作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
前面3个小节,我们介绍了单机情况下的HDFS的3个组件,其中nn和dn无论单机还是集群都是需要的,而2nn则只在单机下才有用,后面几个我们将介绍高可用集群模式涉及到的几个组件:JournalNode,ZKFailoverController(ZKFC) ,本小节介绍:JournalNode。
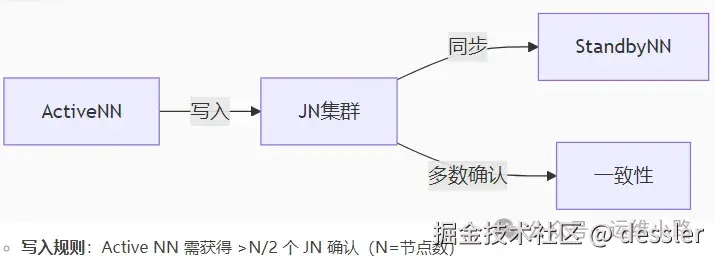
JournalNode 是 Hadoop HDFS 中用于实现 NameNode 高可用(High Availability, HA)的核心组件,主要作用是在 Active 和 Standby 两个 NameNode 之间同步元数据变更,确保集群在主 NameNode 故障时,备用节点能快速切换并恢复服务。其设计聚焦于数据一致性、高可靠性与低延迟,以下从核心功能、工作机制、部署架构及关键特性展开详解。
一、核心功能
**元数据变更日志(EditLog)的共享存储:**在非 HA 架构中,NameNode 的元数据变更日志(EditLog)仅存储在本地磁盘,若主节点故障,未同步的日志会导致数据丢失。JournalNode 则作为分布式日志存储服务,接收 Active NameNode 写入的 EditLog,并为 Standby NameNode 提供日志读取接口,实现两者的元数据实时同步:
-
Active NameNode 每次修改元数据(如创建文件、删除目录)后,会将变更记录写入本地 EditLog 的同时,同步发送至 JournalNode 集群;
-
Standby NameNode 持续从 JournalNode 读取新的 EditLog,并重放至自身内存中的元数据镜像(FsImage),确保与 Active 节点的元数据状态一致。
分布式一致性校验:JournalNode 集群采用 "多数派协议"(Quorum)保证日志写入的可靠性:只有当超过半数((N/2)+1,N 为 JournalNode 节点数)的节点成功写入 EditLog 后,Active NameNode 才会确认该日志写入成功。这种机制避免了单节点故障导致的日志丢失,同时兼顾写入效率(无需等待所有节点确认)。
二、工作机制
EditLog 的写入流程
当 Active NameNode 产生元数据变更时,与 JournalNode 的交互步骤如下:
连接建立:Active NameNode 与所有 JournalNode 建立持久化 TCP 连接,通过 RPC 协议通信;
日志提交:将 EditLog 条目封装为事务(Transaction),按顺序发送至 JournalNode 集群;
多数派确认:每个 JournalNode 接收事务后,先写入本地磁盘的日志文件(路径由 dfs.journalnode.edits.dir 配置),再返回确认信息。Active NameNode 收到超过半数节点的确认后,标记该事务为 "已提交",并更新自身的日志序列号(EditLog Sequence Number);
本地同步:同时将事务写入本地 EditLog 文件(作为备份,避免 JournalNode 集群临时不可用时的日志丢失)。
Standby NameNode 的日志同步
Standby NameNode 通过以下方式保持与 Active 节点的一致性:
-
定期向 JournalNode 发起请求,获取最新的 EditLog 事务(基于自身已同步的最大序列号);
-
将新事务逐条重放至内存中的 FsImage,更新元数据状态;
-
当 Active 节点故障时,Standby 节点已拥有最新的元数据(仅差最后几秒可能未同步的事务,可通过 JournalNode 补全),因此能快速切换为 Active 状态
故障检测与自动恢复
-
JournalNode 定期向 NameNode 发送心跳(默认 5 秒一次),报告自身状态;
-
若某个 JournalNode 故障,Active NameNode 会忽略该节点,仅向正常节点提交日志(只要多数节点存活,服务即可继续);
-
故障节点恢复后,会自动从其他 JournalNode 同步缺失的 EditLog 日志,确保集群日志一致性。
总结
JournalNode 是 HDFS 实现高可用的关键组件,其核心价值在于通过分布式日志存储与一致性协议,解决了 NameNode 元数据同步的难题。在 HA 架构中,它既是 Active 节点的日志备份者,也是 Standby 节点的状态同步源,确保集群在主节点故障时能无缝切换,大幅提升了 HDFS 的可用性。部署时需注意节点数量(奇数)、硬件性能(低延迟磁盘与网络)及容错配置,以充分发挥其在高可用集群中的核心作用。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。