你是否好奇过,一条看似简单的SQL查询语句,在MySQL内部究竟经历了怎样的"奇幻之旅"?从连接建立到结果返回,MySQL是如何层层处理、优化执行,最终将数据呈现在我们面前的?
作为一名开发者,深入理解MySQL的内部工作原理,就像是获得了数据库性能优化的"上帝视角"。无论是连接池的配置、索引的设计,还是存储引擎的选型,都将变得有据可依。今天,就让我们一起揭开MySQL的神秘面纱,探寻其内部工作机制,为构建高性能数据库应用打下坚实基础!
一、MySQL整体架构设计
MySQL 采用经典的分层架构设计,整体可分为 Server 层和存储引擎层两大部分。这种设计实现了核心功能与存储实现的分离,为不同类型的应用场景提供了灵活的存储方案。
MySQL的基本架构示意图
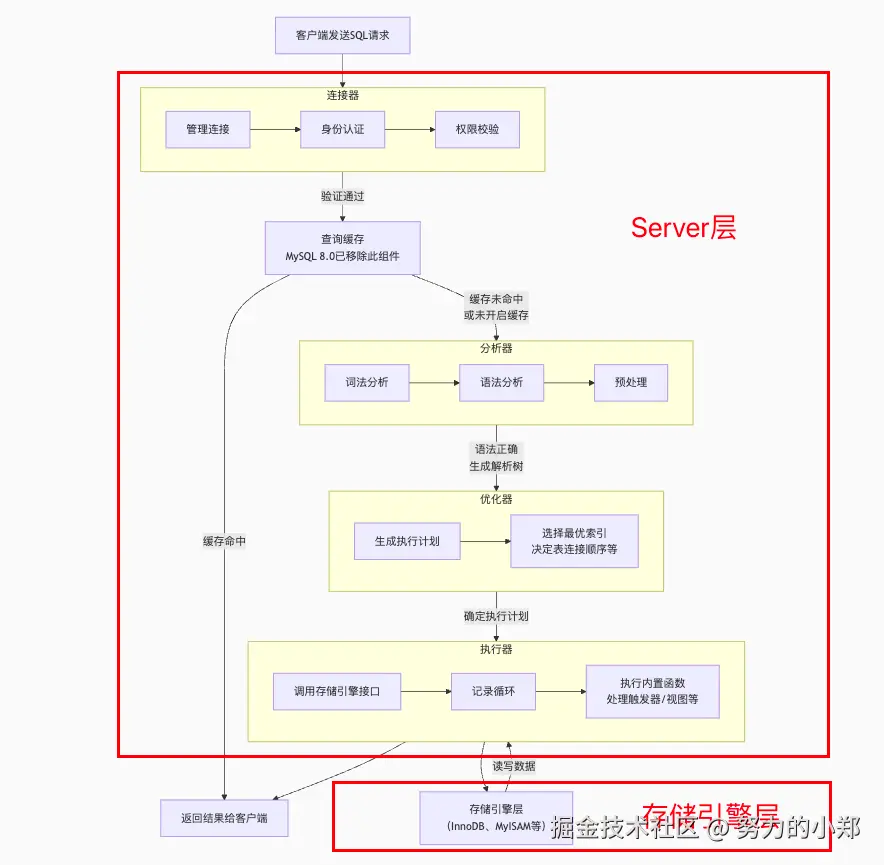
1.1 Server层:核心服务枢纽
Server 层包含 MySQL 的核心服务组件,主要负责以下功能:
- 连接管理:处理客户端连接、身份认证和权限验证
- SQL 接口:接收并解析 SQL 命令,返回执行结果
- 查询处理:包括查询解析、优化和执行
- 所有的内置函数:提供日期、时间、数学、加密等各类函数
- 跨引擎功能:实现存储过程、触发器、视图等高级特性
或者说Server层包括连接器、查询缓存、分析器、优化器、执行器等
1.2 存储引擎层:数据存储解决方案
存储引擎层负责数据的物理存储和提取,采用插件式架构,支持多种存储引擎:
- InnoDB:MySQL 5.5.5+ 的默认引擎,支持事务和行级锁
- MyISAM:适用于读密集型场景
- Memory:数据存储在内存中,读写速度极快
- 其他引擎:如 Archive、CSV 等特定用途引擎
存储引擎是基于表的,而不是数据库。
架构特点:所有存储引擎共享同一个 Server 层,这意味着开发者可以根据业务需求选择合适的存储引擎,而无需修改上层应用代码。例如,可以通过以下方式指定存储引擎:
sql
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50)
) ENGINE=InnoDB;
-- 或者使用Memory引擎
CREATE TABLE temp_data (
id INT PRIMARY KEY,
content VARCHAR(100)
) ENGINE=MEMORY;二、连接器:连接管理与权限控制
2.1 连接建立过程
连接器负责管理客户端与 MySQL 服务器的连接建立和维护:
sql
-- 查看连接超时设置(默认8小时)
SHOW VARIABLES LIKE 'wait_timeout';连接建立流程:
- TCP 三次握手建立网络连接
- 身份认证(用户名密码验证)
- 权限信息获取和缓存
- 连接状态维护
2.2 连接权限特性
权限缓存机制:连接建立时获取的权限信息会缓存在连接会话中。即使管理员修改了用户权限,已存在的连接仍然使用旧的权限设置,只有新建立的连接才会应用新的权限。
2.3 连接策略优化
长连接 vs 短连接:
- 长连接:连接建立后保持不关闭,适合频繁请求场景
- 短连接:每次查询后断开连接,适合低频访问场景
推荐策略 :由于建立连接的开销较大(网络握手、权限验证等),建议优先使用长连接。
2.4 长连接内存管理
问题分析:长连接可能导致内存占用持续增长,因为每个连接会话会缓存权限信息、临时变量等资源,这些资源只有在连接断开时才会释放。
解决方案:
- 定期断开重连:在程序中设置连接最大存活时间
- 连接重置 (MySQL 5.7+):使用
mysql_reset_connection重置会话状态 - 连接池配置:合理设置最大连接数和空闲超时时间
java
// JDBC连接池配置示例
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(20);
config.setIdleTimeout(600000); // 10分钟空闲超时
config.setMaxLifetime(1800000); // 30分钟最大存活时间
config.setConnectionTestQuery("SELECT 1");
config.setDataSourceClassName("com.mysql.cj.jdbc.MysqlDataSource");
config.addDataSourceProperty("url", "jdbc:mysql://localhost:3306/test");
config.addDataSourceProperty("user", "username");
config.addDataSourceProperty("password", "password");三、查询缓存:历史功能的演进与淘汰
3.1 工作原理
查询缓存曾经是 MySQL 的性能优化特性:
- 以 Key-Value 形式缓存查询结果
- Key 为查询语句,Value 为查询结果
- 返回结果前进行权限验证
3.2 淘汰原因
缓存失效问题:任何对表的更新操作都会导致该表的所有查询缓存失效。在更新频繁的生产环境中,缓存命中率极低,反而增加了维护开销。(通常使用查询缓存弊大于利)
版本演进:MySQL 8.0 正式移除了查询缓存功能,建议开发者通过其他方式优化查询性能。
四、分析器:SQL解析与语法验证
4.1 词法分析
将 SQL 字符串分解为有意义的标记(tokens):
示例语句:SELECT id, name FROM users WHERE age > 18
分解结果:SELECT、id、,、name、FROM、users、WHERE、age、>、18
4.2 语法分析
根据 MySQL 语法规则验证语句结构,生成抽象语法树(AST)。如果发现语法错误,会返回详细的错误信息:
sql
-- 错误示例
SELECT id, name FROM users WHRE age > 18;
-- 错误信息
ERROR 1064 (42000): You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version
for the right syntax to use near 'WHRE age > 18' at line 1排查技巧:关注错误信息中 "use near" 后面的内容,这通常是语法错误的位置。
五、优化器:执行计划生成与优化
5.1 优化决策
优化器负责生成最优的执行计划,主要决策包括:
索引选择:根据统计信息选择最合适的索引
连接顺序:决定多表连接的顺序和方式
查询重写:对查询进行等价变换以提高性能
5.2 执行计划分析
使用 EXPLAIN 命令查看优化器生成的执行计划:
sql
EXPLAIN
SELECT * FROM orders o JOIN users u ON o.user_id = u.id WHERE o.amount > 1000;关键指标:
- type:连接类型(性能从优到差:const > eq_ref > ref > range > index > ALL)
- rows:预估扫描行数
- key:实际使用的索引
- Extra:额外信息(如 Using where、Using index 等)
六、执行器:查询执行与结果返回
6.1 执行流程
执行器负责调用存储引擎接口执行查询:
- 权限验证:验证用户对目标表的操作权限
- 引擎调用:根据表定义的存储引擎调用相应接口
- 结果返回:处理结果集并返回给客户端
6.2 执行示例
以简单查询为例说明执行过程:
sql
SELECT * FROM users WHERE id = 100;执行步骤:
- 调用存储引擎接口获取第一行数据
- 判断 id 是否等于 100,符合条件则加入结果集
- 继续获取下一行,重复判断过程
- 遍历完成后返回结果集
6.3 性能监控
慢查询分析:通过慢查询日志监控执行性能
sql
-- 查看慢查询配置
SHOW VARIABLES LIKE '%slow_query_log%';
SHOW VARIABLES LIKE 'long_query_time';
-- 查看MySQL运行状态
SHOW STATUS LIKE "%uptime%";
SHOW STATUS LIKE "Threads_connected";
SHOW STATUS LIKE "Threads_running";重要指标 :rows_examined 表示实际扫描的行数,是查询优化的重要参考。
七、存储引擎层详解与选型指南
7.1 InnoDB:事务安全首选
适用场景:
- 需要事务支持的业务系统
- 高并发读写场景
- 要求数据一致性和持久性的应用
核心特性:
- 支持 ACID 事务
- 行级锁设计,支持高并发
- 外键约束支持
- MVCC 多版本并发控制
- 崩溃恢复能力
存储结构:
- 数据与索引聚簇存储
- 使用 Buffer Pool 缓存数据页
- 支持在线热备份
7.2 MyISAM:读密集型应用
适用场景:
- 读多写少的业务
- 数据仓库和报表系统
- 不需要事务支持的日志记录
特点:
- 表级锁设计,并发性能有限
- 数据和索引分离存储(.MYD 和 .MYI 文件)
- 不支持事务和外键
- 全文索引支持
7.3 Memory:内存临时存储
适用场景:
- 临时数据存储
- 高速缓存层
- 中间结果处理
特点:
- 数据存储在内存中,读写极快
- 服务重启后数据丢失
- 不支持 TEXT 和 BLOB 类型
- 表级锁设计
7.4 存储引擎对比与选型
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务支持 | ✅ | ❌ | ❌ |
| 锁粒度 | 行级锁 | 表级锁 | 表级锁 |
| 外键支持 | ✅ | ❌ | ❌ |
| 崩溃恢复 | 支持 | 不支持 | 不支持 |
| 并发性能 | 高 | 低 | 中 |
| 存储限制 | 64TB | 256TB | RAM大小 |
| 适用场景 | 事务型应用 | 读密集型 | 临时数据 |
选型建议:
- 默认选择 InnoDB:适用于大多数业务场景
- 读密集型考虑 MyISAM:但要注意锁机制限制
- 临时数据使用 Memory:注意数据持久性问题
- 混合使用:在同一数据库中根据表的特点选择不同引擎
绝大多数时候我们使用的都是MySQL默认的InnoDB存储引擎,在某些读密集的极特殊情况下,使用MyISAM也是合适的。不过,前提是你的项目不介意MyISAM不支持事务、崩溃恢复等缺点。
《MySQL 高性能》中有一句话这样写到:不要轻易相信"MyISAM 比 InnoDB 快"之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
八、实践总结与优化建议
8.1 连接管理最佳实践
- 使用连接池:减少连接建立开销,控制连接数量
- 合理配置超时:根据业务特点设置连接超时时间
- 监控连接状态:定期检查连接使用情况,避免泄漏
- 连接重用:使用连接重置代替重新建立连接
8.2 查询性能优化
- 索引优化:为常用查询条件创建合适索引
- 避免全表扫描:通过 EXPLAIN 分析执行计划
- 分批处理:大数据量操作分批次进行
- 查询重写:优化复杂查询,避免不必要的连接和子查询
8.3 存储引擎选择策略
- 事务需求:需要事务支持时选择 InnoDB
- 并发考量:高并发写入场景选择 InnoDB
- 读性能:纯读场景可考虑 MyISAM
- 数据量:大数据量场景选择 InnoDB
- 临时数据:临时处理选择 Memory 引擎
8.4 监控与维护
sql
-- 常用监控命令
SHOW PROCESSLIST; -- 查看当前连接
SHOW ENGINE INNODB STATUS; -- InnoDB状态
SHOW GLOBAL STATUS LIKE 'Handler_read%'; -- 索引使用情况
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%'; -- 缓冲池状态九、结语
MySQL的内部工作机制就像一个精密的流水线,每个组件各司其职又相互协作。从连接管理到SQL解析,从查询优化到最终执行,每一个环节都蕴含着丰富的设计智慧。
深入理解 MySQL 的架构设计和工作原理,对于开发高性能数据库应用至关重要。通过合理配置连接参数、优化查询语句和选择合适的存储引擎,可以显著提升系统性能和稳定性。
MySQL 的插件式存储引擎架构为不同场景提供了灵活的解决方案,开发者应该根据具体的业务需求和数据特性选择合适的存储引擎。同时,定期的性能监控和优化是保持数据库健康运行的关键。
参考资料: