- 作者:Ziyu Zhu1,2^{1,2}1,2, Xilin Wang2,4^{2,4}2,4, Yixuan Li2,3^{2,3}2,3, Zhuofan Zhang1,2^{1,2}1,2, Xiaojian Ma2^{2}2, Yixin Chen2^{2}2, Baoxiong Jia2^{2}2, Wei Liang3^{3}3, Qian Yu4^{4}4, Zhidong Deng1^{1}1, Siyuan Huang2^{2}2, Qing Li2^{2}2
- 单位:1^{1}1清华大学,3^{3}3北京理工大学,4^{4}4北京航空航天大学,2^{2}2通用人工智能国家重点实验室
- 论文标题: Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
- 论文链接:https://arxiv.org/pdf/2507.04047v1
主要贡献
- 提出了Move to Understand(MTU3D)框架,能够将视觉定位(visual grounding)和探索(exploration)相结合,从而实现高效且多样的具身导航(embodied navigation)。
- 设计了一个统一的目标函数,能够同时对定位和探索进行优化,充分利用了两者的互补性来提升整体性能。
- 提出了视觉 - 语言 - 探索(Vision-Language-Exploration,VLE)训练方案,利用大规模的模拟数据和真实世界轨迹数据进行训练。
- 通过大量实验验证了该方法的有效性,在开放词汇导航 、多模态终身导航 、面向任务的顺序导航 以及主动具身问答等多个基准测试中,都取得了显著优于现有方法的探索效率和定位精度。
研究背景
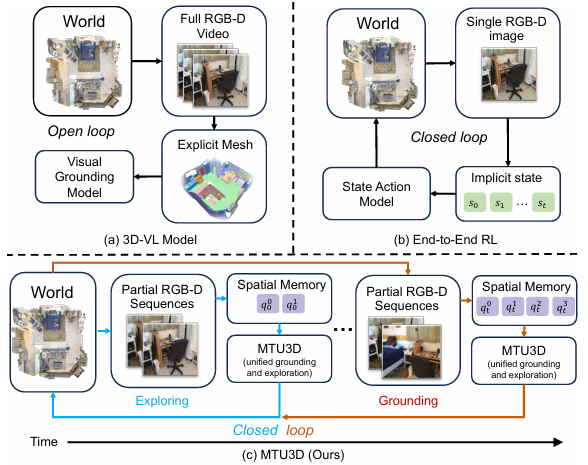
- 具身场景理解(Embodied scene understanding)不仅需要理解已经观察到的视觉空间信息,还需要确定在三维物理世界中接下来要探索的位置。
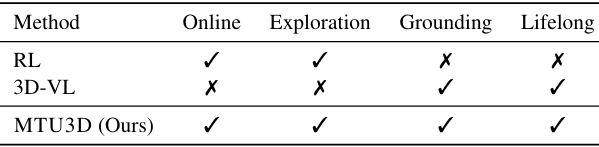
- 现有的三维视觉 - 语言(3D-VL)模型主要侧重于在静态的三维重建(如网格和点云)上进行物体定位,但缺乏主动感知和探索环境的能力。
- 以往的强化学习(RL)基础的具身智能体虽然能够探索环境,但通常存在样本效率低下、由于训练数据有限导致泛化能力差以及缺乏明确空间表示等问题。
- 因此,如何将被动的3D-VL定位和主动探索相结合,是开发能够高效探索和理解三维世界的智能系统的关键挑战。
MTU3D 方法
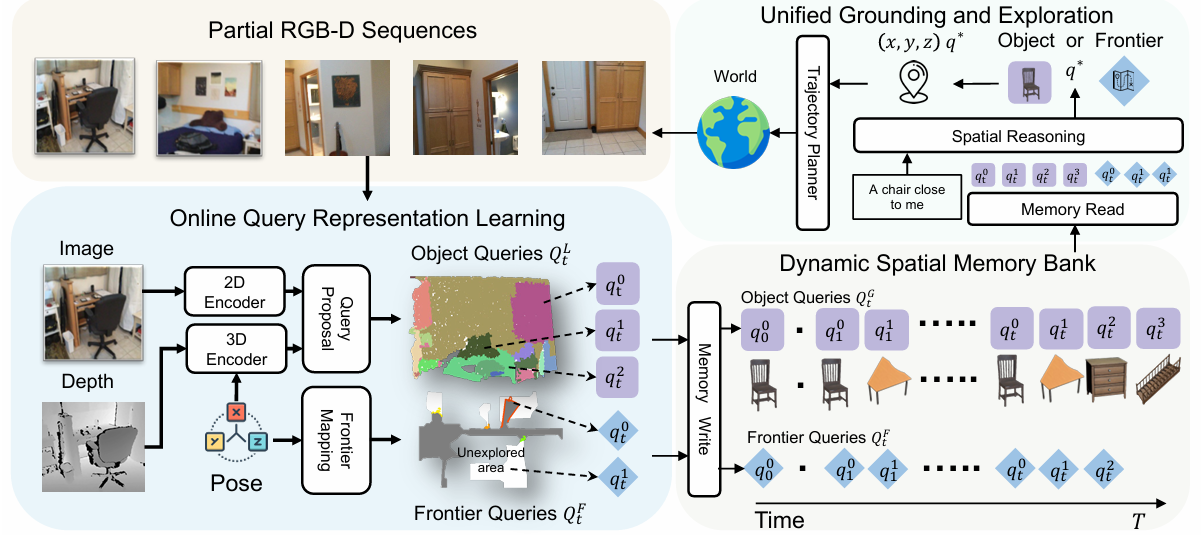
在线查询表示学习
- 输入 :模型接收部分RGB-D序列作为输入,该序列跨越任意时间范围,表示为 O=ot1,ot2,...,otO = o_{t1}, o_{t2}, \\ldots, o_{t}O=ot1,ot2,...,ot。在每个时间步 ttt,从输入观测 ot=It,Dt,Pto_t = I_t, D_t, P_tot=It,Dt,Pt 中提取局部查询 QtLQ^L_tQtL,其中 ItI_tIt 是RGB图像,DtD_tDt 是深度图像,PtP_tPt 是相机姿态。
- 2D和3D编码 :
- 使用FastSAM对图像进行分割,生成段索引图 StS_tSt。
- 通过DINO骨干网络对RGB图像 ItI_tIt 进行2D特征提取,得到像素级特征 Ft2DF^{2D}_tFt2D,然后根据 StS_tSt 进行池化,生成段级表示 F^t2D\hat{F}^{2D}_tF^t2D。
- 将深度图像 DtD_tDt 投影到点云并均匀下采样,通过稀疏卷积U-Net生成3D特征 Ft3DF^{3D}_tFt3D,再通过段索引图 StS_tSt 进行段级池化,得到 F^t3D\hat{F}^{3D}_tF^t3D。
- 局部查询提议 :
- 通过多层感知机(MLP)将2D和3D特征融合,生成初始查询 Qt=MLP(F^t2D,F^t3D)Q_t = MLP(\hat{F}^{2D}_t, \hat{F}^{3D}_t)Qt=MLP(F^t2D,F^t3D)。
- 使用PQ3D启发式的解码器层对初始查询进行细化,得到局部输出查询 QtLQ^L_tQtL。每个细化后的局部查询 qtLq^L_tqtL 包含多个组件,如3D边界框 btb_tbt、实例分割掩码 mtm_tmt、开放词汇特征嵌入 vtv_tvt、查询解码器的输出特征 ftf_tft 和置信度分数 sts_tst。
- 动态空间记忆库 :
- 将局部查询与空间记忆库中的历史查询通过计算边界框IoU进行合并,生成更新后的全局查询 QtGQ^G_tQtG,包含特征嵌入 ftf_tft 和语义向量 vtv_tvt,用于后续的定位和探索。
- 通过维护占据图 MMM 来识别未探索区域,将探索区域与未探索区域之间的边界定义为前沿(frontiers) QtFQ^F_tQtF,作为潜在的探索目标。
统一定位和探索
- 决策框架 :给定自然语言目标 LLL(如"找到一把红色的椅子"),模型需要决定是定位当前全局查询 QtGQ^G_tQtG 中的物体,还是选择一个前沿 QtFQ^F_tQtF 进行探索。
- 空间推理Transformer :该Transformer将语言指令、物体表示和前沿信息整合起来,为每个候选决策生成统一的分数 StU=f(QtG,QtF,L)S^U_t = f(Q^G_t, Q^F_t, L)StU=f(QtG,QtF,L)。前沿点通过一个简单的两层MLP进行编码,然后输入到Transformer中。对于语言目标,使用CLIP文本编码器;对于基于图像的目标,则使用CLIP图像编码器。这些嵌入被投影到Transformer的特征空间中,与查询表示进行交叉注意力操作。
- 决策过程 :最终决策选择分数最高的查询 q∗=argmaxqi∈QtG∪QtFStU(qi)q^* = \arg\max_{q_i \in Q^G_t \cup Q^F_t} S^U_t(q_i)q∗=argmaxqi∈QtG∪QtFStU(qi)。如果 q∗∈QtGq^* \in Q^G_tq∗∈QtG,则定位对应的物体;如果 q∗∈QtFq^* \in Q^F_tq∗∈QtF,则导航到该前沿位置。使用Habitat-Sim最短路径规划器生成局部轨迹,动态平衡探索和定位。
轨迹数据收集
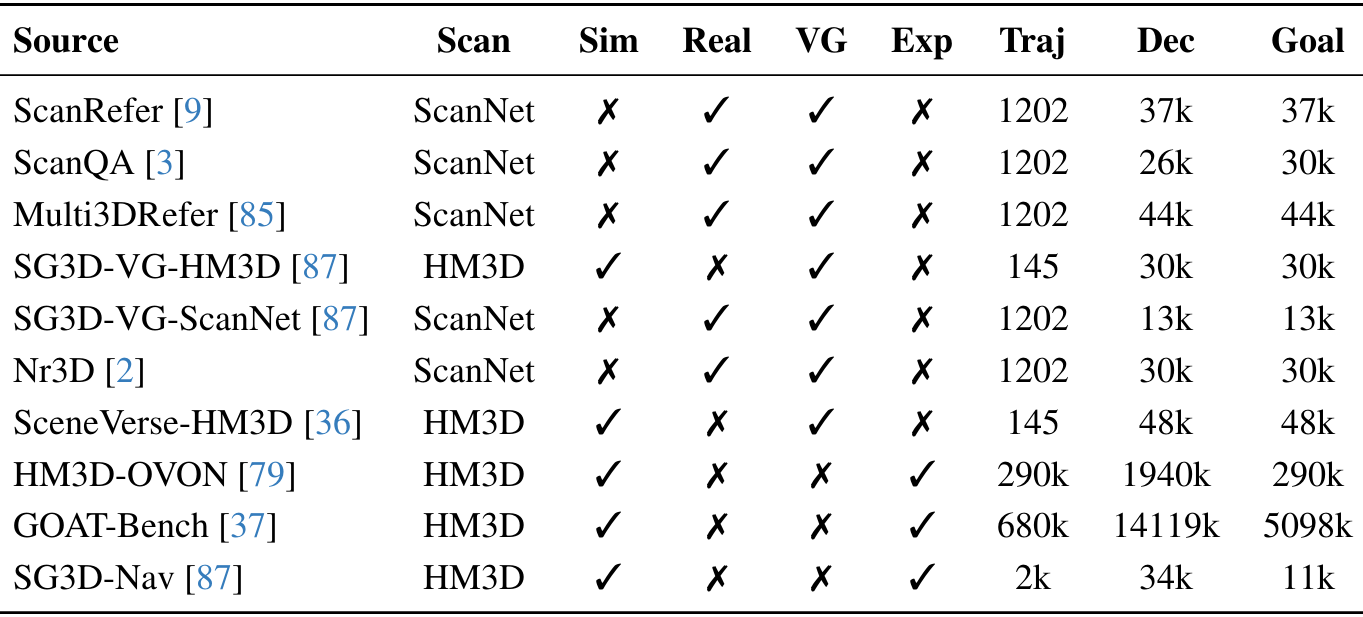
- 视觉定位轨迹:利用ScanNet中的离线RGB-D视频作为轨迹,直接使用这些配对的样本进行预训练。每个样本将物体查询与语言描述关联起来,生成决策。
- 探索轨迹 :探索数据遵循格式 (ObjectQtG,FrontierQtF,GoalG)→(DecisionStU)(Object Q^G_t, Frontier Q^F_t, Goal G) \rightarrow (Decision S^U_t)(ObjectQtG,FrontierQtF,GoalG)→(DecisionStU),在探索过程中前沿会改变。为了避免过拟合,实施随机前沿选择和混合策略(随机和最优前沿选择的组合)。从模拟扫描(HM3D通过Habitat-Sim)收集轨迹,应用不同的探索策略。探索成功时,目标变得可见且可达。为防止不必要的探索,维护一个已访问前沿列表,仅在存在更好的潜在前沿时进行探索。
视觉 - 语言 - 探索训练
- 第一阶段:低级感知训练 :利用ScanNet和HM3D中的RGB-D轨迹训练查询表示,使用实例分割损失进行训练。损失函数结合了多个组件,包括3D边界框IoU损失、二元交叉熵损失(掩码和置信度分数)以及余弦相似性损失(词汇表)。这种方法确保输出的局部查询 QtLQ^L_tQtL 能够有效捕获空间、语义和置信度信息。
- 第二阶段:视觉 - 语言 - 探索预训练 :在VLE预训练中,使用第一阶段输出的查询联合训练探索和定位。使用表2中的数据集,在超过一百万的轨迹上训练决策模型。统一决策分数 StUS^U_tStU 通过二元交叉熵损失进行优化,教导模型根据当前状态和目标为适当的查询位置分配更高的分数。
- 第三阶段:特定任务导航微调:在这一阶段,使用与第二阶段相同的目标,并针对特定的导航轨迹对MTU3D进行微调,优化针对目标部署场景的性能。
实验
实验设置
数据集和基准测试
- 在多个不同的基准测试上进行评估,包括:
- GOAT-Bench:多模态终身导航(multi-modal lifelong navigation)。
- HM3D-OVON:开放词汇导航(open-vocabulary navigation)。
- SG3D:顺序任务导航(sequential task navigation)。
- A-EQA:具身问答(embodied question answering)。
- 使用的评估指标包括成功率(Success Rate,SR)和按路径长度加权的成功率(Success weighted by Path Length,SPL)。SG3D使用任务成功率(task Success Rate,t-SR)来衡量步骤连贯性。A-EQA使用LLM匹配分数(LLM match score,LLM-SR)和按探索长度平均的分数(LLM-SPL)。
实现细节
- 在第一阶段,使用AdamW优化器进行50个周期的训练,学习率为1e-4,β1=0.9,β2=0.98,损失权重分别为λb=1.0,λm=1.0,λv=1.0,λs=0.5。
- 第二阶段和第三阶段使用与第一阶段相同的优化器设置,各进行10个周期的训练。
- 第一阶段和第二阶段均使用4层的Transformer。查询提议在第一阶段进行训练,然后冻结,空间推理在后续阶段进行训练。
- 所有训练都在四块NVIDIA A100 GPU上进行,大约需要164个GPU小时。
- 在模拟环境中进行评估时,使用Stretch机器人(1.41米高,底座半径17厘米),处理360×640的RGB图像、深度图和姿态信息。动作包括向前移动(0.25米)、向左转、向右转、向上看和向下看。在到达每个目标位置时激活空间推理。在连续目标位置之间沿轨迹采样18帧。
- 对于A-EQA,模型仅用于生成探索轨迹并收集每个问题对应的视频。
定量结果
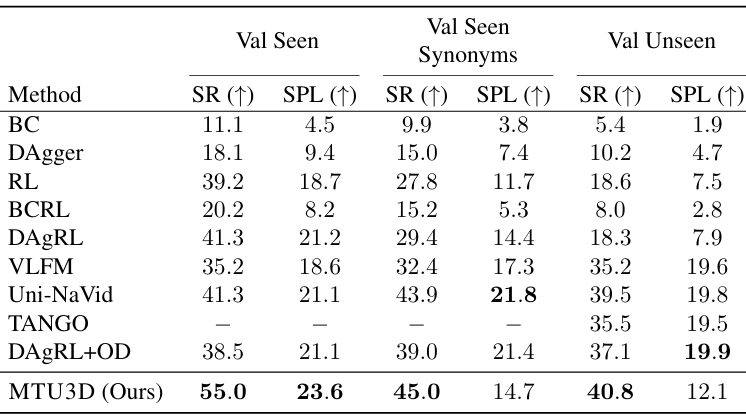
- 开放词汇导航 :
- 在HM3D-OVON数据集上,MTU3D在Val Seen、Val Unseen和Val Synonyms设置中的成功率(SR)均显著高于所有基线方法。在Val Unseen设置中,MTU3D达到了40.8%的成功率,显示出其强大的泛化能力。
- 然而,MTU3D的SPL低于Uni-Navid,尤其是在Val Synonyms和Val Unseen设置中。这可能是因为HM3D-OVON数据集中的轨迹相对较短,基于视频的模型在直接导航到目标时具有优势。
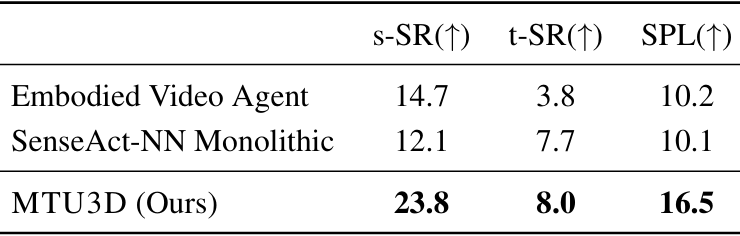
- 任务导向顺序导航 :
- 在SG3D基准测试中,MTU3D实现了最高的s-SR(23.8%)、t-SR(8.0%)和SPL(16.5%),证明了其在顺序任务执行和任务理解方面的有效性。
- 与Embodied Video Agent和SenseAct-NN Monolithic等方法相比,MTU3D显著提高了性能。然而,SG3D的总体成功率仍然低于GOAT-Bench和HM3D-OVON,这表明SG3D任务的复杂性,需要在多个步骤中保持导航和任务准确性。
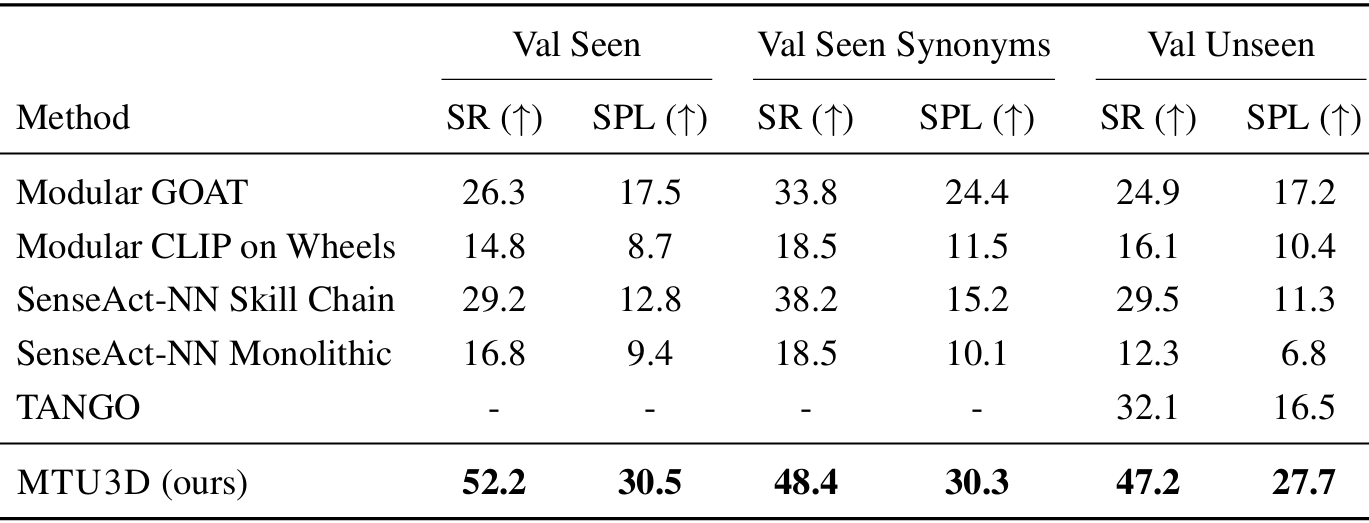
- 多模态终身导航 :
- 在GOAT-Bench基准测试中,MTU3D在所有设置中均实现了最高的成功率(SR),在Val Seen、Val Seen Synonyms和Val Unseen中分别达到了52.2%、48.4%和47.2%。
- 与开放词汇导航相比,多模态终身导航任务更具挑战性,因为它需要连续的空间记忆和长期推理。MTU3D的终身空间记忆使其能够更有效地保留和利用过去的经历,从而在性能上大幅超越基线方法。
- 此外,MTU3D在所有设置中均实现了最高的SPL,表明其不仅能够更准确地到达目标,而且能够遵循更高效的轨迹。
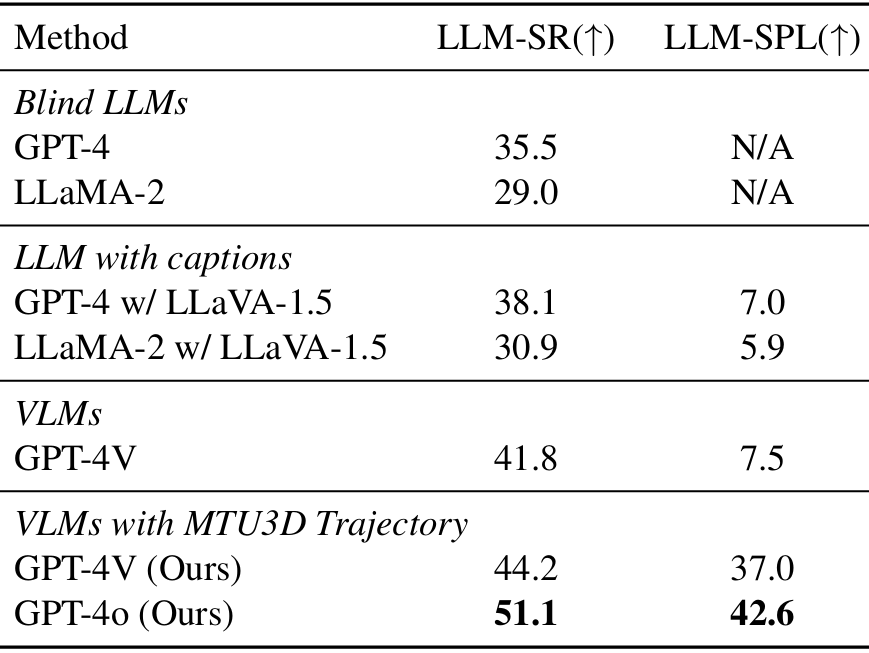
- 主动具身问答 :
- 在A-EQA基准测试中,MTU3D增强的GPT-4V模型显著优于基线GPT-4V模型,LLM-SR达到了44.2%,LLM-SPL达到了37.0%。
- 与GPT4o结合时,LLM-SR进一步提升至51.1%,LLM-SPL提升至42.6%,这表明MTU3D能够使模型以更高效的方式生成探索轨迹,避免了基线模型依赖于穷举搜索所有位置的问题。
讨论
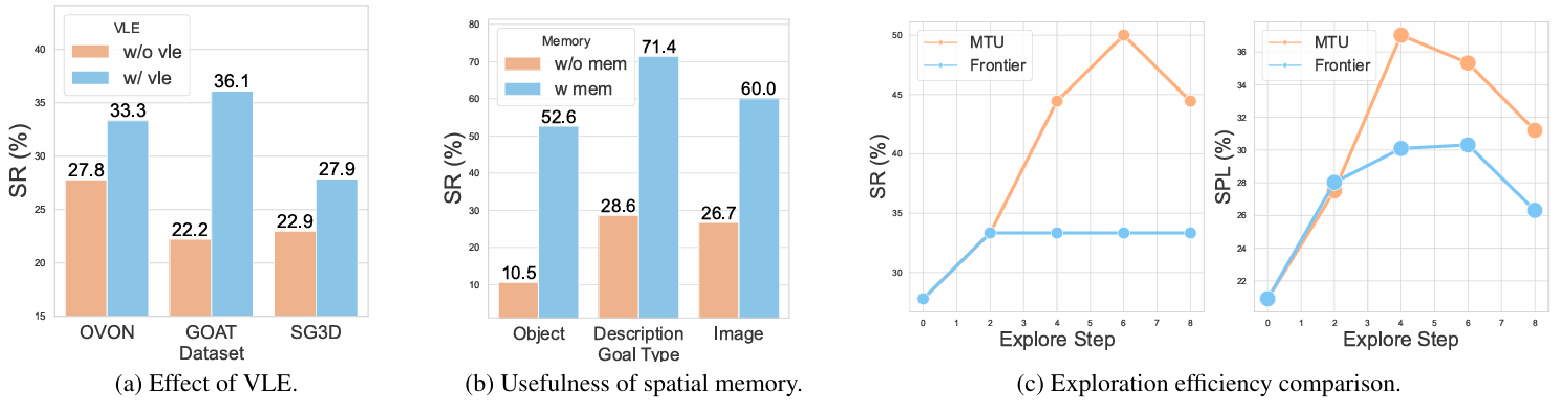
- 视觉 - 语言 - 探索预训练的效果 :
- 实验结果表明,视觉 - 语言 - 探索(VLE)预训练能够显著提升导航性能,在不同数据集上的成功率(SR)都有提升。具体来说,在OVON、GOAT和SG3D数据集上,成功率分别从27.8%提升至33.3%、22.2%提升至36.1%和22.9%提升至27.9%,这表明VLE预训练在不同任务设置和分布下都能带来一致的益处。
- 定位训练是否导致高效探索 :
- 实验结果表明,MTU3D在探索步骤增加时,其成功率(SR)和按路径长度加权的成功率(SPL)均优于前沿探索方法。与前沿探索盲目选择最近的前沿不同,MTU3D利用语义引导进行更高效、目标导向的探索。例如,在探索步骤为6时,MTU3D的成功率为50.0%,SPL为35.3%,而前沿探索的成功率为33.3%,SPL为30.3%。
- 空间记忆库是否增强终身导航 :
- 通过在GOAT-Bench基准测试中重置空间记忆(w/o mem)与保留空间记忆(w/ mem)进行对比,实验结果表明空间记忆显著提升了成功率(SR)。例如,对于目标类型为物体、描述和图像的目标,成功率分别从10.5%提升至52.6%、28.6%提升至71.4%和26.7%提升至60.0%,这表明空间记忆有助于保留有用的空

- MTU3D是否能够实时运行 :
- 上表显示,MTU3D模型在查询提议方面耗时192毫秒,在空间推理方面耗时31毫秒,同时保持了3.4的帧率(FPS),拥有266M个参数。这些结果表明,MTU3D在速度和性能之间取得了最佳平衡,使其非常适合实时应用。
定性结果
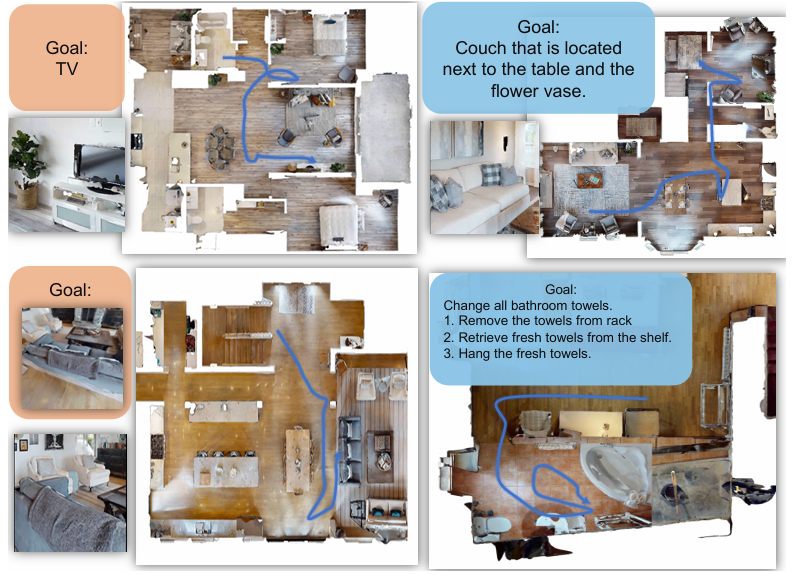
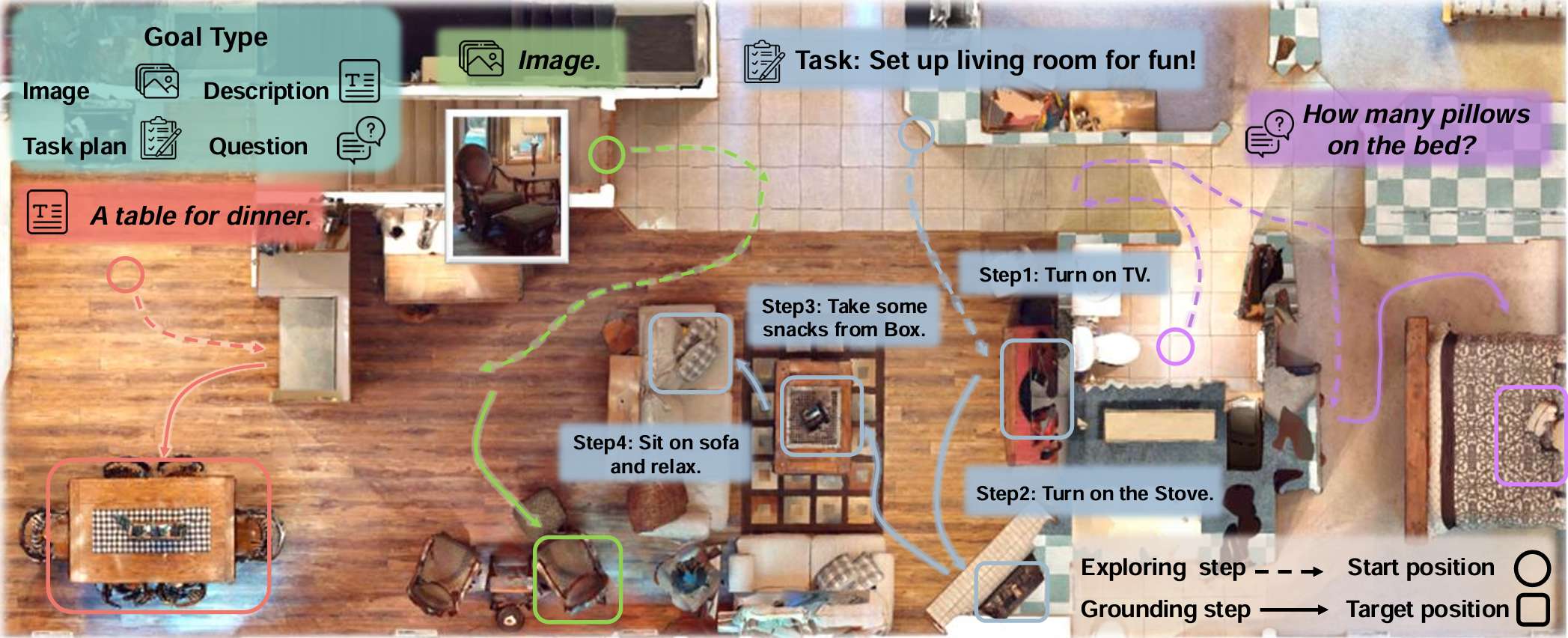
- 定性结果展示了智能体在Habitat-Sim中的导航能力,能够完成包括语言、图像、描述和任务规划目标在内的多样化目标类型。
- 轨迹图展示了智能体如何基于视觉和语义线索高效地定位物体,证明了其理解基于图像和文本指令的能力。特别是对于任务规划目标,智能体能够按照结构化的动作序列进行操作。
真实世界测试
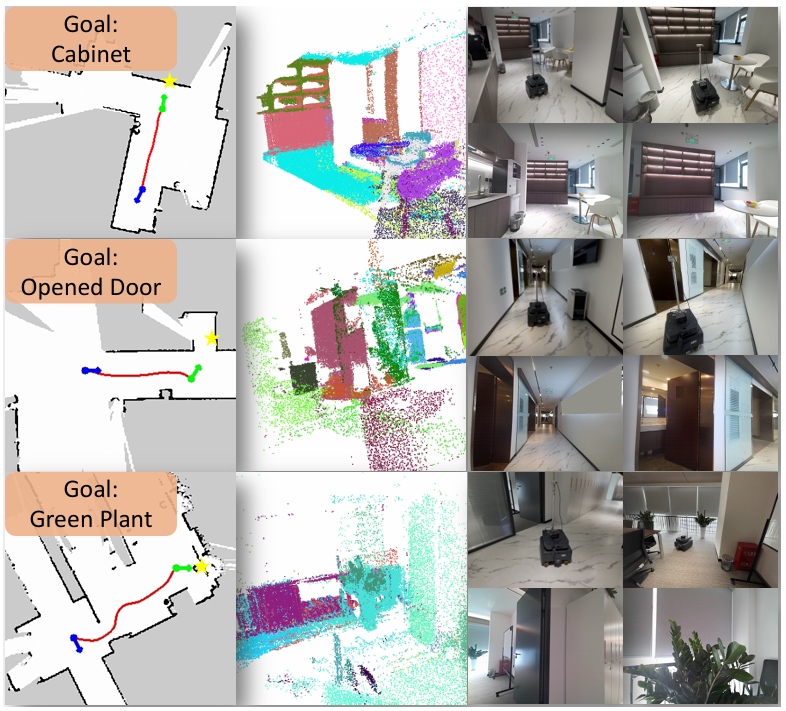
- 通过在真实世界环境中部署MTU3D,使用NVIDIA Jetson Orin和Kinect进行实时RGB-D数据采集,以及配备Lidar的移动机器人进行探索,测试了该模型在家庭、走廊和会议室等不同场景中的性能。尽管没有进行真实世界微调,MTU3D仍然能够有效地导航到目标位置。
- 由于MTU3D在模拟和真实数据上都进行了训练,因此它克服了通常在基于强化学习的方法中面临的从模拟到真实(Sim-to-Real)转移的挑战。这种能力不仅增强了其在真实世界中的适用性,而且使其在未来推进具身智能方面具有高度的可扩展性和影响力。
结论与未来工作
- 结论 :
- MTU3D通过将视觉定位和探索相结合,实现了高效导航,能够处理多种输入模态,促进了对空间环境的深入理解。其VLE训练利用大规模轨迹数据,在多个具身AI基准测试中达到了最先进的性能水平。
- 实验结果强调了空间记忆在实现终身多模态导航和空间智能中的关键作用,使智能体能够对复杂环境进行推理和适应。此外,真实世界部署验证了MTU3D的泛化能力,证明了其混合模拟和真实世界数据训练的有效性。
- 未来工作 :
- 未来将进一步探索如何提高模型在更复杂和动态环境中的性能,以及如何更好地将这种技术应用于实际的机器人系统中,以实现更智能的具身交互和任务执行。
