各位后端友友们,是不是也遇到过这种糟心场景:产品说 "要做个文章搜索功能,用户输关键词能秒出结果",你拍胸脯说 "小事儿,MySQL like 走一波"------ 结果测试拿 10 万条数据一测,输入 "Elasticsearch",页面转了 3 秒才出来,产品盯着你:"这叫秒出?"
这时候,旁边老大哥幽幽一句:"试试 ES 呗。"
你:"ES 是啥?怎么用?跟 MySQL 啥关系?"
别慌!今天咱们就从 "ES 入门" 到 "动手撸代码",用唠嗑的方式把 ES 相关知识点扒得明明白白,以后再遇到文本搜索需求,咱也能底气十足!
1. 先唠唠:ES 到底是个啥?
Elasticsearch(简称 ES),你可以把它理解成 "搜索引擎界的全能打工人"------ 既不是数据库,也不是缓存,但在 "文本搜索" 和 "日志分析" 这两件事上,能把很多工具按在地上摩擦。
官方定义是 "分布式、RESTful 风格的搜索和数据分析引擎",听着挺玄乎,咱翻译成人话:

-
分布式:数据能拆成好几份存在不同机器上,不怕丢,还能并行查,速度快;
-
RESTful:操作它不用写复杂协议,发个 HTTP 请求(GET/POST/PUT/DELETE)就行,比如查数据用 GET,存数据用 POST;
-
核心本事:能把文本拆成关键词(分词),再用 "倒排索引" 快速定位,不管是搜文章、搜日志还是搜商品,都能秒级响应。
简单说:ES 就是为 "找文本" 而生的 ------ 你想搜日志里的 "报错信息",想搜博客里的 "Elasticsearch 教程",找它就对了。
2. 灵魂拷问:ES 查文本为啥这么快?先搞懂 "正排" 和 "倒排"
要搞懂 ES 的速度,得先明白两个概念:正向索引 和倒排索引。咱用 "学生作文" 举个例子,一看就懂。
2.1 正向索引:像 "按学号找作文",慢到着急
假设你是老师,手里有个笔记本,记了每个学生的 "学号" 和 "作文内容":
-
学号 1:《我的足球梦》... 今天和小明踢足球...
-
学号 2:《校园生活》... 上午上数学,下午打篮球...
-
学号 3:《运动日记》... 足球比篮球更有趣...
现在要找 "提到足球" 的学生,正向索引的做法是:拿着 "足球" 这个关键词,逐个翻每个学生的作文------ 学号 1 的看一遍(有!),学号 2 的看一遍(没有),学号 3 的看一遍(有!)...
如果有 1000 个学生,就得翻 1000 遍;要是 100 万条数据,那不得等到下班?这就是 MySQL 用like '%足球%'慢的原因 ------ 它本质就是走正向索引,全表扫描。
2.2 倒排索引:像 "按关键词找学号",快到飞起
倒排索引就聪明多了,它先做了一步 "预处理":把所有作文拆成关键词,再记录 "哪些学号提到过这个关键词" 。
比如上面的作文,倒排索引会长成这样:
-
关键词 "足球":对应学号 1、学号 3;
-
关键词 "篮球":对应学号 2、学号 3;
-
关键词 "数学":对应学号 2;
现在要找 "提到足球" 的学生,直接查 "足球" 这个关键词对应的学号列表就行 ------ 一步到位,不用翻任何一篇作文!
而 ES 的核心,就是提前把文本做了 "分词" 和 "倒排索引",所以查文本时才能秒出结果。这就像你查字典,先查部首(关键词),再找页码(文档),比逐页翻快 100 倍!
3. ES vs MySQL:不是 "替代",是 "互补"
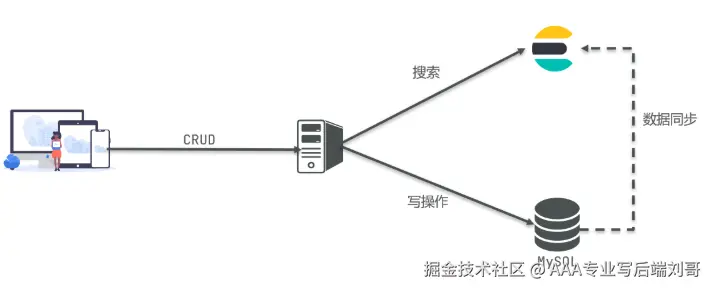 很多人会问:"有了 ES,还要 MySQL 吗?"------ 咱先看张表,就知道它俩根本不是 "竞争对手",而是 "最佳搭档":
很多人会问:"有了 ES,还要 MySQL 吗?"------ 咱先看张表,就知道它俩根本不是 "竞争对手",而是 "最佳搭档":
| 对比维度 | MySQL(关系型数据库) | Elasticsearch(搜索引擎) |
|---|---|---|
| 核心定位 | 关系型数据管家(管交易、管关联) | 文本搜索 / 日志分析专家(管找文本) |
| 数据模型 | 表、行、列(强关联,比如订单关联用户) | JSON 文档(无强关联,结构灵活) |
| 文本搜索能力 | 弱(like 模糊查询,全表扫描,慢) | 强(分词 + 倒排索引,支持精准 / 模糊 / 短语搜索) |
| 事务支持 | 支持(ACID,比如转账不能错) | 弱(默认不支持事务,新版有改进但不常用) |
| 适用场景 | 存订单、用户信息、对账报表 | 日志分析(ELK 栈)、文章搜索、商品搜索 |
简单说:
-
该用 MySQL 的地方别让 ES 上:比如存用户的银行卡信息、订单支付记录,这些需要事务保证的,MySQL 是老大;
-
该用 ES 的地方别硬扛 MySQL:比如用户搜 "2024 年 ES 教程",用 ES 分词 + 倒排索引,秒出结果,比 MySQL 快 10 倍不止。
举个实际场景:电商 App 里,"商品基本信息(名称、价格、库存)" 存在 MySQL,"商品详情(长文本描述)" 存在 ES------ 用户点 "商品列表" 查 MySQL,搜 "红色连衣裙" 查 ES,完美配合!
4. 中文搜索的 "救星":IK 分词器
ES 默认的分词器有个大问题:不认识中文。比如你输入 "我爱中国",它会拆成 "我""爱""中""国"------ 这显然不对,咱要的是 "我""爱""中国" 这种有意义的词。
这时候,IK 分词器就登场了 ------ 专门为中文设计的分词插件,能把中文拆成 "人类能理解的关键词"。
4.1 IK 的两种分词模式(必懂!)
IK 有两种常用模式,用的时候得根据场景选:
-
ik_max_word(最大化分词) :把文本拆到最细,尽可能多拆出关键词。
例子:"Elasticsearch 是个好工具" → 拆成 "elasticsearch""是""个""好""工具""好工具";
-
ik_smart(智能分词) :按人类理解的逻辑粗粒度拆分,不重复拆。
例子:"Elasticsearch 是个好工具" → 拆成 "elasticsearch""是""个""好工具"。
实际用的时候:
- 建索引(存数据)时用
ik_max_word:拆得细,后续搜索能匹配到更多结果(比如用户搜 "好工具" 也能命中); - 搜索时用
ik_smart:拆得粗,速度快,避免匹配太多无关内容。
5. 实战环节:跟 ES "打交道",从建索引到撸 Java 代码
光说不练假把式,接下来咱们用 "博客搜索" 场景,实战 ES 的核心操作 ------ 建索引、定义 Mapping、操作文档(CRUD),既有 DSL(ES 的查询语言,类似 SQL),也有 Java 代码,新手也能跟着敲!
5.1 第一步:操作索引(像给 ES 建 "文件夹")
索引(Index)可以理解成 MySQL 的 "表",是存文档的地方。操作索引主要是 "建、查、删",用 HTTP 请求就能搞定。
5.1.1 新建索引(带 IK 分词)
比如建一个叫blog_index的索引,存博客文章,指定 "标题" 和 "内容" 用 IK 分词:
json
json
# POST请求:http://你的ES地址:9200/blog_index
PUT /blog_index
{
"settings": {
"number_of_shards": 1, // 分片数(默认5,测试用1就行)
"number_of_replicas": 0 // 副本数(默认1,测试用0,省资源)
},
"mappings": { // 这里就是Mapping,给字段定规矩
"properties": {
"title": { // 博客标题
"type": "text", // 文本类型(支持分词)
"analyzer": "ik_max_word", // 建索引用IK最大化分词
"search_analyzer": "ik_smart" // 搜索用IK智能分词
},
"content": { // 博客内容
"type": "text",
"analyzer": "ik_max_word"
},
"createTime": { // 发布时间
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss" // 日期格式
}
}
}
}5.1.2 查看索引
想知道blog_index建得对不对,发个 GET 请求:
json
bash
# GET请求:http://你的ES地址:9200/blog_index
GET /blog_index5.1.3 删除索引
要是建错了,删了重来吧(注意:生产环境谨慎!):
json
bash
# DELETE请求:http://你的ES地址:9200/blog_index
DELETE /blog_index5.2 第二步:Mapping 映射(给字段 "定规矩")
刚才建索引时已经包含了 Mapping,这里单独拎出来说 ------Mapping 就像 MySQL 的 "表结构",告诉 ES:
-
这个字段是文本(text)还是数字(integer)?
-
能不能被搜索?要不要分词?用什么分词器?
重点提醒 :Mapping 一旦创建,大部分字段不能修改!比如你把 "title" 设成text,再想改成integer就不行了 ------ 所以建索引前一定要想好字段类型!
比如常见的字段类型:
text:文本类型,支持分词(比如标题、内容);keyword:关键词类型,不支持分词(比如标签 "ES 教程",要完整匹配才命中);integer/long:数字类型;date:日期类型(要指定格式)。
5.3 第三步:操作文档(CRUD,像 MySQL 增删改查行)
文档(Document)就是 ES 里的 "数据行",用 JSON 格式存储。比如一篇博客就是一个文档,接下来咱们用 DSL 和 Java 分别实现 CRUD。
5.3.1 DSL 操作文档(HTTP 请求)
1. 新增文档(类似 MySQL insert)
给blog_index加一篇博客,指定文档 ID 为 1:
json
bash
# POST请求:http://你的ES地址:9200/blog_index/_doc/1
POST /blog_index/_doc/1
{
"title": "Elasticsearch入门教程:从0到1学ES",
"content": "Elasticsearch是一款强大的全文搜索引擎,常用于日志分析和博客搜索。本文教你如何搭建ES环境,以及基本的索引操作。",
"createTime": "2024-05-20 14:30:00"
}2. 查询文档(类似 MySQL select)
-
按 ID 查:
json
bash# GET请求:http://你的ES地址:9200/blog_index/_doc/1 GET /blog_index/_doc/1 -
按关键词搜(比如搜标题含 "ES" 的博客):
json
sql# GET请求:http://你的ES地址:9200/blog_index/_search GET /blog_index/_search { "query": { "match": { // match查询:支持分词匹配 "title": "ES" } } }
3. 更新文档(类似 MySQL update)
修改 ID 为 1 的博客标题:
json
bash
# POST请求:http://你的ES地址:9200/blog_index/_update/1
POST /blog_index/_update/1
{
"doc": {
"title": "Elasticsearch入门教程:从0到1学ES(2024版)"
}
}4. 删除文档(类似 MySQL delete)
删除 ID 为 1 的博客:
json
bash
# DELETE请求:http://你的ES地址:9200/blog_index/_doc/1
DELETE /blog_index/_doc/15.3.2 Java 操作文档(Spring Boot 实战)
实际开发中,咱们不会手动发 HTTP 请求,而是用 Java 代码调用 ES 客户端。这里用最常用的 "Spring Data Elasticsearch"(封装了原生客户端,上手快)。
1. 加依赖(pom.xml)
xml
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<!-- 版本跟Spring Boot一致就行,比如2.7.x -->
</dependency>2. 配置 ES 地址(application.yml)
yaml
yaml
spring:
elasticsearch:
rest:
uris: http://你的ES地址:9200 # ES的HTTP地址3. 定义实体类(对应文档)
java
kotlin
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Date;
// 对应ES的blog_index索引
@Data // lombok简化get/set
@Document(indexName = "blog_index") // 指定索引名
public class Blog {
@Id // 对应文档的_id字段
private String id;
// 对应Mapping里的title字段,指定分词器
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
// 日期类型,指定格式
@Field(type = FieldType.Date, format = {}, pattern = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
}4. 定义 Repository(类似 MyBatis 的 Mapper)
Spring Data Elasticsearch 会自动实现 CRUD 方法,不用写 SQL:
java
kotlin
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
// 泛型:<实体类, 主键类型>
public interface BlogRepository extends ElasticsearchRepository<Blog, String> {
// 自定义查询:根据标题包含关键词查询(分页)
// 不用写实现,Spring会根据方法名自动生成查询逻辑
Page<Blog> findByTitleContaining(String keyword, Pageable pageable);
}5. Service 层(业务逻辑)
java
typescript
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
import java.util.Date;
import java.util.Optional;
@Service
public class BlogService {
@Autowired
private BlogRepository blogRepository;
// 新增/修改文档(save方法:有id则更新,无id则新增)
public void saveBlog(Blog blog) {
if (blog.getCreateTime() == null) {
blog.setCreateTime(new Date());
}
blogRepository.save(blog);
}
// 按id查询
public Blog getBlogById(String id) {
Optional<Blog> optional = blogRepository.findById(id);
// 存在则返回,不存在返回null
return optional.orElse(null);
}
// 按标题搜索(分页)
public Page<Blog> searchBlogByTitle(String keyword, int pageNum, int pageSize) {
// ES分页从0开始,所以pageNum要减1
Pageable pageable = PageRequest.of(pageNum - 1, pageSize);
return blogRepository.findByTitleContaining(keyword, pageable);
}
// 按id删除
public void deleteBlog(String id) {
blogRepository.deleteById(id);
}
}6. 测试一下(Controller 或 Test)
java
typescript
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
@SpringBootTest
public class BlogServiceTest {
@Autowired
private BlogService blogService;
// 测试新增
@Test
public void testSave() {
Blog blog = new Blog();
blog.setId("2"); // 指定文档id
blog.setTitle("Spring Boot整合Elasticsearch实战");
blog.setContent("本文介绍如何用Spring Boot整合ES,实现博客搜索功能。");
blogService.saveBlog(blog);
System.out.println("新增成功!");
}
// 测试搜索
@Test
public void testSearch() {
// 搜索标题含"ES"的博客,第1页,每页10条
Page<Blog> page = blogService.searchBlogByTitle("ES", 1, 10);
System.out.println("总条数:" + page.getTotalElements());
// 遍历结果
page.getContent().forEach(blog ->
System.out.println("标题:" + blog.getTitle() + ",时间:" + blog.getCreateTime())
);
}
}运行测试类,你会发现:新增文档后,搜索 "ES" 能秒级查到结果 ------ 这就是 ES 的魅力!
6. 最后总结:ES 该用在哪?
看完这么多,可能有人会问:"我平时开发,哪些场景该用 ES?" 记住 3 个核心场景就行:
-
全文搜索:博客搜索、商品搜索、文档搜索(用户输关键词要秒出结果);
-
日志分析:配合 ELK 栈(Elasticsearch+Logstash+Kibana)收集和分析日志,比如查 "昨天晚上 8 点的报错日志";
-
数据分析:快速统计文本中的关键词出现次数,比如 "统计近 7 天博客中'ES'被提到多少次"。
最后再强调一句:ES 不是 MySQL 的替代品,而是互补品 ------MySQL 管 "存数据、保事务",ES 管 "找文本、做分析",两者搭配,后端开发才能更高效!
如果这篇文章帮到你了,别忘了点赞收藏~ 你平时用 ES 做过什么场景?评论区聊聊呗!