通常,在选择公司的过程中,我们往往会关注总收入(package)。总收入不仅包括基本的月薪,还包括奖金、股票或股份的分红等所有收入。然而,仅仅关注总收入可能会导致我们忽视一个关键因素:时薪。
时薪是指你在单位时间内所获得的报酬,它是衡量工作性价比的重要标准。总收入高并不一定意味着时薪高。比如,一家公司提供的总收入非常诱人,但如果工作时长超长,实际时薪可能并不理想。相反,一些时薪高的公司不仅可以提供不错的收入,还能保证员工的生活质量。
职级对标这个网站对各大公司的不同级别工程师的薪资进行了详细统计,这些数据不仅包含了年薪,还考虑了工作时长,从而计算出更为准确的时薪。我觉得这是一个非常不错的参考,值得分享一下!
下面是 2025 年初级工程师时薪排行榜:
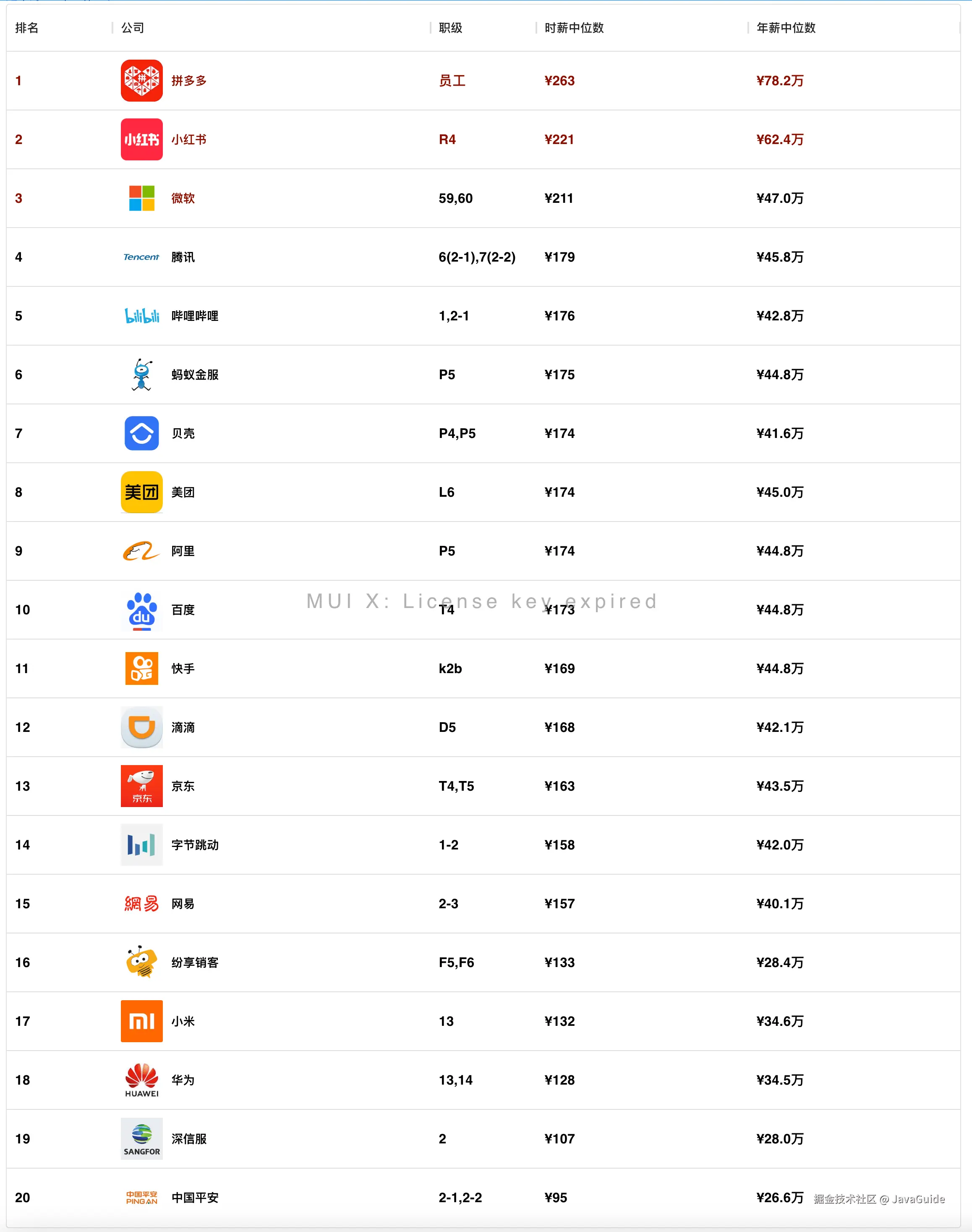
这是 2024 年的初级工程师时薪排行榜:
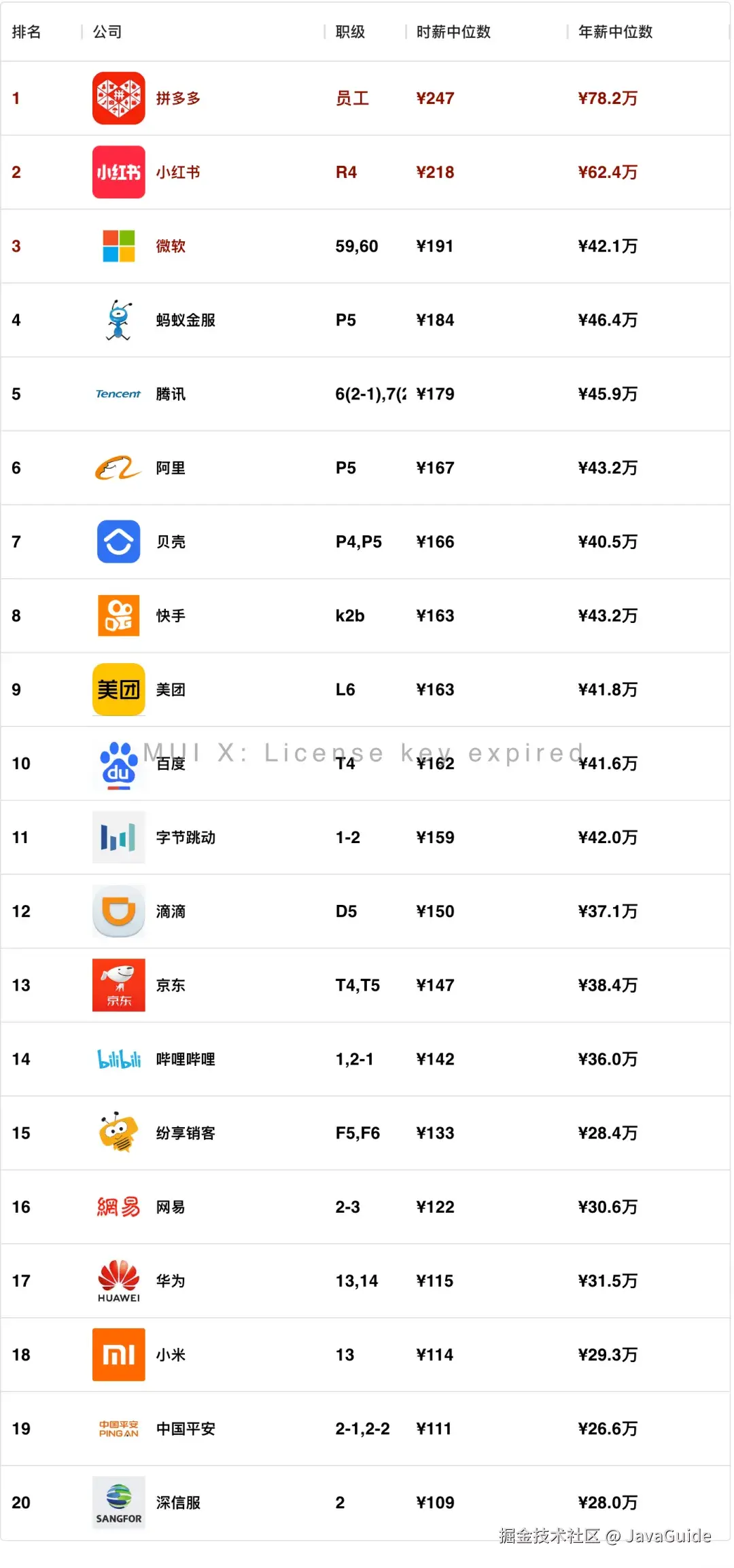
可以看到,PDD 、小红书、和微软还是比较稳定的,依然是前三,腾讯上了一名,蚂蚁金服掉了一名,哔哩哔哩从十四名上升到第五名了。
下面,给大家分享一篇 PDD 的社招三年经验面经,大家感受一下难度如何,题目来源于之前分享的这篇面经的一面:PDD 社招后端一二面,凉了。。。。
自我介绍
面试时的自我介绍,其实是你给面试官的"第一印象浓缩版"。它不需要面面俱到,但要精准、自信地展现你的核心价值和与岗位的匹配度。通常控制在 1-2 分钟内比较合适。一个好的自我介绍应该包含这几点要素:
- 用简单的话说清楚自己主要的技术栈于擅长的领域,例如 Java 后端开发、分布式系统开发;
- 把重点放在自己的优势上,重点突出自己的能力,最好能用一个简短的例子支撑,例如:我比较擅长定位和解决复杂问题。在某项目/实习中,我曾通过简述方法,如日志分析、源码追踪、压力测试成功解决了某个具体问题,如一个棘手的性能瓶颈/一个偶现的 Bug,将某个指标提升了百分比/具体数值。
- 简要提及 1-2 个最能体现你能力和与岗位要求匹配的项目经历、实习经历或竞赛成绩。不需要展开细节,目的是引出面试官后续的提问。
- 如果时间允许,可以非常简短地表达对所申请岗位的兴趣和对公司的向往,表明你是有备而来。
分布式缓存和本地缓存各自适用于哪些场景
本地缓存 (Local Cache): 缓存数据直接存储在应用进程的内存中。

- 实现方案:
ConcurrentHashMap, Guava Cache, Caffeine(推荐)、Ehcache 等。 - 优缺点:
- 优点: 访问速度极快,无网络开销,实现简单。
- 缺点: 缓存容量受限于单机内存;数据在多个应用实例间不共享,存在数据不一致的风险;应用重启后缓存数据丢失。
- 适用场景:
- 变化频率低、数据量小的热点数据: 如系统配置、数据字典、权限列表等。这些数据不常变动,但访问频繁,放在本地缓存可以极大提升性能。
- 单机环境: 不存在多个服务实例需要协同工作,共享状态。
分布式缓存 (Distributed Cache): 缓存数据存储在独立的、外部的缓存服务集群中,应用通过网络访问。
- 实现方案: Redis(推荐), Memcached,KeyDB、Dragonfly。
- 优缺点:
- 优点: 缓存容量可水平扩展,不受单机限制;所有应用实例共享同一份缓存数据,保证了数据的一致性;服务独立,不随应用重启而丢失数据。
- 缺点: 存在网络开销,访问速度低于本地缓存;需要维护独立的缓存集群,增加了系统复杂度和运维成本。
- 适用场景:
- 高频读写、数据量大的场景: 如用户信息、商品详情、会话(Session)等。
- 需要保证数据一致性的分布式环境: 多个服务实例需要协同工作,共享状态。
ThreadLocal 的应用场景有哪些?使用时注意什么?
ThreadLocal 的核心思想是用空间换时间,通过为每个线程创建独立的变量副本,来彻底避免多线程间的竞争和同步。它并不解决共享变量的并发问题,而是让变量不再共享。
ThreadLocal的典型应用场景如下:
- 在一次请求处理的调用链中传递上下文信息 :在一个 Web 请求中,用户的身份信息、请求的 TraceID 等需要在 Service 层、DAO 层等多个方法间传递。如果通过方法参数层层传递,会让代码变得非常冗长和耦合。使用
ThreadLocal可以将这些信息存入,在线程的任何一个执行点都能轻松获取,而无需修改方法签名。例如 Spring Security 使用SecurityContextHolder存储用户认证信息,其底层默认就是ThreadLocal。 - 管理线程独占的资源,避免频繁创建和销毁:比如管理数据库连接。在服务层开启事务后,后续所有数据库操作都必须使用同一个连接。通过 ThreadLocal 为当前线程保存这个连接,可以确保事务的完整性,并避免了连接被其他线程误用或关闭的问题。
在使用 ThreadLocal 时需要避免内存泄露问题的发生:
- 在使用完
ThreadLocal后,务必调用remove()方法。 这是最安全和最推荐的做法。remove()方法会从ThreadLocalMap中显式地移除对应的 entry,彻底解决内存泄漏的风险。 即使将ThreadLocal定义为static final,也强烈建议在每次使用后调用remove()。 - 在线程池等线程复用的场景下,使用
try-finally块可以确保即使发生异常,remove()方法也一定会被执行。
另外,由于 ThreadLocal 的变量值存放在 Thread 里,而父子线程属于不同的 Thread 的。因此在异步场景下,父子线程的 ThreadLocal 值无法进行传递。如果想要在异步场景下传递 ThreadLocal 值,有两种解决方案:
InheritableThreadLocal:InheritableThreadLocal是 JDK1.2 提供的工具,继承自ThreadLocal。使用InheritableThreadLocal时,会在创建子线程时,令子线程继承父线程中的ThreadLocal值,但是无法支持线程池场景下的ThreadLocal值传递。TransmittableThreadLocal:TransmittableThreadLocal(简称 TTL) 是阿里巴巴开源的工具类,继承并加强了InheritableThreadLocal类,可以在线程池的场景下支持ThreadLocal值传递。项目地址:github.com/alibaba/tra... 。
请描述一下你如何排查线上内存泄漏问题
我们可以通过 MAT、JVisualVM 等工具分析 Heap Dump 找到导致OutOfMemoryError 的原因。Heap Dump 可以通过 jmap、jcmd、Arthas、JVisualVM 等方式生成,这里就不细说了。
以 MAT 为例,其提供的泄漏嫌疑(Leak Suspects)报告是 MAT 最强大的功能之一。它会基于启发式算法自动分析整个堆,直接指出最可疑的内存泄漏点,并给出详细的报告,包括问题组件、累积点(Accumulation Point)和引用链的图示。
如果"泄漏嫌疑"报告不够明确,或者想要分析的是内存占用过高(而非泄漏)问题,可以切换到**支配树(Dominator Tree)**视图。这个视图将内存对象关系组织成一棵树,父节点"支配"子节点(即父节点被回收,子节点也必被回收)。
下面是一段模拟出现 OutOfMemoryError的代码:
java
import java.util.ArrayList;
import java.util.List;
public class SimpleLeak {
// 静态集合,生命周期与应用程序一样长
public static List<byte[]> staticList = new ArrayList<>();
public void leakMethod() {
// 每次调用都向静态集合中添加一个 1MB 的字节数组
staticList.add(new byte[1024 * 1024]); // 1MB
}
public static void main(String[] args) throws InterruptedException {
SimpleLeak leak = new SimpleLeak();
System.out.println("Starting leak simulation...");
// 循环添加对象,模拟内存泄漏过程
for (int i = 0; i < 200; i++) {
leak.leakMethod();
System.out.println("Added " + (i + 1) + " MB to the list.");
Thread.sleep(200); // 稍微延时,方便观察
}
System.out.println("Leak simulation finished. Keeping process alive for Heap Dump.");
// 保持进程存活,以便我们有时间生成 Heap Dump
Thread.sleep(Long.MAX_VALUE);
}
}为了更快让程序出现 OutOfMemoryError 问题,我们可以故意设置一个较小的堆 -Xmx256m。
IDEA 设置 VM 参数的方式如下图所示:
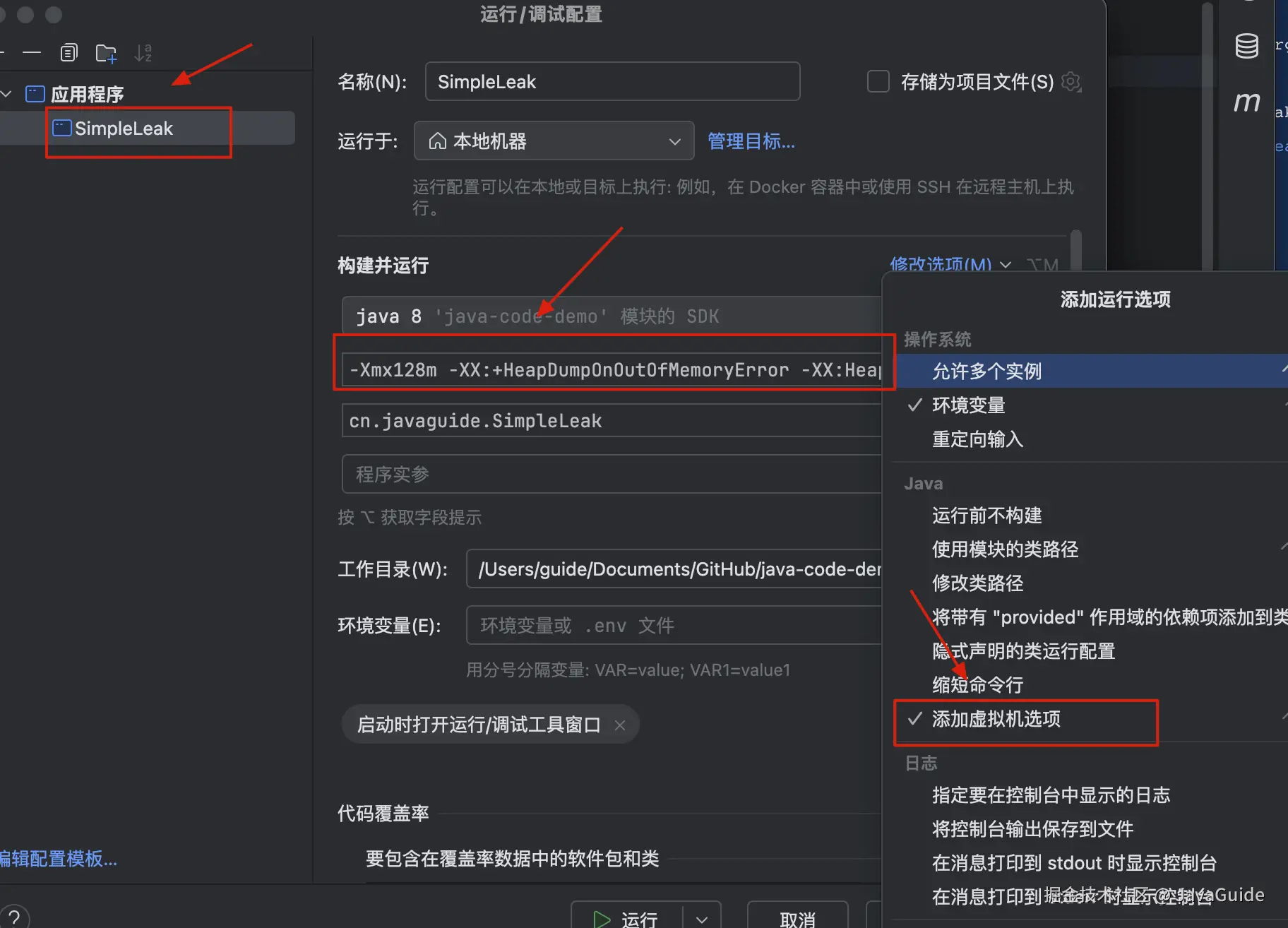
具体设置的 VM 参数是:-Xmx128m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=simple_leak.hprof,其中:
-Xmx128m:设置 JVM 最大堆内存为 128MB。-XX:+HeapDumpOnOutOfMemoryError:当 JVM 发生OutOfMemoryError时,自动生成堆转储文件(.hprof)。-XX:HeapDumpPath=simple_leak.hprof:指定 OOM 时生成的堆转储文件路径及文件名(这里是simple_leak.hprof)。
运行程序之后,会出现 OutOfMemoryError并自动生成了 Heap Dump 文件。
bash
Starting leak simulation...
Added 1 MB to the list.
Added 2 MB to the list.
Added 3 MB to the list.
......
Added 113 MB to the list.
Added 114 MB to the list.
Added 115 MB to the list.
java.lang.OutOfMemoryError: Java heap space
Dumping heap to simple_leak.hprof ...
Heap dump file created [124217346 bytes in 0.121 secs]我们将 .hprof 文件导入 MAT 后,它会首先进行解析和索引。完成后,可以查看它的 "泄漏嫌疑报告" (Leak Suspects Report)。
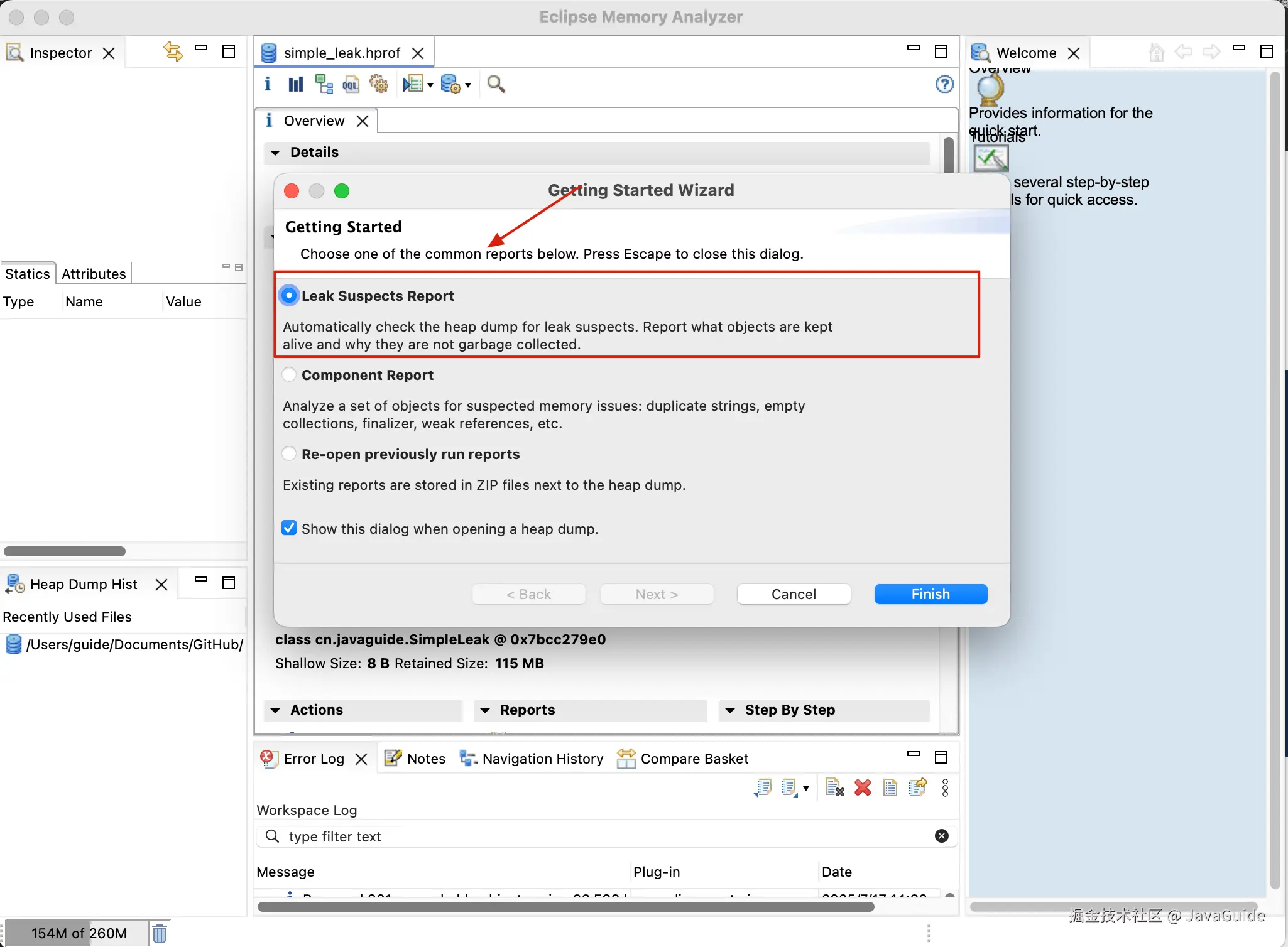
下图中的 Problem Suspect 1 就是可能出现内存泄露的问题分析:
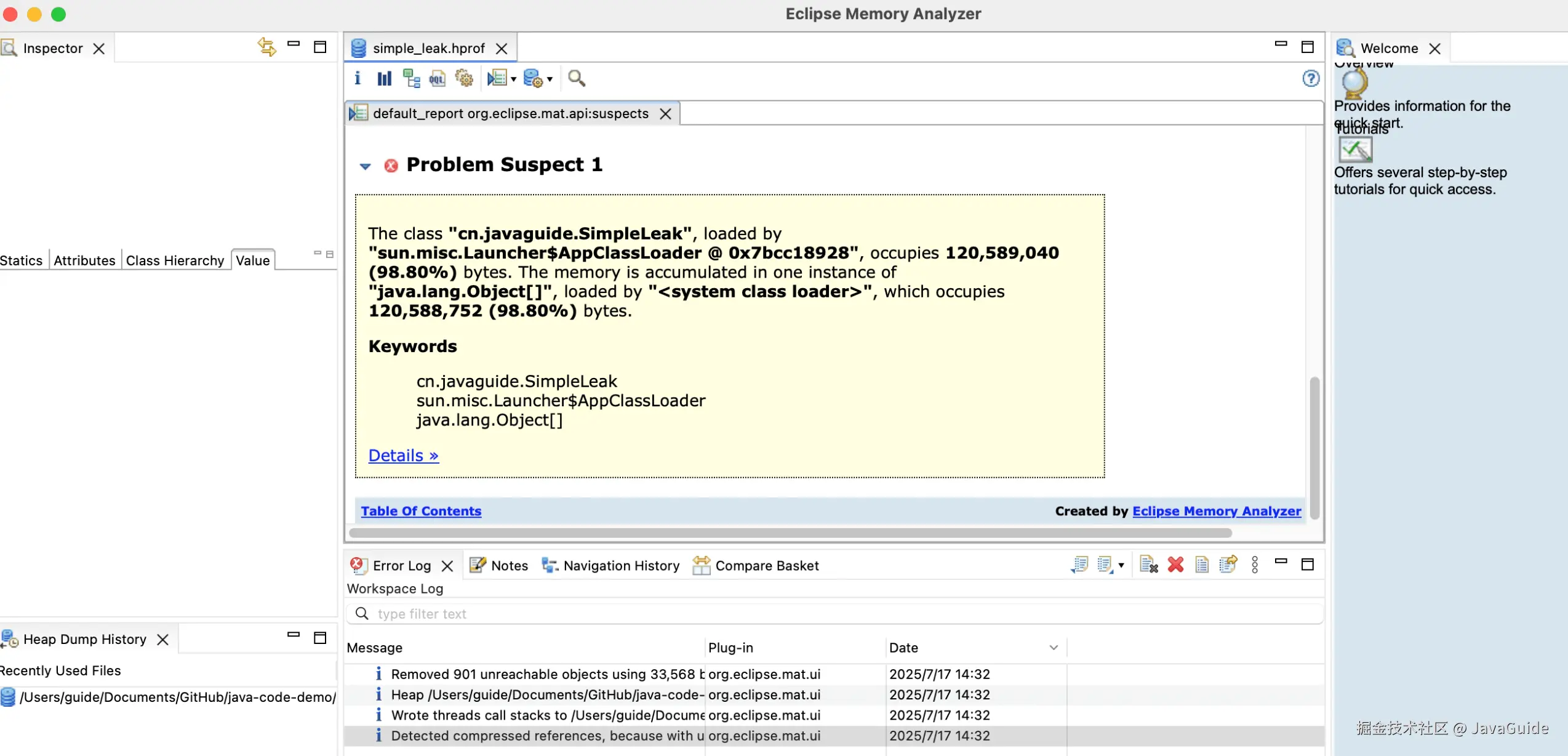
cn.javaguide.SimpleLeak类由sun.misc.Launcher$AppClassLoader加载,占用 120,589,040 字节(约 115MB,占堆 98.80%),是内存占用的核心。- 内存主要被
java.lang.Object[]数组 占用(120,588,752 字节),说明SimpleLeak中可能存在大量Object数组未释放,触发内存泄漏。
Problem Suspect 1 的可以看到有一个 Details,点进去即可看到内存泄漏的关键路径和对象占比:
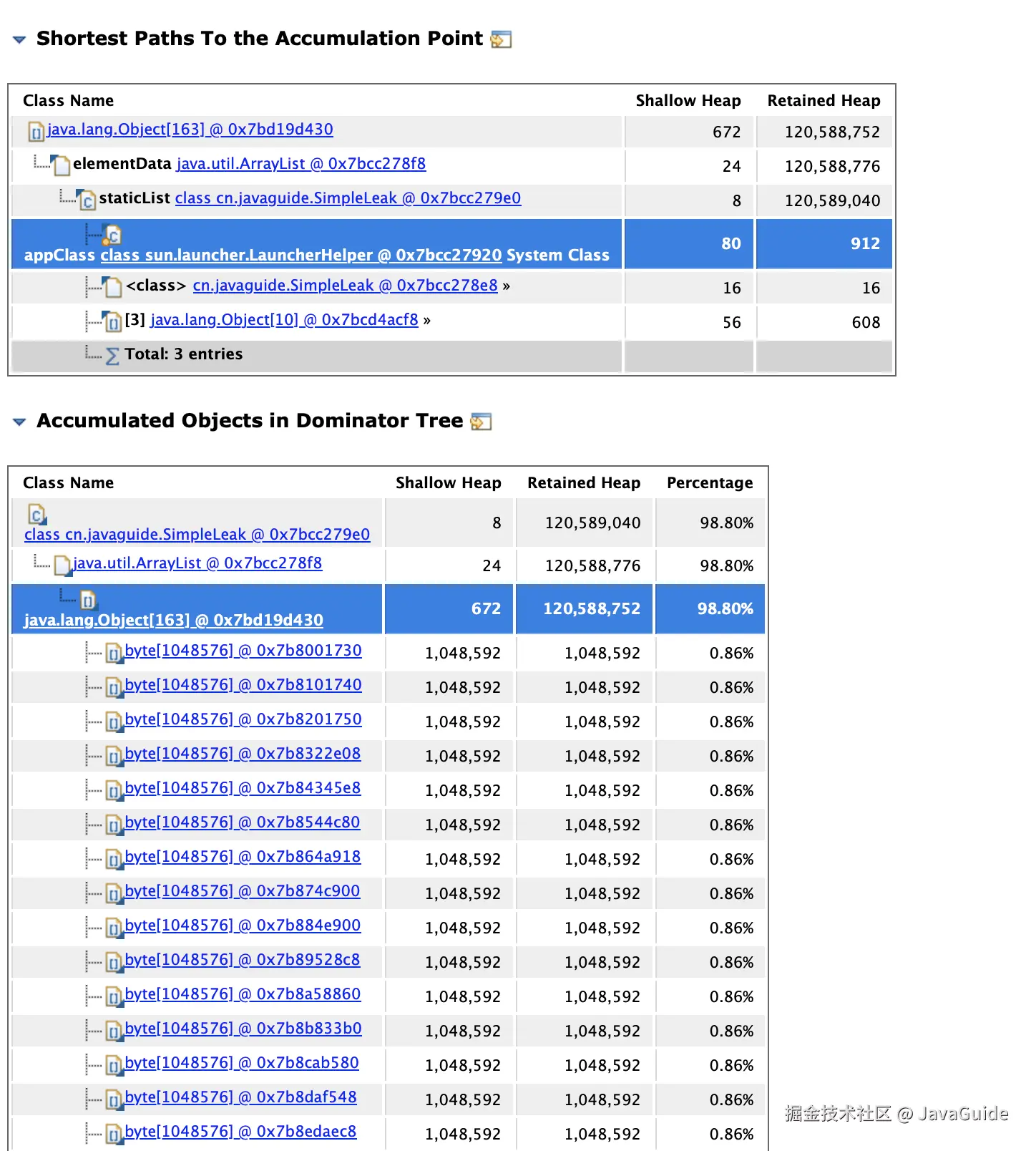
可以看到:SimpleLeak 中的静态集合 staticList 是内存泄漏的 "根源",因为静态变量生命周期与类一致,若持续向其中添加对象且不清理,会导致对象无法被 GC 回收。
我总结过 JVM 相关的高频面试题,其中包含了常见的问题排查案例,需要的朋友可以自取:后端面试 PDF 合集!
死锁问题怎么排查?
- 使用
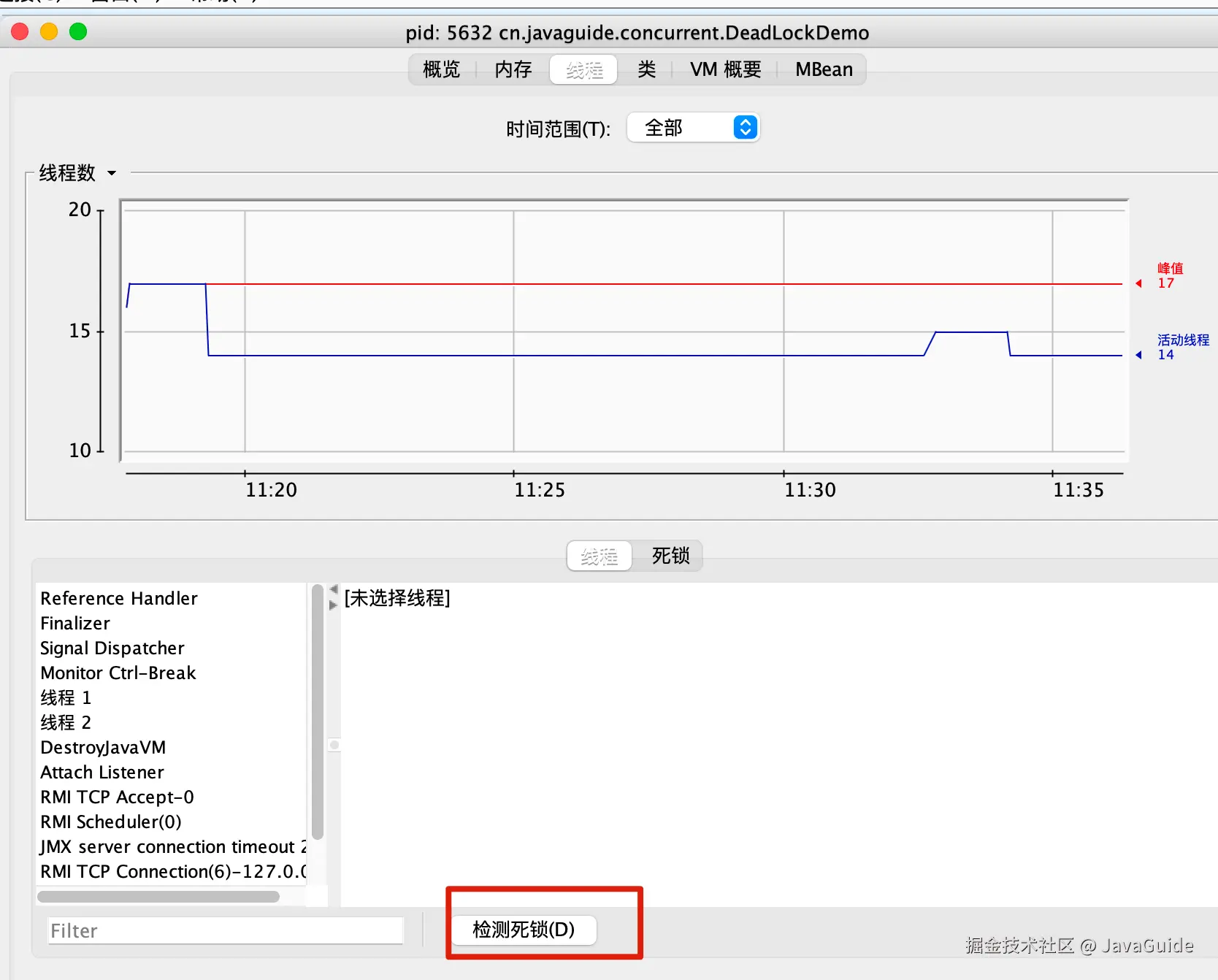
jmap、jstack等命令查看 JVM 线程栈和堆内存的情况。如果有死锁,jstack的输出中通常会有Found one Java-level deadlock:的字样,后面会跟着死锁相关的线程信息。另外,实际项目中还可以搭配使用top、df、free等命令查看操作系统的基本情况,出现死锁可能会导致 CPU、内存等资源消耗过高。 - 采用 VisualVM、JConsole 等工具进行排查。
这里以 JConsole 工具为例进行演示。
首先,我们要找到 JDK 的 bin 目录,找到 jconsole 并双击打开。
对于 MAC 用户来说,可以通过 /usr/libexec/java_home -V查看 JDK 安装目录,找到后通过 open . + 文件夹地址打开即可。例如,我本地的某个 JDK 的路径是:
bash
open . /Users/guide/Library/Java/JavaVirtualMachines/corretto-1.8.0_252/Contents/Home打开 jconsole 后,连接对应的程序,然后进入线程界面选择检测死锁即可!
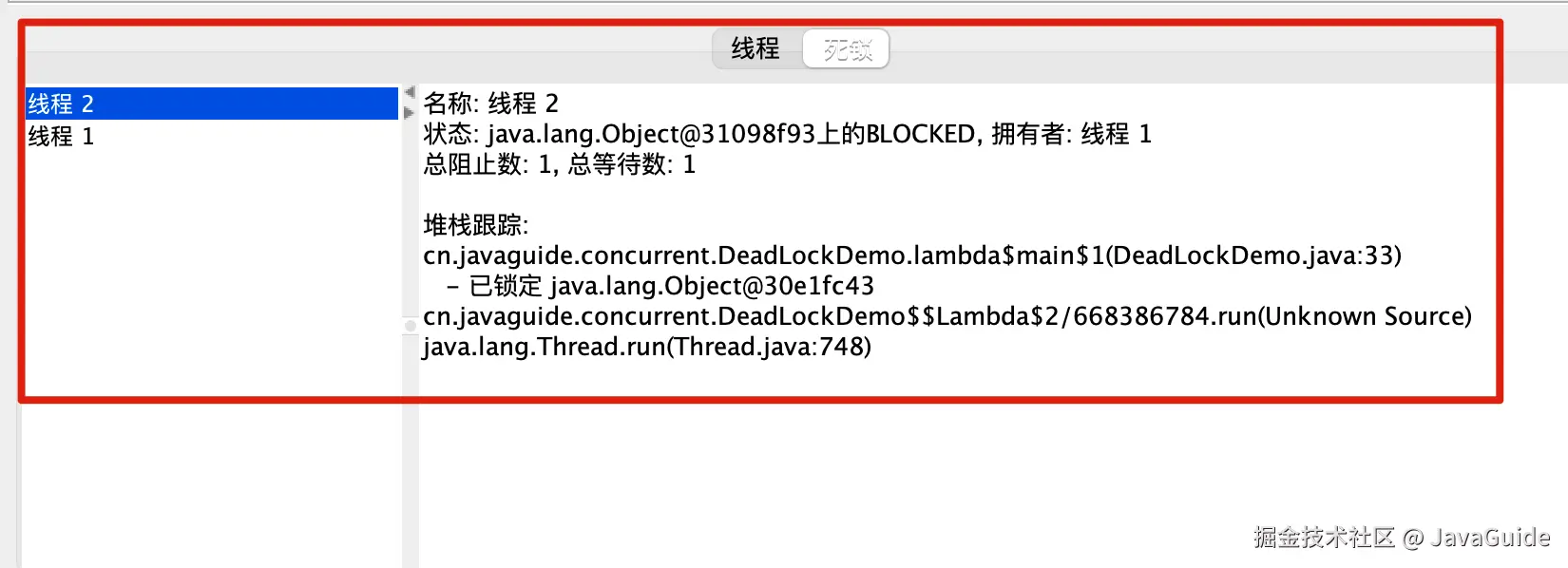
推荐阅读:Java 并发常见面试题总结(上)(多线程基础知识,例如线程和进程的概念、死锁) 。
请描述一下 Spring Bean 的完整生命周期
个人建议面试少问这种问题!
- 创建 Bean 的实例:Bean 容器首先会找到配置文件中的 Bean 定义,然后使用 Java 反射 API 来创建 Bean 的实例。
- Bean 属性赋值/填充 :为 Bean 设置相关属性和依赖,例如
@Autowired等注解注入的对象、@Value注入的值、setter方法或构造函数注入依赖和值、@Resource注入的各种资源。 - Bean 初始化 :
- 如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 如果 Bean 实现了
BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。 - 与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法 - 如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果 Bean 在配置文件中的定义包含
init-method属性,执行指定的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法。
- 如果 Bean 实现了
- 销毁 Bean :销毁并不是说要立马把 Bean 给销毁掉,而是把 Bean 的销毁方法先记录下来,将来需要销毁 Bean 或者销毁容器的时候,就调用这些方法去释放 Bean 所持有的资源。
- 如果 Bean 实现了
DisposableBean接口,执行destroy()方法。 - 如果 Bean 在配置文件中的定义包含
destroy-method属性,执行指定的 Bean 销毁方法。或者,也可以直接通过@PreDestroy注解标记 Bean 销毁之前执行的方法。
- 如果 Bean 实现了
AbstractAutowireCapableBeanFactory 的 doCreateBean() 方法中能看到依次执行了这 4 个阶段:
java
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 1. 创建 Bean 的实例
BeanWrapper instanceWrapper = null;
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object exposedObject = bean;
try {
// 2. Bean 属性赋值/填充
populateBean(beanName, mbd, instanceWrapper);
// 3. Bean 初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
// 4. 销毁 Bean-注册回调接口
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
return exposedObject;
}Aware 接口能让 Bean 能拿到 Spring 容器资源。
Spring 中提供的 Aware 接口主要有:
BeanNameAware:注入当前 bean 对应 beanName;BeanClassLoaderAware:注入加载当前 bean 的 ClassLoader;BeanFactoryAware:注入当前BeanFactory容器的引用。
BeanPostProcessor 接口是 Spring 为修改 Bean 提供的强大扩展点。
java
public interface BeanPostProcessor {
// 初始化前置处理
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
// 初始化后置处理
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}postProcessBeforeInitialization:Bean 实例化、属性注入完成后,InitializingBean#afterPropertiesSet方法以及自定义的init-method方法之前执行;postProcessAfterInitialization:类似于上面,不过是在InitializingBean#afterPropertiesSet方法以及自定义的init-method方法之后执行。
InitializingBean 和 init-method 是 Spring 为 Bean 初始化提供的扩展点。
java
public interface InitializingBean {
// 初始化逻辑
void afterPropertiesSet() throws Exception;
}指定 init-method 方法,指定初始化方法:
xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="demo" class="com.chaycao.Demo" init-method="init()"/>
</beans>如何记忆呢?
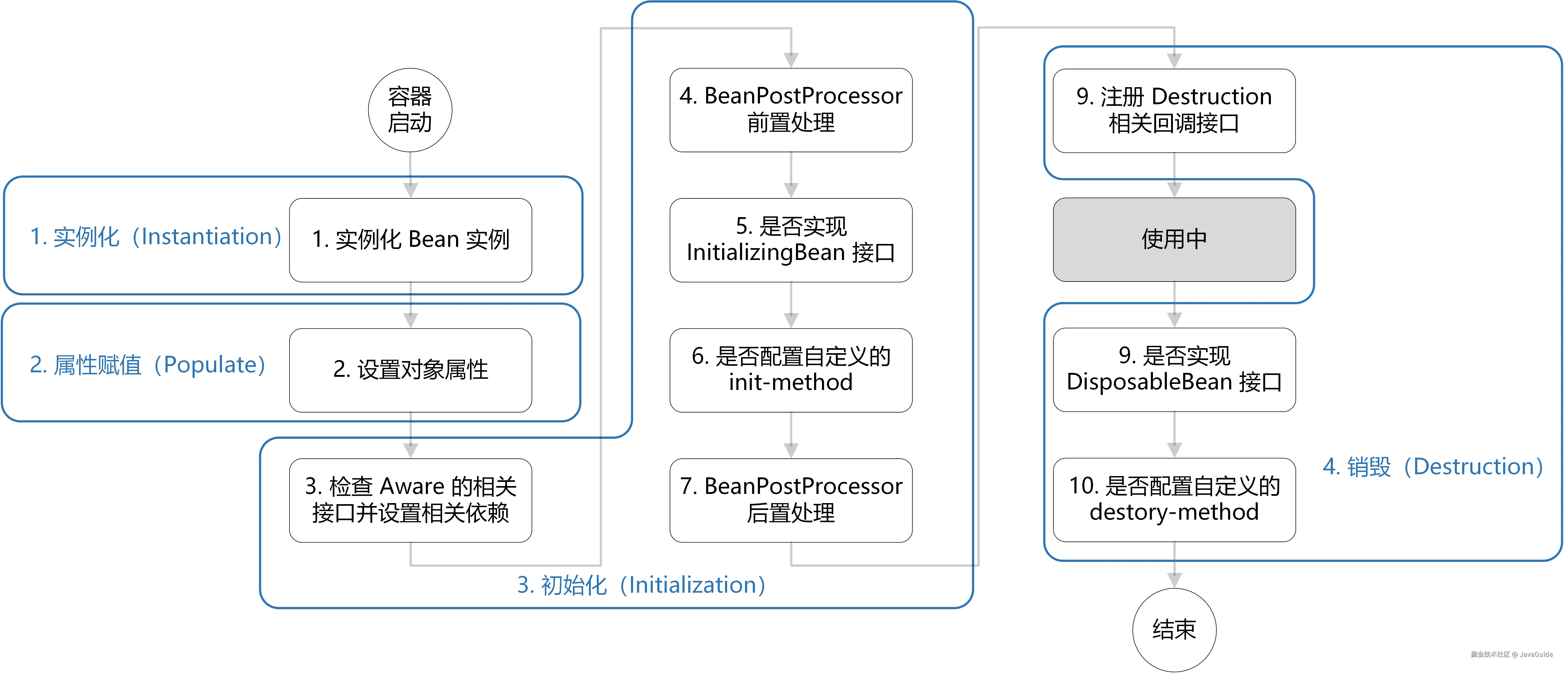
- 整体上可以简单分为四步:实例化 ---> 属性赋值 ---> 初始化 ---> 销毁。
- 初始化这一步涉及到的步骤比较多,包含
Aware接口的依赖注入、BeanPostProcessor在初始化前后的处理以及InitializingBean和init-method的初始化操作。 - 销毁这一步会注册相关销毁回调接口,最后通过
DisposableBean和destory-method进行销毁。
最后,再分享一张清晰的图解(图源:如何记忆 Spring Bean 的生命周期)。
Spring AOP 的底层实现原理?你在项目中是如何应用 AOP 的?
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy ,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
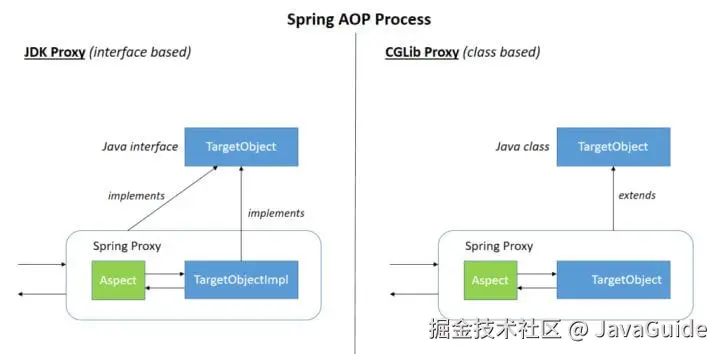
AOP 的应用场景如下:
- 日志记录:自定义日志记录注解,利用 AOP,一行代码即可实现日志记录。
- 性能统计:利用 AOP 在目标方法的执行前后统计方法的执行时间,方便优化和分析。
- 事务管理:
@Transactional注解可以让 Spring 为我们进行事务管理比如回滚异常操作,免去了重复的事务管理逻辑。@Transactional注解就是基于 AOP 实现的。 - 权限控制:利用 AOP 在目标方法执行前判断用户是否具备所需要的权限,如果具备,就执行目标方法,否则就不执行。例如,SpringSecurity 利用
@PreAuthorize注解一行代码即可自定义权限校验。 - 接口限流:利用 AOP 在目标方法执行前通过具体的限流算法和实现对请求进行限流处理。
- 缓存管理:利用 AOP 在目标方法执行前后进行缓存的读取和更新。
- ......
更多 Spring 面试题总结可以参考笔者写的这篇文章:Spring 常见面试题总结(Spring 基础、IoC、AOP、MVC、事务、循环依赖等)
如何实现分布式锁?
通过 Redis 来做分布式锁是一种比较常见的方式。
建议使用 Reedisson 内置的分布式锁。Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,不仅仅包括多种分布式锁的实现。并且,Redisson 还支持 Redis 单机、Redis Sentinel 、Redis Cluster 等多种部署架构。
Redisson 中的分布式锁自带自动续期机制,使用起来非常简单,原理也比较简单,其提供了一个专门用来监控和续期锁的 Watch Dog( 看门狗),如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放。
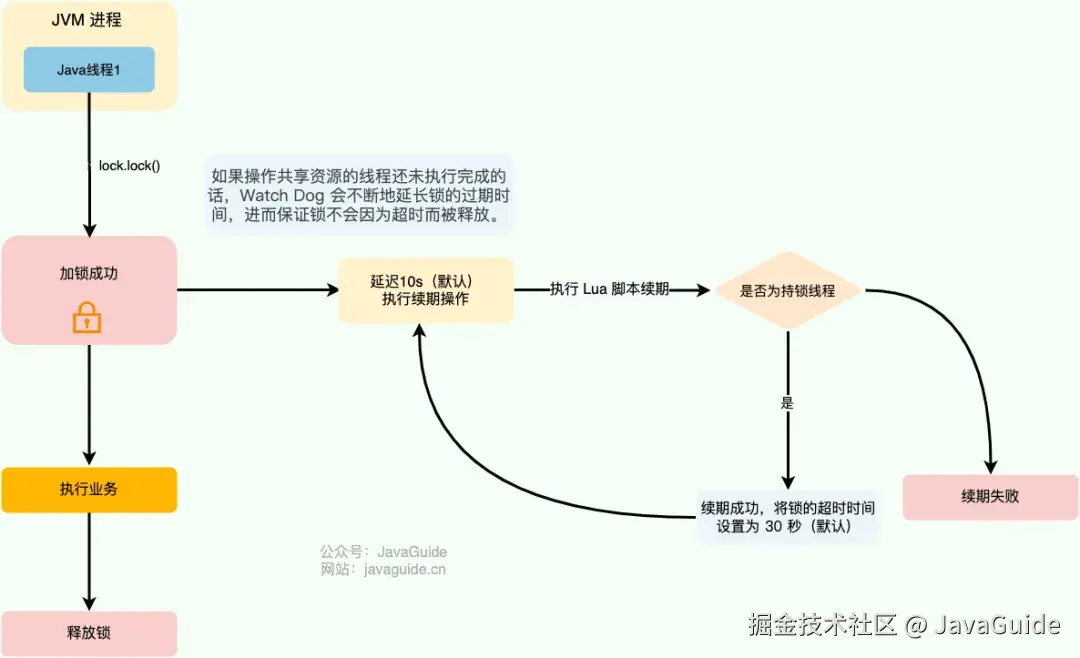
详细介绍可以参考我写的这两篇文章: