Keras是TensorFlow的高级深度学习API,可以构建、训练、评估和执行各种神经网络。
深度学习库还有Facebook的PyTorch和谷歌的JAX库,归功于它简单性和出色的文档,PyTorch的API和Keras非常相似,了解Keras后容易迁移到Pytorch。
一、使用顺序API构建分类MLP
1、构建方式
顺序API是一种线性堆叠网络层的方式,其创建MLP有两种方式。
一种是创建一个Sequential模型对象,之后通过.add()方法一层层的添加;另一种是在初始化Sequential对象的时候传入多层组成的列表。如下:
python
import tensorflow as tf
# 使用顺序(Squential API创建模型),创建具有两个隐藏层的分类MLP
tf.random.set_seed(42)
model = tf.keras.Sequential() # 初始化顺序模型
# 第一层
model.add(tf.keras.layers.Input(shape=[28, 28]))
# 第二层 将数据摊平
# 这里第一层和第二层可以并列写成:tf.keras.layers.Flatten(input_shape=[28,28])
model.add(tf.keras.layers.Flatten())
# 第三层 密集层(全连接),使用relu进行激活
model.add(tf.keras.layers.Dense(300, activation="relu")) # tf.keras.activations.relu
model.add(tf.keras.layers.Dense(100, activation="relu"))
model.add(tf.keras.layers.Dense(10, activation="softmax"))
# 第二种写作方式:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape = [28,28]),
tf.keras.layers.Dense(300,activation = "relu"),
tf.keras.layers.Dense(100,activation = "relu"),
tf.keras.layers.Dense(10,activation = "softmax")
])| 以上构建模型的步骤 | 层含义 | 解释 |
| tensorflow的随机种子以实现结果可以重现 | | 每次运行的时候,隐藏层和输出层的随机权重是相同的,可以使用tf.keras.untils.set_random_seed()函数,它可以很方便的将Tensorflow、Python(random.seed())和Numpy(np.random.seed())设置随机种子。 |
| 创建Sequential模型 | | 这个适用于神经网络的最简单的Keras模型,仅由顺序连接的单层堆栈组成,称为顺序API |
| Input | 输入 | 指定输入内容,输入shape形状,其中不包括批量大小,仅包括实例的形状 |
| Flatten | 形状调整层 | Flatten:指定input_shape,如果不指定形状,Keras会等待直到知道形状才会构建参数 将每个输入图像转换为一维数组(将 (28,28) 重塑为 (-1,784)) |
| Dense | 全连接层 | nuits:神经元数量 activation:激活函数(relu、sigmoid、softmax、tanh、linear、none) use_bias:是否使用偏置 kernel_initializer、bias_initializer:权重初始化(random_normal正态分布初始化;zeros全零初始化;ones全1初始化;glorot_uniform默认初始化;he_normal适合ReLU的初始化)、偏置初始化 kernel_regularizer、bias_regularizer:权重正则化、偏置正则化 activity_regularizer:输出正则化 kernel_constraint:权重约束 该层随机随机初始化连接权重,并且偏置被初始化为0.如果使用其他初始化方法,则可以在创建层的时候使用初始化参数。权重矩阵的形状在创建模型的时候指定,如果不指定会一直等待,知道知道输入的形状。 |
|---|
模型中的每一层都必须有一个唯一的名称,可以使用构造函数的name参数显示设置图层名称(不用的画会自动命名图层)。Keras还通过在需要时附加索引来确保名称全局唯一,即使跨模型也是如此,如"dense_2"。 命名唯一保证合并模型时不会出现名称冲突。
2、模型的参数
Keras管理的所有全局状态都存储在Keras会话中,可以使用tf.keras.backend.clear_session()清除该会话,可以重置名称计数器。
|--------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------|
| model.layers | 返回模型中所有层的列表,或者使用get_layer("name") |
| model.layers.name | 层的名字 |
| model.layers.name | 层的类型 |
| model.layers.input_shape | 层的输入形状 |
| model.layers.output_shape | 层的输出形状 |
| model.layers.count_params() | 层的参数数量 |
| model.layers.get_weight() | 层的权重 |
| model.inputs 、model.outputs | 模型的输入张量列表、模型的输出张量列表 |
| model.trainable_weights 、model.non_trainable_weights | 可训练权重列表、不可训练权重列表 |
| model.params | 模型的训练参数 |
| model.epoch | 模型经历的轮次列表 |
| model.summary() | 显示模型的所有层。包括每个层的名称、输出形状、参数数量,以参数总数结尾(可训练和不可训练的参数)。 |
| python tf.keras.utils.plot_model( model, # 模型 "./images/neural_network/my_fashion_mnist_model.png", # 输出图片位置 show_shapes=True ) | 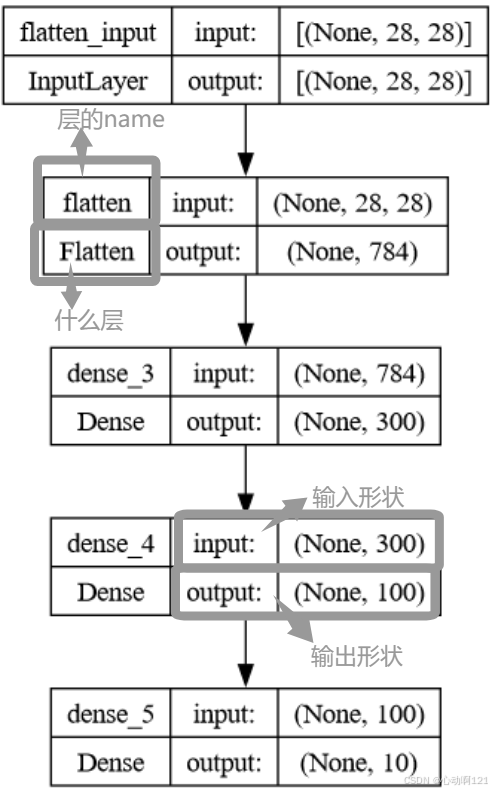 |
|
| tf.keras.backend.clear_session() | 清理当前的 Keras 会话(Session),重置整个计算图(Graph)状态。 |
3、模型的拟合、评估与预测
创建模型后,必须调用compile()方法来指定loss损失函数 和 optimizer 要使用的优化器。也可以选择指定在训练和评估期间要计算的其他指标(比如metrics评估指标)。
在拟合数据的时候需要:传入输入特征和目标类(X_train、y_train);要训练的轮次数epochs(否则将它默认为1,这绝对不足以收敛成为一个好模型);验证集(validation_data)或validation_split指定数据中的多少为验证集;在训练集不平衡的时候可以使用特征权重(class_weight)实例权重(sample_weight)参数。
在每个轮次结束时测量此集合上的损失和其他指标,这对于查看模型的实际效果非常有用。如果训练集的性能好于验证集,则模型可能过拟合训练集或存在错误。
python
model.compile(loss=tf.keras.losses.sparse_categorical_crossentropy,
optimizer=tf.keras.optimizers.SGD(),
metrics=[tf.keras.metrics.sparse_categorical_accuracy])
history = model.fit(X_train, y_train, epochs=30, validation_data=(X_valid, y_valid))| fit方法后的history对象 | 含义 |
|---|---|
| model.history.keys() | 每轮结束时测得的损失和额外指定的字典的键 |
| model.history"loss" | 模型在训练集上的损失值 |
| model.history"accuracy" | 模型在训练集上的准确值 |
| model.history"val_loss" | 模型在验证集上的损失值 |
| model.history"val_accuracy" | 模型在验证集上的准确值 |
| model.history"lr" | 每个epoch的学习率(如果使用学习率调度) |
在训练结束之后,使用evaluate方法传入测试集,可以查看模型在测试集上的损失值、准确率信息。
在使用多分类模型进行预测时,预测的结果是每个类的概率。因此,想要知道具体属于哪一类需要使用argmax函数进行选择。
python
# 在测试集上评估模型
model.evaluate(X_test,y_test)
# 使用模型进行预测
X_new = X_test[10:20]
y_proba = model.predict(X_new) # 多标签输出的是属于每个类别的概率
y_proba.round(2)
import numpy as np
y_pred = np.argmax(y_proba, axis=-1) # 选择概率最大的一个4、在拟合的过程中判断模型的好坏
如何判断模型是欠拟合、过拟合还是正常收敛:
| 情况 | 训练集准确率趋势 | 验证集准确率趋势 | 准确率差距变化 | 建议 |
|---|---|---|---|---|
| 正常收敛 | ↗️ 上升 | ↗️ 上升 | ↔️ 稳定 | 继续训练 |
| 欠拟合 | ↗️ 缓慢上升 | ↗️ 缓慢上升 | ↔️ 稳定但都低 | 增加模型复杂度 调整学习率、层数、每层神经元的数量、激活函数的类型、batch_size批量大小 |
| 开始过拟合 | ↗️ 继续上升 | ↘️ 开始下降 | ↗️ 快速扩大 | 立即停止 |
| 完全过拟合 | ↗️ 很高 | ↘️ 很低 | ↗️ 很大差距 | 使用早停 |
5、整个过程的小总结
| 方法 | 作用 | 输入数据 | 输出 |
|---|---|---|---|
model=tf.keras.Sequential([输入层,隐藏层,输出层]) |
实例化模型 | 给实例添加神经元层数和神经元数量 | 神经网络模型 |
model.fit() |
训练模型 | 特征数据 X_train 和 标签 y_train |
训练历史(History对象),不直接返回性能分数 |
model.evaluate() |
评估模型 | 特征数据 X_test 和 标签 y_test |
一个包含损失值和评估指标的列表 |
model.predict() |
使用模型预测 | 特征数据 X_new (没有标签) |
预测出的结果 y_pred |
二、使用顺序API构架回归MLP
使用顺序API来构建、训练、评估和使用回归MLP与分类所做的非常相似。
首先要明确:回归输出的是连续数值,并且不适用激活函数(因为激活函数会将输出限制在一个固定的区间内)这样就能预测任何范围的数值。
整个流程:数据处理层(这一步就包含输入) ------ 其他隐藏层 ------ 输出层 ------ 模型编译 ------ 模型训练(在此之前需要adapt拟合数据) ------ 模型评估和预测
数据处理层:不需要Flatten层,而是使用Normalization层作为第一层:它与Scikit-Learn的StandardScaler做同样的事情,但它必须在调用模型的fit()方法之前调用adapt()方法来拟合训练数据。
输出层:只有一个神经元(因为只预测一个值),并且它不使用激活函数,损失函数是均方误差,度量是RMSE, 使用像Scikit-Learn的MLPRegressor那样的Adam优化器。
python
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(
housing.data, housing.target, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_full, y_train_full, random_state=42)
tf.random.set_seed(42)
# keras的input_shape要的是单个样本的形状, 把第一个维度去掉就是标准化需要的样本形状
norm_layer = tf.keras.layers.Normalization(input_shape=X_train.shape[1:])
model = tf.keras.Sequential([
norm_layer,
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(1)
])
# 创建Adam的优化器对象,用于在训练网络的时候更新权重
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
model.compile(loss="mse", optimizer=optimizer, metrics=["RootMeanSquaredError"])
# 调用adapt方法,Normalization层会学习训练数据中特征均值和标准差
# 统计数据被列为不可训练参数,因为这些参数不受梯度下降影响
norm_layer.adapt(X_train)
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
mse_test, rmse_test = model.evaluate(X_test, y_test)
X_new = X_test[:3]
y_pred = model.predict(X_new)adapt()方法:适配预处理层(例如,在标准化层Normalization之前需要使用adapt方法从数据中学习均值和方差以便标准化)
Adam优化器:目标是最小化损失函数。
learning_rate(权重更新的时候的学习率);
weight_decay(权重更新时是否使用L2正则化,防止过拟合);
amsgrad(是否使用Adam的变体,比Adam更加稳定解决一些收敛问题);
clipnorm/clipvalue(在训练不稳定的时候启用梯度裁剪)
三、使用函数式API构建复杂模型
顺序API非常简洁明了。然而,虽然Sequential模型非常常见,但有时构建具有更复杂拓扑结构或具有多个输入或输出的神经网络很有用。为此,Keras提供了函数式API。
非顺序神经网络的一个示例是"宽深"神经网络。这种神经网络架构是在2016年发表的论文引入的。它将所有或部分输入直接连接到输出层。这种架构使神经网络能够学习深度模式(使用深度路径)和简单规则(通过短路径)。
相比之下,常规的MLP迫使所有数据流经整个层的堆栈。因此,数据的简单模式最终可能会因为顺序被转换而失真。
1、构建单输入输出的model模型
与顺序API通过add()方法叠加层不同,函数式API的连接层是通过函数一样调用层进行模型的构建,最后实例化模型inputs、outputs。
python
normal = tf.keras.layers.Normalization()
hidden1_layer = tf.keras.layers.Dense(30,activation="relu")
hidden2_layer = tf.keras.layers.Dense(30, activation="relu")
concat_layer = tf.keras.layers.Concatenate()
output_layer = tf.keras.layers.Dense(1)
input_ = tf.keras.layers.Input(shape=X_train.shape[1:])
normalized = normal(input_)
hidden1 = hidden1_layer(normalized)
hidden2 = hidden2_layer(hidden1)
concat = concat_layer([normalized,hidden2])
output = output_layer(concat)
model = tf.keras.Model(inputs=[input_], outputs=[output])为什么创建两个一模一样的隐藏层:因为如果是调用两次相同的隐藏层,其权重和偏置是一样的,并没有深入一层进行拟合数据,相当于是一层隐藏层。
2、拟合数据评估的选择模型
python
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
model.compile(loss="mse", optimizer=optimizer, metrics=["RootMeanSquaredError"])
normalization_layer.adapt(X_train)
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
mse_test, rmse_test = model.evaluate(X_test, y_test) # 损失值,评价值如何选择loss损失函数和metrics评估指标:
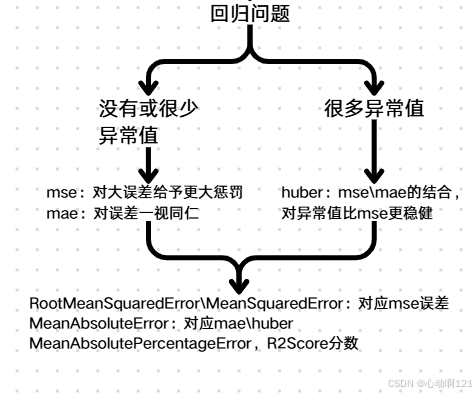
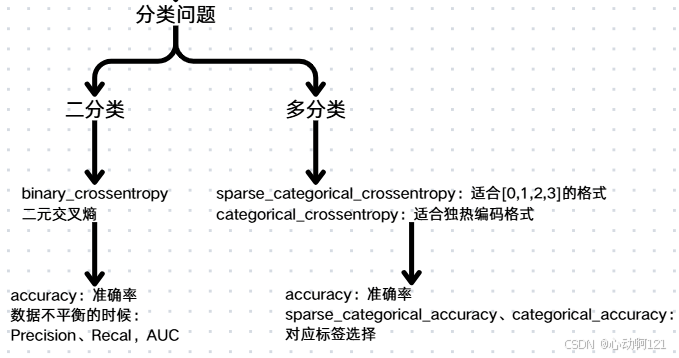
3、构建多输入、多输出的模型
构架一个如图所示的模型
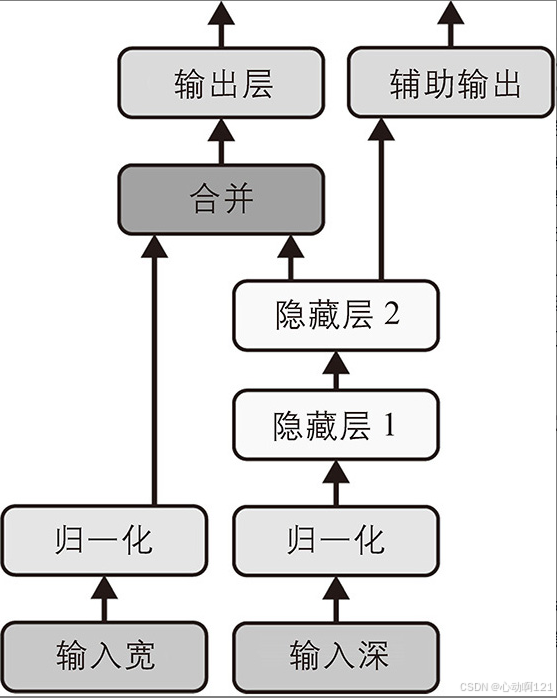
python
input_wide = tf.keras.layers.Input(shape=[5])
input_deep = tf.keras.layers.Input(shape=[6])
norm_layer_wide = tf.keras.layers.Normalization()
norm_layer_deep = tf.keras.layers.Normalization()
norm_wide = norm_layer_wide(input_wide)
norm_deep = norm_layer_deep(input_deep)
hidden1 = tf.keras.layers.Dense(30, activation="relu")(norm_deep)
hidden2 = tf.keras.layers.Dense(30, activation="relu")(hidden1)
concat = tf.keras.layers.concatenate([norm_wide, hidden2])
output = tf.keras.layers.Dense(1)(concat)
aux_output = tf.keras.layers.Dense(1)(hidden2)
# 使用字典创建模型易于维护
outputs = {"main":output,"aux":aux_output}
inputs = {"wide":input_wide,"deep":input_deep}
model = tf.keras.Model(inputs=inputs, outputs=outputs)
# 使用列表创建模型
# model = tf.keras.Model(inputs=[input_wide, input_deep], outputs=[output, aux_output])每个输出都需要自己的损失函数:因为不同的任务的意义和尺度不同,不能统一个损失函数衡量不同的任务。因此,在编译模型的时候需要传递列表指定每个输出对应的损失函数。
最终损失的计算是简单的累加,也就是不同的输出对应不同的损失函数,优化器的目标是将这些损失函数进行相加得到总损失后,最小化这个总损失。
在模型最终的输出结果中,我们更关注主要输出而不是辅助输出(仅用于正则化,帮助主输出学的更好,防止模型过拟合)。因此,可以给每个输出的损失分配一个权重,这样在计算最终损失的时候就不是简单的累加,而是加权求和。能够有效的解决权重相同的损失函数,导致主任务性能下降。
python
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
model.compile(loss=("mse", "mse"), loss_weights=(0.9, 0.1),
optimizer=optimizer, metrics=["RootMeanSquaredError"])
norm_layer_wide.adapt(X_train_wide)
norm_layer_deep.adapt(X_train_deep)
history = model.fit(
(X_train_wide, X_train_deep), (y_train, y_train),
epochs=20,
validation_data=((X_valid_wide, X_valid_deep), (y_valid, y_valid))
)
# 这两种写法是相同的
# model.compile(loss={"主输出的name":"mse","辅助输出的name":"mse"},
# loss_weights={"主输出的name":0.9,"辅助输出的name":0.1},
# optimizer = optimizer,
# metrics=["RootMeanSquaredError"])
# history = model.fit(
# {"wide_input": X_train_wide, # 使用输入层名称
# "deep_input": X_train_deep # 使用输入层名称
# },
# {"main_output": y_train, # 使用输出层名称
# "aux_output": y_train # 使用输出层名称
# },
# epochs=20,
# validation_data=(
# {"wide_input": X_valid_wide, "deep_input": X_valid_deep},
# {"main_output": y_valid, "aux_output": y_valid}
# ))
python
# 评估模型时,Keras返回损失的加权和,以及所有单独的损失和指标
# 如果设置return_dict=True,那么会返回一个字典而不是一个列表
eval_results = model.evaluate((X_test_wide, X_test_deep),
(y_test, y_test),
return_dict=False)
# predict()方法将为每个输出返回预测值
y_train_main, y_pred_aux = model.predict((X_new_wide, X_new_deep))
# predict()方法返回一个元组,它没有return_dict参数来获取字典,但可以利用model.output_names创建一个
y_pred_tuple = model.predict((X_new_wide, X_new_deep))
y_pred = dict(zip(model.output_names, y_pred_tuple))四、使用子类化API构建动态模型
顺序API和函数化API都是声明性的:首先声明要使用的层以及如何连接它们,之后才能够开始向模型提供一些数据进行训练和推断。这可以轻松的保存、克隆和共享模型;可以显示的分析结构、推断形状和检查类型,及时发现错误。
但是,由于整个模型是一个静态入,虽然调试起来相当容易,但是一些设计循环、条件分支、变化形状的行为,就比较困难。而子类化API可以轻松的解决这些问题。
子类化Model类的核心是继承tf.keras.Model 或 tf.keras.layers.Layer 这两个基类,并通过重写 __init__ 和 call 方法来定义你的自定义模型或层。
构建流程:继承tf.keras.Model ------ 在__init__方法中定义层 ------ 在call方法中定义前向传播
继承tf.keras.Model:这是一个基础要求,它赋予了你的类 Keras 模型的所有特性,如训练、评估、保存等。
定义层:用tf.keras.layers中的层或者自定义层初始化所有将要使用的层,务必调用super().init()。
call方法:定义了输入 inputs 如何经过各层并生成输出。
python
# 构造函数中创建层与在call()方法中使用层分开。
# 不需要创建Input对象:可以使用call()方法的Input参数
class WideAndDeepModel(tf.keras.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs) # 需要调用这句话,模型才有名字
self.norm_layer_wide = tf.keras.layers.Normalization()
self.norm_layer_deep = tf.keras.layers.Normalization()
self.hidden1 = tf.keras.layers.Dense(units, activation=activation)
self.hidden2 = tf.keras.layers.Dense(units, activation=activation)
self.main_output = tf.keras.layers.Dense(1)
self.aux_output = tf.keras.layers.Dense(1)
def call(self, inputs):
input_wide, input_deep = inputs
norm_wide = self.norm_layer_wide(input_wide)
norm_deep = self.norm_layer_deep(input_deep)
hidden1 = self.hidden1(norm_deep)
hidden2 = self.hidden2(hidden1)
concat = tf.keras.layers.concatenate([norm_wide, hidden2])
output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return output, aux_output
tf.random.set_seed(42)
model = WideAndDeepModel(30, activation="relu", name="my_model")使用子类化API虽然很灵活,但是由于模型架构隐藏在call()方法中,出错的时候没有显示化的架构方便检查数据的形状和类型错误。
python
# 现在有了一个模型实例,可以编译它,调用它的归一化层
# 拟合它,评估它,并使用它进行预测,就像对函数式API所做的那样。
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
model.compile(loss=["mse", "mse"], loss_weights=[0.9, 0.1], optimizer=optimizer,
metrics=["RootMeanSquaredError"])
model.norm_layer_wide.adapt(X_train_wide)
model.norm_layer_deep.adapt(X_train_deep)
history = model.fit(
(X_train_wide, X_train_deep), (y_train, y_train), epochs=10,
validation_data=((X_valid_wide, X_valid_deep), (y_valid, y_valid)))
eval_results = model.evaluate((X_test_wide, X_test_deep), (y_test, y_test))
y_pred_main, y_pred_aux = model.predict((X_new_wide, X_new_deep))对于子类化的模型,必须在调用summary()方法之前先通过调用model.build()方法来构建模型,否则无法显示层的信息。
五、保留、还原、可视化模型和检查点回调
1、模型保存
模型保留 (Model Preservation / Saving):指将训练好的神经网络模型的结构(层数、连接方式、每层的类型)、参数(权重和偏置) 以及优化器状态等信息序列化(转换成可存储的格式)并保存到磁盘文件中的过程。
python
# 保存完整模型
model.save("模型路径及名字",save_format="tf")
# 只保存参数(包括权重偏置、预处理数据等等)
model.save_weight("文件路径及名称")比起保存整个模型,保存参数的速度更快,磁盘空间更少,适用于训练期间保存快速检查点。
2、模型还原
模型还原 (Model Restoration / Loading): 指从磁盘文件中读取保存的模型信息,并将其反序列化,重新构建出一个与保存时状态完全一致的模型的过程。这个模型可以直接用于进行预测(推理)或继续训练。
python
# 加载模型
tf.keras.models.load_model("模型路径及名字",custom_objects={模型字典映射})
# 加载参数
model.load_weights("文件路径及名称")3、检查点回调
如果正在训练一个大模型,需要数小时或数天,可以在fit()方法中接受一个callbacks参数(这个需要先定义一个回调)。这个参数允许指定在训练前后、每个轮次前后,甚至处理每个批次前后调用对象列表。
检查点通常保存的信息:模型权重、优化器状态、训练状态(当前的训练轮次、批次索引)、损失和指标。 TensorFlow/Keras 中,通常保存为.ckpt目录或.h5文件。
tf.keras.callbacks.ModelCheckpoint函数的参数:
|-------------------|----------------------------------------------------------------------------------------------|
| filepath | 回调的保存路径 |
| save_weights_only | True:只保存权重 False:保存完整模型 |
| save_best_only | True:只保存最好的模型 False:在每个保存时间点保存模型 |
| monitor | 监控指标 val_loss或val_accuracy |
| mode | max:指标越大越好 min:指标越小越好 |
| period、save_freq | 保存频率 period:是按 epoch 计(如每2个epoch保存一次) save_freq:可以按 batch 计(如 save_freq=500 每500个batch保存一次)。 |
如果在训练期间使用验证集,则可以在创建ModelCheckpoint时设置save_best_only=True。这种情况下,只有当模型在验证集上的性能达到当前最佳时,它才会保存模型,这就是验证集中的最佳模型。
python
# 定义一个回调,在每个 epoch 结束后保存模型
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath='文件路径及名称', # 文件名包含 epoch 号
save_freq='epoch', # 每个 epoch 保存一次
save_weights_only=False, # 保存完整模型,设为 True 则只保存权重
)
# 传入回调进行训练
model.fit(
x_train, y_train,
epochs=10,
callbacks=[checkpoint_callback]
)
# 如果训练中断,可以从最新的检查点加载并继续
latest_model = tf.keras.models.load_model('文件路径及名称')
latest_model.fit(x_train, y_train, epochs=5) # 从第6个epoch开始继续训练自定义自己的回调函数,通过重写基类中的特定方法来进行自定义逻辑。
on_train_begin、on_train_end方法:训练开始和结束的时候调用
on_epoch_begin、on_epoch_end方法:每个epoch开始和结束的时候调用
on_batch_begin、on_batch_end方法:每个batch开始和结束的时候开始调用
on_train_batch_begin、on_train_batch_end方法:训练batch开始和结束时调用
on_test_begin、on_test_end方法:测试开始和结束的时候调用
on_opredict_begin、on_predict_end方法:预测开始和结束时调用
python
# 回调:训练开始的时候初始化损失的列表
# 每个轮次(epoch)结束的时候去记录损失值,训练结束的时候,去把损失值绘制成折线图
# 效果:fit运行后 这个图会自动出来
class MyCallback(tf.keras.callbacks.Callback):
def on_train_begin(self, logs):
self.loss_list = []
def on_epoch_end(self, epoch, logs):
self.loss_list.append(logs["val_loss"] / logs["loss"])
def on_train_end(self,logs):
plt.plot(self.loss_list,"r-")
history = model.fit(
(X_train_wide, X_train_deep), (y_train, y_train), epochs=10,
validation_data=((X_valid_wide, X_valid_deep), (y_valid, y_valid)),
callbacks=[MyCallback()], verbose=0)另一种方法是使用EarlyStopping回调。当它在多个轮次(由patience参数定义)测量验证集没有进展时,它将中断训练,如果设置restore_best_weights=True,则它将在训练结束时回滚到最佳模型。可以结合这两个回调来保存模型的检查点,以防计算机崩溃,并在没有更多进展时提前中断训练,以避免浪费时间和资源并减少过拟合。
其他的回调函数有ModelCheckpoint(定期保存模型和权重)、ReduceLROnPlateau(当指标停止改善时,动态降低学习率)、TensorBoard(可视化)
python
import tensorflow as tf
from tensorflow.keras.callbacks import EarlyStopping
# 定义 EarlyStopping 回调
# 最常用配置:监控验证集损失,如果连续 10 轮不再下降就停止
early_stopping = EarlyStopping(
monitor='val_loss', # 监控的指标:验证集损失
patience=10, # 容忍轮次:10轮没有改善就停止
verbose=1 # 输出信息:1=打印信息,0=安静模式
)
# 开始训练,并传入回调
# 注意:必须提供 validation_data 才能监控 'val_loss' 或 'val_accuracy'
history = model.fit(
x_train, y_train,
epochs=100, # 设置一个很大的总轮次,让早停自己决定何时停止
batch_size=32,
validation_data=(x_val, y_val), # 必须提供验证集!
callbacks=[early_stopping] # 传入回调列表
)
# 训练会自动在最佳时机停止
print(f"训练在第 {len(history.history['loss'])} 轮停止。")
# 此时,model 对象已经是训练好的、在验证集上性能最佳的模型。4、可视化模型
TensorBoard是TensorFlow生态中的终极可视化工具。它提供了一个Web界面,可以动态、交互式地查看以下内容:标量(损失和指标随时间的变化曲线)、图、直方图、投影器(高维数据的降维可视化)Profiler(分析训练性能瓶颈)。
使用TensorBoard插件必须修改程序,一边将想要的可视化数据输出到称为事件文件的特殊二进制日志文件。每个二进制数据记录称为摘要。TensorBoard服务器将监视日志目录,并将自动获取更改并更新可视化效果:这可以可视化实时数据(有短暂延迟)。
使用TensorBoard实现可视化的基本流程:创建日志目录------创建TensorBoard回调对象------在模型中传入回调------启动TensorBoard服务器并指定日志目录
python
from pathlib import Path
from time import strftime
# 1、根据当前日期和时间生成日志子目录的路径,以便每次运行时都不同:
def get_run_logdir(root_logdir="my_logs"):
return Path(root_logdir) / strftime("run_%Y_%m_%d_%H_%M_%S")
run_logdir = get_run_logdir()
# 2、对批次100和200之间的网络进行分析
tensorboard_cb = tf.keras.callbacks.TensorBoard(run_logdir,profile_batch=(100, 200))
# 3、传入回调
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid),
callbacks=[tensorboard_cb])
# 4、启动服务器
%load_ext tensorboard
%tensorboard --logdir=./my_logs六、微调神经网络超参数
神经网络的灵活性也是它们的主要缺点之一:有许多超参数需要调整。
不仅可以使用任何可以想象的网络架构,而且即使在基本的MLP中,也可以更改层数、神经元数量和每层中使用的激活函数类型、权重初始化逻辑、要使用的优化器类型、它的学习率、批量大小,等等。
可以使用Keras Tuner库,这是一个用于Keras模型的超参数微调库。它提供多种微调策略,高度可定制,并且与TensorBoard完美集成。
1、对于超参数的介绍
(1)隐藏层数量
对于许多问题,你可以从单个隐藏层开始并获得合理的结果。只要有足够多的神经元,只有一个隐藏层的MLP理论上就可以对最复杂的功能进行建模。但是对于复杂的问题,深层网络的参数效率要比浅层网络高得多:与浅层网络相比,深层网络可以使用更少的神经元对复杂的功能进行建模,从而使它们在相同数量的训练数据下可以获得更好的性能。
现实世界中的数据通常以这种层次结构进行构造,而深度神经网络会自动利用这一事实:较低的隐藏层对低层结构(例如形状和方向不同的线段)建模,中间的隐藏层组合这些低层结构,对中间层结构(例如正方形、圆形)进行建模,而最高的隐藏层和输出层将这些中间结构组合起来,对高层结构(例如人脸)进行建模。
这种分层架构不仅可以帮助DNN更快地收敛到一个好的解,而且还可以提高DNN泛化到新数据集的能力。例如,如果已经训练了一个模型来识别图片中的人脸,并且现在想训练一个新的神经网络来识别发型,则可以通过重用第一个网络的较低层来开始训练。你可以将它们初始化为第一个网络较低层的权重和偏置,而不是随机初始化新神经网络前几层的权重和偏置。这样,网络就不必从头开始学习大多数图片中出现的所有低层结构。只需学习更高层次的结构(例如发型)。这称为迁移学习。
总而言之,对于许多问题,你可以仅从一两个隐藏层开始,然后神经网络就可以正常工作。对于更复杂的问题,你可以增加隐藏层的数量,直到开始过拟合训练集为止。非常复杂的任务(例如图像分类或语音识别)通常需要具有数十层(甚至数百层,但不是全连接的网络)的网络,并且它们需要大量的训练数据。几乎不必从头开始训练这样的网络,更常见的方法是重用一部分执行类似任务的预训练过的最新网络。这样,训练就会快得多,所需的数据也要少得多。
(2)每个隐藏层的神经元数量
输入和输出层中神经元的数量取决于任务所需的输入和输出类型。
例如,MNIST任务需要28×28=784个输入神经元和10个输出神经元。对于隐藏层,过去通常将它们的大小划分成金字塔状,每一层的神经元越来越少。理由是许多低层特征可以合并成更少的高层特征。MNIST的典型神经网络可能有3个隐藏层,第一层包含300个神经元,第二层包含200个神经元,第三层包含100个神经元。 但是,这种做法在很大程度上已被放弃。
因为在所有隐藏层中使用相同数量的神经元似乎在大多数情况下都表现一样好,甚至更好;还只需要调整一个超参数,而不是每层一个。 就像层数一样,可以尝试逐渐增加神经元的数量,直到网络开始过拟合为止。或者,可以尝试构建一个模型,其层数和神经元比你实际需要的多一些,然后使用早停和其他正则化技术来防止过拟合。Google的科学家将这种方法称为"弹力裤"方法:与其浪费时间寻找与自己的尺码完全匹配的裤子,不如使用大尺寸的弹力裤来缩小到合适的尺寸。使用这种方法,可以避免可能会破坏模型的瓶颈层。
事实上,如果一层的神经元太少,那么它将没有足够的表征能力来保留来自输入的所有有用信息(例如,一个有两个神经元的层只能输出2D数据,因此如果它获得3D数据作为输入,那么一些信息将丢失)。无论网络的其余部分有多强大,这些信息都将永远无法恢复。 通常通过增加层数而不是每层神经元数,将获得更多收益。
(3)学习率
学习率可以说是最重要的超参数。一般而言,最佳学习率约为最大学习率的一半(即学习率大于算法发散的学习率,线性回归梯度下降)。
找到一个好的学习率的一种方法是对模型进行数百次迭代训练,从非常小的学习率(例如10^(-5))开始,然后逐渐将其增加到非常大的值(例如10)。这是通过在每次迭代中将学习率乘以恒定因子来完成的(例如,乘以(10/10-5)1/500以在500次迭代中从10-5变为10)。
如果将损失作为学习率的函数进行绘制(对学习率使用对数坐标),应该首先看到它在下降。但是过一会儿学习率将变得过大,因此损失将重新上升:最佳学习率将比损失开始攀升的点低一些(通常是转折点的十分之一)。然后你可以重新初始化模型,并以这种良好的学习率正常训练模型 最佳学习率取决于其他超参数,尤其是批量大小,因此如果你修改了任何超参数,请确保也更新学习率。
(4)批量大小
批量大小可能会对模型的性能和训练时间产生重大影响。
使用大批量的主要好处是像GPU这样的硬件加速器可以有效地对其进行处理 ,因此训练算法每秒会看到更多的实例。因此,许多研究人员和从业人员建议使用GPU RAM可容纳的最大批量。
但是这里有一个陷阱:在实践中,大批量通常会导致训练不稳定,尤其是在训练开始时,结果模型的泛化能力可能不如小批量训练的模型 Yann LeCun甚至在推特上写道:"朋友不会让朋友使用大于32的小批量处理。"并引用了在2018年发表的一篇论文,得出的结论是首选使用小批量(2--32),因为小批量可以在更少的训练时间内获得更好的模型。
但是,其他研究者提出相反意见,论文表明,可以通过各种技术手段使用非常大的批量(最多8192)处理,例如提高学习率(即以较小的学习率开始训练,然后提高学习率),并可以获得非常短的训练时间,没有泛化能力的差距。因此一种策略是尝试使用大批量处理,慢慢增加学习率,如果训练不稳定或最终表现令人失望,则尝试使用小批量处理。
(5)其他超参数
优化器:选择比普通小批量梯度下降更好的优化器(并调整其超参数)也很重要。
激活函数:通常ReLU激活函数是所有隐藏层默认好的设置,但对于输出层,其激活函数取决于具体任务。
迭代次数:大多数情况不需要调整,只需要设置一个很大的数,之后使用早停就可以了。
2、神经网络的超参数搜索的流程
实现流程:定义超模型函数------选择调优器并实例化------ 执行搜索------获取搜索后的草参数或模型
定义超模型函数:该函数接受kt.HyperParameters对象作为参数,在函数内部通过这个对象定义要搜索的超参数空间(隐藏层数量、隐藏层的神经元数量、学习率、优化器、批量大小、激活函数的范围),最终返回编译好的model。
选择调优器并实例化:RandomSearch随机搜索、Hyperband速度快、BayesianOptimization比随机搜索高效。不同的优化器相同参数有:最大试验次数,seed随机种子,overweite是否覆盖现有项目,project_name项目名称,directory保存路径。
python
tuner = kt.RandomSearch(
my_hy,
objective="val_accuracy",
max_trials=50, # 中等数量的试验
executions_per_trial=2, # 每个配置运行2次取平均
seed=42,
project_name="quick_search"
)
tuner = kt.Hyperband(
my_hy,
objective="val_accuracy",
max_epochs=200, # 设置足够的epochs让早停工作
factor=3,
hyperband_iterations=2, # 增加迭代次数提高搜索质量
seed=42,
project_name="efficient_search"
)
tuner = kt.BayesianOptimization(
my_hy,
objective="val_accuracy",
max_trials=100,
num_initial_points=10, # 更多的初始随机采样
alpha=1e-4,
beta=2.6,
seed=42,
project_name="smart_search"
)执行搜索:调用tuner.search()方法,传入训练数据、验证数据、训练轮次等。
python
def build_model(hp):
n_hidden = hp.Int("n_hidden", min_value=0, max_value=8, default=2)
n_neurons = hp.Int("n_neurons", min_value=16, max_value=256)
learning_rate = hp.Float("learning_rate", min_value=1e-4, max_value=1e-2, sampling="log")
optimizer = hp.Choice("optimizer", values=["sgd", "adam"])
activation = hp.Choice("activation", values=["relu", "sigmoid"])
if optimizer == "sgd":
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)
else:
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten())
for _ in range(n_hidden):
model.add(tf.keras.layers.Dense(n_neurons, activation=activation))
model.add(tf.keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
return model
random_search_tuner = kt.RandomSearch(build_model, objective="val_accuracy", max_trials=3, overwrite=True,
directory="./models/my_fashion_mnist", project_name="my_rnd_search", seed=42)
random_search_tuner.search(X_train, y_train,epochs = 5, validation_data=(X_valid, y_valid))3、使用函数式 API 实现搜索
build方法返回完整的模型,也就不需要写call方法定义模型内部的连接细节了
python
import keras_tuner as kt
class MyClassificationHyperModel(kt.HyperModel):
def build(self,hp):
return build_model(hp)
def fit(self, hp, model, X, y, **kwargs):
if hp.Boolean("normalize"):
norm_layer = tf.keras.layers.Normalization()
X = norm_layer(X) # 对训练数据的标准化
batch_size = hp.Int("batch_size", min_value=2, max_value=128, default=32)
return model.fit(X, y,batch_size = batch_size, **kwargs)
my_hypermodel = MyClassificationHyperModel()
random_search_tuner = kt.RandomSearch(my_hypermodel, objective="val_accuracy", max_trials=3, overwrite=True,directory="./models/my_fashion_mnist", project_name="my_rnd_search", seed=42)
random_search_tuner.search(X_train, y_train,epochs = 5, validation_data=(X_valid, y_valid))4、获取搜索后的参数
使用tuner.get_best_hyperparameters() 或 tuner.get_best_models() 来检索性能最佳的超参数组合或直接加载训练好的最佳模型。
python
# 获取最佳模型
top3_models = random_search_tuner.get_best_models(num_models=3)
best_model = top3_models[0]
# 获取最佳模型的超参数
top3_params = random_search_tuner.get_best_hyperparameters(num_trials=3)
top3_params[0].values # best hyperparameter values每个微调器都由一个Oracle引导:在每次实验之前,微调器要求Oracle告诉它下次实验应该是什么。RandomSearch微调器使用RandomSearch Oracle,它只是随机选择下一个实验, 由于"神谕"跟踪所有实验,可以要求它给你最好的一个,并且可以显示该实验的摘要。
python
# 通过Oracle找到最佳参数
best_trial = random_search_tuner.oracle.get_best_trials(num_trials=1)[0]
best_trial.summary()
# 直接访问具体指标
best_trial.metrics.get_last_value("val_accuracy")对最佳性能满意,则可以在完整训练集(X_train_full和y_train_full)上继续几轮训练,然后在测试集上评估,最后部署到生产环境中。
python
best_model.fit(X_train_full, y_train_full, epochs=10)
test_loss, test_accuracy = best_model.evaluate(X_test, y_test)