目录
虚拟内存和分页机制介绍
早期计算机系统的内存是比较小,不过相应的程序也是比较小的,这时程序可以直接加载到内存中运行,
后来为了支持多个程序的并行,内存中出现了固定分区,在编译阶段将不同程序,划分在不同的内存区域上
这种方式存在不少问题:
- 内存分区大小与程序大小要匹配,
- 是地址空间无法动态的增长
内存动态分区思想便诞生了,内存上线划出一块区域给操作系统,然后剩余的内存空间给用户进程使用,这样用户程序所使用的内存空间,跟随程序大小及数目进行变动
不论是静态分析,还是动态分区,都存在一些问题:
-
进程地址空间安全问题(地址空间不隔离)
-
内存使用效率低(不能动态回收或者交换)
-
虚拟内存技术的产生
为了能够让多程序安全、高效地并行运行,物理内存中需要存放多个程序的代码及数据,这时虚拟内存便诞生了,虚拟内存是一个伟大的发明,一方面它让每个程序认为自己是独自、连续的使用内存 ,
另一方面,每个程序之间的内存形成了安全隔离,避免程序破坏彼此的内存
后来随着软件的快速发展,一个程序的大小变得很大,这时物理内存大小跟不上程序大小增加的速度,
这样便不能将整个程序加载到物理内存中,一是物理内存没有这么大,二是如果将整个程序加载到内存,为了多程序并行,就需要将大量的数据及代码换入、换出,这导致程序运行效率低下
虚拟内存并没解决高效使用内存的问题,好在程序运行遵循时间、空间局部性原理,进而出现了分页机制
分页机制从根本上解决了高效使用物理内存的问题,每次只需要将几页的代码、数据从磁盘中加载到内存,程序就能正常运行
当程序运行的过程中,需要新的代码、数据会产生缺页异常,这些代码、数据就会从磁盘加载到内存,然后程序从异常恢复正常运行
- 分页机制的产生
对于支持虚拟内存,分页机制的系统,处理器直接寻址虚拟地址 ,这个地址不会直接发给内存控制器,而是先发给内存管理单元(Memory Manager Unit)
MMU 就是负责将虚拟地址转换和翻译成物理地址的一个硬件模块,其实 MMU 所做的事,完全可以通过 CPU 来实现,为啥还要一个 MMU 硬件模块呢?就是为了提升虚拟地址到物理地址转换的速度,减少转换所消耗的时间
MMU包含两个模块TLB(Translation Lookaside Buffer)和TWU(Table Walk Unit)
TLB 是一个高速缓存,用于缓存页表转换的结果,从而缩短页表查询的时间,TWU 是一个页表遍历模块,页表是由操作系统维护在物理内存中,但是页表的遍历查询是由 TWU 完成的,这样减少对 CPU资源的消耗
MMU 基本概念
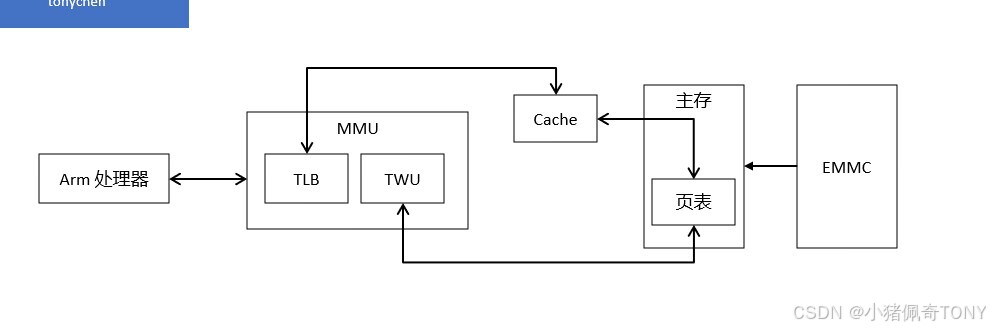
在 SMP(Symmetric Multi Process,对称多处理器)系统中,每个处理器内置了 MMU 模块 ,
MMU 模块包含了 TLB 和 TWU 两个子模块,TLB 是一个高速缓存,用于缓存虚拟地址到物理地址的转换结果
页表的查询过程是由 TWU 硬件自动完成的,但是页表的维护是需要操作系统实现的,页表存放在主存中
页表的查询是一个耗时的过程,理想情况下,TLB 命中,可以从中直接得到虚拟地址对应的物理地址
当 TLB 未命中的时候,MMU 才会通过 TWU 查询页表,从而翻译虚拟地址得到物理地址
得到物理地址后,首先要查询该物理地址的内容是否存在于 Cache 中,若 Cache 命中,则直接取出物理地址对应的内容返回给处理器
若 Cache 没有命中,会进一步访问主存获取相应的内容,然后回写到 Cache,并返回给处理器
如果没能在页表中查询到虚拟地址对应的物理地址,则会触发一个与 MMU 相关的缺页异常,
在异常处理的过程中,会将ROM 存储器中相关的数据加载到主存,然后建立相应的页表,然后将物理地址对应的内容返回给 Cache及处理器
虚拟地址基本概念
虚拟内存(Virtual Memory,VM):为每个进程提供了一致的、连续的、私有的内存空间,简化了内存管理
虚拟地址空间(Virtual Address Space,VAS):每个进程独有,每个进程占有的虚拟地址范围
虚拟页(Virtual Page,VP):把虚拟内存按照页表大小进行划分
虚拟地址(Virtual Address,VA):CPU 处理器实际使用的地址
虚拟页号(Virtual Page Number,VPN):用于定位页表的 PTE
物理地址基本概念
物理内存(Physical Memory,PM):主存上能够使用的物理空间
物理页(Physical Page):把物理内存按照页表的大小进行划分
物理地址(Physical Address,PA):物理内存划分很多块,通过物理内存进行定位
物理页号(Physical Page Number,PPN):定位物理内存中块的位置
页表基本概念
页表(Page Tabel):虚拟地址与物理地址映射表的集合(注意是一个映射的集合)
页全局目录(Page Global Directory,PGD):多级页表中的最高一级
页上级目录(Page Upper Directory,PUD):多级页表中的次高一级
页中间目录(Page Middle Directory,PMD):多级页表中的一级
页表条目(Page Table Entry,PTE):虚拟地址与独立地址具体对应的记录
说明: 页表时一个映射的集合,保存在内存中,规定了如何映射到物理地址
页表(Page Table) 是操作系统在物理内存(RAM)中分配的一段数据结构
它由一系列 页表项(Page Table Entry, PTE) 组成,每个 PTE 通常为 8 字节(在 64 位系统中)
每个 PTE 包含:
下一级页表或物理页的物理地址(高几位)
权限位(可读/可写/可执行)
是否有效(Valid)
是否被访问过(Accessed)
是否被修改过(Dirty)
是否是全局页(Global)
虽然页表在内存中,但 CPU 需要知道 从哪里开始查找,这就用到了寄存器:
在 x86-64 中:CR3 寄存器保存 顶层页表(如 PML4)的物理基地址
在 ARM64 中:TTBR0_EL1 和 TTBR1_EL1 寄存器分别保存 用户/内核顶层页表(L0)的物理基地址
TLB 是寄存器吗?
TLB(Translation Lookaside Buffer) 是 CPU 内部的高速缓存(Cache),用于缓存最近使用的 VA → PA 映射,
它不是通用寄存器,而是专用的关联存储器(CAM),属于 MMU 的一部分,TLB 的内容来源于页表,但本身不是页表
多节页表的映射过程
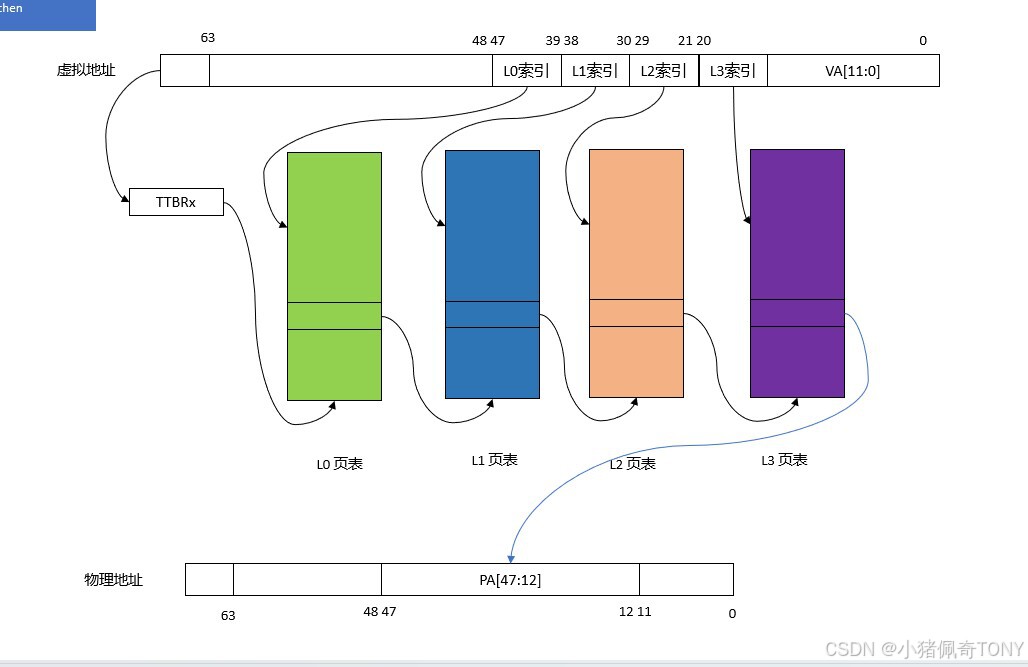
物理页面大小一级地址总线宽度不同,页表的级数也不同,以 AArch64运行状态,4KB 大小物理页面,48 位地址宽度为例,页表映射的查询过程如图:
对于多任务操作系统,每个用户进程都拥有独立的进程地址空间,也有相应的页表负责虚拟地址到物理地址之间的转换
MMU查询的过程中,用户进程的一级页表的基址存放在TTBR0
操作系统的内核空间公用一块地址空间,MMU 查询的过程中,内核空间的一级页表基址存放在TTBR1
当 TLB 未命中时,处理器查询页表的过程如下:
-
处理器根据虚拟地址第
63位,来选择使用TTBR0或者TTBR1,当VA[63]为0时,选择TTBR0,TTBR中存放着L0页表的基址 -
处理器以
VA[47:39]作为L0的索引,在L0页表中查找页表项,L0页表有512个页表项 -
L0页表的页表项中存放着L1页表的物理基址,处理器以VA[38:30]作为L1索引,在L1页表中找到相应的页表项,L1页表中有512个页表项 (L1中会存储L2页表的物理基址) -
L1页表的页表项中存放着L2页表的物理基址,处理器以VA[29:21]作为L2索引,在L2页表中找到相应的页表项,L2页表中有512个页表项 -
L2页表的页表项中存放着L3页表的物理基址,处理器以VA[20:12]作为L3索引,在L3页表中找到相应的页表项,L3页表中有512个页表项 -
L3页表的页表项里,存放着 4KB 页面的物理基址 ,然后加上VA[11:0],这样就构成了物理地址,至此处理器完成了一次虚拟地址到物理地址的查询与翻译的工作
简化的流程:
TLB 未命中 → 触发页表遍历(page table walk),
检查 VA63(更准确说是 VA63:48):
若为 0 → 使用 TTBR0_EL1(用户空间)
若为 1 → 使用 TTBR1_EL1(内核空间)
从 TTBR 拿到 L0 页表的物理基址,
用 VA47:39 索引 L0 → 得到 L1 基址
用 VA38:30 索引 L1 → 得到 L2 基址
用 VA29:21 索引 L2 → 得到 L3 基址
用 VA20:12 索引 L3 → 得到 4KB 页的物理基址
物理地址 = (L3 页表项中的物理页号 << 12) | VA11:0
现代 CPU 通常有 硬件页表遍历器(page walker),自动完成这个过程,无需软件干预
内核空间页表
即使在内核态(kernel mode),CPU 仍然运行在虚拟地址模式下
- 内核代码、数据、堆栈等都使用虚拟地址
- 所有内核空间的虚拟地址(包括直接映射区、vmalloc 区、内核代码段等)都必须通过
MMU+ 页表 转换为物理地址 - 内核本身在虚拟地址空间中,只是这个空间是所有进程共享的(在 x86_64 等架构中,高地址部分是内核空间)
内核页表存放位置
页表是内存中的页(通常是 4KB 对齐的,它们自己也必须能被 CPU 访问
因此,页表所在的物理页也被映射到内核的虚拟地址空间中(通常是直接映射区)
例如:pgd(页全局目录)可能位于物理地址 0x12345000,那么它的虚拟地址就是 PAGE_OFFSET + 0x12345000
进程页表和内核页表
内核的页表本质上是普通内存中的数据结构,由内核自己分配和管理
在支持进程隔离的系统中,每个进程有自己的一套页表(PGD)
但所有进程的内核空间页表项是相同的
也就是说:当进程 A 和进程 B 切换时,虽然用户空间页表不同,但内核空间的映射是复用的(或快速切换)
切换到内核态时,会自动加载页表吗
-
用户态 → 内核态(如系统调用、中断)
因为当前进程的页表 已经包含了内核空间的映射
当 CPU 陷入内核(例如执行 syscall),MMU 仍然使用当前进程的页表(即 CR3 寄存器未变)
内核可以直接访问其虚拟地址,因为页表中已经建立了从内核虚拟地址 → 物理地址的映射
-
进程切换(进程 A → 进程 B)
此时会切换页表:将
CR3寄存器更新为进程B的PGD(页全局目录)物理地址但新页表中同样包含完整的内核空间映射,所以内核代码依然可访问
-
内核页表初始化
启动早期(汇编阶段):
内核在 head.S 中建立临时页表(identity mapping + 直接映射,启用 MMU 后,跳转到 C 代码(此时已使用虚拟地址)
start_kernel() 阶段:
调用 paging_init()、zone_sizes_init() 等函数,建立完整的直接映射区、vmalloc 区、内核代码段等映射
为每个新创建的进程复制/共享内核页表部分