1. MySQL 体系结构

2. Connectors(客户端)
MySQL 服务器之外的客户端程序,与具体的语言相关,例如 Java 中的J DBC,图形用户界面 SQLyog, Navicat 等。本质上都是在TCP连接上通过MySQL协议和MySQL服务器进行通信。
3. MySQL Server(服务器)
3.1 连接层
- 客户端访问 MySQL 服务器前,做的第一件事就是建立 TCP 连接。
- 经过三次握手建立连接成功后, MySQL 服务器对 TCP 传输过来的账号密码做身份认证、权限获取。
- 用户名或密码不对,会收到一个Access denied for user错误,客户端程序结束执行
- 用户名密码认证通过,会从权限表查出账号拥有的权限与连接关联,之后的权限判断逻辑,都将依赖于此时读到的权限
- TCP 连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后面的流程。每一个连接从线程池中获取线程,省去了创建和销毁线程的开销。
3.2 服务层
Management Serveices & Utilities: 系统管理和控制工具
SQL Interface:SQL接口:
- 接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT ... FROM就是调用SQL Interface
- MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定义函数等多种SQL语言接口
Parser:解析器 :
在SQL命令传递到解析器的时候会被解析器验证和解析。解析器中SQL 语句进行词法分析、语法分析、语义分析,并为其创建语法树。
- 词法分析:将整个语句拆分成一个个字段
- 语法分析:将词法分析拆分出的字段,按照MySQl语法规则,生成解析树
- 语义分析:检查解析树是否合法,比如查看表是否存在,列是否存在
典型的解析树如下:
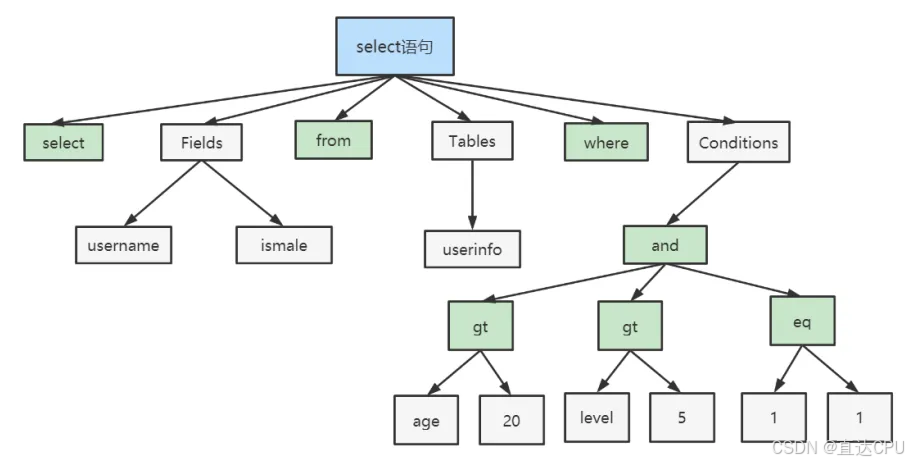
Optimizer:查询优化器:
- SQL语句在语法解析后、查询前会使用查询优化器对查询进行优化,确定SQL语句的执行路径,生成一个执行计划。
Caches & Buffers: 查询缓存组件:
- MySQL内部维持着一些Cache和Buffer,比如Query Cache用来缓存一条SELECT语句的执行结果,如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、查询优化和执行的整个过程了,直接将结果反馈给客户端。
- 这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 。
● 这个查询缓存可以在不同客户端之间共享 。 - 问:大多数情况查询缓存就是个鸡肋,为什么呢?
- 只有相同的SQL语句才会命中查询缓存。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。
- 在两条查询之间 有 INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE 语句也会导致缓存失效
- 因此 MySQL的查询缓存命中率不高。所以在MySQL 8之后就抛弃了这个功能。
3.3. 引擎层
存储引擎层( Storage Engines),负责MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,管理的表有不同的存储结构,采用的存取算法也不同,这样我们可以根据自己的实际需要进行选取。例如MyISAM引擎和InnoDB引擎。
4. 存储层
所有的数据、数据库、表的定义、表的每一行的内容、索引,都是存在文件系统 上,以文件的方式存在,并完成与存储引擎的交互。
5. 查询流程说明
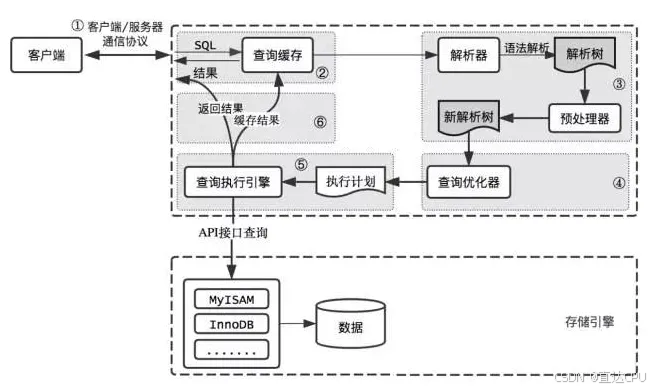
首先,MySQL客户端通过协议与MySQL服务器建连接,通过SQL接口发送SQL语句,先检查查询缓存,如果命中,直接返回结果,否则进行语句解析。也就是说,在解析查询之前,服务器会先访问查询缓存,如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可。
接下来是解析过程,MySQL解析器通过关键字将SQL语句进行解析,并生成一棵对应的解析树,解析器使用MySQL语法规则验证和解析SQL语句。例如,它将验证是否使用了错误的关键字,或者使用关键字的顺序是否正确,引号能否前后匹配等;预处理器则根据MySQL规则进一步检查解析树是否合法,例如,这里将检查数据表和数据列是否存在,还会解析名字和别名,看是否有歧义等,并生成一棵新解析树,新解析树可能和旧解析树结构一致。
然后是优化过程,MySQL优化程序会对我们的语句做一些优化,将查询的IO成本和CPU成本降到最低。优化的结果就是生成一个执行计划。这个执行计划表明了应该使用哪些索引执行查询,以及表之间的连接顺序是啥样,必要时将子查询转换为连接、表达式简化等等。我们可以使用EXPLAIN语句来查看某个语句的执行计划。
最后,进入执行阶段。完成查询优化后,查询执行引擎会按照生成的执行计划调用存储引擎提供的接口执行SQL查询并将结果返回给客户端。在MySQL8以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存,再返回给客户端。