作者:来自 Elastic Udayasimha Theepireddy, Srinivas Pendyala , Matt Ryan 及 Ganesh Ramesh Shenoy

通过在 Amazon Bedrock AgentCore Runtime 平台上部署 Elastic 的搜索功能,将复杂的数据库查询转化为简单的对话。
Elasticsearch 拥有与行业领先的 Gen AI 工具和提供商的原生集成。查看我们的网络研讨会,内容包括超越 RAG 基础,或使用 Elastic Vector Database 构建可用于生产的应用程序。
要为你的用例构建最佳搜索解决方案,现在就开始免费的云试用,或在本地机器上尝试 Elastic。
想象一下用简单的英文向你的数据提问:"根据我的健康目标提供健身/饮食建议 - Fitness/diet recommendations based on my health goals,",或"帮我根据风险水平寻找投资机会?- Help find investment opportunities based on my risk level?",并且无需写任何查询就能得到准确的答案。今天,我们将探讨如何通过在 Amazon Bedrock AgentCore Runtime 上部署 Elastic 的 Model Context Protocol (MCP) 服务器,实现这一点,从而在对话式 AI 与数据之间建立强大的桥梁。
从核心来看,这个解决方案结合了 Elasticsearch 搜索功能与 Amazon 无服务器 AI 基础设施的力量。它的工作方式如下:
-
你的自然语言问题通过部署在 Amazon Bedrock AgentCore Runtime 上的 MCP 服务器处理
-
MCP 服务器将这些问题转换为精确的 Elasticsearch 查询
-
结果以可读的格式返回,让你的数据即时可访问
-
所有这些都发生在一个安全、可扩展、可用于生产的环境中,并部署在 Amazon Bedrock AgentCore Runtime 上
在这篇博客中,我们将探讨如何:
-
在 Amazon Bedrock AgentCore Runtime 上部署 Elastic 的 MCP 服务器
-
将本地 MCP 原型转化为可用于生产的解决方案
-
如何在 Elasticsearch 之上构建对话式界面
-
实现安全、可扩展的 AI agent 架构
背景
Model Context Protocol (MCP)
MCP 是一种开放协议,革新了企业通过 AI 与数据交互的方式。与传统的仅仅检索文档的 RAG(Retrieval-Augmented Generation)系统不同,MCP 让 AI agent 能够实时动态构建并执行复杂任务,模拟人类解决问题的灵活性。
在实际应用中,这意味着业务分析师可以针对市场趋势提出一系列越来越具体的问题,MCP 驱动的系统会智能地选择并组合合适的数据源和分析工具,提供全面的答案,同时保持上下文,使后续问题无需重复。
例如,在分析产品发布时,AI 可能会整合销售报告、客户反馈和社交媒体情绪的数据,同时协调多个工具来提供整体视图,从而帮助企业挖掘更深层次的洞察并做出明智决策------这一切都通过与数据系统的自然语言交互来实现。
Agents
Agent 是由 AI 驱动的软件应用程序,可以在最少人工监督的情况下进行思考、规划和行动,以实现特定目标。它们使用基础模型(先进的 AI 模型)来理解并完成复杂任务。
AI agent 有两种类型。
知识型 AI agent
这些 agent 专注于企业知识。它们从公司数据 ------ 文档、日志、仪表板、通信和客户记录中收集上下文,并利用这些信息来完成业务任务。
示例:一个知识型 AI agent 可以跨合同、政策和历史工单进行搜索,帮助客户支持代表即时解决问题。
通用型 AI agent
这些 agent 更进一步。它们能够理解目标,并在更广泛的跨领域工作流中代表用户自主执行任务。
示例:一个通用型 AI agent 可以预订差旅、管理日程,并与其他系统协作完成用户的端到端请求。
Elastic 在 agentic AI 中的角色
对于知识型 AI agent:Elastic 提供对企业数据的安全访问,检索相关上下文,并将响应建立在事实之上。
对于通用型 AI agent:Elastic 作为知识存储和上下文引擎,提供可信信息,使 agent 能执行更复杂、以目标为导向的任务。
简而言之,Elastic 不只是存储数据;它让企业知识可用、可操作,并为 AI 做好准备。这是构建既能理解又能行动的智能 agent 的基础。
AWS 合作与 MCP 服务器
Elastic 已获得 AWS Generative AI Competency 资质。该认证授予那些能够提供前沿生成式 AI 解决方案的 AWS 合作伙伴,这些方案在业务效率、创造力和生产力方面带来可衡量的提升。
Elastic 还集成了 Model Context Protocol (MCP),为 AI agent 和应用程序通过自然语言对话与 Elasticsearch 数据交互提供无缝方式。
借助 MCP 服务器,你可以从任何 MCP 客户端(如 Claude Desktop、MCP Inspector 或 agentic 应用程序)直接连接到 Elasticsearch。Elasticsearch MCP 服务器可免费使用(但可能会产生基础设施和 Elasticsearch 集群费用)。
随着 Amazon Bedrock 模型(如 Anthropic 的 Claude)支持 MCP 客户端,组织现在可以比以往更轻松、更强大地部署智能、具备数据感知能力的 agent。
Amazon Bedrock AgentCore
Amazon Bedrock AgentCore 是一个企业级编排平台,专为可扩展的 AI agent 部署和管理而设计。
- 该平台提供无服务器运行时环境,并具备会话隔离能力,支持在多个框架下并发运行 agent。
- 它实现了用于会话状态和持久存储的内存管理系统,便于实现具备上下文感知的模型交互和学习能力。
- 架构包含可观测性功能,支持细粒度日志、指标收集和高级调试,用于分析 agent 的运行轨迹。
- 该平台强大的身份和访问管理层,使服务之间能够安全认证,并对 AWS 和第三方服务集成提供细粒度的授权控制。
它还配备协议无关的网关,用于 API 转换和工具发现,支持符合 MCP 的接口。基础设施还包括容器化的浏览器实例,用于网页自动化工作流,以及隔离的计算环境,用于安全代码执行。这个端到端的解决方案消除了构建自定义基础设施组件的需求,同时保持企业级的安全和合规标准。
解决方案概览
高层架构
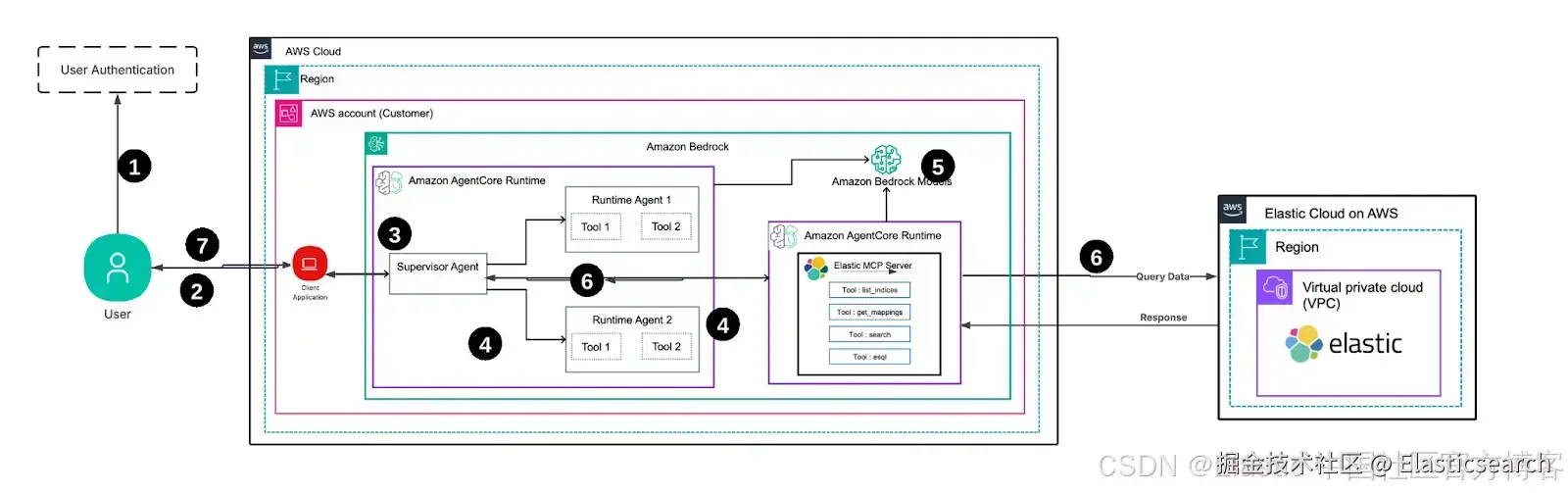
该架构由四个主要组件组成:
-
Python 客户端:处理用户交互和 AWS 身份验证
-
Amazon Bedrock AgentCore Runtime:提供无服务器托管和会话管理
-
Elastic MCP 服务器:处理 MCP 协议请求并查询 Elasticsearch
-
Elasticsearch 集群:存储和索引可搜索数据
逐步工作流演练
-
用户通过 OAuth 等身份验证机制进行认证。
-
用户使用已认证凭据访问运行在客户 AWS 账户中的安全客户端应用程序。
-
客户端应用程序调用 Supervisor Agent,该 Agent 进一步调用并编排其他 Agent。
-
所有 Agent 部署在 Amazon AgentCore Runtime 上,并为这些 Agent 提供工具,包括 Elastic 的 MCP 服务器及其工具。
-
基础模型通过 Amazon Bedrock 提供给 agentic AI 应用程序。
-
Elastic Cloud 部署在 AWS 上,其端点由 Elastic MCP 服务器访问。Elastic MCP 服务器会自动构建所需查询,对 Elastic 数据运行查询,并将结果返回给 Supervisor Agent。
-
Supervisor Agent 通过客户端应用程序将结果返回给最终用户。
实施指南
请参考此 GitHub 仓库,获取该解决方案的实践操作示例。开始前请特别注意先决条件。
步骤 1:将 Elastic MCP 服务器部署到 ECR
自动化部署脚本会处理整个容器构建和上传过程:
bash
`./deploy-elastic-mcp.sh`AI写代码执行脚本时,它会完成以下操作:
-
下载官方 Elastic MCP 服务器仓库
-
使用 Dockerfile-8000 构建 Docker 容器
-
创建启用镜像扫描的 ECR 仓库
-
将容器镜像上传到 ECR,并进行正确标记
步骤 2:创建 AgentCore Runtime 主机
在 AWS 控制台中配置你的 AgentCore Runtime:
1)访问 AgentCore:进入 Amazon Bedrock AgentCore > Build and Deploy > Agent Runtime > Host Agent
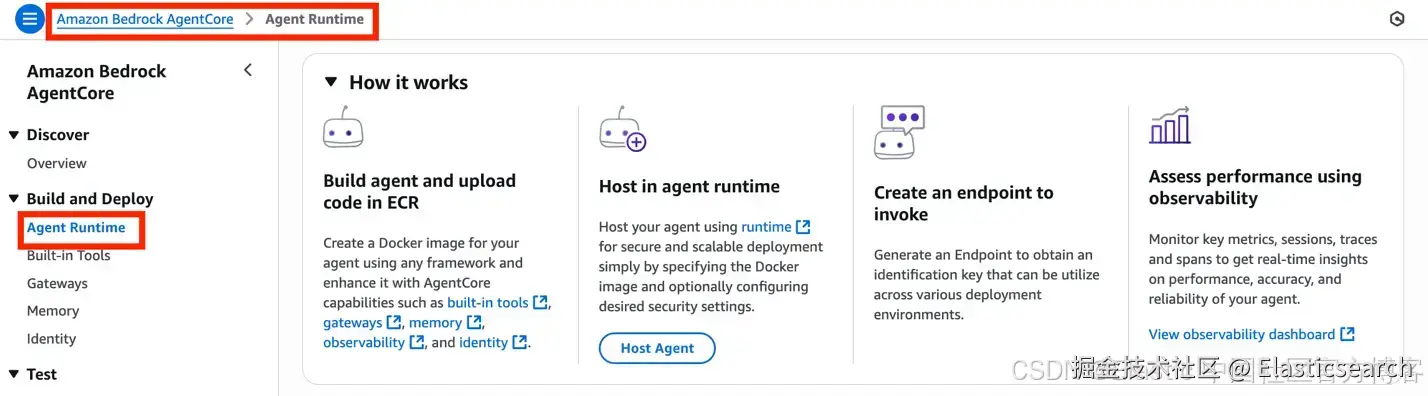
2)基本配置:点击 "Host Agent",如需可为其命名一个有意义的名称。指向你已上传到 Amazon ECR 的容器镜像。
vbnet
`1. Name: hosted_agent_elastic_mcp
2. Container Image: [ECR URI from Step 1]`AI写代码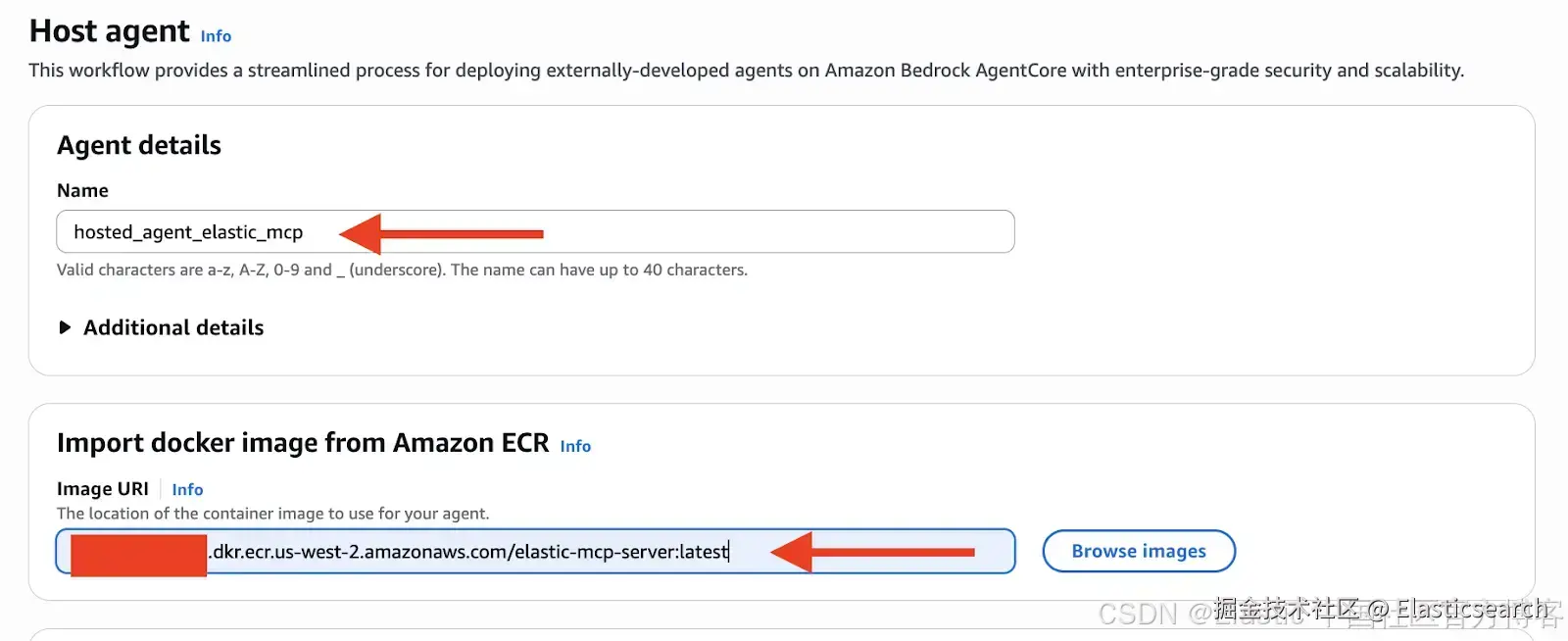
3)服务角色:选择 "Create and use a new service role"
4)协议设置:选择 MCP,对于入站身份验证,选择 Use IAM username

5)环境变量:最后,配置你的 Elasticsearch 端点,并将其作为环境变量传递给 Docker 容器。
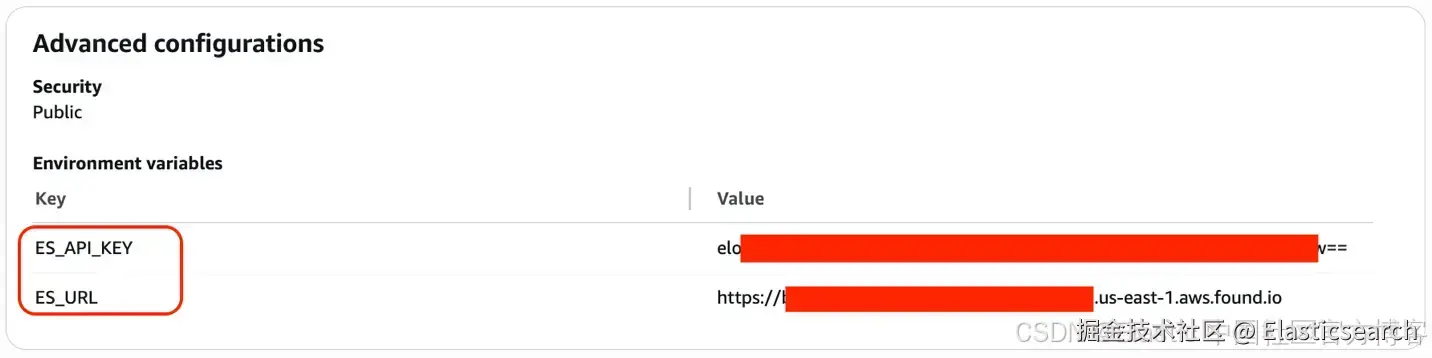
6)创建主机 Agent 后,前往 "View invocation code" 部分,复制 Agent Runtime ARN。示例如下:
bash
`arn:aws:bedrock-agentcore:us-west-2:XXXXXXXXXX:runtime/hosted_agent_elastic_mcp-xWSaxNGjf5`AI写代码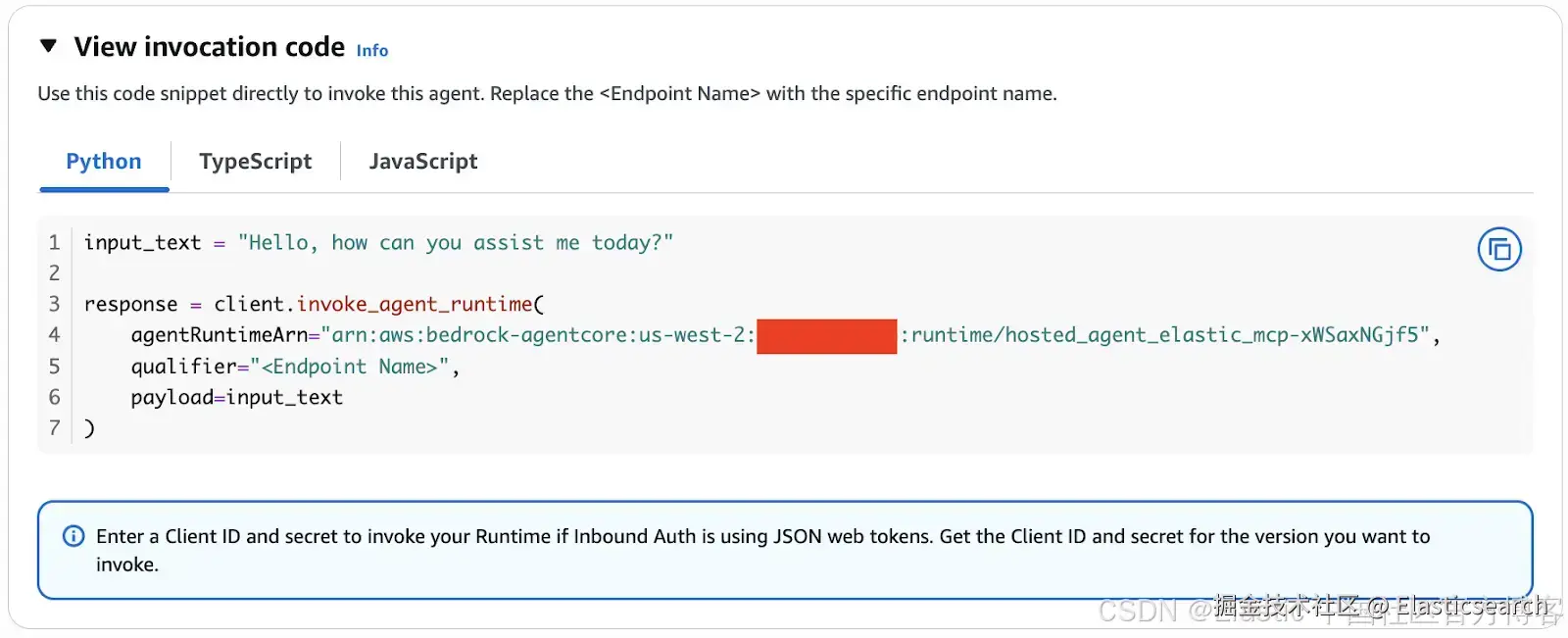
步骤 3:配置 Python 客户端
安装依赖:
创建虚拟环境并安装所需的 Python 库。
bash
`
1. python3 -m venv venv
2. source venv/bin/activate # On Windows: venv\Scripts\activate
3. pip install -r requirements.txt
`AI写代码在 my_mcp_client_remote.py 中更新 Agent ARN:
接下来,将你在前面步骤中获取的 Agent ARN 更新到 Python MCP 客户端中。
ini
`agent_arn = "arn:aws:bedrock-agentcore:us-west-2:XXXXXXXX:runtime/hosted_agent_elastic_mcp-xWSbYNGjf5"`AI写代码以下是该 Python 文件中的关键客户端组件。
AWS 身份验证类:
python
`
1. class AWSAuth:
2. def __init__(self, service='bedrock-agentcore', region='us-west-2'):
3. self.session = boto3.Session()
4. self.credentials = self.session.get_credentials()
5. self.region = region
6. self.service = service
8. def get_auth_headers(self, url, method='POST', body=None):
9. request = AWSRequest(method=method, url=url, data=body)
10. SigV4Auth(self.credentials, self.service, self.region).add_auth(request)
11. return dict(request.headers)
`AI写代码MCP 请求构建 / payload:
bash
`
1. chat_request = {
2. "jsonrpc": "2.0",
3. "id": 3,
4. "method": "tools/call",
5. "params": {
6. "name": "search",
7. "arguments": {
8. "index": "events",
9. "query_body": {
10. "query": {
11. "bool": {
12. "should": [
13. {"match": {"name": "paris"}},
14. {"match": {"description": "paris"}},
15. {"match": {"venue": "paris"}},
16. {"match": {"address": "paris"}}
17. ]
18. }
19. },
20. "size": 10
21. }
22. }
23. }
24. }
`AI写代码步骤 4:运行客户端
执行 Python 客户端以测试集成。该 Python 程序实现了一个异步客户端,用于与 Amazon Bedrock AgentCore 交互,专门设计用于查询事件信息。代码使用 AWS SigV4 身份验证,并包含两个主要函数:test_mcp_endpoint() 和 chat_with_agentcore()。
-
第一个函数展示了基本的 API 交互,包括列出可用工具和执行搜索查询
-
第二个函数实现了更复杂的搜索功能,专门用于查询巴黎的事件
程序使用 httpx 库进行异步 HTTP 请求,并处理 Server-Sent Events (SSE) 响应,解析并显示事件详情,包括名称、地点、日期和描述。身份验证由自定义的 AWSAuth 类管理,处理 AWS SigV4 请求签名。代码包含全面的错误处理和格式化输出显示,适合用于测试和生产环境。
go
`python my_mcp_client_remote.py`AI写代码用例演示
用例 1:数据发现
场景:使用自然语言查找特定城市的事件。
查询:"Events in Paris"
MCP 请求:以下是你提供给 Amazon Bedrock AgentCore Runtime 的 payload。
bash
`
1. {
2. "jsonrpc": "2.0",
3. "method": "tools/call",
4. "params": {
5. "name": "search",
6. "arguments": {
7. "index": "events",
8. "query_body": {
9. "query": {
10. "bool": {
11. "should": [
12. {"match": {"name": "paris"}},
13. {"match": {"description": "paris"}},
14. {"match": {"venue": "paris"}},
15. {"match": {"address": "paris"}}
16. ]
17. }
18. }
19. }
20. }
21. }
22. }
`AI写代码响应:以下是在 Elastic 的 MCP 服务器对 Elastic Search AI 平台运行查询并返回结果后得到的响应。
markdown
`
1. 🎉 I found 1 events in Paris:
4. 1. Paris Fashion Week
5. 📍 Murray-Howell Theater - 17814 Mills Mountains Apt. 815, Poncetown, DE 29241
6. 📅 2026-04-02
7. 📝 Major fashion event showcasing the latest collections from top designers.
8. 💰 $$$
9. 🎫 https://tickets.reed.net/event/DEST0001_EVT002
`AI写代码用例 2:Elastic MCP 工具发现
场景:发现 Elastic 的 MCP 服务器提供的可用 MCP 工具。
MCP 请求:
json
`
1. {
2. "jsonrpc": "2.0",
3. "method": "tools/list",
4. "id": 1
5. }
`AI写代码这会返回 MCP 服务器提供的可用工具列表,从而实现动态工具发现。
用例 3:复杂搜索查询
场景:使用多个条件进行高级筛选。
你可以运行基于 Elastic Search Query Language 的更高级查询,例如如下示例。
查询:具有特定价格范围、日期和类别的事件
MCP 请求:
bash
`
1. {
2. "jsonrpc": "2.0",
3. "method": "tools/call",
4. "params": {
5. "name": "search",
6. "arguments": {
7. "index": "events",
8. "query_body": {
9. "query": {
10. "bool": {
11. "must": [
12. {"range": {"start_date": {"gte": "2026-01-01"}}},
13. {"term": {"price_range": "$$$"}}
14. ],
15. "should": [
16. {"match": {"type": "Fashion"}},
17. {"match": {"type": "Music"}}
18. ]
19. }
20. },
21. "size": 20
22. }
23. }
24. }
25. }
`AI写代码工作原理(技术深入)
MCP 实现
Model Context Protocol 在所有通信中使用 JSON-RPC 2.0 格式:
vbscript
`Client Request → AgentCore → MCP Server → Elasticsearch → Response Chain`AI写代码关键协议特性:
-
无状态操作:每个请求独立,具有会话隔离
-
工具发现:动态发现可用功能
-
结构化响应:所有工具保持一致的响应格式
-
错误处理:标准化的错误报告和恢复
AWS 身份验证流程:
scss
`
1. # 1. Create AWS request object
2. request = AWSRequest(method='POST', url=mcp_url, data=body)
5. # 2. Apply SigV4 authentication
6. SigV4Auth(credentials, 'bedrock-agentcore', region).add_auth(request)
9. # 3. Extract headers for HTTP client
10. headers = dict(request.headers)
11. headers["Content-Type"] = "application/json"
12. headers["Accept"] = "application/json, text/event-stream"
`AI写代码会话管理
AgentCore 自动添加 Mcp-Session-Id 头以实现会话隔离:
-
每个客户端会话获得唯一标识符
-
无状态服务器可以维护对话上下文
-
自动清理不活跃的会话
响应处理流程
-
Server-Sent Events (SSE) :响应以
data: {...}的 JSON 格式返回 -
JSON 解析:从 SSE 包装中提取 JSON
-
内容提取:解析 MCP 结果结构
-
数据格式化:将 Elasticsearch 结果转换为用户友好格式
ini
`
1. # Parse SSE response
2. if response.text.startswith('data: '):
3. json_part = response.text[6:] # Remove 'data: ' prefix
4. response_json = json.loads(json_part)
6. # Extract search results
7. result = response_json.get('result', {})
8. for content_item in result['content']:
9. if content_item['type'] == 'text':
10. # Process and format results
11. search_results = json.loads(content_item['text'])
`AI写代码清理
在你完成此设置的试用后,如果想清理环境,请按照以下步骤操作。
删除 AgentCore Runtime:
-
在 AWS 控制台中进入 Amazon Bedrock AgentCore
-
选择你的 agent runtime
-
点击 "Delete" 并确认
移除 ECR 仓库:
markdown
`
1. aws ecr delete-repository \
2. --repository-name elastic-mcp-server \
3. --region us-west-2 \
4. --force
`AI写代码清理本地环境:
markdown
`
1. # Remove virtual environment
2. deactivate
3. rm -rf venv
5. # Remove cloned repository
6. rm -rf mcp-server-elasticsearch
8. # Remove Docker images
9. docker rmi elastic-mcp-server:latest
10. docker rmi [ECR_URI]:latest
`AI写代码结论
通过在 Amazon Bedrock AgentCore Runtime 上部署 Elastic 的 MCP 服务器,我们创建了一个强大、可扩展、可用于生产的自然语言与 Elasticsearch 数据交互的解决方案。该实现为数据探索和分析开辟了新可能,使复杂查询能够通过简单对话完成。
关键要点:
-
无缝集成:MCP 协议支持对复杂数据的自然语言查询
-
生产级可扩展性:AgentCore 提供企业级托管,配置最少
-
开发者效率:本地原型可通过最少代码更改转为生产环境
-
安全优先:内置 AWS 安全与身份验证机制
潜在应用领域:
-
客户支持:自然语言查询支持工单数据库
-
商业智能:业务指标的对话式分析
-
内容发现:跨文档库的智能搜索
-
物联网数据分析:传感器和遥测数据的自然语言查询
附加资源: