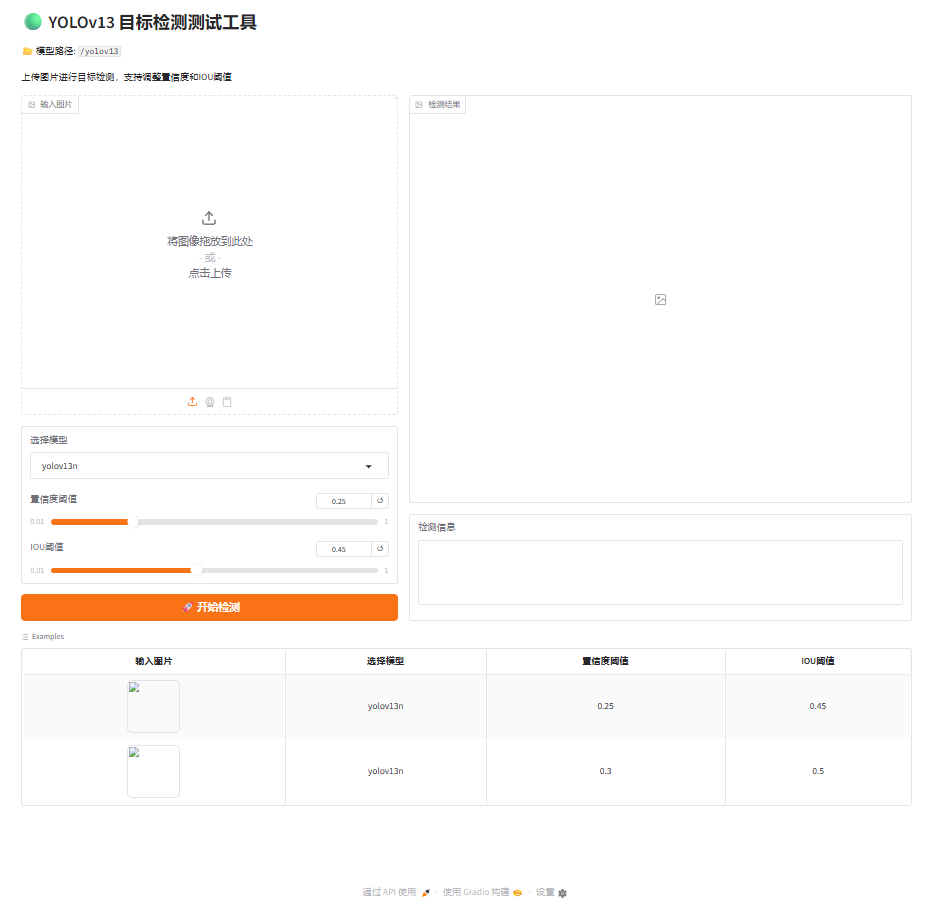
一、介绍
YOLOv13 隆重推出 ------新一代实时检测器,拥有尖端的性能和效率。YOLOv13 系列包含四个版本:Nano、Small、Large 和 X-Large,并由以下技术提供支持:
- HyperACE:基于超图的自适应相关增强
- 将多尺度特征图中的像素视为超图顶点。
- 采用可学习的超边构造模块,自适应地探索顶点之间的高阶相关性。
- 利用线性复杂度的消息传递模块,在高阶相关的指导下有效地聚合多尺度特征,实现对复杂场景的有效视觉感知。
- FullPAD:全管道聚合和分发范例
- 使用 HyperACE 聚合主干的多尺度特征并提取超图空间中的高阶相关性。
- FullPAD 范式进一步利用三个独立的隧道,将这些相关性增强的特征分别转发到骨干与颈部的连接、颈部内部层以及颈部与头部的连接。通过这种方式,YOLOv13 实现了整个流程的细粒度信息流和表征协同。
- FullPAD 显著改善了梯度传播并提高了检测性能。
- 通过基于 DS 的块实现模型轻量化
- 用基于深度可分离卷积(DSConv、DS-Bottleneck、DS-C3k、DS-C3k2)的块构建取代大核卷积,在保留感受野的同时,大大减少参数和计算量。
- 在不牺牲准确性的情况下实现更快的推理速度。
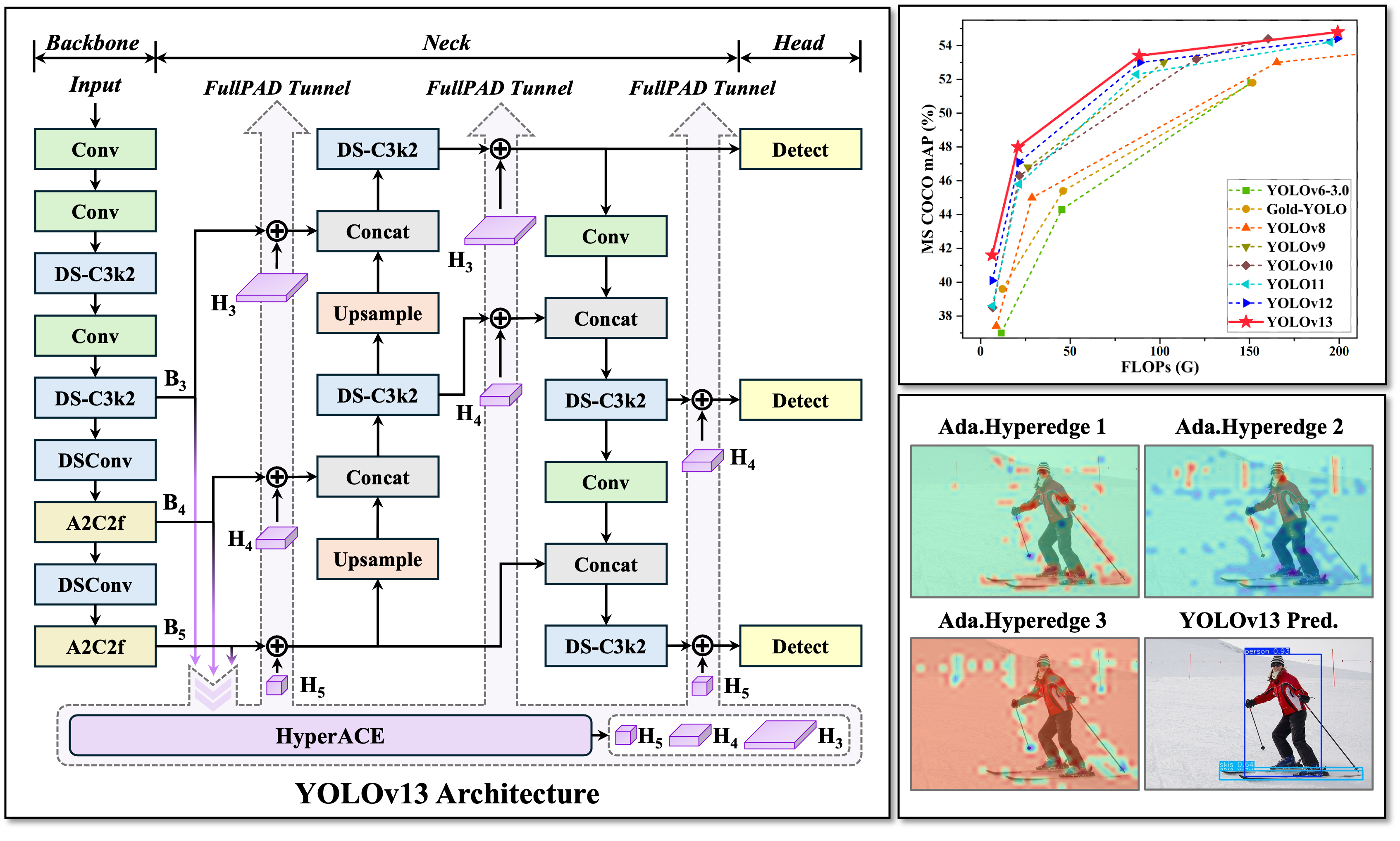
二、部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04.5 LTS |
| python | 3.11 |
| Cuda | 12.4.1 |
| NVIDIA Corporation | 3060 |
1. 构建基础镜像 Miniconda-Ubuntu-22.04-cuda12.1.1
2.创建虚拟环境
conda create -n yolov13 python=3.11 -y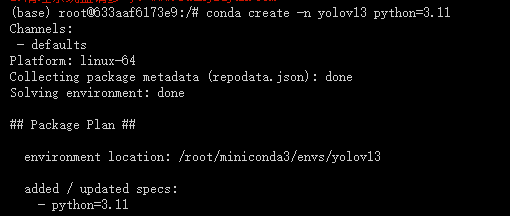
3.从github上克隆项目:
git clone https://github.com/iMoonLab/yolov13.git
4.安装环境依赖
conda activate yolov13
cd yolov13
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
pip install -r requirements.txt
pip install -e .
5.下载预训练权重
wget https://github.com/iMoonLab/yolov13/releases/download/yolov13/yolov13n.pt6.验证
YOLOv13-N YOLOv13-S YOLOv13-L YOLOv13-X
使用以下代码在 COCO 数据集上验证 YOLOv13 模型。请务必将其替换 {n/s/l/x} 为所需的模型规模(nano、small、plus 或 ultra)。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale7.训练
使用以下代码训练 YOLOv13 模型。请确保将 替换 yolov13n.yaml 为所需的模型配置文件路径,并将其 coco.yaml 替换为你的 Coco 数据集配置文件。
from ultralytics import YOLO
model = YOLO('yolov13n.yaml')
# Train the model
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; L:0.5; X:0.6
device="0,1,2,3",
)
# Evaluate model performance on the validation set
metrics = model.val('coco.yaml')
# Perform object detection on an image
results = model("path/to/your/image.jpg")
results[0].show()8.预测
使用以下代码,使用 YOLOv13 模型执行对象检测。请确保将其替换 {n/s/l/x} 为所需的模型比例。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale
model.predict()9. 导出
使用以下代码将 YOLOv13 模型导出为 ONNX 或 TensorRT 格式。请确保将其替换 {n/s/l/x} 为所需的模型比例。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale
model.export(format="engine", half=True) # or format="onnx"10.测试界面demo
启动app_demo.py文件
python app_demo.py