点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月01日更新到: Java-113 深入浅出 MySQL 扩容全攻略:触发条件、迁移方案与性能优化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Spark RDD 操作方式Action
- Spark RDD的 Key-Value RDD
- 详细解释与测试案例

梦的开始
WordCount:大数据学习的敲门砖
写一个WordCount程序虽然看似简单,但它在大数据学习中有着深远的意义。就像编程世界中的"Hello World"一样,WordCount是我们迈入分布式计算世界的第一步。这个简单的程序背后蕴含着大数据处理的核心思想:分而治之(Divide and Conquer)。
技术细节与实现过程
在实现WordCount的过程中,我使用了Apache Spark框架和Scala语言。以下是基本的实现步骤:
- 数据加载:使用SparkContext的textFile方法读取输入文本
- 数据转换:通过flatMap将每行文本拆分为单词
- 映射阶段:用map将每个单词转换为(单词,1)的键值对
- 归约阶段:通过reduceByKey将相同单词的计数累加
- 结果输出:将最终结果保存到文件系统或打印到控制台
scala
val textFile = sparkContext.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")实践中的深入理解
通过编写和运行这个程序,我获得了许多宝贵的经验:
- 分布式处理原理:认识到RDD(弹性分布式数据集)是如何在集群节点间分布和处理的
- 性能考虑:理解到shuffle操作的成本,以及如何通过优化分区策略来提升性能
- 容错机制:了解Spark如何通过DAG(有向无环图)和lineage信息实现容错
- 资源管理:学习到如何根据数据规模合理配置executor数量和内存大小
技术优势的体现
WordCount让我深刻体会到Scala语言和Spark框架的优势:
- 函数式编程:Scala的高阶函数让数据处理逻辑表达更加简洁
- 惰性求值:Spark的转换操作只有遇到行动操作才会真正执行
- 并行处理:自动将任务分发到集群节点并行执行
- 内存计算:通过内存缓存中间结果显著提升性能
实际应用场景
这个简单的WordCount程序可以扩展到许多实际应用:
- 日志分析:统计服务器日志中的错误类型频率
- 用户行为分析:分析电商网站搜索关键词的热度
- 文本挖掘:计算文档集合中的词频用于特征提取
- 推荐系统:基于用户评论内容的关键词统计
通过在实际生产环境中部署和运行这个程序,我完成了从理论学习到实践应用的重要跨越。这不仅是代码的实现,更是思维方式的转变。我学会了如何将一个看似简单的问题分解为适合分布式处理的多个阶段。
总的来说,这段经历让我更加坚定在大数据领域深入探索的决心。WordCount不仅是一个起点,它教会我的分布式思维方式和问题解决方法,将成为我大数据技术栈中最重要的基础。
环境依赖
首先要确保你之前的环境都搭建完毕了,最起码的要有单机的Spark,最好是有Spark集群,可以更好的进行学习和测试。
导入依赖
xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>icu.wzk</groupId>
<artifactId>spark-wordcount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.12.10</scala.version>
<spark.version>2.4.5</spark.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>1.3.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.4.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<archive>
<manifest>
<mainClass>cn.lagou.sparkcore.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>编写Scala
使用Scala完成我们的Word Count程序:
scala
package icu.wzk
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setAppName("ScalaHelloWorldCount")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val lines: RDD[String] = sc.textFile(args(0))
val words: RDD[String] = lines.flatMap(line => line.split("\\s+"))
val wordMap: RDD[(String, Int)] = words.map(x => (x, 1))
val result: RDD[(String, Int)] = wordMap.reduceByKey(_ + _)
result.foreach(println)
sc.stop()
}
}大致的项目结构和内容,如下图所示: 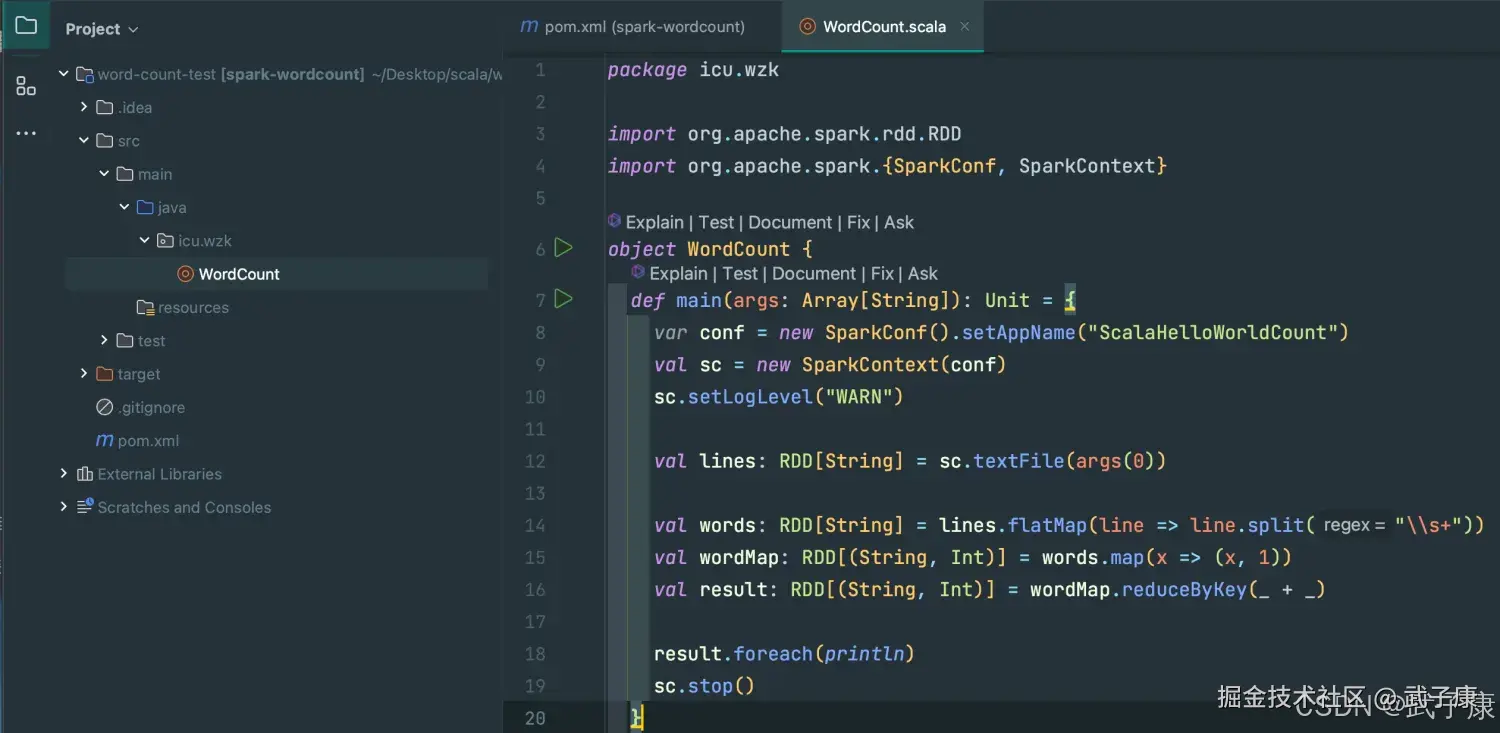
编译项目
运行Maven的Package,等待执行完毕后,会在 target 下打包出一个 Jar 包。 如果是第一次打包,需要下载包,时间会比较久。
shell
# 你也可以用Shell的方式
mvn clean package运行的过程如下图所示: 
打包完的结果大致如下: 
上传项目
将项目上传到Spark的集群中:
shell
cd /opt/wzk我上传到该目录,该目录的情况大致如下: 
运行项目
编写如下的指令,将任务提交到Spark集群中进行运行。 我这里随便找了个文件,你也可以找个文件进行运行。
shell
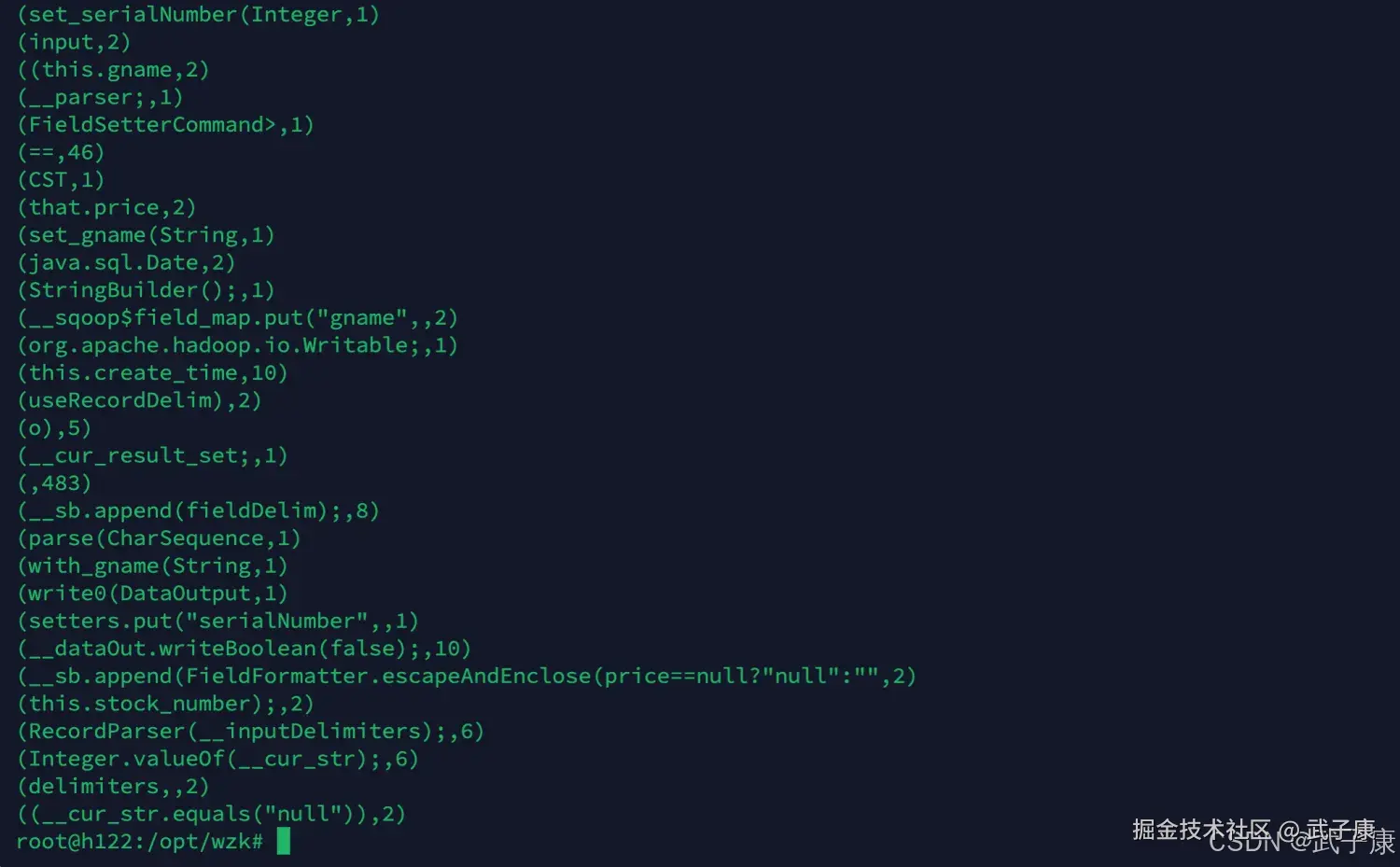
spark-submit --master local[*] --class icu.wzk.WordCount spark-wordcount-1.0-SNAPSHOT.jar /opt/wzk/goodtbl.java运行结果如下图:  经过一段时间的计算之后,可以看到最终的结果如下图所示:
经过一段时间的计算之后,可以看到最终的结果如下图所示: 
编写Java
java
package icu.wzk;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class JavaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("JavaWordCount")
.setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> lines = sc.textFile(args[0]);
JavaRDD<String> words = lines
.flatMap(line -> Arrays.stream(line.split("\\s+")).iterator());
JavaPairRDD<String, Integer> wordsMap = words
.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> results = wordsMap.reduceByKey((x, y) -> x + y);
results.foreach(elem -> System.out.println(elem));
sc.stop();
}
}编译项目
和上面一样,Scala的方式一样: 
上传项目
同样的,和上述的Scala的过程一样,将项目上传:
shell
/opt/wzk/spark-wordcount-1.0-SNAPSHOT.jar运行项目
这里注意,写的是Java的类,而不是Scala的启动:
shell
spark-submit --master local[*] --class icu.wzk.JavaWordCount spark-wordcount-1.0-SNAPSHOT.jar /opt/wzk/goodtbl.java运行的过程截图如下图所示:  等待执行完毕,最终的结果如下图所示:
等待执行完毕,最终的结果如下图所示: