Virtual Thread
由JEP444 发起,在JDK 21中正式发布。相比平台线程更加轻量级,在某些场景下可以显著提供程序的吞吐量,API使用也十分的简单,不需要太多的学习成本。
虚拟线程具体实现参考:bytejava.cn/md/jvm/jvm/...
常见用法
java
public static void main(String[] args) {
Thread.ofVirtual().start(() -> {
System.out.println(Thread.currentThread());
}).join();
Thread.startVirtualThread(() -> {
System.out.println(Thread.currentThread());
}); //.setName("virtual thread");
ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();
executorService.submit(() -> {});
} 原理简单分析
VirtualThread类从Thread继承而来,Thread 支持的功能虚拟线程同样支持,可以无缝切换Thread 到虚拟线程
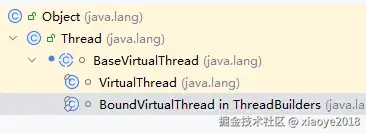
虚拟线程执行流程:
- 当虚拟线程执行任务时,会将任务包装成一个Continuation,continuation会管理当前任务的执行状态以及堆栈信息。
- 将continuation提交给Scheduler调度器。目前是ForkJoinPool,拥有工作窃取机制,可以很高效的处理任务。
- continuation被scheduler某个线程选中(称为Carrier线程),开始执行continuation中的任务。
- 当任务中出现阻塞操作时,如 LockSupport.park,会执行yield暂停当前任务(内部会判断虚拟线程执行yield,如果是平台线程依然走park),将当前运行的栈、上下文信息保存到continuation对象中。
- Carrier线程不会阻塞,接着处理其他任务。在Carrier眼中相当于这个任务已经执行完成
- 当任务的阻塞操作完成后,会唤醒continuation (LockSupport.unpark),重新提交给scheduler。
- scheduler 再次选中该continuation,触发continuation#run, 恢复continuation中的栈、上下文信息, 从暂停的位置继续执行程序。(现在的Carrier线程不一定跟之前的相同)
Continuation
Continuation作为一个执行任务载体,内部维护着任务的执行状态。当执行yield 的时候会将当前运行的上下文信息保存到堆中,放弃执行权。 当被唤醒后会重新恢复上下文信息,继续从暂停的地方执行 continuation也可以单独使用,如下:
java
/**
* --add-exports java.base/jdk.internal.vm=ALL-UNNAMED
* @date 2025/9/3
*/
public class ContinuationTest2 {
public static void main(String[] args) {
ContinuationScope scope = new ContinuationScope("scope");
Continuation continuation = new Continuation(scope, () -> {
System.out.println("continuation start execute...");
Continuation.yield(scope); // 暂停执行continuation
System.out.println("continuation end execute...");
});
continuation.run(); // 开始执行continuation
System.out.println(continuation.isDone()); // false: 由于continuation内部执行了yield
continuation.run(); // 继续执行continuation
}
}输出如下:
text
continuation start execute...
false
continuation end execute...Pinning
前面说了虚拟现在在执行continuation的时候,遇到阻塞的时候会执行yield,完成后Carrier线程会继续去处理其他任务。 但是在某些情况下执行yield 并不能立即结束当前的任务,导致该Carrier线程一直阻塞,这种情况就叫Pinning
下面情况会发生Pinning:
- 在一个sychronized块或方法中遇到了续体yield调用,受限于轻量级锁和Object_monitor_waiter的实现,所以会一并使得当前的载体线程阻塞。 monitor释放之后(synchronized块/方法退出),线程就被解除Pinning。
- 从Native层回调Java层时,遇到了续体yield调用,此时受限于FFI实现不应当让出当前线程,所以产生了Pinning
当虚拟线程等待synchronized 块时,不会发生pinning
pinning 检查参数: -Djdk.tracePinnedThreads=short/full. 如果发生pin,将会输出: <== monitors 由于这个参数内部实现和jvmti交互有bug, 因此在debug场景下会卡死。
java
// -Djdk.tracePinnedThreads=short
public class Main {
public static void main(String[] args) {
Thread.startVirtualThread(() -> {
synchronized (Main.class) {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println("finish");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}); //.setName("virtual thread");
LockSupport.park();
}
}输出:
text
Thread[#31,ForkJoinPool-1-worker-1,5,CarrierThreads]
org.example.Main.lambda$main$0(Main.java:11) <== monitors:1
finishJEP491: 解决Synchronize 情况下发生pinning, 参数tracePinnedThreads将无用。 由JDK24 中发布,并没有完全解决pinning.
虚拟线程观测 & ThreadContainer
在使用 jstack 或 jcmd 获取的 JDK 传统线程转储展示的是一个扁平的线程列表,不利于虚拟线程的观察,jcmd 中引入一种新型的线程转储 , 以有意义的方式将虚拟线程与平台线程一起分组展示。当程序使用结构化并发时,可以展示线程之间更丰富的关系。
在执行过程可以使用下面命令可以输出线程信息: jcmd Thread.dump_to_file -format=json 等价于下面代码: new HotSpotDiagnostic().dumpThreads("C:\project\feature23\test.json", HotSpotDiagnosticMXBean.ThreadDumpFormat.JSON);
输出如下:每个container下面输出对应的线程信息
内部主要由ThreadContainer 对象用跟踪线程信息,有虚拟线程数量统计、线程跟踪等。在结构化并发中比较有用。 ThreadContainer继承关系:
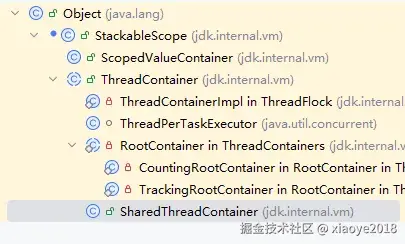
开启虚拟线程前会设置默认container 为rootContainers --> ThreadContainers.root(): 每个Thread对象都有一个container属性, 即使new Thread 没有设置container,默认也为:
根据jdk.trackAllThreads 属性决定是用TrackingRootContainer(default),还是CountingRootContainer。 name 都叫
- TrackingRootContainer: jdk.trackAllThreads 为true,或者为空。 每次创建虚拟线程会将其加入virtualThreads集合中,结束时会清理。
- CountingRootContainer: jdk.trackAllThreads 为false。 只是统计一个数量. 此时Thread.Builder API 创建的虚拟线程将不会始终被运行时跟踪。即JCMD无法获取到虚拟线程的信息
除了上面的Container外,还有SharedThreadContainer(不继承RootContainer), 用于非结构化使用,例如线程池
手动创建虚拟线程container构造过程: start(ThreadContainers.root()): 虚拟线程执行过程
- 使用container跟踪当前线程
- 如果container#owner 不为空,同时有scopedValue,那么需要将其继承过来,放入Thread#scopedValueBindings
- 提交continuation 到scheduler (默认forkJoin) -- 平台线程执行continuation: mount、run、unmount。 -- 如果完成清理资源,从container中移除。 否则yield。
- 清理资源,可能执行同样的清理逻辑
ScopeValue
ScopeValue:jep481 线程间不可变,比threadlocal更加高效,且内存更低。 主要用于虚拟线程、结构化编程 jep480 threadLocal: 数据可变、易内存泄露、当子线程过多,继承父线程的inheritableThreadLocals可能导致内存占用较大
StructuredTaskScope: 子线程可以继承父线程的Scope
Snapshot: 快照,相当于threadlocal 相关记录位置: Thread#scopedValueBindings: 默认Thread.class, Snapshot (包含previous指针) 对象 Thread#headStackableScopes: 指向线程栈顶元素 。 previous 记录上一个StackableScope 。 貌似StructuredTaskScope才使用这个东西 Thread#scopedValueCache: native 方法
ScopeValue#call
- ScopedValue.Carrier.call: ScopeValue对象执行call/run的时候 会将当前线程 ScopeValue对象取出(thread#scopedValueBindings),与当前ScopeValue对象形成一个链表: Snapshot。
- Carrier.runWith: 会将上面生成的链表对象Snapshot 重新放入当前线程的scopedValueBindings
- ScopedValueContainer.call:
- headStackableScopes为空:直接执行目标
- headStackableScopes非空: 生成一个ScopedValueContainer(继承StackableScope,owner 为当前thread )对象,绑定之前的scopedValueBindings 到 previous, 重新设置当前线程的栈顶元素headStackableScopes
ScopeValue 存放数据的实际上是Snapshot对象,Snapshot 持有bindings 值 Snapshot#bitmask: Carrier#bitmask:
ScopeValue.get():
- 从当前线程的缓存scopedValueCache 取
- 取不到从scopedValueBindings取 (slowGet)
- 遍历取到的Snapshot(栈顶 元素),找到当前相同的key(ScopeValue对象, 同一个线程可能有多个ScopeValue对象)
- 遍历Snapshot
- 遍历Snapshot#carrier。
- 最后放入缓存scopedValueCache(native 实现)。 一个32长度的数组。 arrn = ScopeValue, arrn+1 = value
ThreadContainerImpl 才是传的false,非共享,有owner, 会继承scoprevalue
StructuredTask
ScopeValue 在线程间共享必须不可变。
ShutdownOnSuccess: 其中一个任务完成后,即终止其他任务 ShutdownOnFailure: 有一个失败后,终止其他任务
Thread flocks: 线程群, 管理线程start, close、 会使用一个tree 结构
StructuredTaskScope# ThreadFlock
#scopedValueBindings: 记录当前线程的scopedValue #container: ThreadContainerImpl (StackableScope子类)实例对象, 会存放当前线程作为owner, StackableScope#previous 记录当前线程的栈顶元素headStackableScopes
scope.fork:
- 为任务创建虚拟线程
- 执行:flock.start(thread), 将线程任务交由ThreadFlock开启线程。
- VirtualThread.start(container)
- 设置虚拟线程的container为StructuredTaskScope的container
- container.onStart: ThreadFlock#threadCount + 1, 将当前线程加入threads
- 继承container#scopedValueBindings
- 执行continuation
- continuation 执行完成后: 最后执行终止操作:afterTerminate, 执行container#onExit --> flock.onExit(thread): ThreadFlock#threadCount -1, 从threads移除。 如果此时threadCount为0, 表示现在执行完了,执行:LockSupport.unpark(owner()); 唤醒join 的线程。
- VirtualThread.start(container)
- 返回任务对象Subtask, 没有等待完成的方法
scope.join: 等待任务完成。
java
var scopedValue = ScopedValue.newInstance();
ScopedValue.runWhere(scopedValue, "duke", () -> {
try (var scope = new StructuredTaskScope<String>()) {
scope.fork(() -> childTask());
scope.fork(() -> childTask2());
scope.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});网络IO 实现
在高版本JDK21中,编写传统的BIO代码时,最终都会进行转换为NIO的实现方式。 对于读取操作:
- 如果是虚拟线程,等待过程中将会释放continuation, 当数据到达后由Poller 进行唤醒continuation继续执行。
- 如果是平台线程,那么等待依然采用阻塞等待的方式。
demo 演示:
Server:
java
public static void main(String[] args) throws Throwable {
HttpServer httpServer = HttpServer.create(new InetSocketAddress(8080), 0);
httpServer.createContext("/test", t -> {
try {
TimeUnit.MINUTES.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
Headers responseHeaders = t.getResponseHeaders();
responseHeaders.add("content-type", "text/plain");
String response = "This is the response";
t.sendResponseHeaders(200, response.length());
OutputStream os = t.getResponseBody();
os.write(response.getBytes());
os.close();
});
httpServer.start();
LockSupport.park();
}
java
static record URLData (URL url, byte[] response) { }
static List<URLData> retrieveURLs(URL... urls) throws Exception {
//创建虚拟线程线程池
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
//生成读取对每个 url 执行 getURL 方法的任务
var tasks = Arrays.stream(urls)
.map(url -> (Callable<URLData>)() -> getURL(url))
.toList();
//提交任务,等待并返回所有结果
return executor.invokeAll(tasks).stream()
.filter(Future::isDone)
.map(f -> {
try {
return f.get();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
})
.toList();
}
}
//读取url的内容
static URLData getURL(URL url) throws IOException {
try (InputStream in = url.openStream()) {
return new URLData(url, in.readAllBytes());
}
}
public static void main(String[] args) throws Exception {
long pid = ProcessHandle.current().pid();
System.out.println("进程 ID (PID): " + pid);
List<URLData> urlData = retrieveURLs(new URL("http://localhost:8080/test"));
System.out.println(urlData);
for (URLData urlDatum : urlData) {
System.out.println(new String(urlDatum.response));
}
}在阻塞过程中可以通过JCMD命令dump 出堆栈信息。 IDEA中自带的dump 工具无法dump出虚拟线程的堆栈信息。
shell
默认会在进程目录生成文件
jcmd 4632 Thread.dump_to_file threads.txt -overwrite
可以看到虚拟线程阻塞的堆栈信息:
#30 "" virtual
java.base/java.lang.VirtualThread.park(VirtualThread.java:582)
java.base/java.lang.System$2.parkVirtualThread(System.java:2643)
java.base/jdk.internal.misc.VirtualThreads.park(VirtualThreads.java:54)
java.base/java.util.concurrent.locks.LockSupport.park(LockSupport.java:369)
java.base/sun.nio.ch.Poller.pollIndirect(Poller.java:139)
java.base/sun.nio.ch.Poller.poll(Poller.java:102)
java.base/sun.nio.ch.Poller.poll(Poller.java:87)
java.base/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:175)
java.base/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:201)
java.base/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:309)
java.base/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:346)
java.base/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:796)
java.base/java.net.Socket$SocketInputStream.read(Socket.java:1099)Poller: 一个Poller相当于一个selector。不同平台实现不同。win为WEPoll,linux 则epoll, mac 则 kqueue。 下面都是win的分析:
-
map: <fd, thread>. 处理park唤醒线程
-
queue:需要异步跟踪的请求对象 (Request:fd、waiter、done。 可以有一个等待完成的线程)
static 中会初始化readPoller,writePoller。 每个Poller 启动的时候会相应的启动一个Updater(默认情况)
jdk.readPollers 属性可以定义poller 个数,默认1. 请求采用fd % len 的方法来选择poller
readPoller: 监听EPOLLIN 事件, writePoller:监听 EPOLLOUT
Updater 从 queue 中获取对象, 将fd 注册到selector, 监听 EPOLLONESHOT(触发方式: report event(s) only once)
连接请求
java.net.Socket#connect(java.net.SocketAddress, int)
- getImpl(): 会创建一个delegate表示底层Socket实现:java.net.SocketImpl#createPlatformSocketImpl , 默认为 NioSocketImpl
- sun.nio.ch.NioSocketImpl#create: 创建FD
- connect(epoint, timeout): 调用Socket实现类 sun.nio.ch.NioSocketImpl#connnect
- configureNonBlockingIfNeeded: 如果有超时设置,或者虚拟线程 那么设置为非阻塞模式
- 调用NioSocketImpl#park(注册fd 到Poller中,最终执行LockSupport.park, 等待唤醒);跟后面分析的等待server响应一样逻辑。
- 再次执行:Net.pollConnectNow,检查是否成功建立连接。
读取响应数据: sun.nio.ch.NioSocketImpl#implRead --> timedRead --> park
tryRead的时候返回-2 (IOStatus: Nothing available (non-blocking)), 就会执行park 逻辑:
sun.nio.ch.NioSocketImpl#park(java.io.FileDescriptor, int, long): 虚拟线程执行Poller#poll。 非虚拟线程执行默认的Net#poll,由底层平台实现。
- 选择一个ReadPoller,注册fd 到该对象的Poller#map, 添加Rquest对象到 queue 2. Updater线程 消费Request对象,执行 fd注册逻辑,添加:EPOLLONESHOT。 3. ReadPoller线程,执行selector# wait,等待事件发生
- 执行LockSupport#park。
- 当server准备好数据后,ReadPoller收到事件,唤醒任务线程 (即执行:LockSupport.unpark(thread);)
- 任务线程执行deregister逻辑,从Selector 中移除 fd。