一个编码器,该编码器通过Mamba Fusion模块有效地融合了相机和LiDAR BEV图像的特征,解码器通过Mamba Transformer解码器生成确定性轨迹,该解码器普遍适用于任何基于Transformer的模型。
- 我们在DRAMA中引入了多尺度卷积和特征状态丢弃模块,并采用了差异化的丢弃策略。这些模块通过在多个尺度上提取场景信息并减轻噪声传感器输入和缺失自我状态的影响,提高了模型的有效性和鲁棒性。
- 使用NAVSIM规划基准对提出的模块和总体架构进行了评估。实验结果表明,与基线相比,我们的模型在使用较少的模型参数和较低的训练成本的情况下实现了显著的性能提升。
相关工作回顾Motion Planning for Autonomous Driving
自动驾驶的运动规划一直是机器人领域的一个长期研究课题。从传统的角度来看,运动规划是行为规划或决策的下游任务,它负责生成可驾驶和舒适的轨迹,保证安全。传统的运动规划通常依赖于几何和优化,可大致分为基于图、基于采样和基于优化的方法。基于图的方法,如A*和Hybrid A*,在离散化车辆配置空间后搜索最小成本路径。基于采样的方法在状态或动作空间内创建轨迹样本,以发现可行的路径。相比之下,基于优化的方法采用EM算法和凸优化等技术来确定满足指定约束的最佳轨迹。这些方法通常涉及大量的手动设计和优化,并且通常在动态或变化的环境中具有通用性。
随着专门用于运动规划的公共驾驶数据集和基准的发布,基于学习的轨迹规划得到了显著加速。目前,nuPlan是运动规划中最大的带注释规划数据集和基准。基于nuPlan和OpenScene数据集,最近开发了一个名为NAVSIM的数据集,以解决开环和闭环评估指标之间的不一致问题,并作为这些评估范式之间的中间地带。
基于这些开源数据集,7分析了数据驱动的运动规划方法中的误解,并提出了一种简单而高效的规划器,该规划器在nuPlan排行榜上排名第一。然而该规划器针对nuPlan指标进行了高度优化,当转移到其他场景时,其性能会下降。这些现有的基于学习的方法往往过度强调度量性能,往往以牺牲计算效率为代价。由于复杂的架构设计或用于轨迹评分和细化的在线模拟,其中许多方法由于无法实现的计算负担而变得枯燥乏味。为了提高计算强度和性能,我们提出了DRAMA,这是一种Mamba嵌入式编解码器流水线,旨在实现高效和卓越的规划性能。
State Space Models
为了减轻状态空间模型(SSM)在建模长期依赖关系时的大量计算和内存需求,10提出了结构化状态空间序列模型(S4),该模型将SSM中的A矩阵修改为具有低秩校正的条件矩阵。这种增强的模型Mamba在图像处理、语言处理和其他领域显示出巨大的应用潜力。6 从理论上证明了SSM与半可分矩阵的等价性。此外,引入了状态空间二元性(SSD)来增强原始的Mamba,该设计将多头注意力(MHA)融入SSM以优化框架,从而使改进版本(Mamba-2)表现出更大的稳定性和更高的性能。受到Mamba家族先前成功的启发,我们将最新的架构Mamba-2应用于端到端的运动规划。据我们所知,这是Mamba-2在自动驾驶领域的首次应用。为清楚和简洁起见,除非另有说明,否则所有后续提及曼巴的内容均适用于Mamba-2。
DRAMA方法详解
我们介绍了基于Mamba的端到端运动规划框架DRAMA,该框架使用卷积神经网络(CNN)和Mamba对相机和LiDAR BEV图像的特征进行编码和融合。解码器采用我们提出的Mamba Transformer解码器层对最终轨迹进行解码。在接下来的部分中,我们将详细探讨我们设计的四个模块:Mamba融合块、Mamba Transformer解码器层、多尺度卷积和特征状态dropout。
Mamba Fusion Block and Mamba-Transformer
Mamba Preliminaries:从连续系统导出的结构化状态空间序列模型(S4)利用1-D输入序列或函数x(t)和中间隐藏状态h(t)来产生最终输出y(t)。中间隐藏状态h(t)和输入x(t)用于通过投影矩阵A、B和C计算y(t)。
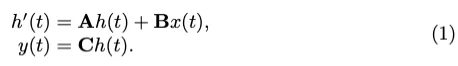
该系统应用可学习步长和零阶保持将连续系统转换为离散系统。因此,方程式(1)可以重新表述如下:

通过数学归纳,方程式(2)的最终输出可以改写如下:
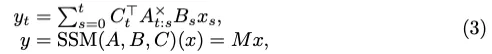
矩阵M定义如下:
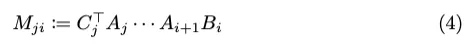
如方程(4)所述,下三角SSM变换矩阵M也满足N-顺序半可分(SSS)表示的定义。因此,SSM和SSS表示是等效的。
因此,SSS的结构化矩阵乘法可以有效地用于涉及SSM的计算。为了实现这种方法,分别使用结构化掩蔽注意力(SMA)方形模式算法和SMA线性模式算法将参数矩阵M分解为对角块和低秩块。此外,采用多头注意力(MHA)来提高模型性能。
曼巴融合:为了捕捉不同模态的多尺度背景,之前的基线在Transformer中实现了自我关注层,以融合和利用激光雷达和相机的特征。首先,对两种模态的特征进行转换和连接,生成组合特征I。然后,I将三个不同的投影矩阵、和相乘,得到Q、K和V。融合模块的最终输出可以通过以下方式计算:
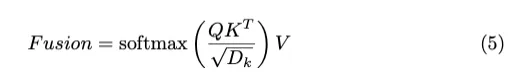
计算复杂度的总体训练由以下公式给出:
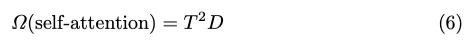
我们建议使用Mamba作为特征融合的自我关注的替代方案,因为它具有高效的矩阵计算能力。我们坚持实施融合方法,如图2所示。与4不同,我们使用Mamba-2而不是Transformer来处理融合的特征。由于传统变压器自关注中没有复杂的计算,Mamba的计算成本大大降低。假设head维度P等于状态维度D,即P=D,则训练成本由下式给出:

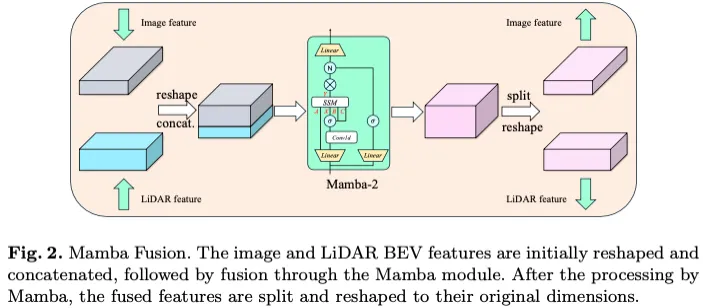
在我们的曼巴融合模块中,我们设置了T E320和P E16,理论上与自我关注相比,在融合过程中训练成本降低了约20倍。
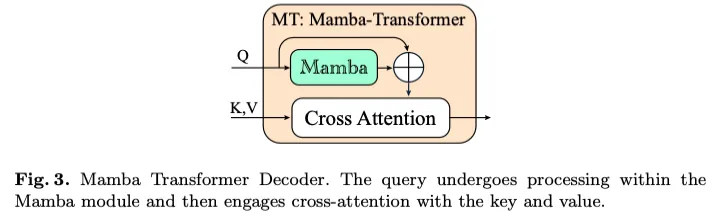
Mamba Transformer解码器:如图(3)所示,我们将Mamba和Transformer架构相结合,开发了新颖的Mamba Transformers(MT)解码器。最初,可学习的查询被传递到机器翻译的Mamba组件中,该组件的功能类似于self-att。由于与Mamba的交叉注意力仍在探索中,我们采用Transformer交叉注意力机制来处理来自Mamba的查询以及来自FSD模块的键和值。
Multi-scale Convolution
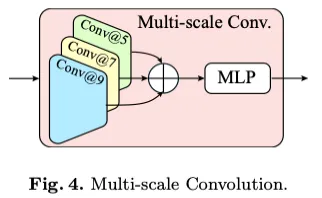
为了捕获多尺度图像特征,我们采用了多卷积设计,如图(4)所示,其中图像通过三个不同核大小的卷积层进行处理,分别为-5、7和9。这些卷积层的输出被组合在一起,并由多层感知器(MLP)层进一步编码,以增强模型的感知能力。
Feature State Dropout
由于硬件限制和机载传感器中的噪声,对周围环境的观察和感知(例如位置或速度)可能不准确,可能无法完全反映真实情况。此外,当导航模块的驾驶命令缺失时,或者在复杂的交通条件下导航时,即使在没有明确指导的情况下,模型也必须深入理解和推理场景和周围的代理,这一点至关重要。先前的研究表明,屏蔽某些图像和车辆状态特征可以提高自我监督任务和运动规划的整体性能。为了解决这些问题并基于这些见解,我们从两种模态和自我状态实现了图像特征融合的特征状态丢弃,如图5所示。最初,要编码的特征被添加了一个可学习的位置嵌入,然后是差异化的dropout来掩盖一些特征。
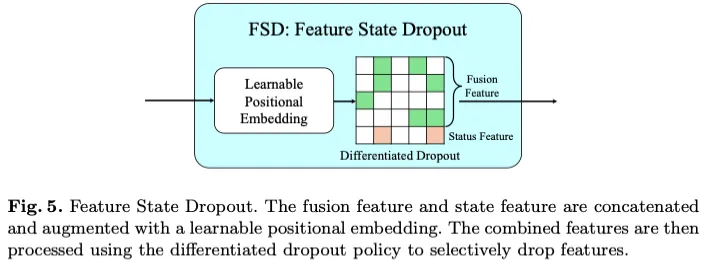
我们在DRAMA中采用了一种差异化的辍学策略,该策略对融合和自我状态特征应用了不同的辍学率。为融合特征分配相对较低的丢失率,以保持其完整性。该措施旨在避免融合感知信息的过度丢失,从而降低整体性能。
实验结果
定量结果
如表1所示,根据Transfuser(T)基线对拟议模块的评估显示,各种指标都有显著改善。整合多尺度卷积(MSC)可以提高PDM得分,从0.835增加到0.843,突出了其在捕获多尺度特征以提高整体模型性能方面的有效性。曼巴融合(MF)的加入进一步将PDM评分提高到0.848,自我进步(EP)从0.782显著提高到0.798,表明融合方式优越。特征状态丢失(FSD)显示了EP的最高单个模块增强,达到0.802,PDM得分为0.848,证明了其在减轻传感器输入不良方面的作用。此外,Mamba Transformer(MT)模块的PDM得分为0.844,碰撞时间(TTC)有了显著改善,突显了其强大的自我关注机制。在没有MSC的DRAMA中,这些模块的组合,即T+MF+FSD+MT,导致PDM得分为0.853,在所有指标上都有持续的改进,整个DRAMA模型达到了最高的PDM得分0.855,证实了综合方法的有效性。
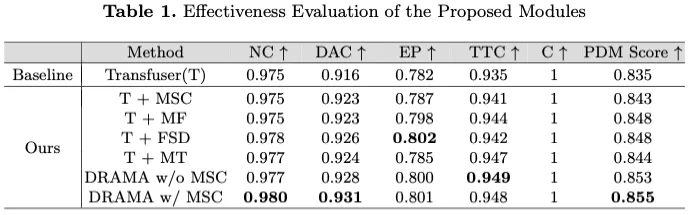
表2显示了不同特征状态丢失率对模型性能的影响,表明改变状态和融合特征的丢失率可以提高模型的鲁棒性和准确性。基线Transfuser(T)得分为0.835。引入融合丢失率为0.1的FSD将得分提高到0.842,状态丢失率为0.5的FSD得分更高,为0.844,这表明该模型受益于处理缺失的状态特征。状态丢失率为0.5和融合丢失率为0.1的组合达到了最高得分0.848,表明这两种特征类型之间的平衡丢失率优化了模型性能。

表3全面比较了各种方法的培训和验证性能,强调了拟议模块的效率。基线Transfuser(T)的总参数大小为56 MB,训练和验证速度分别为每秒4.61次迭代(it/s)和9.73次迭代/秒。引入多尺度卷积(MSC)模块将训练速度略微降低到3.77it/s,同时保持类似的验证速度,这表明在增强的特征提取和计算成本之间进行了权衡。相反,Mamba Fusion(MF)模块将总参数大小显著减小到49.9 MB,并将训练速度提高到4.92 it/s,验证速度提高到9.94 it/s,展示了其在模态融合方面的卓越效率。
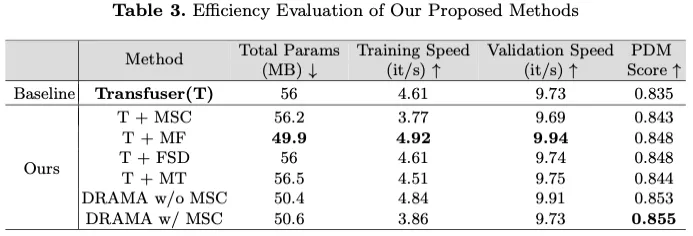
特征状态dropout(FSD)的集成保持了与基线相当的速度,在不增加计算开销的情况下证明了其效率。这一发现突显了FSD模块的通用性和轻质性,可以有效地将其整合到各种型号中以提高其性能。
Mamba Transformer(MT)模块在性能和速度方面实现了平衡的提高,尽管它将训练速度略微降低到4.51it/s。这是由于我们的输入长度T31小于状态维度D128,从而将训练成本从Ω()增加到Ω()。没有MSC的DRAMA组合架构通过将总参数减少到50.4MB,训练和验证速度分别为4.84it/s和9.91it/s,进一步提高了效率。最后,包含所有模块的完整DRAMA模型保持了50.6 MB的参数大小,但训练速度略有下降,降至3.86 it/s。尽管如此,它还是获得了最高的PDM分数,验证了集成方法的整体有效性和效率。
定性结果
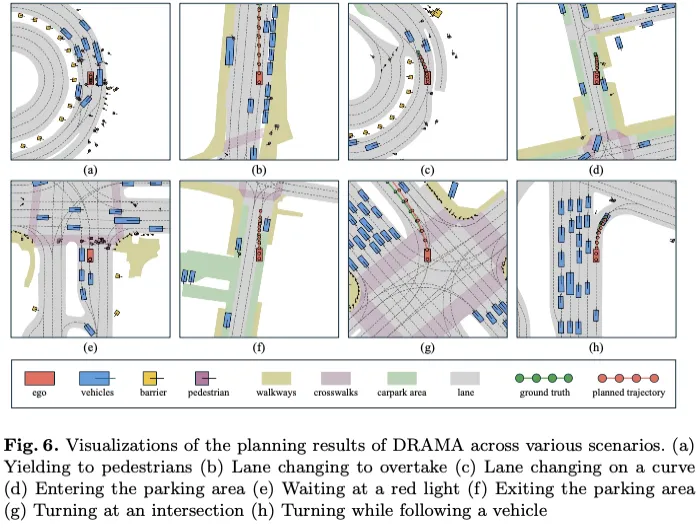
我们展示了图6所示的8个代表性场景,其中我们的DRAMA模型展示了安全准确的端到端规划结果。在子图(a)和(e)中,我们的规划师准确地发出命令,保持静止,为过街的行人让路,而不考虑是否存在明确的交通灯控制。在子图(a)中,行人在没有红绿灯的弯道过马路,而在子图中(e),行人在有红绿灯和人行横道的情况下过马路。这些场景表明,我们的规划师能够识别交通信号灯和潜在危险,做出安全的规划决策。在子图(b)和(c)中,我们的规划师根据前方车辆的低速发出变道命令。这表明我们的规划师能够生成快速复杂的规划操作,以提高驾驶效率。子图(d)和(f)展示了我们的规划师在低速场景中的熟练程度,特别是在进出停车位方面。这些例子突出了规划师的精确控制和决策能力,确保了平稳高效的停车操作。最后,子图(g)和(h)展示了我们的模型在执行右转和左转时的规划能力。这些例子突出了规划者在精确和安全地处理各种交通场景方面的适应性,展示了其对复杂驾驶操作的全面理解。
讨论和未来工作
由于NAVSIM排行榜的临时关闭和比较解决方案的可用性有限,我们采用了公共测试数据集来评估基线和我们提出的方法。基线在NAVSIM排行榜上的PDM得分为0.8483;然而,当在公共数据集上进行测试时,它下降到0.8347。我们表现最佳的方法获得了0.8548的PDM得分,这在公共测试数据集上的基线中令人惊讶。所提出的多尺度卷积有助于DRAMA的性能,尽管不影响验证速度,但牺牲了训练效率。开发板商城 天皓智联 TB上有视觉设备哦 支持AI相关~ 大模型相关也可用 whaosoft aiot自动驾驶也可以哦
鉴于所提出的多尺度卷积训练速度的降低,我们将探索其他强大而高效的视觉编码器。此外,我们还将考虑在现实场景中测试我们提出的计划器。
结论
这项工作提出了一种名为DRAMA的基于Mamba的端到端运动规划器,这是Mamba在自动驾驶运动规划方面的第一项研究。我们提出的Mamba融合和Mamba Transformer解码器有效地提高了整体规划性能,Mamba Transformers为传统Transformer解码器提供了一种可行的替代方案,特别是在处理长序列时。此外,我们引入的特征状态丢弃提高了规划器的鲁棒性,可以集成到其他基于注意力的模型中,在不增加训练或推理时间的情况下提高性能。我们使用公共规划数据集NAVSIM对DRAMA进行了评估,结果表明,我们的方法在参数少、计算成本低的情况下明显优于基线Transfer。
.
#DeepInteraction++
多模态3D再进化!融合感知算法新SOTA
目前随着自动驾驶技术的快速发展,安全的自动驾驶车辆需要依赖可靠和准确的场景感知,其中3D目标检测是非常核心的一项任务。自动驾驶中的感知模块通过定位和识别周围3D世界中的决策敏感物体,从而为下游的规控模块做出准确的决策提供保障。
自动驾驶车辆为了输出准确和可靠的感知结果,通常均会配备激光雷达、相机、毫米波雷达以及超声波雷达等多种传感器采集设备。为了增强自动驾驶车辆的感知能力,目前大多数自动驾驶汽车都同时部署了激光雷达和摄像头传感器,分别提供3D点云和RGB图像。由于两种传感器的感知特性不同,它们自然表现出强烈的互补效应。点云涉及必要的目标定位和几何信息,具有稀疏表示的特性,而2D图像则以高分辨率的形式提供丰富的目标外观和语义信息。因此,跨模态的专用信息融合对于强大的场景感知尤为重要。
目前常用的多模态3D目标检测方法通常采用如下图(a)图的融合策略,将各个模态的表示组合成混合的特征。然而,这种融合方法在结构上受到限制,由于信息融合到统一表示的过程中存在很大程度上的不完善,所以可能会丢失很大一部分特定模态的表示信息。
针对上述提到的相关问题,并为了克服上述提到的相关挑战,我们提出了一种新颖的模态交互策略,称之为DeepInteraction++,相关的融合结构如下图的(b)图所示。
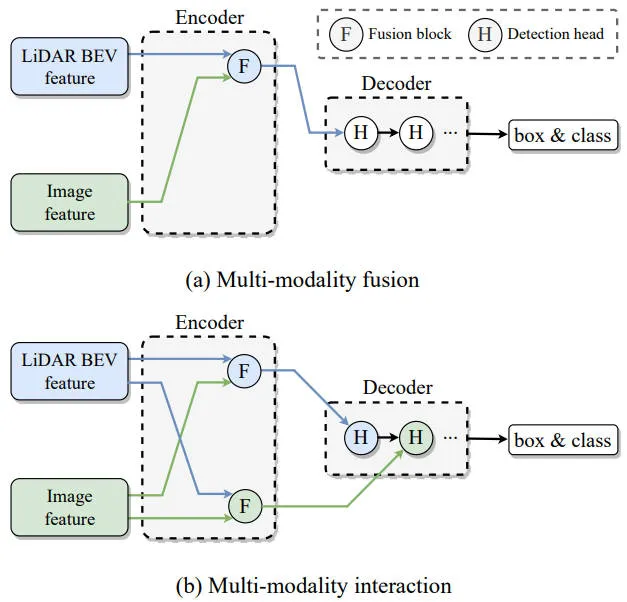
各类不同的多模态融合感知算法架构对比
我们工作的核心思路是学习和维护多种特定模态的特征表示,而不是得出单一模态的融合表示。我们提出的方法实现了模态间的交互,允许自发交换信息并保留特定模态的信息优势,同时最小化不同模态之间的干扰。具体来说,我们首先使用两个独立的特征提取主干网络,以并行的方式将3D空间的点云数据和2D平面的多视图图像映射到多尺度的LiDAR BEV特征和相机全景特征中。随后,我们使用编码器以双边方式交互异构特征来进行渐进式表示学习和集成。为了充分利用每个模态的特征表达,我们设计了一个解码器以级联方式进行多模态预测交互,以产生更准确的感知结果。大量实验证明了我们提出的DeepInteraction++框架在3D目标检测和端到端自动驾驶任务上均具有卓越的性能。
论文链接:https://www.arxiv.org/pdf/2408.05075
代码链接:https://github.com/fudan-zvg/DeepInteraction
网络模型的整体架构和细节梳理
在详细介绍本文提出的DeepInteraction++算法模型之前,下图整体展示了提出的DeepInteraction++算法模型的网络结构。
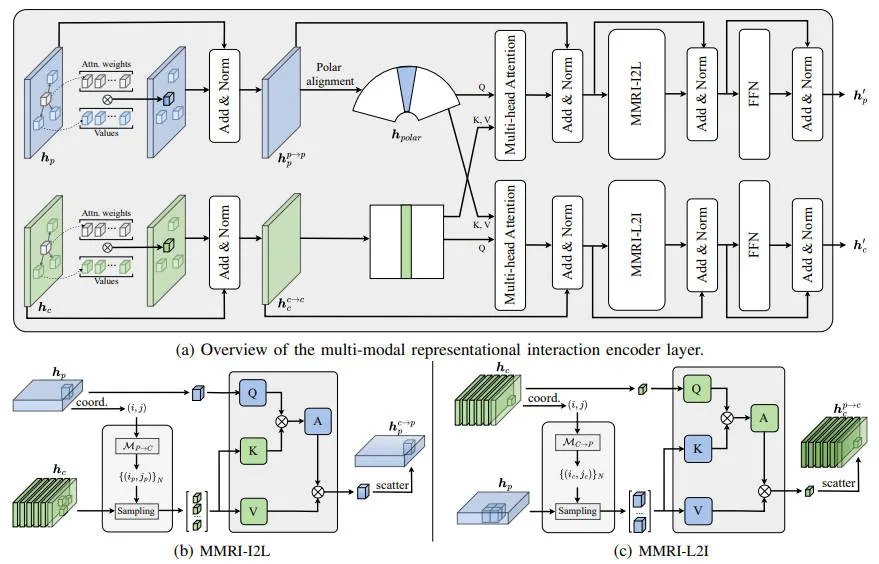
提出DeepInteraction算法模型的整体框架图
与现有技术相比,本文提出的算法模型在整个检测流程中为激光雷达点云和相机图像模态保留两种不同的特征表示,同时通过多模态的交互策略实现了不同模态信息交换和聚合,而不是创建单一的模态融合表示。通过上图的网络结构可以看出,提出的DeepInteraction++由两个主要模块组成:具有多模态表征交互的编码器模块和具有多模态预测交互的解码器模块。编码器实现模态之间的信息交换和集成,同时通过多模态表征交互保持每个模态的单独场景表达。解码器从单独的模态特定表示中聚合信息,并以统一的模态无关方式迭代细化检测结果。
编码器:实现多模态的表达交互
与通常将多个模态的输入特征聚合到一个混合特征图的传统模态融合策略不同,我们设计的编码器模块采用了多输入多输出的结构,通过多模态表达交互的方式来维护和增强单个模态的特征,其编码器的网络结构如上图中的(a)图所示。整体而言,编码器模块将激光雷达和图像主干独立提取的两个特定模态场景表示特征作为输入,并产生两个精修的特征表达作为输出。具体而言,编码器模块由堆叠多个多模态表征交互编码器层组成。在每一层中,来自不同模态的特征参与多模态表征交互和模态内表征学习,以实现模态间和模态内的交互过程。
双流Transformer的交互编码器模块
在之前DeepInteraction算法模型的基础上,为了进一步推动更高的可扩展性和降低计算开销,我们通过将原始编码器层替换为一对自定义的注意交互机制的Transformer层来实现。此外,多模态表达交互模块中的并行模态内和模态间表征学习现在用作重构架构中的自注意和交叉注意操作。这里,我们以激光雷达分支为例,每个Transformer层内的计算可以表示为如下的情况:
其中公式中的FFN表示前馈网络层,LN表示层归一化,SA和CA分别为表示多模表达交互和模态内表征学习。图像分支中的Transformer 层遵循类似的设计。
多模态表达交互
以相机全景特征表达以及激光雷达BEV表达作为两种模态的输入,我们的多模态表达交互用于实现以双边的方式交换临近上下文的信息,具体实现过程如下。
为了定义跨模态之间的邻接关系,我们首先需要建立激光雷达BEV特征表达和相机全景特征表达之间的像素到像素的对应关系。为此,我们在图像坐标系和BEV坐标系之间构建密集映射( 和)。
再确定了跨模态的邻接关系之后,我们采用注意机制来实现跨模态信息的交换过程。具体而言,给定一张图片作为查询,它的跨模态邻域用于交叉注意力机制中的键和值,其表示方式如下:
其中代表的是在2D表达中位置的元素,是激光雷达到图像表达交互,实现使用激光雷达的点云信息增强图像特征图。同样反过来,给定一个激光雷达BEV特征点作为查询,我们获取它的跨模态领域作为查询。同样采用上述的计算流程用于实现图像到激光雷达的表达交互。
为了促进稀疏激光雷达点云和密集图像模态之间的表征交互,我们需要进行有效的跨模态表征增强。我们引入了一种新的交互机制,即利用激光雷达引导的图像列和BEV极射线之间的跨平面注意力机制,从而实现有效地利用表征交互中的密集图像特征。具体而言,对于每个相机,我们首先转换到极坐标进而得到,其中是图像特征的宽度,是半径的维度。一旦相机参数固定,两个序列元素之间的对应关系将变得更加稳定且更容易学习。我们利用多头注意力和正弦位置编码来捕捉这种模式
模态内表征学习
除了直接合并来自异构模态的信息之外,模态内推理还有助于更全面地整合这些表征。因此,在编码器的每一层中,我们进行与多模态交互互补的模态内表征学习。在本文中,我们利用可变形注意力进行模态内表征学习。同时,考虑到透视投影引入的尺度差异,相比于固定局部邻域内的交叉注意力,具有更灵活感受野的交互操作更为合理,从而在保持原有高效局部计算的同时,实现了更灵活的感受野,并促进了多尺度的信息交互。
分组稀疏注意力实现高效交互
考虑到激光雷达点云固有的稀疏性,激光雷达点的数量在Pillar内会根据其位置而变化,并且单个Pillar内的点最多只能被两个摄像头看到。因此,为了在图像到激光雷达的表示交互期间充分利用GPU的并行计算能力,我们仔细检查每个Pillar中有效图像标记数量的分布,并将这些Pillar划分为几个区间,然后,我们通过将键和值的数量填充到间隔的上限来批量处理每个间隔内的支柱,以进行注意力计算。通过仔细选择间隔边界,可显著减少内存消耗,而对并行性的影响可忽略不计。
解码器:多模态预测交互
除了考虑表示层面的多模态交互之外,我们还引入了具有多模态预测交互的解码器来进行预测,其网络结构如下图所示。
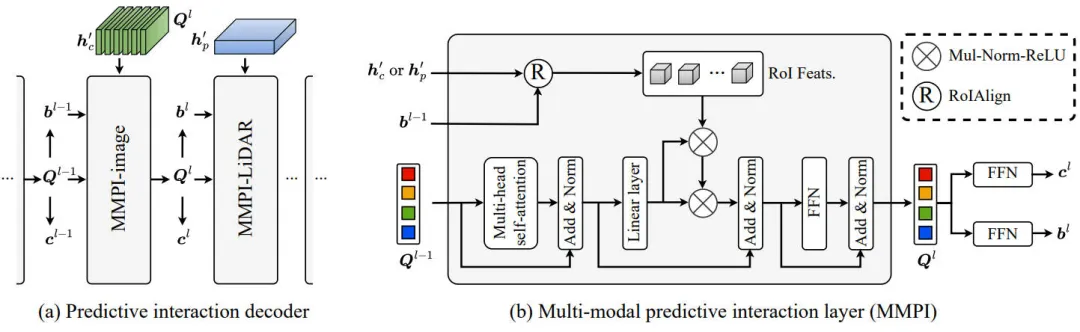
多模态预测交互模块网络结构图
通过上图的(a)图可以看出,我们的核心思想是增强一种模态在另一种模态条件下的3D目标检测。具体来说,解码器是通过堆叠多个多模态预测交互层来构建的,其中部署预测交互以通过交替聚合来自增强图像表示和增强BEV表示的信息来逐步细化预测过程。
端到端的自动驾驶
为了进一步证明我们提出的DeepInteraction++的可扩展性和优越性,我们将DeepInteraction++扩展为端到端多任务框架,同时解决场景感知、运动预测和规划任务。具体而言,在使用了现有的检测头之外,我们还使用了额外的任务头来形成端到端框架,包括用于地图分割的分割头、用于估计被检测物体运动状态的预测头和用于为自我车辆提供最终行动计划的规划头。考虑到来自BEV和周围视图的特征图用于深度交互式解码,我们做了一些修改以利用这一优势。首先,与激光雷达点云相比,图像上下文对于地图表示更具辨别性,而大量的点云信息可能会反过来造成混淆。因此,我们通过LSS将周围视图特征投影到BEV上,然后将它们传播到地图分割头中。随后,预测和规划头将检测和分割生成的结果作为输入,并使用标准Transformer解码器对其进行处理,从而实现端到端的自动驾驶任务。
实验
为了验证我们提出算法模型的有效性,我们在nuScenes的验证集和测试集上与其它SOTA算法模型进行了对比,相关的实验结果如下图所示。
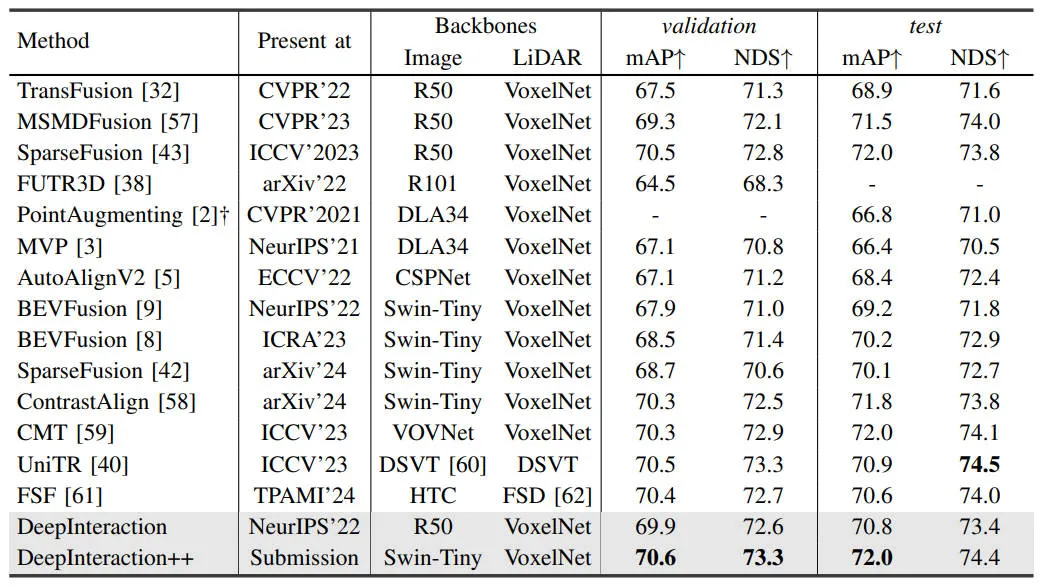
不同算法模型在nuScenes数据集上的精度对比
通过上述的实验结果可以看出,我们提出的DeepInteraction++算法模型实现了SOTA的感知性能。此外,为了进一步直观的展现我们提出算法模型的效果,我们将模型的检测结果进行了可视化,如下图所示。

算法模型的可视化结果
此外,为了展现我们提出的DeepInteraction++框架在端到端任务上的性能,我们也在nuScenes的验证集上比较了SOTA算法模型的端到端的规划性能,具体的性能指标如下图所示。
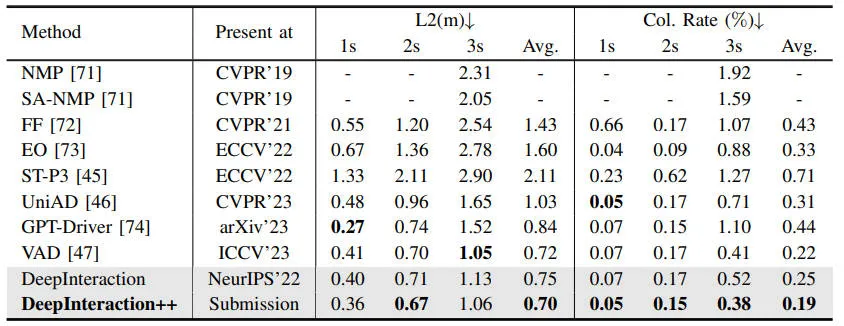
不同算法模型的planning性能
上述的实验结果表明我们提出的算法框架在大多数评估指标上显著超越了现有的面向规划的方法。除了提供更准确的规划轨迹外,DeepInteraction++ 还可以通过对交通参与者进行更精确、更全面的感知和预测来实现更低的碰撞率。为了更加直观的展现我们模型的planning性能,我们也将相关的结果进行了可视化,如下图所示。
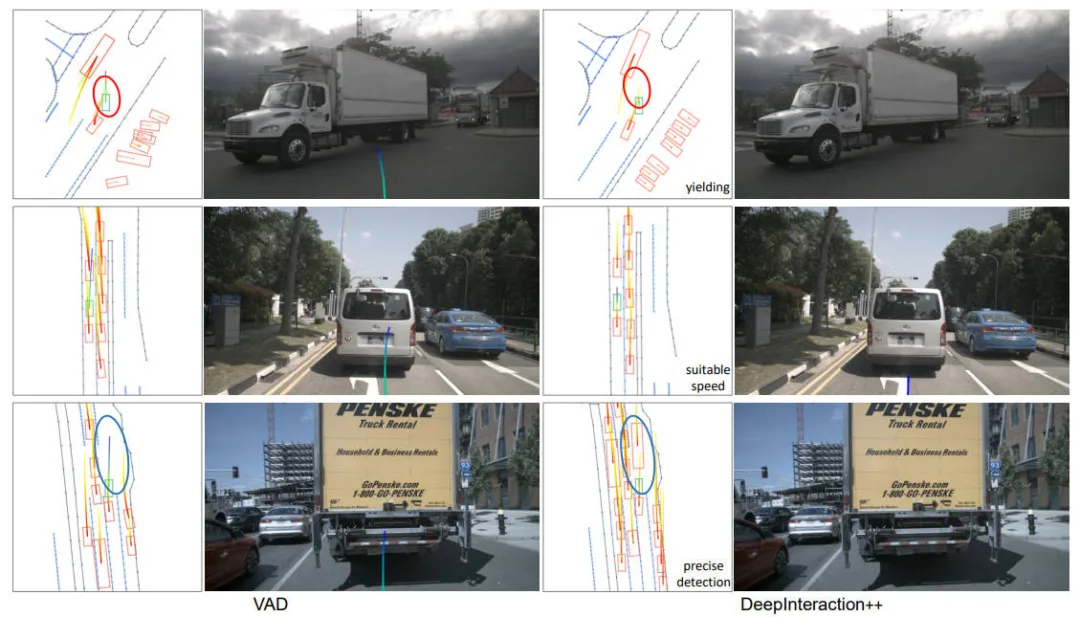
端到端planning任务的性能对比情况
通过上图的可视化结果可以看出,通过整合多模态信息并采用有意义的融合策略,我们提出的方法可以全面理解和分析驾驶场景,从而即使在复杂而错综复杂的驾驶环境中也能做出更合理的规划行为。此外,由于上游的精准感知,DeepInteraction++能够有效避免因累积误差而导致的错误动作,如上图中的第三行所示。
结论
在本文中,我们提出了一种新颖的多模态交互方法DeepInteraction++,用于探索自动驾驶任务中内在的多模态互补性及其各自模态的特性。大量的实验结果表明,我们提出的方法在nuScenes数据集上的3D目标检测以及端到端任务上取得了最先进的性能。
.
#轨迹预测之问
Anchor-based方法能否被Anchor-free取代?
Anchor-based方法能否被Anchor-free取代?
Anchor-based方法真的不行吗?
在目标检测和轨迹预测领域,Anchor的概念扮演着举足轻重的角色。它不仅作为检测或预测过程中的重要参考信息,还深刻影响着算法的设计与应用效果。
在目标检测领域,Anchor-based方法通过预设一系列具有不同大小和长宽比的锚框(Anchor Boxes)作为候选区域,用于目标检测。这些锚框基于图像特征或统计数据设计,旨在覆盖可能的目标位置和形状。模型会预测每个锚框内是否存在目标物体,以及目标的位置偏移和类别。这类方法通常具有较高的检测准确率,因为它们通过精细设计的锚框来缩小搜索空间,使得模型更容易学习到目标的特征。同时,它也便于实现多尺度检测,通过在不同层级的特征图上设置不同尺度的锚框来适应不同大小的目标。Anchor-free方法不依赖于预定义的锚框,而是直接在图像或特征图上预测目标的位置和形状。这种方法通过预测关键点(如中心点、角点等)或边界框本身来实现目标检测。这种方法较为灵活,因为它们不受锚框数量和尺度的限制,能够更好地适应不同大小和形状的目标。同时,由于不需要手动设计锚框,这种方法也减少了人工干预和调试的工作量。
在轨迹预测领域,Anchor-based方法通常依赖于先验信息或历史数据来定义一系列可能的轨迹点或路径作为参考。这些方法通过预测智能体相对于这些参考点的运动状态或偏移来预测其未来轨迹,因此,可以利用丰富的历史数据和先验知识来指导预测过程,提高预测的准确性和鲁棒性,同时便于实现多模态预测,通过考虑不同的轨迹点或路径组合来应对智能体行为的不确定性。而Anchor-free轨迹预测方法不依赖于固定的参考点或路径,而是直接根据智能体的历史状态和周围环境信息来预测其未来轨迹。这些方法通常使用深度学习模型来捕捉智能体的运动规律和意图,并据此生成预测轨迹,它们不受限于任何预设的轨迹点或路径,因此能够更好地适应复杂多变的交通环境和智能体行为模式。
当我们观察Argoverse榜单,能看到许许多多anchor-free架构的模型如LOF1、HPNet2、SEPT3以及HiVT4等,却难以看见anchor-based模型的影子。这一现象说明了anchor-free方法的预测准确性远远超过anchor-based方法,那anchor-based方法是否会被时代淘汰呢?
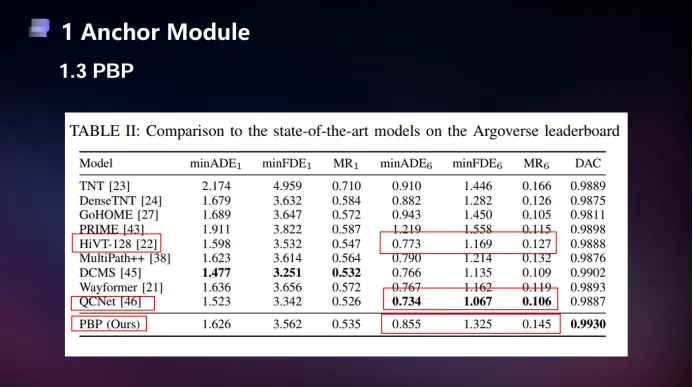
图1PBP与SOTA的对比
但在工业界,实际上大家普遍更加认可的却是anchor-based架构,如PBP5、TNT6或DenseTNT7等。一方面,对于下游而言,轨迹预测的准确性并非越高越好,我们定义的准确性是将预测轨迹和预测的GT进行对比,然而数据集的GT不是现实生活中的唯一解另一方面,anchor-based方法输出的轨迹具有真实性,能够更好地部署到自动驾驶框架之中。
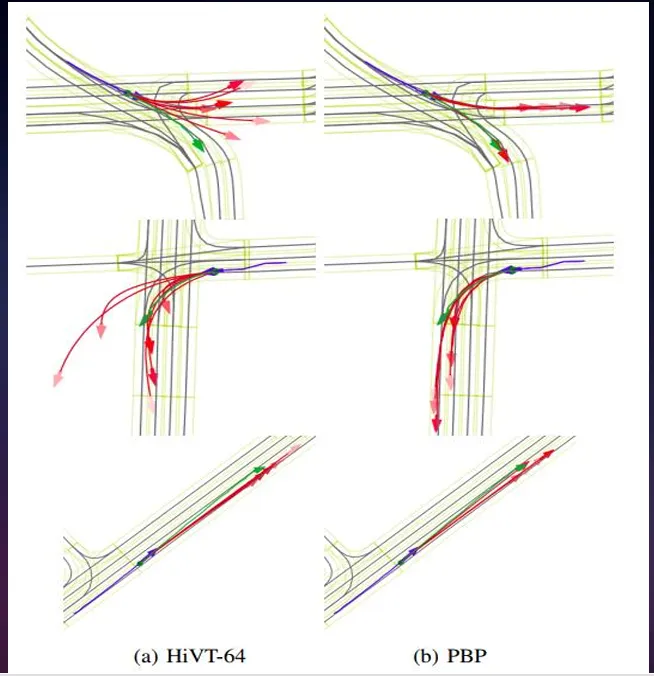
图2HiVT-64和PBP对比(注:HiVT尽管精度比PBP高,但会出现①超出道路边界的不可能预测②不符合地图结构的预测③缺少模态)
总的来说,轨迹预测中两种方法的主要的优缺点总结如下:
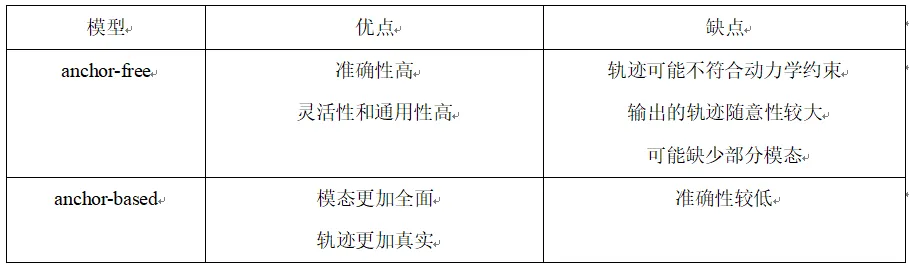
表1.Anchor-based和anchor-free方法对比
那么为什么anchor-based方法能够输出更加真实、与地图兼容和全面的轨迹呢?接下来,我们将从anchor-based典型代表:PBP和MTR轨迹预测模型分析其中的奥秘。
PBP:有目标的轨迹预测
本文提出了一个名为Path-based Prediction方法,这一网络首先利用场景编码器提取智能体(如其他车辆)的历史位置和高精地图信息的特征向量。然后,候选路径采样器从地图的车道图中为每个代理生成一系列可能的参考路径。路径分类器进一步预测这些路径的概率分布。最后,轨迹回归器在Frenet路径坐标系中,针对每条参考路径预测代理的未来轨迹,这些轨迹随后转换回笛卡尔坐标系以获得多模态预测结果。与传统的目标驱动预测相比,PBP方法通过在整个参考路径上进行操作,而不是仅依赖于目标位置,从而提高了预测的准确性和地图适应性。
PBP框架的核心亮点在于候选轨迹和Frenet坐标系的应用。候选轨迹生成的目的是基于矢量地图和目标智能体的位置与行驶方向得到目标智能体的未来可能的所有轨迹。候选轨迹需要满足两个原则:其一是轨迹起点要在目标智能体足够接近,以保证不会出现状态跳变的现象,其二是候选轨迹必须沿着目标智能体的形式方向,其原因在于车辆在正常路面上倒车属于小概率事件。在满足这两个条件之后,便可以通过宽度优先算法进行搜索,得到多条候选轨迹。候选轨迹可以为轨迹解码器提供参考的先验信息使得输出的轨迹更倾向沿着车道中心线的方向,以此保证输出轨迹的地图适应性。
Frenet坐标系定义沿着参考轨迹前进方向为正方向,以车辆中心为原点,X表示沿着参考轨迹的曲线距离,Y代表与参考轨迹对应切线的最短距离。Frenet坐标系将轨迹预测问题从二维或三维笛卡尔空间转换为基于路径的一维纵向(s)和横向(d)坐标表示,简化了预测模型需要处理的数据维度。同时,由于车道中心线提供了一个自然的参考,轨迹预测的方差会降低,这有助于生成更加稳定和可靠,更加符合道路布局和交通规则的轨迹。
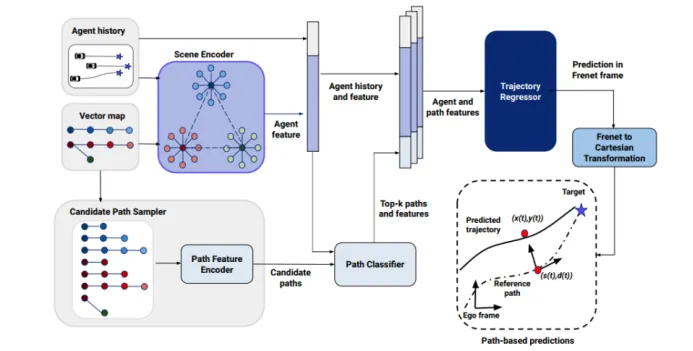
图3PBP模型框架
MTR:全局意图定位和局部运动细化的有机结合
在自动驾驶技术的前沿探索中,Motion Transformer(MTR)以其独特的全局意图定位和局部运动细化机制,为anchor-based轨迹预测树立了新的标杆。
1.全局意图定位
全局意图定位是MTR框架中的基石,它为后续的轨迹预测提供了宏观的方向性指导。这一步骤的核心在于确定交通参与者可能的宏观运动意图,这些意图通常与参与者的最终目的地或主要运动方向紧密相关。
通过引入静态意图查询(static intention queries),MTR巧妙地构建了一组代表性的意图点,每个点都对应着一个特定的运动模式。这些静态查询作为学习到的positional embeddings,能够生成特定于运动模式的初步轨迹。与传统的密集目标候选集相比,静态意图查询显著提高了训练过程的稳定性,并确保了模型能够更全面地覆盖所有潜在的未来行为。
全局意图定位的作用不仅在于缩小预测范围,使模型能够集中精力探索最有可能的轨迹,更在于为后续的局部运动细化提供了有力的基础。通过确定大致的运动方向和意图,模型能够在复杂的交通环境中保持清晰的思路,为更精细的预测奠定基础。
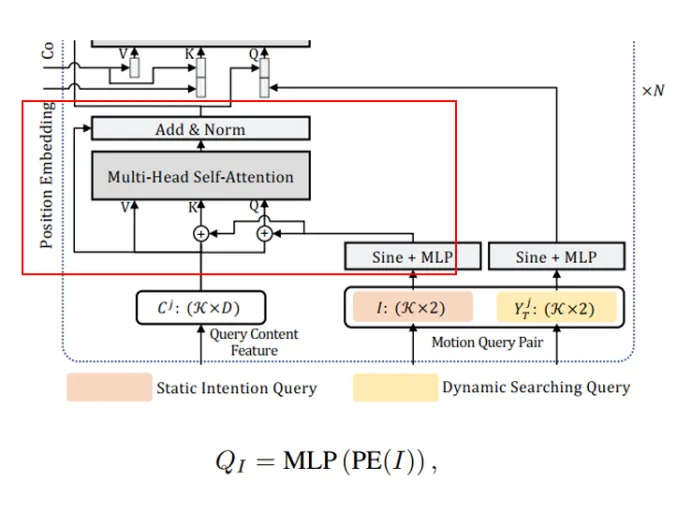
图4全局意图定位(注:引入静态意图点的目的:①每个意图点负责一个模态,保证预测模态全面②降低未来轨迹的不确定性③稳定训练过程)
2.局部运动细化
在全局意图定位之后,局部运动细化作为MTR框架的精细打磨环节,负责对预测的轨迹进行细粒度的调整和优化。这一步骤的核心在于捕捉并利用局部区域的具体信息,以提高预测的精度和可靠性。
动态搜索查询(dynamic searching queries)在这一过程中扮演了关键角色。它们被初始化为与静态意图查询相对应的位置嵌入,但能够根据预测的轨迹动态更新。这些动态查询像是一双双敏锐的眼睛,不断检索每个意图点周围的细粒度局部特征,使模型能够根据最新的局部上下文信息对预测轨迹进行微调。
局部运动细化的作用在于捕捉复杂的场景细节,如道路条件、交通信号、周围其他参与者的行为等。通过充分利用这些信息,模型能够生成更加符合实际场景的轨迹预测,从而提高自动驾驶系统的安全性和可靠性。
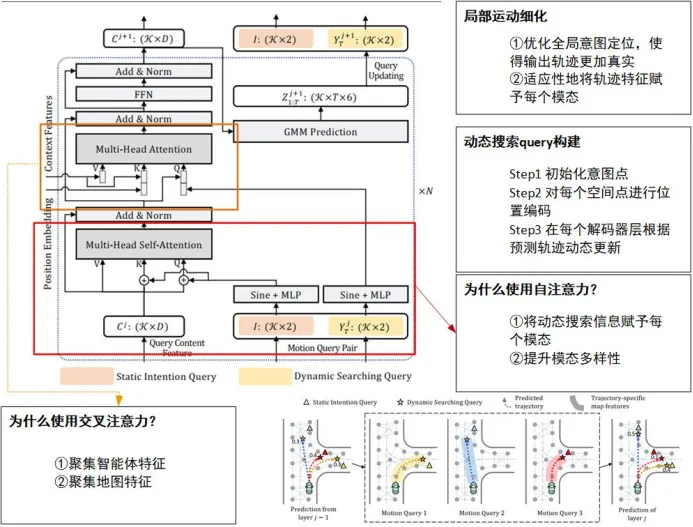
图5MTR局部运动细化
3.局部和全局的协同工作
全局意图定位和局部运动细化在MTR框架中并非孤立存在,而是紧密相连、协同工作的。全局意图定位提供了宏观的指导方向,为局部运动细化划定了探索范围;而局部运动细化则通过精细的调整和优化,确保了预测轨迹的准确性和可靠性。
这种分层次的处理方法不仅提高了轨迹预测的效率,还显著提升了预测的精度。在自动驾驶系统中,这样的预测能力对于车辆理解周围环境、规划安全路径以及做出快速响应至关重要。
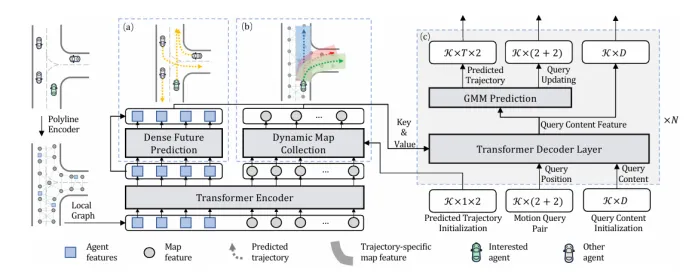
图6MTR总体框架
总结
在轨迹预测领域,尽管近年来Anchor-free方法因其高准确性和灵活性在学术研究和排行榜上崭露头角,但Anchor-based方法依然占据着不可或缺的重要地位,特别是在工业界和实际应用中。本文深入探讨了Anchor-based与Anchor-free两种方法的优缺点,并通过分析PBP和MTR这两个典型的Anchor-based轨迹预测模型,揭示了Anchor-based方法为何能够输出更加真实、与地图兼容且全面的轨迹。
Anchor-based方法通过预设一系列基于先验知识或历史数据的锚点或路径作为参考,不仅缩小了预测空间,提高了预测效率,还使得预测结果更加符合实际交通规则和道路布局。例如,PBP模型通过候选路径采样器和Frenet坐标系的应用,确保了预测轨迹的地图适应性和真实性。而MTR模型则通过全局意图定位和局部运动细化的有机结合,进一步提升了预测的准确性和鲁棒性。
在工业界,轨迹预测的准确性并非唯一追求,更重要的是预测轨迹的实用性和可部署性。Anchor-based方法输出的轨迹更加真实,能够更好地与自动驾驶框架中的其他模块(如路径规划、控制等)协同工作,确保车辆在实际道路环境中的安全行驶。此外,Anchor-based方法还能够实现多模态预测,通过考虑不同的轨迹点或路径组合来应对智能体行为的不确定性,为自动驾驶系统提供更加全面的决策支持。
未来,随着技术的不断进步和需求的不断变化,Anchor-based与Anchor-free方法或将进一步融合创新,共同推动轨迹预测技术的发展。
一点小感悟
在参与轨迹预测小班课的过程中,Thomas和Paul老师的生动讲解不仅让我对技术细节有了更深入的理解,而且领悟到两个人生道理。首先,我深刻体会到了"预设与灵活性"的辩证关系。Anchor-based方法通过预设锚点或路径,为预测提供了稳定的框架,但这也要求我们在面对变化时保持足够的灵活性。人生亦是如此,我们需要设定目标,规划路径,但更要有应对突发情况、灵活调整策略的能力。正如在自动驾驶中,车辆需要根据实时路况和周围环境的变化来动态调整行驶轨迹,我们在人生道路上也需要根据环境和自身条件的变化,适时调整方向,保持前进的动力。其次,我认识到了"全面性与真实性"的重要性。Anchor-based方法能够输出更加全面、真实的轨迹,这得益于它对多种可能性的综合考虑和对实际环境的深刻理解。人生亦是如此,我们不仅要追求表面的成功和成就,更要注重内心的真实感受和价值观的塑造。只有全面审视自己的生活,真诚面对自己的内心,才能找到真正属于自己的道路,活出真实的自我。
#LEO
多模态LLM能力升级,与3D世界交互更进一步!
论文题目:LEO: An Embodied Generalist Agent in 3D World
原文链接:https://arxiv.org/abs/2311.12871
项目地址:https://embodied-generalist.github.io/
作者单位:北京通用人工智能研究院通用视觉实验室
在人工智能和神经科学领域,构建一个能够处理各种综合任务的通用模型一直是研究者们长期追求的目标。这种模型应该能够像人类一样,不仅在二维空间中表现出色,更能深入理解和交互于复杂的三维物理世界。然而,现有的通用模型在二维领域的成就虽然显著,但它们在三维空间的理解上却显得力不从心,这成为了它们在解决现实世界任务和接近人类智能水平时的一大障碍。为了克服这一限制,文章提出了一个核心问题:**如何使智能体不仅能够全面理解真实的三维世界,还能与之进行有效的交互?**在探索这一问题的过程中,文章发现智能体的发展面临三个主要的挑战:
- 数据集的缺乏:与二维数据相比,三维数据的收集成本更高,这限制了模型训练和验证的广度和深度。
- 统一模型的缺失:以往的三维视觉语言(3D VL)模型并没有经过大规模的统一预训练,也没有有效的微调策略,这些模型通常基于强先验设计,而缺乏灵活性和泛化能力。
- 学习策略的不足:在视觉语言学习(VLA)的潜力和大型语言模型(LLM)对三维任务的适应性方面,还有很多未被充分探索的问题。
为此,北京通用人工智能研究院通用视觉实验室(BIGAI)的研究团队引入了多模态通用智能体LEO,它能以自我视角的2D图像、3D点云、文本作为任务输入,在3D环境中处理综合性任务。 LEO展示了具有统一任务接口、模型架构和目标的感知、基础、推理、计划和行动能力。
LEO采用了两阶段的训练方案,即**(i) 3D 视觉-语言 (3D VL) 对齐和 (ii) 3D 视觉-语言-动作 (VLA) 指令调优** 。文章收集的大规模数据集包括各种对象级和场景级任务,这些任务需要对 3D 世界有深入的理解并与之交互。值得注意的是,文章精心设计了一个LLM辅助流水线 来生成高质量的3D VL数据,并使用场景图和以对象为中心的思维链(O-CoT)方法来提示LLM。为了进一步加强质量控制,文章设计了一系列通过正则表达式匹配和场景图检索的改进程序。文章证明了该方法在很大程度上丰富了数据的规模和多样性,同时减轻了LLM生成数据时的错误率。文章在不同的3D任务上定量地评估LEO并进行消融研究,包括3D字幕描述、3D问答、定位问题回答、xx导航和机器人操作设计。
模型
下面一起来看看LEO的模型是如何设计的吧。LEO主要做了两件事,第一件事是将自我视角的二维图、全局视角的三维图、文本指令转化为多模态输入,并用统一架构输出文本回复和具体动作命令。具体来说,首先将所有不同模态的数据转换为一系列符号(如下所示),然后用预训练的LLM来处理这些序列:
进而,LEO的学习过程被表述为一种特定的语言建模任务。具体来说,它使用了GPT(Generative Pre-trained Transformer)风格的自回归语言建模方法,即通过自回归的方式(即依次生成序列中的每个元素,每个元素的生成依赖于前面已经生成的元素)来预测文本序列的下一个词或字符。GPT自回归语言建模时输入一个给定前缀的上下文中,并指导后续文本的生成。综上所述,通过将LEO的学习过程采用前缀语言建模的方法,使其能够根据给定的前缀生成适当的响应或输出。
LEO做的第二件事就是利用预训练的大型语言模型(LLM)作为下游任务的强大先验知识,从而泛化应用在多种通用化人工智能任务上(包括3D字幕描述、3D问答、定位问题回答、xx导航和机器人操作设计等)。
LEO通过一个自我视角的2D图像编码器来感知实体视图,通过一个以物体为中心的3D点云编码器来感知他人视角的全局视图。这种感知模块可以灵活适应各种xx环境,增强三维推理能力。编码的视觉标记与文本标记相互交织,形成统一的多模态任务序列,该序列进一步作为仅解码器的LLM的输入。LLM配备了包含文本和动作标记的词汇表,可以同时生成对各种任务的回复。因此,所有的任务都被表述为序列预测,从而实现了统一的训练目标。
训练和推断
文章以前缀语言建模的方式制定了LEO训练跟随的目标函数。对于标记序列s和第B个批次,文章通过以下函数来优化LEO:
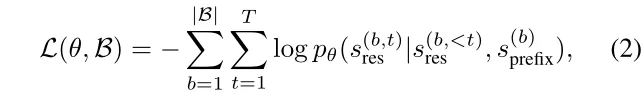
其中,s_prefix表示(1)中的前缀标记。在训练过程中,文章冻结了预训练的3D点云编码器和LLM,并微调了2D图像编码器、Spatial Transformer和LoRA参数。LEO总共有约7B个参数,其中约142M个参数将被调谐。在推理过程中,文章使用光束搜索来生成文本回复。
数据集
在展示训练结果之前还要说明数据集的划分以及一些训练细节。由于LEO是一个接受多模态输入并遵循指令的通用智能体,因此文章采用两阶段训练方法,并将数据分成两组:
(i) LEO-align :侧重于3D 视觉-语言 (3D VL) 对齐,以弥合3D场景表示与自然语言之间的差距。与BLIP-2类似,文章训练LEO在给定各种3D输入的情况下生成字幕。具体来说,文章收集了三种类型的3D字幕数据:1)对象级字幕,其中文章将3D单个对象与其描述对齐;2)场景中的对象描述,其目标是在3D场景上下文中生成对象的指代表达;3)场景级字幕,重点是用自然语言描述全局3D场景。
(ii) LEO-directive :针对3D 视觉-语言-动作 (3D VLA) 指令调优,赋予LEO各种泛化能力。文章策划了一套全面的任务,涵盖了从基础场景理解和推理到对话、规划和具体化动作。具体来说,文章引入了:1)3D字幕描述和问题回答------给定3D场景输入,智能体需要生成自然语言回应来描述场景或回答问题;2) 3D对话和任务规划,其中智能体被期望对给定3D场景的复杂指令产生灵活连贯的回复;3)导航和操作,这需要智能体在3D场景中完成各种xx操作任务(embodied acting tasks)。
LLM辅助的3D文本配对数据生成
产生大量LEO-align和LEO - directive数据集的核心是用LLM(即ChatGPT)辅助生成3D文本配对数据,如图二。
能力评估和分析
文章全面评估了包括感知、定位、推理、规划和行动在内的三维任务,展示了LEO的能力。
1 3D视觉语言理解和推理
从智能体自我中心的角度理解和推理对象属性、对象关系和3D场景的其他方面是3D世界中xx通用智能体的基本能力。文章研究了LEO执行3D 视觉语言理解和具体化推理任务的能力。具体来说,文章考虑了三个著名的3D任务:Scan2Cap上的3D字幕描述,ScanQA上的3D问答,以及SQA3D上的3D具体化推理。为了进行定量比较,文章采用了针对特定任务的方法和通用模型,包括:1)3D密集字幕描述的最先进专家模型;2)最先进的3D 问答(3D QA)专家模型;3)任务特定的微调通用模型,如3D-VisTA 和3D-LLM 。据文章所知,与之前的模型形成鲜明对比的是,LEO是第一个可以在统一架构中直接处理上述3D视觉语言任务而无需针对任务进行微调的模型。
结果如表4所示。**LEO在3D密集字幕描述和3D QA任务上明显优于最先进的单任务和特定任务微调模型。**与使用特定任务头部的专家模型相比,文章基于LLM的方法不仅提供了生成开放式回复的灵活性,而且还展示了出色的定量结果。另一方面,考虑到3D-LLM中复杂的特征聚合,文章认为以对象为中心的3D表示是一种简单而有效的选择,可以在利用LLM先验知识的同时将3D场景与LLM连接起来。
2 情景对话和规划
文章预期LEO将支持与人类更复杂的交互,例如,在3D世界中回应复杂的多轮用户指令。为了验证LEO的3D视觉语言的理解和推理能力,文章对3D对话和规划任务进行定性研究,并从LEO - instruction的测试集中使用模型未见过的场景测试。
结果如图A .1所示,LEO能够生成高质量的回复,它具有两个特点:1)精确对应到3D场景:LEO提出的任务规划涉及与3D场景相关的具体对象,以及这些对象相关的合理动作。2)丰富的信息性空间关系。LEO的回答中的实体通常伴随着详细的描述。此类信息有助于在复杂的3D场景中识别特定对象,并为人类提供相当大的帮助。
3 三维世界中的xx动作
为了探索LEO在3D世界中连接视觉语言行为的能力,文章选择了两个典型的xx化AI任务:AI Habitat上的对象导航(ObjNav)和CLIPort上的机器人操作。表5和6中展示了CLIPort操作和对象导航的结果。文章的研究结果如下:1)**在机器人操作方面,LEO的性能可与最先进的性能相媲美,在一些具有挑战性的未知任务上甚至更胜一筹。**特别是,LEO 直接产生运动指令,无需归纳偏差(如热图),展示了 LEO 在学习具体动作方面的巨大能力。
2)在对象导航(ObjNav)中,LEO实现了与基线相当的成功率,并且在MP3D-val上具有更好的SPL,这表明LEO可以利用以物体为中心的3D场景输入(可能提供粗略的全局地图)并采取更短的路径到达目标。此外,HM3Dval上的结果证实了LEO对新场景的零样本泛化能力。值得注意的是,所有基线模型都配备了循环模块,而LEO仅包含截断的过去行动,这可能是成功率较低的原因。
4 更多关于LEO的见解
文章在使用不同的数据配置进行训练时评估LEO,包括精确匹配、句子相似度和人工评级。文章将LEO指令调优而不包含动作任务(w/o Act)的组别作为默认设置。
是否对齐的影响: 与完成两阶段训练(w/o Act)相比,文章直接对没有对齐阶段的模型进行指令调整(w/o Align)。表7中的结果显示了对齐的一致影响。尤其是在Scan2Cap任务上,对齐的优势显得尤为突出,因为该任务专注于详细的场景理解和相应的字幕描述,而这正是对齐训练所聚焦的核心要点。
**专家模型VS通用模型:**即使在ScanNet任务上,ScanNet场景专家模型的表现也比w/o Act略差,尤其是在跨场景(3RQA)和任务(3RDialog和3RPlan)的泛化方面。这证明了通用的指令调优具有广泛的场景和任务覆盖的优势。
是否包含xx化的动作任务对视觉语言能力的影响: 文章比较了w/o Act和VLA,它们的不同之处在于是否包含xx化的动作任务。表7的结果显示,加入xx动作任务会导致3D VL任务的性能下降。这可能源于1)语言生成与xx动作预测之间的差距,2)xx动作任务的数据规模不平衡。与VL数据有利于VLA协同训练中的xx动作任务的发现(Brohan等人,2023)相反,文章的观察表明,xx动作任务可能反过来损害视觉语言(VL)能力。如何不断弥合虚拟语言与xx动作任务之间的差距,是进一步探索的重要方向。
有无对话和规划数据的影响: 与默认模型(表8中的w/ dialog)相反,文章在没有对话和规划数据(w/o dialog)的情况下训练LEO。文章设计了一个包含三种类型问题(可回答、不可回答和NLP)的评估集,并根据人类偏好使用TrueSkill 进行评估。表8的结果证实,在无对话的情况下,出现了更多的错觉 (用户对"无法回答"的偏好较低)**和更差的NLP技能。**这可能是因为1)对话数据中的不同对话有助于培养对复杂指令的灵活反应;2)文章的规划数据可以提供基于场景的常识性知识,并鼓励详细连贯的文本。
数据平衡的影响: 文章发现不平衡的数据可能会导致LEO产生错觉,例如,当被问到"这个房间里有什么东西吗?"时,它倾向于回答"是"。为了解决这个问题,文章在3RScanQA数据中添加了更多的负面样本(w/ Aug),其中查询了不存在的对象。文章还设计了一个具有不同类型(Yes和No)的对象存在性问题的评估集。表9中的结果表明,文章可以通过平衡调优数据有效地缓解错觉问题。此外,增强3RScan数据的好处可以以零样本的方式转移到ScanNet场景。
5 规模效应分析
文章研究了规模效应,即跟踪测试集上的指令调优损失随着数据规模的增长而增加的现象。除了默认的Vicuna-7B,文章还纳入了两个不同规模的LLM: OPT-1.3B 和Vicuna-13B 。对于Vicuna-7B,文章还探讨了对齐的影响(Scratch未对齐 vs. Aligned对齐)。
从图3的测试损失曲线中,文章发现:1)LEO的指令调优后符合规模定律: 所有曲线都随数据规模呈对数线性递减。2)扩展LLM的规模可以带来进一步的性能改进 :对齐的Vicuna-7B的损失明显低于对齐的OPT-1.3B。相比之下,尽管有持续的改进,但对齐的Vicuna-7B和Vicuna-13B之间的差距似乎不那么显著,这表明如果文章继续扩大LLM的规模,可能会出现饱和。这表明了LEO的规模扩大和扩展数据以匹配模型容量的必要性。3)对齐会带来性能改进:对齐的Vicuna-7B的损耗始终低于未对齐的 Vicuna-7B,这与表7中未对齐的Vicuna-7B的性能较差的结果相一致。
结论
本文提出的智能体LEO将当前LLM的通用能力从文本扩展到三维世界和xx化任务,这是构建xx通用人工智能的关键的第一步。结果表明:
(1) 通过对统一的模型进行与任务无关的指令调优,LEO在大多数任务上达到了最先进的性能,特别是超过了以前的特定任务模型;
(2) LEO精通情景对话和规划,能够产生灵活和连贯的反应;
(3) LEO在导航和操作任务上的性能可与当前最先进的特定任务模型相媲美,具有显著的泛化能力;
(4) LEO的强大性能源于数据和模型两个方面,包括对齐阶段、数据多样性、通用的指令调优和以对象为中心的表征;
(5) LEO表现出的规模效应规律印证了先前的研究结果。文章还展示了定性结果,以说明LEO的多功能性和熟练程度接地3D场景的理解。
尽管如此,也存在一些局限性,包括对新场景的泛化,以及视觉语言(VL)学习与xx动作规划之间的尚未弥合的差距。对此,文章提出了几个有前景的改进方向:
(1)通过利用来自更丰富的3D域的更大规模视觉语言(3D VL)数据来增强3D VL的理解能力;
(2)不断弥合3D VL和xx动作之间的差距,文章的实验揭示了他们联合学习的有效性;
(3)在xx通用智能体的背景下研究LLM错觉和对齐问题,特别是考虑到文章的规模分析表明,通过对数据和模型扩大规模可以显著优化模型。
.
#HybridOcc
NeRF与Occ能怎么结合?HybridOcc也许是个答案
基于视觉的3D语义场景补全(SSC)通过3D volume表示来描述自动驾驶场景。然而,场景表面对不可见体素的遮挡给当前SSC方法在幻想精细3D几何形状方面带来了挑战。这里提出了一种名为HybridOcc的混合方法,该方法结合了Transformer框架和NeRF表示生成的3D volume查询建议,并在一个由粗到细的SSC预测框架中进行优化。HybridOcc通过基于混合查询建议的Transformer范式来聚合上下文特征,同时结合NeRF表示来获得深度监督。Transformer分支包含多个尺度,并使用空间交叉注意力进行2D到3D的转换。新设计的NeRF分支通过volume渲染隐式推断场景占用情况,包括可见和不可见的体素,并显式捕获场景深度而非生成RGB颜色。此外还提出了一种创新的占用感知光线采样方法,以引导SSC任务而非仅关注场景表面,从而进一步提高整体性能。在nuScenes和SemanticKITTI数据集上进行的大量实验证明了HybridOcc在SSC任务中的有效性。
领域背景介绍
基于相机的3D场景理解是自动驾驶感知系统的重要组成部分。它涉及获取准确且全面的现实世界3D信息,即使在车辆轻微移动的情况下也能如此。近年来,在多相机系统的帮助下,在深度估计和3D检测等任务中,多相机系统已经取得了与激光雷达相媲美的成绩。语义场景补全(SSC)最近比3D检测获得了更多关注。由于语义场景补全能够表示任意形状和类别的场景,因此它更适合自动驾驶的下游任务。然而,从有限的观测视角推断出全面的语义场景是具有挑战性的。
MonoScene 提出了直接通过特征投影将2D图像提升到3D体素以完成SSC任务。最近,一些工作提出了基于空间交叉注意力将多视角相机特征提升到3D表示。在Occ3D 提出的从粗到细的框架中,性能受限于缺乏深度信号。其它研究采用了额外的深度估计模块来提高3D体素表示的质量,如图1(a)所示。FB-Occ使用了预训练的深度预测模型和深度感知的反投影模型来辅助生成3D体素特征。然而,大多数基于深度的方法都集中在场景的可视表面上,缺乏对遮挡区域的推断。VoxFormer提出了一个额外的基于掩码自动编码器的模块来考虑遮挡体素,但其繁琐的两阶段结构不利于端到端模型训练。目前的各种方法都表明了深度信号对于SSC任务的重要性。值得注意的是,目前存在两种用于自动驾驶的不同功能的3D占用数据集。一种是仅评估可视表面(图2(b)),另一种则用于场景的完整占用,即SSC任务(图2(a))。本文更侧重于SSC任务,该任务考虑了遮挡的物体或区域。当前的SSC工作大多受到遮挡的影响,使得每个体素特征包含许多模糊性。因此,遮挡体素的占用预测仍面临挑战。
神经辐射场(NeRFs)的引入极大地提高了3D场景重建的性能。SceneRF 为辐射场设计了一种概率射线采样方法,并将其应用于自动驾驶场景的3D重建。最近,一些方法利用提升的3D体素特征进行深度和颜色渲染。由于基于NeRF的3D重建方法主要关注场景的可视表面,如图1(b)所示,SSC任务需要对不可见区域的体素特征给予额外关注。因此,在SSC任务上粗略且直接地应用NeRF模型可能不利于优化隐函数和完成SSC任务。
为了应对这些挑战,本文提出了HybridOcc,这是一种基于多相机的语义场景补全方法。HybridOcc在粗到细的结构中细化了由NeRF表示和Transformer架构生成的混合占用建议。如图1(c)所示,HybridOcc包含两个分支。受SurroundOcc 和Occ3D 启发的Transformer分支,使用可学习的交叉注意力将2D图像提升到3D体素,并从粗到细的结构中逐渐细化3D体素查询。NeRF分支创新性地采用了具有深度监督的体积渲染来预测完整的占用情况。由于自动驾驶场景中的遮挡给NeRF优化带来了挑战,我们提出了占用感知射线采样来优化大型辐射volumes。隐函数通过沿射线在可见和不可见体素之间取占用感知采样点来训练,以服务于SSC任务。在粗到细的结构中,需要仔细考虑每一层的占用先验。改进的NeRF可以推断出遮挡不可见区域的占用情况。将NeRF和粗粒度Transformer预测的二进制占用混合成新的体素查询集,以细化语义占用。综上所述,我们的贡献有三方面:
- 提出了一种新颖的Transformer上下文特征聚合与NeRF深度监督相结合的互补方法。在粗到细的结构中,NeRF表示和Transformer框架生成的混合占用建议得到了端到端的细化。
- 引入了一种新颖的深度监督神经辐射场,该辐射场在SSC任务中考虑了所有可见和遮挡的不可见体素。它将深度信号添加到粗到细的SSC预测框架中,并包括了一个占用感知射线采样策略。
- 大量实验证明了HybridOcc的有效性,其性能优于基于深度预测网络的方法,如FB-Occ和VoxFormer。
一些相关工作介绍
3D语义场景补全可以提供对自动驾驶场景更详细的理解。一些先前的工作是在小规模室内场景中进行的。随着SemanticKITTI数据集和nuScenes数据集的发布,最近迅速提出了针对大规模自动驾驶场景的SSC基准。SurroundOcc和Occ3D分别构建了基于nuScenes的3D占用预测数据集,一个面向密集的SSC任务,另一个仅评估可见表面的占用情况。这些占用方法可以简单地分为两类:基于深度预测构建3D体素特征,以及使用基于Transformer的可学习体素特征聚合。一些方法引入历史帧数据来解决深度预测和遮挡问题。OccFiner提出隐式捕获和处理多个局部帧。此外,一些方法使用NeRF表示来探索占用任务,但它们更侧重于重建而非SSC。我们提出了一种结合Transformer范式和NeRF表示优势的方法,以增强SSC任务性能。
3D场景重建旨在从单视图或多视图的2D图像中建模3D表面信息。早期的重建方法侧重于体素的显式表示,但现在神经辐射场(NeRF)和3D高斯splatting在隐式重建中越来越受欢迎。考虑到NeRF存在渲染速度慢的问题,一些方法在保持渲染质量的同时提高了渲染速度。基于图像特征的隐式重建工作将对象级重建扩展到室内场景,并致力于构建一个通用的隐式网络。一些工作采用粗到细的方法融合多尺度特征,以获得更准确的室内场景3D重建。SceneRF提出了球形U-Net和概率射线采样,以扩展NeRF用于大规模室外场景。值得注意的是,在NeRF范式下的3D重建需要沿射线的采样点集中在3D表面附近,以便更好地渲染颜色或语义。然而,对于SSC任务来说,将辐射场集中在被占用的体素上更有意义。
HybridOcc方法介绍
HybridOcc的总体流程如图3所示。以camera图像为输入,使用图像主干网络提取多尺度摄像头特征。然后,通过由Transformer框架和NeRF表示组成的双分支学习稀疏的3D体素特征。具体来说,Transformer分支通过2D到3D转换模块从多摄像头特征中学习3D体素形状的查询。混合3D查询proposal分别来自Transformer和NeRF,并以粗到细的方式逐步细化。在NeRF分支中,原始的NeRF范式被新的自动驾驶场景占用预测NeRF模块所取代。体渲染占用预测模型直接受深度监督,而不是RGB颜色。语义占用真实值监督多尺度体素语义占用预测。
1)Transformer Branch
粗到细的方法。与SurroundOcc中获得的密集3D体素不同,受Occ3D的启发,我们采用粗到细的方法来逐步细化稀疏体素,如图3上半部分所示。具体来说,每个尺度的3D体素空间的语义占用Ol是通过遵循SurroundOcc的MLP(多层感知机)进行预测的。占用值低于占用阈值θ的体素被定义为空体素。第l层的体素占用Ol作为更高分辨率体素中查询先验位置分布的一部分,如图3中的紫色箭头和紫色方框所示。中的稀疏体素被记录为稀疏查询建议,,其中,并且是通过每个尺度的2D到3D模块从多camera特征中学习得到的。最后,与上采样的进行跳跃连接,并输入到MLP中以预测第l+1层的语义占用。语义占用预测可以表示为:
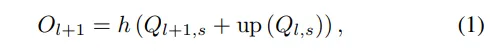
其中,up表示2倍上采样,h(·)表示多层感知机(MLP)。值得注意的是,粗粒度体素V1的初始查询建议是密集构建的。细粒度V2、V3和V4的查询建议的先验空间分布分别由Transformer分支和NeRF分支在每个尺度上的二进制占用率的混合组成。
2D到3D的转换。受近期基于Transformer的多camera的3D感知方法的启发,将体素的3D参考点投影到2D相机上以聚合特征。具体来说,每个对应于查询的3D参考点,都根据给定的相机内参和外参投影到2D特征图上,并执行可变形交叉注意力(DeformAtt)来学习特征:
其中,X是多camera特征,和是通过线性投影获得的权重,是注意力权重且,X(p + ∆pmk)是与2D参考点p相对应的采样特征,∆pmk是与p相对应的学习到的位置偏移量。其他设置遵循SurroundOcc和BEVFormer。最后,通过3D稀疏卷积对体素形状的查询Q进行进一步优化,使得每个体素查询子集都关注于彼此之间的局部信息。
2)Neural Radiance Field Branch
深度渲染监督。传统的NeRF基于光线沿路上采样点的密度ρ来优化连续的辐射场f(·) = (c, ρ),并通过RGB进行体渲染的监督。与之不同的是,我们基于SceneRF设计了一个新的辐射场,而新的NeRF模型具有深度监督以预测3D占用率。NeRF分支如图3底部所示,NeRF分支基于来自图像主干的第l层多摄像头特征Xl(l = 2, 3, 和 4)进行占用率预测和深度渲染。从每个相机的像素坐标中均匀采样I个像素,并沿着通过这些像素的光线采样N个点。这种均匀采样策略与SceneRF一致。然后,按照SceneRF的方法将Xl转换为球面空间以获得,以便每个采样点x可以投影到球面空间上,通过双线性插值检索图像特征向量。最后,将点x的特征和3D位置编码γ输入到隐式表达函数MLP中,以预测体素的二值占用率σ。值得注意的是,NeRF分支仅需要为基于Transformer的粗到细结构提供查询的先验空间分布信息,因此,我们只预测与类别无关的占用率。二值占用率预测的隐式辐射场定义为:
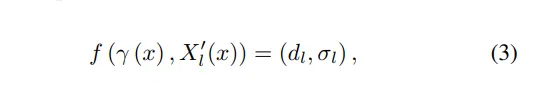
与大多数使用从密度到颜色的体渲染的NeRFs不同,我们尝试从辐射体显式地揭示深度。分别在多尺度图像特征X2、X3和X4上进行深度体渲染,以便多尺度特征可以获得深度监督。对于第l尺度的特征,我们将深度体渲染定义为:
占用率感知的光线采样。先前的研究表明,沿着场景表面附近的光线采样点可以有效地提高渲染效率。图4(a)展示了分层体采样方法,该方法生成了一个沿着光线聚焦于表面的概率密度函数(PDF),以优化采样点。在SSC任务的NeRF模块中,目标是根据可见表面和不可见体素的特征来估计深度,而不是颜色或类别。NeRF分支的隐函数需要完成对整个场景的3D体素二值占用率预测。对于占用率预测的NeRF模型,直观地看,落在非空体素上的光线采样点可以提高渲染效果。因此,我们提出了一种占用率感知的光线采样策略,其中体积Vl的占用率预测结果Ol明确地指导体积中每条光线上的每个采样点,如图4(b)所示。
具体来说,对于每条光线,首先在近边界和远边界之间均匀采样128个点。然后,将这些点投影到3D体素V3中,以查询占用状态O3,并根据占用状态采样32个点。如果占用的点超过32个,则从中随机采样32个点。否则,我们接受所有占用的点,并随机采样其余的点。这种占用率感知的光线采样策略侧重于对场景内占用体素的采样,从而优化二值占用率预测和深度体渲染。
混合查询提proposal。上述NeRF分支具有3D占用率预测能力,以nuScenes数据集为例,首先将每个相机的特征X2、X3和X4独立地划分到3D体素空间中,并通过NeRF模块预测3D体素的二值占用率。然后,在体素坐标中融合多相机结果,并结合相机外参,获得占用率分布。同时,深度监督信号也会更新图像特征,使模型对深度敏感。最后,将NeRF分支隐式预测的占用率与粗粒度Transformer分支在体素Vl-1中显式估计的进行融合。混合查询proposal作为第l级查询,参与2D到3D的过程。混合查询proposal 可以表示为:
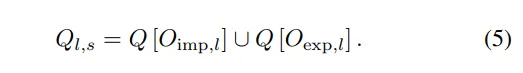
3)损失函数
双分支占用率预测网络是一个端到端的优化模型。模型的总损失β,其中是Transformer分支的显式损失,是NeRF分支的隐式损失,β设置为0.5。多尺度3D体素的监督灵感来源于SurroundOcc。这里也对每个尺度的体素进行监督,以获得粗粒度和细粒度的3D特征。采用交叉熵损失来进行3D语义占用率预测,可以表示为:
其中αi是第l尺度监督的衰减损失权重。高分辨率体素V4的混合查询需要足够的监督信号,对于NeRF分支的损失,使用二元交叉熵损失来进行类别无关的占用率预测,并利用SILog损失来优化深度,深度由激光雷达点的投影进行监督。同时也包括衰减损失权重α,可以表示为:
实验结果对比
在nuScenes数据集上进行了多相机语义场景补全实验,该数据集包含来自6个相机的环绕RGB图像数据和覆盖360度全视场的激光雷达扫描数据。这1000个多模态数据被分为训练集/验证集/测试集,比例为700/150/150。SurroundOcc基于nuScenes数据集提出了一个3D SSC基准,其中包含17个类别的3D占用率。感知范围在X、Y轴上被裁剪为-50m, 50m,在Z轴上被裁剪为-5m, 3m。语义占用率的真实体素维度为200×200×16,体素大小为0.5m。对于Occ3D-nuScenes,感知范围在X、Y轴上被裁剪为-40m, 40m,在Z轴上被裁剪为-1m, 5.4m。最终输出的占用率形状为200×200×16,体素大小为0.4m。
为了进一步证明方法的有效性,在SemanticKITTI数据集上进行了单目语义场景补全实验,该数据集用21个语义类别(19个语义类别、1个自由类别和1个未知类别)标注了自动驾驶场景。数据集包含22个序列,并被分为10/1/11用于训练/验证/测试。感知范围在X轴上被裁剪为-25.6m, 25.6m,在Y轴上被裁剪为0, 51.2m,在Z轴上被裁剪为-2m, 4.4m。真实语义占用率的维度为256×256×32,体素大小为0.2m。
1)Metrics
对于SurroundOcc-nuScenes和SemanticKITTI数据集,我们报告了占用体素的交并比(IoU)作为类别无关场景补全(SC)任务的评估指标,并遵循SurroundOcc的方法,报告了SSC任务中所有语义类别的平均交并比(mIoU)。对于Occ3D-nuScenes,遵循FB-Occ和Occ3D的方法报告mIoU。值得注意的是,Occ3D-nuScenes仅评估可见区域,如图2所示。
2)详细的实施细节
对于SurroundOcc-nuScenes数据集,输入图像的分辨率为900×1600。遵循SurroundOcc采用从FCOS3D模型初始化的ResNet-101作为图像主干网络。图像主干网络产生3级特征图,并采用FPN在主干网络之后生成4级隐藏维度为256的特征图。对于SemanticKITTI数据集,将cam2的图像裁剪为370×1220的大小,并使用EfficientNetB7作为图像主干网络以进行公平比较。对于Occ3D-nuScenes数据集,遵循FB-Occ将输入图像的分辨率调整为256×704,并采用ResNet-50作为图像主干网络。
对于SurroundOcc-nuScenes和SemanticKITTI数据集,将2D到3D空间交叉注意力层的数量分别设置为6、3、1和3。每个级别的空间交叉注意力在每个参考点周围分别使用8、4、4和4个采样点。NeRF模块中隐函数f(·)的MLP结构与SceneRF一致。我们在占用率感知射线采样中每条射线使用32个点。占用率阈值θ设置为0.5。Occ3D-nuScenes数据集评估场景的可见表面,将我们的HybridOcc采样策略简单地设置为概率射线采样。我们在nuScenes数据集上训练了24个周期,在SemanticKITTI数据集上训练了30个epoch,默认学习率为2×10−4。所有模型均在4个NVIDIA A800 GPU上以bs为4进行训练。
3)结果对比
.
#稚晖君的人形机器人发布会
总的来说,发布会中规中矩,甚至有点低于预期了。
没有炸裂的产品,没有足够出彩的技术,更多的是停留在PPT上的东西,跟一般的企业老板开发布会没啥大区别。
这次发布会强调的更多的也是大模型、交互以及AGI的一些东西,提倡的"xx智能"要具体依托和实现的平台是不是人形机器人也无所谓了。
在去年的智元机器人发布会上,人形机器人的腿被做成了类似"Cassie"的反屈膝形态。
当时的解释是"不是为了模仿人而模仿人,是为了更好的完成任务",我就觉得有一点莫名其妙的,毕竟人的膝盖也是正屈膝的,反屈膝怎么就能更好地完成任务呢?应该只是早期的方案将错就错了,或者他们为了凸显特点而故意为之的~
果然,今年发布的新一代人形机器人就将这个形态改过来了,这就跟波士顿动力、特斯拉以及国内大多数的人形机器人一个形态了,算是回到了大众的路线上来。
在运动控制方面,个人觉得其实没有什么进展,采用的方案也是传统方案,所表现出来的运动控制能力也很一般,属于是典型的老太太步行方式,步行过程较为谨慎。
因此,可以看到,智元机器人其实也没有在腿足的控制方面发力,更多的还是在交互、大模型、多模态感知、灵巧手等的设计方面做研发,腿足的控制在未来一段时间内不会有什么大的进步。
不过这也能够理解,毕竟,目前来说,腿部控制得好不好,对于机器人的作业能力并不起决定性作用,更关键的还是感知、手臂和手的操作。
所以,智元主推的一个方向还是基于底盘式的双臂协作机器人,可以没有腿,但是一定要有一双灵巧的手。
可以看到,智元在手的设计上融入了更多的传感器,在手指上嵌入摄像头用于视觉感知这个确实是一种相对较新的方案,结合在头部附近的相机并融合许多现有的视觉方案,应该可以做出一些创新的东西出来。
目前,对于企业来说,能够更快落地的方案才有可能带来盈利。因此,在智元的路线中,人形机器人是一项长期投资的技术方向,但是实际落地的现在一定不是带腿的人形机器人,但是必须是能够实际完成任务的机器人,所以下面这个形态是目前最佳的方案。
这样可以在底盘保证运动稳定的情况下完成更多的任务,结合现在的大模型技术也可以提供更好的交互和任务完成的能力。
硬件本体其实跟之前比较老套的这类家用机器人没什么本质区别了,比如大家所熟知的PR2。
以及一些新兴起来的公司所设计的机器人,比如星尘智能的双臂机器人。
这类底盘(AGV)+双臂形式的机器人应该是目前在大模型等AI技术的加持下想要实现通用机器人的最佳平台了。
智能的感知、灵巧的双手、友好的交互再加上一定的负重就可以完成大部分我们生活中的作业任务,基本能实现机器人辅助人类生产生活的初衷,有没有腿也就没有那么重要了。
当然,本次发布会还是有一些值得期待的亮点工作。
比如即将开源的全面兼容ROS的轻量级机器人操作系统:
比如可以实现"零元购"的开源模块化机器人灵犀X1:
总之,智元机器人本身也是初创企业,在国内这种日新月异的创业环境中,能不能更快地自我造血将会是决定其是否能够活下来的关键。
上述底盘+双臂的机器人可能会是他们推出的第一款能够落地的产品,但是,是否有足够出彩的地方让其能够超越对手而活下去,还需要继续观察,现在机器人创业大环境中泡沫还是大于实际的。
作者:波士顿动力开源了
manipulation在我一个外行眼里demo做的挺不错的,数据集部分有些审美疲劳的,最近好多xx智能公司都在搞,饼有些同质化。
locomotion部分很无聊,走路慢吞吞的,X1的算法摔跤前的动作一眼就是在测RL。摔跤的时候扔枕头的镜头非常真实,以前实验室尝试过扔泡沫,也是一样从来都没接住过,后来就摆烂如下图。
侧面看出智元的办公环境非常好,都能往地上扔枕头,应该非常适宜工作。最后学会了新型的电机转速展示方式,用rpm做单位,数字可以轻松比同行多一位。
作者:喝一口可乐
demo视频很惊艳,但考虑到没有实机直播展示与算法细节,具体多少有落地的可能,要打上很大的问号。比如说unigrasp和最后x1的抓取视频,如果效果真的有那么好的话完全可以直播演示,机器人也拉过来了,但是没有演示,说明ppt的水份可能很大。
另外这个公司描述的业务场景很广阔,硬件仿真部署训练一条龙服务,但实际上能做好其中一个点就不错了。
.
#用QA问答详解端到端落地
UniAD/PARA-Drive/SpareDrive/VADv2Q:端到端模型通常大致分为几种?分为两种,一种是完全黑盒OneNet,模型直接优化Planner;另一种是模块化端到端,即模块级联或者并联,通过感知模块,预测模块以及规划模块之间feat-level/query-level的交互,减少分段式自动驾驶模型的误差累积。
Q:UniAD
整个框架分为4部分,输入multi-view camera imgs,Backbone模块提取BEV feat,Perception模块完成对于scene-level的感知包括对于agents+ego以及map,Prediction模块基于时序交互以及agents-scene的交互完成对于agents+ego的multi-mode轨迹预测,Planner模块基于预测的轨迹以及BEV feat完成路径的规划。各模块均采用Query+Transformer形式进行构建,方便各模块间信息的交互。
UniAD模型架构
- TrackFormer:query由3部分组成,检测query,跟踪query以及ego query。对于检测部分,对于当前时刻,定义当前时刻的det query ,采用DETR检测模型,用来检测未跟踪到的新目标newborn;对于跟踪部分,每一个query对应其跟踪的对应object,track query 的集合长度随着部分object消失而动态变化。 推理过程:following MOTR,训练时对于初始时刻det query采用BEVFormer检测newborn,track query集合为空,后续时刻将当前时刻的det query合并到下一时刻的track query集合中。合并后的query集合即cat(,)与BEV feat送入decoder作交互,输出的query经过QIM与上一时刻的track query作MHA获取时序信息,最终输出更新后的。根据预测score用thre来决定newborn加入以及跟踪目标的消失。
MOTR推理思路
- MapFormer:基于Panoptic Segformer(Q2中作详细介绍),对环境进行全景分割,包含两类things和stuff,things表示可记数的实例比如行人或者车辆,每个实例有唯一独立的id区别于其他实例,而stuff表示不可数或者不定形的实例比如天空或者草原,没有实例id。
- MotionFormer: agent表示交通参与者包括车辆行人等,goal表示交通参与者的目标位置后者轨迹的终点。 MotionFormer共有3种交互:agent-agent(与表示动态agent的query交互),agent-map(与表示静态map的query交互),agent-goal。agent-agent输入track query和motion query,agent-map输入map query和motion query,agent-goal输入BEV feat和motion query(类似于BEVFormer中通过dcn完成query从BEV feat中extract motion context)。 motion query由5部分组成:当前同一时刻的上一层decoder输出的goal point位置pos信息和query context上下文信息,agent当前位置,以及位置pos先验信息scene全局坐标系下的anchor end point和agent自车坐标系下clustered anchor end point(先验pos即从gt中利用kmeans对所有agents聚类)。 decoder最终输出每个时刻所有可能轨迹点组成的multi-mode轨迹即多种可能性的轨迹,training中pre与gt的cost包含3部分,pre轨迹与gt轨迹之间点和点的距离,轨迹运动的物理约束。
MotionFormer
OccFormer:类似于RNN结构,逻辑也类似于NLP中顺序预测下一时刻词元。由个序列block顺序级联,第t个block对应时刻。上一时刻block输出的scene feat 以及sparse agent feat作为此时刻的输入,其中sparse agent feat包括TrackFormer输出的track query和agent position,以及MotionFormer输出的motion query(每个agent只取多mode轨迹中score最大值对应的query),表示未来场景中agent-level的知识。 虚线框中pixel-agent interaction采用mask cross-attention使得 dense scene feat 只专注此时刻的agent,专注聚焦局部的相关agent信息。Instance-level occupancy将refined 与coarse mask agent-instance feat 矩阵相乘,得到包含每个agent的id表示的Occ 。
OccFormer
Q:PARA-Drive
基于UniAD的各模块,重新调整了感知预测以及规划各模块的连接方式。PARA-Drive中各子模块都采用并行同步协同训练的方式,各模块之间的联系只有updated BEV query(同BEVFormer)。测试推理时可去除Map/Motion/Occ模块,推理速度boost。
Mapping:following Panoptic SegFormer,对于输入RGBbackbone提取2D feat,neck提取多尺度特征 (s8/s16/s32),将多尺度特征flatten后cat得到,作为encoder的输入,进行self-attention得到,decoder分为2步,输入为things和stuff query,第1步用DETR方式refine query,引入目标检测的 location label进行监督训练,推理时去除od的head,第2步将带有od知识的refined query输入mask decoder进一步refine和update,用class和seg label进行监督训练,其中mask decoder采用cross-attention实现,输入query(Q)和feat (K/V),attention map经过split得到不同步长尺度的feat,然后通过上采样统一feat尺寸后cat进行mask的预测,weighted value经过FC预测class。
Panoptic SegFormer
Q:SpareDrive
由3部分组成:image encoder提取多尺度多视角2D特征,symmetric sparse perception进行agents和map的感知以及motion planner预测agents和ego的轨迹。
- Image encoder: 输入为多视角图像,encoder提取 mutli-view multi-scale 2D feat,输出特征,其中和分别表示view数量和scale数量。
- Symmetric sparse perception:分为左右并行的两部分,分别为agents目标检测和map。
- agents OD任务:采用DETR范式,输入包括特征 和query,其中query由 instance feat query 和 anchor box query 组成,其中 表示anchor数量,box的11维包括位置坐标,长宽高,角度以及速度;模型结构由 层decoder构成,其中有 层时序decoder,1层非时序decoder。非时序decoder通过deformable cross-attention update ,时序decoder对temporal query和当前帧的query作cross-attention,然后当前帧query作self-attention。时序query即memory queue,用上一帧的refined query取topk来更新,相当于recurrent temporal query,然后warp到当前时刻作cat以及attention。decoder以及时序融合部分详情见 Sparse4Dv2
- map OM任务:采用DETR范式,结构与OD相同。输入query包括instance feat query 和 anchor polyline query 组成,具体来说共设置 条anchor polylines,每条polyline包括 个点,每个点包括 两个坐标。
- tracking 任务:见Sparse4Dv3中Tracking pipeline,OD训练任务无需添加tracking约束。
symmetric sparse perception
- Motion planner:由3部分组成:ego instance initialization, spatial-temporal interactions 和 hierarchical planning selection。
- ego instance initialization: query类似于agents,包括 instance feat query 和 anchor box query 。对于前者初始化采用smallest feat map of font,既包含了环境的上下文信息又避免了采用上述稀疏感知特征而带来的信息缺失,对于后者初始化速度采用上一帧预测的速度,其余status信息利用辅助任务从 中解码出
- spatial-temporal interactions: 逻辑类似于稀疏感知中的时序融合,但有所不同,之前稀疏感知中的cross-attention是当前帧instance与历史帧所有instance的交互,是scene-level,现在的agent-temporal是instance-level,聚焦的是某个instance与自己的历史instance的交互。query依然包括feat和anchor
,memory queue共有 个历史帧时刻,每个时刻包含 个agents的feat+anchor以及1个ego的feat+anchor。最后预测输出周围agents的 条轨迹和 种planning, 表示多个timestamp,此外还预测相应的轨迹得分对应 条轨迹和 种planning - hierarchical planning selection:首先,根据驾驶命令cmd选择对应的轨迹集合;接着,结合周围agents的预测的轨迹和自车的planning轨迹,计算碰撞风险,碰撞风险高的轨迹,得分低;最后,选择最高分数的轨迹输出。
motion planner
Q:VADv2
VADv2
planning transformer输入包括planning token,scene token以及navi token导航/ego status token,通过planning token与scene的交互,最终输出每个action相应的概率,通过概率选出一条action。 通过真实人类轨迹数据集当中action的概率来约束预测action概率,同时保留常见的轨迹冲突代价loss。
- planning token:通过在真实人类驾驶规划action数据集中通过最远距离轨迹采样得到N条具有代表性的action,具体每个轨迹用点表示,然后作MLP得到planning token。
- scene token:输入multi view图片,计算map/agents/traffic element token即提取静态动态不同环境要素pre,同时输入image token补充稀疏pre没有的信息。
- navi/ego token:导航信息和ego status通过MLP也提取相应token。
.
#华为坚定不走VLA路线
WA才是自动驾驶终极方案?
截至今年7月份,搭载华为乾崑智驾的车辆达到100万辆,华为激光雷达的发货量超过100万台,华为辅助驾驶累计里程数达到40亿公里;
到今年8月底,共有28款与华为合作的车型上市,其中包含"五个界"和阿维塔、深蓝、岚图、猛士、传褀、方程豹、奥迪等品牌。
在靳玉志看来,华为之所以能在汽车领域取得这一系列成绩的核心原因,是华为的长期主义战略眼光。
靳玉志表示,华为车BU从2014年开始投资,用了超过十年的时间,投入了大量研发资源,才实现当期盈利。而实现当期盈利后,华为也并未给汽车业务制定非常明确的商业化目标。
按靳玉志的说法,华为这样做,背后的考量是,只盯着商业化,往往会适得其反;反之只要坚持技术研发、满足用户需求,华为汽车业务总有一年能做到当期盈利,也总有一年能实现累计盈利。
在辅助驾驶技术路线的选择上,当头部车企押注VLA(感知语言行为模型),并实现了辅助驾驶能力的快速追赶时,靳玉志却认为,WA(世界行为模型)才是能真正实现自动驾驶的终极方案。
在他看来,VLA是在大模型凭借LM(语言模型)已经演变得相对成熟的背景下,把视频也转化成语言的token进行训练,再变成action、控制车的运动轨迹,这种路径看似取巧,却不是自动驾驶的终极方案。
因此,华为更愿意尝试WA这个目前看起来很难,但在他们看来,更能实现真正自动驾驶的技术方案。
靳玉志认为,WA是直接通过vision这样的信息输入实现控车的大模型,而无需把各种各样的信息转成语言,再通过语言大模型来控制车。在这里,他所说的vision只是一个代表,它可能来自于声音,可能来自于视觉,也可能来自于触觉。
华为也已经基于WA架构,推出了WEWA(云端世界引擎、世界行为模型)模型,将于ADS4.0中部署。
对于辅助驾驶是否应当收费这个问题,靳玉志也毫不讳言:世上根本没有免费的东西,所谓的免费,只是支付方式的转移。
他指出,当前宣传提供免费辅助驾驶的车企,要么只在限定的几年里免费,要么辅助驾驶的价格已经包含在车价里了,要么做得不够好,把用户当作实验品,除此之外,天下根本没有免费的面包。
而且从商业回报的角度,辅助驾驶系统收费,也是合理的。
在整车的使用周期中,辅助驾驶供应商要持续进行迭代、维护、OTA,这些都需要投入成本。而对于买了ADS最初版本的用户,华为每年都在为他迭代升级,用户初期买得贵,但是买的时间越长,体验越好,因此折算下来,华为辅助驾驶的成本并不高。
这种全生命周期管理的理念,华为不仅应用在乾崑智驾上,也应用在鸿蒙座舱上。
鸿蒙座舱不仅基于MoLA架构横向打通各类垂域,也在纵向上打通应用生态、硬件和设备。
靳玉志观察到,当前部分车车企试图通过座舱硬件、软件的解耦,降低整车生产、研发成本,但由此带来的,是用户体验的下降,以及后期维护的高难度。所以无论鸿蒙座舱,还是乾崑智驾,华为都坚定采用全栈模式,让软硬件充分耦合,以此保障用户的体验及后期的维护、升级。
面向未来,华为对辅助驾驶和智能座舱的规划分别是:
2026年让辅助驾驶具备高速L3能力以及城区L4试点能力,2027年进行无人干线物流试点、城区L4规模化商用,2028年争取达到无人干线物流规模化商用;
与此同时,华为也在努力让智能座舱变成"数字保姆",让AI变成AI Agent。
以下是36氪汽车等与华为智能汽车解决方案BU CEO靳玉志的交流,内容经编辑:
问: 当前有一些车企认为VLA是辅助驾驶行业的最终技术路线,甚至可以通过它实现真正的L4,华为对这个问题是怎么看的?
**靳玉志:**走VLA技术路线的企业,认为现在大家是通过Open AI等各种语言大模型,把网上的信息学了一遍以后,将语言、所有的学习转换成LM的方式掌握知识。
而VLA在尝试,在大模型通过LM已经演变得相对成熟的背景下,把视频也转化成语言的token进行训练,再变成action,控制车的运动轨迹。
华为不会走向VLA的路径。我们认为这样的路径看似取巧,其实并不是走向真正自动驾驶的路径。华为更看重WA,也就是world action,中间省掉language这个环节。
这个路径目前看起来非常难,但能实现真正的自动驾驶。
WA就是直接通过行为端,或者说直接通过vision这样的信息输入控车,而不是把各种各样的信息转成语言,再通过语言大模型来控制车。这里的vision只是一个代表,它可能来自于声音,可能来自于vision,也可能来自于触觉。
问:华为认为,未来几年,全球范围内会出现几家真正具备L3、L4实力的玩家?
**靳玉志:**最终能实现自动驾驶的企业有多少家,目前我们不知道,但肯定不多。就像五六年前的xx智能行业非常热闹,赛道里的玩家非常多,但现在已经减少了很多,还会进一步减少。
无论是走向端到端,还是更进一步走向世界模型控制,辅助驾驶在极大程度上,都是依赖于数据驱动,数据驱动本质上比的数据量,是算力、算法。那时,大家会发现,一个公共的智能化平台对这个行业非常重要,因为单独一家企业投入是不划算的。
今天因为英伟达做的算力芯片禁止在中国销售,所以国内才会出现各种各样的算力芯片。
问: 现在华为要匹配一款车型,一般要花多长时间?
**靳玉志:**最快的话,大概在6-9个月。
问: 此前博世提出,自动驾驶就得让用户付费,车企不能免费给,如果是这样,会不会出现,华为乾崑智驾标价7万元,友商标价5万元,或者4万元的情况?
**靳玉志:**首先我认为,这个世界上根本没有免费的东西,我们享受到的看似免费的服务,其实它的商业模式是从另外一个方式收费了,比如通过广告或者其他形式,这就是俗称的"羊毛出在猪身上",羊毛没出在羊身上。这实质上是支付方式转移了。
第二,关于最终的定价,现在有一些主机厂宣传,提供免费的辅助驾驶,要么就是在限定的几年里免费,要么就是辅助驾驶的价格已经包含在车价里了,要么做得不够好,把用户当作实验品,等将来能力提升了再收费,主要是这几种形式,除此之外,天下哪有免费的面包。
第三,关于您说的定多少价,这肯定是合理的。因为辅助驾驶功能卖给消费者,这看似是一次性的行为,但是未来整车的整个使用周期中,辅助驾驶供应商要一直迭代、维护、OTA,这不可能不投入成本。
以华为为例,从ADS 1升级到ADS 4,再到ADS 5,这是大的版本迭代,每年中间还有细微的升级迭代。过去用户买了车以后,除非要保养才去4S店,而现在买的是常用常新的车,隔一段时间就能收到推送,让车变得更安全,让用户有更丝滑的服务体验,这里都是有投入的,而且是长期持续的投入。
买ADS最初版本的人,到现在,华为每年都在给他迭代升级,而且我们从一开始就有对软件、硬件有生命周期管理的概念,所以用户买的第一套硬件,到现在都能升级。而有的用户买的车的硬件,用了两年以后就没法升级了,看起来便宜,甚至是免费的,但过两年用不了了,只能不要了。
这意味着一个好的产品,一定是一开始就设计好了,未来能够持续迭代升级的,用户初期买得贵,但是用的时间更长,体验更好,折算下来它的成本并不高。
问: 有人说华为乾崑智驾搭载的激光雷达越来越多,这是为了撑起溢价,对此您怎么看?
**靳玉志:**本质上,华为是为了更安全,才增加传感器的配置。我们追求是的零伤亡事故,但凡能提升安全性的,我们认为都值得投入。就像尊界S800除了前向激光雷达,我们还增加了两个侧向、一个后向的固态激光雷达。
拿后向固态激光雷达来说,我们是为了泊车更加安全才增加的。后面原本是有摄像头的,还有超声波雷达,但超声波雷达精准度没有那么高,摄像头是靠训练学习才能判断,这是不是障碍物。而且,摄像头拍出来的照片是平面的,没有纵深信息,没有具体信息的概念。
比如车后的墙上挂的是它不认识的水管,还是从墙上伸出的一根长长的管子,摄像头没有学习过的话,是判断不出来的,这样一来,倒车肯定会撞上去。我们以前泊车就遇到过这样的情况。
增加了后向的雷达,系统精度能达到厘米级,从而系统能判断后面是否有障碍物,避免产生剐蹭。
我们还有一些倒车场景倒车。比如买了一辆新车后,春节回农村,向亲戚展示自动泊车,结果后面是农田,开到了农田里。
这说明系统对纵向的识别也有问题。有了固态激光雷达,纵向角度上,系统能探索到这是一个坑,倒车就不会倒进田里。
这些需求都是客观存在的,增加配置,也是由用户的使用场景里面驱动而来,并不是刻意增加。本质上华为还是从用户场景出发,从用户需求出发,我们的追求就是,无论泊车还是城区,亦或高速,辅助驾驶都要更加安全。其他的都是猜测。
.
#面向xx操作的模型架构与演进
近年来,xx智能(Embodied Intelligence)成为学术界与产业界的热门方向。与仅停留在虚拟数据层面的传统智能不同,xx智能强调智能体通过与真实环境的持续交互获得能力提升。作为其中的核心,操作机器人 正在从工厂走向家庭与开放环境。在这一背景下,视觉-语言-动作(Vision-Language-Action, VLA)模型应运而生。它将视觉感知、自然语言理解与动作控制深度融合,使机器人能够理解环境、解析指令并自主执行复杂操作,被认为是通用机器人智能的重要里程碑。
中科院自动化所深度强化学习团队联合北京中科慧灵撰写了题为《面向xx操作的视觉-语言-动作模型综述》的论文,**系统梳理了 VLA 模型的研究进展,聚焦其在机器人操作任务中的应用与挑战。**这一方向,被视为打造下一代通用机器人智能的关键。
论文地址:https://arxiv.org/abs/2508.15201
1 发展历程梳理
根据 VLA 发展过程中的特点,本文将 VLA 模型发展历程划分成3 个阶段:萌芽阶段 ,VLA 概念尚未形成,但已经出现相似功能的模型;探索阶段 ,VLA 模型架构"百花齐放",但逐渐确立了以 Transformer 为核心的可扩展骨干结构;快速发展阶段,模型架构从单层往多层方向发展,并且随着数据积累,多模态VLA 模型已经"崭露头角"。
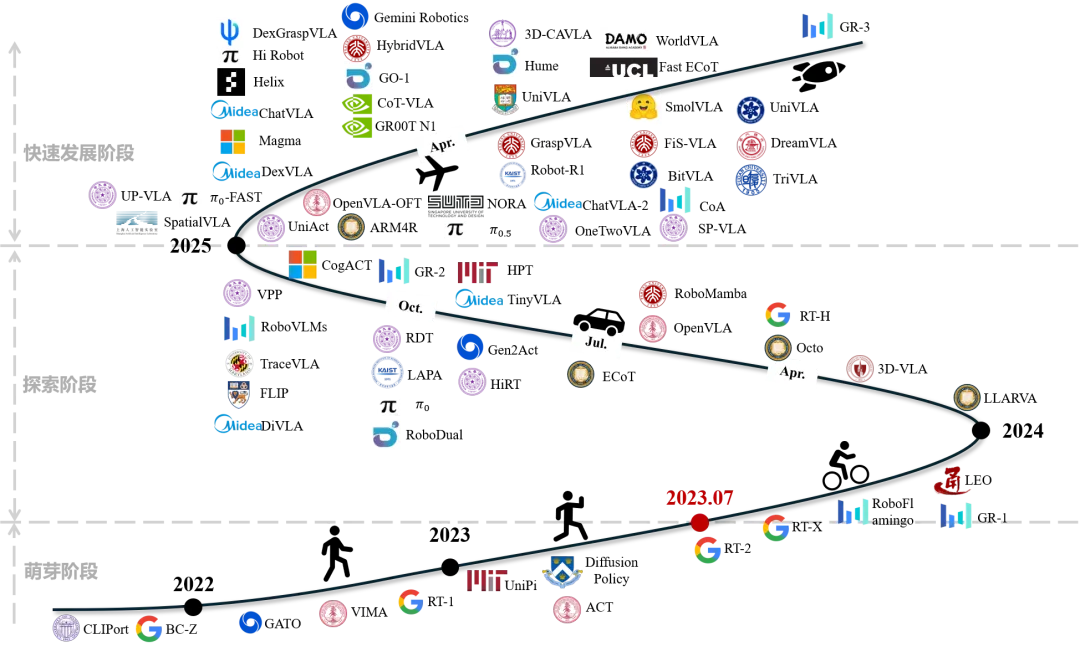
萌芽阶段
早期阶段 VLA 概念尚未提出,但已有一些尝试将视觉、语言与动作联系起来。研究多以视觉模仿学习 和语言标注辅助为主,能够在特定任务上展现效果,但在任务多样性和环境复杂性方面仍显不足。总体上,这一时期的探索为 VLA 的提出奠定了基础。
探索阶段
到 2023 年中,VLA 概念正式提出,研究进入快速探索期。Transformer 架构逐渐成为主流,推动模型在开放场景下展现更强的泛化能力。与此同时,大规模机器人数据集相继构建,跨机器人、跨任务学习成为可能。整体上,这一阶段呈现出"百花齐放"的局面,模型形态多样,但核心方向逐渐收敛。
快速发展阶段
自 2024 年底以来,VLA 模型进入快速迭代期。研究聚焦于解决 泛化性不足与推理效率问题:一方面,模型架构从单层向分层结构演进,使其更好地平衡复杂任务理解与实时动作控制;另一方面,多模态信息(如三维、触觉、力觉)逐渐被引入,进一步提升机器人在真实场景下的适应能力。整体上,VLA 模型已从概念验证走向更具实用性的方向。
2 五大核心维度介绍
VLA 模型结构
VLA 模型通常由三部分组成:观测编码、特征推理和动作解码。近年来,随着任务复杂度的增加,分层推理也逐渐成为重要方向。
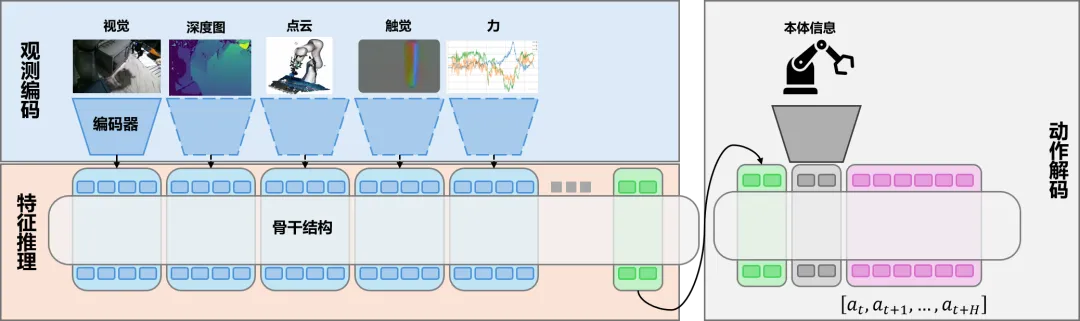
1.观测编码 : 早期方法多采用 CNN 或 RNN 结构,用于图像和语言等单模态特征提取。近年来,研究逐步转向 ViT、跨模态 Transformer 等统一架构,并融合三维视觉、触觉和力觉等多模态信息,以提升环境感知的完整性与鲁棒性;
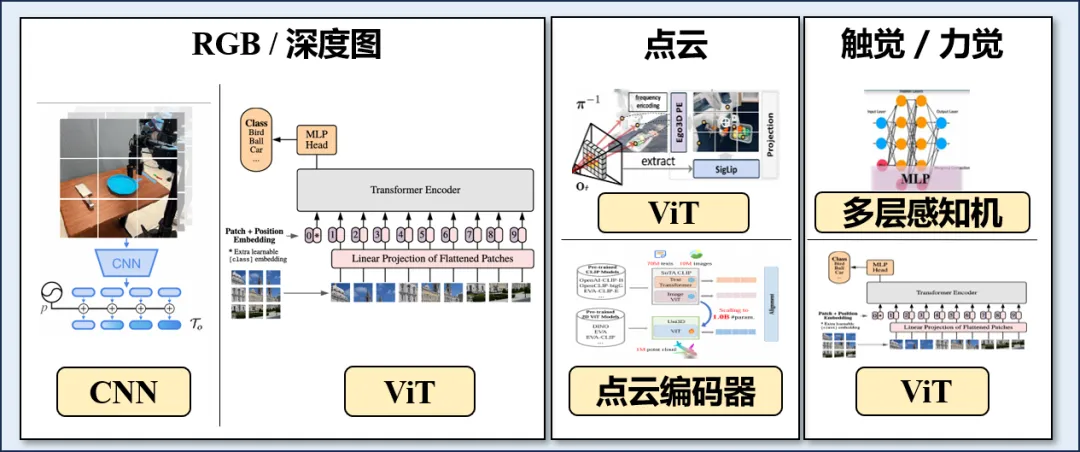
2.特征推理 : Transformer 已成为主流骨干,因其具备良好的可扩展性和跨模态对齐能力。同时,Diffusion Transfomer和混合专家模型(Mixture of Experts, MoE)以及线性复杂度结构(如 Mamba)等新型架构不断被引入,以进一步增强模型的推理能力和计算效率;
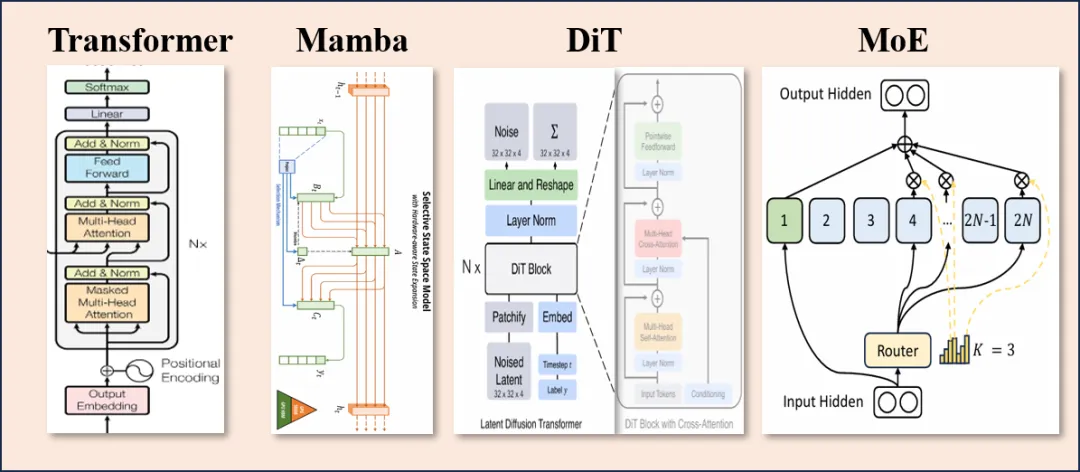
3.动作解码 : 从早期的离散 token 表示逐渐发展到连续控制预测,提升了机器人在真实环境下的操作精度与流畅性。部分最新工作还引入混合动作空间,在长时任务规划与短时动作精度之间实现更好的平衡;
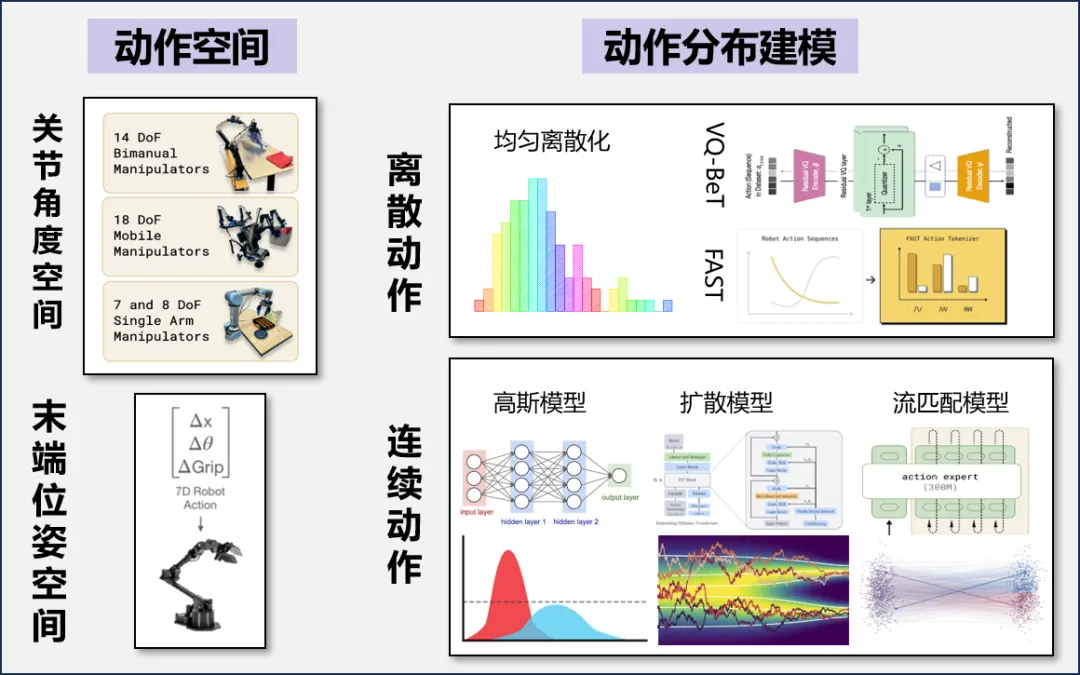
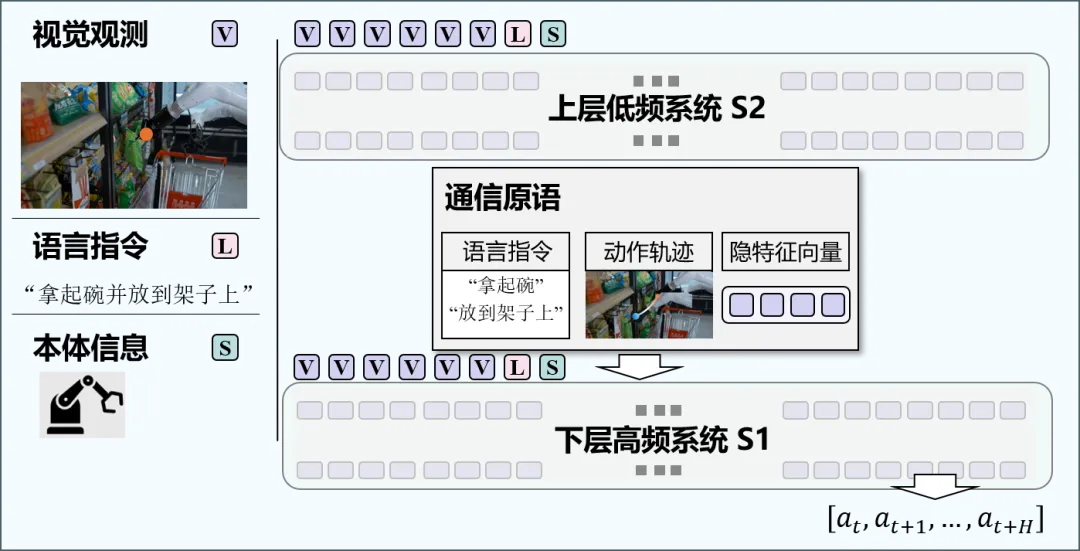
4.分层系统 : 在复杂xx操作任务中,仅依赖单层决策往往难以兼顾高层任务理解和低层实时控制。因此,越来越多的研究探索分层推理架构:上层负责环境建模、任务分解和全局规划,下层专注于高频率的动作控制与短时序执行。这种结构不仅提升了模型的语义推理能力和泛化性,也增强了实际部署中的稳定性和实时性。
VLA 训练数据
数据是 VLA 模型的核心驱动因素。根据来源与特性,可分为以下四类:
1.互联网图文数据 : 互联网中的图像---文本对为 VLA 提供了丰富的视觉与语言先验,能够支持跨模态表征与对齐,使模型具备初步的环境理解与指令解析能力。然而,这类数据与机器人实际操作之间存在显著差距,缺少对动态环境理解;
2.视频数据 : 视频,尤其是人类活动视频,蕴含自然交互的时序特征,为模型学习复杂操作技能提供了重要线索。通过对视频中的行为进行建模,VLA 可以学习到任务分解与动作模式。但视频数据往往缺少精确的动作标注,如何从中提炼可迁移的操作知识仍是挑战;
3.仿真数据 : 仿真环境能够生成低成本、规模化、标注完整的数据,因而被广泛用于 VLA 的大规模预训练和策略探索。其优势在于可控性与多样性,但由于"Sim2Real"鸿沟,仿真学到的能力往往需要额外适配才能在真实场景中可靠落地;
4.真实机器人采集数据 : 通过机器人在真实环境中收集的数据,能够最直接反映传感器噪声、动力学特性与复杂环境因素。这类数据对提升 VLA 的泛化性与可靠性至关重要,但采集成本高昂、效率低,限制了其规模扩展。
本文列举了以 OXE 为代表的 13 种真实机器人采集数据,以及 10 余种互联网图文数据、视频数据和仿真数据,并详细介绍了数据的名称、描述、规模、支持任务、和典型相关方法。
VLA 预训练方法
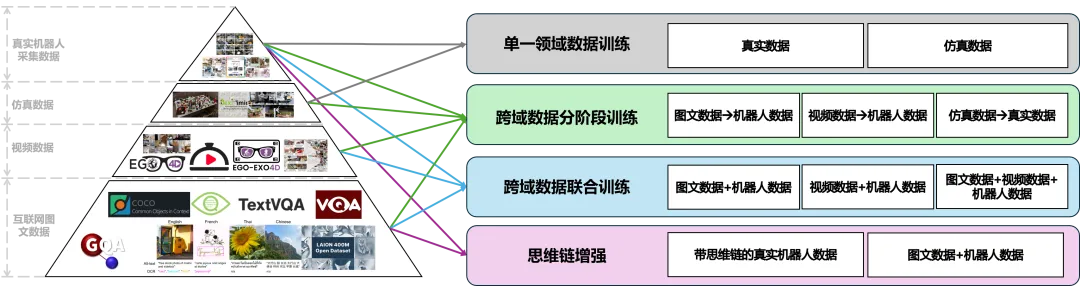
VLA 预训练的目标是赋予模型跨任务、跨场景的通用能力。常见策略包括:
1.单一领域数据训练 : 早期方法主要在单一模态或单一来源数据上进行预训练,例如仅依赖图像---动作对、语言---动作对或视频---动作对。这类方法能够让模型获得初步的感知与动作表征能力,为后续多模态对齐奠定基础。然而,其在复杂任务中的泛化能力有限,难以适应开放环境;
2.跨域数据分阶段训练 : 模型先在规模较大的互联网图文或视频数据上预训练,以学习通用视觉与语言表征;随后再在机器人操作数据上进行二次训练,从而逐步引入动作控制能力。这种"先通用,后专用"的方式,能够有效利用大规模数据先验,并缓解机器人数据稀缺的问题;
3.跨域数据联合训练 : 不同于分阶段策略,联合训练方法在同一框架下同时利用图文、视频和机器人操作数据。通过统一的多模态对齐目标,模型能够在训练中直接学习感知---语言---动作之间的协同关系。这种方式有助于缩小模态间的分布差异,提升模型在跨任务与跨场景下的泛化性能,但对数据规模和训练资源的需求更高;
4.思维链增强 : 近年来,研究者开始探索在 VLA 预训练中引入思维链(Chain-of-Thought, CoT)机制。通过显式建模推理链条,模型不仅能够执行简单的感知---动作映射,还能具备任务分解、逻辑推理与规划能力。这类方法为机器人从"能做"走向"会思考"提供了可能性,被认为是推动通用智能的重要方向。
VLA 后训练方法
后训练旨在利用有限的机器人数据或交互过程,对预训练的 VLA 模型进行进一步优化,以提升其在特定任务与真实环境中的表现。常见方式主要包括:
1.监督微调 : 通过标注轨迹数据对模型进行端到端训练,使其学习到更精确的动作控制映射。这类方法简单直接,能够在特定任务中快速收敛。但其泛化能力依赖于标注数据的多样性和覆盖度,因此往往需要与预训练结合,才能在开放环境下保持稳健;
2.强化微调 : 利用与环境交互数据对模型策略进行优化。强化微调在提升大语言模型和多模态大模型的推理能力方面发挥重要作用,其也被用于VLA后训练,常见方法包括训练强化学习策略生成数据,或直接使用强化学习微调VLA模型。相比监督微调,强化微调能更好地适应动态和获得更高的性能,提升模型的鲁棒性与长期任务完成能力,但也对训练成本和样本效率提出了更高要求;
3.推理扩展 : 并非直接修改模型参数,而是通过增强推理过程提升模型性能。典型方式包括在推理阶段引入评价机制,通过多次推理与搜索辅助任务规划和动作选择。这类方法能够在不增加大量训练成本的前提下,提升模型的泛化与规划能力,是实现快速适应新任务的一条重要途径。
本文列举了 16 种使用监督微调的典型方法、10 种使用强化微调的典型方法及 5 种使用推理扩展的典型方法,并详细介绍了方法的主要贡献、发表刊物与实践。
VLA 模型评估
评估体系是衡量 VLA 模型性能的重要环节。现有评估主要分为三类:
1.基于真实世界评估 : 此类方法通过在实体机器人和真实环境中直接执行任务来测试模型性能,能够最真实地反映模型的执行效果与鲁棒性。其优点在于结果可靠且具有实际参考价值,但由于实验成本高、可重复性差、测试效率低,难以进行大规模实验;
2.基于仿真器评估 : 为降低成本与提升可重复性,研究者普遍采用高保真仿真平台(如 Isaac Gym、MuJoCo等)对 VLA 模型进行测试。仿真器能够提供统一的评测基准,支持大规模实验和跨方法对比,但其与真实世界存在差距,模型在仿真中表现良好并不一定能完全迁移至真实环境。本文列举了包括 SimplerEnv和 LIBERO在内的 7 种常用的仿真器评估环境,并对各个环境进行了详细介绍和总结相关典型方法;
3.基于世界模型评估 : 随着世界模型的发展,一些工作尝试利用学习得到的环境模型进行虚拟评估。在这种框架下,VLA 模型可以在内部环境模拟器中进行快速迭代,显著降低了评估成本并提高了效率。尽管该方法能够支持大规模验证,但其评估的准确性依赖于世界模型的逼真度,目前仍存在偏差与可信度问题。
此外,很多研究还提出多维度评价指标,包括任务成功率、泛化能力、跨机器人迁移性和实时性等。综合评估体系有助于全面刻画 VLA 模型的能力边界。
3 xx操作的 VLA 模型展望
随着 VLA 模型在xx操作领域的快速发展,其未来研究方向与挑战逐渐清晰。本文认为 VLA 模型的演进将围绕以下几个方面展开:
1.泛化推理 **:**VLA 模型在开放环境下执行任务时,仍然面临跨任务、跨场景和跨平台泛化不足的问题。未来研究需要进一步提升模型的推理与迁移能力,使其能够在未知任务和新环境中快速适应。同时,将语言模型的逻辑推理能力与机器人操作结合,发展出更强的任务分解与规划能力,将成为推动 VLA 迈向通用智能的关键。
2.精细操作 **:**当前 VLA 在处理精细化和复杂操作任务(如柔性物体操作、双臂协作)时,仍存在局限。未来的发展方向是融合多模态感知信息(视觉、触觉、力觉、三维空间等),并在模型中建立更精确的动作生成与控制机制,以实现对细微交互的精准建模和执行。这将显著提升机器人在真实场景中的实用性和可靠性。
3.实时推理 **:**由于模型规模庞大,VLA 在真实机器人上的推理速度和执行效率仍难以满足高频控制需求。未来亟需探索高效架构设计(如分层结构、线性复杂度模型)、模型压缩与端云协同推理等方法,以实现低延迟的实时控制。只有解决实时性问题,VLA 才能真正具备在开放世界中持续交互与自主操作的能力。
VLA 模型的发展,正让机器人从"会模仿"走向"能理解、会推理、能行动"。无论是跨任务的泛化推理,复杂任务中的精细操作,还是落地应用所需的实时推理,都在不断推动机器人智能的边界。未来,当机器人真正具备理解世界、精准操作、即时反应的能力时,通用型xx智能将不再只是愿景,而会走进我们的日常生活。
.
#Tier 1一哥博世端到端终于走到量产,还是一段式!
"Robotaxi第一股" 、出海落地No.1------文远知行,这是外界最熟悉的标签。
但在内部,文远给自己的定位一直是通用自动驾驶玩家。
证据是什么?
有,且新鲜出炉:
文远知行刚刚发布一段式端到端ADAS解决方案,年内量产上车。
去年智能车参考介绍过Tier 1巨头博世在文远核心算法能力加持下,终于拿出高阶智能辅助驾驶方案。
这次的模式也完全相同,博世联合文远,一夜间掌握、量产端到端最先进技术范式。
文远一段式端到端,体验如何?
文远一段式端到端有了新的名称:WePilot AiDrive。
重点在这个"AI"上,也是"一段式端到端"的核心含义:从传感器数据输入端,到行车轨迹输出端,一个大模型搞定。
在广州城区道路的实测,文远有意提升了很大的难度。
第一个场景是城中村,叠加的Debuff包括行人、电动车、临时修路:

城中村穿行,考验更多的是规控能力。下面这个场景,重点在感知能力上:
同样是在夜间,对象大逆光的环境下,WePilot AiDrive成功识别了横穿马路的行人,及时避让:

"拟人"还体现在连续顺滑变道的情况下,变道路线规划十分平顺。

这个变道场景其实不难,毕竟整个过程没有后向、侧向车辆逼近,系统没有参与博弈。
"老司机"的博弈能力,更多体现在这个无保护转弯场景:

整个过程不疾不徐,既没有因为避让路口电动车急刹,也没有"瞅准一个机会"猛打方向抢行,全程保持合理跟车距离。
整体行车效率和安全性,系统也有兼顾:

光照条件不理想的隧道里,保持安全跟车距离的同时,还能快速超越慢车。
直观体验上,端到端一直就是老司机,但文远的新系统显然更加"老司机"了:
以前是"先看到再思考",而现在是看见那一刻就已经在动方向盘,路径更短,反应更快,容错率也更高。
和去年量产的系统,不同在哪里
"一段式"是相对之前的端到端模型范式而言的。
端到端的含义是用AI模型替代人工定义规则,直接学习人类成熟驾驶行为,体感上更舒适,也能应对各种各样的corner case。
输入端是传感器数据,输出端是自车行驶轨迹。

但之前的系统,感知一个模型、规控一个模型,再辅以一定的规则兜底。
这是大部分玩家量产端到端最简单、成本最低、最可控的方式------相当于再用保底线的"AEB"思维做智能辅助驾驶。
但带着规则时代的基因,意味着还是解决不了规则时代的核心痛点。
首先是两段式模型间信息传递时,免不了会有数据的变形、损失。
其次,规控模型本身规模不大,很难产生对环境场景的理解能力,更多还是条件反射式地模仿人类开车行为,所以这也是为何有观点认为规控其实根本没必要模型化。
但"规则"就像是端到端开发中令人"上瘾"的止痛药。一开始上少量规则,需要大量数据训练迭代的问题有可能迅速解决......但规则越上越多,最终会发现又搞出一个泛化性极低、驾驶逻辑"前倨后恭"、乘坐体感"前俯后仰"的系统出来。
文远迅速迭代一段式端到端体系,其实是贯彻端到端技术范式的"第一性"原理:
让模型直接学习输入数据与输出轨迹之间的映射关系。
系统性能的迭代提升,主要利用强化学习手段进行训练,而针对性的场景数据,可以来自文远去年已经量产搭载的奇瑞星纪元车型,也可以来自文远的Robotaxi车队,还可以是世界模型。
毕竟文远早就构建起通用AI司机,在感知识别、决策规划等等环节复用算法,无论L2L4、无论乘用货运,基础模型使用相同的数据来训练迭代,后续的仿真测试等等环节,也可以用统一的工具。
所以一段式端到端,是文远探索更进一步的规则+模型的多元技术体系,自证L2+的泛化性、L4的安全性可以共存的落地第一步。
如果文远知行能统一融合L4、L2架构,Robotaxi"地理围栏"范围就有希望逐渐扩大到普通乘用车一样的程度,到这一步实际上地理围栏就已经不存在了,升维降维之争也会彻底终结。
更进一步,通用AI司机的基座大模型,启发的也许不只是自动驾驶...
落地层面,一段式端到端本质其实是"VLA"中的"V"和"A"。
成本上看,VLA中体量最大、占用计算资源最多的是L,意味着车端必须要上千TOPS 级别的计算硬件,难以普及到30万以下的车型。
技术上看,大语言模型在车端有限算力上,很难把延迟做低。
有多难呢?举个例子,6月份英伟达发布了Thor平台的延迟测试报告,用的是内部自研大模型,而且是参数量仅2B的VLM,一通优化后在1000T的ThorX平台上跑出了530ms延迟,不到2Hz,远低于自动驾驶底线要求10Hz左右。
系统延迟降不下来,意味着VLA用在实时性要求极高的智能辅助驾驶系统,对技术实力、成本投入要求极高,更多的车企可能最多做一做"语音控车"这样非刚需功能。
但对于文远和合作伙伴博世来说,最后交付量产的方案,必须是全行业的方案,而不是给某个车企某个车型独供。
眼下,中国市场标配高阶智能辅助驾驶的车型,算全价位全品类,占比还不到20%。
所以文远+博世的一段式端到端,目标不是追赶行业一股脑押注的单点技术突破,而是真正把高阶能力普及到各个价位车型,用L4同源技术尽快推动L2+越过"价值拐点**。
好消息是,这项任务中最大的挑战,已经不在文远"技术"本身了。
.
#马斯克暴论,激光雷达和毫米波雷达对自驾来说除了碍事,没有好处......
最近车圈又上演 "大佬互怼" 名场面!Uber CEO和老马干起来了。啥原因呐,最近全球最大网约车平台Uber的CEO达拉·科斯罗萨西(Dara Khosrowshahi)在接受一个采访中表示:"自动驾驶一定是未来,但现在自动驾驶行业仍存在的路线之争,激光雷达还是纯视觉?从他个人角度来说更支持激光雷达,成本低、安全系数高"。他还表示Uber所有的合作伙伴都有采用多传感融合方案。 尽管达拉发布了"免责声明",表示自己可能会被证明是错的。但对坚持纯视觉路线的埃隆.马斯克来说,肯定是不赞同了。马斯克本人很快在社交媒体上抨击,表示**"激光雷达和雷达因传感器竞争而降低安全性!"**
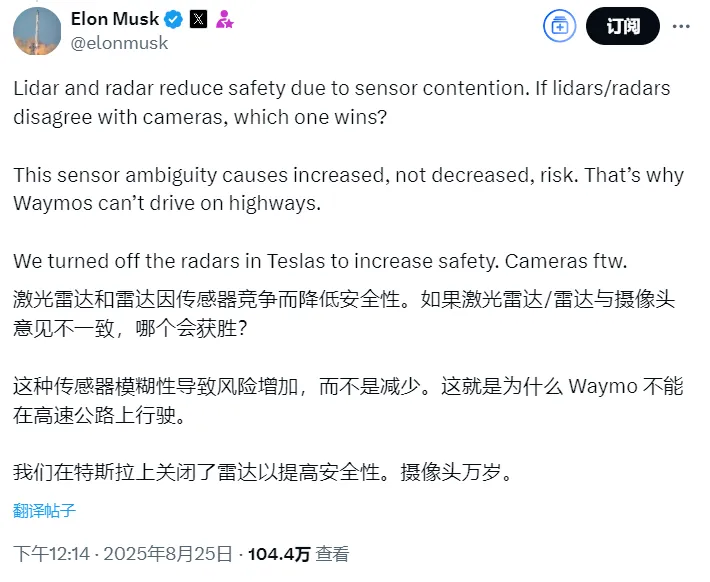
社交网络上,马斯克也顺带cue了下waymo,**"传感器模糊导致风险增加,而不是减少,这就是waymo不能在高速公路上行驶的原因"。**然而,下面的网友也开始反驳,如果传感器模糊、相互竞争,同一类传感器能避免这个问题吗?比如前视和侧视相机?
马斯克是一个极度坚持去冗余设计产品的工程师,但多传感器方案真的冗余没有用处甚至起反作用吗?其实不仅仅是国外。早期国内许多自驾公司也出现过类似的争论,一派坚持低成本、少冗余的纯视觉自驾方案;一派坚持激光雷达所代表的L4级别方案。
国内也有一家重要自动驾驶玩家,对激光雷达方案和纯视觉方案有着独特的见解。从Apollo到萝卜快跑,百度一直坚持激光雷达更能保证行车安全。Robin也发表过类似的观点,指出激光雷达目前已跑通且具有成本优势,纯视觉技术尚处早期,但未来有发展空间。
作为一个深耕自驾的技术自媒体,xx心对此有着自己的看法。但三家之言,你更认同哪个?
从全球三家头部自驾公司看方案优缺点
全球范围内早期入场自驾的三个玩家:waymo、特斯拉和百度在技术路线上存在一定分歧。Waymo和百度坚持基于激光雷达的多传感器融合方案,而特斯拉坚持纯视觉方案。所谓"既存在,即合理",我们不直接下结论。不妨从技术逻辑、商业考量、市场前景、真实测试来分析下每种方案的优劣。
1)特斯拉
2015年前,Telsa和大多车型一样,仍然采用激光雷达测试。但由于使用的Velodyne激光雷达相当贵(接近8w美元),后期就抛弃了相关方案。这里再和大家盘一下特斯拉的方案。2019年4月特斯拉搭载自研FSD芯片,使用8V1R12S的技术方案。2021年7月推出FSD Beta V9.0方案,取消毫米波雷达,转向纯视觉方案。2022年11月推出纯视觉Occupancy方案,传感器未变动。而如今,视觉传感器的配置延续至今,模型转向纯视觉的端到端方案。
马斯克认为,人类仅靠双眼和大脑就能驾驶,因此经过充分训练的AI系统同样可以通过摄像头实现甚至超越人类的驾驶能力。当然,这要求海量的数据作为支撑。特斯拉拥有规模庞大的车队,这些车辆每天能收集到海量的真实世界视觉数据。这些数据用于持续训练和优化其神经网络模型,形成一个数据闭环,使得系统能不断学习和改进,应对各种长尾场景(Corner Cases)。
特斯拉摒弃昂贵的激光雷达,原因之一还有控本。采用成本相对较低的摄像头,有助于降低整车成本,更利于方案大规模普及。
然而,纯视觉方案仍然存在一定的场景难优化问题。虽然马斯克反复强调,自动驾驶本质是机器学习与AI的问题,不是传感器问题;竞争力体现在算法与数据规模上,而非传感器堆砌。但事故的发生,依然和汽车获取的"数据不足"有关!
2019年佛罗里达州,Model S开启Autopilot状态下撞上停靠的SUV,致1死1伤。Autopilot未能识别前方停靠车辆和障碍物。2023年宾夕法尼亚州,特斯拉在Autopilot状态下撞上停止的卡车(长尾效应没有解决)。2025年特斯拉Robotaxi试运营中低速擦碰停放车辆,纯视觉系统在复杂场景(如昏暗小巷、光线不足)下可能出现感知缺陷或误判。
特斯拉的数据规模非常大,但即使在数据量堆积的情况下,依然有几类问题是特斯拉方案头疼的,比如恶劣天气与光照条件、准确的距离和空间感知、太重算法和数据等。这类问题同时存在于早期的分层感知规划模块和现在的端到端方案。
视觉在3D环境感知中,存在天生的不足,结合激光雷达,可以有效在视觉失控的情况下做一个补充。
2)Waymo
Waymo 是 Google 旗下的自动驾驶技术公司,服务于网约车业务。和特斯拉方案不同,Waymo 采用典型的 "多模态" 方案(视觉+雷达+激光雷达),硬件传感器的方案设计使其拥有"最安全的自动驾驶出租车解决方案"。早在 2020 年,Waymo 就在此启动了商业化的无人驾驶出租车服务;在2024 年,Waymo 将业务扩展到了旧金山湾区和洛杉矶;2025年初,扩展到了南部德州的奥斯汀。
目前约1500辆无人出租正在运营。从划分等级上来看,Waymo是L4级别。这一点国内许多自驾公司连L3都还没完全做到,他们是怎么做到的?
Waymo第六代自动驾驶系统采用13V + 4L + 6R的多传感器融合方案,通过三种互补的传感模式实现 360 度无死角感知,最远可识别 500 米外的路况。和特斯拉一样,Waymo也关注数据和算法两个层面。数据上Waymo采用逼真的仿真器生成各类case,算法上中多传感器融合,这两点和特斯拉都有较大差异。从近几年Waymo产出的论文或开源的数据集可以看出,无论是模块化还是端到端模型,这家公司一直在多模态感知中突破。
值得注意的是,Waymo出租车不仅仅只行驶在路况好,人员稀少的区域。在洛杉矶最繁荣的圣莫尼卡、好莱坞、下城,状况比较复杂的情况下也保持良好性能。今年以来,Waymo每周提供的付费服务量从 2 月份的 20 万次增长到 4 月底的超过 25万次,平均每辆车每天约 24 次。足够的安全,用户才能买单。这也是Waymo为什么受到青睐的原因。
相比于特斯拉,Waymo出现重大事故的概率较小,更多的是人为引诱破坏。比如2025年,许多抗议者通过App引诱车辆至现场后进行打砸烧。
3)百度
百度自2013年开始布局自动驾驶领域,2017年推出全球首个自动驾驶开放平台Apollo(阿波罗),2021年推出自动驾驶出行服务平台萝卜快跑。经过十余年压强式、马拉松式地研发与投入,萝卜快跑已成为全球最大的无人驾驶出行服务商。作为百度Apollo(阿波罗)生态的重要组成部分,萝卜快跑承载了百度在自动驾驶领域的技术积累、创新实践和落地应用。
**萝卜快跑的自动驾驶车辆则采用多传感器融合方案,结合激光雷达、摄像头、毫米波雷达和超声波雷达,以实现L4级自动驾驶能力。**典型车型(如Apollo RT6)的传感器由4L12V5R-12S组成,存在一定的安全冗余,多传感器融合方案对复杂和突发的场景也能应对自如。
2024年5月,百度Apollo发布了全球首个支持L4级自动驾驶的大模型Apollo ADFM以及第六代无人车。其中,Apollo ADFM基于大模型技术重构自动驾驶,可以兼顾技术的安全性和泛化性,做到安全性高于人类驾驶员10倍以上,实现城市级全域复杂场景覆盖。萝卜快跑第六代无人车则全面应用"Apollo ADFM大模型+硬件产品+安全架构"的方案,通过10重安全冗余方案、6重MRC安全策略确保车辆稳定可靠。
目前萝卜快跑已在全球15个城市落地,全无人自动驾驶车队已驶入北京、深圳、武汉、重庆等多个城市。截止目前,萝卜快跑总服务订单量超过1100万次,总行驶里程超过1.7亿公里,未发生过重大安全事故。过去两年的数据显示,萝卜快跑实际车辆出险率仅为人类驾驶员的1/14。"无人车,打萝卜"正在成为更多用户出行的新选择。
萝卜快跑还积极拓展海外市场,力求将竞争优势扩展到中国大陆以外的地区。2024年11月29日,萝卜快跑获批香港首个自动驾驶车辆先导牌照,这也是萝卜快跑获得的首个右舵左行地区自动驾驶测试牌照,萝卜快跑开启面向全球的业务拓展。2025年3月28日,萝卜快跑宣布与迪拜道路交通局(RTA)签署战略合作协议,在迪拜市区开展无人驾驶规模化测试和服务,双方计划,将在迪拜部署超过1000台全无人驾驶汽车。这也是萝卜快跑首次在中国以外的地区开展无人驾驶规模化测试和服务。当天,萝卜快跑宣布与阿联酋自动驾驶出行公司Autogo达成战略合作,双方将充分发挥各自优势,共同为阿联酋的另外一座城市阿布扎比提供无人驾驶出行服务。未来,双方将致力于持续扩大车队规模,打造阿布扎比地区规模最大的无人车队。
今年5月,萝卜快跑在迪拜开始了开放道路验证测试,目前正在探索更多海外城市。
7月15日,萝卜快跑与全球最大的移动出行服务平台Uber建立战略合作伙伴关系,将数千辆无人驾驶汽车,接入Uber全球出行网络,为世界各地的用户提供人人可用且稳定可靠的无人驾驶出行服务。年底前,双方将率先在亚洲和中东市场部署萝卜快跑第六代无人驾驶汽车。服务上线后,乘客可通过Uber App,呼叫到由萝卜快跑提供服务的无人驾驶车辆。
从Uber和萝卜快跑的合作来看,多传感融合方案虽然存在一定安全冗余,但相比于生命安全,市场"更容易接受"!毕竟多一个传感器,就是多一个数据源和保障。
激光雷达多传感融合 vs 纯视觉方案
作为一个技术自媒体,更愿意从技术角度来剖析纯视觉和激光雷达方案的优缺点(关于价格对比,后面会有章节铺开)。这里我们不妨从数据、算法、性能和成本几个模块展开。
数据上层面上,基于激光雷达的多传感器融合方案需要前视雷达+周视雷达,相机、毫米波雷达等;而纯视觉方案则只需要相机和一些超声波雷达。3D毫米波雷达主要作为辅助雷达用于测速,点云相对稀疏,噪声多。但最近兴起的4D毫米波雷达已经弥补这类缺陷,在成像上更胜一筹。而激光雷达的优势在于空间感知能力非常强、测距长,能准确locate目标的位置,这一点是上述其它传感器做不到的。目前车载主激光雷达,大多采用前向固态雷达,结合视觉等其它传感器,一起完成感知规划任务。
算法层面上,基于点云视觉融合的模型上线要高于纯视觉模型方案,特别是一些极端天气、光照、截断等场景下的感知规划任务。即使视觉不工作,激光雷达也可以弥补这个缺陷。近3年,我们也和多家自驾公司的技术负责人沟通过相关方案,兜底大多依赖毫米波雷达(比如传统3D毫米波或新兴的4D毫米波雷达)、激光雷达等传感器。长尾问题的解决,需要大量的数据支持,这一旦国内很多公司无法保证。数据不够,传感器来做弥补,才能保证安全。其实这一点可以显而易见的考虑到,如果视觉漏掉了一个截断或非常规形态/颜色的目标,激光打在目标上形成点云,也是一大坨unknown。无论如何,某个传感器发现了目标,兜底的逻辑上也不会让它硬撞。
性能上,在nuScenes、Waymo等数据集上的BEV感知(比如3D检测)、Occupancy、端到端任务上,加持激光雷达数据的方案,多模态融合方案要高于纯视觉5个点甚至10个点不止。奇装异服的person、截断的目标(比如car、truck)、非通用几何障碍物(比如树木的占用检测等)、强光场景、弱光场景、夜晚场景等。多模态感知方案,几乎可以不受影响地工作。
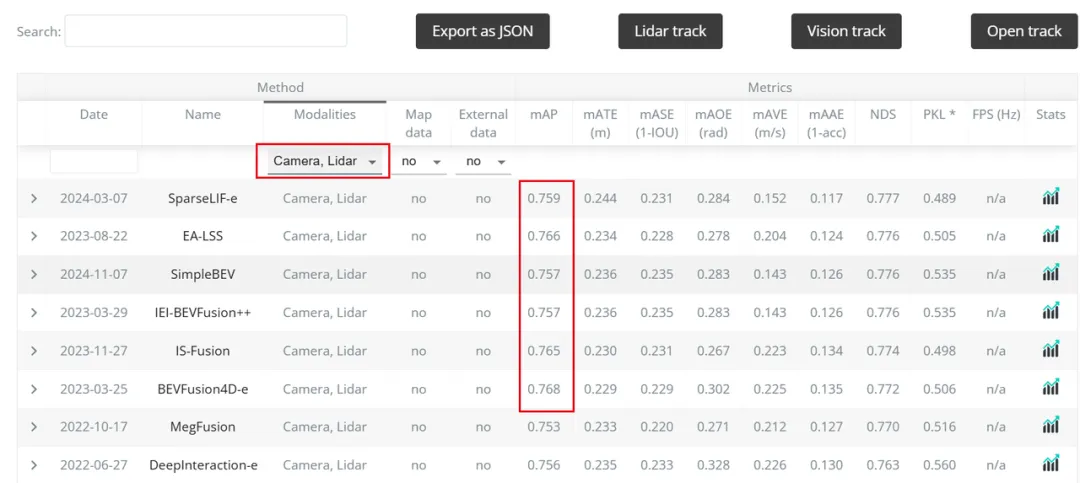
下图是nuScenes中3D检测任务性能对比,上面为纯视觉性能,下方为Lidar+Camera。
成本上,面向OEM的Lidar目前基本可以做到千元或几千元级别,在中高端车型上装配的较多。比如理想的L7-L9,华为M7-M9还有小米汽车的一些车型。十年前Velodyne一颗64线激光雷达卖8万美元,今天萝卜快跑第六代无人车4颗远距激光雷达成本只要3.5万元人民币。
在技术不断突破和供应链越来越强大的条件下,价格最终不会是壁垒,安全的驾驶才是市场真正关注的。即使纯视觉成本较低,但是安全面前,增加的成本实在不算什么。
为什么激光雷达work?有哪些自驾产品采用?
1)智能驾驶为什么需要激光雷达呢?
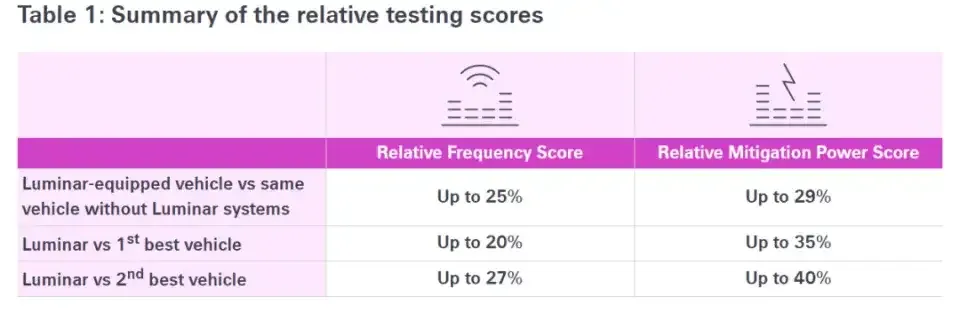
国际保险巨头瑞士再保险(Swiss Re)的测试显示,配备激光雷达的同款车型相较于未配备版本,可避免25%的碰撞事故,事故影响缓解能力提升29% 1。所以,激光雷达切实地在保证智能驾驶的行车安全。
早期一个上万美元的纯机械式激光雷达,确实谈不上性价比,但现在千元级别的激光雷达已经可以规模化生产。激光雷达的降本速度着实太快,十年期间,成本从Waymo使用的全机械式激光雷达一个大几万美元,到现在的半固态200美元左右,成本降低了几百倍。
那么激光雷达到底如何智能驾驶的行车安全?这要从激光雷达的原理说起,作为主动传感器,激光雷达通过激光器发射激光,接受反射信息,计算光往返的时间,进而判断障碍物的距离。而摄像头是被动的,接受外部光线成像。这种原理上的特性,也让激光雷达成为车辆安全上必要的冗余。
超长感知距离:为高速场景预留安全冗余
车辆在高速行驶时(如高速路 120km/h),需要足够的 "预判距离" 来应对突发情况 ---发现前方障碍物时,一般需要 1.5 秒反应时间 + 2 秒刹车时间,车辆至少需覆盖 120 米的感知范围。激光雷达的硬件设计恰恰满足这一需求:当前主流车规级激光雷达(如速腾聚创 M1、禾赛 AT128)的最远感知距离普遍达到150-200 米,禾赛最新的ATX甚至可探测 300 米外的目标。超长感知能力的背后,是激光发射器的 "高功率激光二极管" 与接收器的 "高灵敏度雪崩光电二极管(APD)" 共同作用的结果:高功率激光能穿透更远的空气介质,而 APD 可将微弱的反射光信号放大数千倍,即使 150 米外的小目标(如路边护栏的金属连接件)反射的激光,也能被精准捕捉。
对比来看,摄像头的最远有效感知距离受光照和物体对比度影响极大 --- 晴天时识别远处车辆的距离约 80-100 米,雨天或夜间则骤降至 50 米以内;毫米波雷达虽能探测 200 米以上,但仅能识别 "有反射的物体",无法区分是车辆还是路牌。而激光雷达的远距离探测能力,能在高速场景中为车辆预留更多决策时间,比如当 150 米外出现异常情况时,激光雷达可提前 3 秒完成识别,让自动驾驶系统有充足时间调整车速或避让,避免因感知距离不足导致的追尾事故。
传感器帧率:实时感知为安全保驾护航
自动驾驶车辆处于持续的运动过程中,而如今智能驾驶车规芯片的算力也越来越大,复杂的驾驶场景对智能驾驶的实时性要求也越来越高,而感知算法的上限也受限于传感器的帧率上限。主流车规级激光雷达的帧率普遍达到10-20Hz(即每秒生成 10-20 帧三维点云),部分针对城市复杂路况的产品甚至提升至 30Hz,可以和摄像头的帧率保持一致。
早期的机械旋转式激光雷达帧率受电机转速限制(通常 10Hz);如今的半固态激光雷达(如 MEMS 微振镜式)通过 "微机电系统控制镜片高频摆动",扫描速度大幅提升,可轻松实现 20Hz 帧率。激光雷达的越来越高帧率硬件特性,让其在动态场景中始终保持 "实时感知",避免因信息滞后引发事故。

恶劣环境适应性:硬件级抗干扰设计突破场景局限
智能驾驶无法规避暴雨、大雾、强光、隧道明暗交替等 "极端场景",而激光雷达的硬件设计从源头解决了这些环境难题。 其核心在于激光波长选择 与光学系统防护两大硬件特性:
- 波长选择:当前主流激光雷达采用 905nm 或 1550nm 的近红外激光波长 ------905nm 波长的激光对雨雾的散射率仅为可见光(如摄像头依赖的 400-700nm 波段)的 1/5,即使暴雨天气,激光也能穿透雨帘实现有效探测;1550nm 波长的激光则具有更强的抗干扰性,不仅能穿透浓雾,还能避开阳光中的红外干扰(阳光中 1550nm 波段的能量仅为 905nm 的 1/10),在强光暴晒的正午,也不会出现 "信号饱和"。
- 光学防护:激光雷达的发射 / 接收窗口采用 "疏水性镀膜玻璃",雨水落在表面会形成水珠快速滑落,不会像摄像头镜头那样形成 "水膜" 遮挡视线;部分产品还内置 "加热除雾模块",在低温大雾天气,可通过加热玻璃表面,防止雾气凝结,确保激光信号正常传输。
实际测试数据显示:在降雨量 20mm/h 的暴雨环境中,激光雷达的测距精度仅下降 8%-12%,仍能准确识别 50 米内的行人;在能见度 50 米的大雾中,其有效探测距离保持在 80 米以上,而摄像头此时已基本无法识别前方物体,毫米波雷达也因雾气中的水汽反射出现 "虚假目标"。这种硬件级的抗干扰能力,让激光雷达在恶劣环境中成为安全的最重要保障。

空间感知:3D建模构建 "全局认知"
智能驾驶天然的需要对现实世界的空间理解,不仅要知道目标 "有多远",还要知道目标 "有多高""有多大",而激光雷达的硬件设计天生具备三维的感知能力。
比如在城市路口,激光雷达可通过三维点云判断:前方 5 米处有一个高 1.2 米的物体(儿童),正以 1.5m/s 的速度横穿马路;右侧 3 米处有一个高 1.8 米的物体(成人),站立不动;远处 10 米处有一个高 2.5 米、宽 1.8 米的物体(SUV),正以 30km/h 的速度直行。基于这些三维信息,决策系统能快速判断:需紧急刹车避让儿童,同时无需担心右侧成人与远处 SUV,避免了 "误判避让" 导致的交通混乱。这种三维空间感知能力,是视觉感知(2D推理3D信息,易出现误差)和毫米波雷达(仅能提供距离与速度,无高度信息)无法替代的,也是自动驾驶实现 "精准决策" 的核心基础。

从超长感知距离的 "安全冗余",到帧率不断提升带来的的 "实时感知",再到恶劣环境适应性的 "抗干扰保障",再到空间感知能力的 "三维认知",激光雷达的核心硬件参数都精准命中了自动驾驶的感知痛点。这些硬件特性并非孤立存在,而是相互协同:高帧率确保动态捕捉的实时性,高稠密点云提供细节支撑,三维感知构建全局认知,再结合恶劣环境下的稳定表现,共同形成了激光雷达的 "可靠工作能力"。
随着硬件技术的持续迭代 --- 比如通过 "硅光芯片" 进一步降低成本、通过 "全固态设计" 提升可靠性、通过 "多波长融合" 增强抗干扰性,激光雷达将在自动驾驶中发挥更核心的作用。未来,当激光雷达的最远感知距离突破 300 米、帧率提升至 50Hz、点云密度达到 2000 点 / 平方米时,自动驾驶车辆将具备更强大的 "环境感知能力",为安全出行提供更坚实的保障。而这一切的起点,正是激光雷达硬件与自动驾驶场景需求的深度契合 --- 这也是它之所以能稳定 "work" 的根本原因。
2)有哪些车型搭载激光雷达?
今年某纯视觉方案车型在高速 NOA 状态下因感知延迟导致 3 人死亡的重大事故,也暴露出 L2 级辅助驾驶的致命缺陷:系统仅提前 2 秒预警,远低于人类 1.5 秒的应激反应时间。而搭载激光雷达的蔚来 ET9 在类似场景下,AEB 触发速度上限提升 50%(夜间 80km/h→120km/h),这正是 L3 + 自动驾驶必须具备的物理级安全冗余。
**因此业内高配版的新能源车型基本都搭载了激光雷达,只有低配的车型才选择纯视觉方案。**国内头部的激光雷达厂商禾赛和速腾聚创已经量产了多款车型。
2025年比亚迪旗下十余款车型将搭载禾赛激光雷达陆续上市。比亚迪在智能化战略发布会上宣布,将全系搭载 "天神之眼" 高阶智驾系统。其中天神之眼 A(DiPilot 600)为高阶智驾三激光雷达版,传感器组合包括3颗激光雷达 + 5颗毫米波雷达 + 11颗摄像头(包括双目前视、4环视、4侧视、1后视摄像头) + 12颗超声波雷达。天神之眼 B(DiPilot 300)即高阶智驾激光版,传感器组合包括1颗激光雷达 + 5颗毫米波雷达 + 12颗摄像头 + 12颗超声波雷达,像已上市的 2025 款汉 DM-i 和汉 EV 就搭载了 DiPilot300,该方案采用单激光雷达或双激光雷达方案,算力平台为单 Orin-X 芯片,功能上支持高速和城市 NOA 。
今年3月,奇瑞汽车旗下新能源品牌 iCAR 量产车也宣布采用禾赛 ATX 激光雷达。零跑汽车的全新 B 系列车型 --- 零跑 B10,也成为行业内首个将带激光雷达硬件的高阶智驾产品下探到 12 万级的车型,其搭载了禾赛的远距离探测激光雷达。理想汽车于 7 月 29 日上市的理想 i8,搭载下一代辅助驾驶架构 Mind VLA,换装全新的禾赛 ATX 激光雷达,配备英伟达 Drive AGX Thor-U 智驾芯片,提升了车辆的辅助驾驶能力 。此外禾赛科技的 AT 系列激光雷达此前已成功搭载于长城魏牌蓝山、高山等车型。在今年5月,长城旗下的品牌欧拉汽车搭载禾赛激光雷达的相关车型预计于今年内量产并逐步交付 。
速腾聚创同样在车载激光雷达市场表现出色,以 519,800 台的年销量,登顶 2024 年全球乘用车激光雷达市场销量冠军,截至 2025 年 3 月底,比亚迪、极氪、上汽智己等全球 30 家整车厂及 Tier1 达成合作,定点车型数量超百款 。其中比亚迪的 2025 款海豹及 2025 款汉,广汽埃安推出的第二代 AION V 及 AION RT,吉利银河、极氪等均搭载了速腾聚创激光雷达 。在 今年2月发布的全新极氪 001,全系 4 款车型均升级标配 RoboSense 速腾聚创 M 平台激光雷达,该激光雷达基于自研芯片技术驱动,具有体积小、稳定可靠、高性能等优势,拥有 120°×25° 的宽广视场,能帮助车辆看清 200 米内的真实三维世界,为全新极氪 001 实现覆盖泊车、高速和城市的全场景智驾提供了强力保障 。早在 2021 年 7 月,广汽集团高端智能电动车独立品牌埃安全球发布应用速腾聚创第二代智能可变焦激光雷达,后续如 2022 年 1 月上市的埃安 AION LX Plus 搭载 3 颗速腾聚创第二代智能固态激光雷达,今年 4 月预售的埃安昊铂 Hyper GT 以速腾聚创 M 系列激光雷达为核心,打造基于多传感器融合感知的全域高阶智能驾驶系统 。
激光雷达能解决哪些视觉难处理的问题?
上面已经说了激光雷达方案的优势,这里我们详细铺开下激光雷达多传感器融合相比于纯视觉方案的优势和技术参数。
1)激光雷达
- 高精度的3D环境感知:
- 激光雷达通过发射激光束并测量反射时间,直接获取周围环境的3D点云,能准确还原物体的形状、距离和空间位置。
- 精度可达厘米级,尤其在测距和深度感知上远超摄像头。
- 不受光照条件影响:
- 激光雷达是主动传感器,不依赖环境光照,在夜间、强光、逆光、隧道出入口等视觉容易失效的情况依然稳定工作。
- 不会出现摄像头常见的过曝、欠曝、眩光等问题。
- 测距准确,深度信息可靠:
- 可以直接获取深度信息(距离),无需像视觉方案那样依赖立体视觉或深度学习网络预测深度。
- 避免了纯视觉方案中因误判距离导致的"幽灵刹车"或"漏检障碍物"问题。
- 对静态和动态物体识别更鲁棒:
- 点云数据能清晰区分地面、障碍物、行人、车辆等,尤其在复杂城市道路中对静止障碍物(如锥桶、故障车)识别更可靠。
- 纯视觉在缺乏运动线索时难以判断静止物体是否构成威胁。
- 多传感器融合的基石:
- 激光雷达常与摄像头、毫米波雷达融合,提供互补信息,提升系统整体鲁棒性。
- 在L3及以上高阶自动驾驶中,激光雷达被视为关键冗余传感器。
2)纯视觉
对于纯视觉方案来说,在3D感知、深度估计和光照异常、天气异常下存在固有短板:
- 深度感知依赖算法推测
- 摄像头是被动传感器,获取的是2D图像,深度信息需通过双目立体视觉或深度学习模型估计,误差较大。
- 在远距离或纹理缺失场景中,深度估计容易失效。
- 受光照和天气影响严重
- 强光、逆光、夜间、雨雾等条件下,摄像头容易出现过曝、反光、低对比度和模糊等问题,纯视觉模型在极端光照场景下无法有效感知。特斯拉在强光下曾多次出现"将白色卡车误认为天空"的事故。
- 对静止障碍物识别能力弱
- 纯视觉系统通常依赖物体的运动来判断其存在和距离,对静止物体(如路边故障车、施工锥)容易漏检。
- 这是导致部分自动驾驶系统"幽灵刹车"或追尾的常见原因。
- 泛化能力依赖海量数据
- 纯视觉方案高度依赖深度学习模型,需在各种极端场景下进行大量标注和训练。
- 面对corner case时,模型可能无法正确响应。
- 缺乏物理冗余,安全性存疑
- 纯视觉系统一旦摄像头失效(如被污损、遮挡),整个感知系统可能崩溃。
- 缺乏独立的测距手段,难以满足功能安全要求。
|--------|--------------|---------|
| 维度 | 激光雷达优势 | 纯视觉劣势 |
| 测距精度 | 高,直接测量 | 低,依赖推测 |
| 环境适应性 | 强,全天候 | 弱,怕光怕雾 |
| 静止物体识别 | 可靠 | 易漏检 |
| 安全冗余 | 有,多传感器融合 | 单点故障风险高 |
| 成本 | 成本可控,下降中 | 低 |
| 技术成熟度 | 已在Robotaxi验证 | 仍在迭代优化 |
激光雷达一直被诟病的雨雾天气性能不佳的问题,也正在被一点点解决。随着激光雷达的成本不断降低,边界场景的逐渐扩展,未来激光雷达的作用将会越来越大!
从政策和安全角度上激光雷达更适合当下
在自动驾驶技术持续演进的当下,激光雷达凭借其独特优势,在政策导向与安全需求的双重驱动下,成为适配当前自动驾驶发展的关键技术。
政策推动激光雷达广泛应用
政策层面为激光雷达的发展与应用开辟了广阔空间。工信部等四部门联合开展的智能网联汽车准入和上路通行试点工作,明确了 L3、L4 级别智能驾驶汽车的商业化路径。这其中,以激光雷达为主导的数据感知系统成为智能驾驶的重要支撑 。激光雷达作为汽车深度感知的关键设备,随着 L3、L4 级智能驾驶政策落地,市场需求迎来进一步增长。
从全球范围的法规来看,激光雷达的重要性愈发凸显。美国交通部国家公路交通安全管理局(NHTSA)规定,到 2029 年 9 月,所有乘用车和轻型卡车都要标配含行人 AEB 的 AEB 系统,要求车辆在特定高速下能有效刹停,这一标准仅靠传统摄像头难以满足,激光雷达的高精度探测能力成为满足该要求的关键,或将被强制标配于 AEB 系统中 。欧洲、日本也有类似法规,要求不同程度地强制安装 AEBS 系统。
国内相关政策同样在推动激光雷达的应用。2025 年 2 月起草、4 月公开征求意见的《轻型汽车自动紧急制动系统技术要求及试验方法》,将代替现行国标,从 "推荐性国标" 升级为 "强制性国标"。新国标在覆盖范围、激活速度和误检 & 漏检等方面全面升级,对传感器精度、探测距离提出更高要求,激光雷达在复杂场景下的感知优势得以彰显 。此外,联合国《自动驾驶法规 R157》要求 L3 级系统提供 10 秒接管缓冲期,这高度依赖激光雷达的超视距感知能力2。而国内《智能网联汽车准入试点》规定,L3 + 车型须通过包含雨雾、夜间等极端场景的多传感器融合测试,激光雷达在极端场景下稳定工作的特性,使其成为满足法规要求的核心传感器。政策的引导下,车企为符合标准,在研发与生产中必然更加重视激光雷达的应用,推动其在各类车型中的普及。
安全保障凸显激光雷达价值
安全是自动驾驶的核心诉求,激光雷达在提升驾驶安全性方面发挥着不可替代的作用。辅助驾驶常用的超声波雷达、毫米波雷达和激光雷达中,激光雷达探测距离远,可达 200 - 300 米,且探测精度最高,能够清晰识别障碍物的立体轮廓 。在实际驾驶场景中,这一优势极为关键。例如,夜晚高速行驶时光线不佳,摄像头很难及时察觉危险,而激光雷达能够凭借其主动发光及精确测距能力,及时探测到轮胎这一黑色障碍物,为车辆制动或避让争取宝贵时间 。
诸多实际案例与数据有力地证明了激光雷达对提升安全性的贡献。今年某纯视觉方案车型在高速 NOA 状态下因感知延迟导致严重事故,暴露出纯视觉方案预警时间不足的致命缺陷 。与之形成鲜明对比的是,搭载激光雷达的蔚来 ET9 在类似场景下,AEB 触发速度上限大幅提升 50% 。瑞士再保险的评估显示,配备激光雷达系统的车辆比未配备的同一车型,预计能多避免高达 25% 的碰撞事故,缓解事故影响的能力提升高达 29% 。在逆光场景下,摄像头误判率达 15%,对静止障碍物漏检率是激光雷达的 3.2 倍 。禾赛 AT512 激光雷达测距远,点云密度提升,夜间施工桩桶识别率提高 80% 。这些数据充分表明,激光雷达能够有效弥补摄像头等其他传感器的不足,极大地提升自动驾驶系统的安全性与可靠性。
随着 L3 级有条件自动驾驶法规逐步落地,安全责任主体可能从驾驶员向整车厂转移。面对潜在的高额事故赔偿风险,整车厂为构建超高冗余感知系统,必然会更加倚重激光雷达。在复杂多变的交通环境中,激光雷达提供的安全冗余,能够在关键时刻保障车辆和乘客的安全,成为当下自动驾驶发展中不可或缺的安全保障技术。
谁是最优解?
国内对自驾安全的把控非常严格,这一点从拿到上路测试拍照的公司可以看出。上汽、滴滴、萝卜快跑、新石器、小鹏等几乎无一例外都是基于激光雷达的多模态融合感知方案。
相比于美国,中国的道路场景更加复杂,Robin的观点貌似更适合当下。纯视觉依然有发展空间,但多传感器融合方案更适合目前对安全的要求。
至于特斯拉的Robotaxi是否能够经得起考验,还需要做进一步市场的验证,而这个过程对纯视觉方案,注定会没那么简单。如果没有安全冗余,即使在海量数据的支撑下,遇到极端天气和弱光、强光场景,依然会是非常大的挑战。
参考
1https://www.zhihu.com/question/15350351811/answer/130445267305
2 https://zhuanlan.zhihu.com/p/1918244982894073682
3 https://mp.weixin.qq.com/s/sFzccqsiJHqwsLEJhFRydQ
#DrivingGaussian++
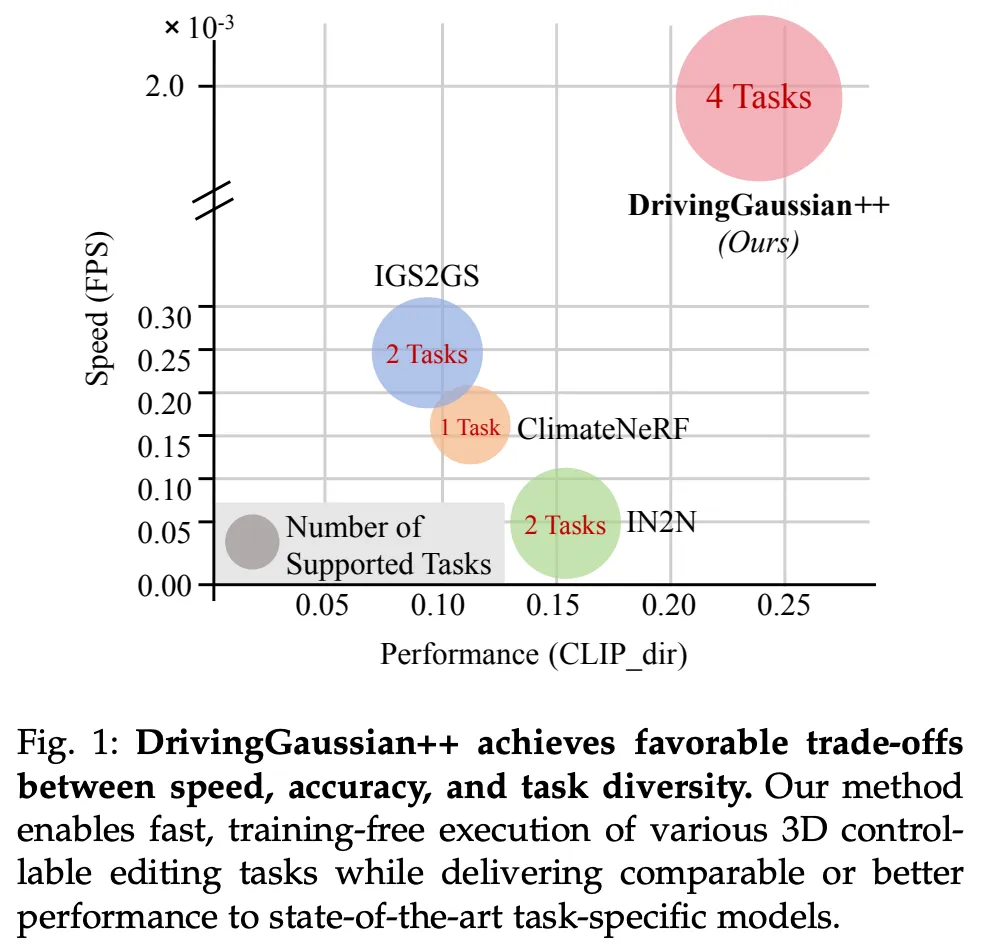
北大升级:无需训练,智驾场景自由编辑!
相信做 learning-based 任务的业内人士都有一个共识:数据一直是自动驾驶发展的一个重要基石,数据的多样性和标注的质量很大程度上决定模型的性能和潜力。自动驾驶发展到今天,需要大家用 80% 的精力去解剩下的 20% 的长尾场景,而往往长尾场景的数据采集并不是一件容易的事情,这就诞生了一个细分领域 ------ 3D场景编辑。通过3D场景编辑,可以仿真各种真实世界的驾驶条件,从而增强自动驾驶系统的鲁棒性和安全性。
3D场景编辑任务 涵盖多种组成部分,包括风格迁移、运动修改、天气仿真以及目标的添加或移除。然而,这些编辑任务各有各的特点和难点,导致现有的编辑工具往往只能专攻某一项,缺少一个"全能型"的框架。目前常用的办法是先对2D画面进行编辑,效果好是好,但为了确保从各个角度看都一致,就得反复调整,非常耗时耗力。所以,这种方法很难用在大规模的自动驾驶仿真上。
要想对3D场景进行编辑,首先得把它精准地重建出来,这对于自动驾驶的测试至关重要。但重建场景本身就是一个大难题:车上装的传感器数量有限,车还在高速运动,采集到的数据既稀疏又不完整。再加上车周摄像头都是朝外安装,视野重叠区域小,光线条件也不统一,导致把不同角度、不同时间的画面拼成一个完整的3D场景格外困难。这种360度、大范围、动态变化的场景,想要建得准确、逼真,真的非常具有挑战性。
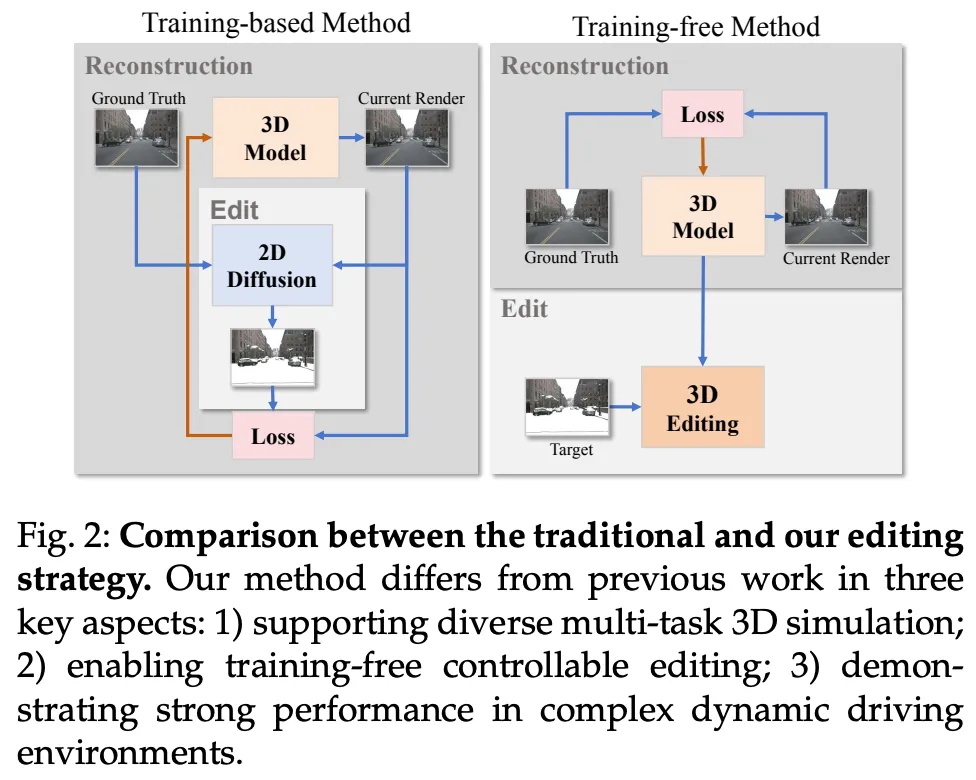
在本文中,作者提出 DrivingGaussian++(CVPR 2024 的工作 DrivingGaussian 的续作),核心思想是 利用来自多个传感器的序列数据对复杂的驾驶场景进行分层建模。作者采用复合 GS(Composite Gaussian Splatting)将场景分解为静态背景和动态目标,并分别重建每个部分。在此基础上,通过 GS 进行全局渲染捕捉真实世界中的遮挡,包括静态背景和动态目标。此外,作者将 LiDAR 先验融入高斯表示中,从而能够恢复更精确的几何结构并保持更好的多视图一致性。
- 论文题目: DrivingGaussian++: Towards Realistic Reconstruction and Editable Simulation for Surrounding Dynamic Driving Scenes
- 论文链接:https://arxiv.org/pdf/2508.20965
与CVPR 2024上发表的初步结果的差异。 作者在几个方面扩展了之前的工作:
- 基于复合 GS 表示大规模动态驾驶场景,引入了两个新颖模块,包括增量静态3D高斯(Incremental Static 3D Gaussians)和复合动态高斯图(Composite Dynamic Gaussian Graphs)。前者增量地重建静态背景,而后者使用高斯图对多个动态目标进行建模。
- 构建了一个场景编辑框架,以无需训练的方式编辑重建的场景,涵盖多个任务,包括纹理修改、天气仿真和目标操纵。它有助于生成新颖且真实的仿真数据。
- 实现了驾驶场景的动态编辑,预测插入场景中的粒子的运动轨迹。
- 通过3D生成和重建构建了一个前景资源库,并验证了数据的质量。
相关工作
3D 重建
神经辐射场
神经辐射场 (NeRFs) 利用多层感知机 (MLPs) 和可微分体渲染,可以从一组 2D 图像和相应的相机位姿信息中重建 3D 场景并合成新视图。
用于有界场景的 NeRF。 典型的 NeRF 模型最初仅适用于有界场景,且对相机与物体的相对位置有较高要求,也难以处理重叠少或向外捕捉的场景。尽管后续研究在训练速度、位姿优化、场景编辑和动态表达等方面改进了 NeRF,但其在处理自动驾驶等大规模无界场景时仍面临显著挑战。
用于无界场景的 NeRF。 针对无界场景,一些方法对 NeRF 进行了扩展,例如引入多尺度城市静态场景建模、采用抗混叠的 MIP-NeRF 结构、融合多分辨率地面特征,或通过解耦方式处理街道视图。但这些方法大多仍基于静态假设,难以有效表达动态元素。
此外,尽管已有工作尝试将 NeRF 用于动态单目视频合成,或通过场景图、实例感知仿真器和多传感器融合(如 LiDAR 和光流)处理动态城市环境,这些方法往往受限于前向视角或难以应对多摄像头、光照变化和动态目标的复杂交互。传统基于 NeRF 的方法严重依赖光线采样,在动态多目标和光照变化显著时渲染质量下降,同时 LiDAR 仅作为辅助深度监督,其几何先验能力未得到充分发挥。
为克服这些局限,本研究采用复合 GS 对无界动态场景进行建模:静态背景随自车移动增量重建,动态目标通过高斯图建模并集成到场景中。LiDAR 不仅用于深度监督,更为高斯初始化提供几何先验,从而提升重建精度与场景一致性。
3DGS
近期的 3D GS 方法使用大量 3D 高斯来表示静态场景,并在新视图合成和训练速度方面取得了最先进的结果。与现有的显式场景表示(例如,网格、体素)相比,3DGS 可以用更少的参数对复杂形状进行建模。与隐式神经渲染不同,3DGS 允许基于泼溅的光栅化进行快速渲染和可微分计算。
动态 3DGS 虽然原始的 3DGS 旨在表示静态场景,但已经开发了几种用于动态目标/场景的方法。给定一组动态单目图像,有些工作引入了一个变形网络来建模高斯的运动。此外还有些通过 HexPlane 连接相邻的高斯,实现实时渲染。然而,这两种方法都是明确为专注于中心物体的单目单摄像头场景设计的。另外一些工作使用一组演化的动态高斯来参数化整个场景。然而,它需要具有密集多视图图像的摄像头阵列作为输入。
在真实世界的自动驾驶场景中,数据采集平台的高速运动导致广泛而复杂的背景变化,并且通常由稀疏视图(例如,2-4 个视图)捕获。此外,具有剧烈空间变化和遮挡的快速移动动态目标使情况进一步复杂化。总的来说,这些因素对现有方法构成了重大挑战。
3D 场景可控编辑
神经辐射场 (NeRF) 和 3D GS 是两种用于 3D 场景重建的重要方法。NeRF 将场景几何和外观隐式编码在多層感知機 (MLP) 中,而 3D GS 使用 3D 高斯椭球显式表示场景。尽管已经展示了重建能力,但编辑这些表示仍然是一个重大挑战。当前的方法大致可分为两类:基于扩散模型引导的编辑和基于 3D 粒子系统的编辑。
基于扩散引导的编辑
扩散模型因支持文本驱动的图像编辑而受到关注。一些方法借助预训练的扩散模型,将这一能力引入3D场景编辑。具体做法是:对3D模型渲染出的图像添加噪声,再通过2D扩散模型结合控制条件预测噪声差异,并借助分数蒸馏采样(SDS)损失优化3D模型。尽管这类方法效果显著,但它们难以保持多视角一致性,也无法很好地处理复杂的大规模动态场景。
例如,Instruct-NeRF2NeRF 将3D编辑任务转化为2D图像编辑问题,但由于无法保证不同视角下编辑的一致性,容易出现不稳定、速度慢和明显伪影的问题。ViCA-NeRF 尝试通过选择部分参考图像编辑再融合其余图像以缓解问题,但仍未根本解决一致性问题,编辑结果往往模糊。
近期一些工作,如 DreamEditor 将 NeRF 转换为网格并借助 SDS 和 DreamBooth 进行优化;HiFA 通过调整扩散时间步和降噪权重提升多视角一致性;还有一些方法将 NeRF 编辑技术扩展至 3DGS,并引入深度估计作为几何先验。尽管这些方法在一致性方面取得进展,但仍因依赖固定深度估计而仅限于纹理修改,且通常需依赖静态掩码控制编辑区域,无法有效用于动态3D模型训练。现有方法多数仅在物体中心数据集上验证,尚未适用于复杂驾驶场景。
相比之下,DrivingGaussian++ 采用了一种无需训练的范式,有效解决了现有方法在动态驾驶场景编辑中的挑战,实现了卓越的编辑一致性和视觉质量。
基于 3D 粒子系统的编辑
另一类方法不依赖扩散模型或额外图像,而是直接操纵3D粒子实现编辑。例如,ClimateNeRF 通过仿真粒子生成雨、雪、雾等天气效果,并将其嵌入神经场中以增强真实感。GaussianEditor 和 Infusion 等则基于 3DGS,通过语义属性识别编辑区域,或借助深度补全控制高斯修复,实现精确的3D插入与删除。这类方法通常编辑效率更高,多视角一致性也更好。DrivingGaussian++ 采用 3D 粒子级编辑,并将其进一步扩展到多个任务,包括纹理、目标和天气编辑。通过无需训练的范式,作者的方法为大规模自动驾驶场景实现了显式、可控和高效的编辑。
方法论
作者的目标是在 3D 自动驾驶场景中实现无需训练的编辑。为了处理多个编辑任务,作者提出了一个可控且高效的框架。首先 ,作者采用复合 GS (Composite Gaussian Splatting) 精确重建动态驾驶场景。接下来 ,作者识别场景中待修改的特定高斯,或生成新的高斯以仿真特定的物理实体。这些目标高斯随后被集成到原始场景中,并预测目标的未来轨迹。最后 ,作者使用图像处理技术细化结果以增强真实感。使用此框架,作者为三个关键任务开发了详细的编辑方法:纹理修改、天气仿真和目标操纵。方法如图 3 所述。
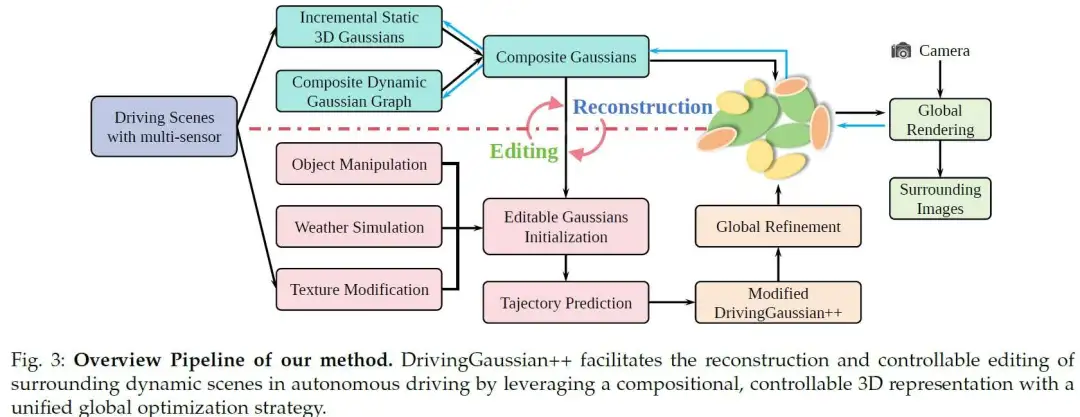
复合 GS
3DGS 在静态场景中表现良好,但在涉及大规模静态背景和多个动态目标的混合场景中具有显著局限性。如图 4 所示,作者的目标是使用复合 GS 来表示环视的大规模驾驶场景,用于无界的静态背景和动态目标。
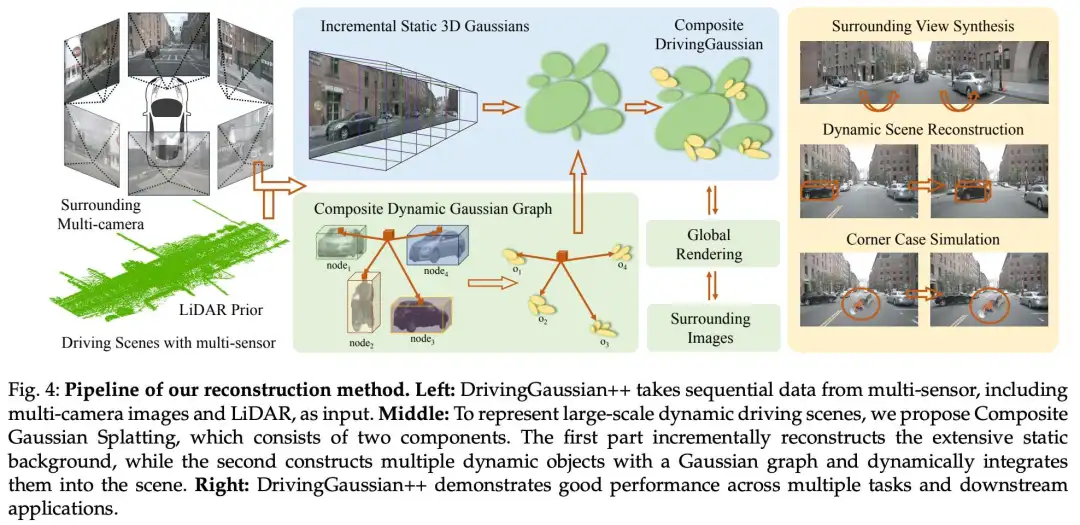
带有环视视图的 LiDAR 先验
原始的 3DGS 尝试通过运动恢复结构 (SfM, structure-from-motion) 来初始化高斯。然而,用于自动驾驶的无界城市场景包含许多多尺度的背景和前景。但是它们仅通过极其稀疏的视图被看见,导致几何结构的错误和不完整恢复。
为了给高斯提供更好的初始化,作者将 LiDAR 先验引入 3D 高斯以获得更好的几何结构,并在环视视图配准中保持多摄像头一致性。在每个时间步 ,给定收集的一组多摄像头图像 和多帧 LiDAR 扫描 。作者利用 LiDAR-图像多模态数据最小化多摄像头配准误差,并获得精确的点位置和几何先验。
作者首先合并多帧 LiDAR 扫描以获得场景的完整点云,记为 。作者遵循 Colmap 并分别从每个图像中提取图像特征 。接下来,作者将 LiDAR 点投影到环视图像上。对于每个 LiDAR 点 ,作者将其坐标转换到相机坐标系,并通过投影将其与相机图像平面的 2D 像素匹配:
其中 是图像的 2D 像素,, 和 分别是正交旋转矩阵和平移向量。此外, 代表已知的相机内参。值得注意的是,来自 LiDAR 的点可能会投影到多个图像的多个像素上。因此,作者选择到图像平面欧几里得距离最短的点,并将其保留为投影点,并分配颜色。
与现有的一些 3D 重建方法类似,作者将密集束调整 (DBA, dense bundle adjustment) 扩展到多摄像头设置并获得更新的 LiDAR 点。实验结果表明,使用 LiDAR 先验进行初始化以与环视多摄像头对齐,有助于为高斯模型提供更精确的几何先验。
增量静态 3D 高斯
驾驶场景的静态背景由于其大规模、长持续时间以及由自车移动和多摄像头变换引起的变化,对场景建模和编辑构成了挑战。随着车辆的移动,静态背景经常经历时间偏移和动态变化。由于透视原理,过早地合并远离当前时间步的遥远街道场景会导致尺度混淆,从而产生令人不快的伪影和模糊。为了解决这个问题,作者通过引入增量静态 3D 高斯来改进 3DGS,利用车辆运动引入的透视变化和相邻帧之间的时间关系,如图 5 所示。
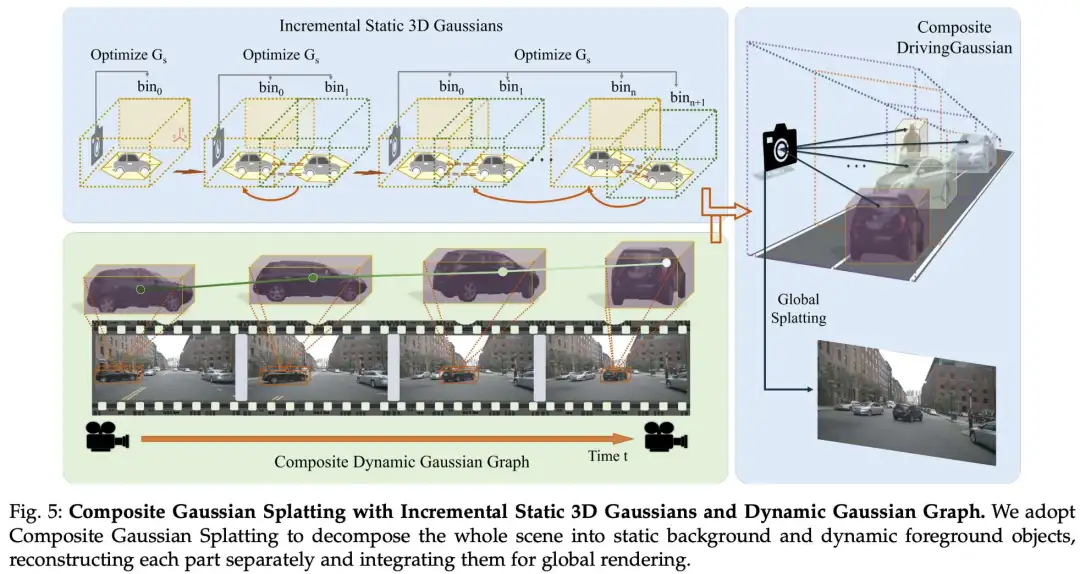
作者根据 LiDAR 先验提供的深度范围,将静态场景统一划分为 个区间 (bins)。这些区间按时间顺序排列,记为 ,每个区间包含来自一个或多个时间步的多摄像头图像。相邻的区间有一个小的重叠区域,用于对齐两个区间的静态背景。然后将后一个区间增量地融合到前几个区间的高斯场中。对于第一个区间内的场景,作者使用 LiDAR 先验(同样适用于 SfM 点)初始化高斯模型:
其中 是 LiDAR 先验的位置; 是 LiDAR 点的均值; 是一个各向异性的协方差矩阵; 是转置运算符。作者利用此区间段内的环视视图作为监督来更新高斯模型的参数,包括位置 、协方差矩阵 、用于视图相关颜色的球谐系数 以及不透明度 。
对于后续的区间,作者使用前一个区间的高斯作为位置先验,并根据它们的重叠区域对齐相邻的区间。每个区间的 3D 中心可以定义为:
其中 是所有当前可见区域的高斯 的 3D 中心集合, 是 区域内的高斯坐标。作者将后续区间中的场景合并到先前构建的高斯中,并以多个环视帧作为监督。增量静态高斯模型 定义为:
其中 表示某个视图中每个高斯对应的颜色, 是不透明度, 是根据所有区间中的 计算出的场景累积透射率。在此过程中,环视多摄像头图像之间的重叠区域用于共同形成高斯模型的隐式对齐。
请注意,在增量构建静态高斯模型期间,前后摄像头对同一场景的采样可能存在差异。因此,作者在 3D 高斯投影过程中使用加权平均来尽可能准确地重建场景的颜色:
其中 是优化后的像素颜色, 表示可微分泼溅, 是不同视图的权重, 是用于对齐多摄像头视图的视图矩阵。
复合动态高斯图
自动驾驶环境高度复杂,涉及多个动态目标和时间变化。如图 5 所示,由于车辆和自我本体的自我中心运动,目标通常从有限的视图(例如,2-4 个视图)中观察到。此外,快速移动的物体也会导致显著的外观变化,使得使用固定的高斯来表示它们具有挑战性。
为了应对这些挑战,作者引入了复合动态高斯图,使得能够在长期、大规模的驾驶场景中构建多个动态目标。作者首先从静态背景中分解出动态前景目标,使用数据集提供的边界框构建动态高斯图。动态目标通过其目标 ID 和相应的出现时间戳进行识别。此外,采用 Grounded SAM 模型基于边界框范围对动态目标进行精确的像素级提取。
作者使用以下公式构建动态高斯图:
其中每个节点存储一个实例目标 , 表示相应的动态高斯, 是每个目标的变换矩阵。这里, 是边界框的中心坐标, 是时间步 时边界框的方向。作者为每个动态目标分别计算一个高斯。使用变换矩阵 ,作者将目标目标 的坐标系转换到静态背景所在的世界坐标系:
其中 和 是分别对应于每个目标的旋转和平移矩阵。
在优化动态高斯图中的所有节点之后,作者使用复合高斯图将动态目标和静态背景组合起来。每个节点的高斯分布根据边界框的位置和方向按时间顺序连接到静态高斯场中。在多个动态目标之间存在遮挡的情况下,作者根据到相机中心的距离调整不透明度:更近的目标具有更高的不透明度,遵循光传播的原理:
其中 是时间步 时目标 的高斯的调整后不透明度, 是该目标的高斯中心。 表示目标到世界的变换矩阵, 表示相机视线的中心, 是高斯的初始不透明度。
包含静态背景和多个动态目标的复合高斯场由以下公式表示:
其中 是通过增量静态 3D 高斯获得的, 表示优化后的动态高斯图。
3D 驾驶场景编辑基于静态背景和动态目标的复合高斯(由复合 GS 重建),并在其上执行多个编辑任务而无需额外训练。
通过 GS 进行全局渲染
作者采用可微分 3DGS 渲染器 ,并将全局复合 3D 高斯与协方差矩阵 一起投影到 2D:
其中 是透视投影的雅可比矩阵, 表示世界到相机的变换矩阵。
复合高斯场将全局 3D 高斯投影到多个 2D 平面上,并在每个时间步使用环视视图进行监督。在全局渲染过程中,下一个时间步的高斯最初对当前时间步不可见,随后在相应全局图像的监督下被合并。
作者方法的损失函数由三部分组成。将 tile 结构相似性 (TSSIM, Tile Structural Similarity) 引入 GS ,它测量渲染的 tile 与相应的真实值之间的相似性:
其中作者将屏幕分割成 个 tile , 是高斯的训练参数, 表示从复合 GS 渲染的 tile , 表示配对的真实 tile 。
作者还引入了一个鲁棒损失来减少 3D 高斯中的异常值,其定义为:
其中 是控制损失鲁棒性的形状参数, 和 分别表示真实图像和合成图像。
通过使用 LiDAR 监督期望高斯的位置,进一步采用 LiDAR 损失,以获得更好的几何结构和边缘形状:
其中 是 3D 高斯的位置, 是 LiDAR 点先验。
作者通过最小化这三个损失之和来优化复合高斯。提出的编辑方法利用全局渲染的图像来识别编辑目标,并利用从 3DGS 导出的深度信息作为几何先验,从而实现有效且真实的多任务编辑。
动态驾驶场景的可控编辑
作者处理自动驾驶仿真的三个关键编辑任务:纹理修改、天气仿真和目标操纵。为了支持这些不同的编辑任务,作者开发了一个框架,该框架使用 3D 几何先验、用于动态预测的大语言模型 (LLMs) 和先进的编辑技术,依次对重建场景的高斯进行操作,以确保整体的连贯性和真实感。
纹理修改: 此任务涉及将图案应用到 3D 目标的表面。在自动驾驶中,纹理修改超越了美学范畴,允许添加关键的道路特征,例如裂缝、井盖和标志,这对于构建更鲁棒的测试环境至关重要。作者在图 7 中展示了物体检测模型的失败案例,突出了编辑仿真重要性。在编辑之前,感知模型准确识别场景内的目标。然而,在使用 DrivingGaussian++ 编辑之后,3D 场景中的具有挑战性的案例对模型变得不可检测,为评估自动驾驶系统内各种组件的可靠性和鲁棒性提供了更有效的测试环境。

天气仿真: 此任务侧重于将动态气象现象(如降雨、降雪和雾)集成到自动驾驶场景中。天气仿真对于复现恶劣天气下的驾驶条件至关重要,展示了其在增强训练数据集方面的重要性。
目标操纵: 此任务分为在重建场景内删除目标和插入目标。目标插入进一步分为静态和动态类型,动态插入自适应地预测目标的运动轨迹。这些操纵对于构建鲁棒的自动驾驶仿真系统至关重要。
为了实现多任务编辑,作者提出了一个框架,该框架无需额外训练即可对重建场景的高斯依次进行操作。该过程首先使用 3D 几何先验识别要编辑的目标高斯,然后将它们集成到场景中。作者采用大语言模型 (LLMs) 来预测动态目标的轨迹,并应用图像处理技术来细化结果,确保连贯性和真实感。编辑流程如图 6 所示。
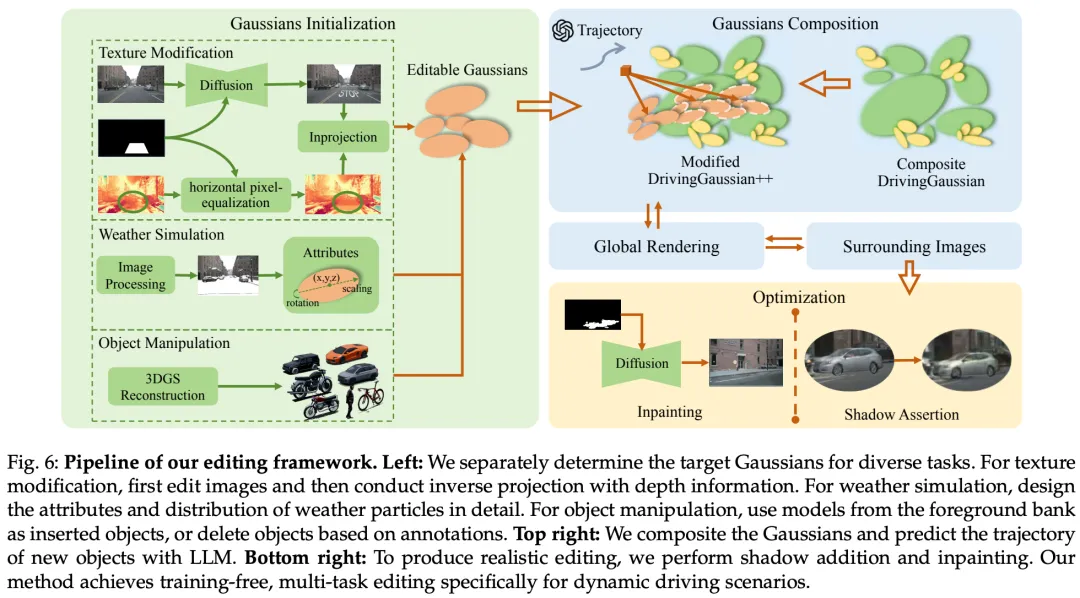
初始化
在提出的编辑框架中,作者将那些引入到原始场景中或从原始场景中移除的高斯称为目标高斯 (target Gaussians),而从初始场景重建的高斯称为原始高斯 (original Gaussians)。确定目标高斯的方法取决于具体的编辑任务。对于目标移除,目标高斯对应于标记为要移除的原始高斯的子集,通过细化数据集提供的 3D 边界框来识别。由于 LiDAR 先验在重建过程中已被集成,作者可以准确定位它们的位置,而无需额外的坐标系对齐。对于其他编辑任务,会生成新的高斯作为目标高斯,并设计具有特定形状和分布以满足每个任务的要求。
纹理修改。 作者通过在指定编辑区域的表面上引入新的扁平高斯来增强目标的表面纹理。该过程首先选择一个视角,并使用扩散模型或类似工具编辑原始图像,生成目标图像和相应的掩码来指导 3D 编辑。具体来说,作者随机选择一个能清晰看到目标区域的视角,并渲染待编辑的图像及其相关的深度图。接下来,作者定义目标区域的 2D 掩码,并应用扩散模型或图像处理软件在 2D 空间中修改图像,生成目标图像。
使用目标图像和掩码,作者通过逆投影生成目标高斯并分配合适的属性。如图 8 所示,DrivingGaussian++ 根据渲染的深度图和像素级对应关系,将编辑内容投影到相应位置。
然而,3D GS 重建的表面与实际物体的表面之间可能会出现差异。这些差异可能导致渲染深度与目标的真实深度不一致,可能使得目标高斯的表面看起来不平整和不真实,从而影响编辑质量。
为了解决这个问题,作者对深度图进行均衡化。具体来说,作者将编辑区域的深度归一化,确保沿水平轴有相对均匀的深度分布,同时保留沿垂直轴的深度分布:
其中 , 分别表示深度均衡化前后的渲染深度, 表示编辑区域的二值掩码,, 是图像坐标。这种方法为目标高斯产生了一个平坦的表面,显著提高了纹理修改的视觉质量和真实感。
天气仿真。 作者通过将具有特定物理属性的高斯合并到当前场景中来仿真天气粒子,并通过在每个时间步调整这些高斯的位置来实现动态效果。天气仿真的第一步是设计与所需物理属性相符的粒子。作者计算原始高斯的数量及其位置范围,并在场景中以特定分布引入具有特定形状和颜色的新高斯。具体来说,作者使用狭窄、半透明的白色高斯来表示雨滴,使用不规则的白色椭球高斯来表示雪花,并使用在场景中遵循随机分布的高斯来表示雾。例如,对于雪仿真,作者通过以下方式定义目标高斯 :
其中第 个高斯 满足 , , , 且 , , 分别表示其 3D 坐标、颜色和尺度属性。
其次,为了实现包括雨滴下落、雪花飘移和雾扩散的动态天气效果,作者根据当前时间步为天气高斯添加特定的轨迹。作者以一个示例描述雪花的轨迹:
其中 表示 中第 个高斯在时间步 的位置, 是一个计算时间序列中连续位置之间相对运动的函数。
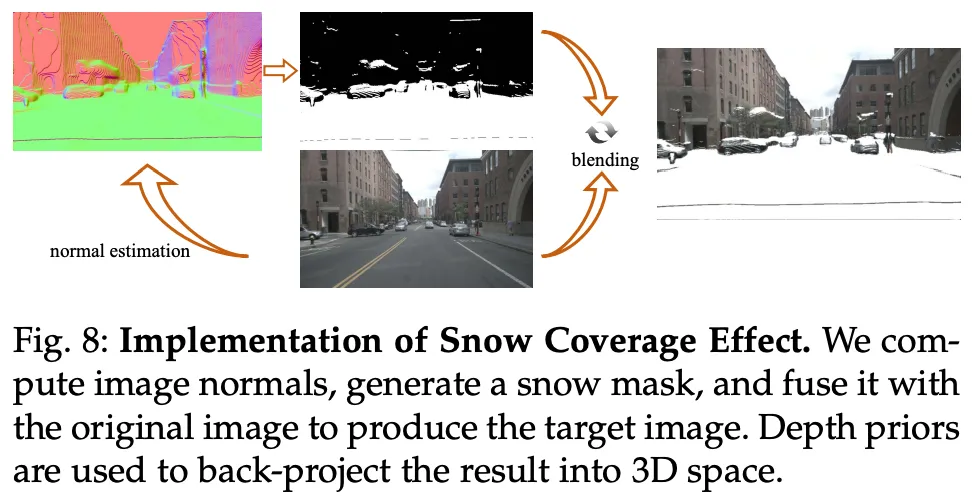
作者还实现了 3D 积雪效果,如图 8 所示。具体来说,作者首先基于 Depth-Anything 和 Sobel 滤波器计算训练图像的法线图:
其中 和 分别表示图像 的深度图和法线图,而 和 是水平和垂直方向的梯度幅度。基于法线图,在具有较大垂直 分量的区域添加雪掩码。使用带有积雪效果和处理后深度图的处理图像,从该视角进行逆投影以计算雪粒子高斯的 3D 位置。最后,作者组合不同视角下的位置以实现帧间一致的积雪效果。为了避免在帧间重叠区域因重复计算而产生不一致,作者构建了一个 KD 树,并修剪彼此距离过近的节点:
其中 表示目标雪粒子高斯的位置, 表示从第 帧的视角计算的位置, 指的是构建的 KD 树, 代表 K 近邻 (KNN) 函数,它接受三个参数作为输入:搜索范围、搜索目标的 KDTree 和 top k 近邻的数量。作者将最终的目标雪粒子高斯插入场景中并实现积雪效果。
目标操纵。 由于操作性质不同,目标插入和删除在实现上有所不同。对于目标移除,目标高斯对应于要删除的目标。首先,作者从数据集标注中提取目标的 3D 边界框矩阵,并裁剪边界框内的高斯。为了解决被遮挡区域因重建不充分而产生的孔洞,作者进一步使用扩散模型对渲染图像进行局部绘制。对于目标插入,作者构建了一个包含使用 3DGS 重建的目标的 3D 前景库,可以直接用于插入。库中的目标是通过对在线收集的 Blender 模型进行 3DGS 重建以及对自动驾驶数据集中的车辆进行稀疏重建而获得的。此外,可以使用 MCLight 调整前景目标的照明以更好地匹配当前场景。
带有轨迹预测的高斯组合
在识别出目标高斯之后,作者将它们与原始场景集成。此过程将两个组件在同一坐标系中对齐,以建立物理上准确的遮挡关系。有意思的是,两组高斯的协方差矩阵在光栅化渲染过程中可能会相互干扰,可能导致模糊的结果。因此,作者对添加的高斯执行额外的前向过程,并存储变换后高斯的协方差矩阵。最后,渲染组合后的场景以进行可视化。
对于目标插入任务,为了确保动态目标具有合理且多样的运动轨迹,作者利用大语言模型的强大场景理解能力来预测插入目标的未来轨迹:
其中 表示插入目标在时间步 的位置,而 是初始位置, 表示由 LLM 生成的在时间步 的相对位置, 是天空方向, 表示期望轨迹的描述。具体来说,作者将初始车辆位置、天空方向和轨迹描述作为提示,并通过 GPT-4o 生成一系列可能的未来轨迹序列。
使用可微分渲染进行全局细化
利用扩散模型和 2D 图像处理的最新进展,作者的方法整合了这些技术以增强目标操纵任务的结果。对于目标移除,作者使用扩散模型对渲染图像的损坏区域进行局部修复。首先,作者基于 3D 标注删除指定区域的目标高斯。然而,由于遮挡和数据采集视角的限制,被删除高斯环视的区域通常包含伪影或重建质量差的孔洞。为了解决这个问题,作者使用 K 近邻算法识别目标区域环视需要修复的一组高斯。然后作者对这些高斯进行二值化渲染以生成相应的修复掩码:
要在Markdown中输出该公式,可使用LaTeX语法:
其中 是一个二值掩码,待修复的高斯设置为 1, 表示移除后剩余的高斯,而 表示被移除的高斯, 表示 的位置, 是决定哪些高斯应被修复的距离阈值。 与 中高斯之间的最近距离由 给出,其计算为 。随后,待修复的图像以及相应的掩码作为输入送入扩散模型。DrivingGaussian++ 执行局部修复以恢复场景的完整性和视觉真实性,实现更真实和无缝的目标移除。
对于目标插入任务,当从自动驾驶数据集中提取数据时,作者执行稀疏重建以生成目标高斯。重建的车辆缺乏阴影信息,这会导致渲染图像中出现悬浮效果。为了在不进行额外训练的情况下增强目标插入的真实感,作者采用了一种受 ARShadowGAN 启发的阴影合成方法。具体来说,作者为插入的目标合成阴影以消除悬浮效果,从而提高场景的视觉一致性和真实感。
实验及结论
重建结果与比较
nuScenes 环视视图的比较
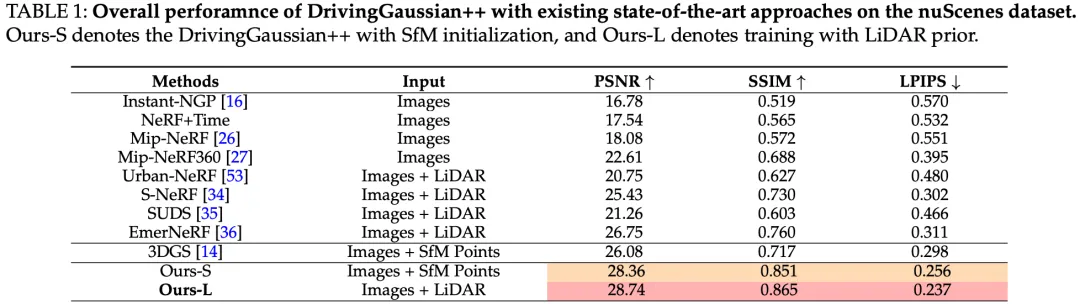
作者将提出的模型与最先进的方法进行比较,包括基于 NeRF 的方法和基于 3DGS 的方案。如表 I 所示,作者的方法优于使用基于哈希的 NeRF 进行新视图合成的 Instant-NGP。虽然 Mip-NeRF 和 Mip-NeRF360 是专门为无界室外场景设计的,但作者的方法在所有指标上都表现良好。
作者在具有挑战性的 nuScenes 驾驶场景上展示了定性评估结果。对于多摄像头环绕视图合成,如图 9 所示,作者的方法能够生成逼真的渲染图像,并确保多摄像头之间的视图一致性。同时,EmerNeRF 和 3DGS 在具有挑战性的区域表现不佳,表现出不理想的视觉伪影,例如重影、动态物体消失、植物纹理细节丢失、车道标记丢失以及远处场景模糊。
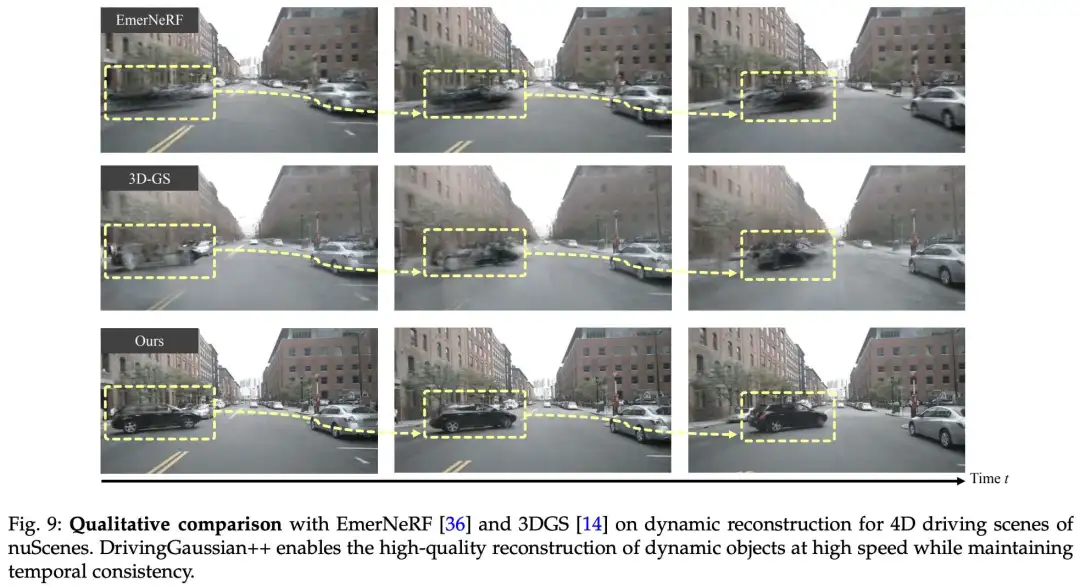
作者接下来展示了动态时序场景的重建结果。作者的方法准确地建模了大场景中的动态目标,缓解了这些动态元素的丢失、重影或模糊等问题。所提出的模型随着时间的推移一致地构建动态目标,尽管它们的移动速度相对较高。如图 9 所示,其他方法对于快速移动的动态目标是不够的。
KITTI-360 单目视图的比较
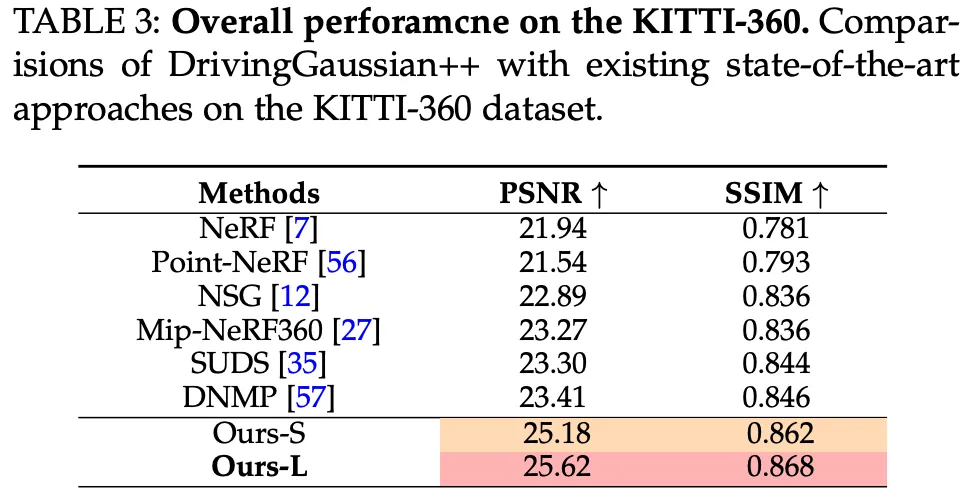
为了进一步验证作者的方法在单目驾驶场景设置中的有效性,作者使用 KITTI-360 数据集进行了实验,并与现有的最先进方法进行比较。如表 III 所示,作者的方法在单目驾驶场景中相对于其他模型表现良好。
编辑结果与比较
作者首先在 nuScenes 数据集上展示了多个任务的编辑结果。与最先进的 2D 和 3D 编辑方法相比,作者的方法实现了卓越的视觉真实感和更好的定量一致性。
为了支持对驾驶场景的灵活编辑,作者还创建了一个包含专用驾驶场景目标的 3D 高斯前景库。这个前景库对于自动驾驶仿真和模型验证至关重要。
定性结果与比较
作者通过 DrivingGaussian++ 对重建的 nuScenes 数据执行无需训练的编辑,涉及三个领域:纹理、天气和目标操纵。综合结果如图 12 所示,展示了 DrivingGaussian++ 在动态驾驶场景中执行各种编辑操作的能力。

对于天气编辑,作者通过基于粒子的仿真实现了真实的效果。特别是对于雪仿真,作者在每个时间步添加雪粒子高斯,并估计表面法线以确定沉积位置。这产生了真实的积雪,如图 13 所示。

对于目标操纵,作者通过使变形模块适应前景上下文,作者实现了灵活多样的动态目标集成。此外,作者采用基于 LLM 的轨迹预测来获取插入目标的轨迹。动态目标插入的结果如图 15 所示。

图 14 提供了与现有 3D 编辑方法的性能比较。虽然 InstructNeRF2Nerf 和 InstructGS2GS 使用扩散模型跨多个任务进行迭代式 3D 场景编辑,但它们在保持照片真实感和视图一致性方面存在局限性。ClimateNeRF 通过表面法线计算专门从事粒子级天气编辑,但其应用缺乏对其他编辑任务的通用性,并且仍局限于静态环境。作者的方法解决了这些局限性,同时在所有编辑任务上实现了高质量的结果。

定量结果与比较
为了评估作者编辑方法的一致性和真实性,作者将 DrivingGaussian++ 与最先进的 3D 和 2D 编辑技术进行了比较。
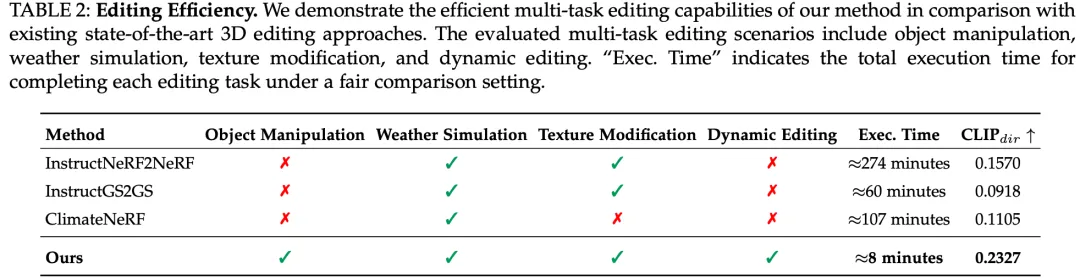
对于 3D 场景编辑,作者在任务多样性、处理时间和 CLIP-direction 相似性方面与 ClimateNeRF、IN2N 和 IGS2GS 进行比较。如表 II 所示,DrivingGaussian++ 在多样性、效率和文本对齐一致性方面均优于所有其他方法。特别是,对于来自 NuScenes 数据集的场景,DrivingGaussian++ 的编辑时间通常在 3~10 分钟内,显著低于其他需要长时间训练的 3D 编辑模型。
为了评估 DrivingGaussian++ 在单视图编辑上的性能,作者还在不同任务上将其与 2D 编辑方法进行了比较,如表 IV 所示。
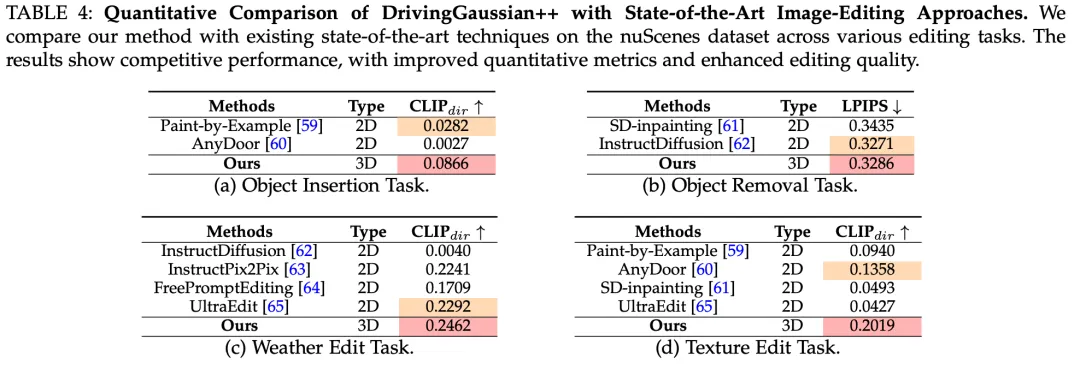
对于纹理修改和目标插入,作者与一些修复方法进行比较。虽然 Any-Door 和 Paint-by-Example 利用 2D 图像进行条件编辑,但它们产生不一致的透视关系并且与条件图像的一致性差。SD-Inpainting 以文本提示和 2D 掩码作为输入,但性能和可控性有限。对于天气仿真,作者评估了文本引导的编辑方法。尽管 FreePromptEditing、InstructPix2Pix 和 InstructDiffusion 表现出良好的文本理解能力,但它们的结果往往缺乏物理合理性------例如,雪仅仅被渲染为风格变化而不是累积的降水。InstructDiffusion 在这些天气场景中的编辑结果不太真实。对于目标移除,作者评估了修复和文本引导方法。SD-Inpainting 和 InstructDiffusion 会留下残留伪影,而 LaMa 在场景恢复中会引入明显的不一致性。
作者使用 CLIP direction similarity 指标评估纹理、天气编辑和目标插入的编辑一致性。对于目标移除,作者使用 LPIPS 和 FID(如 SPIn-NeRF 所示)评估质量。DrivingGaussian++ 在所有任务上均实现了卓越的性能。
用于驾驶场景的 3D 高斯前景库
作者构建了一个全面的 3D 高斯前景库,包含各种交通元素:车辆、自行车、摩托车、行人、动物以及标志和交通锥等静态物体。图 16 显示了作者的前景库和插入结果。
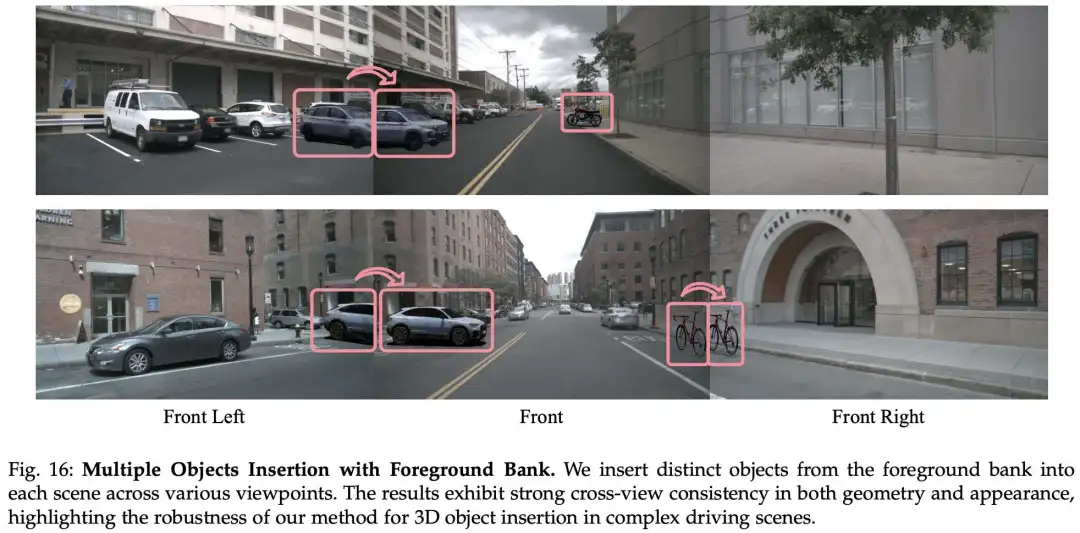
在线模型重建。 作者从在线来源和 Chatsim 收集 3D 模型(行人、车辆等),然后使用 3DGS 重建它们。对于每个模型,作者在 Blender 中渲染 360 度视图,并使用 COLMAP 执行 3DGS 重建。作者使用从 nuScenes 提取的环境贴图调整照明。
nuScenes 车辆的稀疏重建。 作者使用 SplatterImage 高效地稀疏重建 nuScenes 中的车辆。每辆车大约需要 2~4 张参考图像进行高斯重建。
基于图像的目标生成。 为了扩展作者的数据集,作者使用图像输入生成 3D 目标。作者首先使用 SAM 提取干净的目标图像。随后,作者使用 DreamGaussian 和 DreamGaussian4D 创建静态和动态 3D 模型,用于少样本 3D 生成,从而能够高效地创建高保真度的静态和动态目标。
消融研究
高斯的初始化先验
作者进行了对比实验来分析不同先验和初始化方法对高斯模型的影响。原始 3DGS 提供两种初始化模式:随机生成的点和使用 COLMAP 计算的 SfM 点。作者另外提供了两种其他方法:来自预训练 NeRF 模型的点云和使用 LiDAR 先验生成的点。
同时,为了分析点云数量的影响,作者将 LiDAR 下采样到 600K 并应用自适应滤波(1M)来控制生成的 LiDAR 点的数量。作者还为随机生成的点设置了不同的最大阈值(600K 和 1M)。这里,SfM-600K±20K 表示由 COLMAP 计算的点数,NeRF-1M±20K 表示预训练 NeRF 模型生成的总点数,LiDAR-2M±20k 指的是 LiDAR 点的原始数量。
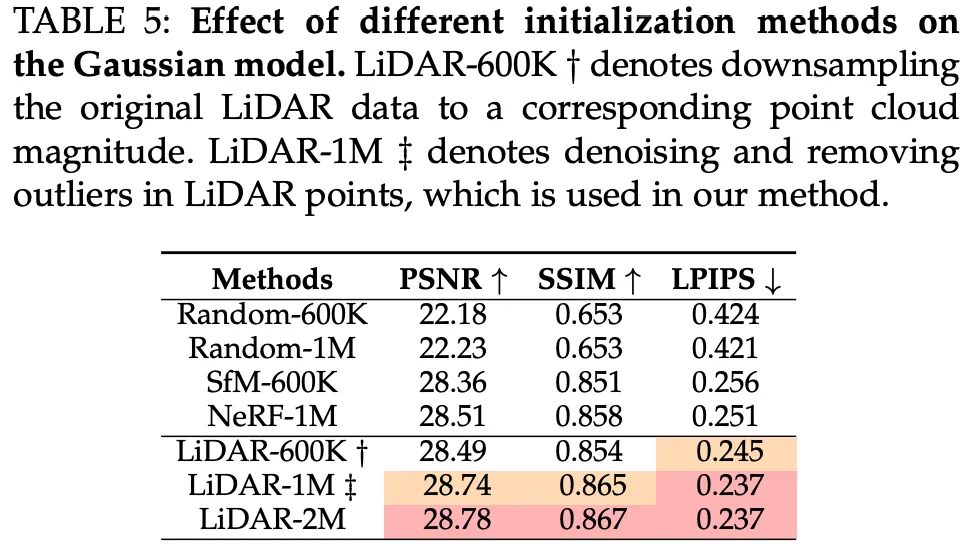
如表 V 所示,随机生成的点导致最差的结果,因为它们缺乏任何几何先验。使用 SfM 点初始化也无法充分恢复场景的精确几何结构,因为点稀疏且存在无法容忍的结构错误。利用从预训练 NeRF 模型生成的点云提供了相对准确的几何先验,但仍然存在明显的异常值。对于使用 LiDAR 先验初始化的模型,尽管下采样会导致某些局部区域的几何信息丢失,但它仍然保留了相对准确的结构先验,因此超过了 SfM(图 18)。作者注意到,实验结果并不随 LiDAR 点数量的增加而线性变化。这可以归因于过于密集的点存储了冗余特征,干扰了高斯模型的优化。

模型组件的有效性
作者分析了所提出模型每个模块的贡献。如表 VI 和图 17 所示,复合动态高斯图 (Composite Dynamic Gaussian Graph) 模块在重建动态驾驶场景中起着至关重要的作用,而增量静态 3D 高斯 (Incremental Static 3D Gaussians) 模块能够实现高质量的大规模背景重建。
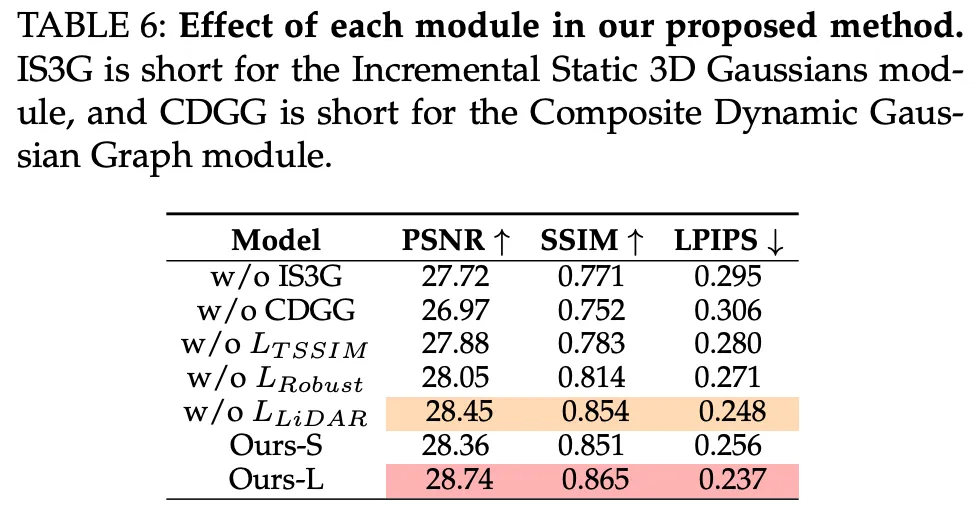
这两个新颖的模块显著增强了复杂驾驶场景的建模质量。关于提出的损失函数,消融结果表明 和 都显著提高了渲染质量,改善了纹理细节并消除了伪影。此外,来自 LiDAR 先验的 帮助高斯获得更好的几何先验。实验结果还表明,即使没有先前的 LiDAR,DrivingGaussian++ 也表现良好,证明了其对各种初始化方法的强大鲁棒性。

结论
作者介绍了 DrivingGaussian++,一个用于重建和编辑大规模动态自动驾驶场景的框架。作者的方法使用增量静态 3D 高斯逐步建模静态背景,并通过复合动态高斯图捕捉多个移动目标。通过利用 LiDAR 先验,作者实现了精确的几何结构和鲁棒的多视图一致性,显著提高了场景重建的质量。DrivingGaussian++ 促进了无需训练的编辑,用于纹理修改、天气仿真和目标操纵等任务,从而能够生成真实且多样化的驾驶场景。在 nuScenes 和 KITTI-360 等数据集上的实验结果表明,作者的框架在重建和编辑任务上均实现了最先进的性能,能够实现高质量的环视视图合成和动态场景编辑。
#后端到端时代:我们必须寻找新的道路吗?
2025年夏天,上一年端到端的热度还没有散去。
即使端到端的概念在各家各显神通的公关稿下已经面目全非;即使面对突然发布的 FSD 的正面竞争,我们还没有获得明显的优势;似乎一夜之间,VLA 的宣传攻势像素级复制去年的端到端。

毕竟,技术切换期是最好的占领用户心智的机会,也是证明团队研发优势的最佳时机。
拿到端到端最大红利的理想汽车,试图用 VLA 来巩固自己的领先优势;用端到端的 Tech Vision 获得珍贵量产订单的元戎启行,希望通过 VLA 提升辅助驾驶的上限;小鹏汽车同样,作为一家以 AI 为核心的公司,早已在xx和 VLA 上深耕多年,把它应用到辅助驾驶中可谓得心应手。
不过,这次似乎和端到端浪潮不太一样。相较于之前行业普遍达成研发共识的局面,这一次不少团队选择了刻意回避。
被公众认为长期处于第一梯队的华为 ADS 明确表示,WA(World Model + Action)才是实现自动驾驶的终极方案;蔚来在低速场景用世界模型展示了一些类似 VLA 的体验,但在对外宣传时却讳莫如深;最近开始用户体验的地平线,虽然表现惊艳,却只强调自己在认真做端到端,对于 VLA 则显得唯恐避之不及。
如果说 2023-2024 年端到端的浪潮是"共识之下的竞速",那么 2025 年的 VLA 则更像是"分歧之中的探索"。
为何?VLA 不够先进吗?还是说观望的团队另有理由?在探究原因之前,我们先看什么是VLA。
什么是 VLA?
VLA,全称 Vision-Language-Action Model,最早在学术界兴起,用于探索如何通过视觉和语言来指导机器人或自动驾驶系统的决策。它的基本思想是:
通过 视觉模块 感知环境;
通过 语言模块 将任务或目标以自然语言的形式表述;
最终由 动作模块将理解转化为可执行的驾驶行为。
换句话说,VLA 试图将"人类的驾驶本能"映射为"可解释的语言指令",再转化为"机器的操作"。在理想状态下,它既能具备端到端的强大感知-决策一体化优势,又能通过语言让系统更具可解释性和可控性。

Wayve 的 LINGO 系列 是 VLA 的代表性探索之一。2023 年,Wayve 发布了 LINGO-1,这是第一个将自然语言与端到端驾驶相结合的模型,能够边驾驶边用自然语言解释自己的决策。2024 年,Wayve 又发布了 LINGO-2,在 VLA 上进一步提升,强调通过语言交互让人类可以更直观地理解和引导自动驾驶系统。具体能力包括:
实时语言提示调整行为(如"靠边停","左转"等);
可向模型提问,如"红绿灯是什么颜色?"并获得实时回答;
提供连贯的驾驶注释,以解释驾驶行为
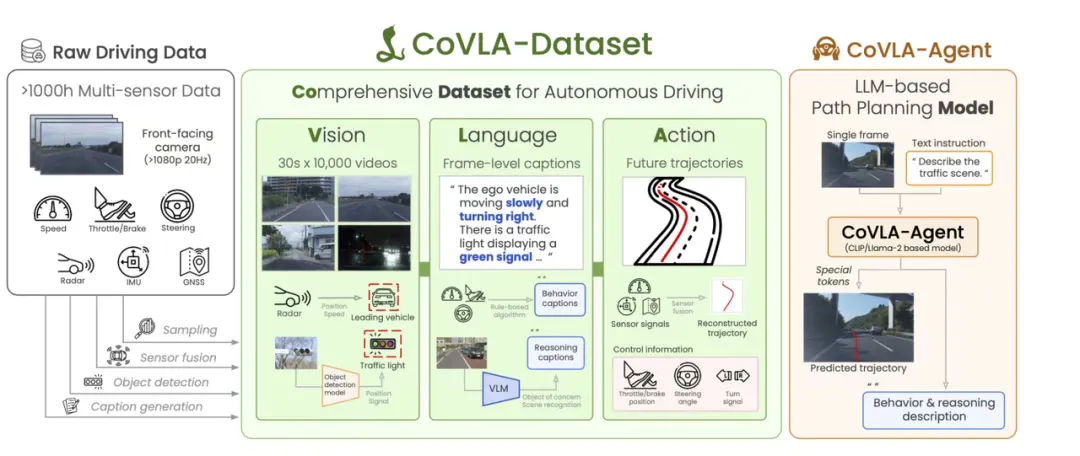
在第一版Lingo发布时,Wayve表示,他们让测试驾驶员,一边执行动作,一边说出自己执行的原因,用这种方式完成语言数据,驾驶动作,感知数据的三方对齐。
而在后续的实践中,随着多模态模型的不断发展,也有了许多直接使用大模型进行语言因果推理进行数据收集的工作,例如CoVLA,就是一种降低数据收集成本的方式。
而OpenDriveVLA将 2D/3D 视觉 token 与语言 进行融合,并通过模型生成控制轨迹,在Nuscenes上取得了最优结果。
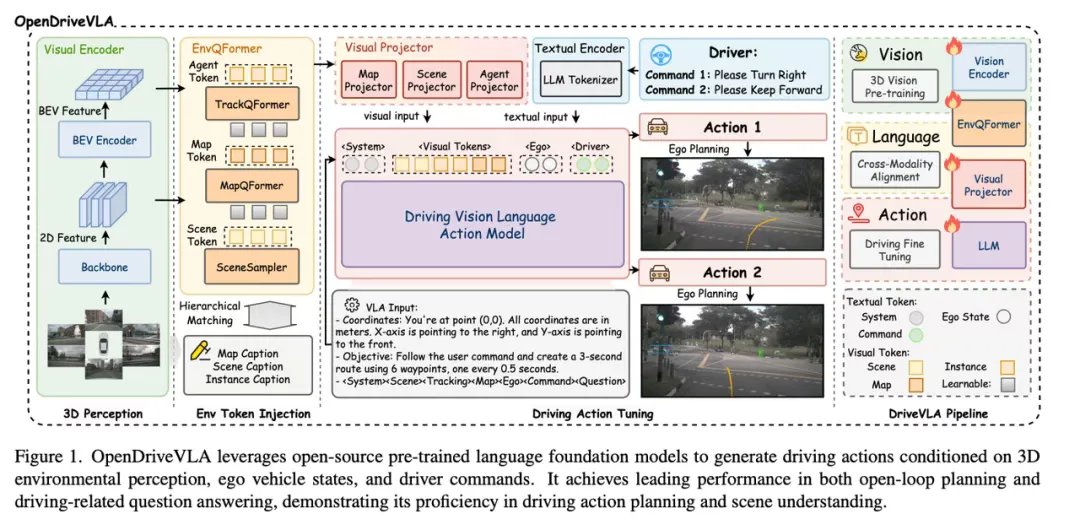
这些研究为 VLA 在辅助驾驶领域的应用提供了理论和工程基础。
同样的,不仅在辅助驾驶领域,在xx领域VLA的应用更加火热,毕竟,这也是xx智能区别于传统机器人公司最重要的特质。
例如Google Deepmind 发布的RT1就将视觉(图像帧)+ 语言任务描述 共同输入给模型,输出低层机器人控制动作,例如末端执行器的位姿等,后续RT2也将网络数据引入,突破了单纯依赖机器人数据的瓶颈,通过 互联网视觉-语言知识 → 机器人控制迁移,提升泛化与推理能力。
一切看上去非常自然,通过网络数据提升认知能力,再迁移到xx智能或者辅助驾驶任务上,自然能够有更好的泛化能力。
优点如此明显,似乎不跟随就会掉队,但是还是不少团队保持着怀疑的态度。
端到端与 VLA 的分歧
VLA 接受了语言给的泛化馈赠,但是所有的礼物都标好了价格。
首先,自然语言在驾驶任务中的表达往往存在模糊性与不完备性:例如"慢一点"或"小心前方"之类的描述缺乏精确的动作约束,而许多驾驶行为(如油门微调、瞬时避让)本身也难以通过自然语言完全描述,回想我们开车的行为,是否所有的行为都能通过语言描述清楚呢?
这种语言-动作不对称性已在多模态学习研究中被广泛讨论。例如OpenVLA就明确表示强调语言主要在任务级别有效,而非细粒度控制。这种"语言-动作不对称"问题导致 VLA 在监督学习中不可避免地存在噪声。
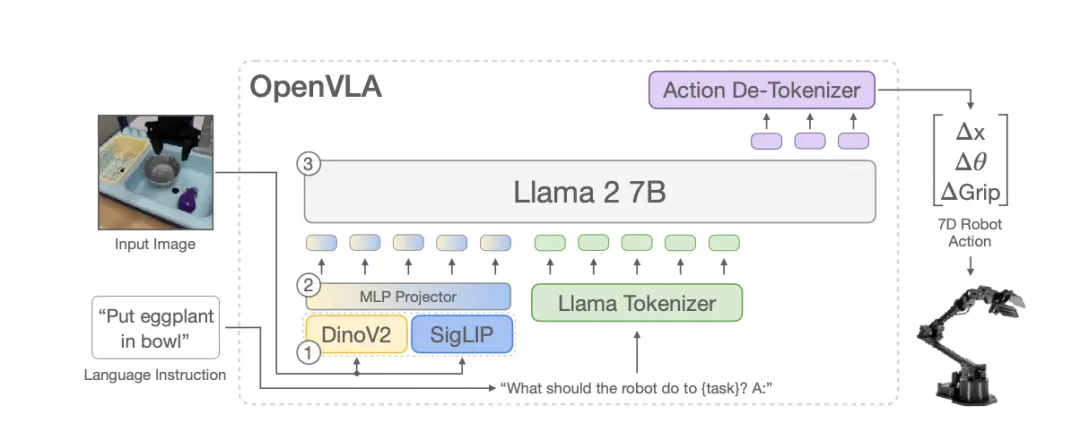
驾驶场景对实时性有极高要求,而多模态 Transformer 同时处理视觉、语言与动作的推理开销远高于传统感知-决策-控制链路。例如典型开源 VLA 模型OpenVLA约7B参数,推理阶段需要约 15 GB GPU 显存,单卡运行约 6 Hz。而目前辅助驾驶行业,一般系统运行速度至少要在10HZ左右。
这意味着 VLA 在实际部署中可能遭遇推理延迟的问题,尤其在需要毫秒级反应的紧急场景下更为突出。需要非常强大的实时算力储备,例如小鹏选择用自研的更高算力芯片来解决这个问题。
不仅如此,语言和空间的对齐关系并不能总是稳定,例如常见的靠边停车指令,有无公交车道,有无自行车道,都存在动作上的歧义。
在这些限制下,实际上,目前行业内辅助驾驶的VLA一般用于上层任务的分配,指令的发放,而轨迹的输出和执行依然由原有模型来完成,也需要一些兜底的方式来防止不合理的输出。
或许也是因为此,部分团队对VLA抱着怀疑的态度,依然选择深入攻克现有的感知输入,动作输出的VA(VisionAction)方案。在足够谨慎训练范式下,即使没有语言模块,VA 模型内部仍会形成对环境状态的向量化表示,可以看作是"内隐世界模型"。例如地平线,华为。
地平线的坚持与结果
在这场分歧中,地平线的态度颇具代表性。这个月,地平线开启了HSD的大规模试驾,媒体们交口称赞,但是问及是否是VLA时,负责人直接否认,这不是VLA。
即使在能够准确识别前方直行可以进入待行区,即使能够对周围的车辆进行危险标识,即使在防御性驾驶上表现非常好,我们依然只得到了一句话,这不是VLA。
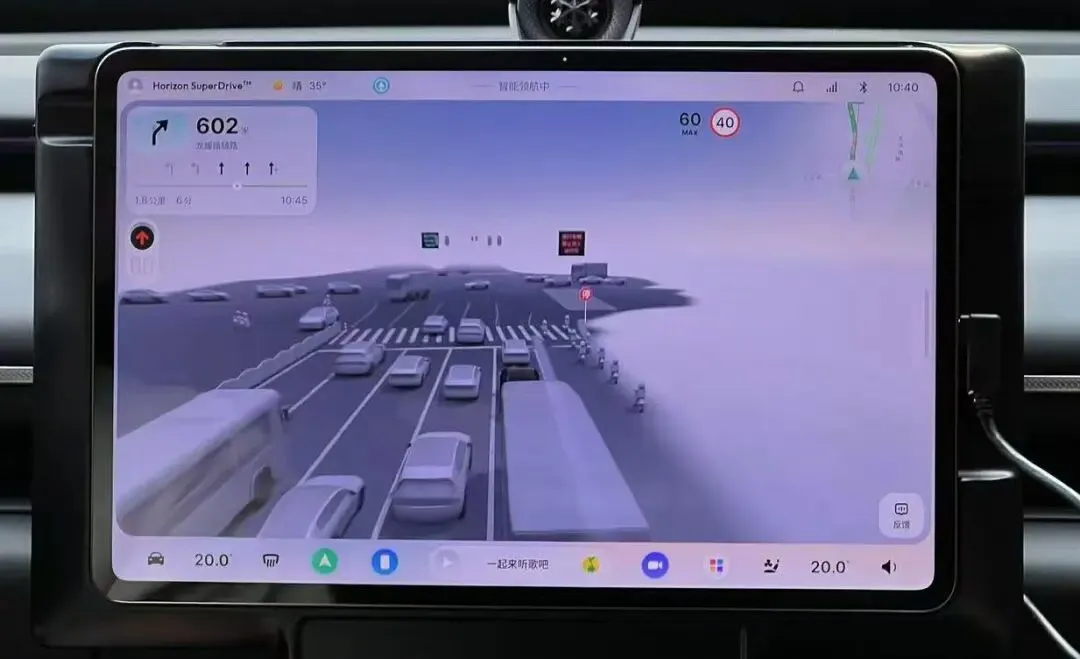
但是我依然感受到了与其他端到端模型的区别,整个系统在试驾的过程中表现非常统一,没有快速和低速时的割裂感,没有低速的过于谨慎,也没有快速的莽撞感。
这其实说明了HSD深度神经网络作为核心决策引擎,充分发挥神经网络的泛化能力。使用了平衡的数据分布。在不同场景和城市环境下,模型实现自适应行为,并在不同道路条件下保持一致的用户体验。
而很明显能感觉到"老司机"驾驶数据得到了充分利用,并对数据进行筛选与优化,确保训练数据最贴合人类日常驾驶习惯。由此训练的模型在决策和动作上更符合人的直觉,从而增强了用户信任。
以下视频来源于
自动驾驶下半场
,时长00:28
在端到端的研发过程中,一定会遇到很多黑盒网络带来的不合理的轨迹和决策,也一定会有团队成员提出我们要不要使用一个外挂的模块,用这个模块去解决这些问题,这样能最快得到结果。
例如施工区域,我们挂一个施工区域规则;不常见的红绿灯,我们再挂一个红绿灯规则;前方我们要右转,但是视野不是很好,我们再挂一个不良视野规则;这些都是非常直觉的做法,也很容易获得更好的结果。
但是做到最后,我们会发现,这还是我们最初设计的端到端吗?
但是似乎地平线不是这么做的,用更难的方式来解决,尽量避免引入非必要的兜底模块,不追求短平快的结果。这保证了系统在 demo 阶段到量产开发过程中的模块最小化,同时维持了整体架构的简洁性和可维护性。乃至于我们试驾的车型上,甚至激光雷达输入也直接被屏蔽了,也要防止感知团队过多依赖激光雷达。
这些都能反映出来,地平线的研发逻辑:如果方向是明确的,就按这个方向去进行,旁枝末节尽量少。这也是一种Stay Focused,在竞争如此激烈,迭代极其迅速的辅助驾驶领域,非常难得。
在研发中的坚持不会白费,众人称HSD为"中国版FSD" 。
以下视频来源于
自动驾驶下半场
,时长00:37
真正的一段式架构降低了时延,横纵向协同控车让方向盘非常稳定,目标位置也很明确。对激光雷达的谨慎使用意味着这一套系统也可以提供纯视觉的版本,加上地平线软硬件一体的方案,也会具备更好的成本优势。
写在最后
从 2023 年马斯克带着 FSD 闯红灯开始,端到端进入了我们的视野。不到三年时间,它从广泛怀疑,到众人追捧,再到成为行业基础名词。
但是端到端的概念并未过时,VLA 某种程度上也是一种端到端系统。我想称现在为"后端到端时代"。
不难发现,即使到了今天,在辅助驾驶领域,我们一直遇到的是缺乏足够对世界理解能力的问题。
语言或许能成为辅助驾驶系统的"另一只眼睛",但是否是必需品,仍未有定论。语言是一种新的输入维度,某种程度上类似激光雷达,高度抽象也具有很好的能力,它能对我们提供帮助,但是辅助驾驶依然没有银弹。
有团队用更大的算力,引入新的语言维度,用VLA来解决问题;而地平线选择用自研的J6P上,用成本相对可控的方式,来解决遇到的问题。
在众人追捧端到端时,我写如果你相信靠端到端就能实现L4,那么你该改行了。在后端到端时代,真正的关键问题可能是:行业究竟需要新的道路,还是需要把脚下的路走得更稳?
我相信每个团队都会有自己的答案,每种答案都会有自己的机会。
参考文献
- Wayve. LINGO-1: Open-loop driving with natural language explanations. 2023. https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/
- Wayve. LINGO-2: Closed-loop Vision-Language-Action driving. 2024. https://wayve.ai/thinking/lingo-2-driving-with-language/
- Arai, H., Miwa, K., Sasaki, K., Yamaguchi, Y., Watanabe, K., Aoki, S., & Yamamoto, I. CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving. WACV 2025. https://arxiv.org/abs/2408.10845
- Zhou, X. OpenDriveVLA: Towards End-to-end Autonomous Driving with Vision-Language-Action Models. 2025. https://arxiv.org/abs/2503.23463
- Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., & Finn, C. OpenVLA: An Open-Source Vision-Language-Action Model. 2024. https://arxiv.org/abs/2406.09246
- Brohan, A., et al. RT-2: Vision-Language-Action Models. 2023. https://arxiv.org/abs/2307.15818
#SmODE
用于生成平滑控制动作的常微分方程神经网络
本文介绍了清华大学李升波教授团队发表于ICLR 2025的研究成果《ODE-based Smoothing Neural Network for Reinforcement Learning Tasks》。该研究创新性地提出了一种使用常微分方程(ODE)的平滑神经元结构,用以替代传统的线性激活神经元。利用此类特殊神经元,团队构建了平滑神经网络(Smooth Ordinary Differential Equations, SmODE),并将其作为强化学习策略网络。该方法在保持强化学习任务性能的同时,显著提升了输出动作的平滑性。
论文地址:https://openreview.net/pdf?id=S5Yo6w3n3f
一.背景
**深度强化学习(Deep Reinforcement Learning, DRL)**已经成为解决物理世界中最优控制问题的有效方法,在无人机控制1、自动驾驶控制2等任务中均取得了显著成果。然而,控制动作的平滑性是深度强化学习技术在解决最优控制问题时面临的一个重大挑战。导致深度强化学习生成动作不平滑的原因主要有两个方面,分别是输入的状态中含有高频噪声干扰,神经网络的Lipschitz常数没有受到任何约束。课题组在ICML2023上提出的LipsNet7从约束神经网络Lipschitz常数上实现了控制平滑,而本研究考虑同时解决导致动作不平滑的两个原因,将平滑性质注入神经元当中。
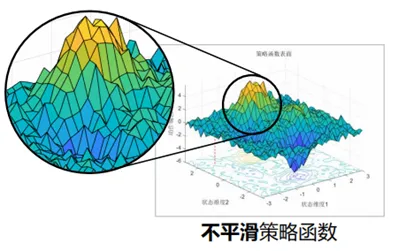
神经常微分网络(Neural ODE)作为一种连续深度学习模型3,其核心思想是通过神经网络参数化常微分方程,从而对连续时间动力学进行建模。该模型借助数值求解器沿连续路径对微分方程进行积分,能够高效处理时序数据,并在物理系统建模、连续控制以及动态系统预测等任务中表现出卓越性能。
传统控制理论中,控制系统的建模与常微分方程密切相关。受此启发,我们尝试从控制理论的视角出发,将控制系统所具备的低通、平滑等特性引入神经元结构设计中。基于这一思路,可将当前研究问题分解如下:
- 如何设计常微分方程,能够实现自适应低通滤波以及对Lipschitz常数的控制?
- 如何设计一种策略网络结构,让其天然具有平滑能力,无需添加滤波器和动作变化率惩罚?
为了解决上述问题,我们提出了一种平滑网络结构 SmODE(Smooth Ordinary Differential Equations)。首先,设计了一种形如一阶低通滤波表达式的常微分神经元,该神经元通过一个可学习的、状态依赖的系统时间常数,实现对高频噪声的动态滤除。随后,研究构建了一个状态依赖的映射函数 g,并从理论上证明了该函数能够有效控制常微分神经元的 Lipschitz 常数。在此基础上,进一步提出了将 SmODE 网络作为强化学习策略的近似器。该方法在训练过程中无需引入动作变化惩罚项,在推理过程中也无需附加滤波处理。
二.SmODE的关键技术2.1 平滑常微分方程设计
为了有效抑制高频噪声,我们设计了一种具有低通特性的常微分神经元。在系统时间常数固定的情况下,尽管较大的时间常数有助于增强平滑性,但往往也会引入明显的响应延迟。当系统对实时性要求较高时,此类延迟可能严重影响控制性能。为此,我们提出通过将输入信号与神经元状态映射至时间常数的倒数,实现滤波强度的自适应调节,具体表达式如下:
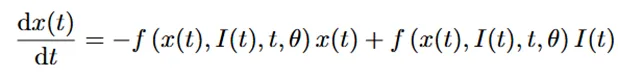
仔细观察上面的公式,Lipschitz 常数的大小可以通过限制等式左侧项的绝对值大小来进行控制。需要注意的是,这种控制也必须是与输入信号和神经元隐状态相关的,这样才能减少对控制性能的负面影响。在这篇论文中,我们将上式最右侧的I(t)替换为一个可学习的映射函数g(x(t),I(t),t,)可以得到
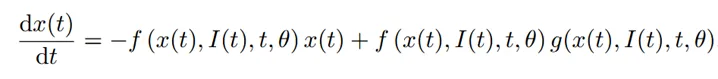
基于上式可以证明
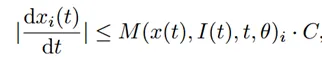
其中
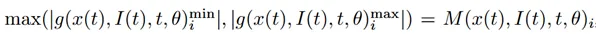
, 是有界的正常数。这个公式表明,一个平滑常微分神经元的隐状态对时间的导数的绝对值有一个上界,这个上界受到 所控制。因此,可以通过限制 来限制 的大小,从而实现 Lipschitz 常数的约束。
受到Lechner et al. 4研究的启发,我们使用仿生建模的方式给出了平滑常微分神经元的具体表达式
其中被表示为,被表示为,被表示为,(其余参数的含义详见论文)。
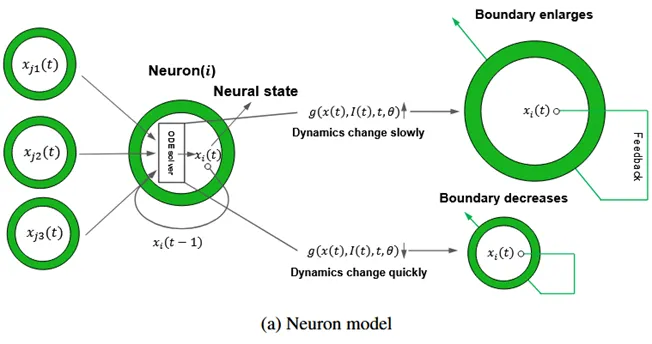
2.2 平滑网络结构设计
利用上述常微分神经元,我们进一步设计了SmODE网络。该网络可广泛应用于各种强化学习框架中作为策略网络。SmODE的架构如下图所示,结构包括输入模块、平滑常微分模块和输出模块(可以根据任务复杂性判断是否需要)。输入模块是一个多层感知器(MLP)网络,输出模块是一个线性变换层,并应用了谱归一化。平滑ODE模块由三层组成,每层中的平滑常微分神经元数量可根据任务的复杂度进行选择。
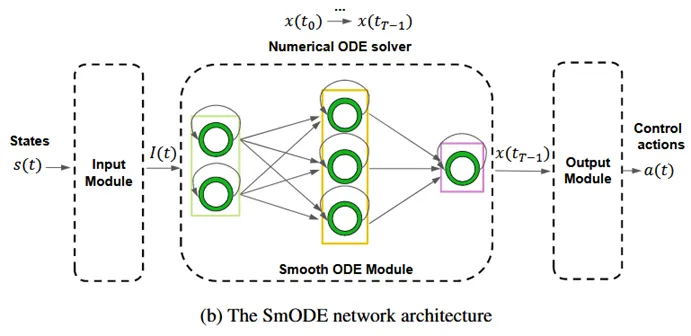
2.3 基于SmODE的强化学习算法
SmODE 作为一种通用策略网络可以很方便的与各类经典深度强化学习算法相结合,本工作将其与课题组提出的DSAC5算法相结合。相较于基本的策略损失函数,本工作需要额外添加限制时间常数和Lipschitz常数的损失项,因此最终的策略损失函数如下所示
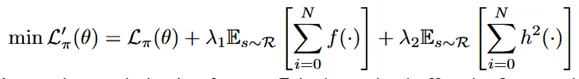
其中lambda1和lambda2是可以调节的超参数,N 是 SmODE 网络的平滑常微分神经元的数量。
算法最终的伪代码如下所示

三.实验结果
在高斯噪声方差为0.05的条件下,我们对使用MLP和SmODE作为策略网络进行正弦曲线和双车道变换曲线跟踪的实验结果进行了分析,显示出明显的差异。我们使用MPC算法作为无噪声环境下的对比基准。如下图所示,SmODE不仅表现出比MLP更低的动作波动率,还在横向速度变化方面具有更小的波动,从而提高了车辆的舒适性和安全性。
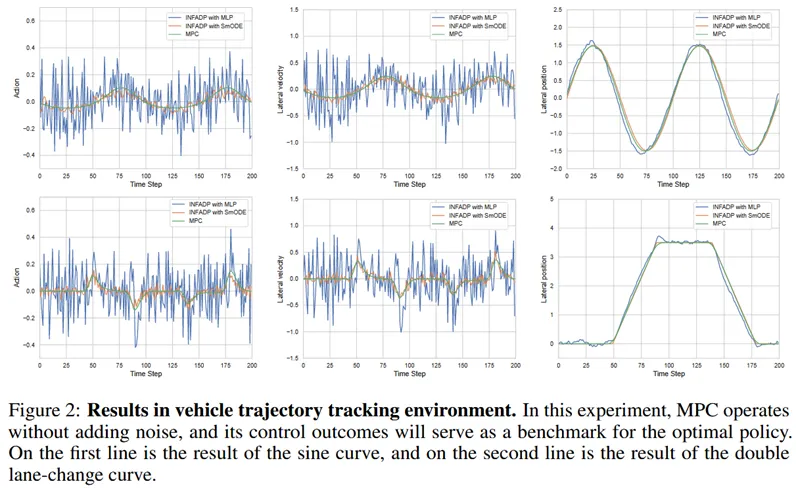
此外,我们在MuJoCo6基准中也进行了测试。我们采用了DSAC作为基础的强化学习算法,并将策略网络配置为MLP、LipsNet7、LTC8和SmODE。在评估过程中,我们在两种高斯噪声水平下进行实验,以模拟不同的现实世界条件。由于不同Mujoco任务的状态值差异较大,我们为八个任务设置了两种高斯噪声水平,如下表所示

在不同高斯噪声水平下,作为策略网络的SmODE相比于LTC、LipsNet和MLP获得了最低的平均动作波动。此外,SmODE在大多数MuJoCo任务中表现出最好的性能。考虑到对动作平滑性和高性能的追求可能存在一定的矛盾,因此并非在所有的实验设置中都能获得最佳的表现是可以理解的。
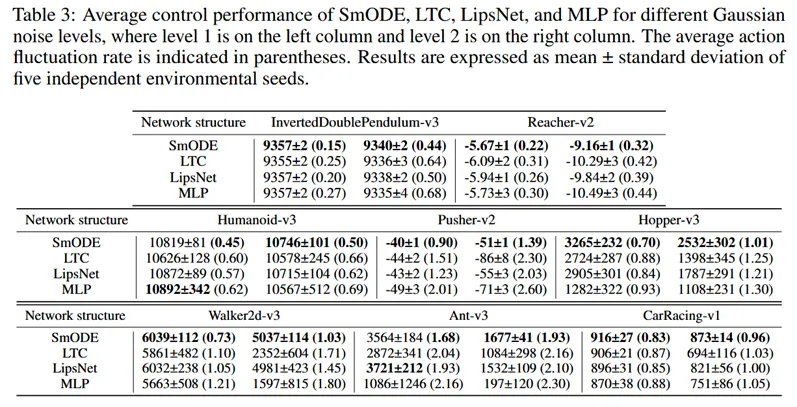
四.总结
在本研究中,我们提出了一种平滑网络结构,旨在缓解深度强化学习中动作输出存在震荡的问题。该网络将常微分方程作为神经元的核心组件,不仅能够实现自适应的低通滤波,还具备对Lipschitz常数的有效控制,从而增强了神经元对输入扰动的抑制能力。作为一种策略网络,与传统的多层感知机和LipsNet相比,SmODE能够有效抑制动作输出震荡的问题,显著提升了各种强化学习任务中的平均回报。我们期望其能够为现实世界中的强化学习应用提供新的思路,并推动该领域的进一步发展。
五.参考文献
**1** Kaufmann E, Bauersfeld L, Loquercio A, et al. Champion-level drone racing using deep reinforcement learningJ. Nature, 2023, 620(7976): 982-987.
**2** Guan Y, Ren Y, Sun Q, et al. Integrated decision and control: Toward interpretable and computationally efficient driving intelligenceJ. IEEE transactions on cybernetics, 2022, 53(2): 859-873.
**3** Chen R T Q, Rubanova Y, Bettencourt J, et al. Neural ordinary differential equationsJ. Advances in neural information processing systems, 2018, 31.
**4** Lechner M, Hasani R, Amini A, et al. Neural circuit policies enabling auditable autonomyJ. Nature Machine Intelligence, 2020, 2(10): 642-652.
**5** Jingliang Duan, Yang Guan, Shengbo Eben Li, Yangang Ren, Qi Sun, and Bo Cheng. Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors. IEEE Transactions on Neural Networks and Learning Systems, 33(11):6584--6598, 2021.
**6** Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In Intelligent Robots and Systems, 2012.
**7** Song X, Duan J, Wang W, et al. LipsNet: A smooth and robust neural network with adaptive Lipschitz constant for high accuracy optimal controlC//International Conference on Machine Learning. PMLR, 2023: 32253-32272.
**8** Hasani R, Lechner M, Amini A, et al. Liquid time-constant networksC//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(9): 7657-7666.
#端到端自动驾驶的万字总结
拆解三大技术路线(UniAD/GenAD/Hydra MDP)
看到一篇非常不错的内容,想给大家分享一下
我们来看一下端到端自动驾驶算法的当前发展状况,并进行简要总结。首先,探讨端到端算法的研究背景。端到端算法框架是什么?它与传统算法有何区别?
我们来看这个 pipeline 的第一行,这是传统自动驾驶算法的流程:先进行感知,然后预测,最后规划。每个模块的输入输出不同。
感知模块 的输入是图像或激光雷达数据,输出边界框作为预测模块的输入;预测模块 输出轨迹,再进行规划。这是传统算法的流程。
端到端算法 的输入是原始传感器数据,直接输出路径点。输出路径点与控制信号本质相同,因为从路径点到控制信号有固定算法转换。此外,回归路径点相对容易,因此多数算法选择输出路径点。
传统算法的优点是易于调试和问题定位,具有一定的 可解释性 。缺点是存在 误差累积 问题,因为无法保证感知和预测模块完全无误差。
小编这里也推荐下xxx最新推出的《端到端与VLA自动驾驶小班课》,课程全面梳理了BEV感知、VLM、强化学习、扩散模型等当下端到端自动驾驶的主流范式,非常适合研究生小白入门和转行进阶的小伙伴,课程详情参考:端到端与VLA自动驾驶小班课(一段式/两段式/扩散模型/VLA等)
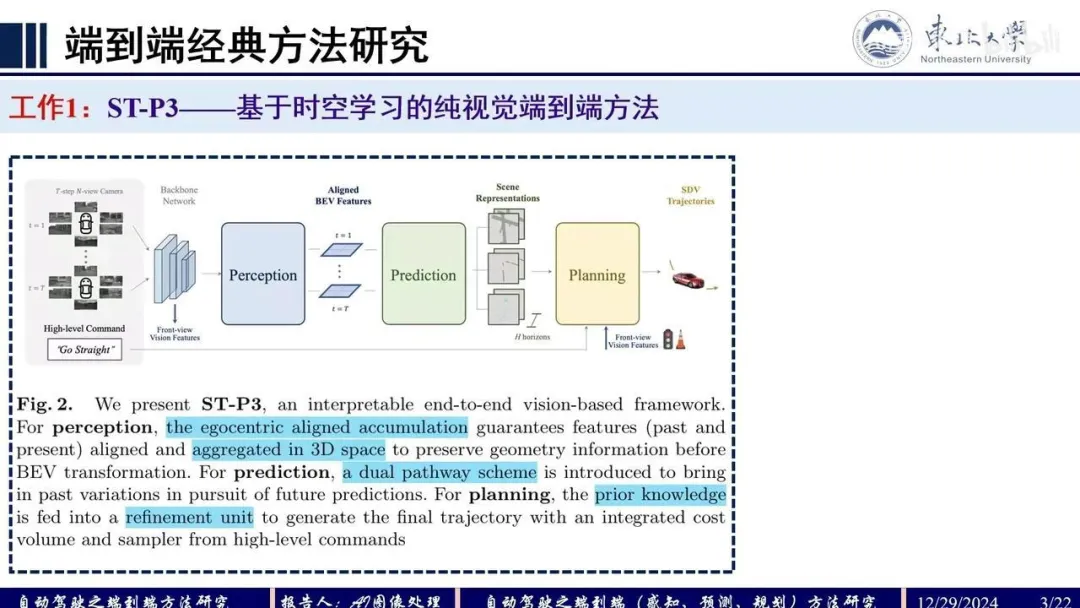
同时,感知信息的原始数据存在一定的信息损失。在预测时,仅输入了感知的输入结果。
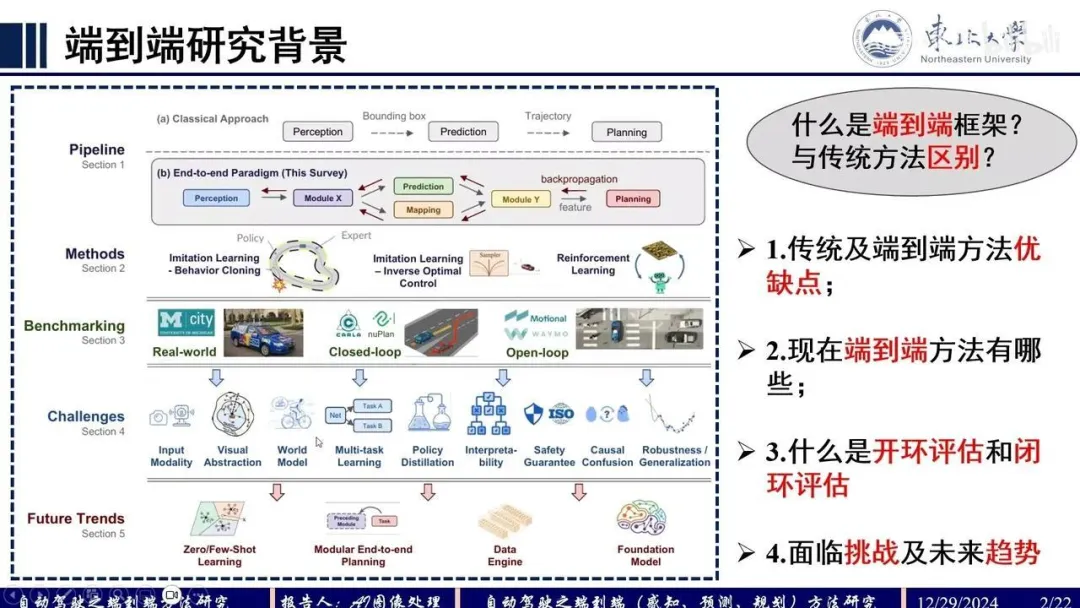
然而,它并未与初始感知信息进行交互。传统端到端算法并非没有缺点。通过大量文献阅读发现,多段多算法也存在局限性。例如,当前常用范式是通过模仿学习实现,但这种方法难以有效解决所有corner case问题,主要因其数据驱动的特性。
若在数据集中加入少量corner case样本,模型可能将其视为噪声而无法充分学习;若增加corner case样本比例,又会影响常规操作性能。此外,真值数据本身存在噪声,在某些场景下人类驾驶数据并非完全最优解,因为规划问题本身不存在绝对固定的最优解。因此,模仿学习方法存在固有局限性,端到端数据驱动算法的能力目前仍有限制。
关于端到端算法的现有范式,综述中总结了以下几种:模仿学习 可分为行为克隆(论文中较常见)和逆优化控制(论文中较少见);强化学习 方法在论文中也不常见。此外,评估方法可分为开环和闭环两种:闭环评估 中,自车与环境存在交互,执行动作会影响他车,信息随时间推移动态变化;而开环评估则使用固定场景数据。
当前面临的挑战包括可解释性问题、安全保证以及因果混淆现象。以因果混淆为例:当车辆在中间车道直行,因红灯停车后绿灯起步时,模型可能并未学习到"绿灯起步"这一因果关系,而是误将旁边车道车辆起步作为启动信号。
在起步阶段,若周围无其他车辆且信号灯为绿灯时,系统可能出现沙瓶效应 。这属于因果混淆的典型案例,在传统算法中构成显著挑战。此外,该系统还需解决输入模态多样性、多任务学习及知识蒸馏等技术难题。
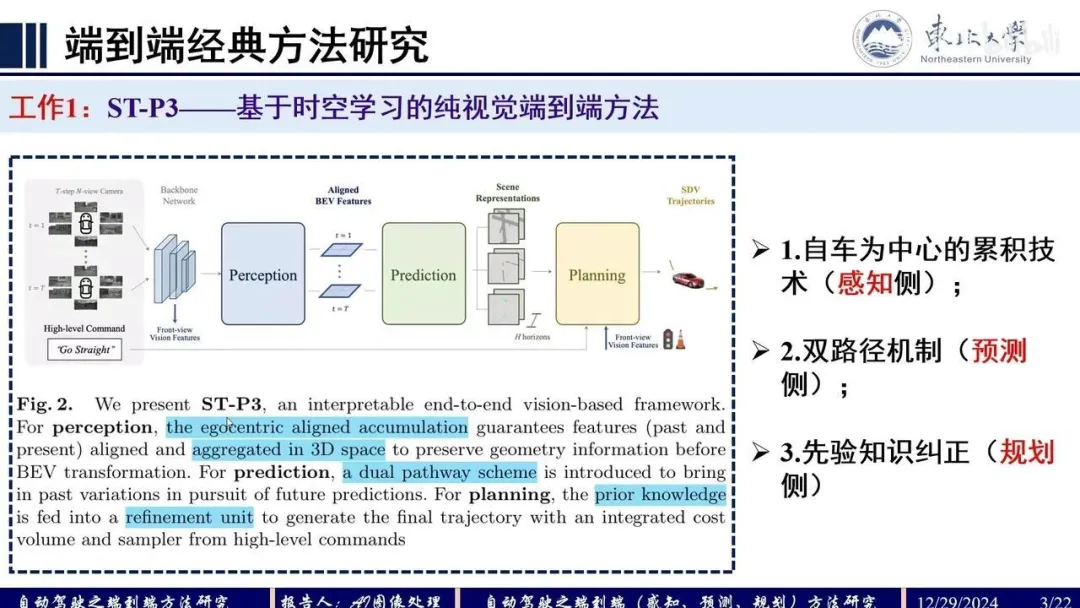
接下来,我们将探讨当前经典的端到端自动驾驶算法的实现方式。
首先介绍的是ST-P3算法,这是一篇较早关于端到端自动驾驶算法的论文。该算法基于时空学习,专注于端到端自动驾驶的实现。其整体框架如下:输入为环视相机图像,明确设计了三个核心模块------感知、预测和规划,最终输出自动驾驶车辆的轨迹。
该论文的创新点主要体现在感知、预测和规划三个方面:
- 感知模块:采用了一种以自车为中心的累积对齐技术。
- 预测模块:通过双路预测机制实现。
- 规划模块:引入先验信息对生成的轨迹进行优化。

我们来看具体的细节。
首先,在感知模块中,右上角的公式表示输入图像信息CHW。对特征进行提取后,结合预测的深度信息DK,采用类似LSS范式的方法,通过图像特征和深度特征进行插值,得到微点云的空间表示,即BEV空间。这里生成的是一个UdVDD1维度的微点云信息。
该方法的创新点在于考虑了RO角和PG角不为零的情况。传统BEV算法假设地面平坦,即RO角为零。而该方法对3D微点云信息进行对齐处理后再投影到BEV空间。此外,还进行了时序融合,为每个时序特征赋予权重,类似于注意力机制的操作,并在特征通道上增加了自车维度。
在预测模块,采用双路结构。第一路输入为X1到ST时刻的感知特征,通过GRU进行递归处理;第二路考虑到感知特征预测的不稳定性,引入高斯噪声进行前向迭代,同时利用当前T时刻特征作为hidden state进行递归更新。将两路预测输出融合,得到T+10、T+20时刻的状态特征。
基于预测模块的表征,进行解码操作。主要通过实例分割实现,涉及agent信息和地图信息。其中agent信息包括行人检测、中心点定位和位移预测等。
在构建地图信息时,通过分割头生成高清地图。预测模块的前向传播逻辑较为简单。规划阶段的创新点在于 :利用前视相机获取红绿灯信息,并对预测轨迹进行优化(Refinement)。具体流程为:选定最终轨迹后,将红绿灯编码输入GRU网络进行解码,输出最终的预测轨迹。
优化过程包含两大组成部分:
- 自车预测轨迹的代价函数(Cost Function):
- 考虑与前车的距离
- 车道分隔线的距离
- 横向和纵向加速度信息
- 轨迹终点与目标点之间的距离(Progress Cost)
- 预测轨迹与真实轨迹之间的L2距离
- ST-P3的规划方法综合考虑了上述因素。
接下来我们讨论第二个工作UniAD。
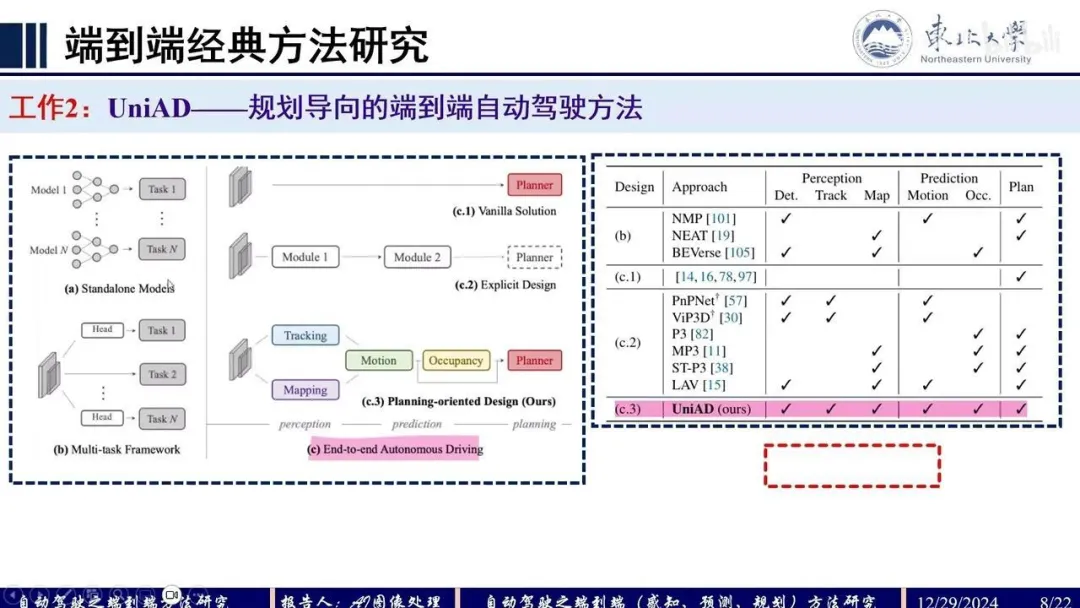
首先,这是Introduction部分的一张图,对比了ABC三种范式的优缺点。模块堆叠方法存在误差累积和信息损失的问题 。多任务框架在同时训练Task1和Task2时会产生负迁移效应,即任务间存在相互影响。右侧展示了端到端自动驾驶的三种范式:
- 原始方法直接通过特征回归轨迹(Planning),但可解释性差且优化困难;
- 显式模块化设计方法,如ST-P3仅使用了Map、Occ和Plan三个模块;
- UniAD的创新点在于引入了五个代理任务(Head Task),通过增加任务数量提升性能。

该系统采用全Transformer框架,以规划为导向,构建端到端自动驾驶系统。
首先,在Backbone 部分与BVFormer相同,获取BEV特征。Transformer部分则借鉴MOTR框架。MapFormer将Segformer的2D版本扩展至3D,用于实例分割:前景包括分割线、边界线和人行道,背景则为可行区域。
MotionFormer通过三种交互进行预测:Agent之间的交互、Agent与地图的交互,以及Agent与目标点的交互。输出包括预测轨迹、特征及每条轨迹的评分。OccFormer利用MotionFormer的Agent级特征作为KV,BEV特征作为Q,计算实例级的占用情况。其中,Agent级特征与场景级特征通过矩阵运算得到最终结果。
Planner的输入包括:自车运动轨迹特征(来自MotionFormer)、位置编码、OccFormer的输出以及BEV特征。规划时需考虑未来占用情况,确保选择可行区域。具体实现细节如下:
- MapFormer部分基于MOTR框架,TrackFormer输出的NA代表动态变化的Agent数量。
- 主要负责预测Agent的数量。TrackFormer部分涉及N×256维度的QA模块,用于表征Agent的特征,即EBTQA(Agent的特征表示)。PA和QM模块分别对应NM×256的维度。
- 关于TrackFormer,其框架与MOTR类似。在t=1时刻,初始化的detect query作为输入,此时track query为空。输入到decoder后,输出的预测框完全由detect query生成。经过detect decoder的特征更新后,进行特征交互,生成track query。该query与下一帧的detect query共同输入decoder,输出t=2时刻的预测框。特征在decoder后进一步进行时序交互,实现迭代推进。TrackFormer的核心思想在于track query与detect query的协同更新。
- MapFormer部分主要完成实例分割,通过前景与背景的分割头实现。
- MotionFormer的框架如下:左侧为MotionFormer模块。
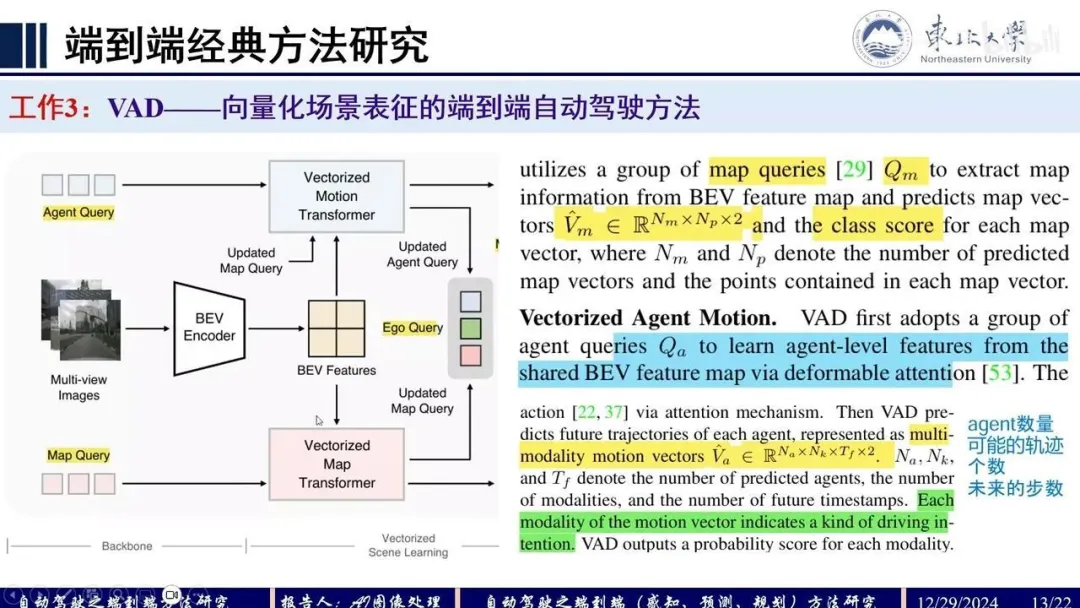
该系统由三个交互模块组成:Agent、Map和Ego 。这三个交互模块相对容易理解,而较难理解的是位置编码的生成方式。具体来说,位置编码分为Agent级别和场景级别两种。
对于Agent级别的位置编码,首先对所有Agent在数据集中进行聚类,通常聚为六类,然后以各类的中心点作为Anchor的位置编码。
对于Map的位置编码,需考虑全局场景信息。具体方法是将局部视角下的Agent坐标通过旋转矩阵和平移矩阵投影到全局坐标系下进行转换,从而得到场景级的位置编码。其中,表示当前时刻初始化的位置编码,表示上一层预测轨迹的终点作为位置编码。这些编码经过MLP处理后相加,作为后续三个交互模块的位置编码。
在交互过程中,Agent与Agent之间先进行自注意力计算,再进行交叉注意力计算。交叉注意力是与BEV特征进行的。Agent之间通过自注意力机制评估各Agent Query的重要性。Agent与Map之间进行交叉注意力计算,而Agent与Ego之间则采用可变形注意力机制。
最终,将三个模块的输出、、拼接后通过MLP生成当前时刻的运动特征表征,再经过另一个MLP进行评分,同时解码出相对轨迹。此时Motion Former输出的表征将用于后续处理,即。
在OCC模块中,首先对BEV特征进行表征。通过自注意力机制处理后,结合Agent级特征和运动预测输出的BEV特征进行交叉注意力计算。将得到的Qx特征相加,获得t时刻的DB表征。随后,将场景级密集表征与Agent级表征进行矩阵乘法运算,预测未来时刻的占用情况。
未来时刻的BEV表征通过迭代输出的特征块获得,经解码器处理后得到场景级占用情况。再与实例信息进行矩阵运算,最终输出实例级别的未来占用预测。这就是OCC Former的核心机制。
在规划模块中,首先整合转向灯信号和自车Agent特征。Transformer模块会融合自车轨迹表征,并在Motion Former中进行交互更新。将更新后的自车表征、轨迹表征以及规划查询(Planning Query)通过MLP和MaxPool处理,生成规划token。
该规划token作为查询向量,与BEV特征作为键值对进行匹配,生成初始轨迹。通过碰撞优化(基于OCC模块的输出)最终输出优化后的轨迹表征。这就是Planning Former的主要流程。
VAD(Vectorized Autonomous Driving) 采用矢量化表征方法,其前身MapTR和MapTRv2将栅格化表征转换为矢量化形式。这种方法能更好地表达地图元素的结构信息,保持其几何特性。矢量化表征在表达结构化信息方面具有显著优势。
其计算速度较快,因此他们尝试将矢量表征应用于短程纵向规划。该矢量表征与传统的感知方法类似,包含运动矢量(motion vector)和地图矢量(map vector) 。具体实现方式为:通过输入地图查询 (map query),经地图变换器 (map transformer)处理后预测地图矢量;通过智能体查询(agent query)预测运动矢量。随后将自车查询与这两个更新后的查询进行交互,输出自车查询结果。更新后的自车查询再与车辆状态信息及指令信息结合,进行规划决策。
在规划过程中引入了矢量化的规划约束,主要包括三个约束条件。本文创新点集中在这两部分:约束条件和矢量表征。具体细节如下:
- 在感知部分,地图查询(Map Query)采用数百个256维的查询向量,预测得到NM×NP×2维的地图矢量及其类别分数。其中,2表示坐标点维度,NP表示每个矢量的点数,NM表示地图上的矢量总数。
- 在智能体部分,通过类似于地图查询的QA机制,采用可变形注意力(deformable attention)学习智能体级别的表征。具体流程为:首先通过可变形注意力与共享的鸟瞰图(BEV)特征进行交互,再利用该表征预测运动矢量。这里预测的是智能体数量及其可能的轨迹模态(K表示轨迹条数)。
这表明了每个轨迹的驾驶意图(Driving Intention)。TF代表未来的时间戳,R则表示未来轨迹点的坐标情况。通过这种Query机制,我们可以预测出相应维度的向量(Vector)。这一部分最终关联到自车的状态。
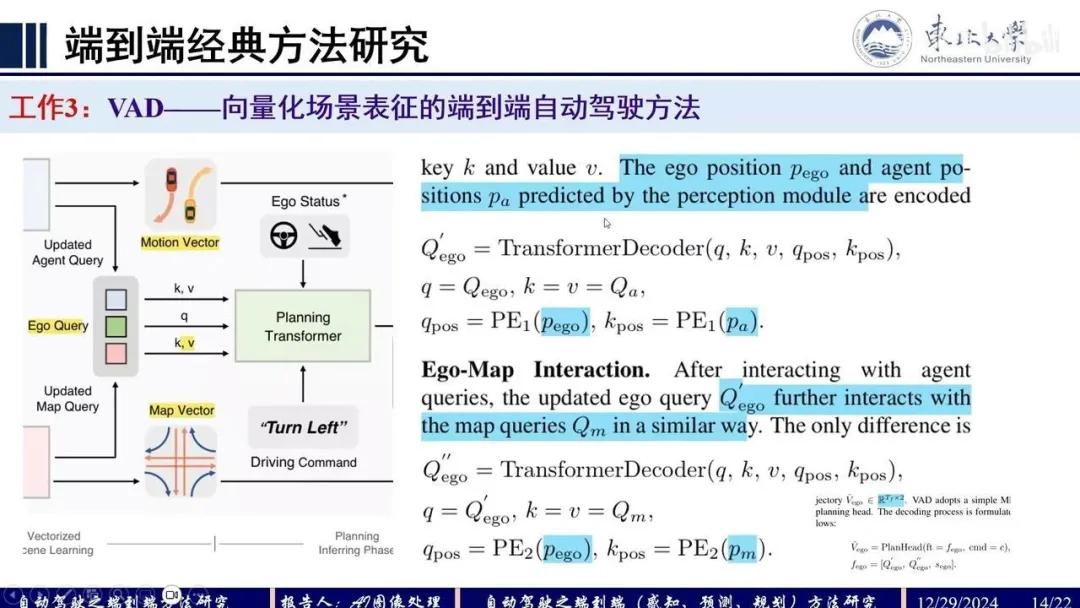
我们通过初始化的自车Query与先前的Motion Vector和Map Vector进行交互。交互过程采用纯Transformer Decoder架构,其中需要位置编码。位置编码来源于感知模块输出的自车和Agent坐标信息。
完成自车与Agent的交互后,再与Map进行交互。该结构与前述类似,但MLP编码部分采用了独立的新MLP。获得自车Vector后,进行预测,输出未来2024年12月29日时刻的确定性轨迹坐标点。
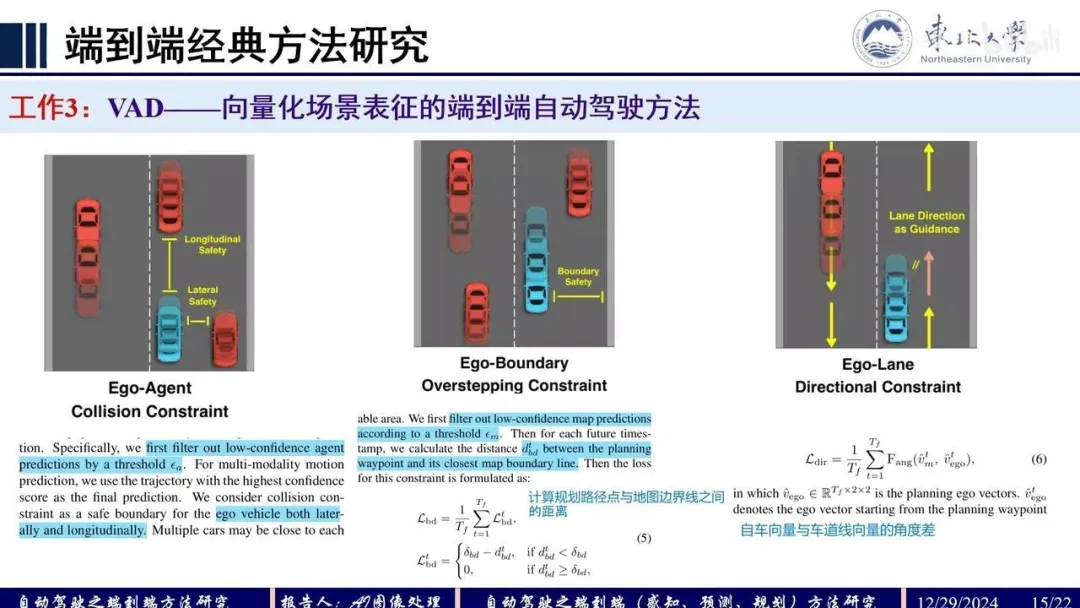
最优轨迹的输出需要考虑多个约束条件。该系统引入了三个主要约束:
- 自车与他车之间的碰撞约束,涉及横向和纵向距离;
- 自车与边界之间的距离约束,通过判断规划路径点与地图边界线之间的距离来实现;
- 自车方向约束,通过计算自车向量与车道线向量之间的角度差来确保行驶方向正确。
这些约束条件通过量化处理,并在规划过程中加入基于成本的抑制机制。
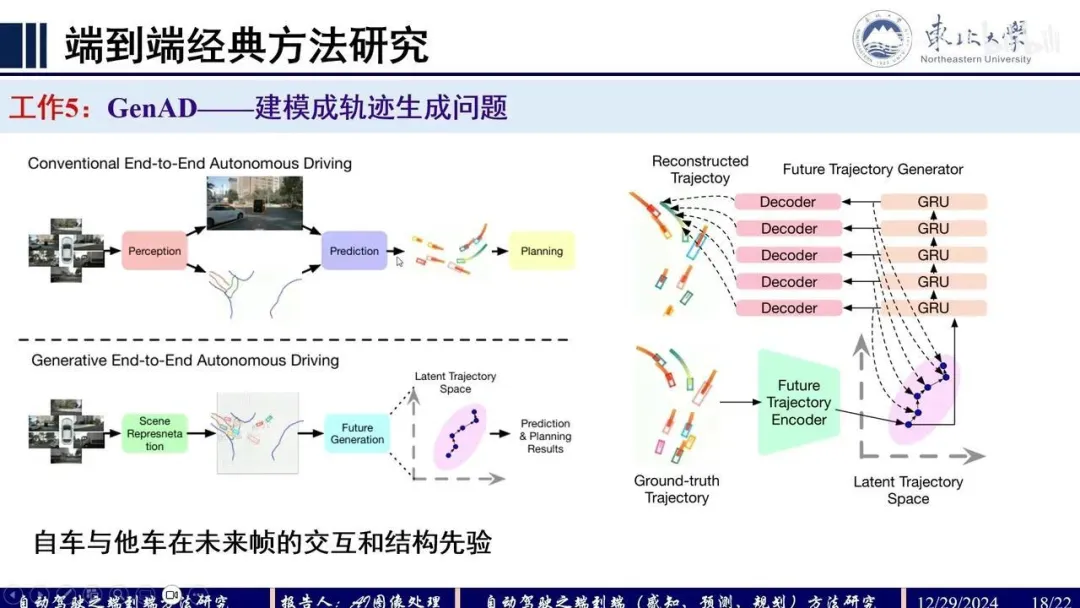
整个思想如下。他们的第二篇工作认为规划是一个不确定性任务 ,确定性方法无法处理掉头等情况。如图所示,作为红车,当前车处于此状态时,可以选择跟车或向右变道。若输出确定性轨迹,当存在两条真实轨迹(GT)时,模型会学习到中间状态的轨迹,容易导致碰撞。而本文采用概率化表征方法,将规划流视为概率分布,从而选择最优轨迹而非模糊折中方案。类似情况下,车辆可选择直行或向左变道,但确定性方法会学习中间表征导致碰撞风险。概率表征则能选择最优轨迹避免此类情况。
具体实现借鉴了类似GPT的ARP思想:首先初始化动作空间(action space),并将其离散化。连续的动作空间(如加速到10km/h、20km/h等)难以直接表征,故离散化为10、20、30等离散值。规划词汇表(planning vocabulary)可理解为字典,类似ARP中将字词存入字典供解码器选择。本文收集了4096种可能动作,如直行、加速至20km/h、刹车、左转、右转等,编码后生成planning token。通过场景token与planning token交互,结合自车状态和导航信息,预测动作分布并选择最优轨迹。
每个分布对应不同的运动概率,系统会选择概率最高的标准轨迹作为规划结果。这是该方法的核心思想。
针对左侧场景级分割部分,其动作空间采用五维连续表征。具体实现中,每个动作在规划词表中表示为一个路径点,通过将动作序列转化为路径点序列,便于后续编码处理。例如:加速至10公里/小时、加速至20公里/小时、左转、加速左转、加速右转、减速左转等不同运动状态都对应特定的路径点编码。
整个流程可以概括为:规划标记(planning token)直接与场景特征进行Transformer交互。其中,env代表场景级表征,ea表示对动作空间路径点的位置编码。位置编码函数τ的具体实现是将所有路径点与0到21维的特征拼接后进行编码,最终输出最优概率表征。
GenAD工作将自动驾驶建模为轨迹生成问题。不同于传统"感知-预测-规划"的级联方法,该方法考虑了自车与他车在未来帧中的交互,采用类似VAE的生成式建模思路:训练时学习轨迹分布,推理时采样分布并通过解码器生成路径点。关键点在于训练过程中如何构建有效的监督信号,这与VAE的训练思想一致。
将GT的track query trajectory通过编码器进行编码,得到latent space的轨迹表征。随后通过解码器重构当前轨迹,并将重构轨迹与原始真值轨迹进行监督训练。
在推理阶段,由于没有真值输入,直接利用学习得到的latent space表征作为输入,生成一个分布。通过采样该分布并解码,最终重构出轨迹。这是该方法的核心思想。
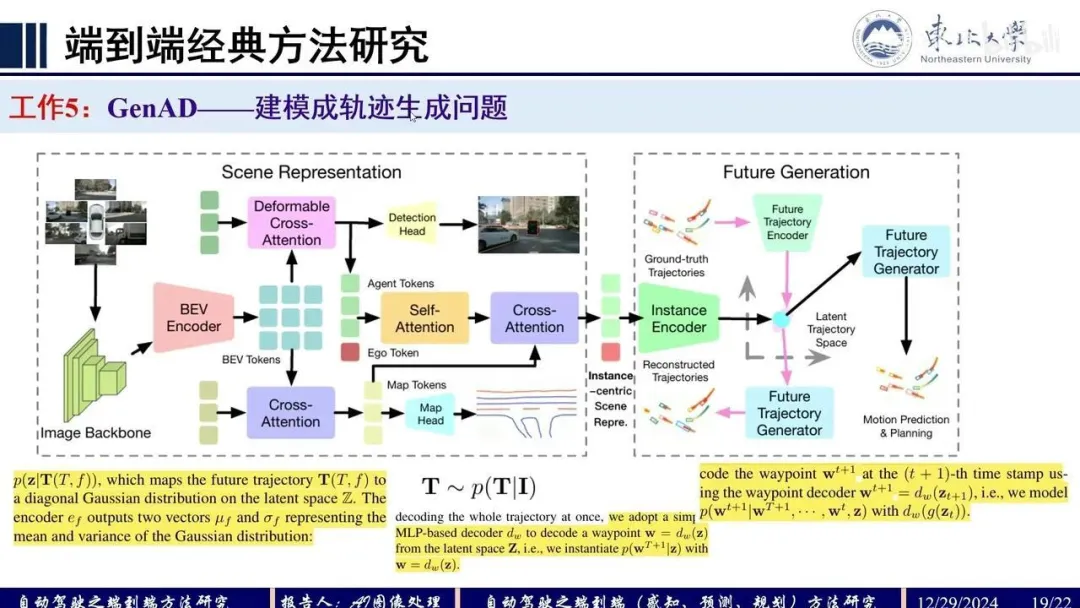
具体而言,左侧通过 token 之间的 cross attention 进行分割处理,输出以自车为中心的 BEV 场景表征,并输入到 InstanceGP Encoder 中。
在推理阶段,输出点分布采样后直接生成未来轨迹,通过 decoder 完成行为预测与规划。而在训练阶段,则利用 ground-truth 轨迹通过 encoder 编码得到分布,再经 decoder 解码生成重建轨迹,二者之间建立监督关系。
接下来,我们分析英伟达的研究成果。

在前人工作的基础上,本研究引入了更多约束条件进行训练。先前模型采用单模态 规划方法,即直接通过感知信息回归预测轨迹。而本研究提出多模态规划方法,以解决轨迹预测的不稳定性问题。该方法通过预测多个候选轨迹并选择最优轨迹进行模型学习。
具体而言,单模型 学习仅预测单一轨迹,而多模型学习 则预测多个轨迹。本研究结合了多模态规划与多模型学习方法,并在多轨迹预测的模型学习损失基础上,增加了知识蒸馏损失。该蒸馏损失来源于多种基于规则的教师模型,这些教师模型的结果通过仿真获得。
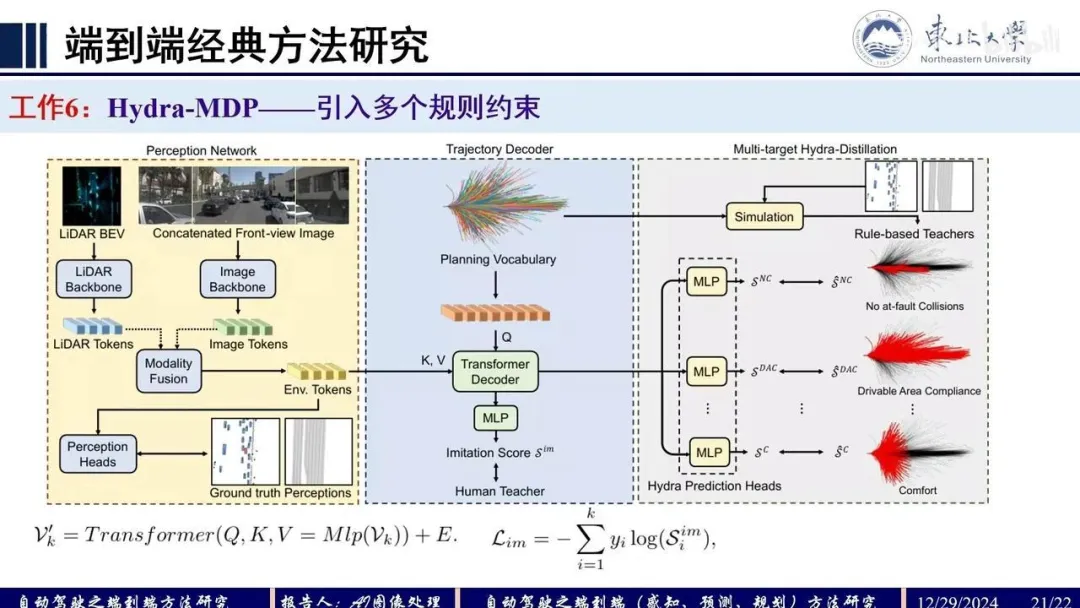
接下来,我们将模型的预测结果用于监督学习。该研究通过引入更多监督信息来提升模型性能。具体而言,其监督框架如下:
左侧模块采用TransFuser架构 进行多模态融合,生成感知token。轨迹解码器 (Trajectory Decoder)部分延续了VADV2中的规划词表(Planning Vocabulary)设计,通过Q向量与KV向量的交互进行编码,这与VADV2的处理方式基本一致。
额外监督信号来源于:将统计轨迹数据置于仿真环境中,生成基于规则的教师信号 (Rule-based Teachers)。多层感知机(MLP)模块主要监督以下指标: 1. 无责任碰撞(No at-fault Collisions) 2. 可行驶区域合规性(Drivable Area Compliance) 3. 驾驶舒适性(Comfort)
这些监督指标均被纳入回归损失函数进行反向传播。其中,无责任碰撞特指非系统行为导致的碰撞事件。本文可视为VADV2研究框架的扩展。
当前端到端自动驾驶算法仍主要采用模仿学习框架,但存在以下局限性: 1. 作为纯数据驱动方法,其优化过程较为困难 2. 难以学习到最优真值(Ground Truth) 3. 对异常案例(Counter Case)的处理能力有限
这些方面仍有待进一步研究探索。关于端到端算法的讨论就到这里。