1. 概念相关
1.1. LangChain 定义
LangChain 是一个旨在帮助开发者更轻松、更灵活地构建基于 LLM 的应用程序的 开源框架。
1.2. 传统 AI 应用开发的痛点
🤡 只有经历过 "手撕脚本 " 调 LLM 的人才知道 LangChain 这套 "工具集 " 有多香,Talk is cheap,show you the Code,通过代码的对比来展示这个库开发 LLM APP 的高效性。【完整可运行源码:c1\d1\traditional_llm_app_problem.py】
① 上下文管理:需手动管理对话历史,代码示例:
python
# 初始化OpenAI客户端
ai_client = openai.OpenAI(
api_key="sk-xxx",
base_url="https://xxx.xxx.xxx/v1"
)
# ====== 痛点1:上下文管理 ======
def traditional_conversation_management():
print("=== 传统方式:多轮对话 ===")
# 💡 初始对话历史
conversation_history = []
# 第一轮对话
user_input1 = "我正在学习LangChain,推荐一些入门书籍"
conversation_history.append({"role": "user", "content": user_input1})
response1 = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=conversation_history,
)
assistant_response1 = response1.choices[0].message.content
# 💡 区分角色,手动追加
conversation_history.append({"role": "assistant", "content": assistant_response1})
print(f"助手: {assistant_response1}")
# 第二轮对话 - 手动管理上下文
user_input2 = "这些书籍中哪本最适合零基础的人?"
conversation_history.append({"role": "user", "content": user_input2})
response2 = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=conversation_history # 必须手动传递完整历史
)
assistant_response2 = response2.choices[0].message.content
# 💡 区分角色,手动追加
conversation_history.append({"role": "assistant", "content": assistant_response2})
print(f"助手: {assistant_response2}")
# 第三轮对话 - 继续手动管理,容易出错
user_input3 = "能给我制定一个学习计划吗?"
conversation_history.append({"role": "user", "content": user_input3})
response3 = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=conversation_history
)
assistant_response3 = response3.choices[0].message.content
print(f"助手: {assistant_response3}")
print(f"对话历史长度: {len(conversation_history)} 条消息")② 多步骤任务:需要手动处理每个步骤,错误处理复杂,定位具体失败步骤麻烦,代码示例:
python
# ====== 痛点2:多步骤任务 ======
def traditional_multi_step_task():
print("\n=== 传统方式:文档分析任务 ===")
document_content = """
公司2023年第三季度财报显示,营收增长15%,达到500万美元。
主要增长来源于新产品线的推出和海外市场拓展。
但是,运营成本也上升了12%,主要由于人员扩张和营销投入增加。
净利润为50万美元,同比增长8%。
"""
try:
# 步骤1:文档摘要
print("步骤1:生成文档摘要...")
summary_prompt = f"请为以下文档生成简洁摘要:\n{document_content}"
summary_response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{"role": "user", "content": summary_prompt}]
)
summary = summary_response.choices[0].message.content
print(f"摘要: {summary}")
# 步骤2:关键指标提取
print("\n步骤2:提取关键财务指标...")
metrics_prompt = f"从以下文档中提取所有数值指标,格式为JSON:\n{document_content}"
metrics_response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{"role": "user", "content": metrics_prompt}]
)
metrics = metrics_response.choices[0].message.content
print(f"关键指标: {metrics}")
# 步骤3:趋势分析
print("\n步骤3:进行趋势分析...")
analysis_prompt = f"""
基于以下摘要和指标,分析公司发展趋势:
摘要: {summary}
指标: {metrics}
"""
analysis_response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{"role": "user", "content": analysis_prompt}]
)
analysis = analysis_response.choices[0].message.content
print(f"趋势分析: {analysis}")
# 步骤4:生成建议
print("\n步骤4:生成改进建议...")
recommendation_prompt = f"""
基于以下分析,提供具体的改进建议:
{analysis}
"""
recommendation_response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{"role": "user", "content": recommendation_prompt}]
)
recommendations = recommendation_response.choices[0].message.content
print(f"改进建议: {recommendations}")
except Exception as e:
print(f"错误发生在某个步骤: {e}")③ 外部工具集成:需大量样板代码,工具选择逻辑复杂,代码示例:
python
# ====== 痛点3:外部工具集成 (天气查询+推荐系统) ======
def traditional_tool_integration():
print("\n=== 传统方式:工具集成 ===")
def get_weather(city: str) -> str:
"""获取天气信息的模拟函数"""
weather_data = {
"北京": "晴天,温度25°C,湿度60%",
"上海": "多云,温度22°C,湿度75%",
"广州": "雨天,温度28°C,湿度85%"
}
return weather_data.get(city, "未找到该城市天气信息")
def get_restaurant_recommendations(city: str, weather: str) -> List[str]:
"""根据天气推荐餐厅的模拟函数"""
if "晴天" in weather:
return ["露天BBQ餐厅", "花园咖啡厅", "屋顶酒吧"]
elif "雨天" in weather:
return ["温馨火锅店", "室内日料店", "舒适茶餐厅"]
else:
return ["中式餐厅", "西式简餐", "快餐连锁"]
# 用户询问
user_query = "我在北京,今天适合去哪些餐厅?"
# 手动解析用户意图
print("步骤1:解析用户意图...")
intent_prompt = f"用户询问:{user_query}\n请判断用户想查询哪个城市的信息,只返回城市名称。"
try:
intent_response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{"role": "user", "content": intent_prompt}]
)
city = intent_response.choices[0].message.content.strip()
print(f"识别城市: {city}")
# 手动调用工具1:获取天气
print("步骤2:获取天气信息...")
weather = get_weather(city)
print(f"天气信息: {weather}")
# 手动调用工具2:获取推荐
print("步骤3:获取餐厅推荐...")
restaurants = get_restaurant_recommendations(city, weather)
print(f"推荐餐厅: {restaurants}")
# 手动整合结果
print("步骤4:整合并生成回复...")
final_prompt = f"""
基于以下信息为用户生成友好的回复:
用户询问: {user_query}
城市: {city}
天气: {weather}
推荐餐厅: {', '.join(restaurants)}
"""
final_response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{"role": "user", "content": final_prompt}]
)
result = final_response.choices[0].message.content
print(f"最终回复: {result}")
except Exception as e:
print(f"工具集成失败: {e}")④ 应用扩展性:添加新功能需要修改大量代码,扩展性差,代码示例:
python
# ====== 痛点4:应用扩展性差 (聊天机器人) ======
class TraditionalChatBot:
def __init__(self):
"""初始化聊天机器人"""
self.conversation_history = []
self.supported_functions = ["天气查询", "餐厅推荐", "新闻搜索"]
def process_message(self, user_input: str) -> str:
"""处理用户消息的主要逻辑"""
try:
# 硬编码的意图识别
if "天气" in user_input:
return self._handle_weather_query(user_input)
elif "餐厅" in user_input or "吃饭" in user_input:
return self._handle_restaurant_query(user_input)
elif "新闻" in user_input:
return self._handle_news_query(user_input)
else:
return self._handle_general_chat(user_input)
except Exception as e:
return f"抱歉,处理您的请求时出现错误:{e}"
def _handle_weather_query(self, user_input: str) -> str:
"""处理天气查询"""
# 需要手动实现所有逻辑
return "天气查询功能需要大量代码实现..."
def _handle_restaurant_query(self, user_input: str) -> str:
"""处理餐厅推荐"""
# 又是一大堆硬编码逻辑
return "餐厅推荐功能需要大量代码实现..."
def _handle_news_query(self, user_input: str) -> str:
"""处理新闻搜索"""
# 每个功能都要重复写相似的代码
return "新闻搜索功能需要大量代码实现..."
def _handle_general_chat(self, user_input: str) -> str:
"""处理普通聊天"""
# 手动管理上下文
self.conversation_history.append({"role": "user", "content": user_input})
response = ai_client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=self.conversation_history
)
assistant_response = response.choices[0].message.content
self.conversation_history.append({"role": "assistant", "content": assistant_response})
return assistant_response
def add_new_function(self, function_name: str):
"""添加新功能(展示扩展困难)"""
print(f"要添加'{function_name}'功能,需要:")
print("1. 修改 process_message 方法添加新的条件判断")
print("2. 实现新的 _handle_xxx_query 方法")
print("3. 可能需要修改意图识别逻辑")
print("4. 添加相应的错误处理")
print("5. 更新支持功能列表")
print("扩展一个功能就要改动这么多地方,太痛苦了! (╯°□°)╯︵ ┻━┻")1.3. 基于 LangChain 实现
接着用 LangChain 来实现相同的功能【完整源码:c1\d1\langchain_solutions_examples.py】
① 上下文管理:自动管理对话历史,代码示例:
python
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain, LLMChain
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
# ====== 解决方案1:自动上下文管理 ======
def langchain_conversation_management():
print("=== LangChain方式:多轮对话 ===")
# 初始化LLM和内存
llm = ChatOpenAI(
temperature=0.7,
openai_api_key="sk-xxx",
base_url="https://xxx.xxx.xxx/v1",
model = "gemini-2.5-flash-lite"
)
memory = ConversationBufferMemory(return_messages=True)
# 创建对话链
conversation = ConversationChain(
llm=llm, memory=memory, verbose=True # 显示内部处理过程
)
# 第一轮对话
response1 = conversation.predict(input="我正在学习LangChain ,推荐一些入门书籍")
print(f"助手: {response1}")
# 第二轮对话 - 自动维护上下文
response2 = conversation.predict(input="这些书籍中哪本最适合零基础的人?")
print(f"助手: {response2}")
# 第三轮对话 - 继续自动维护上下文
response3 = conversation.predict(input="能给我制定一个学习计划吗?")
print(f"助手: {response3}")② 多步骤任务:链式处理,错误自动传播,代码示例:
python
# ====== 解决方案2:多步骤任务 - 链式处理 ======
class DocumentAnalysisChain:
"""
LangChain方式:用链式处理实现复杂文档分析
每个步骤都是独立的链,易于维护和测试
"""
def __init__(self):
"""初始化分析链"""
self.llm = ChatOpenAI(
temperature=0.3,
openai_api_key="sk-xxx",
base_url="https://xxx.xxx.xxx/v1",
model = "gemini-2.5-flash-lite"
)
self._setup_chains()
def _setup_chains(self):
"""设置各个处理链"""
# 文档摘要链
summary_prompt = PromptTemplate(
input_variables=["document"],
template="请为以下文档生成简洁摘要,突出关键信息:\n{document}"
)
self.summary_chain = LLMChain(
llm=self.llm,
prompt=summary_prompt,
output_key="summary"
)
# 指标提取链
metrics_prompt = PromptTemplate(
input_variables=["document"],
template="""
从以下文档中提取所有数值指标,以JSON格式返回:
{document}
请按以下格式返回:
{{"营收": "具体数值", "增长率": "具体数值", "成本": "具体数值"}}
"""
)
self.metrics_chain = LLMChain(
llm=self.llm,
prompt=metrics_prompt,
output_key="metrics"
)
# 趋势分析链
analysis_prompt = PromptTemplate(
input_variables=["summary", "metrics"],
template="""
基于以下信息分析公司发展趋势:
文档摘要:{summary}
关键指标:{metrics}
请从以下角度分析:
1. 财务健康状况
2. 增长趋势
3. 潜在风险
"""
)
self.analysis_chain = LLMChain(
llm=self.llm,
prompt=analysis_prompt,
output_key="analysis"
)
# 建议生成链
recommendation_prompt = PromptTemplate(
input_variables=["analysis"],
template="""
基于以下趋势分析,提供3-5条具体的改进建议:
{analysis}
每条建议请包含:
- 具体行动
- 预期效果
- 实施难度
"""
)
self.recommendation_chain = LLMChain(
llm=self.llm,
prompt=recommendation_prompt,
output_key="recommendations"
)
# 组合成顺序链
self.full_chain = SequentialChain(
chains=[
self.summary_chain,
self.metrics_chain,
self.analysis_chain,
self.recommendation_chain
],
input_variables=["document"],
output_variables=["summary", "metrics", "analysis", "recommendations"],
verbose=True
)
def analyze_document(self, document_content: str) -> Dict[str, str]:
"""分析文档并返回完整结果"""
try:
result = self.full_chain({"document": document_content})
return result
except Exception as e:
print(f"分析过程中出现错误: {e}")
return {"error": str(e)}
def langchain_multi_step_task():
"""演示LangChain的多步骤任务处理"""
print("\n=== LangChain方式:文档分析任务 ===")
document_content = """
公司2023年第三季度财报显示,营收增长15%,达到500万美元。
主要增长来源于新产品线的推出和海外市场拓展。
但是,运营成本也上升了12%,主要由于人员扩张和营销投入增加。
净利润为50万美元,同比增长8%。
"""
# 创建文档分析器
analyzer = DocumentAnalysisChain()
# 一行代码完成复杂的多步骤分析
results = analyzer.analyze_document(document_content)
# 输出结果
for key, value in results.items():
if key != "error":
print(f"\n{key.title()}: {value}")③ 外部工具集成:Agent自动选择和组合工具,无需手动编排,代码示例:
python
# ====== 解决方案3:工具集成 - Agent架构 ======
def create_weather_tool():
"""创建天气查询工具"""
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
weather_data = {
"北京": "晴天,温度25°C,湿度60%",
"上海": "多云,温度22°C,湿度75%",
"广州": "雨天,温度28°C,湿度85%",
}
return weather_data.get(city, "未找到该城市天气信息")
return Tool(
name="天气查询",
description="获取指定城市的当前天气信息。输入应该是城市名称。",
func=get_weather,
)
def create_restaurant_tool():
"""创建餐厅推荐工具"""
def get_restaurant_recommendations(query: str) -> str:
"""根据城市和天气推荐餐厅"""
# 简化的推荐逻辑
if "晴天" in query:
restaurants = ["露天BBQ餐厅", "花园咖啡厅", "屋顶酒吧"]
elif "雨天" in query:
restaurants = ["温馨火锅店", "室内日料店", "舒适茶餐厅"]
else:
restaurants = ["中式餐厅", "西式简餐", "快餐连锁"]
return f"推荐餐厅:{', '.join(restaurants)}"
return Tool(
name="餐厅推荐",
description="根据天气情况推荐合适的餐厅。输入应该包含天气信息。",
func=get_restaurant_recommendations,
)
def langchain_tool_integration():
"""LangChain方式:智能工具集成"""
print("\n=== LangChain方式:工具集成 ===")
# 创建工具列表
tools = [create_weather_tool(), create_restaurant_tool()]
# 创建LLM
llm = ChatOpenAI(
temperature=0.3,
openai_api_key="sk-xxx",
base_url="https://xxx.xxx.xxx/v1",
model="gemini-2.5-flash-lite",
)
# 创建Agent
agent_prompt = """
你是一个智能助手,可以帮助用户查询天气和推荐餐厅。
可用工具:{tool_names}
工具描述:
{tools}
用户问题:{input}
请按以下格式思考和行动:
Thought: 我需要分析用户的需求
Action: [工具名称]
Action Input: [工具输入]
Observation: [工具输出]
... (重复 Thought/Action/Action Input/Observation)
Final Answer: [最终回答]
{agent_scratchpad}
"""
# 创建提示模板
prompt = PromptTemplate(
input_variables=["tool_names", "tools", "input", "agent_scratchpad"],
template=agent_prompt,
)
# 创建ReAct Agent
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent, tools=tools, verbose=True, max_iterations=3
)
# 用户查询
user_query = "我在北京,今天适合去哪些餐厅?"
try:
result = agent_executor.invoke({"input": user_query})
print(f"\n最终回复: {result['output']}")
except Exception as e:
print(f"Agent执行错误: {e}")④ 应用扩展性:模块化架构,添加功能只需改动少量代码,代码示例:
python
# ====== 解决方案4:应用扩展性 - 模块化架构 ======
class LangChainChatBot:
"""
LangChain方式:模块化聊天机器人
添加新功能只需注册新工具,无需修改核心逻辑
"""
def __init__(self):
"""初始化聊天机器人"""
self.llm = ChatOpenAI(temperature=0.7,
openai_api_key="sk-xxx",
base_url="https://xxx.xxx.xxx/v1",
model="gemini-2.5-flash-lite",
)
self.memory = ConversationBufferMemory(return_messages=True)
self.tools = []
self.agent_executor = None
# 初始化基础工具
self._register_default_tools()
self._setup_agent()
def _register_default_tools(self):
"""注册默认工具"""
self.add_tool(create_weather_tool())
self.add_tool(create_restaurant_tool())
def add_tool(self, tool: Tool):
"""添加新工具(扩展功能的唯一入口)"""
self.tools.append(tool)
print(f"✅ 已添加工具:{tool.name}")
# 重新设置Agent以包含新工具
if len(self.tools) > 0:
self._setup_agent()
def _setup_agent(self):
"""设置Agent(自动包含所有已注册工具)"""
if not self.tools:
return
agent_prompt = """
你是一个智能助手,可以使用以下工具帮助用户:
可用工具:{tool_names}
工具描述:
{tools}
对话历史:
{chat_history}
用户问题:{input}
{agent_scratchpad}
"""
prompt = PromptTemplate(
input_variables=["tool_names", "tools", "chat_history", "input", "agent_scratchpad"],
template=agent_prompt
)
agent = create_react_agent(self.llm, self.tools, prompt)
self.agent_executor = AgentExecutor(
agent=agent,
tools=self.tools,
memory=self.memory,
verbose=True,
max_iterations=3
)
def chat(self, user_input: str) -> str:
"""处理用户消息"""
try:
if self.agent_executor:
result = self.agent_executor.invoke({"input": user_input})
return result['output']
else:
# 如果没有工具,使用基础对话
conversation = ConversationChain(
llm=self.llm,
memory=self.memory
)
return conversation.predict(input=user_input)
except Exception as e:
return f"抱歉,处理您的请求时出现错误:{e}"
def list_capabilities(self) -> List[str]:
"""列出当前支持的功能"""
capabilities = [tool.name for tool in self.tools]
capabilities.append("普通对话")
return capabilities
def create_stock_tool():
"""创建股票查询工具(演示扩展性)"""
def get_stock_info(symbol: str) -> str:
"""获取股票信息"""
# 模拟股票数据
stock_data = {
"AAPL": "苹果公司 - 当前价格: $150.25, 涨幅: +2.3%",
"GOOGL": "谷歌 - 当前价格: $2,750.80, 涨幅: +1.8%",
"TSLA": "特斯拉 - 当前价格: $850.45, 跌幅: -0.9%"
}
return stock_data.get(symbol.upper(), f"未找到股票 {symbol} 的信息")
return Tool(
name="股票查询",
description="查询指定股票的当前价格和涨跌情况。输入应该是股票代码,如AAPL、GOOGL等。",
func=get_stock_info
)
def demonstrate_langchain_extensibility():
"""演示LangChain的扩展性"""
print("\n=== LangChain方式:应用扩展性 ===")
# 创建聊天机器人
bot = LangChainChatBot()
print("初始功能列表:", bot.list_capabilities())
# 轻松添加新功能
print("\n🔧 添加股票查询功能...")
stock_tool = create_stock_tool()
bot.add_tool(stock_tool)
print("更新后功能列表:", bot.list_capabilities())
# 测试新功能
print("\n💬 测试对话...")
response1 = bot.chat("北京今天天气怎么样?")
print(f"用户: 北京今天天气怎么样?")
print(f"助手: {response1}")
response2 = bot.chat("AAPL股票现在多少钱?")
print(f"\n用户: AAPL股票现在多少钱?")
print(f"助手: {response2}")😄 自动管理对话历史和记忆,通过链式调用实现复杂推理,支持工具集成和外部数据访问,少量代码即可实现Agent自主决策,LangChain 0.1.x 后还进行了重大重构,如:从传统 Chain 到 LCEL 。开发 LLM 应用 LangChain 是正解啊 ❗️
1.4. 安装与环境配置
python
# ==============================
# 💡 ① 强烈建议创建虚拟环境,在项目根目录下执行:
# ==============================
python -m venv .venv
# 激活虚拟环境
# Windows (PowerShell)
..venv\Scripts\Activate.ps1
# macOS/Linux
source .venv/bin/activate
# ==============================
# 💡 ② 相关依赖库安装,(🔥标识的是必须的!)
# ==============================
# ✨入门学习项目直接下面这句一把梭就好,其它库按需选择
pip install langchain langchain-openai python-dotenv
# 【核心框架包】
pip install langchain # 🔥 主要功能包
pip install langchain-core # 基础抽象层
pip install langchain-community # 第三方集成
pip install langchain-experimental # 实验性功能
# 【LLM提供商集成包】
pip install langchain-openai # 🔥专用的 OpenAI 集成包
pip install langchain-anthropic # Claude 模型
pip install langchain-huggingface # Hugging Face 模型
pip install langchain-google-vertexai # Google 模型
# 【向量数据库集成包】
# 本地向量数据库
pip install chromadb # 轻量级向量数据库
pip install faiss-cpu # Facebook AI 相似性搜索
# 云端向量数据库
pip install pinecone-client # Pinecone 向量数据库
pip install weaviate-client # Weaviate 向量数据库
# 【工具和实用包】
# 文本处理和分割
pip install tiktoken # 🔥 OpenAI 的 tokenizer,用于文本分词和编码
pip install unstructured # 文档解析
# 环境配置
pip install python-dotenv # 🔥 环境变量管理,方便配置 API Key 等敏感信息
# 网页处理
pip install beautifulsoup4 # 网页解析
pip install requests # HTTP 请求
# 【部署与服务包】
# LangChain 服务化
pip install langserve # REST API 部署
pip install langchain-cli # 命令行工具
pip install langgraph # 多智能体应用构建
# 监控和调试
pip install langsmith # LangSmith SDK
# ==============================
# 💡 ③ 环境变量配置
# ==============================
# 大多数 LangChain 功能依赖外部 LLM 服务,需设置对应的API密钥,除了在代码调用时动态设置外,
# 还可以配置对应的环境变量,如 (OpenAI):
# macOS/Linux
export OPENAI_API_KEY="your_openai_api_key"
# Windows(PowerShell)
$Env:OPENAI_API_KEY="your_openai_api_key"
# 也可通过代码动态设置,其它 LLM 可参考各自文档,将对应环境变量添加到系统中。
# 如:Hugging Face: export HUGGINGFACEHUB_API_TOKEN="your_token"
# 😄还可以通过【python-dotenv】库将变量存放在【.env】文件中,在程序运行时
# 自动加载到系统环境中,这样可以避免在代码中硬编码敏感信息python-dotenv 库的用法非常简单:
① 在项目根目录下新建一个名为 .env 的文本文件
格式为 KEY=VALUE,示例如下 (每行一个,使用#添加注释,不要在等号两侧添加空格):
python
OPENAI_API_KEY=sk-xxxxxxx
DATABASE_URL=postgresql://user:password@localhost:5432/mydb
DEBUG=True② 使用 load_dotenv 加载,之后就可以通过 os.getenv() 或 os.environ() 读取变量:
python
from dotenv import load_dotenv
import os
# 从项目根目录或指定路径加载 .env
load_dotenv()
# 之后就可以通过 os.getenv 或 os.environ 读取变量
openai_key = os.getenv("OPENAI_API_KEY")
db_url = os.environ.get("DATABASE_URL")
debug_mode = os.getenv("DEBUG", "False") == "True"
print("OpenAI Key:", openai_key)
print("Database URL:", db_url)
print("Debug Mode:", debug_mode)
# Tips:如果 .env 文件不在当前工作目录,可以设置自定义路径
load_dotenv(dotenv_path="/path/to/your/.env")
# 还可以调用 load_dotenv() 可以递归向上查找,直到找到 .env 为止
load_dotenv(find_dotenv())
#【强制覆盖】默认情况下,已存在的环境变量不会被 .env 覆盖,如需强制覆盖,可设置属性
load_dotenv(override=True)
#【只加载指定变量】可通过 dotenv_values 读取并过滤
from dotenv import dotenv_values
config = dotenv_values(".env")
# config 是一个 dict,可按需使用
api_key = config.get("OPENAI_API_KEY")1.5. LangChain 生态系统
① langchain-core (核心抽象和LCEL)
- 统一接口设计:提供Runnable协议,让所有组件都能无缝组合。
- LCEL语言:声明式的链组合语言,类似于Unix管道操作。
- 异步支持:原生支持async/await,提升性能。
② langchain-community (第三方集成)
- 丰富的集成:支持200+种LLM供应商、向量数据库 (如Pinecone、Chroma、FAISS、Weaviate等)、工具 (搜索引擎、API调用、数据库查询等)
- 开源生态:社区贡献的各种集成组件。
- 快速试验:新技术的试验场地。
③ langchain (主要链、代理和检索策略)
- 预构建链:RAG链、总结链、问答链。
- Agent系统:ReAct、Plan-and-Execute等智能代理。
- 检索策略:多查询检索、混合检索、上下文压缩。
④ LangGraph (有状态多Agent应用构建)
- 状态管理:支持复杂的工作流状态。
- Agent协作:多个专业Agent的协同工作。
- 可视化工作流:图形化的状态机设计。
⑤ LangSmith (开发者平台-调试、测试、监控)
- 全链路追踪:从输入到输出的完整调用链
- 性能监控:延迟、成本、准确率等关键指标
- A/B测试:不同模型和策略的对比测试
- 数据集评估:自动化的评估流程
⑥ LangServe (将链部署为REST API)
- 一键部署:将LangChain链转换为REST API。
- 自动文档:生成OpenAPI规范和交互界面。
- 性能优化:支持批处理、流式响应。
- 监控集成:与LangSmith无缝集成。
1.6. 文档 & 资讯
- 【Github仓库】langchain-ai/langchain
- 【官方文档】LangChain Introduction
- 【官网网站】产品介绍、最新动态和商业解决方案
- 【开发者社区】交流学习,遇到问题随时问问
😄 概念相关的东西就了解到这,接着系统学习 LangChain 的 "七大核心组件"。
2. Models - LLM模型配置
🤔 Models 组件是与大型语言模型 (LLMs ) 进行交互的核心,它为 不同类型的AI模型 提供了一个 "标准化的接口"。 这使得开发者可以轻松地在不同的模型之间切换,而无需重写大量的代码。
该组件的主要作用是 "简化和标准化与 AI 模型的交互",其核心优势包括:
- 接口统一:为所有支持的模型提供了一致的调用方式,降低了学习成本。
- 模型切换灵活:可以轻松地更换底层的语言模型,便于测试和选择最适合特定任务的模型。
- 简化模型管理:将模型的实例化和配置过程变得简单明了。
LangChain 的 Models 组件主要分为三种类型,每种都有其特定的应用场景:
- LLMs (Large Language Models):接受一个字符串作为输入,并返回一个字符串作为输出。它们是文本补全模型,适用于各种自然语言处理任务。
- Chat Models (聊天模型):与 LLMs 不同,聊天模型以一系列消息作为输入,并返回一个消息作为输出。这种基于消息的交互方式非常适合构建对话式应用,如:聊天机器人。
- Text Embedding Models (文本嵌入模型):将文本转换为密集的向量表示 (即 "嵌入 "),这些向量可以被存储在 向量数据库 中,用于进行 相似性搜索 ,这在 检索增强生成(RAG) 等应用中至关重要。
2.1. 多模型支持
2.1.1. 不同LLM厂商的API调用
安装核心的 langchain-core 包 + 想要使用的模型的具体集成包 (如 langchain_openai) 即可调用对应LLM提供商的模型,梳理下常见 LLM 供应商的依赖的包和核心类:
【OpenAI → langchain-openai】
- OpenAI - GPT-3.5/GPT-4 文本补全模型
- ChatOpenAI - GPT-3.5/GPT-4 聊天模型
- OpenAIEmbeddings - 嵌入模型
- AzureChatOpenAI - Azure OpenAI 聊天模型
- AzureOpenAI - Azure OpenAI 文本模型
- AzureOpenAIEmbeddings - Azure OpenAI 嵌入模型
【Google → langchain-google-genai、langchain-google-vertexai】
- ChatGoogleGenerativeAI - Gemini 聊天模型
- GoogleGenerativeAI - Gemini 文本模型
- GoogleGenerativeAIEmbeddings - Google 嵌入模型
- ChatVertexAI - Vertex AI 聊天模型
- VertexAI - Vertex AI 文本模型
- VertexAIEmbeddings - Vertex AI 嵌入模型
【Anthropic → langchain-anthropic】
- ChatAnthropic - Claude 聊天模型
- AnthropicLLM - Claude 文本模型
【Hugging Face → angchain-huggingface】
- ChatHuggingFace - Hugging Face 聊天模型
- HuggingFacePipeline - Hugging Face Pipeline 模型
- HuggingFaceEmbeddings - Hugging Face 嵌入模型
- HuggingFaceEndpoint - Hugging Face 推理端点
【Ollama (本地模型) → langchain-ollama】
- ChatOllama - Ollama 聊天模型
- OllamaLLM - Ollama 文本模型
- OllamaEmbeddings - Ollama 嵌入模型
【DeepSeek → langchain-deepseek】
- ChatDeepSeek - DeepSeek 聊天模型
😄 其它LLM 厂商可移步至官方文档查询:主站、集成页面、模型集成、聊天模型、嵌入模型。
💡 Tips :每个LLM厂商都有自己的 专属API Key 、LangChain集成类 和 API端点 ,三者必须配套使用 ❗️ 但我上面 ChatOpenAI 用的 Google Gemini 模型,却能正确使用,没有报错,是因为用的不是 "官方服务器 ",而是 "第三方代理中转" (base_url 设置)。原理如下:
- ChatOpenAI 这个类被设计用来创建符合 OpenAI 官方 API 规范的 HTTP 请求。它会打包一个包含 {"model": "gemini-2.5-flash-lite", "messages": ...} 这样的 JSON 数据包。
- 代理服务器收到这个 OpenAI 格式的请求,内部路由逻辑识别到 "gemini" 应该由 Google 的 API 来处理,于是它开始 "翻译 ",将 OpenAI 格式的 messages 数组,转换成 Gemini API 需要的 contents 格式,将 temperature 等通用参数进行映射,最后使用 Google Gemini API 需要的凭证 (google_api_key) 向真正的 Google AI Platform API 发起一个 Gemini 能听懂的请求。
- Google 的服务器处理这个请求,并生成一个 Gemini 格式的响应,中间代理服务器接收到响应,再次进行 "翻译",将 Gemini 的响应格式转换回 OpenAI 的标准响应格式,例如 {"choices": {"message": {"role": "assistant", "content": "..."}}}。
- 代理服务器将这个标准 OpenAI 格式的响应发回给你的 LangChain 应用,ChatOpenAI 这样格式的响应,成功解析并返回最终结果。
🤔 在企业环境中,这种 "代理层" 是必不可少的,它可以:
- 统一管理 API 密钥: 公司只需要管理少数几个 (如 Google, Anthropic) 主密钥,然后给开发者分发代理服务的密钥。
- 集中式日志和监控: 所有 LLM 的调用都会经过一个地方,便于审计、分析成本和监控性能。
- 实现高级路由和回退 : 代理层可以实现 "智能路由",如:Gemini 挂了,它可以自动将请求转发给 Claude,而前端应用代码无需任何改动。
- 统一缓存: 可以在代理层实现对所有模型调用的缓存,进一步节省成本。
😶 这种 "中转平台 " 还挺多,如 OpenRouter、OneChat 等,有 "免费 " 也有 "付费 " 的,使用时注意保护 "隐私安全 ",充钱的话不建议一次性充太多,平台跑路见太多了,这种基本申诉无门 ❗️ 分享一个能轻松将多种 LLM API 转换为 OpenAI 兼容接口的流行 "开源项目 ":BerriAI/litellm
2.1.2. LLM 核心类-可配置属性
LLM核心类 在 "实例化 " 时可以配置各种属性,这里以最常用的 ChatOpenAI 为例,其它类也是类似,具体可参见对应的文档或源码 (😄 其实,这些参数在《3、AI-概念名词 & LLM-模型微调》已经涉猎过):
①【核心身份参数】
- model :str,必需,模型名称,用于指定要使用的具体模型,如:"gpt-4o",不同模型的性能、价格和上下文窗口大小都不同。
- api_key :str,可选,API 密钥 ,如果不在实例化时提供,LangChain 会自动从名为 OPENAI_API_KEY 的环境变量中读取。
- base_url :str,可选,API 请求的服务器基地址,当你需要使用代理、兼容 OpenAI 的端点(如 LiteLLM)或 Azure OpenAI 服务时,可以设置这个参数。
- organization :str,可选,OpenAI 组织 ID,主要用于区分不同组织下的用量和计费。
② 【生成控制参数】
- temperature:float,可选,范围0,2,温度/控制输出的随机性,值越低 (如 0.1),输出越确定、重复性越高,值越高 (如 1.0),输出越具创造性和多样性。
- max_tokens :int,可选,限制单次调用生成文本的最大长度 (词元数量),一般用于控制API成本和确保输出简洁。
- top_p :float,可选,范围0,1,核心采样,与 temperature 类似,但通过另一种方式控制随机性。它让模型只考虑概率总和达到 top_p 值的那些词汇。一般建议只使用 temperature 或 top_p 中的一个。
- stop :liststr,可选,停止序列,当模型生成其中任何一个字符串时,会立即停止生成,且停止的字符串不会包含在最终输出中。
- presence_penalty :float,可选,范围-2.0, 2.0,存在惩罚,正值会惩罚那些已经出现在文本中的词汇,鼓励模型谈论新主题,降低重复性。
- frequency_penalty :float,可选,范围 -2.0, 2.0,频率惩罚,正值会根据词汇在文本中出现的频率来惩罚它们,进一步降低模型重复相同词语的概率。
- seed :int,可选,随机种子,配合较低的 temperature 使用时,提供此参数可以使模型的输出在多次调用中保持确定性和可复现性,对于测试和调试非常有用。
- response_format :dict,可选,强制模型输出特定格式。如:设置为 {"type": "json_object"} 可以启用 JSON 模式,确保模型输出一个有效的 JSON 对象。
- n :int,可选,默认为 1,生成数量,让模型为每个输入消息生成 n 个不同的备选输出(choices)。
③ 【工具调用参数】
- tools :list,可选,工具列表 ,用于向模型提供它可以调用的外部工具 (如函数、API),是实现 Function Calling 功能的核心。
- tool_choice :str 或 dict,可选,控制工具选择策略 ,可以设置为 none-不使用工具 、auto-模型自行决定,或强制模型调用某个特定工具。
④ 【高级与网络参数】
- streaming :bool,可选,流式输出,默认为 False,如果设为 True,当你使用 .stream() 或 .astream() 方法时,模型会以数据块的形式实时返回结果,而不是等待全部生成完毕。
- timeout :float,可选,请求超时,等待 OpenAI API 响应的最长时间 (单位秒)。
- max_retries :int,可选,默认为 2,最大重试次数,当 API 请求失败 (如网络问题、速率限制) 时,自动重试的最大次数。
- model_kwargs :dict,可选,额外模型参数,用于传递 OpenAI API 支持但 ChatOpenAI 类没有直接暴露的任何其他参数。如:通过这里传递 logit_bias 来调整特定词汇的出现概率。
⑤ 【元数据与回调参数】
- tags :liststr,可选,为此次模型调用附加标签,便于在 LangSmith 等追踪工具中进行筛选和分组。
- metadata :dict,可选,元数据,附加一个包含任意键值对的字典,为调用提供更丰富的上下文信息,同样便于在 LangSmith 中追踪。
- callbacks :list,可选,回调管理器 ,用于在模型调用的不同生命周期阶段 (如开始、结束、出错时) 执行自定义代码,是 LangChain 中实现 自定义逻辑和监控 的重要机制。
简单代码调用示例:
python
from langchain_openai import OpenAI
# ==============================
# 💡 语言模型
# ==============================
llm = OpenAI(
model="gpt-4",
temperature=0.7,
max_tokens=1000,
timeout=30,
max_retries=3
)
# 调用模型
text = "请为我写一篇关于LangChain的简短介绍"
response = llm.invoke(text)
print(response)
# 流式生成
for chunk in llm.stream("请详细介绍机器学习的基本概念"):
print(chunk, end="", flush=True)
# 批量调用
texts = ["介绍Python", "介绍Java", "介绍JavaScript"]
responses = llm.batch(texts)
for response in responses:
print(response)
# ==============================
# 💡 聊天模型
# ==============================
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 初始化聊天模型
chat_model = ChatOpenAI(
model="gpt-4",
temperature=0.7,
max_tokens=1000
)
# 单轮对话
messages = [HumanMessage(content="你好,请介绍一下自己")]
response = chat_model.invoke(messages)
print(response.content)
# 多轮对话
conversation = [
SystemMessage(content="你是一个专业的Python编程助手"),
HumanMessage(content="什么是列表推导式?"),
AIMessage(content="列表推导式是Python中创建列表的简洁方式..."),
HumanMessage(content="能给我一个具体的例子吗?")
]
response = chat_model.invoke(conversation)
print(response.content)
# 支持多模态输入,如:包含图像的消息
from langchain_core.messages import HumanMessage
message = HumanMessage(
content=[
{"type": "text", "text": "这张图片中有什么?"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
]
)
response = chat_model.invoke([message])
print(response.content)💡 顺带介绍下上面涉及到的几个 LangChain 中的 "消息类型":
python
#【SystemMessage-system】系统信息,用于:
# 设置AI的角色和性格、定义回答的风格和规则、
# 提供上下文背景信息、设置安全和伦理约束
system_msg = SystemMessage(content="你是一个专业的Python编程助手,请用简洁明了的方式回答问题")
#【HumanMessage-user】用户消息,用于表示用户的输入
human_msg = HumanMessage(content="什么是列表推导式?")
#【AIMessage-assistant】AI消息,用于表示 AI 的回复
ai_msg = AIMessage(content="列表推导式是Python中创建列表的简洁方式...")
# 带有工具调用的 AI 信息
ai_msg_with_tools = AIMessage(
content="我需要查询天气信息",
tool_calls=[{
"id": "call_123",
"function": {"name": "get_weather", "arguments": '{"city": "北京"}'},
"type": "function"
}]
)
#【ToolMessage-tool】工具消息,表示工具调用的结果
tool_msg = ToolMessage(
content='{"temperature": 22, "condition": "sunny"}',
tool_call_id="call_123"
)
#【ChatMessage】通用聊天信息。可以指定任意角色
custom_msg = ChatMessage(
content="这是一个自定义角色的消息",
role="moderator" # 自定义角色
)
# 共同的属性和方法
msg = HumanMessage(content="Hello")
# 基本属性
print(f"类型: {msg.type}") # 'human'
print(f"内容: {msg.content}") # 'Hello'
print(f"ID: {msg.id}") # 自动生成的唯一ID
# 附加数据
msg_with_metadata = HumanMessage(
content="Hello",
additional_kwargs={"user_id": "123", "timestamp": "2024-01-01"},
name="用户张三"
)
# 序列化和反序列化
msg_dict = msg.dict()
print(msg_dict)
# 从字典创建消息
recreated_msg = HumanMessage(**msg_dict)
#【自定消息类型】
from langchain_core.messages import BaseMessage
from typing import List, Dict, Any
class CustomMessage(BaseMessage):
def __init__(self, content: str, metadata: Dict[str, Any] = None, **kwargs):
super().__init__(content=content, **kwargs)
self.metadata = metadata or {}
@property
def type(self) -> str:
return "custom"
# 使用自定义消息
custom_msg = CustomMessage(
content="这是一个自定义消息",
metadata={"priority": "high", "category": "urgent"}
)
print(f"消息类型: {custom_msg.type}")
print(f"元数据: {custom_msg.metadata}")2.2. 自定义模型类
LangChain 提供了两类核心模型接口:BaseLLM (纯文本生成) 和 BaseChatModel (需处理对话历史),继承实现特定的抽象方法和属性,添加自定义逻辑即可 (如API调用、数据预处理等)。简单代码示例如下:
python
from langchain_core.language_models.llms import BaseLLM
from langchain_core.language_models.chat_models import BaseChatModel
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.outputs import LLMResult, ChatResult, ChatGeneration
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, SystemMessage
from typing import Any, List, Optional
class CustomLLM(BaseLLM):
"""自定义LLM模型类示例"""
# 定义模型参数
api_key: str = ""
base_url: str = ""
model_name: str = "custom-model"
temperature: float = 0.7
@property
def _llm_type(self) -> str:
"""返回模型类型标识"""
return "custom_llm"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
"""核心调用方法"""
# 实现你的自定义API调用逻辑
response = self._call_custom_api(prompt, **kwargs)
return response
def _call_custom_api(self, prompt: str, **kwargs) -> str:
"""具体的API调用实现"""
# 这里可以调用任何你想要的模型API
# 例如:本地模型、其他云服务等
import requests
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
data = {
"prompt": prompt,
"temperature": self.temperature,
"max_tokens": kwargs.get("max_tokens", 100)
}
try:
response = requests.post(
f"{self.base_url}/generate",
headers=headers,
json=data,
timeout=30
)
response.raise_for_status()
result = response.json()
return result.get("text", "")
except Exception as e:
return f"API调用失败: {str(e)}"
@property
def _identifying_params(self) -> dict:
"""返回模型标识参数"""
return {
"model_name": self.model_name,
"temperature": self.temperature,
}
class CustomChatModel(BaseChatModel):
"""自定义ChatModel - 处理对话历史"""
api_key: str = ""
base_url: str = ""
@property
def _llm_type(self) -> str:
return "custom_chat"
def _generate(
self,
messages: List[BaseMessage], # 接受消息列表
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> ChatResult: # 返回结构化结果
"""处理消息历史,返回对话回复"""
print(f"💬 ChatModel收到 {len(messages)} 条消息")
# 解析消息历史
conversation_history = []
for msg in messages:
if isinstance(msg, SystemMessage):
conversation_history.append(f"系统: {msg.content}")
elif isinstance(msg, HumanMessage):
conversation_history.append(f"用户: {msg.content}")
elif isinstance(msg, AIMessage):
conversation_history.append(f"助手: {msg.content}")
print(f"📜 对话历史: {conversation_history}")
# 基于对话历史生成回复
last_user_msg = ""
for msg in reversed(messages):
if isinstance(msg, HumanMessage):
last_user_msg = msg.content
break
response_text = f"[Chat回复] 理解你的问题:'{last_user_msg}'。这是基于对话历史的智能回复。"
# 返回结构化的消息对象
message = AIMessage(content=response_text)
generation = ChatGeneration(message=message)
return ChatResult(generations=[generation])
@property
def _identifying_params(self) -> dict:
return {"model_type": "chat"}
from custom_llm import CustomLLM
from custom_chat_model import CustomChatModel
from langchain_core.prompts import PromptTemplate
def demonstrate_difference():
"""使用自定义模型"""
llm = CustomLLM()
chat_model = CustomChatModel()
print("=== LLM vs ChatModel 对比 ===\n")
# LLM的使用方式
print("🤖 LLM模式:")
llm_result = llm.invoke("解释什么是人工智能")
print(f"输入: 纯文本字符串")
print(f"输出: {llm_result}\n")
# ChatModel的使用方式
print("💬 ChatModel模式:")
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="你是一个AI助手"),
HumanMessage(content="今天天气怎么样"),
AIMessage(content="我需要知道你的位置才能准确告诉你天气"),
HumanMessage(content="我在北京")
]
chat_result = chat_model.invoke(messages)
print(f"输入: {len(messages)} 条消息对象")
print(f"输出: {chat_result.content}\n")
print("🎯 核心区别:")
print("• LLM: 文本 → 文本")
print("• ChatModel: 消息历史 → 结构化回复")
if __name__ == "__main__":
demonstrate_difference()2.3. 嵌入模型
嵌入模型 (Embedding Models) 是 RAG (检索增强生成) 等许多高级应用的基石,它的作用是 将文本转化为一串数字(向量) ,这个向量可以捕捉文本的语义信息。语义相近的文本,其向量在空间中的距离也相近。🤔 "嵌入" 这个概念,之前没提到,这里先展开讲讲。
2.3.1. 嵌入 (Embedding)
😄 对于一台计算机,你可以告诉它:A=1,B=2,它能理解,但你怎么告诉它 "国王 " 这个词是什么意思呢?一个最原始、最笨的方法,可能是给字典里的每个词都分配一个 独一无二的编号 ,如:国王(5494)、女王(7168)、苹果 (45)。😶 虽然现在有了 数字,但这些数字毫无意义,计算机看不出5494和7168间有任何关系,更不知道"国王"和"女王"的关系,对计算机来说,这些数字跟随机分配的门牌号没任何区别。
🤔 想象有一种方法,它能把世界上所有词语、句子和概念,都标注在一张巨大的、多维度的地图上。这张地图不止有东西南北两个方向,而是有成百上千个 "方向" (维度 )。在这张 "意义地图 " 上,意思相近的东西,在空间中的位置也相互靠近。通过一个简单的二维地图来打比方:
- 嵌入模型 阅读了互联网上万亿的句子,学习到 "国王" 经常和 "皇家"、"权利"、"王座"、"男人" 这些词一起出现。基于这些上下文信息,它把 "国王" 放在了地图上的一个坐标点,如 10, 12.
- 接着它拿到 "女王 " 这个词,它发现 "女王" 也经常和 "皇家"、"权力"、"王座" 一起出现,但更多是和 "女人" 关联。于是,它把 "女王" 放在一个离 "国王" 非常近的坐标点,如 10.1, 11.9。
- 然后它拿到 "苹果" 这个词,它学到这个词总是和"水果"、"吃"、"树"、"红色" 一起出现。这些语境和上面完全不同!于是把"苹果"放在一个离"国王"和"女王"十万八千里远的坐标点,如-50,45
💁♂️ 这个代表坐标点的一串数字 (如10, 12),就是 "嵌入向量 " (Embedding Vector),然后地图上点与点间的 "方向 " 和 "距离 " 也蕴含着深层含义 (关系),这就引出AI领域最经典、最著名的例子:
向量("国王") - 向量("男人") + 向量("女人") ≈ 向量("女王")
😳 简单的数学运算,竟然得出了符合逻辑的结果!这意味着,嵌入模型 已经从海量文本中,自主学习并理解了"性别"、"皇权" 这类抽象概念,并把它们编码进了地图的空间几何关系中,它知道了从"男性"到"女性"在地图上是一个固定的 "方向向量"!
早期模型 (如 Word2Vec) 擅长为 单个词语 (词嵌入) 创建地图坐标,现代模型 (如 OpenAIEmbeddings) 则要先进得多,它们可以阅读 一整句话/一整段文字 ,然后为这一 "整段内容 " 生成一个 唯一的坐标/向量 (文本嵌入),这个坐标代表了整段话的核心意思。如:"国王统治着他的土地" 会得到一个坐标,"女王陛下发表了演说" 会得到一个离上面那句话非常近的坐标,"我午饭吃了一个美味的苹果" 则会得到一个离前两句话非常远的坐标。
2.3.2. 语义搜索
嵌入技术目前最核心、最普遍的应用就是 语义搜索 (Semantic Search),就是 "按意思 " 来搜索,而非 "关键词" 匹配,它的工作流程非常简单:
- 知识入库与向量化 :你把你公司所有的文档 (知识库、PDF、网站文章等) 都拿出来,用 嵌入模型 把每一篇/段文档都计算出它在 "意义地图" 上的坐标 (向量)。
- 存储 :把所有这些算好的坐标 (向量),存入一个特殊的数据库 → 向量数据库 (Vector Store)。
- 用户提问:如 "我们公司的产假政策是怎样的?"
- 问题向量化与比较 :系统不会去傻傻地搜索 "产假 "、"政策 " 这两个关键词,而是用同一个 嵌入模型,把用户这句问话也计算出它在地图上的坐标。
- 寻找"近邻" :然后,系统去向量数据库里问:"快帮我找找,数据库里存的那些文档坐标,哪些离我这个问题的坐标最近?"。
- 检索与生成:数据库会返回语义上最接近的几篇文档原文。然后,你把这几篇原文和用户的原始问题一起,喂给一个强大的大语言模型 (如 GPT-4),并对它说:"请参考这几份资料,回答用户下面这个问题。"
2.3.3. 代码示例
LangChain 支持多种嵌入模型,如:
- OpenAI Embeddings:质量高,适用于生产环境
- 本地嵌入模型:如 Sentence Transformers,隐私友好。
- 云服务嵌入:如Azure OpenAI、Cohere等。
- 自定义嵌入:继承BaseEmbeddings实现。
这里只演示下 OpenAI Embeddings 的用法,可用模型名称:
- text-embedding-3-small:高性价比检索/RAG、相似度/去重,维度默认1536。
- text-embedding-3-large:高精度检索、聚类、复杂排序、多语种强鲁棒 (跨语言检索召回稳定),维度默认3072。
- text-embedding-ada-002:旧版兼容过渡,不建议新项目起步。
支持通过 dimensions 参数自定义输出向量的维度,在优化存储和计算效率时非常有用,直接上代码:
python
def demonstrate_openai_embeddings():
"""OpenAI嵌入模型的使用"""
# 初始化OpenAI嵌入模型
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key=openai_api_key,
openai_api_base=openai_base_url,
dimensions=1536, # 维度
)
# 测试文本
texts = [
"人工智能是计算机科学的一个分支",
"机器学习是AI的重要组成部分",
"深度学习使用神经网络进行学习",
"自然语言处理帮助计算机理解人类语言",
]
print("=== OpenAI嵌入模型演示 ===\n")
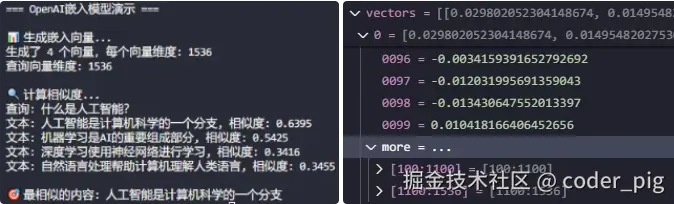
# 1. 批量生成嵌入向量
print("📊 生成嵌入向量...")
vectors = embeddings.embed_documents(texts)
print(f"生成了 {len(vectors)} 个向量,每个向量维度: {len(vectors[0])}")
# 2. 为单个查询生成嵌入
query = "什么是人工智能?"
query_vector = embeddings.embed_query(query)
print(f"查询向量维度: {len(query_vector)}")
# 3. 计算相似度
print("\n🔍 计算相似度...")
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 向量越相似,夹角越小 (余弦相似度越大,1.0-完全相同方向,
最相似、0.0-垂直,不相关、-1.0完全相反方向,最不相似)
similarities = cosine_similarity([query_vector], vectors)[0]
print(f"查询: {query}")
for i, (text, similarity) in enumerate(zip(texts, similarities)):
print(f"文本: {text}, 相似度: {similarity:.4f}")
# 4. 找到最相似的文本
best_match_idx = np.argmax(similarities)
print(f"\n🎯 最相似的内容: {texts[best_match_idx]}")
if __name__ == "__main__":
openai_api_key = os.getenv("OPENAI_API_KEY")
openai_base_url = os.getenv("OPENAI_API_BASE")
demonstrate_openai_embeddings()运行输出结果:
3. Prompts - 提示词模板
实际应用中,我们很少使用完全写死 (静态) 的 Prompt,而是根据用户输入或其它动态数据来生成Prompt。如:为一个电商客服机器人涉及一个查询订单状态的Prompt,其中的订单号是动态变化的。
😄 这时,LangChain的Prompts组件 就派上了用场,它的核心是 Prompt Templates (提示词模板) ------ 一种预先定义好的、可复用的Prompt结构,它包含了 占位符 (变量) ,可在 运行时动态填充信息,主要由两部分构成:
- 模板字符串 :包含自然语言文本和用花括号 {} 标记的占位符。
- 输入变量: 定义了模板中需要填充的变量名称。
使用提示词模板的好处:
- 复用性与效率:一次创建,多次使用,极大地提高了开发效率,避免了代码重复。
- 灵活性与动态性:可以根据不同的场景和输入,动态生成定制化的Prompt。
- 一致性与可维护性:确保了应用中同类任务的Prompt结构一致,便于团队协作和后期维护。
- 代码解耦:将Prompt的逻辑与应用的其他逻辑分离,使代码更加清晰、模块化。
3.1. PromptTemplate - 字符串模板
LangChain 中最基础也是最常用的模板,适用于 "生成单个字符串Prompt" 的场景,使用代码示例:
python
from langchain_core.prompts import PromptTemplate
# ==============================
# 💡 基础用法
# ==============================
# 方式1:使用from_template(推荐)
template1 = PromptTemplate.from_template(
"你是一个{role},请回答关于{topic}的问题:{question}"
)
# 方式2:使用构造函数
template2 = PromptTemplate(
input_variables=["role", "topic", "question"],
template="你是一个{role},请回答关于{topic}的问题:{question}",
)
# 使用模板
formatted_prompt1 = template1.format(
role="Python专家", topic="数据结构", question="什么是字典?"
)
formatted_prompt2 = template2.format(
role="Python专家", topic="数据结构", question="什么是字典?"
)
print(formatted_prompt1)
print(formatted_prompt2)
# ==============================
# 💡 高级用法:部分变量
# ==============================
# 创建模板
template = PromptTemplate.from_template("你是{company}的{role},用户问:{question}")
# 部分填充(预设某些变量)
partial_template = template.partial(company="OpenAI")
# 只需要填充剩余变量
final_prompt = partial_template.format(role="AI研究员", question="GPT是如何工作的?")
print(final_prompt)3.2. ChatPromptTemplate - 对话模板
LangChain 中用于 快速构建结构化消息列表 的模板,使用代码示例:
python
from langchain_core.prompts import ChatPromptTemplate
# 消息类型
#【system】系统消息,设定AI的行为和角色,
#【human】人类用户的消息,
#【ai】AI助手的消息,
#【function】函数调用结果消息,
#【tool】工具调用消息"
# 创建对话模板
chat_template = ChatPromptTemplate.from_messages([
("system", "你是一个专业的{domain}助手。"),
("human", "请解释{concept}是什么?"),
("ai", "我很乐意为你解释{concept}。"),
("human", "{question}")
])
# 格式化消息
messages = chat_template.format_messages(
domain="编程",
concept="函数",
question="能给个具体例子吗?"
)
for message in messages:
print(f"{message.type}: {message.content}")💁♂️ 其中有一个特殊的占位符 "MessagesPlaceholder ",它允许我们在 ChatPromptTemplate 中动态插入一个 "消息列表",使用代码示例:
python
from langchain_core.prompts import MessagesPlaceholder
chat_template = ChatPromptTemplate.from_messages([
("system", "你是一个有趣的编程老师,喜欢用比喻来解释概念。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "什么是{concept}?")
])
messages = chat_template.format_messages(
chat_history=[
("human", "什么是函数?"),
("ai", "函数是一种编程概念,用于将输入转换为输出。")
],
concept="函数"
)
for message in messages:
print(f"{message.type}: {message.content}")3.3. FewShotPromptTemplate - 少样本学习模板
LangChain 中用于 "创建包含少量示例" 的模板,核心参数:
- example_prompt: PromptTemplate,用于格式化单个示例的模板。
- suffix: str,示例后的提示模板字符串。
- example_separator: str = "\n\n",示例分隔符,默认双换行。
- prefix: str = "",示例前的提示模板字符串。
- template_format: Literal"f-string", "jinja2" = "f-string",模板格式
- validate_template: bool = False,是否验证模板。
使用代码示例:
python
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
def basic_usage_demo():
examples = [
{"question": "3+2=?", "answer": "4", "category": "math"},
{"question": "3+3=?", "answer": "6", "category": "math"},
{
"question": "法国的首都是什么?",
"answer": "巴黎",
"category": "geography",
},
{
"question": "日本的首都是什么?",
"answer": "东京",
"category": "geography",
},
{
"question": "如何煮意大利面?",
"answer": "煮水, 加意大利面, 煮10分钟",
"category": "cooking",
},
{
"question": "如何煮咖啡?",
"answer": "磨豆, 用热水煮",
"category": "cooking",
},
]
# 创建示例模板
example_template = PromptTemplate(
input_variables=["question", "answer"],
template="问题: {question}\n答案: {answer}",
)
# 创建FewShot模板
few_shot_template = FewShotPromptTemplate(
examples=examples[:3], # 使用前3个示例
example_prompt=example_template,
prefix="请根据以下示例回答问题:\n",
suffix="问题: {input}\n答案:",
input_variables=["input"],
)
# 生成prompt
prompt = few_shot_template.format(input="5+5=?")
print(f"生成的prompt: {prompt}")3.4. 动态示例选择
😄 让AI根据 问题的相似度 自动选择最相关的示例,代码示例:
python
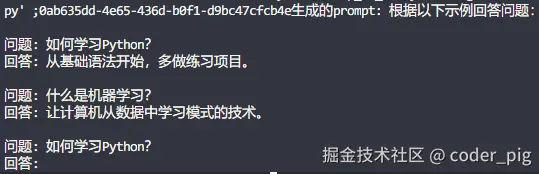
def prompt_dynamic_selector():
# 创建示例数据
examples = [
{"input": "如何学习Python?", "output": "从基础语法开始,多做练习项目。"},
{"input": "什么是机器学习?", "output": "让计算机从数据中学习模式的技术。"},
{"input": "如何优化代码性能?", "output": "使用分析工具找瓶颈,选择合适的算法和数据结构。"},
]
# 创建语义相似度示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(), # 使用嵌入模型来计算语义相似度
InMemoryVectorStore, # 使用内存向量存储来存储示例
k=2 # 选择最相似的2个示例
)
# 创建动态少样本模板
dynamic_template = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=PromptTemplate.from_template(
"问题: {input}\n回答: {output}"
),
prefix="根据以下示例回答问题:",
suffix="问题: {question}\n回答:",
input_variables=["question"]
)
return dynamic_template.format(question="如何学习Python?")运行输出结果:
3.5. 条件化提示词
😄 就是根据 "条件变量" 的切换动态生成不同的提示模板,代码示例:
python
from langchain_core.prompts import PromptTemplate
def create_conditional_prompt(user_level):
"""根据用户水平创建不同的提示"""
if user_level == "beginner":
template = """
你是一个耐心的编程入门导师。请用最简单的语言解释:
问题:{question}
要求:
1. 使用通俗易懂的比喻
2. 避免技术术语
3. 提供简单示例
"""
elif user_level == "intermediate":
template = """
你是一个专业的技术导师。请详细解释:
问题:{question}
要求:
1. 包含技术细节
2. 提供代码示例
3. 说明最佳实践
"""
else: # advanced
template = """
作为技术专家,请从深度技术角度分析:
问题:{question}
要求:
1. 深入原理分析
2. 性能优化建议
3. 架构设计考虑
"""
return PromptTemplate.from_template(template)
# 使用条件化提示
beginner_prompt = create_conditional_prompt("beginner")
expert_prompt = create_conditional_prompt("advanced")3.6. 组合式提示词
😄 就是将 复杂提示词 拆解成多个 "职责单一的独立组件" (角色、情境、任务等),然后通过 "组合函数" 将组件组装成完整的提示词,以实现 "模块化复用" 和 "灵活定制"。代码示例:
python
from langchain_core.prompts import PromptTemplate
# 创建可复用的提示组件
role_template = PromptTemplate.from_template("你是一个{role}。")
context_template = PromptTemplate.from_template("当前情境:{context}")
task_template = PromptTemplate.from_template("请完成以下任务:{task}")
# 组合提示
def combine_prompts(role, context, task):
role_part = role_template.format(role=role)
context_part = context_template.format(context=context)
task_part = task_template.format(task=task)
return f"{role_part}\n\n{context_part}\n\n{task_part}"
# 使用组合式提示
final_prompt = combine_prompts(
role="Python专家",
context="在代码审查会议中",
task="分析这段代码的性能问题"
)4. Tools - 工具函数
🤔 Tools 组件的本质是将 Python函数 与其 元数据 (名称、描述、参数架构) 关联起来的抽象层,它让LLM模型具备了 "动手能力",如:执行具体的操作、获取外部信息,从而不仅仅局限于它自身训练数据中的静态知识。
4.1. @tool 装饰器
被修饰的函数会转换成一个 LangChain Tool,函数签名 (a: int, b: int) 和 类型提示 (-> int) 非常重要,LangChain会利用它们自动推断出工具的 参数模式 (schema) 。函数的 文档字符串 (docstring) 也很重要,它会成为 工具的描述,这个描述是给LLM看的,LLM会根据这个描述来判断在何种情况下应该使用这个工具。一个用于计算两数乘积的简单工具定义示例:
python
import os
from langchain_core.tools import tool
from langchain_openai.chat_models import ChatOpenAI
# ================================
# 💡 ① 定义自定义Tool
# ================================
@tool
def multiply(a: int, b: int) -> int:
"""计算两个整数的乘积。"""
return a * b
if __name__ == "__main__":
print("=" * 50)
# ================================
# 💡 ② 检查自动生成的Tool 属性,可以帮助我们理解它是如何被结构化的
# ================================
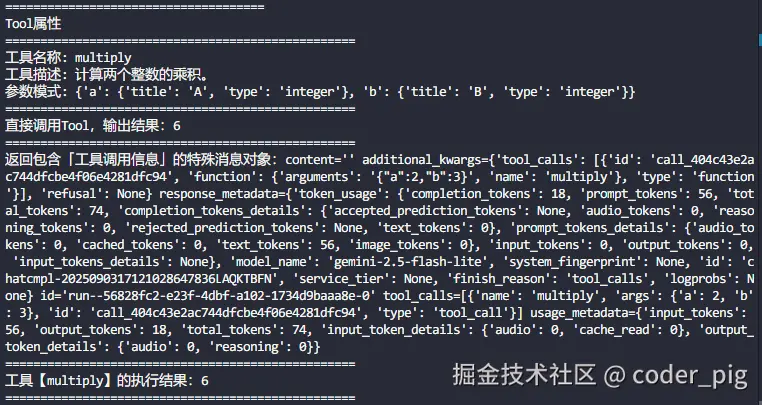
print("Tool属性")
print("=" * 50)
print(f"工具名称: {multiply.name}")
print(f"工具描述: {multiply.description}")
print(f"参数模式: {multiply.args}")
print("=" * 50)
print(f"直接调用Tool,输出结果:{multiply.invoke({'a': 2, 'b': 3})}")
print("=" * 50)
# ================================
# 💡 ③ 让LLM模型决定是否调用工具
# ================================
openai_api_key = os.getenv("OPENAI_API_KEY")
openai_base_url = os.getenv("OPENAI_BASE_URL")
openai_api_model = os.getenv("DEFAULT_LLM_MODEL")
llm = ChatOpenAI(
openai_api_key=openai_api_key,
openai_api_base=openai_base_url,
model=openai_api_model,
)
# ================================
# 💡 ⑤ 将工具列表绑定到LLM模型上,😄 可以指定【tool_choice】参数强制使用某个工具
# ================================
available_tools = [multiply]
llm_with_tool = llm.bind_tools(available_tools)
# ================================
# 💡 ⑥ 让LLM模型决定调用哪个Tool,模型本身不执行工具,它只是"请求"执行,这就是所谓的"工具调用"
# ================================
response = llm_with_tool.invoke('计算2和3的乘积')
print(f"返回包含「工具调用信息」的特殊消息对象:{response}")
print("=" * 50)
# ================================
# 💡 ⑦ 根据工具调用信息,调用工具执行
# ================================
if not response.tool_calls:
print("没有工具调用")
else:
for tool_call in response.tool_calls:
tool_name = tool_call['name']
tool_args = tool_call['args']
# 查找对应的工具
tool = next((t for t in available_tools if t.name == tool_name), None)
if tool:
result = tool.invoke(tool_args)
print(f"工具【{tool_name}】的执行结果:{result}")
print("=" * 50)
else:
print(f"未找到工具【{tool_name}】")
print("=" * 50)运行输出结果:
😄 更优雅的方式是使用 Agent 组件,它可以自动处理多轮对话和复杂的工具调用场景,这个后面会讲~
4.2. StructuredTool
专为 "结构化输入 " 设计,简化了工具创建过程,特别适合处理多参数、复杂输入的场景。通过 类方法 from_function() 快速构建工具,同时支持同步和异步版本,能自动从函数签名推断参数模式,还支持自定义名称、描述、模式。使用代码示例:
python
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
import asyncio
class AreaInput(BaseModel):
length: float = Field(description="长度(米)")
width: float = Field(description="宽度(米)")
def calculate_area(length: float, width: float) -> float:
"""计算矩形面积"""
return length * width
async def async_calculate_area(length: float, width: float) -> float:
"""异步计算矩形面积"""
return length * width
area_tool = StructuredTool.from_function(
func=calculate_area, # 同步版本
coroutine=async_calculate_area, # 异步版本
name="area_calculator", # 工具名称
description="计算矩形面积的专用工具", # 工具描述
args_schema=AreaInput, # 工具参数
return_direct=False, # 是否直接返回结果
handle_tool_error=True, # 启用错误处理
)
async def main():
"""主函数:演示同步和异步工具调用"""
print("=" * 50)
print("同步调用")
print("=" * 50)
print(area_tool.invoke({"length": 5.0, "width": 3.0}))
print("=" * 50)
print("异步调用")
print("=" * 50)
print(await area_tool.ainvoke({"length": 5.0, "width": 3.0}))
if __name__ == "__main__":
asyncio.run(main())4.3. BaseTool
所有工具类的抽象父类,当你需要完全的、底层的控制时,才会选择继承 BaseTool,通常适用于下述高级场景:
- 需要分别定义工具的同步 (_run) 和异步 (_arun) 实现。
- 工具需要管理复杂的状态或连接 (如:数据库连接池)。
- 参数的解析逻辑非常特殊,无法通过 Pydantic 自动推断。
简单代码示例:
python
import asyncio
from typing import Type, Optional
from pydantic import BaseModel, Field
from langchain_core.tools import BaseTool
from langchain_core.callbacks import CallbackManagerForToolRun, AsyncCallbackManagerForToolRun
# 1. 定义参数的Pydantic模型
class DatabaseQuerySchema(BaseModel):
query: str = Field(description="需要执行的SQL查询语句。")
# 2. 继承BaseTool
class DatabaseQueryTool(BaseTool):
name: str = "execute_sql_query"
description: str = "连接到数据库并执行只读的SQL查询。"
args_schema: Type[BaseModel] = DatabaseQuerySchema
def _run(
self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""执行同步查询"""
print("--- 正在执行同步查询 ---")
# 伪代码:db.connect().execute(query)
return f"查询 '{query}' 的结果是:[数据...]"
async def _arun(
self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None
) -> str:
"""执行异步查询"""
print("--- 正在执行异步查询 ---")
await asyncio.sleep(1) # 模拟异步IO操作
# 伪代码:await db.async_connect().execute(query)
return f"异步查询 '{query}' 的结果是:[数据...]"
# 实例化工具
db_tool = DatabaseQueryTool()
print(db_tool.invoke({"query": "SELECT * FROM users;"}))4.4. 内置工具库
LangChain 团队和社区已经为我们预先构建了大量可以直接使用的工具,覆盖了搜索、计算、API交互等最常见的应用场景。使用这些内置工具,可以让我们避免重复造轮子,专注于应用的业务逻辑。梳理下三类常用库:
python
# ================================
# 💡 一、搜索
# ================================
#【DuckDuckGo Search】无需API密钥,开箱即用,非常适合学习和快速原型开发。
# 需安装依赖「duckduckgo-search、ddgs」
from langchain_community.tools import DuckDuckGoSearchRun
search_tool = DuckDuckGoSearchRun()
result = search_tool.invoke("LangChain的最新版本是多少?")
print(result)
#【Google Search】功能强大,搜索结果质量高,但需要设置API密钥。
# 需安装依赖「google-api-python-client」,配置环境变量 GOOGLE_API_KEY 和 GOOGLE_CSE_ID
from langchain_community.tools import GoogleSearchRun
google_search_tool = GoogleSearchRun()
print(google_search_tool.invoke("2024年奥运会在哪里举办?"))
# 【Tavily Search】一个专门为LLM应用优化的搜索引擎,它返回的结果格式更简洁、更适合Agent处理,
# 是目前LangChain官方文档中比较推荐的工具。需安装依赖「tavily-python」,配置环境变量「TAVILY_API_KEY」
from langchain_community.tools.tavily_search import TavilySearchResults
tavily_tool = TavilySearchResults(max_results=3) # 可以指定返回结果数量
print(tavily_tool.invoke("介绍一下谷歌最新的图像模型nano banana"))
# ================================
# 💡 二、计算与代码执行
# 大型语言模型本质上是基于概率的文本生成器,它们并不擅长精确的数学计算和严谨的逻辑执行
# ================================
#【Python REPL Tool】一个极其强大但也需要谨慎使用的工具。它允许LLM生成并执行Python代码。
# ⚠️ 安全警告:绝对不能在不加任何防护的生产环境中直接暴露此工具。请务必在沙箱环境
# (如Docker容器)中运行,以隔离其文件系统和网络访问权限。
from langchain_experimental.tools import PythonREPLTool
python_repl_tool = PythonREPLTool()
# LLM可以生成并执行代码
code = "print(len('Hello World')**2)"
print(python_repl_tool.invoke(code))
#【Wolfram Alpha】一个强大的计算知识引擎,擅长自然科学、数学、符号计算等。
# 需安装依赖「wolframalpha」和设置环境变量「WOLFRAM_ALPHA_APP_ID」
from langchain_community.utilities.wolfram_alpha import WolframAlphaAPIWrapper
wolfram_wrapper = WolframAlphaAPIWrapper()
wolfram_tool = Tool(
name="wolfram_alpha",
func=wolfram_wrapper.run,
description="当你需要回答关于数学、科学、技术、文化、社会和日常生活的问题时很有用。"
)
print(wolfram_tool.invoke("derivative of x^4 sin(x)"))
# ================================
# 💡 三、与外部系统交互工具 (如数据库、内部API、SaaS服务等)
# ================================
#【SQL Database Toolkit】提供了一整套与SQL数据库交互的工具,包括查询数据、查看表结构等的工具包
# 需安装依赖「langchain-community、sqlalchemy」
from langchain_community.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseToolkit
# 连接到数据库 (这里用SQLite做示例)
db = SQLDatabase.from_uri("sqlite:///mydatabase.db")
toolkit = SQLDatabaseToolkit(db=db, llm=ChatOpenAI())
# 工具包里包含多个工具
sql_tools = toolkit.get_tools()
# 例如: sql_tools[0].name -> 'sql_db_query'
# 例如: sql_tools[1].name -> 'sql_db_schema'
# Agent可以利用这些工具先查看有哪些表 (sql_db_list_tables),再看表的结构 (sql_db_schema),
# 最后构造并执行查询 (sql_db_query)。
#【Requests Tools】用于发出HTTP请求,让LLM可以与任何RESTful API进行交互。
# 需安装依赖「requests」
from langchain_community.tools.requests.tool import RequestsGetTool
from langchain_community.utilities.requests import TextRequestsWrapper
# 创建网络请求工具
requests_tool = RequestsGetTool(
requests_wrapper=TextRequestsWrapper(),
allow_dangerous_requests=True # 允许危险请求(仅用于学习和测试)
)
response = requests_tool.invoke("https://httpbin.org/json")
print(response)5. Chains - 链式调用
🤔 Chains (链) 是 LangChain 框架中用于 "将多个组件串联起来 " 的核心概念,就像一条 "流水线",将不同的处理步骤连接在一起,如:提示模板 → LLM → 输出解析器。每个环节都有特定的功能,数据在链中依次流转,还可以嵌套其他链,形成更复杂的处理逻辑。
5.1. 传统Chains类型
💡 在新版本中,传统Chains 已经被 LCEL (LangChain Expression Language) 所替代,大部分在 LangChain 0.1.17 版本后被标记为废弃,0.3.0 版本中已移除,笔者用的 0.3.32 版本,使用直接报错,所以这里只对 传统Chains 做下简单介绍,主要还是以 LCEL 为主。
- LLMChain:最基础的 Chain,用于连接 PromptTemplate 和 LLM,按模板格式化输入并调用模型,适用于简单的文本生成任务。
- SimpleSequentialChain :顺序执行链,当任务需要多个步骤,且上一步的输出是下一步的输入时使用。
- RouterChain :智能路由链,支持条件分支逻辑,根据输入内容选择不同的处理路径,适用于多场景应用,如:客服机器人的意图识别。
- StuffDocumentsChain :文档填充链,将所有文档内容直接填入提示模板,简单直接,但受token限制,不适合长文档。
- MapReduceDocumentsChain :映射归约链,先对每个文档单独处理,再汇总结果,可处理大量文档,支持并行,但可能丢失文档间的关联信息。
- RefineDocumentsChain :迭代优化链,逐步处理文档,不断优化结果,优点是保持上下文连贯性,缺点是处理时间较长。
- ConversationalRetrievalChain :对话检索链,结合对话历史和知识检索,适用于需要支持多轮对话上下文的场景,如:智能问答系统。
- RetrievalQA:检索问答链,基于文档检索回答问题,结合向量搜索和语言模型,适用于知识库问答的场景。
🤔 传统Chains 对于初学者来说,面向对象的方式很直观,能明确知道在创建一个什么类型的链,每个链对象都封装了特定的逻辑,开箱即用。但缺乏 "灵活性 ",如果想创建一个官方没有提供的、自定义的逻辑流,就需要继承基类并编写 大量模板代码 ,非常繁琐。而且 "功能受限 ",对 流式(Streaming) 、异步(Async) 和 批量 (Batch) 操作的支持不是原生的,需额外的配置。
5.2. LCEL
LCEL 是 LangChain 的一种 "声明式编程范式 ",用于构建和组合可运行的链 (Chains),不是一个具体的 "类 ",而是一套使用 Python运算符 (主要是 管道符| ) 来组合组件的 "语法 "。其核心是 "Runnable 接口",它定义了一个标准的接口,使得组件能够:
- 调用 (invoke): 单个输入转换为输出。
- 批处理 (batch): 多个输入高效转换为输出。
- 流式处理 (stream): 输出在生成时进行流式传输。
- 检查 (inspect): 访问 Runnable 的输入、输出和配置的模式信息。
- 组合 (compose): 多个 Runnables 可以使用 LCEL 组合成复杂管道。
管道操作符 | ,通过 "运算符重载" 实现了链式组合:
python
# 管道操作符写法:
chain = prompt | model | output_parser
# 等同于「显式创建」
chain = RunnableSequence([prompt, model, output_parser])LCEL的优势:
- 优化的并行执行:使用 RunnableParallel 或 Runnable Batch API 并行运行多个 Runnables,显著减少延迟。
- 保证的异步支持:任何用 LCEL 构建的链都可以使用 Runnable Async API 异步运行,适用于需要处理大量并发请求的服务器环境。
- 简化流式处理:LCEL 链可以进行流式处理,允许在链执行时增量输出,优化流式输出以最小化首个令牌时间。
- 无缝的 LangSmith 追踪:所有步骤自动记录到 LangSmith,提供最大的可观测性和可调试性。
- 标准 API 和部署能力:所有链都使用 Runnable 接口构建,可以用 LangServe 部署到生产环境。
😄 接着介绍下它的几个核心组件~
5.2.1. RunnableSequence - 序列组合
允许你按顺序链接多个 runnables,一个 runnable 的输出作为下一个的输入。简单代码示例:
python
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 创建组件
prompt = ChatPromptTemplate.from_template("请解释{concept}的概念")
model = ChatOpenAI(
api_key=openai_api_key,
base_url=openai_base_url,
model=openai_api_model,
temperature=1,
)
parser = StrOutputParser() # 将LLM输出(通常是AIMessage对象)转换为纯字符串
# 组合成序列
chain = prompt | model | parser
# 等价于:chain = RunnableSequence([prompt, model, parser])
result = chain.invoke({"concept": "LECL"})
print(result)5.2.2. RunnableParallel - 并行组合
允许同时执行多个处理分支,每个分支可以独立处理输入数据,最后将所有结果合并返回。简单代码示例:
python
from langchain_core.runnables import RunnableParallel, RunnableLambda
# 创建并行处理链
# 文本分析器,同时对输入文本进行多种数据分析
analyzer = RunnableParallel({
"summary": RunnableLambda(lambda x: f"总结:{x[:50]}..."),
"length": RunnableLambda(lambda x: f"长度:{len(x)}字符"),
"word_count": RunnableLambda(lambda x: f"词数:{len(x.split())}个"),
"uppercase": RunnableLambda(lambda x: x.upper())
})
# 执行并行处理
text = "人工智能正在改变我们的生活方式"
result = analyzer.invoke(text)
# 输出结果
print(result)
# {
# "summary": "总结:人工智能正在改变我们的生活方式...",
# "length": "长度:16字符",
# "word_count": "词数:1个",
# "uppercase": "人工智能正在改变我们的生活方式"
# }
# RAG 应用中的多路检索
retrieval_chain = RunnableParallel({
"vector_results": vector_store.as_retriever(),
"keyword_results": keyword_search,
"semantic_results": semantic_search
})
# 多模型集成
multi_model_chain = RunnableParallel({
"gpt_response": gpt_chain,
"claude_response": claude_chain,
"gemini_response": gemini_chain
})5.2.3. RunnablePassthrough - 数据透传
一个特殊的组件,它接收输入数据后不做任何处理,直接将数据透传到下一个组件。简单代码示例:
python
# 💡 ① 保留原始数据
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
# 在并行处理中保留原始输入
processing_chain = RunnableParallel(
{
"original": RunnablePassthrough(),
"processed": RunnableLambda(lambda x: x.upper()),
}
)
result = processing_chain.invoke("hello world")
print(result)
# 输出:{"original": "hello world", "processed": "HELLO WORLD"}
# 💡 ② RAG 应用中的上下文传递
from langchain_core.runnables import RunnablePassthrough
# 在 RAG 链中传递上下文
rag_chain = RunnableParallel({
"context": retriever,
"question": RunnablePassthrough()
}) | prompt | model | parser
# 💡 ③ 数据预处理和后处理
# 数据预处理 + 透传 + 后处理
data_pipeline = (
RunnableLambda(lambda x: preprocess(x)) # 预处理
| RunnablePassthrough() # 透传处理后的数据
| RunnableLambda(lambda x: postprocess(x)) # 后处理
)5.2.4. RunnableLambda - 函数包装器
将普通 Python 函数转换为 Runnable 对象的包装器,让任何函数都能集成到 LCEL 链中。简单代码示例:
python
# 💡 ① 简单数据转换
double = RunnableLambda(lambda x: x * 2)
result = double.invoke(5) # 输出:10
# 字符串处理
uppercase = RunnableLambda(lambda x: x.upper())
result = uppercase.invoke("hello") # 输出:"HELLO"
# 💡 ② 复杂数据处理
def analyze_text(text: str) -> dict:
"""分析文本的复杂函数"""
return {
"original": text,
"length": len(text),
"words": len(text.split()),
"uppercase": text.upper(),
"reversed": text[::-1]
}
# 包装为 Runnable
text_analyzer = RunnableLambda(analyze_text)
# 使用
result = text_analyzer.invoke("Hello World")
print(result)
# {
# "original": "Hello World",
# "length": 11,
# "words": 2,
# "uppercase": "HELLO WORLD",
# "reversed": "dlroW olleH"
# }
# 💡 ③ 在链中的使用
processing_chain = (
RunnableLambda(lambda x: f"输入:{x}")
| RunnableLambda(lambda x: x.upper())
| RunnableLambda(lambda x: f"结果:{x}")
)
result = processing_chain.invoke("test")
print(result) # 输出:"结果:输入:TEST"5.2.5. 异步支持
python
import asyncio
from langchain_core.runnables import RunnableLambda
async def async_process(text: str) -> str:
"""异步处理函数"""
await asyncio.sleep(0.1) # 模拟异步操作
return f"处理完成:{text.upper()}"
# 创建异步 Runnable
async_processor = RunnableLambda(async_process)
# 异步调用
result = await async_processor.ainvoke("hello world")
print(result) # 输出:"处理完成:HELLO WORLD"5.2.6. 高级组合模式
python
#================================
# 💡 嵌套组合,并行+序列组合
#================================
complex_chain = RunnableParallel({
"analysis": RunnableParallel({
"sentiment": sentiment_analyzer,
"keywords": keyword_extractor,
"summary": text_summarizer
}),
"metadata": RunnableParallel({
"timestamp": RunnableLambda(lambda x: datetime.now()),
"source": RunnableLambda(lambda x: "api"),
"version": RunnableLambda(lambda x: "1.0")
}),
"original": RunnablePassthrough()
})
#================================
# 💡 基于条件的分支处理
#================================
from langchain_core.runnables import RunnableBranch
branch_chain = RunnableBranch(
(lambda x: len(x) < 10, short_text_processor),
(lambda x: len(x) < 100, medium_text_processor),
long_text_processor # 默认分支
)
#================================
# 💡 配置管理,配置化链
#================================
from langchain_core.runnables import RunnableConfig
configurable_chain = chain.with_config(
RunnableConfig(
max_concurrency=5,
max_retries=3,
timeout=30.0
)
)
#================================
# 💡 错误处理
#================================
from langchain_core.runnables import RunnableWithFallbacks
# 带回退的链
robust_chain = RunnableWithFallbacks(
primary=primary_chain,
fallbacks=[backup_chain1, backup_chain2]
)
# 带重试的执行
result = await robust_chain.ainvoke(input, config={"max_retries": 3})5.2.7. 完整应用示例-简单文档分析器
AI推理 与 简单计算 分开处理,三个AI任务同时进行,而非串行等待,单个链失败不影响其他链的执行,使用RunnablePassthrough()避免重复数据拷贝,原始文档引用传递,节省内存,具体代码实现:
python
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
from typing import Dict, Any
openai_api_key = os.getenv("OPENAI_API_KEY")
openai_base_url = os.getenv("OPENAI_BASE_URL")
openai_api_model = os.getenv("DEFAULT_LLM_MODEL")
class DocumentAnalyzer:
"""文档分析器"""
def __init__(self):
self.llm = ChatOpenAI(
api_key=openai_api_key,
base_url=openai_base_url,
model=openai_api_model,
temperature=0.1,
)
# 摘要生成链
summary_prompt = ChatPromptTemplate.from_template(
"请为以下文档生成一个简洁的摘要:\n\n{document}"
)
self.summary_chain = summary_prompt | self.llm | StrOutputParser()
# 关键词提取链
keywords_prompt = ChatPromptTemplate.from_template(
"从以下文档中提取5-8个关键词:\n\n{document}"
)
self.keywords_chain = keywords_prompt | self.llm | StrOutputParser()
# 情感分析链
sentiment_prompt = ChatPromptTemplate.from_template(
"分析以下文档的情感倾向(积极/消极/中性):\n\n{document}"
)
self.sentiment_chain = sentiment_prompt | self.llm | StrOutputParser()
def create_analysis_chain(self):
"""创建完整的分析链"""
# 并行分析链
analysis_chain = RunnableParallel({
"summary": self.summary_chain,
"keywords": self.keywords_chain,
"sentiment": self.sentiment_chain,
"metadata": RunnableParallel({
"word_count": RunnableLambda(lambda x: len(x["document"].split())),
"char_count": RunnableLambda(lambda x: len(x["document"])),
"language": RunnableLambda(lambda x: "中文" if any("\u4e00" <= c <= "\u9fff" for c in x["document"]) else "英文")
}),
"original": RunnablePassthrough() # 原始输入
})
return analysis_chain
def analyze(self, document: str) -> Dict[str, Any]:
"""分析文档"""
analysis_chain = self.create_analysis_chain()
input_data = {"document": document}
result = analysis_chain.invoke(input_data)
return result
def main():
"""主函数演示"""
# 创建分析器
analyzer = DocumentAnalyzer()
# 测试文档
test_document = """
人工智能技术正在快速发展。在过去的几年中,我们看到了机器学习和深度学习技术的重大突破。
从图像识别到自然语言处理,AI正在改变各个行业的工作方式。
然而,随着AI技术的普及,也带来了许多挑战和伦理问题。我们需要在技术创新的同时,
确保AI的发展符合人类的价值观和利益。
展望未来,AI将继续在医疗、教育、交通等多个领域发挥重要作用。
"""
print("🔍 正在分析文档...")
result = analyzer.analyze(test_document)
print("\n📊 分析结果:")
print("=" * 50)
print("📝 摘要:")
print(result["summary"])
print()
print("🏷️ 关键词:")
print(result["keywords"])
print()
print("😊 情感分析:")
print(result["sentiment"])
print()
print("📊 元数据:")
for key, value in result["metadata"].items():
print(f" {key}: {value}")
print()
print("✅ 文档分析完成!")
if __name__ == "__main__":
main()运行输出结果:
bash
🔍 正在分析文档...
📊 分析结果:
==================================================
📝 摘要:
人工智能技术发展迅速,在机器学习和深度学习方面取得突破,正在改变各行各业。然而,AI的普及也带来了挑战和伦理
问题,需要确保其发展符合人类价值观。未来,AI将在医疗、教育、交通等领域发挥重要作用。
🏷️ 关键词:
以下是从文档中提取的5-8个关键词:
1. **人工智能 (AI)**
2. **机器学习**
3. **深度学习**
4. **技术发展**
5. **行业应用**
6. **挑战与伦理**
7. **未来展望**
8. **价值观与利益**
😊 情感分析:
文档的情感倾向分析如下:
* **整体情感倾向:中性偏积极**
**分析过程:**
1. **积极方面:**
* "人工智能技术正在快速发展。" - 描述了技术进步,通常是积极的。
* "我们看到了机器学习和深度学习技术的重大突破。" - 强调了积极的进展和成就。
* "AI正在改变各个行业的工作方式。" - 暗示了效率提升和创新,是积极的影响。
* "展望未来,AI将继续在医疗、教育、交通等多个领域发挥重要作用。" - 描绘了AI在未来社会中的积极应用前景
。
2. **消极方面(或挑战):**
* "然而,随着AI技术的普及,也带来了许多挑战和伦理问题。" - 明确指出了潜在的负面影响和需要解决的问题。
* "我们需要在技术创新的同时,确保AI的发展符合人类的价值观和利益。" - 这是一个警示性的陈述,强调了风险
和责任。
3. **中性方面:**
* 文档整体上是在陈述事实、描述现状和展望未来,并没有强烈的个人情感表达。
**结论:**
文档在描述AI的快速发展和未来潜力时,带有明显的积极色彩。但同时,它也客观地指出了AI发展带来的挑战和伦理问题
,并强调了负责任发展的必要性。因此,虽然存在对挑战的提及,但整体基调更偏向于对AI技术进步的肯定和对其未来积
极作用的展望。
所以,最准确的描述是**中性偏积极**。
📊 元数据:
word_count: 5
char_count: 194
language: 中文
✅ 文档分析完成!