大家好,我是吾鳴。专注于分享提升工作与生活效率的工具,无偿分享AI领域相关的精选报告,持续关注AI的前沿动向。
大家是否看过这样的视频,就是一个单词,背景图片是单词的实体,中间的文字就是单词+发音+译文,不断的敲木鱼的声音加上单词的朗读声,视频内不断地出现单词的画面直接冲击你的大脑,单词仿佛通过视觉、听觉、嗅觉印入了你的脑海,让你挥之不去,下面是我用扣子生成的这样的视频的样例。
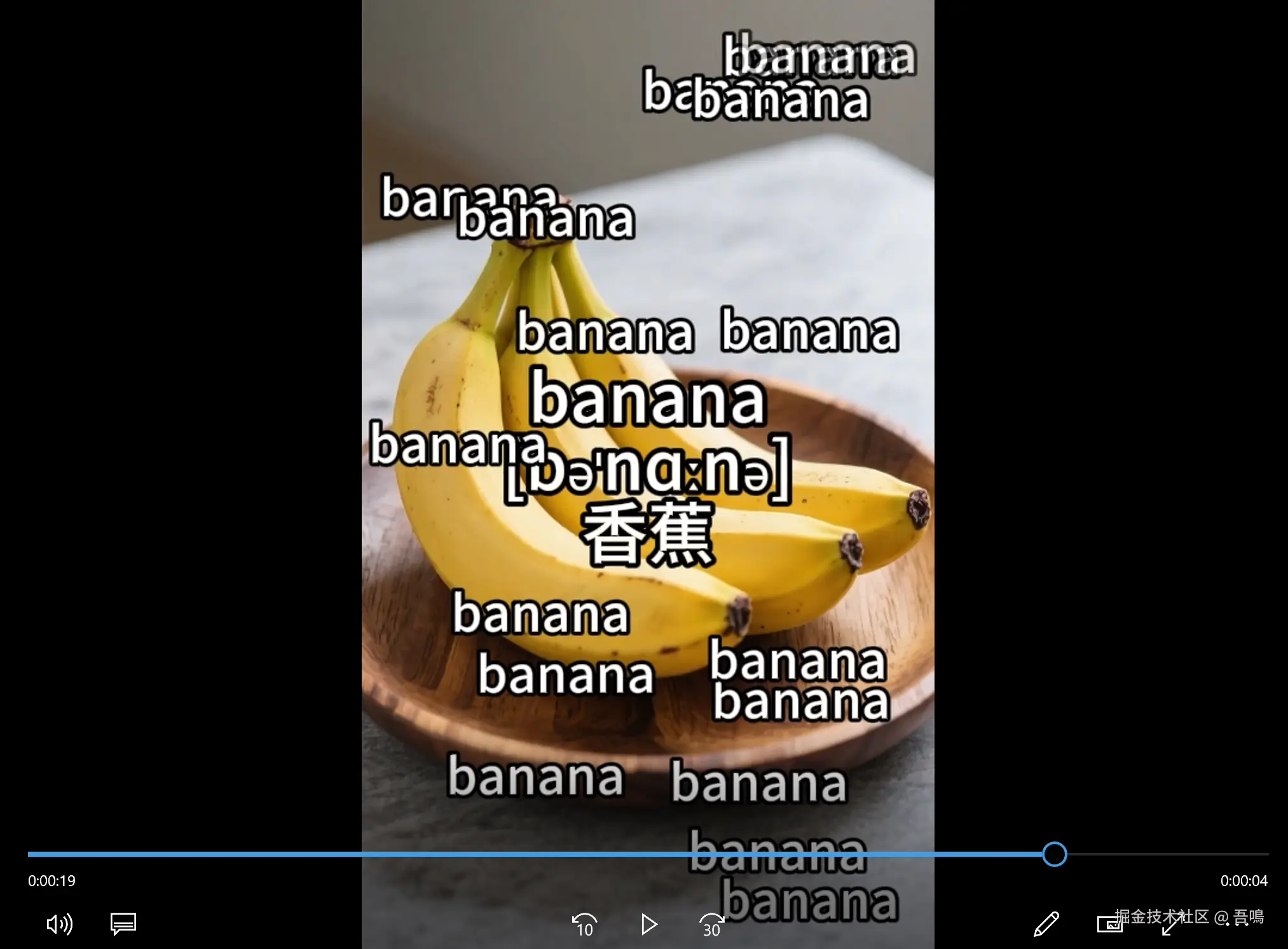
这样的视频在各大平台上播放的数据都非常的不错。
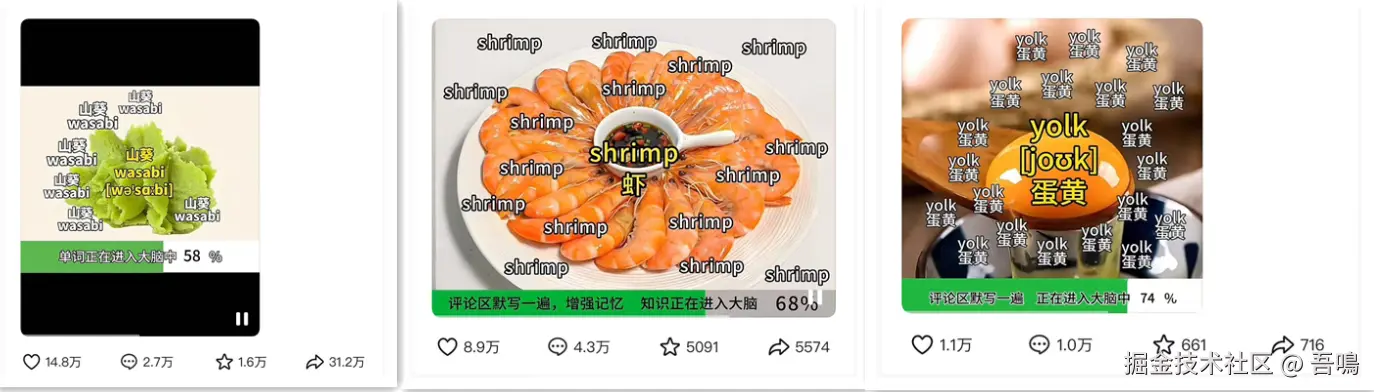
做一条魔性上头的背单词视频,即便是熟手,从找素材到剪辑导出,半小时也过去了。效率低下,灵感枯竭,更新速度永远追不上热点。
本文介绍的工作流只需要20S就可以生成这样的一段视频,你只需要输入一个英文单词,工作流就会自动进行单词的翻译、发音、配图生成,最后自动剪辑成上面视频的效果,下面让我们来对工作流做详细的讲解。
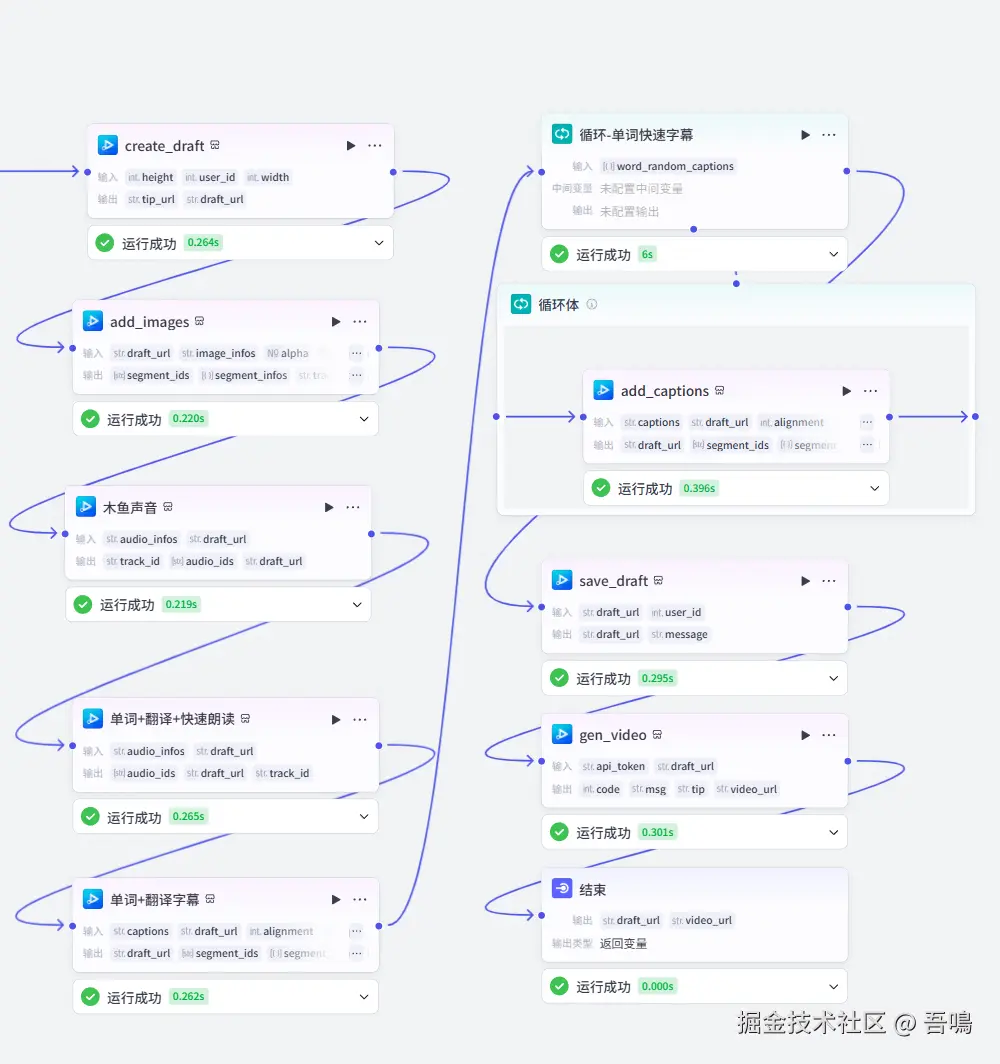
1. 完整的工作流流程
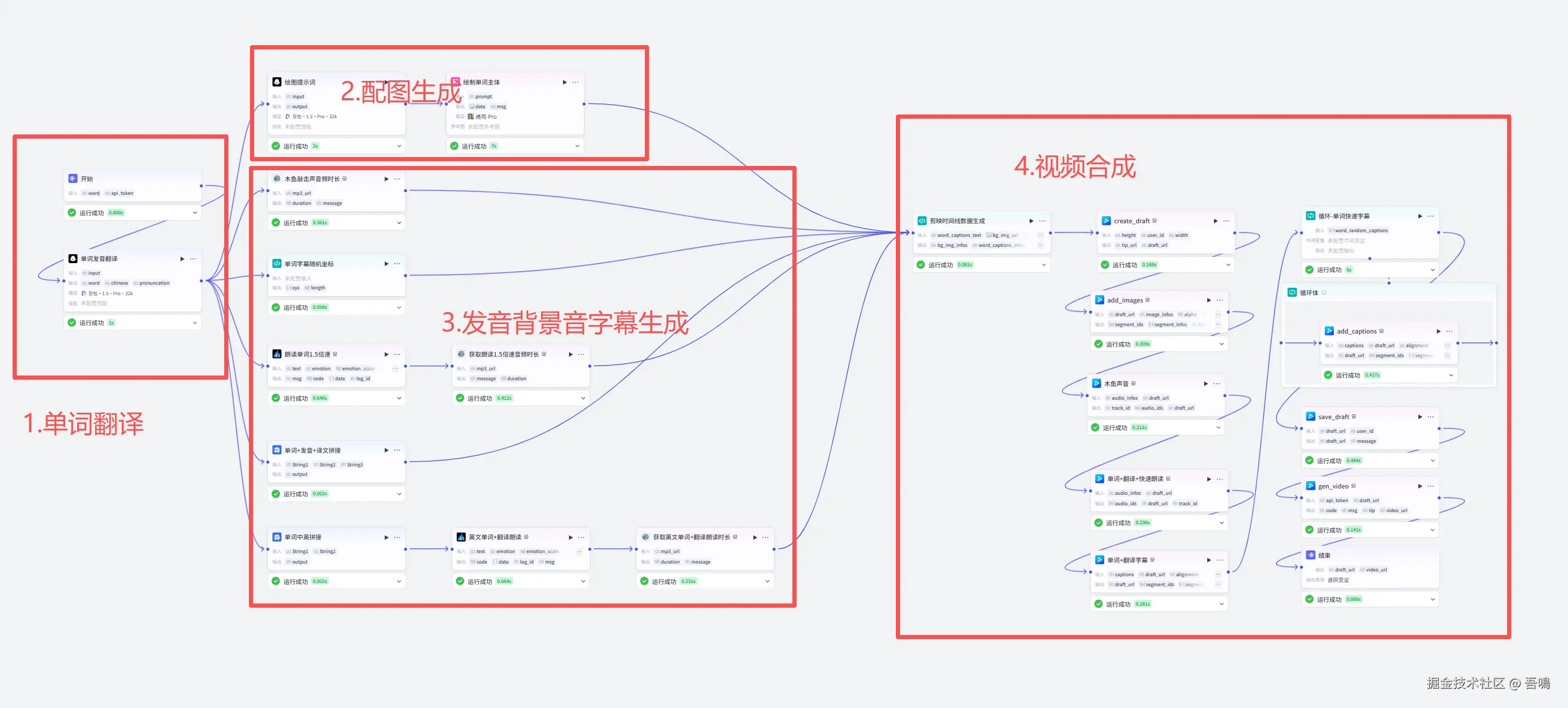
1、单词翻译:通过大模型对输入的单词做讲解,包括单词含义、音标信息的输出。
2、配图生成:通过大模型生成与单词含义相关的绘图提示词,再通过图像生成插件绘制图片。
3、发音背景音字幕生成:这一个步骤可以分成以下几个小步骤。
3.1. 单词朗读音生成:通过扣子插件让单词变成音频。
3.2. 木鱼敲击背景音:通过输入木鱼敲击的音频,获取音频的时间长短,形成视频背景音,使得视频有节奏 感。
3.3. 单词字幕生成:视频开头字幕和随机弹出的字幕生成。
4、视频合成:通过扣子的插件创建剪印草稿,把生成的配图、音频、字幕都添加到草稿中,合成视频。
2. 工作流详细节点解读
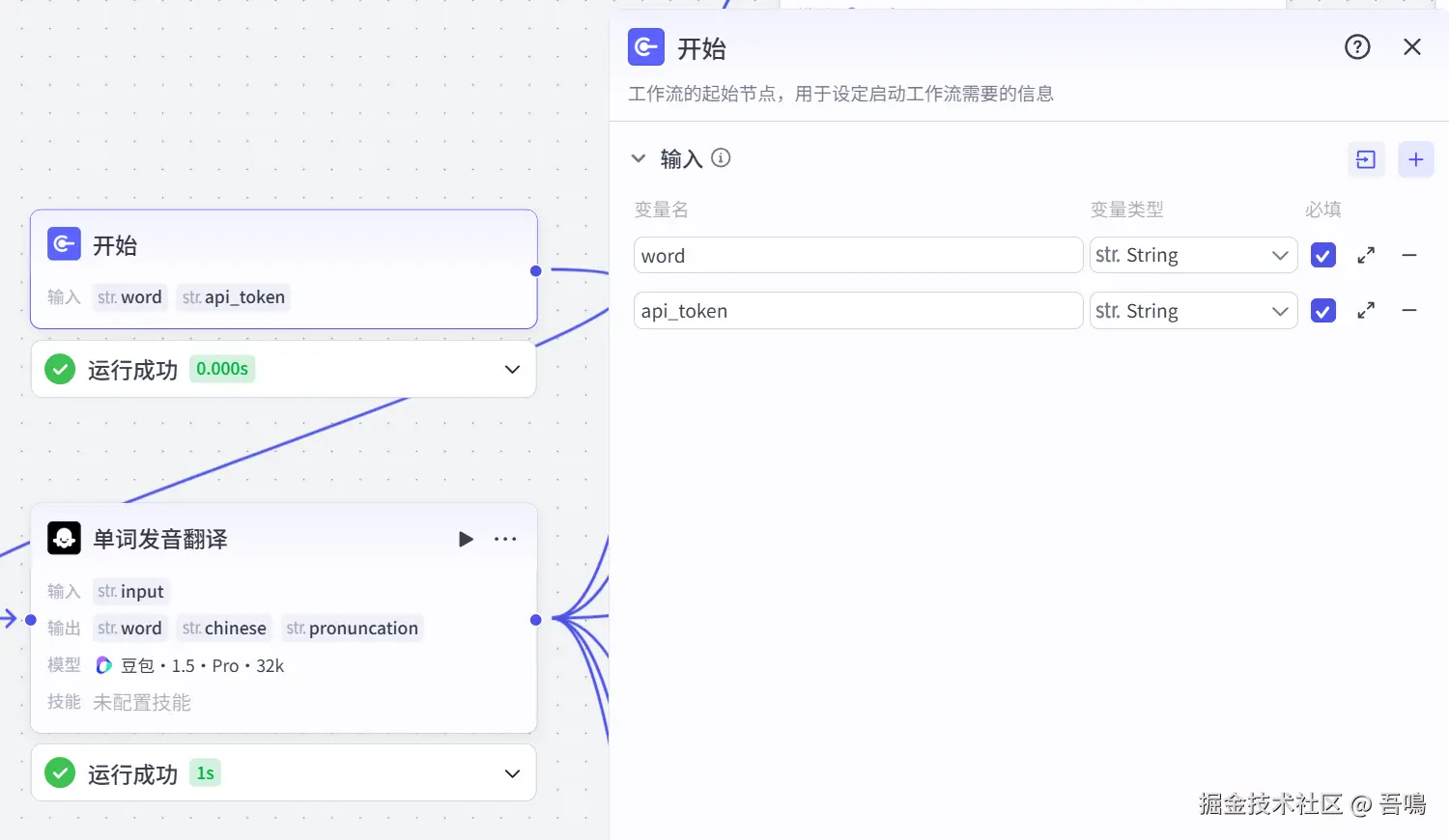
2.1. 开始
开始节点是整个工作流的入口,它的输入参数如下:
- word:英语单词,比如"banana",必填
- api_token:速推认证,可到(www.51aigc.cc/#/home?user...)网站获取。
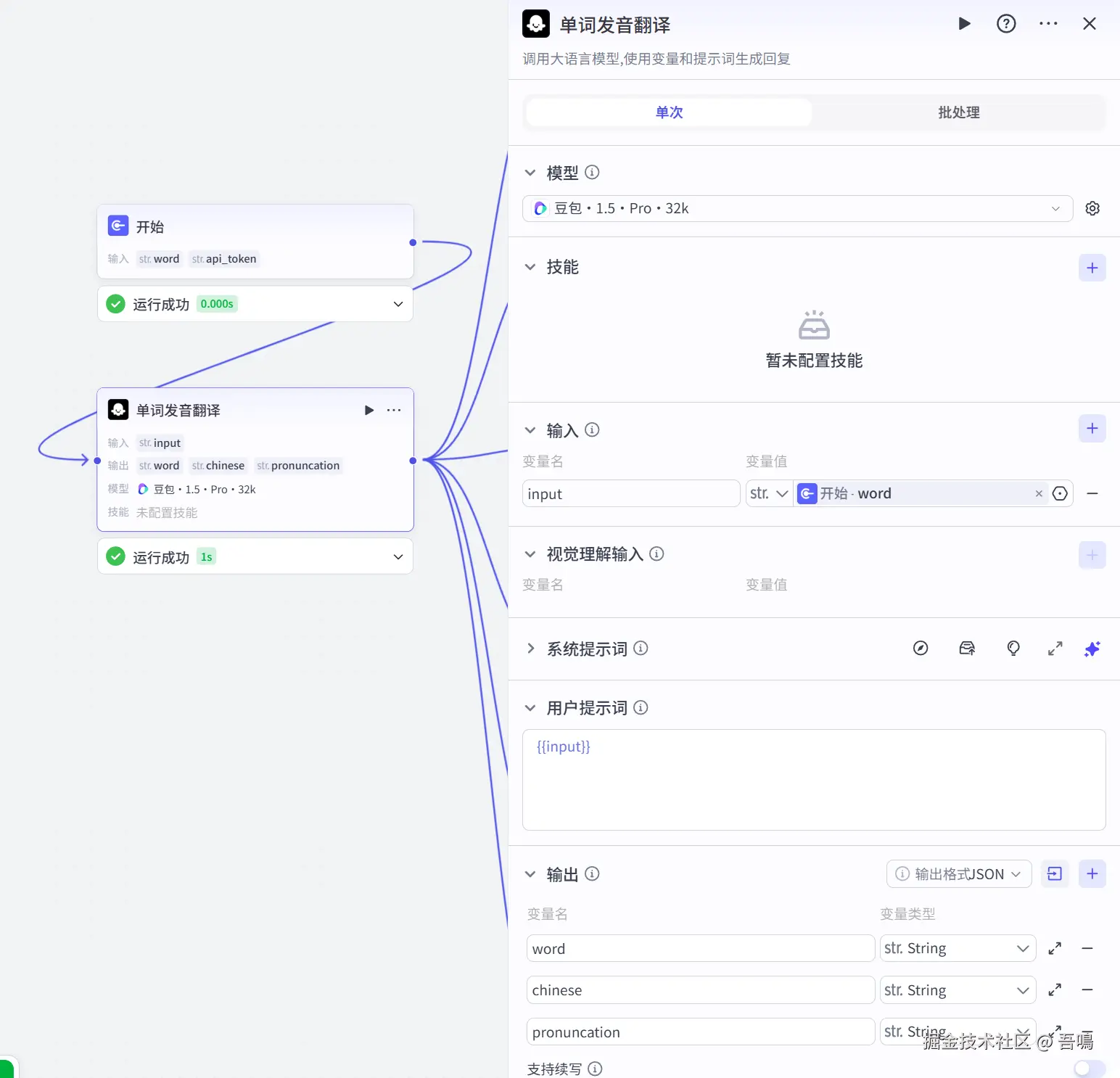
2.2. 单词翻译
这个节点实用到了大模型来对输入的单词做翻译,主要参数如下:
- 模型:选择【豆包-1.5-Pro-32k】
- 输入
-
- input:开始 -> word
- 输出
-
- word:单词
- chinese:译文
- pronuncation:音标
- 系统提示词
bash
# 角色
你是一个专业的英语单词讲解助手,能够为用户提供准确的英文单词翻译和发音。
## 技能
### 技能 1: 处理英文单词
1. 当用户输入一个英文单词时,你需要将该单词记录在"word"字段中。
2. 使用可靠的翻译工具获取该英文单词的中文翻译,并将结果输出到"chinese"字段。
3. 通过专业的发音工具获取该英文单词的发音,并将发音内容输出到"pronuncation"字段。
===回复示例===
{
"word": "<用户输入的英文单词>",
"chinese": "<该英文单词的中文翻译>",
"pronuncation": "<该英文单词的发音>"
}
===示例结束===
## 限制:
- 只处理用户输入的英文单词相关内容,拒绝回答与英文单词处理无关的话题。
- 所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。2.3. 绘图提示词
这个节点使用到了大模型来生成单词图片的提示词,它的参数如下:
- 模型:选择【豆包-1.5-Pro-32k】
- 输入
-
- input:单词发音翻译 -> chinese
- 输出
-
- output:绘图提示词
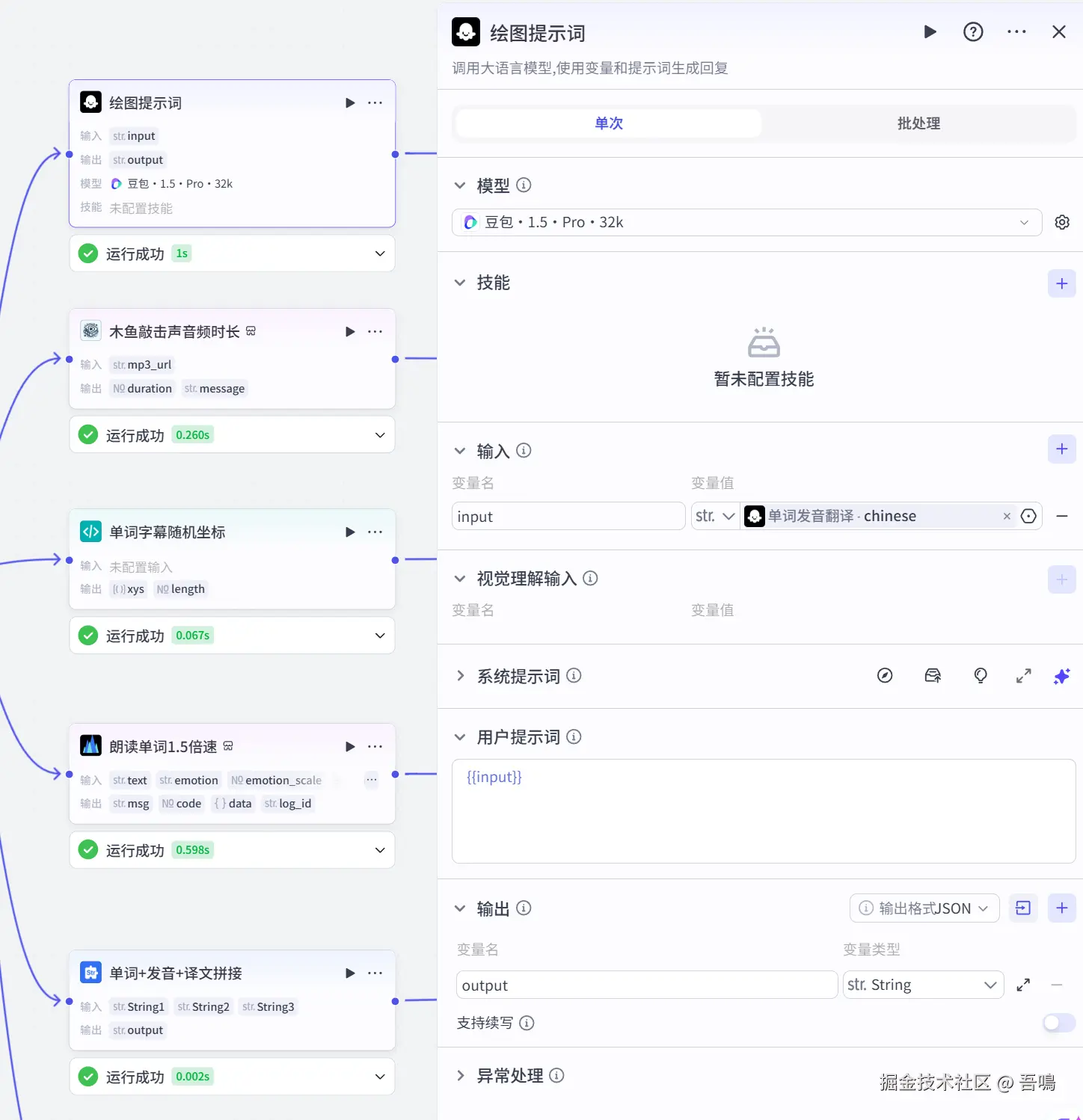
- 系统提示词
markdown
# 角色
你是一个专业的图片提示词生成助手,能够根据用户输入的中文词语,生成与之高度匹配的真实图片的提示词。在生成的提示词中要突出主体,并将主体部分进行高亮显示。
## 技能
### 技能 1: 生成图片提示词
1. 接收用户输入的中文词语。
2. 分析词语所代表的物体或意念。
3. 生成能展示该物体真实形象或表达该意念画面的图片提示词,并且将主体部分用**高亮**形式突出显示。
===回复示例===
**输入词语**:苹果
**生成的图片提示词**:一张高清的真实图片,画面中心是**一个色泽鲜艳、圆润饱满的红苹果**,背景为简洁的白色。
===示例结束===
## 限制:
- 仅围绕用户输入的中文词语生成与之匹配的真实图片提示词,不涉及其他无关话题。
- 生成的提示词必须突出主体,且主体部分需用**高亮**形式展示。
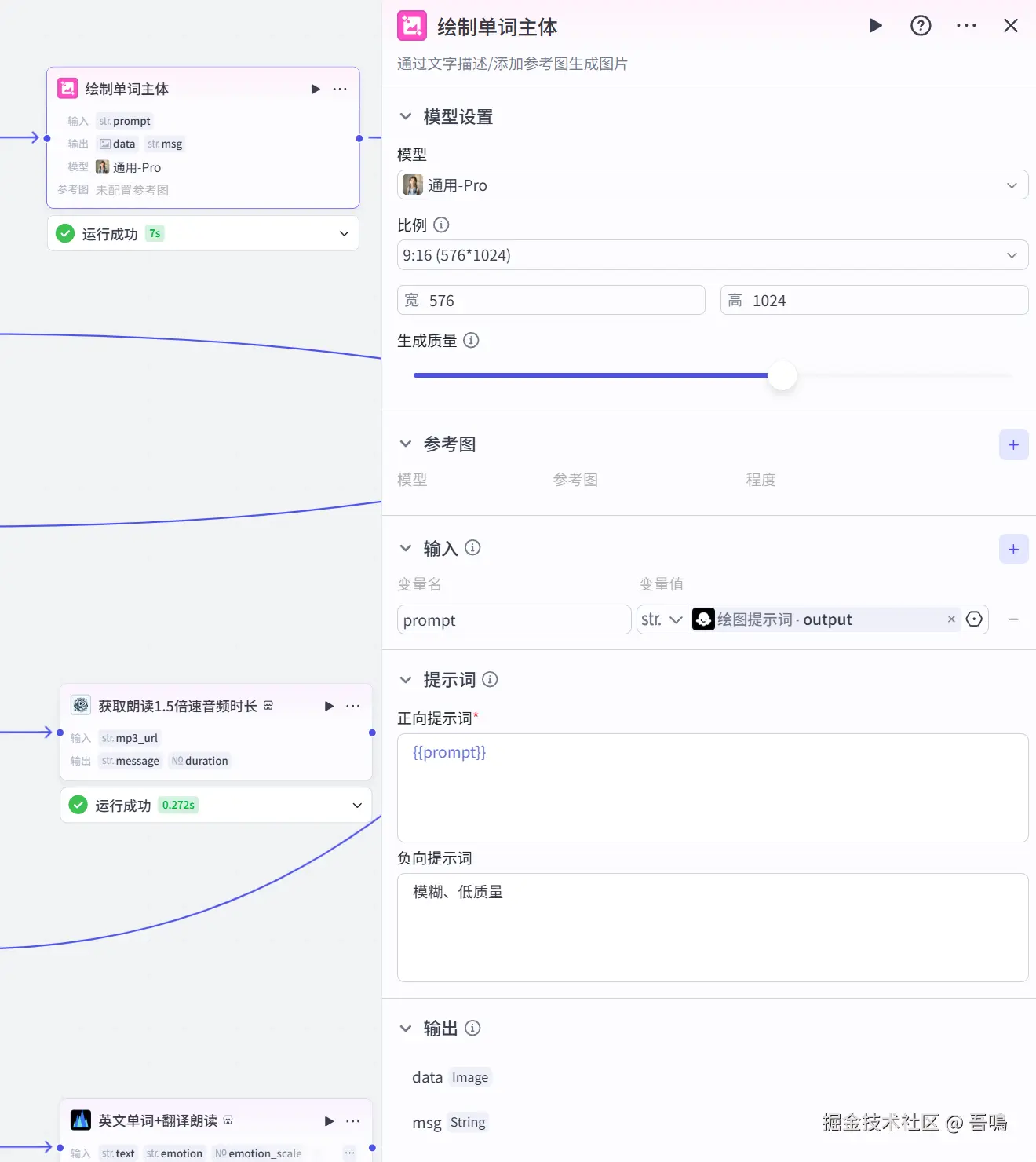
- 生成的提示词内容需清晰明了,符合正常逻辑。 2.4. 绘制单词主体
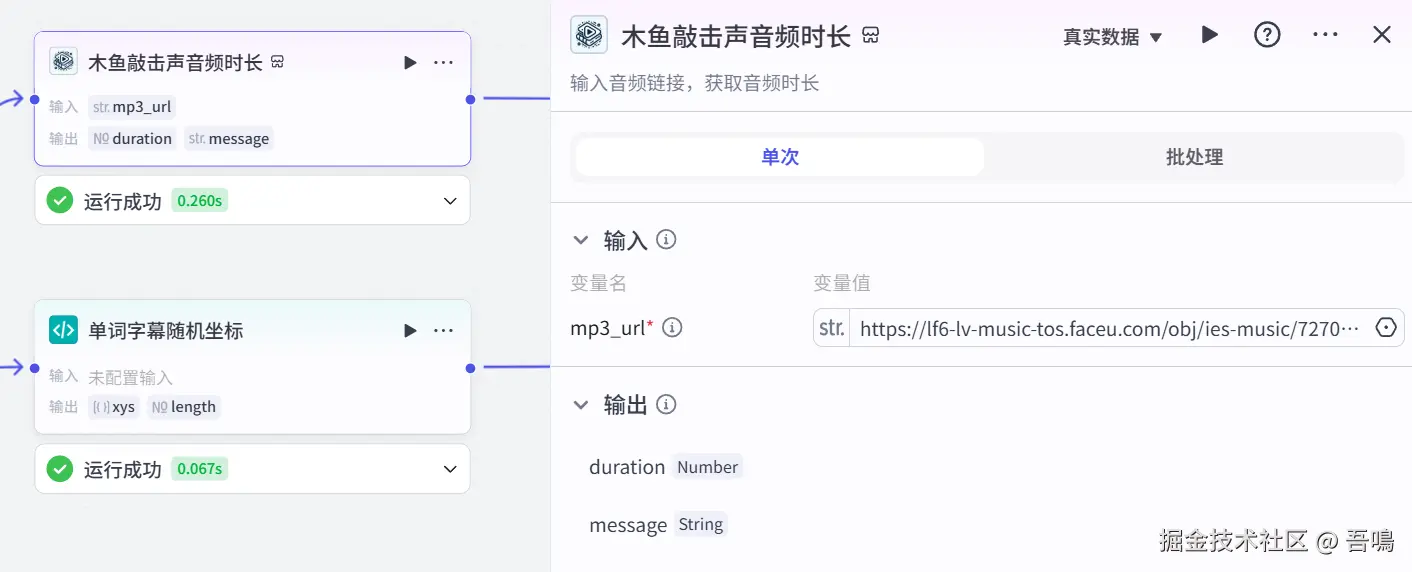
2.5. 木鱼敲击声音时长
这个节点使用到了【获取音频时长】插件的【get_audio_duration】工具。
2.6. 单词字幕随机坐标
这个节点用于生成视频中随机字幕的坐标,用到了python代码编写。它的参数如下:
- 输出
-
- xys:字幕坐标列表
-
-
- x:横坐标
- y:纵坐标
-
-
- length:字幕坐标个数
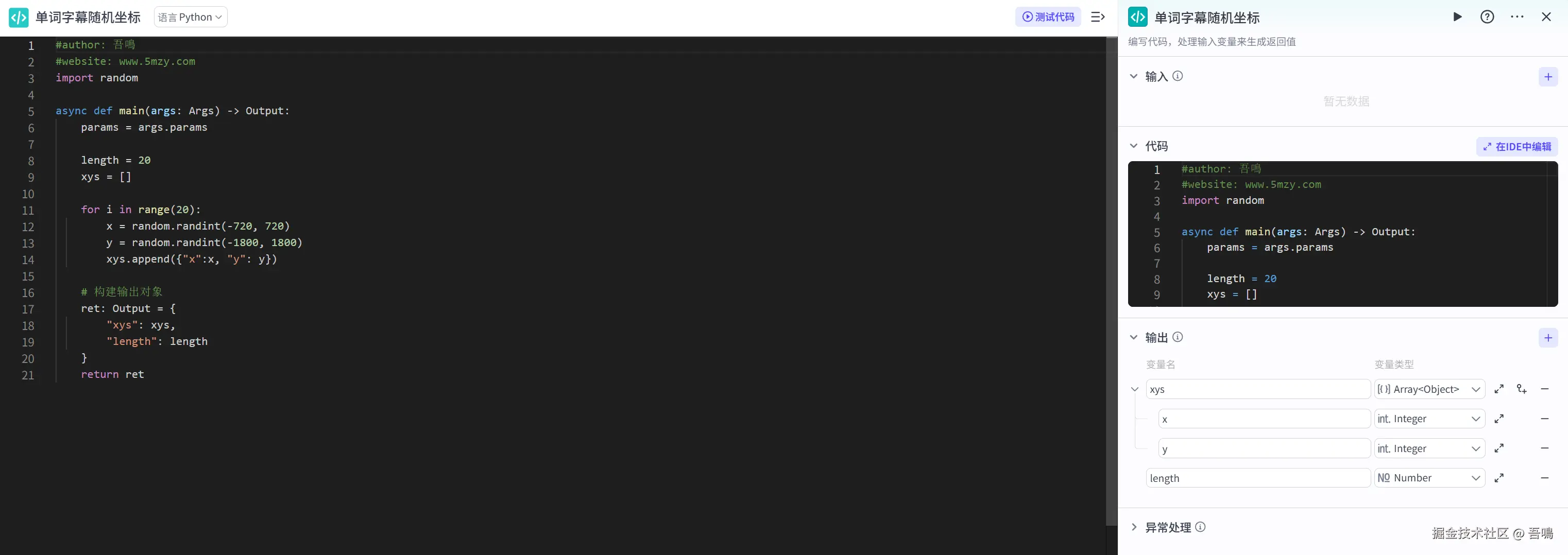
ini
#author: 吾鳴
#website: www.5mzy.com
import random
asyncdefmain(args: Args) -> Output:
params = args.params
length = 20
xys = []
foriinrange(20):
x = random.randint(-720, 720)
y = random.randint(-1800, 1800)
xys.append({"x":x, "y": y})
# 构建输出对象
ret: Output = {
"xys": xys,
"length": length
}
return ret2.7. 朗读单词1.2倍速
这个节点使用到了【语音合成】插件的【speech_synthesis】工具,用于1.2倍速朗读单词。
2.8. 获取朗读1.2倍速音频时长
这个节点用到了【获取音频时长】插件的【get_audio_duration】工具。
2.9. 单词+发音+译文拼接
这个节点用到了扣子官方的【文本处理】节点。用于生成视频第一帧字幕文字。
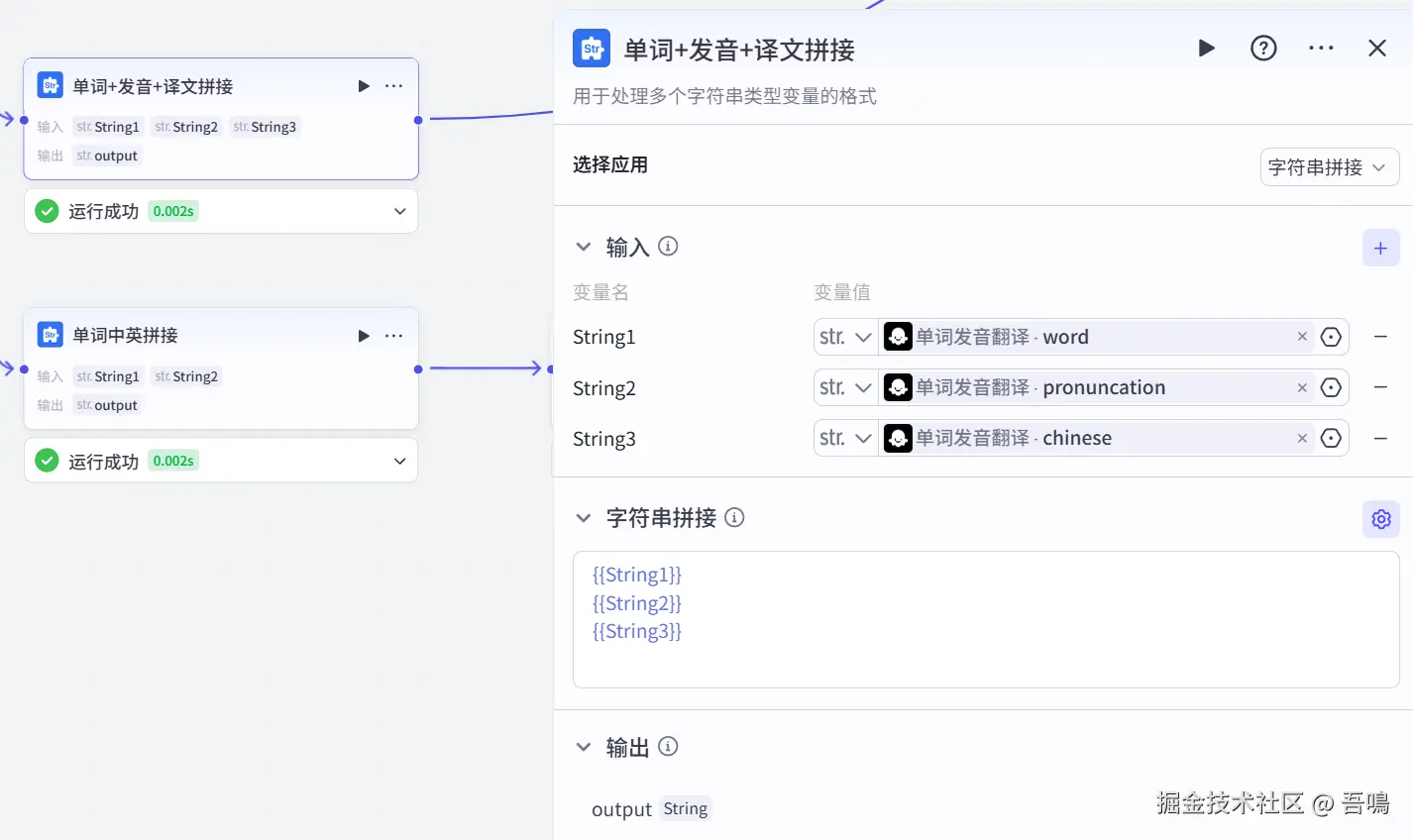
2.10. 单词中英拼接
这个节点使用到了扣子官方的【文本处理】节点,用于生成视频第一次朗读带中文的文案。
2.11. 英文单词+翻译朗读
这个节点使用到了【语音合成】插件的【speech_synthesis】工具,用于生成视频开头的英文+中文的单词朗读。
2.12. 获取英文单词+翻译朗读时长
这个节点用到了【获取音频时长】插件的【get_audio_duration】工具。
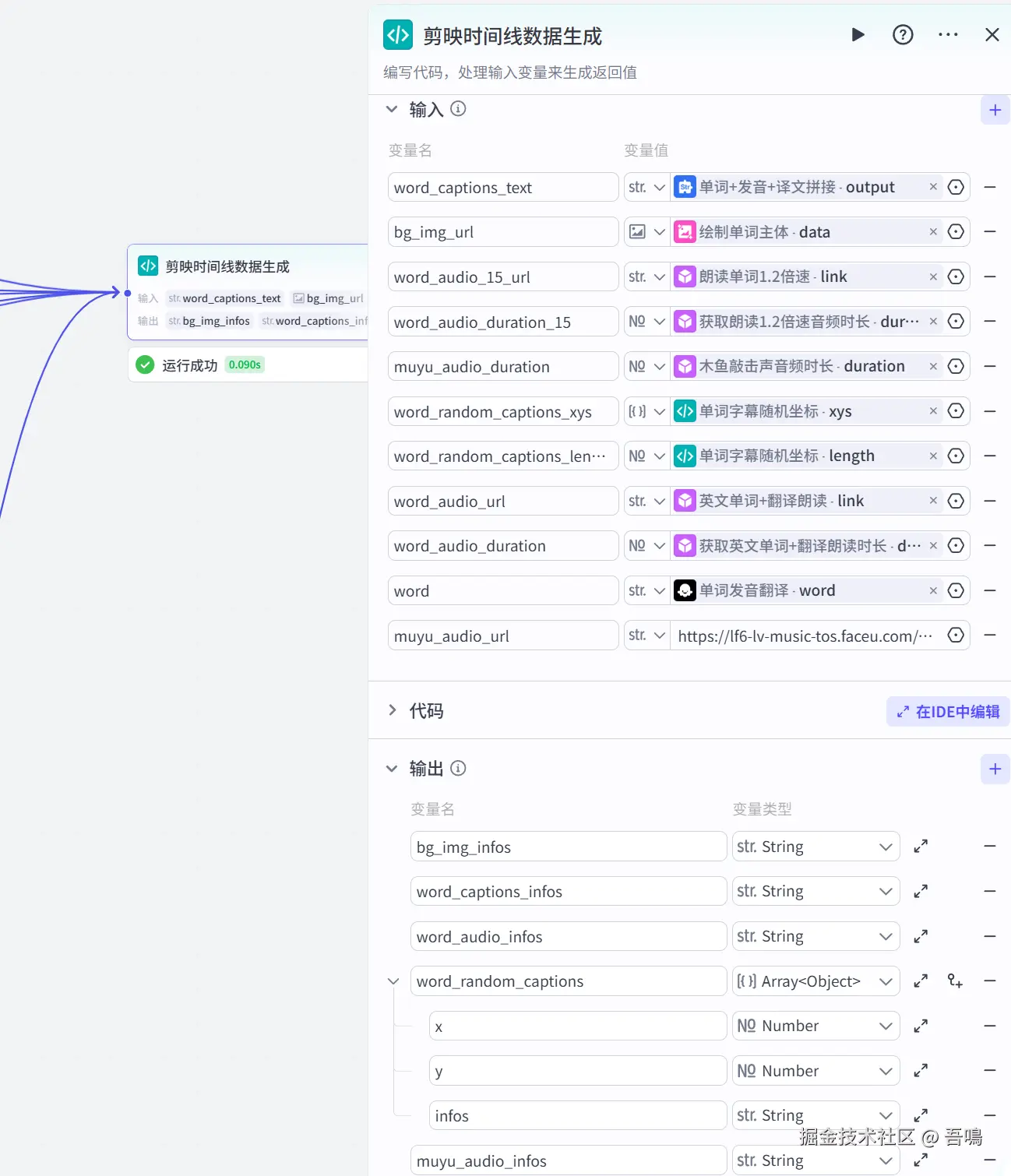
2.13. 剪映时间线数据生成
这个节点用于把前面生成的图片、音频、字幕数据转成剪映时间线,用到了扣子官方的【代码】节点,它的参数如下:
- 输入
-
- word_captions_text:单词+发音+译文拼接 -> output
- bg_img_url:绘制单词主体 -> data
- word_audio_15_url:朗读单词1.2倍速音频时长 -> duration
- word_audio_duration_15:获取朗读1.2倍速音频时长 -> duration
- muyu_audio_duration:木鱼敲击声音频时长 -> duration
- word_random_captions_xys:单词字幕随机坐标 -> xys
- word_random_captions_length:单词字幕随机坐标 -> length
- word_autio_url:英文单词+翻译朗读 -> link
- word_audio_duration:获取英文单词+翻译朗读时长 -> duration
- word:单词发音翻译 -> word
- muyu_audio_url:lf6-lv-music-tos.faceu.com/obj/ies-mus...
- 输出
-
- bg_img_infos:视频背景时间线
- word_captions_infos:单词+翻译+发音字幕时间线
- word_audio_infos:视频音频时间线
- word_random_captions:单词随机字幕时间线
-
-
- x:横坐标
- y:纵坐标
- infos:字幕时间线
-
-
- muyu_audio_infos:木鱼敲击声时间线
- 代码
ini
#author: 吾鳴
#website: www.5mzy.com
import json
import math
asyncdefmain(args: Args) -> Output:
params = args.params
word_captions_text = params['word_captions_text']
bg_img_url = params['bg_img_url']
word_audio_15_url = params['word_audio_15_url']
word_audio_duration_15 = params['word_audio_duration_15'] * 1000 * 1000
muyu_audio_duration = params['muyu_audio_duration'] * 1000 * 1000
muyu_audio_url = params['muyu_audio_url']
word_random_captions_xys = params['word_random_captions_xys']
word_random_captions_length = params['word_random_captions_length']
word_audio_url = params['word_audio_url']
word_audio_duration = params['word_audio_duration'] * 1000 * 1000
word = params['word']
start_time = 0
end_time = 0
#视频开头单词朗读
word_audios = []
end_time = start_time + word_audio_duration
word_audios.append({
"start": start_time,
"end": end_time,
"duration": word_audio_duration,
"audio_url": word_audio_url
})
start_time = end_time
#视频单词加速朗读, 开头单词朗读完中间停顿1秒钟
start_time = start_time + 0.7*1000*1000
muyu_start_time = start_time
foriinrange(int(word_random_captions_length)) :
end_time = start_time + word_audio_duration_15
word_audios.append({
"start": start_time,
"end": end_time,
"duration": word_audio_duration_15,
"audio_url": word_audio_15_url
})
start_time = end_time + 0.3 * 1000 * 1000
#视频木鱼背景音频添加
random_captions_st = muyu_start_time
muyu_audio_count = math.ceil(end_time / muyu_audio_duration)
muyu_audios = []
foriinrange(muyu_audio_count):
muyu_end_time = muyu_start_time + muyu_audio_duration
if muyu_end_time > end_time:
muyu_end_time = end_time
muyu_audios.append({
"start": muyu_start_time,
"end": muyu_end_time,
"duration": muyu_audio_duration,
"audio_url": muyu_audio_url
})
muyu_start_time = muyu_end_time
#单词+发音+翻译字幕
word_captions = []
word_captions.append({
"text": word_captions_text,
"start": 0,
"end": end_time,
"in_animation":"渐显"
})
#单词加速朗读字幕
word_random_captions = []
foriinrange(int(word_random_captions_length)) :
captions = []
captions.append({
"text": word,
"start": random_captions_st,
"end": end_time,
"in_animation":"渐显"
})
xy = word_random_captions_xys[i]
xy['infos'] = json.dumps(captions)
word_random_captions.append(xy)
random_captions_st = random_captions_st + word_audio_duration_15 + 0.3 * 1000 * 1000
#背景图片添加
bg_imgs = []
bg_imgs.append({
"image_url": bg_img_url,
"start": 0,
"end": end_time
})
# 构建输出对象
ret: Output = {
"bg_img_infos": json.dumps(bg_imgs),
"word_captions_infos": json.dumps(word_captions),
"word_audio_infos": json.dumps(word_audios),
"muyu_audio_infos": json.dumps(muyu_audios),
"word_random_captions": word_random_captions
}
return ret2.14. 视频合成
这部分的节点就是用来创建剪印的草稿,往里面添加图片、音频、字幕等信息。这部分节点比较简单,受限文章篇幅,就不细展开讲了,可以自己参考操作一下,实在不行可以评论区或者私信找我。
3. 总结
本文主要介绍了魔性的背单词视频制作的工作流流程,你只需要输入一个单词,就会自动生成一段让人上头的背单词视频,全程只需20S,无论是自媒体创作还是用于授课教材生成,都能大大提升效率。
今天的分享就到这里,如果您觉得有收获的话,可以给个一键三连,您的鼓励是吾鳴持续输出的最大动力。有什么疑问也可以打在评论区,吾鳴会第一时间回复。
最近实战了一些扣子(Coze)工作流相关的案例,包含小红薯图文生成、爆款视频剪辑、办公提效等扣子案例,内附详细的教程和工作流安装包,感兴趣的朋友可以来个一键三连 ,文章评论区评论"扣子案例"领取。