写在前面
正如标题所讲,这里只是浅谈三者的关系,并不会很深入的去讲底层的源码之类的东西,大家可以有批判的去看
开始吧
一、偏虚拟DOM部分
首先是虚拟DOM树,为什么React要有虚拟DOM树,什么是虚拟DOM树。JS虽然是用来操作DOM的脚本,但是操作DOM的成本还是很大的,那么有没有一种成本低一点的DOM树操作?有的兄弟,我们可以用JS去模拟虚拟DOM树,哎,既然不操作真实的DOM树,页面也不会变,这不是自己骗自己吗兄弟?实则不然。现在就先理解成是自己骗自己吧。
让我们聚焦到虚拟DOM的模拟,JS如何模拟虚拟DOM,很简单一个对象代表一个节点就可以了,对象模拟节点其实很简单,简单来说只需要三个属性,现在是三个节点,三个,考虑的是最简单的情况,如下
三个属性就可以,我们拿一个最简单的DOM树来看
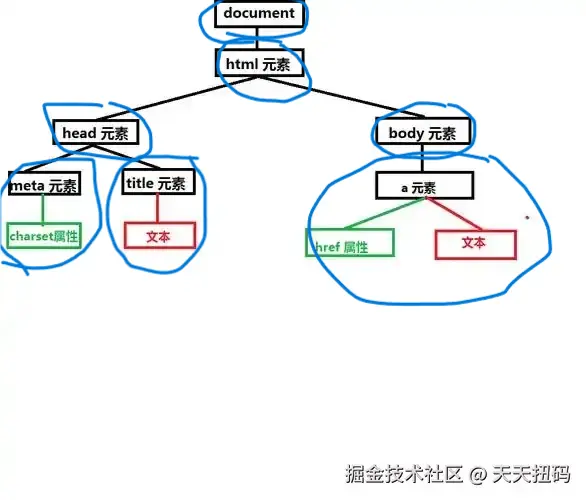
可以看一下这个DOM树,这里一个蓝色的圈是一个节点,彩色是附着在黑色上的哈
那么一个节点在HTML中是什么表现形式呢?
xml
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8"> <!-- meta元素,设置charset属性 -->
<title>这里是标题文本</title> <!-- title元素,包含文本 -->
</head>
<body>
<a href="#">这里是链接文本</a> <!-- a元素,包含href属性和文本 -->
</body>
</html>那么现在我们要模拟一个节点,我们要考虑什么,现在就最简单的考虑。
首先要有节点的类型------head、meta、title、body、a
其次要有节点中的属性------比如charset、href
最后我们要有子节点------比如meta、title是head的子节点;a是body的子节点等。
OK!三个属性齐活了,下面的Element就是我们的模拟,对,很漂亮的模拟。很多的节点对象就组成了一个虚拟DOM树。
typescript
// element.js
// 虚拟DOM元素的类,构建实例对象,用来描述DOM
class Element {
constructor(type, props, children) {
this.type = type;
this.props = props;
this.children = children;
}
}
// 创建虚拟DOM,返回虚拟节点(object)
function createElement(type, props, children) {
return new Element(type, props, children);
}
export {
Element,
createElement
}经过上述的讲解,我们大概了解了虚拟dom树的结构,那么接下来我们来考虑虚拟DOM树为何高效,以及虚拟DOM树是否是"自己骗自己"
虚拟DOM为何高效?
这个是对比来讲的,我们可以来看一下为什么js操作真实DOM昂贵之处就理解了------
-
布局: 当你修改了 DOM 元素的几何属性(如宽度、高度、位置、边距、边框等)时,浏览器需要重新计算所有受影响元素的几何位置和尺寸,这个过程叫做"布局"或"重排"。
想象一下,你在一个大文档中移动了一个小方块。对于这个方块,浏览器需要算它的新位置。但如果这个方块周围的元素也受其影响(比如,如果它旁边的文本会因为方块移动而换行),那么浏览器需要重新计算这些周围元素的布局。更糟糕的是,如果这个方块的位置依赖于它父元素的大小,而父元素的大小又依赖于它的父元素...... 这种情况会形成一个连锁反应,可能需要浏览器重新计算整个页面或部分页面的布局。
-
绘制: 当像素颜色、背景、边框颜色等外观属性发生变化时,浏览器需要重新绘制受影响的区域,这个过程叫做"绘制"。
改变一个元素的背景颜色,或者改变一个元素的文本颜色。浏览器只需要重新渲染这些受影响的像素。
为什么 JavaScript 直接操作会频繁触发这些操作?
考虑以下 JavaScript 代码:
ini
const div = document.getElementById('myDiv');
// 第一次修改:宽度
div.style.width = '200px'; // 触发一次 Layout
// 第二次修改:高度
div.style.height = '300px'; // 再次触发一次 Layout
// 第三次修改:背景颜色
div.style.backgroundColor = 'blue'; // 触发一次 Repaint
// 第四次修改:文本颜色
div.style.color = 'white'; // 再次触发一次 Repaint在这个简化的例子中,每一次对 div.style 的直接修改(尤其是修改几何属性)都可能立即触发一次浏览器对 DOM 的计算和更新(Reflow 或 Repaint)。如果在一个循环中进行多次 DOM 操作,浏览器就会非常忙碌,不断地 recalculate -> repaint -> recalculate -> repaint,导致明显的性能瓶颈。
那么,虚拟DOM是如何提升效率的?可以分为三个步骤
-
生成新的DOM树
- 当 React 组件的状态或 props 发生变化时,React 不会立刻去操作真实 DOM。
- 而是使用新的 state/props 去重新执行组件的
render方法,生成一个新的虚拟 DOM 树。
-
Diff 算法的"批量更新":
- React 将这个新的虚拟 DOM 树与上一次渲染生成的旧虚拟 DOM 树进行比较。
- 这个比较过程(Diff 算法)非常高效,是 O(n) 的时间复杂度,因为它遵循上述的启发式规则。Diff 算法会找出两棵虚拟 DOM 树之间"真正"的差异:哪些节点被修改了
props,哪些节点被删除,哪些节点是新增的,哪些节点被移动了。 - React 会生成一个包含所有这些差异的"变更列表"(patch list)。
-
一次性更新真实 DOM:
- 最后,React 会将这个"变更列表"一次性地应用到真实 DOM 上。
- 因为 React 已经知道需要进行哪些更改,它可以将这些更改进行批量处理。比如,如果多个元素的位置发生了变化,React 可以一次性地计算出所有受影响元素的最终布局,而不是每次都单独计算。如果多个元素的背景色发生了变化,React 也可以批量地进行重绘。
- 这种"批量更新(Batch Update)"策略极大地减少了浏览器执行昂贵的 Reflow 和 Repaint 的次数。
现在让我们回想第一个问题------虚拟DOM为何高效?
1.批量更新的策略把最耗性能的操作(重绘重排)减少了几倍不止,这在很多情况下就意味着性能提升了几倍,这是巨大的提升。
2.diff算法找出了虚拟DOM和真实DOM的变化差异的最小"变更列表",没有虚拟 DOM 时,也可能只更新变化部分,但效率和控制程度不如使用虚拟 DOM 和 Diff 算法
那么第二个问题------虚拟DOM是"自己骗自己吗"?
如果虚拟DOM树只有前两步可能是的(生成新的DOM树、Diff 算法的"批量更新),因为它们并不影响真实的dom渲染,但是如果加上了最后一步(一次性更新真实 DOM),意义就变了,这就直接摆脱了"自己骗自己"的嫌疑,还被送上了"大幅提升性能"的锦旗。
虚拟DOM难道在进行完性能的优化之后就燃尽了吗?不会的,其实虚拟DOM还有其他的一些好处,我们拿一个来讲------跨平台性
通过前面的讲解,我们知道虚拟dom在不更改真实DOM前是和浏览器的DOM分离的,这就意味着虚拟DOM不止可以"映射"到浏览器DOM,可以使用 Virtual DOM 框架(如 React, Vue)来构建在多种平台运行的 UI,而无需重写核心逻辑。
但是总的来讲,虚拟DOM最大的优势还是性能上的优化。这里简单解决一下大家可能有的一个疑问------虚拟DOM可以批量更新,那么是如何判断哪些"是一批"呢?
简单来说,React 认为"一批"更新是指:
在同一个 JavaScript 事件循环周期内,或者在 React 自身的调度过程中,所有触发的状态更新被累积起来,并在一个合适的时机(通常是 React 准备进行 DOM 更新之前)进行合并和处理,最终生成一次对真实 DOM 的批量操作。
简单的总结:
React v17 及之前(非并发模式):
- 事件处理器内的
setState属于一批(同步批量)。
kotlin
handleClick = () => {
// 这几次 setState 发生在同一个事件处理函数内,
// 它们会被 React 收集并合并处理。
this.setState({ count: this.state.count + 1 });
this.setState({ count: this.state.count + 1 }); // 第二个会覆盖第一个,最终 count + 2
this.setState({ text: 'Clicked!' }); // 新的状态
};- 其他地方(setTimeout, Promise, 生命周期等)的
setState属于另一批(异步批量)。
javascript
componentDidMount() {
// 这是一个异步操作
setTimeout(() => {
this.setState({ visible: true });
}, 100);
// 另一个在 componentDidMount 中调用的 setState,
// 尽管时间上不一致,但它们同属于 componentDidMount 的执行上下文,
// 并且 React 会将它们放入一个大的异步更新队列里。
this.setState({ data: fetchedData });
}- React 会等待当前的同步任务(如事件处理器)执行完毕,然后处理所有累积的异步更新。
React v18 及以后(默认并发模式):
- 所有
setState默认都被视为"可以被延迟"的更新。 - React 的调度器会根据任务的紧急程度(通过
startTransition等 API 控制)将更新分组。 - "一批"是指,能够被 React 在一个渲染阶段(或者一系列连续的微任务/宏任务)中一次性处理和应用到 DOM 的更新集合。
核心是:React 不会对每一次 setState 都进行一次完整的 DOM diff 和更新。它会尽可能地将多个状态更新的意图收集起来,进行合并和计算,最终通过一次或几次高效的 DOM 操作来完成 UI 的更新。
setState大家可以简单的理解为组件状态更新
所以简单来说,很大可能下的批量更新是这样进行的
1.执行调用栈中的同步代码 (如果有)。
2.检查并执行宏任务队列,每次只取出一个任务执行。
3.检查并清空微任务队列 (在每个宏任务执行后立即清空)。
4.批量更新渲染 (对于浏览器环境,例如,进行 DOM 更新)。
二、偏虚拟diff算法部分
OK,那么现在回归正题,我们在前面的讲解中可以发现在虚拟DOM批量更新的过程中有一个叫做diff算法的东西,我们可以来回顾一下diff算法的作用

我们可以得知diff算法发挥作用的阶段是比较新旧虚拟DOM树的阶段,会生成一个"变更列表",根据这个更新列表才可以一次性更新虚拟DOM树。
我们知道,虚拟DOM树是庞大的,树与树的比较更是性能低下,而且直接js操作dom并不涉及到虚拟DOM树的比较,所以这个比较是一项额外的开销,如何把这个开销给压低到最小是很有意义的,这时候就要搬出diff算法了,那么diff算法到底是如何做到的高效比较呢?
React 的 Diff 算法是基于 "最优化的、启发式的" 策略。它的核心目标是在 O(n) 的时间复杂度内找到两个树形结构之间的最小差异,其中 n 是节点数。为了达到这个目标,它做了一些合理的假设和简化:
-
跨组件类型的比较: 如果根节点是不同的组件类型,React 会认为旧的组件树已经完全没有价值,直接销毁旧组件树,然后创建全新的组件树。例如,
<div>变成<span>,或者MyComponentA变成MyComponentB。为什么? 因为跨组件类型的差异通常很大,而且维护它们的关联性(比如生命周期、state 迁移)会非常复杂和低效。
-
同一组件类型的比较: 如果两个组件是同一类型,React 会保留现有的 DOM 节点,并继续比较它们的子节点。
如果子节点是不同类型: 同样遵循规则 1,直接替换。
如果子节点是同一类型:
-
同一种 DOM 标签: React 会比较它们的属性。如果属性不同,则只更新修改的属性。然后,递归地对子节点进行 Diff。
-
列表(数组)的子节点: 这是 Diff 算法中最复杂和关键的部分。如果一个节点有一个子列表,React 需要一种方式来高效地标识列表中的每个元素。
问题: 如果列表顺序发生变化,或者有元素被插入、删除,如何快速找到对应的元素?
解决方案:
key属性! React 要求为列表中的每个元素提供一个 唯一且稳定的key属性。key的作用:key就像是列表中每个元素的身份 ID。当 Diff 算法比较列表时,它会根据key来匹配新旧节点。查找相同
key的节点: 如果新旧列表中都有同一个key的节点,React 认为它们是同一个元素,然后比较它们的属性和子节点。
查找新增加的key: 如果新列表中有key,但在旧列表中不存在,则认为是一个新节点,进行插入。
查找被删除的key: 如果旧列表中有key,但在新列表中不存在,则被认为是旧节点,进行删除。为什么
key必须稳定? 如果key每次渲染都变化,Diff 算法就无法有效地识别出哪些元素是"同一个",反而会认为所有元素都发生了变化,导致不必要的 DOM 重建,性能更差。不推荐使用
index作为key: 如果列表顺序会改变(插入、删除、移动),使用index作为key会导致 Diff 算法误判,带来性能问题。只有在列表是静态的、不会改变顺序,并且没有被插入/删除元素时,index才勉强可以接受(但仍不推荐)。
-
Diff 算法的步骤概览 (针对比较两个节点 oldNode 和 newNode):
-
如果
newNode为null或undefined:- 返回"删除节点"的操作。
-
如果
oldNode为null或undefined:- 返回"创建节点"的操作。
-
如果
oldNode和newNode不是同一个 DOM 元素(标签、组件类型不同):- 返回"替换节点"(即删除
oldNode,创建newNode)的操作。
- 返回"替换节点"(即删除
-
如果
oldNode和newNode是同一个 DOM 元素(标签相同):-
比较属性: 找出新旧属性的差异,生成"更新属性"的操作。
-
比较子节点:
-
如果子节点数量不同:
- 根据
key,找出需要新增、删除、移动的子节点,生成相应的操作。
- 根据
-
如果子节点数量相同:
- 递归地对每一对相同
key的子节点调用 Diff 算法。
- 递归地对每一对相同
-
-
Diff 算法的实现细节思考:
- 虚拟 DOM 的层级遍历: Diff 算法是在虚拟 DOM 树上进行的,它会从根节点开始,自顶向下地进行比较。
- JavaScript 对象模拟 DOM: 虚拟 DOM 本质上就是用 JavaScript 对象来描述 DOM 结构,这使得在内存中进行高效的比较成为可能。
- Patch: Diff 算法的最终产物不是直接修改 DOM,而是一个包含所有实际 DOM 操作的 "补丁"(Patch) 对象。这个 Patch 对象会被传递给 DOM 更新模块,由它来批量地、高效地将这些操作应用到真实 DOM 上。
Diff 算法的核心就是通过智能的比较策略 (如基于组件类型、DOM 标签、属性以及最重要的 key 属性)来找出两棵虚拟 DOM 树的差异,并生成一系列精确的 DOM 操作指令,最终实现高效的 DOM 更新。其中,key 属性对于列表的 Diff 至关重要,能够极大地提升列表项增删改查的性能。
我们知道了上面的比较逻辑之后,甚至可以自己写一个简单的diff算法
scss
// diff.js
function diff(oldTree, newTree) {
// 声明变量patches用来存放补丁的对象
let patches = {};
// 第一次比较应该是树的第0个索引
let index = 0;
// 递归树 比较后的结果放到补丁里
walk(oldTree, newTree, index, patches);
return patches;
}
function walk(oldNode, newNode, index, patches) {
// 每个元素都有一个补丁
let current = [];
if (!newNode) { // rule1
current.push({ type: 'REMOVE', index });
} else if (isString(oldNode) && isString(newNode)) {
// 判断文本是否一致
if (oldNode !== newNode) {
current.push({ type: 'TEXT', text: newNode });
}
} else if (oldNode.type === newNode.type) {
// 比较属性是否有更改
let attr = diffAttr(oldNode.props, newNode.props);
if (Object.keys(attr).length > 0) {
current.push({ type: 'ATTR', attr });
}
// 如果有子节点,遍历子节点
diffChildren(oldNode.children, newNode.children, patches);
} else { // 说明节点被替换了
current.push({ type: 'REPLACE', newNode});
}
// 当前元素确实有补丁存在
if (current.length) {
// 将元素和补丁对应起来,放到大补丁包中
patches[index] = current;
}
}
function isString(obj) {
return typeof obj === 'string';
}
function diffAttr(oldAttrs, newAttrs) {
let patch = {};
// 判断老的属性中和新的属性的关系
for (let key in oldAttrs) {
if (oldAttrs[key] !== newAttrs[key]) {
patch[key] = newAttrs[key]; // 有可能还是undefined
}
}
for (let key in newAttrs) {
// 老节点没有新节点的属性
if (!oldAttrs.hasOwnProperty(key)) {
patch[key] = newAttrs[key];
}
}
return patch;
}
// 所有都基于一个序号来实现
let num = 0;
function diffChildren(oldChildren, newChildren, patches) {
// 比较老的第一个和新的第一个
oldChildren.forEach((child, index) => {
walk(child, newChildren[index], ++num, patches);
});
}
// 默认导出
export default diff;这样看来也不是很难理解,不是么?
我们来总结一下diff算法的作用
Diff 算法的核心在于比较虚拟 DOM 的差异,生成描述这些差异的补丁(Patch)。 它通过对新旧虚拟 DOM 的节点进行递归比较,找出最小的更新集合,避免了直接操作 DOM 带来的性能损耗。 这个过程的关键在于高效地比较节点类型、属性和子节点,最终目标是只更新变化的部分,从而最大限度地减少对真实 DOM 的操作,提高页面更新的效率。
diff算法的高性能可以体现在两个方面
- 最小限度的减少了新旧虚拟DOM树的比较开支(有负面buff,但是尽可能把buff的影响变小)
- 最大限度地减少对真实 DOM 的操作(有正面buff)
三、偏虚拟fiber架构部分
讲实话,前面的优化已经很完美、很天才了,但是,还有高手------fiber架构
正如前面所讲,虚拟 DOM 和 Diff 算法的组合拳已经极大地提升了 React 的性能。它们通过"计算差异"和"批量更新"的策略,有效减少了直接操作真实 DOM 带来的昂贵开销。然而,随着前端应用变得越来越复杂,组件树越来越深,旧的 React 协调机制逐渐暴露出一个核心瓶颈:这是一个不可中断的同步计算过程。
为什么"不可中断"是个问题?
在 React 16 之前,当组件的状态或 props 发生变化时,React 会立即开始工作:
- 调用 Render: 重新渲染整个组件子树(生成新的虚拟 DOM)。
- 进行 Diff: 递归比较新旧两棵虚拟 DOM 树。
- 应用更新: 将计算出的差异(Patch)应用到真实 DOM。
这个过程是同步的,并且会一次性完成。如果组件树非常庞大,这个计算过程就会长时间占用 JavaScript 主线程。
而浏览器的主线程是单线程的,它除了要执行 JavaScript,还负责样式计算、布局、绘制等任务。长时间被 JS 计算霸占主线程会导致:
- 浏览器无法及时响应用户的输入(点击、滚动等),页面会感觉"卡顿"。
- 浏览器无法按时完成帧渲染,导致动画掉帧、页面渲染不流畅。
"栈协调"的困境
你可以把旧的协调过程想象成 React 在"递归"地遍历整个组件树。JavaScript 的递归调用会形成一个很深的"调用栈"。React 必须完整地走完这个调用栈,才能进行下一步。它无法暂停,无法中途去处理更高优先级的任务(比如用户的点击)。这种基于递归深度优先遍历的架构被称为 "栈协调" 。
Fiber 架构的诞生
讲实话,前面的优化(虚拟DOM + Diff算法)已经很完美、很天才了。它们通过"计算差异"和"批量更新"的策略,极大地减少了直接操作DOM带来的性能开销。但是,随着前端应用变得越来越复杂,组件树越来越深,旧的React协调机制(Stack Reconciler)逐渐暴露出一个核心瓶颈:整个虚拟DOM的Diff过程是一个【不可中断】的同步计算过程。
为什么"不可中断"是个致命问题?
在React 16之前,当状态变化触发更新时,React会这样做:
- 递归渲染:重新渲染整个受影响的组件子树,生成新的虚拟DOM树。
- 递归Diff:递归地比较新旧两棵虚拟DOM树。
- 提交更新:将计算出的差异(Patch)应用到真实DOM。
这个过程是同步且一气呵成的。如果组件树非常庞大,这个复杂的计算过程就会长时间霸占JavaScript主线程。
而浏览器的主线程是单线程的,它除了要执行JavaScript,还负责样式计算、布局、绘制以及响应用户交互(如点击、滚动)。长时间被JS计算阻塞会导致:
- 页面卡顿:浏览器无法及时响应用户操作,点击按钮没反应,滚动起来一卡一卡。
- 掉帧:动画无法在16.6ms内完成一帧的渲染,导致视觉上的不流畅。
"栈协调"的困境
旧的协调器基于递归 。递归调用会在JavaScript引擎中形成一个很深的"调用栈"。React必须完整地走完这个调用栈(即处理完整个虚拟DOM树),才能进行下一步。它就像一列高速行驶的火车,无法在中间站点暂停让道,必须到终点站才能停下。这种机制被称为 "栈协调"(Stack Reconciler) 。
Fiber架构的诞生:为了解决"不可中断"
为了从根本上解决"同步更新不可中断"的问题,React团队从底层重写了协调算法,引入了Fiber架构 和Fiber Reconciler。
Fiber是什么?
Fiber可以从两个层面理解:
- 一种数据结构 :Fiber是React 16+中虚拟DOM的新表示形式。它是一个功能更强大的JavaScript对象,包含了比传统虚拟DOM节点更丰富的调度信息。
- 一个执行单元 :Fiber代表了可以拆分、可以调度、可以中断的一个工作任务。React的渲染和更新过程不再是一次性递归完成,而是分解成一个个小的Fiber节点任务来处理。
这时候就有同学要问了:'为什么不在原来的虚拟DOM树上直接加个中断机制,非要整一个新的Fiber出来?'
问得好!答案是:传统的虚拟DOM树数据结构不支持。
- 传统的虚拟DOM树节点之间只有父子关系,通过
children数组连接。这是一种递归树形结构。中断后,你想恢复遍历,必须从头开始或者用非常复杂的方式记录进度,成本极高。 - Fiber节点通过链表连接 。每个Fiber节点不仅有指向第一个子节点(
child)的指针,还有指向下一个兄弟节点(sibling)和父节点(return)的指针。这种链表树结构 使得React可以用循环 来模拟递归遍历。中断时,只需保存当前正在处理的Fiber节点引用,恢复时就能立刻从它开始继续处理它的child或sibling,极其高效。
Fiber节点的核心属性(了解即可):
type&key: 同虚拟DOM,标识组件类型和列表项的Key。child: 指向第一个子Fiber。sibling: 指向下一个兄弟Fiber。return: 指向父级Fiber。alternate: 一个极其重要的指针 。它指向另一棵树上对应的Fiber节点,是实现双缓存和Diff比较的基础。stateNode: 对应的真实DOM节点或组件实例。flags(旧版叫effectTag): 标记这个Fiber节点需要进行的操作(如Placement-插入,Update-更新,Deletion-删除)。
Fiber如何工作?可中断的"双缓存"策略
Fiber架构将协调过程分为两个截然不同的阶段:
-
Render / Reconciliation Phase (渲染/协调阶段)
- 可中断、可恢复、异步。 这个阶段负责计算"哪些需要更新",但绝不操作真实DOM。
- React会在内存中构建一棵新的Fiber树,称为 WorkInProgress Tree(工作在进行树) 。它通过与当前屏幕上显示的 Current Tree(当前树) 上的Fiber节点进行Diff比较来完成构建。
- 工作方式 :React的调度器会循环处理每个Fiber单元。处理完一个单元,它就检查主线程是否还有空闲时间(通过
requestIdleCallback或scheduler)。如果没有时间了,或者有更高优先级的任务(如用户输入),React就立刻中断当前工作,保存进度(下一个要处理的Fiber),把主线程交还给浏览器。等浏览器忙完了,React再回来从断点继续。 - 这个阶段可能会被打断多次。
-
Commit Phase (提交阶段)
- 不可中断、同步执行。 这个阶段是React将协调阶段计算出的所有副作用 (即需要更新的操作列表)一次性、同步地应用到真实DOM上的阶段。
- 因为这个阶段会实际操作DOM,而DOM的变更会立刻触发浏览器的重绘重排,所以必须快速完成,用户不会看到"更新到一半"的UI。
- 一旦开始提交,React就会一口气完成所有DOM操作。
刚才其实已经提到了"双缓存"的概念,这里展开讲讲 "双缓存"技术
Current Tree和WorkInProgress Tree通过alternate指针相互指向。当WorkInProgress Tree构建完成并在提交阶段渲染到屏幕后,这两棵树会"互换角色":刚刚建好的WorkInProgress Tree就变成新的Current Tree,而旧的Current Tree就作为下一次更新的WorkInProgress Tree的基础。这保证了渲染的连贯性和性能。
- 当 React 开始一个渲染周期(例如,响应一个事件,数据改变)时,它会创建一个新的 Fiber 树,称为 "工作" Fiber 树。
- 这个"工作" Fiber 树是独立于用户当前看到的 DOM 树的。
- Fiber 节点在"工作" Fiber 树中进行计算,标记出需要更新、插入或删除的 DOM 节点。
- 当整个"工作" Fiber 树的计算完成后,React 会执行一个 "提交"(commit) 阶段。
- 在"提交"阶段,React 会遍历"工作" Fiber 树,并将所有需要进行的 DOM 操作一次性地应用到真实的 DOM 上。
- 此时,老的一棵 Fiber 树(代表了用户当前看到的 UI)可以被标记为"已完成"或被丢弃,而新的 Fiber 树则成为了"当前"的 Fiber 状态,准备下一次更新。
OK,关于虚拟DOM、diff算法、fiber架构大概就是这么多内容,下面我们来进行一些有趣的探讨,来解决大家心中可能有些迷惑的地方。
react中diff算法发挥作用的阶段是比较新旧虚拟DOM树的阶段,还是生成新的虚拟DOM的阶段?
Diff 算法发挥作用的阶段是"比较新旧虚拟DOM树的阶段",而不是"生成新的虚拟DOM的阶段"。
让我们来清晰地分解这两个阶段:
阶段一:生成新的虚拟DOM (Render Phase)
- 发生了什么? 当组件的状态(state)或属性(props)发生变化时,React 会重新执行 组件的
render方法。 - 结果是什么? 这个执行过程会返回一个新的 React 元素树(即新的虚拟DOM树 )。这个过程是声明式的,React 只是根据当前最新的 state 和 props 计算出 UI 应该是什么样子。
- Diff算法参与了吗? 没有。 这个阶段只是简单地根据数据生成一个新的UI描述(一棵新的树),不涉及任何比较操作。
阶段二:比较新旧虚拟DOM树 (Reconciliation Phase)
- 发生了什么? 在生成了新的虚拟DOM树之后,React 需要弄清楚新的树和当前屏幕上显示的旧虚拟DOM树(
currenttree)之间的差异。 - 如何工作? React 会启动 Diffing 算法 ,递归地比较新旧的 React 元素(虚拟DOM节点)的
type、key和props。 - 结果是什么? Diff 算法会得出一份精确的"变更清单"(或称为副作用 effect list),详细记录了为了将旧树更新为新树,需要对真实DOM进行的具体操作,例如:"在父节点下插入一个id为X的新节点"、"更新id为Y的节点的className属性"、"删除id为Z的节点"等。
- Diff算法参与了吗? 是的! 这是 Diff 算法核心工作的阶段。
新虚拟DOM树的构建是否依赖于旧的虚拟DOM树?
不会。
新的虚拟DOM树的生成是一个完全独立 和纯粹 的过程,它不依赖于旧的虚拟DOM树。这是一个非常关键的设计理念。
让我们来详细解释:
1. 生成新虚拟DOM树的逻辑
当组件的状态(state)或属性(props)发生变化时,React 会做的就是重新执行 组件的渲染函数(对于类组件是 render() 方法,对于函数组件是函数体本身)。
这个过程可以简化为:
新的虚拟DOM树 = render(currentState, currentProps)
它只依赖于两个输入:
- 当前最新的状态(currentState)
- 当前接收到的属性(currentProps)
旧的虚拟DOM树(或旧的 Fiber 树)不是这个函数的输入参数。渲染函数就像一个"纯函数",给定相同的 state 和 props,它总是会返回相同的 UI 描述(虚拟DOM树)。它完全不知道、也不关心上一次渲染出来的结果是什么。
2. 为什么这个设计如此重要?
这种"不依赖旧树"的设计是 React 声明式编程模型的核心优势:
- 可预测性 :UI 只由当前的 state 和 props 决定,这使得应用的行为非常容易理解和预测。你不需要考虑"当前屏幕上显示的是什么",只需要思考"在这个数据状态下,UI 应该是什么样子"。
- 简化逻辑:开发者编写渲染逻辑时,只需要关注如何根据当前数据构建UI,而不需要处理如何从旧UI更新到新UI的复杂指令(这是 React 的职责)。
- 性能优化的基础:正因为生成新树是一个相对独立的过程,React 才能在背后灵活地调度这项工作。例如,在并发模式下,React 可以先在后台为一次即将到来的更新生成新的虚拟DOM树,而不立即提交,如果又有更高优先级的更新插队,它甚至可以丢弃这棵还没用完的树,重新开始生成,而不会破坏一致性。
在Fiber架构下diff算法到底是比较的什么?
在 Fiber 架构下,Diff 算法比较的并不是两棵完整的、传统的"虚拟DOM树",而是两棵"Fiber 树"上的对应节点。
理解这一点是理解 Fiber 架构如何工作的核心。让我们来彻底拆解它。
核心概念:两棵Fiber树
在 Fiber 架构中,React 在内存中同时维护着两棵 Fiber 树:
-
Current Tree(当前树) :
- 这棵树代表当前已渲染到屏幕上的UI状态。
- 树中的每个 Fiber 节点都直接对应着一个真实的 DOM 节点(对于宿主组件如
div、span)或一个组件实例(对于类组件)。 - 你可以把它想象成"旧的虚拟DOM树"的Fiber版本。
-
WorkInProgress Tree(工作中树) :
- 当状态更新发生时,React 会在后台开始构建这棵新树。它代表了下一次渲染希望更新到的UI状态。
- 这棵树的构建过程是可中断的。
- 你可以把它想象成"新的虚拟DOM树"的Fiber版本。
Diff 算法的本质,就是比较同一节点在 Current Tree 和 WorkInProgress Tree 上的两个 Fiber 节点。
Diff 的具体过程:ReconcileChildren
Diff 过程发生在 React 为 WorkInProgress 树创建子节点(Fiber节点)的时候。这个函数通常被称为 reconcileChildren 或 reconcileChildFibers。
它的工作流程如下:
- 输入 :一个父级 Fiber 节点(在 WorkInProgress 树中)和它通过
render函数返回的 新的React元素(React Elements) 。 - 目标 :为这些新的React元素创建或复用Fiber节点,从而构建出父级Fiber的
child链表。 - 比较策略 :React 会将新的React元素 与Current Tree中该父F节点下对应的旧子Fiber节点进行比较。
这个过程是逐层 且逐节点进行的,而不是一次性比较整棵树。
Diff 算法在Fiber中比较的具体内容
当处理一个新的React元素 和一个旧的Fiber节点时,Diff 算法会按顺序检查以下属性:
-
Fiber.key vs. Element.key
- 这是第一优先级! 这是列表diff性能的关键。
- 算法会首先检查key是否相同。如果key不同,React会认为这是一个不同的元素,即使
type相同。
-
Fiber.type vs. Element.type
- 这是第二优先级! 检查节点类型(如
'div'、'MyComponent')是否相同。 - 如果key相同但type不同,React会认为需要替换整个节点及其子树(因为一个
div不可能直接变成一个span)。
- 这是第二优先级! 检查节点类型(如
-
Fiber.pendingProps vs. Element.props
- 如果key和type都相同,React则认为这是一个可以复用的Fiber节点。
- 接下来会比较新旧属性(props)的差异,并将需要更新的属性标记出来。
Fiber节点的"池化"
在Fiber架构中,"比较"的目的不仅仅是找出差异,更重要的是尽可能地复用现有的Fiber节点。这是一种性能优化策略,类似于"对象池"。
-
如果可以复用(key和type都相同) :React不会销毁旧的Fiber节点并创建一个全新的对象,而是会 "克隆" 旧的Fiber节点(来自Current树),用它来构建WorkInProgress树。它只是用新的props和新的子元素引用更新这个克隆体的属性。
- 好处:避免了频繁创建和销毁JavaScript对象的开销,极大提升了性能。
-
如果不能复用(key或type不同) :React会为新的React元素创建一个全新的Fiber节点 ,并标记旧的Fiber节点及其整个子树需要被删除。
读到这里,也可以猜到我的下一个问题
Fiber树的构建是否依赖虚拟DOM树
是的,Fiber树的构建完全依赖虚拟DOM树,并且这是一个持续依赖的关系。
更准确地说,虚拟DOM树(React Element Tree)是构建Fiber树的"蓝图"或"指令" 。没有虚拟DOM树,Fiber树就无法被创建或更新。
让我们来详细分解这个依赖关系:
1. 初始渲染:从虚拟DOM到Fiber树
当你的应用首次加载时,React 的工作流程是这样的:
-
生成虚拟DOM树 :React 调用你的根组件的
render()方法(或执行函数组件体)。这个执行过程会返回一个由 React 元素 组成的树,这就是最初的虚拟DOM树。它是对UI的声明式描述。 -
构建Fiber树 :React 接收到这棵虚拟DOM树后,以它为依据 ,开始创建对应的 Fiber 节点 ,并将这些节点连接成一棵 Fiber 树(也就是最初的 Current 树)。
- 每个 Fiber 节点都是从对应的 React 元素中获取其
type,key,props等信息。 - 虚拟DOM树描述了 "UI应该是什么样子" ,而Fiber树是 为了实现协调和更新而构建的"工作单元数据结构" 。
- 每个 Fiber 节点都是从对应的 React 元素中获取其
初始渲染的依赖关系:
组件render() -> 虚拟DOM树 -> Fiber树 -> 真实DOM
2. 状态更新:虚拟DOM是驱动Fiber树重建的源头
当状态发生变化,触发更新时,这个依赖关系更加明显:
-
生成新的虚拟DOM树 :状态更新导致组件重新渲染,再次调用
render方法。这会生成一棵新的虚拟DOM树 。这个过程是纯粹的,不依赖旧的Fiber树,只依赖于当前的 state 和 props。 -
协调 :React 现在手上有两样东西:
- 旧的Fiber树(Current 树):代表当前屏幕上显示的内容。
- 新的虚拟DOM树:代表下一次渲染希望更新到的UI状态。
-
构建新的Fiber树 :React 开始构建 WorkInProgress 树。它遍历新的虚拟DOM树 ,并逐节点地与旧的Fiber树进行比较(Diff算法) 。
- 对于新的虚拟DOM树上的每一个 React 元素,React 都会去旧的Fiber树中寻找可以复用的Fiber节点。
- 复用的决策(key和type是否相同)完全基于新的React元素和旧的Fiber节点的属性。
- 最终,React 会根据比较结果,创建新的Fiber节点或复用旧的Fiber节点,从而构建出完整的 WorkInProgress 树。
更新时的依赖关系:
状态改变 -> 组件重新render() -> 新的虚拟DOM树 -> (Diff算法) -> 构建新的Fiber树(WorkInProgress) -> 更新真实DOM
现在(react18以后)UI的改变是比较两个虚拟DOM从而改变UI了,还是新旧fiber树的比较改变UI?
在 React 16 之后,UI 的改变不再仅仅依赖于比较两个虚拟 DOM (VDOM) 树来决定 DOM 的更新,更重要的是,React 的更新过程现在主要基于 Fiber 架构,并通过比较新旧 Fiber 树来实现高效的 UI 更新。
让我们更详细地解释一下:
1. 传统 (React 16 及以前) 的 VDOM 更新机制 (简化版)
- 组件状态改变 -> 创建新的 VDOM
- 新 VDOM 与旧 VDOM 比较 (diffing)
- Diffing 算法识别变化,生成 DOM 更新指令
- DOM 更新指令被应用到真实的 DOM
关键问题:
- 同步过程: 整个 diffing 过程是同步的,会阻塞主线程,如果组件复杂,会影响用户体验(卡顿)。
- 优先级问题: 所有更新都被同等对待,无法区分重要性和紧急程度。
2. Fiber 架构下的更新机制 (React 17及以后)
-
组件状态改变 -> (触发更新)
-
React 根据新状态创建新的 Fiber 树 (工作 Fiber 树)
-
构建 (render) 阶段:
- React 遍历新的 Fiber 树。
- 比较 新 Fiber 树与旧 Fiber 树 (旧 Fiber 树的父节点指向新 Fiber, new Fiber 存在
alternate 属性指向 old fiber , 即通过 Fiber 树的信息,来比较新旧UI)。 - 计算需要进行的 DOM 操作 (插入、删除、更新)
- React 可以中断 这个过程,处理高优先级任务 (例如用户交互),之后 可以恢复
-
提交 (commit) 阶段:
- 一次性将所有 DOM 操作 (变化) 应用到真实的 DOM
flushPassiveEffects触发一些useEffect- 此时,旧的 Fiber 树 (代表之前的 UI) 被标记为不可用, 新的 Fiber 树 (代表新的 UI) 成为"当前"的 Fiber 状态。
关键变化:
- Fiber 树取代了 VDOM 树成为更重要的结构: React 用 Fiber 节点来表示 UI 的工作单元。 Fiber 树 (新旧) 之间的比较,驱动了 DOM 的更新。
- 构建阶段可中断: React 可以在**
render阶段** 中中断耗时的计算任务,让出主线程。 这使得用户体验更好。 - 并发 (Concurreny): Fiber 开启了并发渲染的可能性。 React 可以在后台准备多个 UI 更新,然后以一种流畅的方式进行切换。
- 优先级和调度: Fiber 架构允许优先处理某些更新 (
Transition, Sync等)。
所以,现在, UI 的变化的核心是:
- React 基于状态变化构建新的 Fiber 树 (工作 Fiber 树)。
- React 通过比较新的 Fiber 树和旧的 Fiber 树 (主要是比较
Fiber节点里的信息) 来确定需要进行的 DOM 操作。 - DOM 操作在
commit阶段一次性应用到 DOM。 这个阶段是同步的,但因为计算发生在后台,所以不会阻塞 UI 渲染太多时间。
一个更精确的解释是:
在 React 18及更高版本中,比较(diffing)仍然存在,但它在 Fiber 架构中得到了重新组织和增强。主要比较的核心是:
- Fiber 节点: 比较的是新旧 Fiber 树中的
Fiber节点。 - 副作用管理: 比较 Fiber 的
effectTag属性,effectTag标记了需要进行哪些 DOM 操作 (例如:插入、更新、删除)。 - 工作单元: ** Fiber 将更新过程分解成工作单元,并使用 优先级**、中断和恢复等技术来优化更新。
虽然 Virtual DOM 仍然是 React 中的一个重要概念,它描述了 UI 的状态,但 Fiber 架构是核心,它控制了更新的调度、性能和并发。 新旧 Fiber 树之间的比较 (更确切地说, Fiber 节点之间的比较) 是触发 UI 变化的根本原因。
我们可以对UI的改变过程做一个React层面的分层
React的架构可以看作一个清晰的 pipeline(流水线),每一层职责分明:
第1层:开发者 (Your Code)
- 职责 :使用声明式 的JSX或
React.createElement编写组件。 - 输出 :虚拟DOM(React元素) 。这只是UI的描述 ("蓝图"),例如"这里应该有一个
<div>,它的className是'active',里面有一个<span>"。
第2层:React核心 (React Core / Reconciler)
- 职责 :协调(Reconciliation) 。这是Fiber架构的核心所在。
- 输入:旧的Fiber树 + 新的虚拟DOM树(来自第1层)。
- 工作 :通过Diff算法比较新旧内容,计算出需要进行的更新操作(如
Placement,Update,Deletion)。 - 输出 :一个包含了所有更新操作的副作用链表(Effect List) 。注意:到这里为止,操作的仍然是JavaScript对象(Fiber节点),没有触及真实DOM。
第3层:渲染器 (Renderer - e.g., ReactDOM)
-
职责 :渲染。这是真正操作平台特定API(如浏览器DOM)的层。
-
输入 :React核心计算出的副作用链表。
-
工作:遍历副作用链表,执行具体的、平台相关的命令。
- 对于ReactDOM来说,就是调用
document.createElement(),element.appendChild(),element.setAttribute(),element.remove()等浏览器DOM API。
- 对于ReactDOM来说,就是调用
-
输出:更新后的真实UI。
总结
OK,就谈到这里吧