论文名称:Wavelet and Prototype Augmented Query-based Transformer for Pixel-level Surface Defect Detection
论文原文 (Paper) :https://openaccess.thecvf.com/content/CVPR2025/html/Yan_Wavelet_and_Prototype_Augmented_Query-based_Transformer_for_Pixel-level_Surface_Defect_CVPR_2025_paper.html
代码 (code) :https://github.com/iefengyan/WPFormer
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
- 论文精读:WPFormer
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
- [3. 主要贡献点](#3. 主要贡献点)
- [4. 方法细节](#4. 方法细节)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 获取即插即用代码关注 【AI即插即用】](#6. 获取即插即用代码关注 【AI即插即用】)
论文精读:WPFormer
1. 核心思想
- 本文提出了一种名为 WPFormer(Wavelet and Prototype Augmented Query-based Transformer)的新型架构,专用于解决**表面缺陷检测(SDD)**中的挑战(如弱缺陷、背景杂乱)。
- 其核心思想是改进标准 Query-based Transformer 。它不再仅依赖空间域信息,而是设计了一个双域 Transformer 解码器(Dual-Domain Transformer, D2T)。
- 这个解码器引入了两个并行 的跨注意力模块来共同优化查询(Queries):
- WCA(小波增强跨注意力) :在频率域 (小波域)操作,通过调制高频和低频分量,使查询(Queries)能聚焦于缺陷的边缘和细节。
- PCA(原型引导跨注意力) :在空间域 操作,它不直接计算 Query 和所有特征的相似度,而是先将特征聚类为"原型"(Prototypes) ,再让 Query 与这些原型交互,从而过滤背景冗余。
- 这种"频率+空间原型"的双重增强机制,使得查询能够更鲁棒地聚合关键缺陷信息,实现 SOTA 性能。
2. 背景与动机
-
文本角度总结
像素级的表面缺陷检测(SDD)在智能制造中至关重要,但极具挑战性。原因在于工业缺陷通常外观微弱 (尺寸小、形状细长)、与背景高度相似 ,且背景本身纹理杂乱。
现有的方法主要有两大瓶颈:
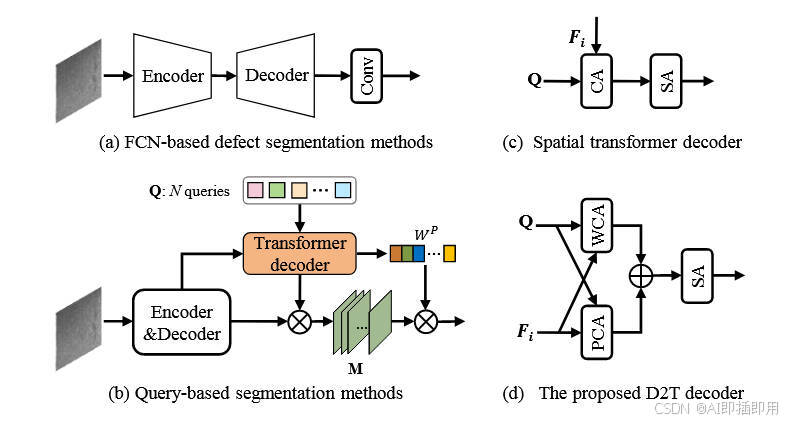
- FCN-based 方法(传统 CNN) :如图 1(a) 所示,它们在最后一层使用一个静态的(Static)卷积核来对所有像素进行分类。这个卷积核是 图像无关(image-independent)的,无法根据输入动态调整。面对弱缺陷和强噪声时,这种"一刀切"的分类方式极易导致漏检 (错过细节)和误检(背景当缺陷)。
- Query-based 方法(标准 Transformer) :如图 1(b)© 所示,这些方法(如 Mask2Former)使用动态的 查询(Queries)和 Transformer 解码器,理论上更优越。但它们也存在问题:
- (1) 仅限空间域: 它们只在空间域 (Spatial domain)进行 Query-Feature 交互。然而,许多弱缺陷(如细微划痕)在空间域几乎不可见,但在频率域 (Frequency domain)中却表现为明显的高频信号。标准方法忽视了宝贵的频率信息。
- (2) 信息冗余: 它们计算 Query 与所有图像特征(Tokens)的相似度。在背景杂乱的工业图像中,海量的"背景"特征会**"稀释"**(dilute)Query 对少数"缺陷"特征的注意力,导致聚合效率低下或错误。
本文的动机 :设计一个双域(Dual-Domain)的 Query-based Transformer,使其既能利用频率域 信息捕捉缺陷细节,又能利用空间域 的某种机制(原型)来过滤背景冗余。
-
动机图解分析(Figure 1 & 3):
-
图表 A (Figure 1):揭示"静态 vs 动态"和"单域 vs 双域"
- "看图说话": 这张图对比了四种架构。
- (a) FCN-based: 最大的问题是
Conv预测层。它是一个静态分类器,对所有像素"一视同仁"。 - (b) Query-based: 引入了
Transformer decoder和N queries。这是一个动态过程,Query 会主动学习去"寻找"特征。 - © Spatial transformer decoder: 这是(b)中解码器的标准实现。它只在空间域操作,Query ( Q Q Q) 和特征 ( F i F_i Fi) 直接交互(
CA- Cross Attention)。这就是本文指出的**"单域"和"信息冗余"**问题。 - (d) The proposed D2T decoder: 这是本文的核心解决方案 。它将 © 中的单一
CA替换为两个并行分支 :WCA(小波/频率域)和PCA(原型/空间域)。Query ( Q Q Q) 和特征 ( F i F_i Fi) 同时 在这两个域中进行交互,然后将结果融合( ⊕ \oplus ⊕)后送入SA(自注意力)。 - 结论: Figure 1 清晰地勾勒出了本文的创新路径:从"静态 FCN" (a) → \rightarrow → "动态 Query-based" (b) → \rightarrow → 改进标准"单域 Query" © → \rightarrow → 提出"双域(WCA+PCA)Query" (d)。
-
图表 B (Figure 3):揭示 PCA 的"去冗余"能力
- "看图说话": 这张图可视化了
PCA模块的效果。 - 分析:
FeatureMaps(原始特征): 上排的原始特征图(#1 到 #4)显示,特征响应非常杂乱 。虽然缺陷区域(中间的白色裂纹)有激活,但大量的背景区域 (如纹理)也被高度激活。Prototype Activation Mapping(PCA 特征): 下排是经过PLU(原型学习单元)处理后的特征图。效果立竿见影:背景噪声几乎被完全抑制 (变为深蓝色),而缺陷区域的激活变得极其干净、锐利和聚焦。
- 结论: Figure 3 直观地证明了本文的第二个动机。即标准注意力(如 Figure 1c)会受到上排"杂乱"特征的干扰,而
PCA模块能有效地将特征**"聚类"**成有意义的"原型",主动过滤掉背景冗余,只保留(下排所示的)关键缺陷信息,从而极大提升了 Query-Feature 交互的信噪比。
- "看图说话": 这张图可视化了
-
3. 主要贡献点
- 提出 WPFormer 架构与 D2T 解码器: 提出了一个用于 SDD 的新型 Query-based 架构。其核心是双域 Transformer 解码器(Dual-Domain Transformer, D2T) ,它允许查询(Queries)同时在频率域 和空间域中与图像特征进行交互和增强。
- 发明 WCA (小波增强跨注意力):
- 这是频率域 分支。WCA 使用**哈尔小波变换(Haar wavelet)**将图像特征 F i F_i Fi 分解为低频 F f r e l F_{fre}^l Ffrel(结构)和高频 F f r e h F_{fre}^h Ffreh(细节/噪声)分量。
- 关键在于,它认识到高频 F f r e h F_{fre}^h Ffreh 虽然包含缺陷细节,但也混杂了背景噪声。因此,它设计了一个多尺度上下文模块(MSCM) ,利用 F f r e l F_{fre}^l Ffrel 和 F f r e h F_{fre}^h Ffreh 的全局和局部关系来生成一个注意力权重,用于**调制(抑制噪声)**高频分量。
- 最终,查询(Queries)与增强后的高频分量和低频分量进行跨注意力计算,从而在关注细节的同时避免了噪声干扰。
- 发明 PCA (原型引导跨注意力):
- 这是空间域分支,旨在解决背景冗余问题。
- PCA 不进行 Query 和全量特征 F i F_i Fi 的 N × H W N \times HW N×HW 交互,而是引入了一个原型学习单元(PLU)。
- PLU(如图 3 所示)通过一个可学习的聚类过程,将 H × W × D H \times W \times D H×W×D 的特征图 F i F_i Fi 自适应地聚类 成 M × D M \times D M×D( M M M 为原型数,且 M ≪ H W M \ll HW M≪HW)的原型 F p r o F_{pro} Fpro。
- 查询(Queries)只与这些高度浓缩的原型 F p r o F_{pro} Fpro 进行交互。这极大地过滤了背景冗余,并显著提高了 Query 聚合关键信息的效率。
- 提出 MSCM (多尺度上下文模块): 这是一个轻量级的通道注意力模块(见 Figure 2c),用于 WCA 和 PCA 内部。它通过并行分支(GAP 和 1x1 卷积)同时捕捉全局 和局部的通道依赖关系,用于生成更鲁棒的注意力权重。
4. 方法细节
-
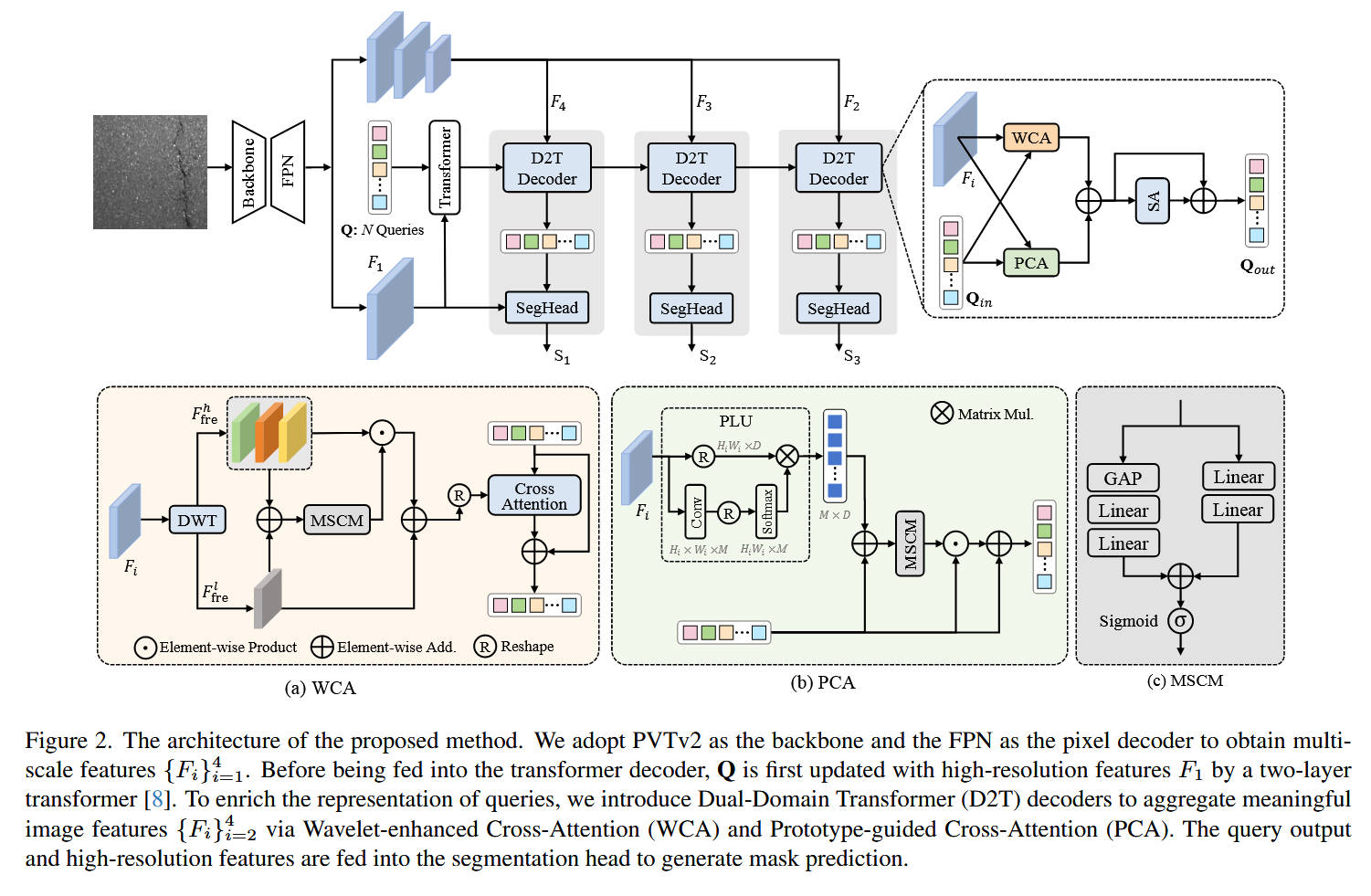
整体网络架构(Figure 2 上半部分):
- 模型名称: WPFormer
- 数据流:
- Backbone & FPN: 使用
PVTv2作为骨干网络,后接FPN,生成多尺度特征 { F i } i = 1 4 \{F_i\}_{i=1}^4 {Fi}i=14(从 1 / 4 1/4 1/4 到 1 / 32 1/32 1/32 分辨率)。 - Query 初始化与预处理: N N N 个可学习的查询 Q Q Q 首先与最高分辨率的特征 F 1 F_1 F1 在一个标准
Transformer解码器中交互(预更新)。 - D2T 解码器(核心): 预更新后的 Q Q Q 被送入一个三层的 D2T 解码器 中。这个解码器从低分辨率到高分辨率 ( F 4 → F 3 → F 2 F_4 \rightarrow F_3 \rightarrow F_2 F4→F3→F2)逐层处理特征。
- D2T Block 内部: 在每一层 D2T Decoder 中(如图 2 右上角放大图),输入的 Q i n Q_{in} Qin 和特征 F i F_i Fi 兵分两路 ,并行 进入:
WCA模块(频率域交互)PCA模块(空间域交互)- 两个模块的输出逐元素相加 ( ⊕ \oplus ⊕)。
- 融合后的 Query 再经过一个
SA(自注意力)层进行 Query 间的内部信息融合,得到 Q o u t Q_{out} Qout。
- 分割头 (SegHead): 每一层 D2T 解码器的输出 Q o u t Q_{out} Qout 都会被送入一个
SegHead,与高分辨率特征 F 1 F_1 F1(注意:所有 SegHead 都使用 F 1 F_1 F1)计算,生成该层的掩码预测 S i S_i Si。
- Backbone & FPN: 使用
-
核心创新模块详解(Figure 2 放大图):
-
对于 模块 A:WCA (小波增强跨注意力)
- 理念: 利用频率域信息,特别是高频信号(边缘、细节)来增强 Query 对弱缺陷的感知。
- 数据流:
- 输入特征 F i F_i Fi 经过
DWT(哈尔小波变换),分解为低频 F f r e l F_{fre}^l Ffrel ( F L L F_{LL} FLL)和高频 F f r e h F_{fre}^h Ffreh ( F L H + F H L + F H H F_{LH}+F_{HL}+F_{HH} FLH+FHL+FHH)。 - 调制(Modulation): 为了抑制高频中的噪声,模型将 F f r e l F_{fre}^l Ffrel 和 F f r e h F_{fre}^h Ffreh 相加,送入
MSCM模块(见模块 C)以生成多尺度(全局+局部)通道权重。 - 生成的权重(经过 Sigmoid)与原始高频特征 F f r e h F_{fre}^h Ffreh 进行逐元素相乘( ⊙ \odot ⊙) ,得到被"净化"过的高频特征 F f r e h ′ F_{fre}^{h\prime} Ffreh′。
- 将 F f r e h ′ F_{fre}^{h\prime} Ffreh′ 和 F f r e l F_{fre}^l Ffrel 相加( ⊕ \oplus ⊕),得到最终的、增强且去噪的频率域特征。
- 交互:
Cross Attention模块以输入的 Query 为 Q Q Q,以增强后的频率特征为 K K K 和 V V V,进行标准交叉注意力计算,并加上残差连接,输出更新后的 Query。
- 输入特征 F i F_i Fi 经过
-
对于 模块 B:PCA (原型引导跨注意力)
- 理念: 在空间域通过"原型"聚类来过滤背景冗余,提高 Query-Feature 交互的信噪比。
- 数据流:
- 输入特征 F i F_i Fi 进入
PLU(原型学习单元) :- F i F_i Fi 经过
Conv→ \rightarrow →Softmax得到一个"分配图" F i w F_i^w Fiw( H W × M HW \times M HW×M, M M M 为原型数量)。 - F i w F_i^w Fiw 的转置与原始 F i F_i Fi(Flattened)进行矩阵乘法 ( ⊗ \otimes ⊗)。
- 这一步在数学上等同于一个可学习的聚类 过程,它将 H W HW HW 个特征点自适应地聚合成 M M M 个"原型" F p r o F_{pro} Fpro( M × D M \times D M×D)。
- F i F_i Fi 经过
- 交互:
PLU输出的原型 F p r o F_{pro} Fpro 与输入的 Query Q i n Q_{in} Qin 逐元素相加 ( ⊕ \oplus ⊕)。- 将相加后的结果送入
MSCM模块(见模块 C),生成多尺度通道权重。 - 该权重(经过 Sigmoid)与 Q i n Q_{in} Qin 进行逐元素相乘( ⊙ \odot ⊙),实现通道域的精炼。
- 最终结果与 Q i n Q_{in} Qin 残差相加,输出更新后的 Query。
- 输入特征 F i F_i Fi 进入
- 设计目的: PCA 与标准 CA(Figure 1c)的根本不同在于,PCA 没有 Query 和 F i F_i Fi 的直接交互 。Query 仅与 F i F_i Fi 聚类而成的 M M M 个"原型"进行交互,从而天然地忽略了 F i F_i Fi 中海量的背景冗余信息(如 Figure 3 所示)。
-
对于 模块 C:MSCM (多尺度上下文模块)
- 理念: 一个轻量级的通道注意力模块,用于 WCA 和 PCA 内部,以同时捕捉全局和局部依赖。
- 数据流:
- 输入特征 X X X 兵分两路。
- 全局分支: X X X → \rightarrow →
GAP(全局平均池化) → \rightarrow →Linear→ \rightarrow → δ \delta δ (ReLU) → \rightarrow →Linear→ \rightarrow → W g c W_g^c Wgc(全局权重)。 - 局部分支: X X X → \rightarrow →
Linear→ \rightarrow → δ \delta δ (ReLU) → \rightarrow →Linear→ \rightarrow → W l c W_l^c Wlc(局部权重,保持空间维度)。 - 融合: W g c + W l c W_g^c + W_l^c Wgc+Wlc → \rightarrow →
Sigmoid→ \rightarrow → 输出最终的注意力权重。
- 设计目的: 这是一个比标准 SE 模块(只有全局分支)更强大的通道注意力,因为它同时考虑了全局上下文( W g c W_g^c Wgc)和局部空间信息( W l c W_l^c Wlc)。
-
-
理念与机制总结:
- 双域并行: WPFormer 的 D2T 解码器(Figure 1d, Figure 2)是其核心。它并行 地处理同一份输入 Q Q Q 和 F i F_i Fi。
- WCA (频率域) :利用小波变换分离高/低频。通过
MSCM学习权重来抑制高频噪声 ,然后将"干净"的细节(高频)和结构(低频)信息融合,用于更新 Query。解决了"弱缺陷细节捕捉"问题。 - PCA (空间域) :利用
PLU可学习聚类,将 F i F_i Fi 压缩成 M M M 个"原型" F p r o F_{pro} Fpro。Query 仅与 F p r o F_{pro} Fpro 交互,跳过了 所有背景特征。解决了"背景杂乱冗余"问题。 - 两个模块的输出被相加,使得 Query 在一次更新中同时获得了频率域的"细节增益"和空间域的"去噪增益",然后送入 SA 模块进行内部消化。
-
图解总结:
- Figure 1 © 揭示了问题 1 (标准 CA 仅在空间域)和问题 2(标准 CA 受冗余信息干扰)。
- Figure 1 (d) 提出了解决方案 :
D2T解码器。 - Figure 2 (a) WCA 详细阐述了如何通过小波变换 和
MSCM调制来解决问题 1(频率域缺失)。 - Figure 2 (b) PCA 和 Figure 3 详细阐述了如何通过原型学习(PLU)来解决问题 2(空间域冗余)。
- Figure 2 © MSCM 是为 WCA 和 PCA 提供支持的轻量级注意力工具。
- Figure 2(整体架构) 展示了如何将 D2T 解码器(WCA+PCA)集成到一个多层级的 Transformer 架构中,以实现对缺陷的渐进式精炼。
5. 即插即用模块的作用
-
本文的三个核心创新
WCA、PCA和MSCM都是高度模块化的,可以作为即插即用的组件。 -
WCA (小波增强跨注意力):
- 作用: 这是一个跨注意力模块 ,可替代任何 Transformer 解码器(如 DETR, Mask2Former)中的标准**交叉注意力(Cross-Attention)**层。
- 适用场景: 任何分割或检测任务,只要目标具有精细的边缘、纹理 或微弱的信号(例如医学的微小病变、遥感的细小裂缝、低光图像)。
- 具体应用: 将其插入解码器,它能利用频率域的高频信息来显著增强模型对"细节"的感知能力。
-
PCA (原型引导跨注意力):
- 作用: 这也是一个跨注意力模块 ,同样可以替代 标准交叉注意力层。
- 适用场景: 任何目标检测或分割任务,只要背景杂乱、纹理复杂,或者存在大量"类目标"的干扰物(例如工业缺陷检测、伪装目标检测)。
- 具体应用: 将其插入解码器,
PLU单元将充当一个自适应的"去噪器"和"聚类器",迫使 Query 忽略背景,只关注由原型代表的"有意义"的语义区域(如 Figure 3 所示)。
-
D2T (双域解码器层):
- 作用: 这是一个完整的 Transformer 解码器层(如图 1d 所示)。
- 适用场景: 可用于替换任何 Query-based 模型(如 Mask2Former, DETR)中的标准 Transformer 解码器层。
- 具体应用: 通过将标准解码器层替换为 D2T 层,模型将同时获得 WCA 的细节捕捉能力 和 PCA 的抗干扰能力,实现双重增益。
-
MSCM (多尺度上下文模块):
- 作用: 这是一个通道注意力模块 ,可替代 标准的 SE (Squeeze-and-Excitation) 模块。
- 适用场景: 任何需要通道注意力的 CNN 或 Transformer。
- 具体应用: MSCM 优于 SE,因为它**同时考虑了全局(GAP)和局部(1x1 卷积)**的通道依赖性,能提供更丰富的特征调制。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。