到目前为止,我们已经探讨了如何构建功能强大的单智能体系统------这些智能体借助工具、知识、记忆与编排层来解决复杂任务。经过正确配置后,它们能够调用广泛的知识与集成,独立行动,表现出很强的能力。不过,当我们超越"单个智能体"时,智能体系统的真正潜力才会逐步展开。
正如人类依赖由不同角色与专长组成的团队,AI 系统也能从多个智能体协同工作中获益匪浅------每个智能体都有自己的专长、视角或职能。
本章将探讨智能体如何通信、协调与协作,以完成单个智能体难以(甚至无法)独立完成的任务。我们将涵盖以下主题:
- 多智能体系统简介
- 理解并设计你的多智能体系统的不同工作流
- 多智能体编排器概览
- 使用 LangGraph 构建你的第一个多智能体应用
读完本章后,你将清楚地了解,如何架构并上线多智能体 AI 应用来应对你的特定用例。
技术要求
本章的全部代码与所需依赖列在本书官方 GitHub 仓库的 requirements.txt 中:github.com/PacktPublis...。
要完成环境搭建,只需克隆仓库并运行以下命令安装依赖:
pip install -r requirements.txt这样即可获得随本章动手示例所需的全部库与工具。
多智能体系统简介
正如前几章所示,单个 AI 智能体通常会配备诸如 Web API、数据库、Web 服务等工具。这些工具把智能体的能力从单纯文本生成扩展到与外界交互、执行以目标为导向的任务。例如,在上一章中,我们展示了一个意大利餐馆的 AI 智能体如何对接后端库存数据库、从向量数据库检索相关洞见,甚至执行将商品加入用户购物车等动作。
但如果我们再进一步呢?
正如单个智能体可以调用一个工具 ,智能体也可以调用另一个智能体 。事实上,从更高层智能体的视角看,只要为"被调用的智能体"提供能力的自然语言描述 ,它就等同于一个工具。由此产生了多智能体系统:多个智能体相互通信与协作,每个智能体为更大的系统贡献一种专门能力。
举个例子:设想一个简单的 AI 系统,其中一个 Python 函数用于从 Google 日历等在线服务获取用户的日程事件。这个函数接收特定参数(如日期或事件 ID),并按要求返回结果,仅此而已。
而在多智能体系统中,同样的日历功能可以由一个专业化的**"Calendar Agent(日历智能体)"**承担。这个智能体将超越基础的数据检索,它可以:
- 理解含糊查询,如"我下一次空闲的下午是何时? "
- 识别并解决日程冲突(例如两个会议重叠)
- 与其他智能体协商变更------比如提出所有参与者都合适的新会议时间
这种从简单函数 到智能智能体的转变,展现了多智能体系统如何把更丰富的推理、灵活性与自治性带入原本基础的任务。
为什么要这么做?难道一个简单工具不行吗?就这个简单例子而言,简短答案是:可以 。然而,在某些场景下,你也许更希望拥有一个高度专业化的智能体 而非工具,以便给它明确的系统消息并进一步扩展其能力。而且,同一个 Calendar Agent 还可以在不同流程与应用中复用,成为组织内可重复使用的组件。
再看一个更复杂的例子:我们希望启用一个 AI 应用,帮助你跨多家商店 进行网购。一个典型查询可能是:"购买 XYW 的新款鞋,欧码 39。 " 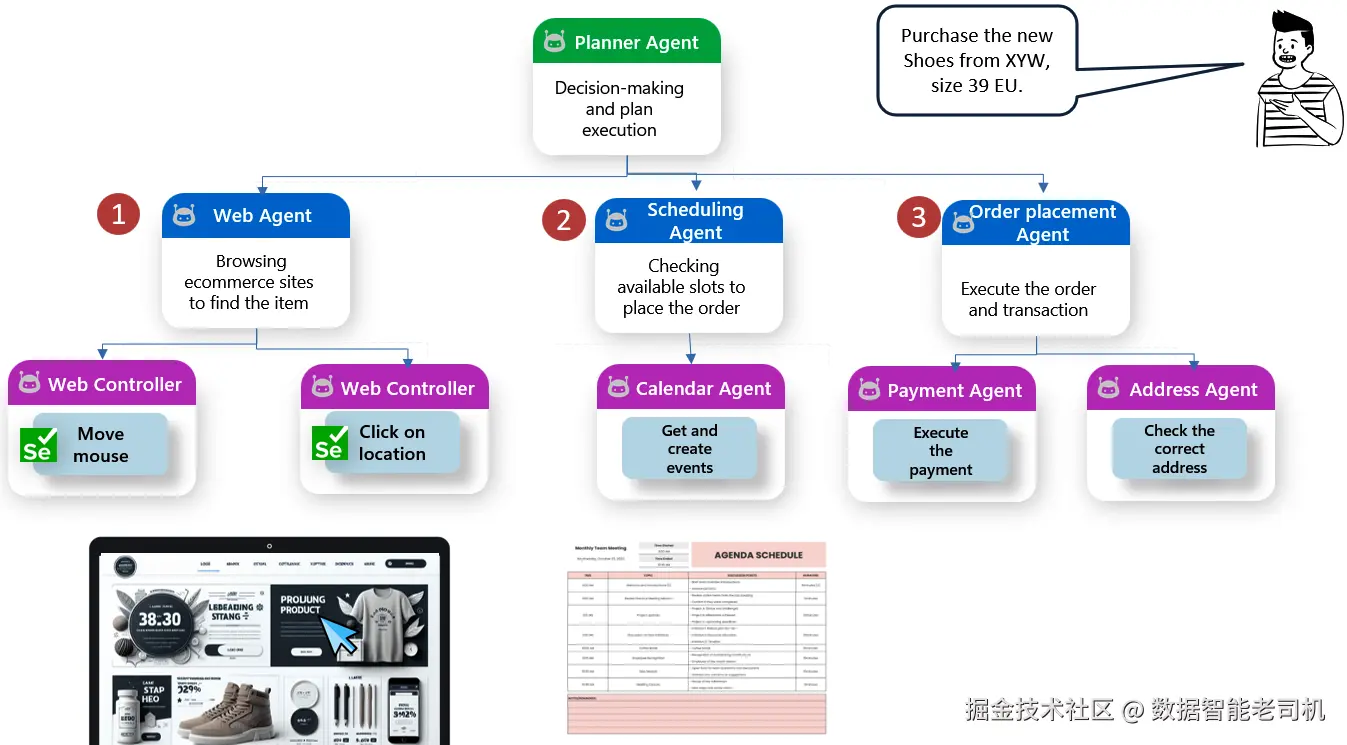
图 7.1:分层式多智能体系统示例
小贴士:需要查看高清版本?请在下一代 Packt Reader 或 PDF/ePub 版中查看。购买本书可免费获得下一代 Packt Reader。访问 packtpub.com/unlock,用书名搜索并确认版本。
在单智能体 设置下,该智能体会顺序 完成:搜索鞋款、管理收货/配送安排、填写地址信息并处理支付。
而在模块化、多智能体设计中,任务会拆分为专门组件:
-
Planner Agent(规划器智能体) :解析指令并协调后续执行。
-
Web Agent(Web 智能体) :浏览电商平台,并使用低层的 **Web Controller Agents(Web 控制器智能体,如基于 Selenium 的机器人)**进行界面交互------点击、滚动与视觉搜索。
-
Scheduling Agent(日程/配送安排智能体) :检查日历中的可配送时段,并调用 Calendar Agent 获取或创建事件。
-
Order Placement Agent(下单智能体) :协调完成购买,联动:
- Payment Agent(支付智能体) :安全处理交易
- Address Agent(地址智能体) :校验并格式化收货地址
各个智能体独立运行 ,共同服务于总体目标。Planner Agent 像指挥家一样编排这支智能团队:Web Agent、Scheduling Agent、Order Placement Agent、Web Controllers、Calendar Agent、Address Agent 与 Payment Agent。
这种做法与我们在前文讨论的两个关键理念模块化 与抽象高度一致,带来多重优势:
- 可扩展性(Scalability) :多智能体系统天然易扩展 。由于每个智能体都封装特定职能,它们可以独立部署到不同的服务器、容器甚至地理区域。如果某个智能体成为瓶颈(例如高峰期的网页抓取智能体),可以横向扩展(副本与负载均衡)而不影响其他部分。
- 可维护性(Maintainability) :模块化促进可维护性。每个智能体自洽 ,通过定义良好的协议/接口 通信,因此可以在不重写整个系统的情况下更新、重构或替换。例如,把一个摘要智能体替换为更先进的模型(甚至不同厂商的模型)不会影响负责检索、过滤或用户交互的智能体逻辑。
- 专业化(Specialization) :每个智能体都可用最合适的工具与模型 微调或构建。有的用擅长代码生成的 LLM(如 GPT-4o),有的基于 RAG 架构,甚至基于规则逻辑。只要遵循共享协议,智能体可以用不同语言/框架 (Python、JavaScript 等)开发。这种灵活性让团队可以在性能与成本之间做最优取舍。
最后,为了构建并理解 多智能体系统,我们还需要从两个层面借鉴微服务 世界:它既是支撑多智能体智能真正落地的基础设计理念 ,也是相应的基础设施模式。
定义
微服务是一种软件架构模式:把应用拆分为小型、独立的服务,每个服务只负责单一职能,并通过轻量协议(HTTP 或消息队列)通信。该模式带来可扩展性、灵活性与易维护性,是现代分布式系统的基石------并日益成为多智能体 AI 系统的基础。
从设计 角度,微服务强调模块化 ------把大型应用拆解为独立、专门 的服务,每个服务把一件事做到最好。这正是智能体系统应有的设计方式:
- 每个智能体仅承担单一职责:浏览、排程、下单、校验或支付;
- 每个智能体封装自身的逻辑与工具,就像微服务封装其 API 与数据库访问;
- 智能体通过结构化协议 (消息、事件与 API)通信,支持异步、灵活的协同;
- 你可以替换 某个智能体为更智能的版本,或回滚/重部署故障智能体,而不干扰系统其余部分。
换言之,多智能体设计就是把微服务设计应用于人工智能:强调解耦、专业化与可组合性------这些都是现代软件工程的核心原则。
从基础设施角度,微服务为在现实世界里部署与管理基于智能体的系统提供了骨干支撑。每个智能体可以:
- 容器化(如使用 Docker),作为独立应用部署并对外暴露 API;
- 托管在云原生 环境(如 Kubernetes)中,独立弹性伸缩;
- 通过服务网格 或消息中间件连接,获得安全、高效的通信;
- 采用多语言技术栈 开发(某个智能体跑 Python,另一个跑 JavaScript------择其适合)。
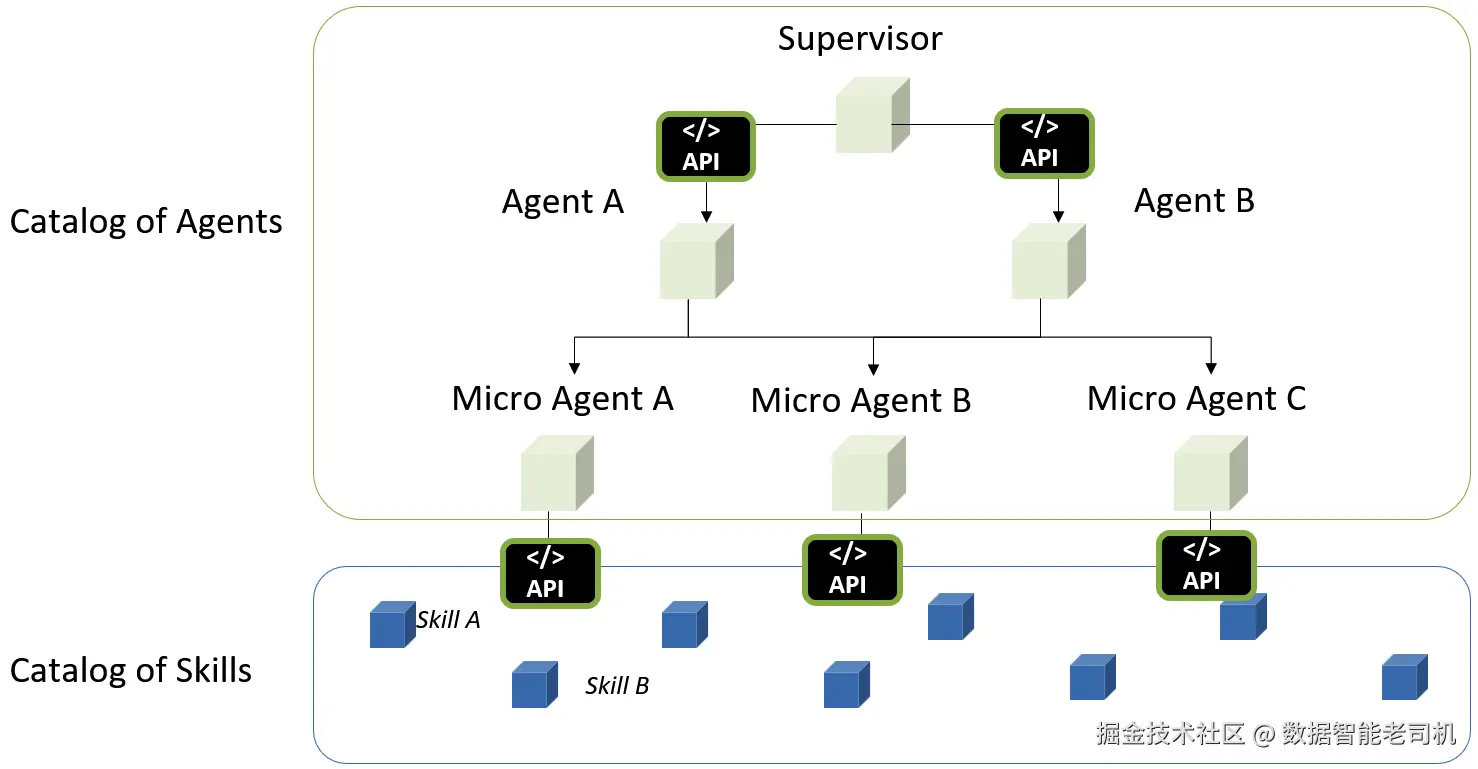
图 7.2:面向多智能体系统的微服务后端
回到图 7.1 的示例:Planner Agent 将"购买鞋子,欧码 39 "分解为若干子任务,由模块化的 Web Agent、Scheduling Agent、Order Placement Agent 分别处理,并进一步调用下游助手(如 Payment Agent 与 Address Agent)。
这些智能体可以运行为:
- 独立微服务:各自部署在 Kubernetes 集群中;
- 隔离的无服务器函数:按需启动;
- 具备持久化记忆与状态的后台服务 :通过事件驱动架构编排。
没有微服务式的基础设施,要构建、部署与管理这样分布式的智能体系统 将会脆弱且低效。正是模块化设计 与可扩展托管的组合,使现实世界中的多智能体 AI 系统成为可能。
同时,我们还需要定义这些智能体之间的通信方式 ,这就引出了多智能体设计工作流这一主题。
理解并设计多智能体系统的不同工作流
当我们从单智能体 系统过渡到多智能体架构 时,智能体之间如何交互 就变得至关重要。不同的工作流(或称通信模式)决定了智能体如何协作、共享信息与做出决策。选择合适的工作流取决于任务性质、各智能体的角色,以及期望的结果。
下面我们来探讨五种核心的多智能体工作流(见图 7.3)。
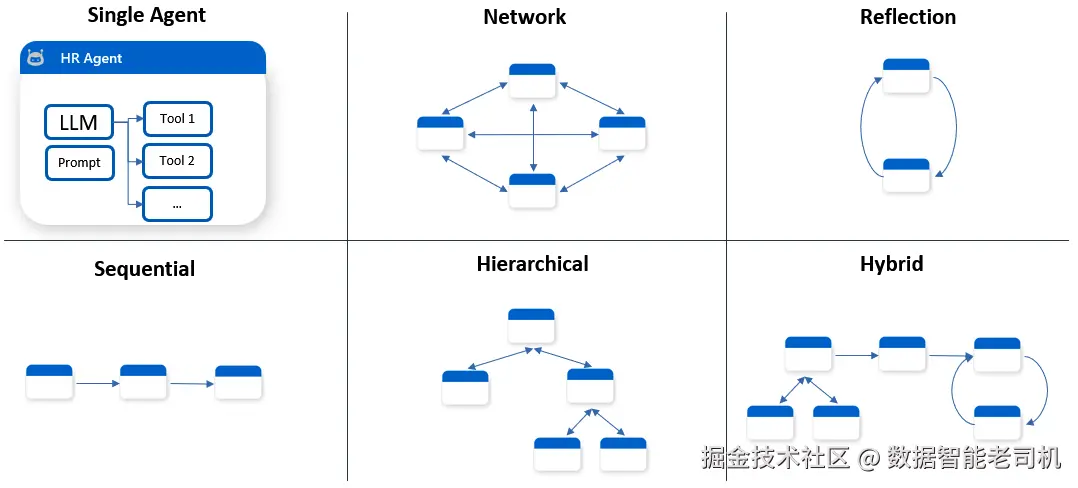
图 7.3:不同类型的智能体工作流
以下是五种核心工作流的详细说明:
1) 网络型(Network)
所有智能体在一个全连接图 中作为对等体存在,每个智能体都可以直接与任何其他智能体通信。这种方式支持高度交互且动态的协作。
示例: 在一家节奏很快的初创公司里,一组 AI 智能体协作完成新移动应用的概念构思、验证与发布规划。每个智能体各司其职,但像真实的产品团队一样以动态、迭代方式共同工作:
- 智能体 A------市场研究智能体:持续监测消费者趋势、应用商店数据与竞品动态。它识别出对 AI 驱动的健康类应用日益增长的兴趣,并分享一份突出未满足用户需求的报告。
- 智能体 B------产品设计智能体:基于市场研究智能体的洞见,绘制健康应用的初始概念,包括用户流程与功能原型;参考 UX 风格指南并复用过去的成功模式;随后将设计共享给团队征求反馈。
- 智能体 C------合规智能体 :在新功能想法提出的第一时间,从法律与隐私(如健康数据处理)角度审查,并提出修改建议以确保符合 GDPR 与 HIPAA。
- 智能体 D------项目管理智能体:跟踪进度与任务依赖,提出时间表并标记风险(例如需要额外合规审批的设计特性),同时在决策待定或任务阻塞时提醒团队。
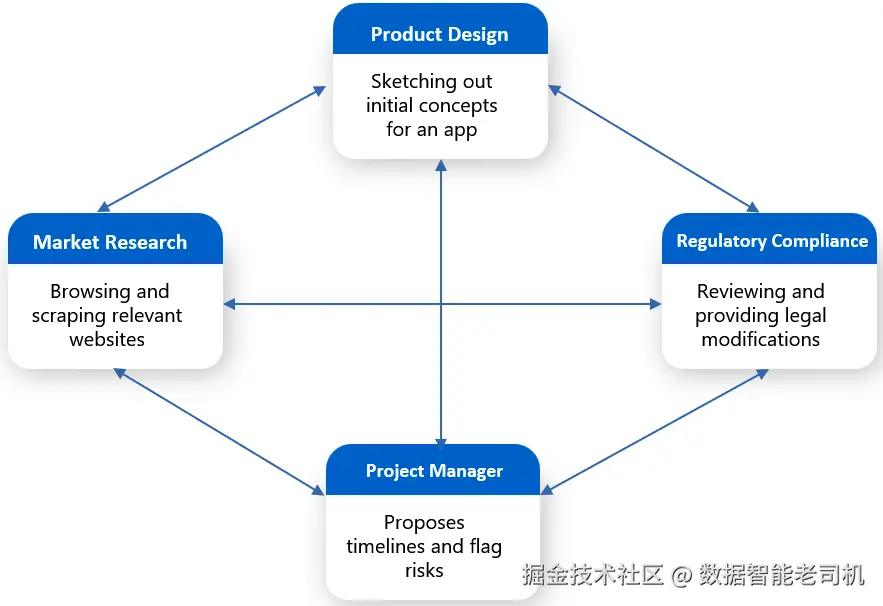
图 7.4:网络型工作流
这种设置模拟了跨职能敏捷团队,依赖持续协调 与快速反馈而蓬勃发展。
2) 反思型(Reflection)
一种自评环:智能体对自身输出进行反思/批评(或由另一智能体执行),通过反馈实现迭代改进。
示例: 某大学研究团队希望用写作助手生成学术论文草稿。主智能体 负责产出内容; "审稿人"智能体从清晰度、逻辑性与引注准确性进行评估,标记论证薄弱点或缺失参考文献。主智能体据此修改后再提交审阅,如此循环,直到达到发表质量。
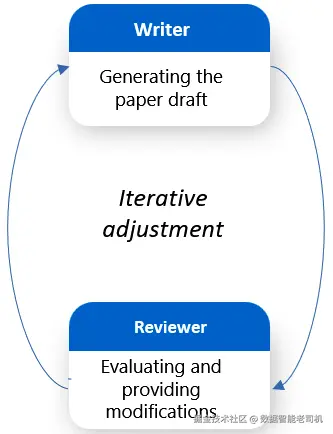
图 7.5:反思型工作流
该工作流对质量控制 与以打磨为核心的任务尤为有效。
3) 顺序型(Sequential)
智能体被组织为线性流水线。每个智能体完成特定子任务,并将输出传给链条中的下一个智能体。
示例: 一家媒体机构用顺序链条的专用智能体来自动化"突发新闻"的创作与发布流程:
- 智能体 A------新闻聚合:监控通讯社、社交媒体与新闻稿等实时源,识别突发事件并提取关键信息。
- 智能体 B------事实核查:将采集到的信息与可信来源(政府数据库、既往报道、知识图谱)比对,标记不一致之处,确保在进入下一步前的准确性。
- 智能体 C------写稿智能体:基于已核实数据撰写有说服力的新闻稿,符合新闻文体与出版规范。
- 智能体 D------SEO 与社媒优化:优化标题、添加元描述与标签,调整格式以最大化在搜索引擎与社交平台的触达。
- 智能体 E------发布智能体:在网页、移动端与新闻简报等渠道进行排程并发布。

图 7.6:顺序型工作流
采用该工作流,你可以对智能体拥有更强的可控性 ,因为你为它们给出了明确的执行顺序。
4) 层级型(Hierarchical)
一个管理者智能体(Manager)监督并下发任务 给下属智能体,并汇总 它们的结果。通信通常是自上而下 再自下而上。
示例: 一家 SaaS 公司为客户服务部署了层级式 AI 系统。用户提交问题:"为什么我这个月被重复扣费 ?"管理者智能体解析请求并拆分子任务:
- 计费智能体检查交易历史;
- 技术智能体审查系统日志以定位重复扣款;
- FAQ 智能体确认是否已知问题。
下属完成后,管理者将结果整合成一致的回答 并返回。此设置模拟现实中的管理方式,促进模块化 与专业化处理。
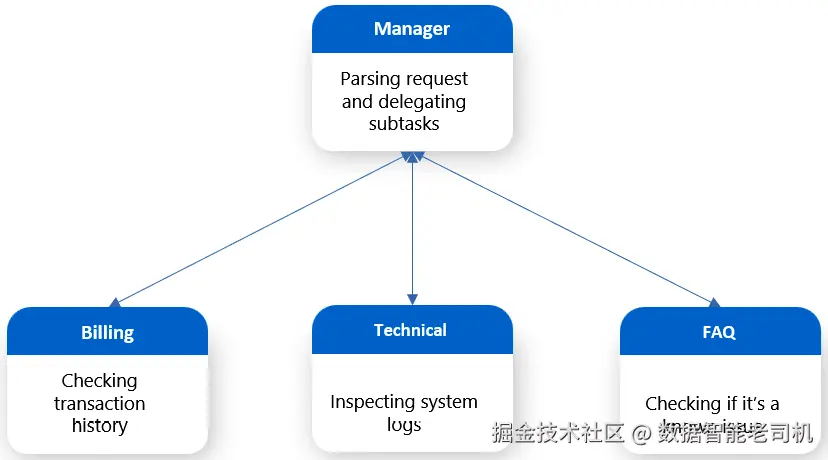
图 7.7:层级型工作流
当执行顺序事先并不明确 (区别于顺序型),但你仍希望在顶层保留一定监控能力(区别于网络型)时,此模式尤为适用。
5) 混合型(Hybrid)
将多种模式组合 (例如:以层级为骨架,内嵌反思环;或顺序链中嵌入网络协作),实现灵活、分层的协作。
示例(在顺序架构基础上加入层级变化):
-
智能体 A------新闻聚合:监控实时源,识别突发事件并提取要点。
-
智能体 B------编辑经理:作为"副主编",不直接写稿,而是管理一个小团队:
- 写稿智能体:基于事实生成初稿;
- 风格智能体:确保语气、语法与格式符合编辑规范;
- 事实核查智能体 :用可靠数据库与报告交叉验证论断。
编辑经理负责监督这些智能体、审阅其成果并编纂最终版本,再传递到下一步。
-
智能体 C------发布智能体:为线上分发做准备,添加标签与 SEO 元数据,并发布至新闻站点和社交平台。
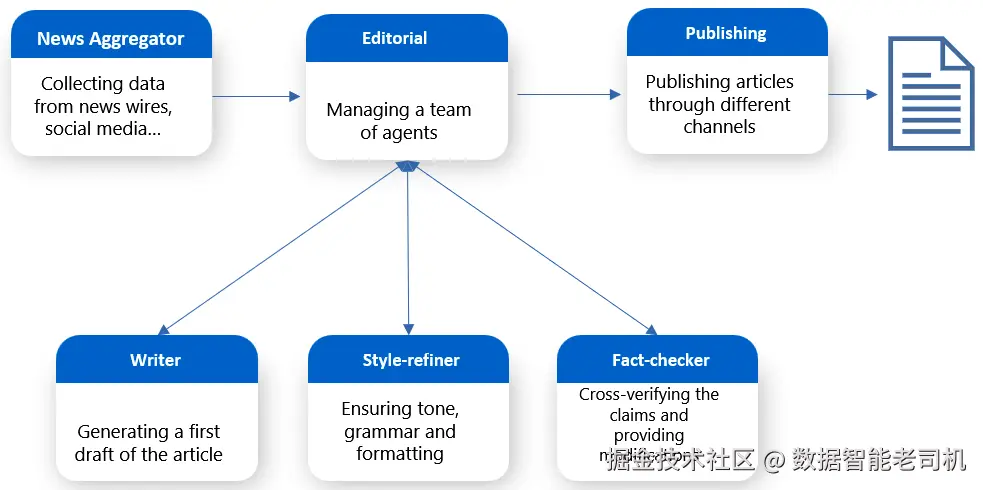
图 7.8:混合型模式
该混合结构为原本线性的流水线注入灵活性与质量控制 。由编辑经理管理的层级子结构,带来专业化与稳健性 ,同时不破坏整体的顺序任务流。
在前面的章节中,我们已讨论:对于单智能体 ,拥有一个 AI 编排器(orchestrator) 能帮助我们合理设计其与工具的交互。而在多智能体系统 中,编排器就更为关键了------它既要管理单个智能体与工具 的交互,也要管理多个智能体之间的交互。
在下一节,我们将探索几种最流行的多智能体编排器。
多智能体编排器概览
随着我们从单智能体 系统演进到协作式多智能体 架构,如何协调多个智能体就显得至关重要,因此对 AI 编排器(orchestrator) 的需求比以往更为迫切。
针对多智能体应用,有一些额外的编排器值得在你的场景中加以探索。
AutoGen
AutoGen 由微软开发,是一个通过"对话式交互"来构建多智能体系统的开源框架。它强调设计能够沟通、协作与自适应的智能体,以完成复杂任务。
该框架采用分层、模块化架构,每一层职责清晰,并在下层能力之上逐级构建。这样,开发者可以在不同复杂度层级与系统交互:从便于快速开发的高层抽象,到提供精细控制的低层组件。
- Core API :作为基础层,负责智能体之间的消息传递 、事件驱动行为 ,并为本地与分布式 部署提供运行时支持。它追求最大灵活性,甚至支持 Python 与 .NET 之间的跨语言互操作。
- AgentChat API :位于 Core 之上,提供更高层次、主观化(opinionated)的接口,聚焦易用性与快速原型 。它简化了诸如双智能体对话 与群组交互等常见模式,便于从早期版本过渡的用户使用。
- Extensions API :最上层用于持续扩展框架能力,支持官方与第三方扩展,包括与主流 LLM 提供商 (如 OpenAI、Azure OpenAI)的集成,以及外部代码执行 与工具使用等高级能力。
除框架本身外,AutoGen 还提供AutoGen Studio (零代码 GUI)与AutoGen Bench(基准测试套件)等开发工具。
AutoGen 适用于自动化客户支持 、协作式内容创作 以及需要智能体协商、规划与共同执行的复杂问题求解场景。
TaskWeaver
TaskWeaver 是微软开发的代码优先 (code-first)智能体框架,面向复杂数据分析工作流 的规划与执行。其显著差异点在于以代码驱动执行 :TaskWeaver 会将用户请求解释为可执行代码片段 并运行,顺畅地协调多个函数或插件。与主要依赖文本对话历史的传统智能体系统不同,TaskWeaver 同时融合聊天历史、代码执行历史与内存态数据 ,非常适合处理诸如表格、数据库等结构化、高维数据。
TaskWeaver 的关键特性包括:
- 复杂任务规划与反思式执行 :支持智能任务分解 、进度跟踪 与反思式(reflective)执行,可基于执行反馈动态调整策略。
- 丰富数据处理与有状态执行 :支持 DataFrame 等丰富的 Python 数据结构,在任务间维护计算状态 ,并在执行前校验生成的代码以保证一致体验。
- 可定制、可扩展且安全 :易于以领域插件 扩展,封装自定义算法,并通过会话隔离 与安全代码执行来可靠地管理多智能体工作流。
- 对开发者友好且透明 :提供简洁的初始化体验与即用型插件、详尽日志便于调试,以及开放透明的架构,帮助用户理解与掌控整个执行过程。
凭借其代码驱动方式与对结构化数据的强力支持,TaskWeaver 尤其适合数据密集型应用、分析工作流、科学研究、金融建模 等对精确性、可复现性与执行可追溯要求极高的场景。
OpenAI Agents SDK
OpenAI Agents SDK 是由 OpenAI 开发的轻量却强大的 框架,旨在简化多智能体工作流 的构建与编排。它以模块化方式连接智能体、分配工具、施加护栏(guardrails) ,并在智能体之间无缝移交控制权。
该 SDK 与提供商无关 :既可使用 OpenAI 的 API,也兼容 100+ 不同 LLM,在后端选择上非常灵活。
主要特性包括:
- 智能体协作的交接(Hand-offs) :提供一等公民的交接机制,可基于任务上下文在智能体间传递控制权,使多智能体协作直观自然。
- 内置安全护栏 :可定义输入验证、输出检查与自定义约束 ,提升工作流的可靠性与合规性。
- 原生追踪与调试 :内置追踪支持 ,可可视化智能体交互、监控执行路径并轻松调试复杂工作流,助力透明性与优化。
- 简单快速的 API :智能体定义(名称、指令、工具)与组装复杂工作流的样板极少,原型速度快且不牺牲深度。
- 多提供商支持 :虽与 OpenAI 模型深度集成,但不被锁定,可轻松接入其他模型提供商,满足多样化部署需求。
总体而言,OpenAI Agents SDK 让开发者能构建可推理、可委派、可自主与工具交互的多智能体系统。
LangGraph
LangGraph 是 LangChain 生态的扩展,用于以**基于图(graph-based)**的架构编排多智能体系统。
定义
在数学中,图(graph)由若干 节点(顶点)与连接它们的边 组成,用于刻画对象对之间的关系。图在网络理论、计算机科学、组合数学等领域中至关重要。
在 LangGraph 语境下,图用于通过以下要素来建模 AI 工作流:
- 节点(Nodes) :每个节点代表工作流中的某个任务或操作。节点可以是 LLM 智能体、工具或自定义函数 ,执行诸如文档检索、数据处理、文本生成 或基于输入的决策等动作。
- 边(Edges) :定义控制与数据 在节点间如何流动,并决定执行顺序;边还可包含条件逻辑,使工作流可依据前序节点的状态/输出进行动态路由。
- 状态(State) :在执行期间于节点间传递的共享数据结构,承载必要上下文(消息、阶段性结果、元数据等),供节点执行任务与协调行动。
- 条件逻辑(Conditional logic) :通过条件边 实现动态决策;它们会评估当前状态以确定下一步,支持分支、循环与实时调整。
- 工作流编译(Workflow compilation) :在定义完成后,LangGraph 会将节点、边与条件逻辑编译为可执行图 ;该工作流负责执行顺序、状态流转与节点协调,确保高效可靠地完成任务。
例如,在图 7.9 中,你可以看到一个 LangGraph 工作流:首先由一个条件边 决定是否需要 Web Agent ;随后再根据输出判断查询是否需要改写 ,或可直接作为最终结果展示给终端用户。
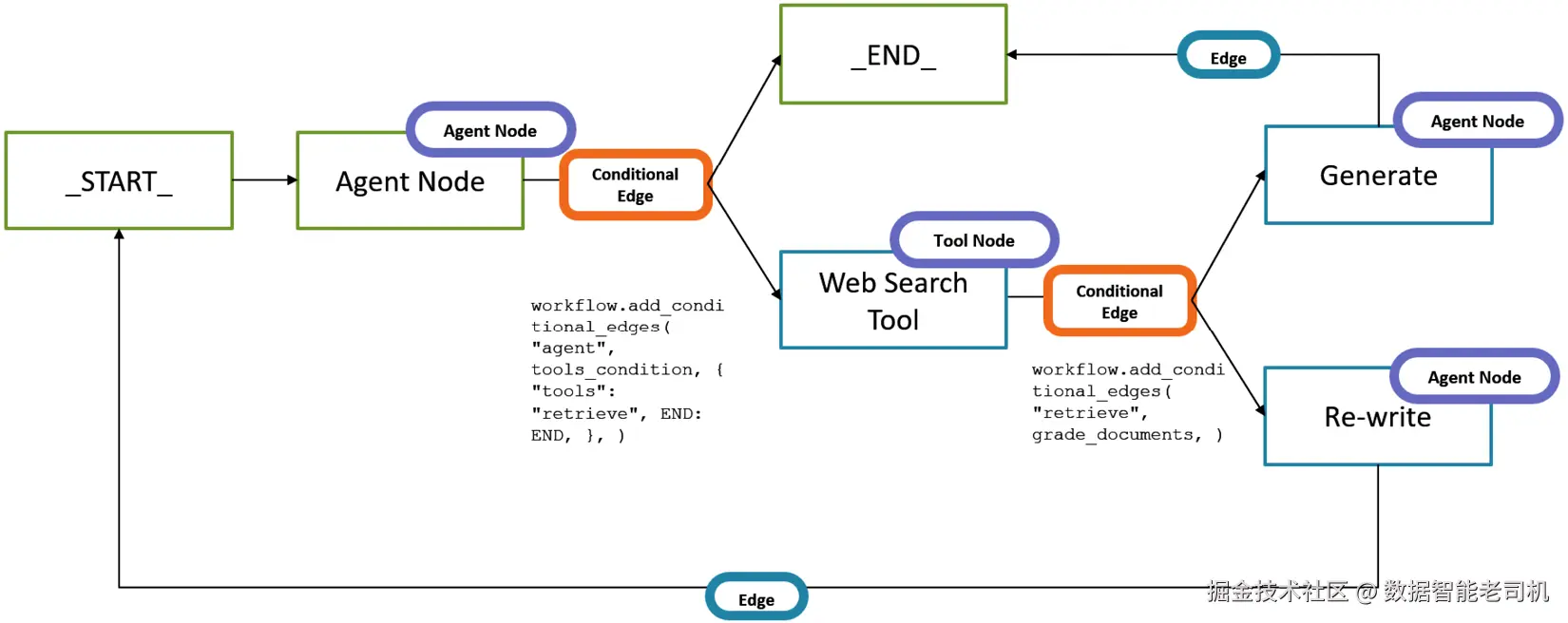
图 7.9:LangGraph 工作流示例
借助这些元素的组合,LangGraph 使开发者能够构建模块化、可复用、动态 的工作流,从而驱动复杂的多智能体交互与结合 LLM/外部工具的高级决策。
并不存在在 AutoGen、TaskWeaver、Agents SDK、LangGraph 之间的绝对"最佳 "。它们各自的设计理念与长处不同;正确选择高度依赖 你的具体用例、技术偏好以及你要构建的工作流复杂度。有的偏向轻量与快速原型 ,有的擅长编排多智能体的复杂有状态交互。
在下一节中,我们将以 LangGraph 为例,面向一个动手实践用例,逐步展示如何利用基于图的编排来构建多智能体系统。
使用 LangGraph 构建你的第一个多智能体应用
动手时间到!本节我们将基于 LangGraph 构建一个多智能体应用。注意:这里不会贴出完整代码 ,而是只展示理解智能体构建模块所需的关键片段 。完整代码可在本书的 GitHub 仓库获取:github.com/PacktPublis...。
先介绍一下我们要用多智能体应用解决的挑战。
管理投资组合 是一项复杂工作,需要持续关注市场趋势、资产表现与风险敞口。许多个人投资者与理财顾问难以手动分析海量金融数据来做出明智决策。本应用旨在通过一组智能体为用户分析投资组合 、抽取相关市场洞见 并提供可行动的建议,以缓解这一难题。
目标是自动生成 一份综合报告,帮助用户在提升收益 或降低风险 之间实现优化。为了演示,假设投资组合以 JSON 文件表示,结构如下:
css
[ { "symbol": "AAPL", "sector": "Technology", "quantity": 13, "purchase_price": 1202.57, "total_invested": 15633.41, "purchase_date": "2022-03-12" },......]小贴士: 想提升编码体验?在下一代 Packt Reader 中使用 AI Code Explainer 与 Quick Copy 。打开本书在线阅读版,点击复制 按钮 (1) 可快速拷贝代码到你的环境;点击讲解 按钮 (2) 可让 AI 助手解释一段代码。
购买本书可免费获得下一代 Packt Reader。扫描二维码或访问 packtpub.com/unlock,用书名搜索并确认版本无误。
为实现该任务,我们开发一个如下结构的多智能体应用:
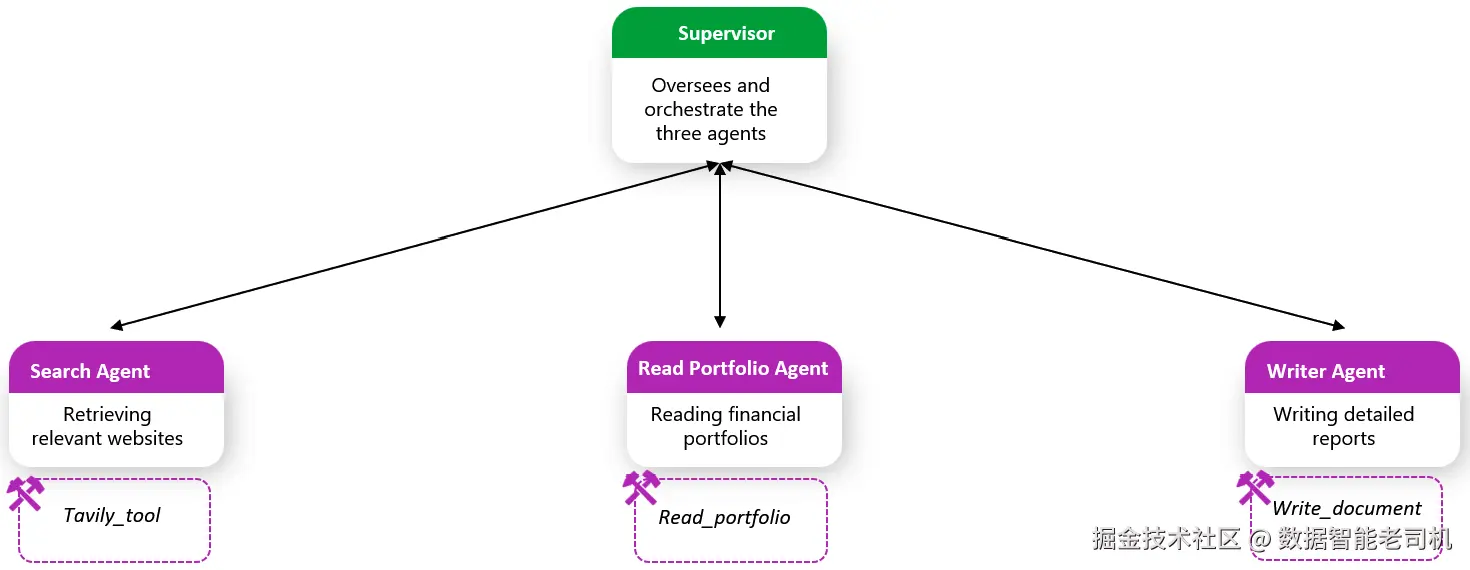
图 7.10:分层式多智能体投资组合分析器
根据图 7.10,我们逐一看看各组件:
search_agent:检索相关网站来回答用户问题,并配备以下工具
tavily_tool:LangChain 提供的预构建工具,用于从 Tavily API 检索搜索结果
定义
Tavily 是一款由 AI 驱动的搜索 API,旨在为 RAG 与基于智能体的应用提供实时、高质量 的网页搜索结果。它通过简单、快速且具成本效益 的 API 调用,让开发者将外部知识集成到 LLM 工作流中。Tavily 常用于通过最新的网页内容 为 AI 生成的回答提供依据 ,提升准确性与相关性。
先初始化工具:
ini
# Load environment variables from .env file
load_dotenv()
# Initialize the Azure OpenAI model
llm = AzureChatOpenAI(
openai_api_version=openai_api_version,
azure_deployment=azure_chat_deployment,
)
tavily_tool = TavilySearchResults(max_results=5,
tavily_api_key=tavily_api_key)创建智能体并将其初始化为 LangGraph 图中的节点:
ini
search_agent = create_react_agent(llm, tools=[tavily_tool])
def search_node(state: State) -> Command[Literal["supervisor"]]:
result = search_agent.invoke(state)
return Command(
update={
"messages": [
HumanMessage(
content=result["messages"][-1].content,
name="search")
]
},
# We want our workers to ALWAYS "report back" to the supervisor when done
goto="supervisor",
)read_portfolio_agent:从给定路径读取投资组合,并配备以下工具
read_portfolio:硬编码函数,用于读取以 JSON 保存的投资组合
初始化工具与智能体:
python
@tool
def read_sample_portfolio(
json_path: str = "sample_portfolio.json"
) -> str:
"""
Reads the sample_portfolio.json file and returns its content as a string.
Each entry includes the stock symbol, sector, quantity, purchase price, and purchase date.
"""
if not os.path.exists(json_path):
return f"File not found: {json_path}"
with open(json_path, "r") as f:
portfolio = json.load(f)
if not isinstance(portfolio, list):
return "Unexpected portfolio format."
response = "Sample Portfolio:\n"
for stock in portfolio:
response += (
f"- {stock['symbol']} ({stock['sector']}): "
f"{stock['quantity']}shares @${stock['purchase_price']}"
f"(Bought on {stock['purchase_date']})\n"
)
return response
read_portfolio_agent = create_react_agent(
llm, tools=[read_sample_portfolio]
)
def read_portfolio_node(
state: State
) -> Command[Literal["supervisor"]]:
result = read_portfolio_agent.invoke(state)
return Command(
update={
"messages": [
HumanMessage(content=result["messages"][-1].content,
name="read_portfolio")
]
},
# We want our workers to ALWAYS "report back" to the supervisor when done
goto="supervisor",
)doc_writer_agent:撰写包含结构化大纲的详细报告,并配备以下工具
write_document:硬编码函数,将智能体输出写入预定义目录
初始化工具与智能体:
python
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import Dict, Optional
from typing_extensions import TypedDict
# Define a real directory path
REAL_DIRECTORY = Path(r"your_path")
#_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(REAL_DIRECTORY)
@tool
def write_document(
content: Annotated[
str, "Text content to be written into the document."],
file_name: Annotated[str, "File path to save the document."],
) -> Annotated[str, "Path of the saved document file."]:
"""Create and save a text document."""
with (WORKING_DIRECTORY / file_name).open("w") as file:
file.write(content)
return f"Document saved to {file_name}"
report_prompt = """
You are an expert report generator. Given the input from other agents, you generate a detailed report on how to optimize the provided portfolio.
The report will have the following outline:
-------------------------------
**Introduction on market landscape**
**Portfolio Overview**
**Investment Strategy**
**Performance Analysis**
**Recommendations**
**Conclusion**
**References**
--------------------------------
Once the report is generated, save it using your write_document tool.
"""
doc_writer_agent = create_react_agent(
llm,
tools=[write_document],
prompt=report_prompt,
)
def doc_writing_node(state: State) -> Command[Literal["supervisor"]]:
result = doc_writer_agent.invoke(state)
return Command(
update={
"messages": [
HumanMessage(content=result["messages"][-1].content,
name="doc_writer")
]
},
# We want our workers to ALWAYS "report back" to the supervisor when done
goto="supervisor",
)现在三位"工作智能体"都已就绪,我们再在更高层加一层抽象:创建一个团队监督者(supervisor) ,根据用户请求调度各个团队:
python
class State(MessagesState):
next: str
def make_supervisor_node(llm: BaseChatModel, members: list[str]) -> str:
options = ["FINISH"] + members
system_prompt = (
"You are a supervisor tasked with managing a conversation between the"
f" following workers: {members}. Given the following user request,"
" respond with the worker to act next. Each worker will perform a"
" task and respond with their results and status. When finished,"
" respond with FINISH."
)
class Router(TypedDict):
"""Worker to route to next. If no workers needed, route to FINISH."""
next: Literal[*options]
def supervisor_node(state: State) -> Command[
Literal[*members, "__end__"]
]:
"""An LLM-based router."""
messages = [
{"role": "system", "content": system_prompt},
] + state["messages"]
response = llm.with_structured_output(Router).invoke(messages)
goto = response["next"]
if goto == "FINISH":
goto = END
return Command(goto=goto, update={"next": goto})
return supervisor_node
supervisor_node = make_supervisor_node(llm,
["search","read_portfolio", "doc_writer"]
)编译图:
makefile
# Define the graph.
builder = StateGraph(State)
builder.add_node("supervisor", supervisor_node)
builder.add_node("read_portfolio", read_portfolio_node)
builder.add_node("search", search_node)
builder.add_node("doc_writer", doc_writing_node)
builder.add_edge(START, "supervisor")
super_graph = builder.compile()测试:
bash
for s in super_graph.stream(
{
"messages": [
("user", "Generate a well structured report on how to improve my portfolio given the market landscape in Q4 2025.")
],
},
{"recursion_limit": 150},
):
print(s)
print("---")截断输出示例:
yaml
{'supervisor': {'next': 'search'}}
---
{'search': {'messages': [HumanMessage(content='**Portfolio Improvement Report Based on Market Landscape Q4 2025**\n\n---\n\n### 1. **Market Landscape Highlights for Q4 2025:**\nThe market trends observed for Q4 2025 suggest:\n- **Elevated Interest Rates:** Policy rates in developed markets, particularly in the US, are expected to remain high. This "higher-for-longer" rate narrative creates opportunities for varied asset positioning.\n- **Equity Market Dispersion:[...]]}}
---
{'supervisor': {'next': 'read_portfolio'}}
---
{'read_portfolio': {'messages': [HumanMessage(content='### Portfolio Improvement Report: Alignment with Market Landscape Q4 2025 \n\n---\n\n#### Portfolio Overview\nYour existing portfolio demonstrates strong exposure to technology (AAPL, GOOGL, MSFT, NVDA), consumer discretionary (AMZN, TSLA, BABA), and financials (V, JPM). [...]]}}
---
{'supervisor': {'next': 'doc_writer'}}
---
{'doc_writer': {'messages': [HumanMessage(content='The report on optimizing your portfolio for Q4 2025 has been successfully generated and saved. You can find it in the file named **Portfolio_Optimization_Q4_2025.txt**. Let me know if you need further assistance or any modifications!', additional_kwargs={}, response_metadata={}, name='doc_writer', id='8fa9e6a9-fafc-466c-8bbc-19514654c3be')]}}
---
{'supervisor': {'next': '__end__'}}你会在指定文件夹下(示例中为 outputs)发现生成的文件。
 图 7.11:我本地文件夹下创建的 .txt 文件示例
图 7.11:我本地文件夹下创建的 .txt 文件示例
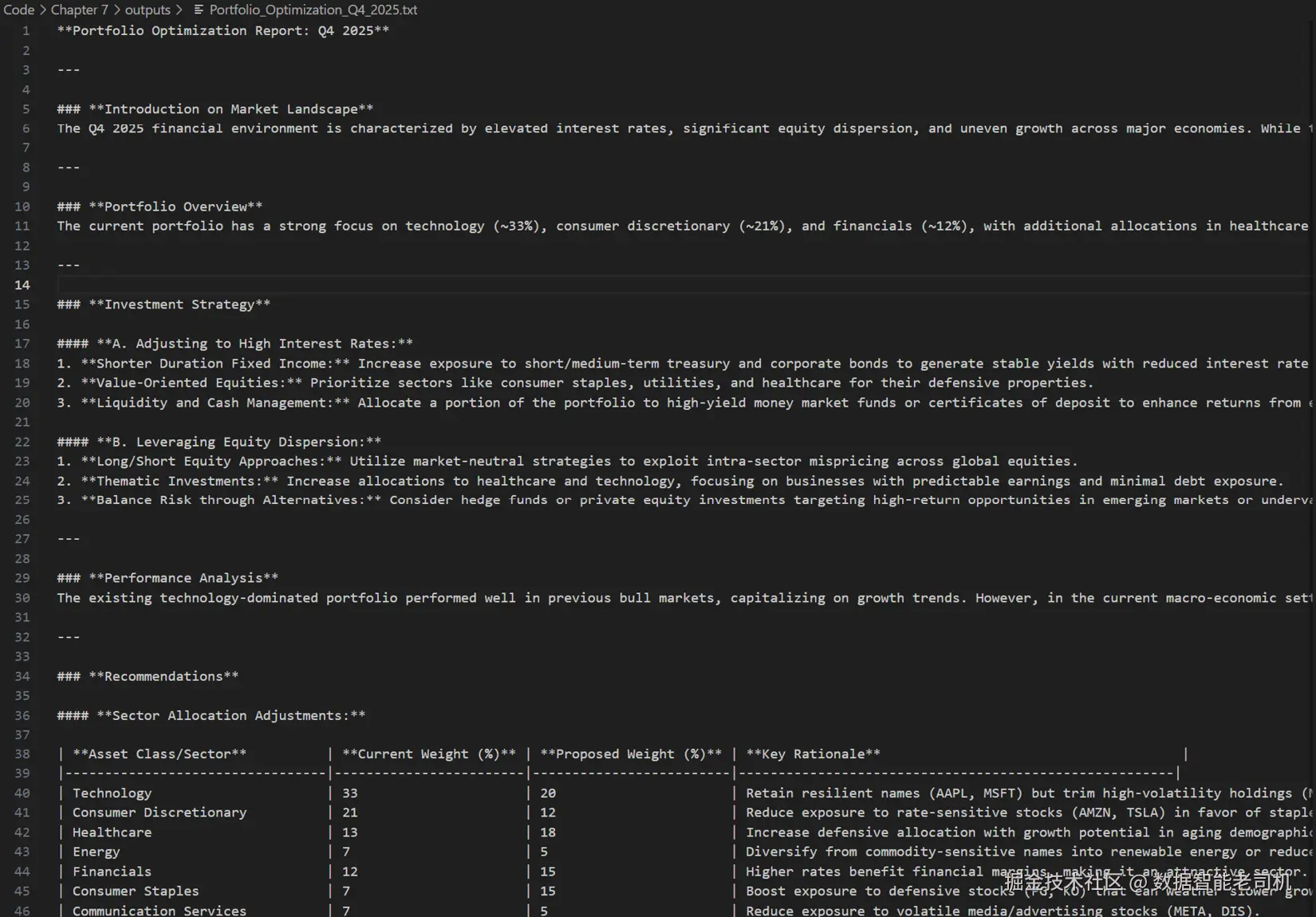 图 7.12:由智能体生成的最终报告示例
图 7.12:由智能体生成的最终报告示例
如你所见,输出遵循了我们在报告生成智能体 的系统消息中指定的大纲。
总结
本章我们走出"单一、工具增强型智能体"的世界,探索了多智能体系统的精彩版图。我们看到,智能体能够像人类团队那样协作:各自专精于不同任务,但又彼此配合,去解决任何单个智能体都难以(或无法)独立完成的复杂问题。
我们也明确:设计多智能体系统既是架构挑战 ,也是AI 挑战 ------需要在模块化、通信、协同与可靠性 上深思熟虑。借鉴微服务架构 的思路,我们认识到智能体可以(也应该)模块化、相互独立 ,并通过智能编排形成可扩展、具韧性的系统。
我们介绍了多智能体编排器,如 AutoGen 、TaskWeaver 与 LangGraph ,并使用 LangGraph 进行了上手示范,构建了我们的第一个多智能体应用。
本章也标志着本书第二部分 的结束。下一章我们将切换到一个关键主题------构建负责任的 AI 系统 。随着更具自治性的智能体与多智能体生态的出现,为安全、透明、保障与伦理对齐而设计变得至关重要。
参考资料
- LangGraph:www.langchain.com/langgraph
- 使用 LangGraph 的多智能体系统:langchain-ai.github.io/langgraph/c...
- LangGraph 的"Agentic"概念:langchain-ai.github.io/langgraph/c...
- OpenAI Agents SDK:github.com/openai/open...
- AutoGen:github.com/microsoft/a...
- TaskWeaver:github.com/microsoft/T...