问题背景
为了加速数据即席查询,需要将离线 Hive 表数据通过 ETL 写入 StarRocks 内表,采用 INSERT INTO 按天分区导入数据。Hive 表各分区数据量相差不大,但导入耗时在 3~20 分钟之间波动。初步排查通过监控集群 CPU、内存、磁盘 IO 和网络 IO,未发现明显瓶颈。查看BE compaction score也是在一个合理的范围内。进一步检查 Hive 表各分区数据量,确认数据量级一致,排除数据量差异导致的耗时问题。源码分析(StarRocks-3.4.0)通过分析 INSERT INTO 任务的执行计划(EXPLAIN),发现查询计划生成一个 PlanFragment,包含 HdfsScanNode 和 OlapTableSink,表示从 Hive 表读取数据并直接写入 StarRocks 内表,无复杂中间算子。数据通过内存从 HdfsScanNode 传递到 OlapTableSink,由 Pipeline 驱动器协调。因此,瓶颈可能出现在 OlapTableSink。BE 发送端发送端逻辑如下:
-
IndexChannel → NodeChannel(通过 _request_queue 发送请求)→ 调用 brpc 的 _stub->tablet_writer_add_chunks。
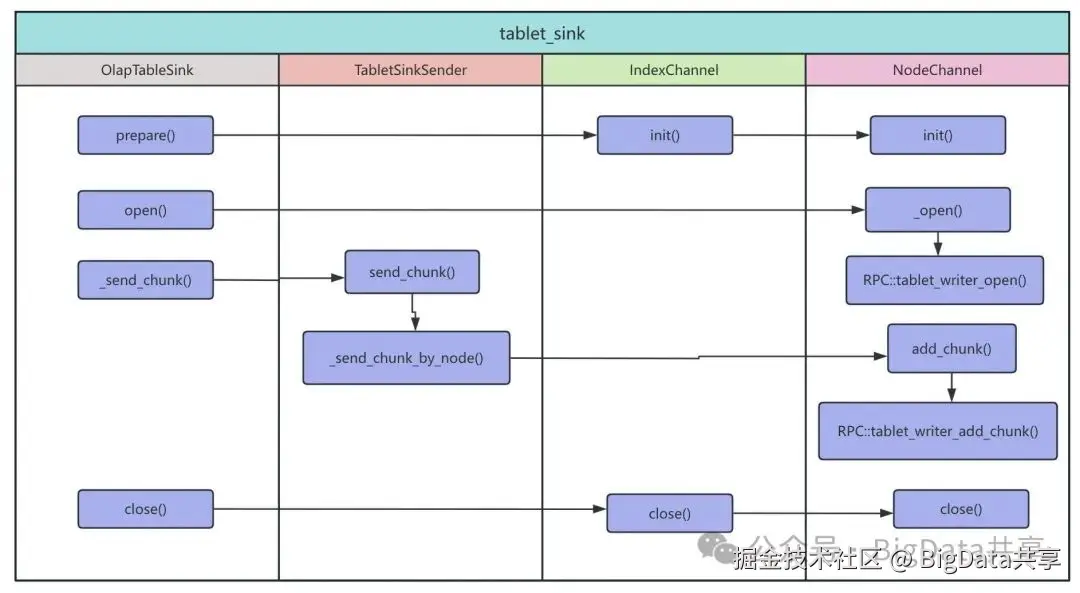
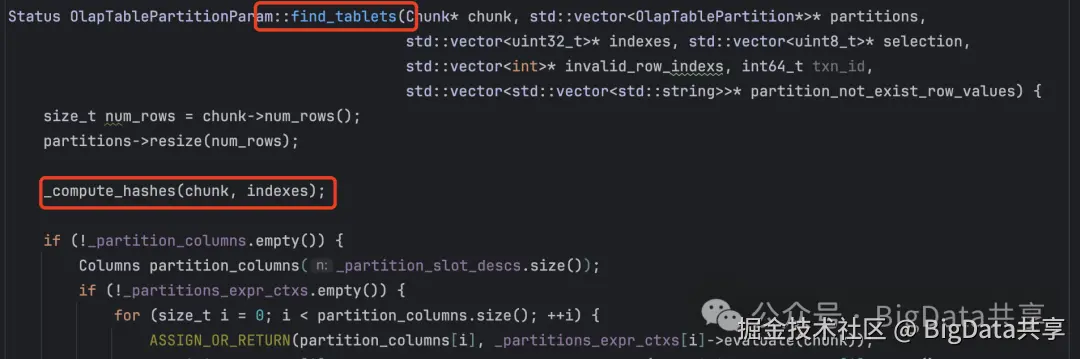
负责将输入的数据块 Chunk 发送到对应的 tablet ,根据输入数据块 Chunk 的分区键值,为每行数据分配目标分区(partitions)和 tablet(indexes),将数据块 Chunk 中的指定行添加到当前节点通道的缓冲区,处理数据过滤、打包,并根据缓冲区状态决定是否发送 RPC 请求到目标存储节点 BE。
-
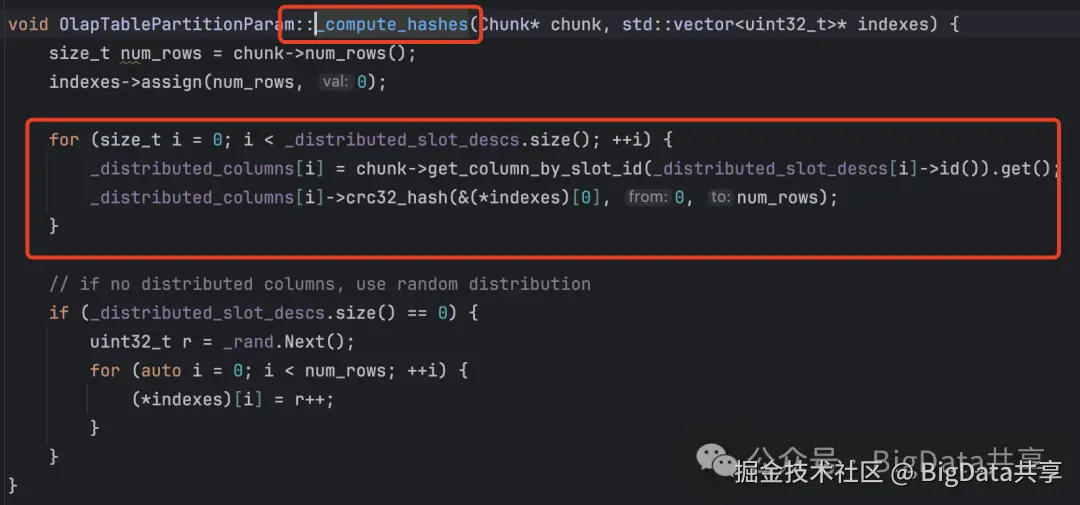
根据输入数据块(Chunk)的分区键值,为每行数据分配目标分区和 tablet,计算哈希值:
BE 接收端接收端流程如下:
-
internal_service.cpp::tablet_writer_add_chunks → load_channel_mgr::add_chunks → load_channel::add_chunks → tablet_channel::add_chunk。
-
数据通过 AsyncDeltaWriter 异步写入 MemTable,内存表满时由 memtable_flush_executor 异步刷盘到持久化存储。
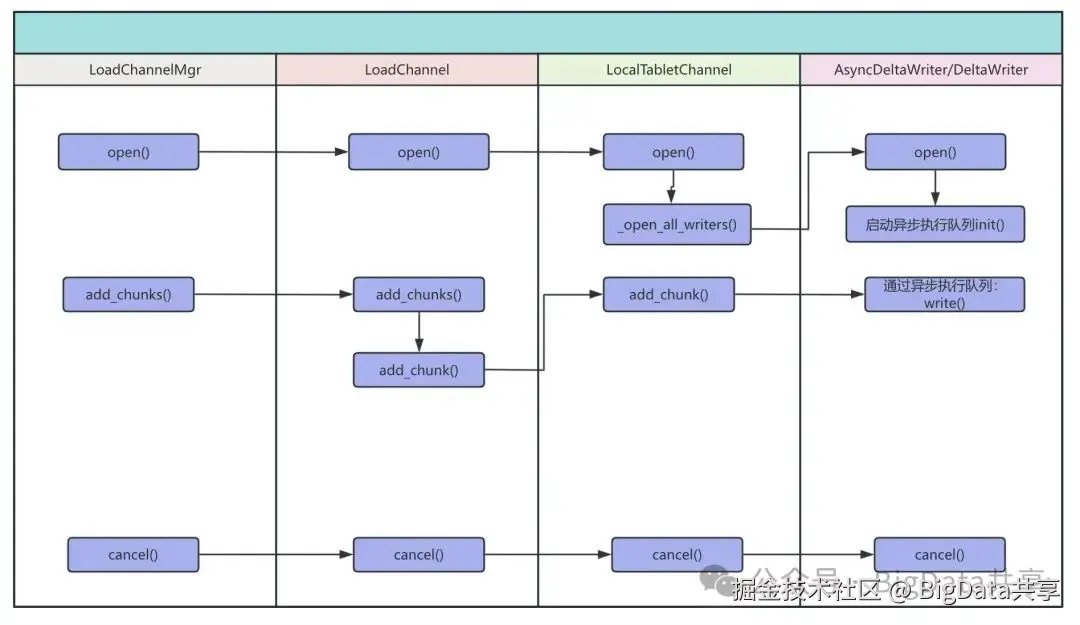
BE内部会有服务用来接收RPC请求,该流程从 tablet_writer_add_chunks 接收外部数据块开始,经过LoadChannelMgr和LoadChannel 的任务分发,路由到 TabletChannel 进行 tablet 级处理。通过 AsyncDeltaWriter 的异步调度,数据被写入MemTable,并在内存表满时由 memtable_flush_executor 异步刷盘到持久化存储。
瓶颈分析
-
数据倾斜排查
最初怀疑是分桶键设置不合理导致数据倾斜。通过 SHOW TABLET FROM tablet_xx DESC RowCount 查看分桶数据量,确认存在一定不均衡,但最大数据量的 tablet 写入速度并非最慢。分析 BE 的 LocalTabletsChannel 日志显示,所有 TabletChannel 持续写入数据,排除分桶键导致的倾斜问题。
-
发送端数据不均衡
进一步分析发现,发送端 tablet_sink_sender 在各 BE 上的数据量差异较大,处理数据量最多的 sender 耗时最长。需要注意的是,这里的数据不均衡是指经过分桶键hash前的数据不均衡。由于任务在一个 PlanFragment 中,问题可能出在 HdfsScanNode 的数据分配。

-
任务分配问题
而执行计划构建和任务分配由FE 完成,流程为:InsertPlanner.plan() → 构建 LogicalPlan → 构建 ExecPlan → DefaultCoordinator 调度。通过DefaultCoordinator 把任务分片分配到不同的BE上。由于scan 的是一张hive表,数据分片的分配逻辑在 HDFSBackendSelector
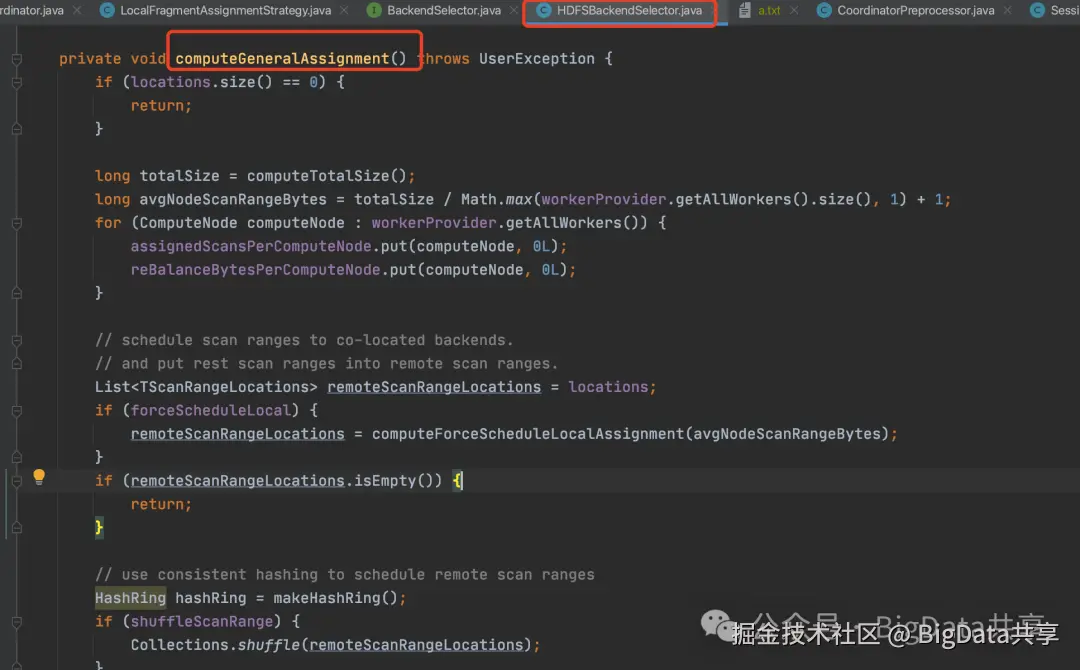 在 forceReBalance = false 且 enableDataCache = false 的情况下,reBalanceScanRangeForComputeNode 方法直接选择一致性哈希环的首个候选节点,不考虑负载均衡:
在 forceReBalance = false 且 enableDataCache = false 的情况下,reBalanceScanRangeForComputeNode 方法直接选择一致性哈希环的首个候选节点,不考虑负载均衡: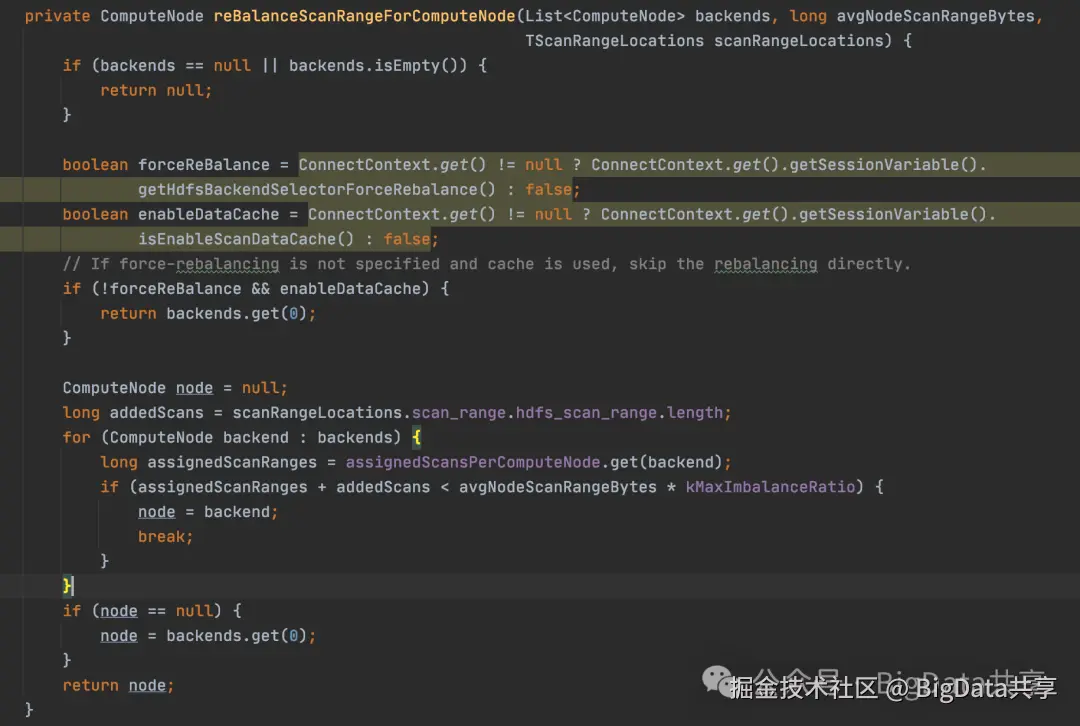 上述逻辑导致数据分配完全依赖哈希映射,未强制平衡数据量(未限制数据量超出 avgNodeScanRangeBytes * 1.1)。
上述逻辑导致数据分配完全依赖哈希映射,未强制平衡数据量(未限制数据量超出 avgNodeScanRangeBytes * 1.1)。
优化措施设置 hdfs_backend_selector_force_rebalance=true,强制重新平衡数据分配。优化后,导入耗时从 19 分钟+缩短至 3 分钟+,显著提升性能。
优化前

优化后 更多大数据干货,欢迎关注我的微信公众号---BigData共享
更多大数据干货,欢迎关注我的微信公众号---BigData共享