01. 数据状态与归纳函数
在前面的课时中,我们说过在 LangGraph 中 节点 在默认情况下返回的字典数据会将原始数据覆盖,例如下面的代码最终返回结果是 {"messages": 4} 而不是 1,2,3,4,如下
class MyState(TypedDict):
messages: list
def fn1(state: MyState):
return {"messages": 4}
... (ignore codes of start->fn1->end, blah blah)
r = graph.invoke({"messages": 1, 2, 3})
如果就是想要 1, 2, 3, 4 呢?第一种方法就是拿到 原始状态 的值,更新新数据,然后返回def fn1(state: MyState):
old = state.get("messages", \[\])
return {"messages": old + 4}
除此之外,在 LangGraph 中,还针对 Annotated 进行了封装,在 Python 中 Annotated 只是另外一种形态的 注释,对类型的声明+使用并没有任何影响,例如
不过这样声明有一个好处,在程序中,我们可以通过 .metadata 元数据属性拿到这个值,如下
cn_salary.metadata
于是在 LangGraph 中就针对 注释+元数据 进行了封装,使用 Annotated 外挂需要处理数据的 归纳函数,如果外挂了则使用,不外挂也没有任何影响,这就是利用 归纳函数 来更新状态的核心。
代码经过更新后,就可以正常对数据执行相应操作了:
def concat_lists(original: list, new: list) -> list:
return original + new
class MyState(TypedDict):
messages: list
messages: Annotatedlist, concat_lists
def fn1(state: MyState):
return {"messages": 4}
r = graph.invoke({"messages": 1, 2, 3})
print(r)
输出是 {'messages': 1, 2, 3, 4}
使用 归纳函数 的优点也非常明显,可以让每个 节点 独立执行,不用理会别人在做啥,不需要花额外的功夫去处理 state 里的其他数据,而且在更新 state 结构时,也不需要逐个节点更新,但是添加 归纳函数 后要想执行一些特殊的操作也非常麻烦,要额外花很多功夫,例如在 add_messages() 中的 RemoveMessage 和 更新消息,就进行了额外的判断与处理
02. 多节点并行同时执行
在 LangGraph 中,END 节点非常特殊,并不是 图结构 程序走到 END 节点就终止了,只是 当前路线结束 了, 也就是说 END 是结束当前 路线,并不是结束 图,理解好这个概念才能处理好 多节点并行执行 的情况。
例如如下并行路线
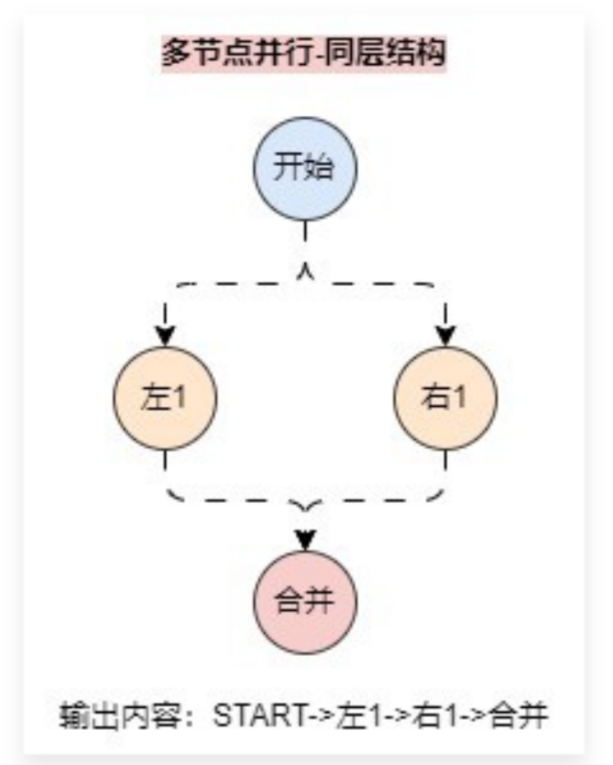
在上述的节点中,如果将图结构转换成带有层级的图,则 左1 和 右1 处于同一层级上,所以这两个节点是并行执行的,但是顺序不一定能保证,虽然在 LangGraph 中会按照连接的顺序来执行,最终输出就是:START->左1->右1->合并。
如果是以下的并行路线
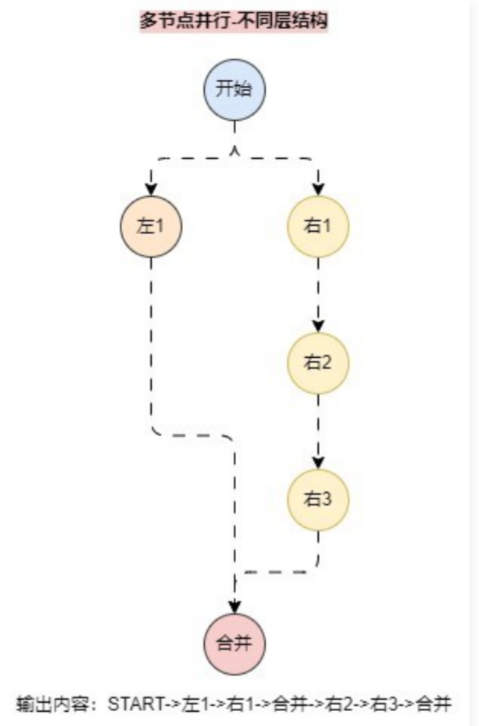
在这个 图结构 中,合并 虽然属于 END 节点,并且在 左1 执行完成之后就会执行 合并,但是 合并节点 并不会终止整个图的执行,而是会和 右2 作为同一层一起执行(并行执行,顺序不确定),所以最终输出:START->左1->右1->合并->右2->右3->合并。
如果想让 合并 节点只执行一次,只要把 左1 和 右3 合并同时连接到 合并 节点上即可,这样这两个节点就处于同一层,更新代码如下
graph.add_edge("left1", "right3", "merge")
03. 检查点 CheckPoint
检查点的概念因为它的名字,初次使用理解起来可能会比较吃力,其实只需要把 检查点 看成是一个 存储介质,用来记录这些资料,就好比游戏存档、不同玩家不同场次、可以存起来,然后载入,甚至篡改更新
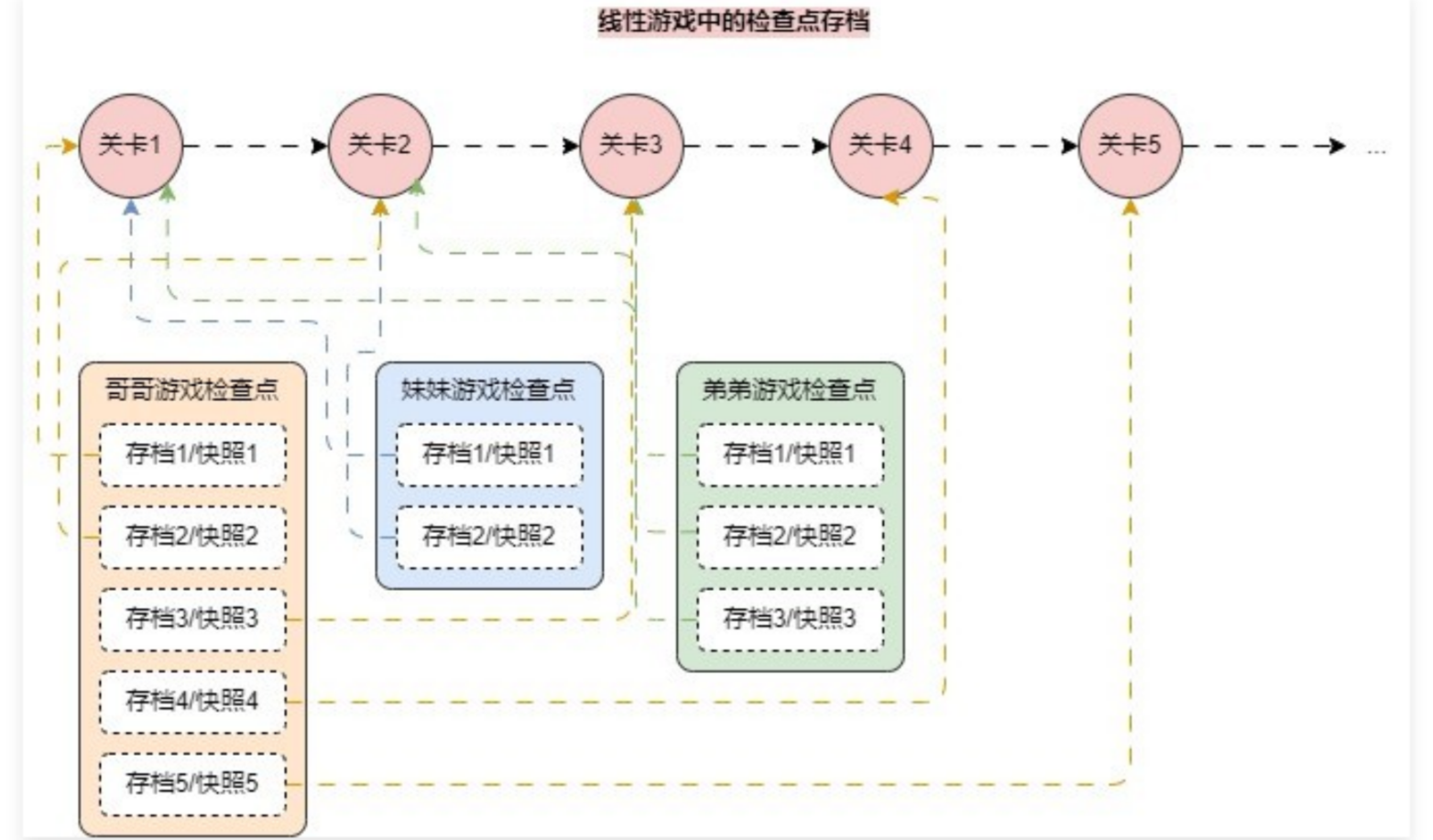
所以在 LangGraph 图程序中加入 检查点 就等同于加入了一个 外部存储介质,会将每一个节点的 状态 都存储起来(StateSnapshot),变成一个历史的 list,所以对于 图程序 必须配置检查点才可以拿到 snapshot游戏存档:
- graph.get_state(config):拿到 检查点 的最后一次存档(最后一个节点更新后的状态)。
- graph.get_state_history(config):拿到检查点的所有存档(每个节点更新后的状态列表)。
在前面的课时中,我们传递的 config 里只有 thread_id,但是在 get_state_history(config) 拿到的所有存档列表中,还存在另外一个字段 thread_ts 代表线程的执行时间,通过该字段就可以唯一定位检查点中的某个存档,例如
StateSnapshot(..., config={'configurable': {'thread_id': '1', 'thread_ts': '1ef2985c-bed5-6dee-8003-6037939ae5aa'}}, ...)
和游戏存档回退一样,如果我们想回退到指定的存档,只需调用 invoke() 玩游戏,并载入指定存档的配置即可
for s in graph.stream(
input=None,
config=past_config, # <--
stream_mode="values"
):
print(s)
甚至是我们想篡改 存档 的数据也是可以的,还记得 update_state() 这个函数么,同样可以传入对应的 config,只需要在修改时,传递需要更改的 存档配置 即可,例如
graph.update_state(
config=past_config,
values={"crew": 66, 77, "v": "BAD GUY"}
)
不过因为回退机制用得比较少,所以该功能在 LangGraph 的官网藏得也比较深,也没有过多文章做出详细的讲解