目录
[1.2MultiStepLR(多间隔调整学习率)](#1.2MultiStepLR(多间隔调整学习率))
[1.3 ExponentialLR (指数衰减调整学习率)](#1.3 ExponentialLR (指数衰减调整学习率))
1.4CosineAnnealing (余弦退火函数调整学习率)
2.1ReduceLROnPlateau (根据指标调整学习率)
[1. 导入必要的库](#1. 导入必要的库)
[2. 数据预处理部分](#2. 数据预处理部分)
[3. 自定义数据集类](#3. 自定义数据集类)
[4. 数据加载器](#4. 数据加载器)
[5. 设备配置](#5. 设备配置)
[6. 定义 CNN 模型](#6. 定义 CNN 模型)
[7. 训练函数](#7. 训练函数)
[8. 测试函数](#8. 测试函数)
[9. 训练配置和执行](#9. 训练配置和执行)
简介
之前我们对数据进行增强、有保存和使用最佳模型,今天我们再对模型进行最后的优化,就是调整我们的学习率,在这之前我们一直使用的是固定的学习率来训练模型。
深度学习之第五课卷积神经网络 (CNN)如何训练自己的数据集(食物分类)
深度学习之第六课卷积神经网络 (CNN)如何保存和使用最优模型
一、调整学习率
Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。并提供3种调整方法:
(1)**有序调整:**等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
(2)**自适应调整:**依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化时,就是调整学习率的时机(ReduceLROnPlateau); (
(3)**自定义调整:**通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
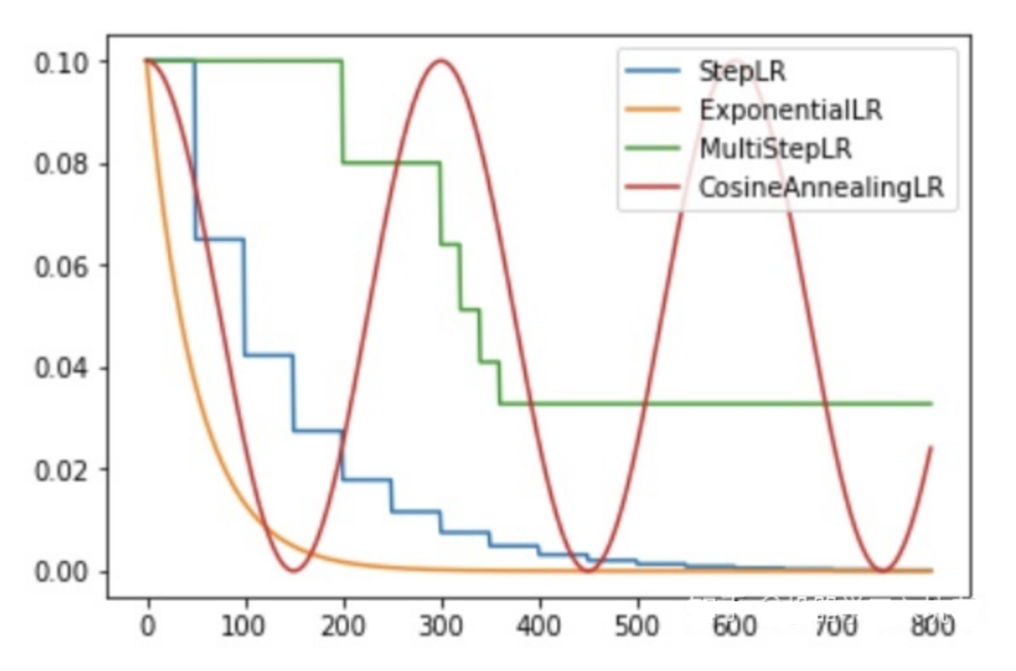
1.有序调整学习率
1.1StepLR(等间隔调整学习率)
python
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)参数:
optimizer: 神经网络训练中使用的优化器,如optimizer=torch.optim.Adam(...)
step_size(int): 学习率下降间隔数,单位是epoch,而不是iteration.
gamma(float):学习率调整倍数,默认为0.1 每训练step_size个epoch,学习率调整为lr=lr*gamma.
1.2MultiStepLR(多间隔调整学习率)
python
torch.optim.lr_shceduler.MultiStepLR(optimizer, milestones, gamma=0.1)参数:
milestone(list): 一个列表参数,表示多个学习率需要调整的epoch值,如milestones=10, 30, 80.
1.3 ExponentialLR (指数衰减调整学习率)
python
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma)参数:
gamma(float):学习率调整倍数的底数,指数为epoch,初始值我lr, 倍数为
1.4CosineAnnealing (余弦退火函数调整学习率)
python
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)参数:
Tmax(int):学习率下降到最小值时的epoch数,即当epoch=T_max时,学习率下降到余弦函数最小值,当epoch>T_max时,学习率将增大;
etamin: 学习率调整的最小值,即epoch=Tmax时,lrmin=etamin, 默认为0.
2.自适应调整
2.1ReduceLROnPlateau (根据指标调整学习率)
python
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1,
patience=10,verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)3.自定义调整
3.1LambdaLR (自定义调整学习率)
python
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)参数:
lr_lambda(function or list): 自定义计算学习率调整倍数的函数,通常时epoch的函数,当有多个参数组时,设为list.
二、代码分析
1. 导入必要的库
python
import torch
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from torchvision import transforms # 对数据进行处理
import numpy as np
from torch import nn- 导入 PyTorch 框架及其数据加载、神经网络模块
- 导入 PIL 库用于图像处理
- 导入 numpy 用于数值计算
2. 数据预处理部分
python
data_transforms = { # 字典,存储不同数据集的预处理方式
'train':
transforms.Compose([ # 组合多个变换
transforms.Resize([300, 300]), # 图像变换大小
transforms.RandomRotation(45), # 图片旋转,45度到-45度之间随机旋转
transforms.CenterCrop(256), # 从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转,概率0.5
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转,概率0.5
transforms.ToTensor(), # 数据转换成Tensor
transforms.Normalize([0.485, 0.456, 0.486], [0.229, 0.224, 0.225]) # 归一化
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.486], [0.229, 0.224, 0.225])
]),
}- 定义了训练集和验证集的不同数据增强和预处理方式
- 训练集使用了更多的数据增强技术(旋转、翻转等)来提高模型泛化能力
- 所有图像最终都转换为 Tensor 并进行归一化
3. 自定义数据集类
python
class food_dataset(Dataset): # 继承Dataset类
def __init__(self, file_path, transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(file_path, 'r') as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self): # 类实例化对象后,可以使用len函数测量对象的个数
return len(self.imgs)
def __getitem__(self, idx):
image = Image.open(self.imgs[idx]) # 读取图像
if self.transform: # 应用预处理
image = self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label, dtype=np.int64))
return image, label- 自定义数据集类,继承自 PyTorch 的 Dataset
__init__方法:从文件中读取图像路径和对应标签__len__方法:返回数据集大小__getitem__方法:根据索引返回图像和对应的标签
4. 数据加载器
python
train_data = food_dataset(file_path='train.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='test.txt', transform=data_transforms['valid'])
train_dataloader = DataLoader(train_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32, shuffle=True)- 创建训练集和测试集的数据集实例
- 使用 DataLoader 将数据集包装成可迭代的批量数据加载器
- 设置 batch_size 为 32,训练集打乱顺序
5. 设备配置
python
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using{device},device")6. 定义 CNN 模型
python
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 第一个卷积块
nn.Conv2d(in_channels=3, # 输入通道数(RGB图像)
out_channels=32, # 输出通道数
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2), # 填充
nn.ReLU(), # 激活函数
nn.MaxPool2d(2) # 最大池化
)
self.conv2 = nn.Sequential( # 第二个卷积块
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(64, 64, 5, 1, 2),
nn.MaxPool2d(2)
)
self.conv3 = nn.Sequential( # 第三个卷积块
nn.Conv2d(64, 128, 5, 1, 2),
nn.ReLU()
)
self.out = nn.Linear(128 * 64 * 64, 20) # 全连接层,输出20类
def forward(self, x): # 前向传播
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # 展平
output = self.out(x)
return output- 定义了一个包含 3 个卷积块的 CNN 模型
- 每个卷积块包含卷积层、激活函数,部分包含池化层
- 最后通过全连接层输出 20 个类别的预测结果
7. 训练函数
python
def train(dataloader, model, loss_fn, optimizer): # 训练函数
model.train() # 切换训练模式
batch_size_num = 1
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 数据移到设备上
pred = model.forward(X) # 前向传播
loss = loss_fn(pred, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
loss = loss.item()
if batch_size_num % 64 == 0: # 每64个批次打印一次损失
print(f"loss:{loss:>7f} [number:{batch_size_num}]")
batch_size_num += 1- 实现模型的训练逻辑
- 包含前向传播、损失计算、反向传播和参数更新
- 定期打印训练损失
8. 测试函数
python
best_acc = 0 # 最佳准确率初始化
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # 切换评估模式
test_loss, correct = 0, 0
with torch.no_grad(): # 禁用梯度计算
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches # 计算平均损失
correct /= size # 计算准确率
print(f"Test resilt:\n Accuracy:{(100*correct)}%,Avg loss:{test_loss}")
# 保存最优模型
global best_acc
if correct > best_acc:
best_acc = correct
torch.save(model, 'best2.pt') # 保存整个模型
return test_loss- 实现模型的测试 / 验证逻辑
- 计算测试集上的损失和准确率
- 保存准确率最高的模型
9. 训练配置和执行
python
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau( # 学习率调度器
optimizer,
mode='max', # 模式为最大化准确率
factor=0.5, # 学习率调整因子
patience=5 # 多少个epoch无改善后调整学习率
)
epochs = 50 # 训练轮数
acc_s = []
loss_s = []
for t in range(epochs):
print(f"Epoch{t+1}\n...............")
train(train_dataloader, model, loss_fn, optimizer) # 训练
val_loss = test(test_dataloader, model, loss_fn) # 测试
scheduler.step(val_loss) # 调整学习率
print("Done!")- 定义损失函数、优化器和学习率调度器
- 执行 50 个 epoch 的训练和测试循环
- 每个 epoch 后根据验证损失调整学习率
最以可以发现我们的准确率得到一些提升,还是那句话,这些都是提升模型的方法,我使用的只是我自己简单搭建的几层模型,主要是像让你们掌握这些提升模型的方法