C#摄像头采集数据,训练模型,进行物体识别
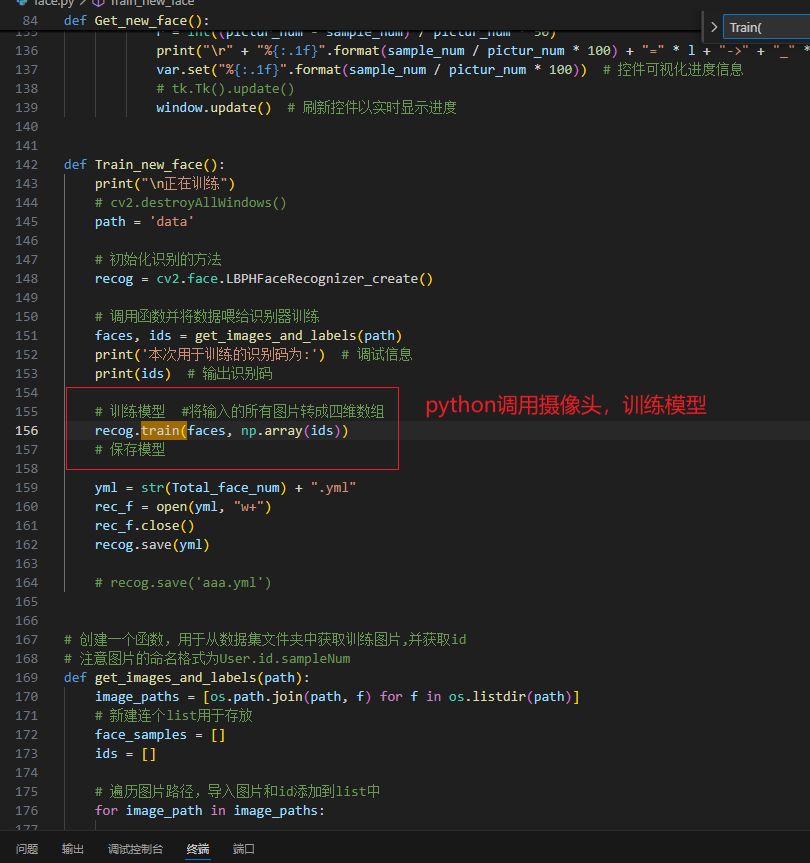
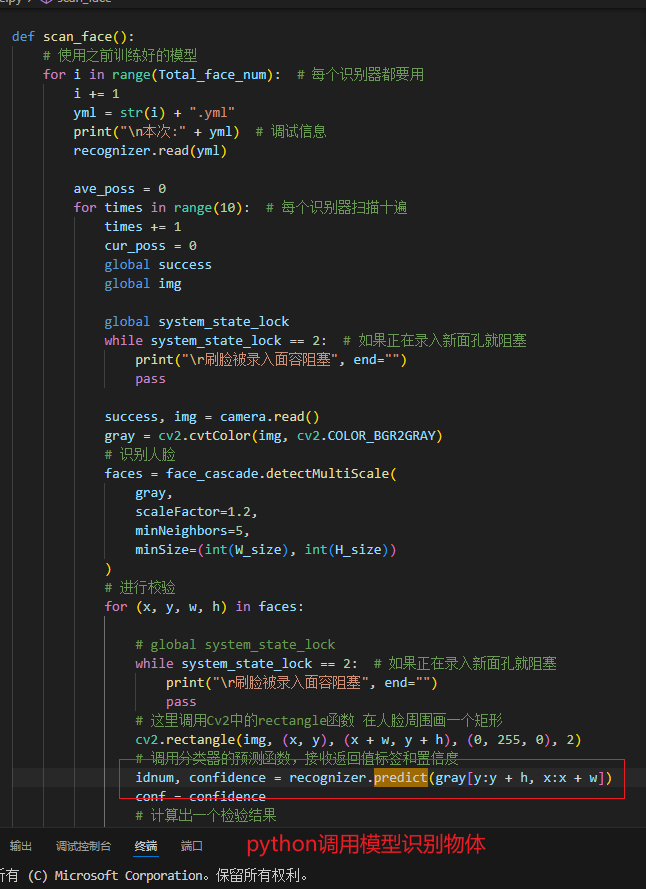
python摄像头采集数据,训练模型,进行物体识别
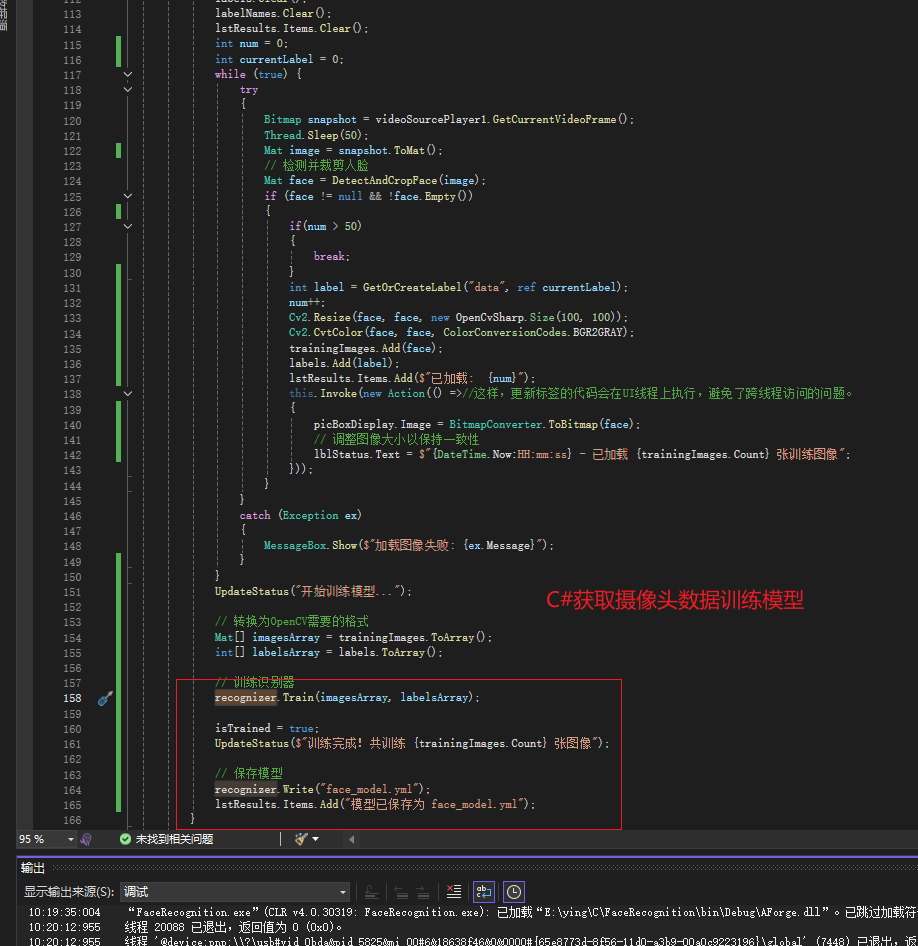
1.模型训练
训练模型,物体识别(opencv)
recognizer.Train()(训练)方法:
用于训练一个模型。它会根据提供的训练数据(如图像和对应的标签)来学习特征和模式,从而建立一个能够进行预测的模型。
训练过程可能涉及调整模型内部的参数,以最小化预测错误。
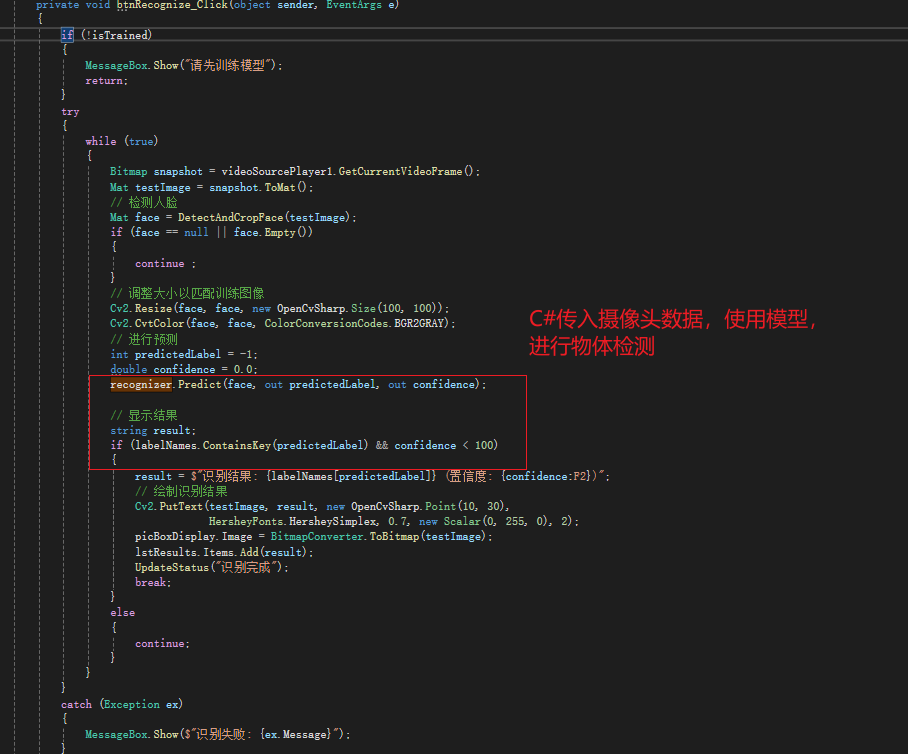
recognizer.Predict()(预测)方法:
使用已经训练好的模型来对新的输入数据进行预测。
例如,在人脸识别中,你可以输入一张新的人脸图像,然后模型会预测这个人的标签(即是谁)。
recognizer.Write("face_model.yml")(保存模型支持.xml和.yml) 方法:
生成模型
2.基类模型
车牌的识别:haarcascade_russian_plate_number.xml
人脸的识别:haarcascade_frontalface_default.xml
全身的识别:haarcascade_fullbody.xml
人体上半身的识别:haarcascade_upperbody.xml
人体下半身的识别:haarcascade_lowerbody.xml
眼镜的识别:haarcascade_eye_tree_eyeglasses.xml
眼睛的识别:haarcascade_eye.xml
左眼的识别:haarcascade_lefteye_2splits.xml
右眼的识别:haarcascade_righteye_2splits.xml
口的识别:haarcascade_mcs_mouth.xml
鼻子的识别:haarcascade_mcs_nose.xml
侧脸的识别:haarcascade_profileface.xml
微笑的识别:haarcascade_smile.xml