目录
- nosql与sql
- 数据类型,
- 常用命令
-
- 字符串
- 哈希H
- ==面试题目,HGETALL还是HSCAN==
- 列表L
- [集合 S](#集合 S)
- 有序集合
- Redis的通用命令
- 在Java中操作Redis
nosql与sql
传统数据库的表与表之间往往存在关联,例如外键。
传统关系型数据库会基于Sql语句做查询,语法有统一标准;不同的非关系数据库查询语法差异极大,五花八门各种各样。
事务
传统关系型数据库能满足事务ACID的原则。
Atomicity (原子性) , 一个事务内部的"完整性"
Isolation (隔离性) ,隔离性(防止中间状态被他人看到),解决并发的脏读,不可重复读,(不可重复读:针对的是已存在的、相同的某一行数据的值(Value) 被修改了。幻读:针对的是结果集(Result Set) 中行的数量(Number of Rows) 发生了变化(新增或删除了满足条件的行)。幻读)(Redis 的隔离性
Redis 的隔离性实现非常简单粗暴:
Redis 是单线程的! 它使用一个线程来处理所有网络请求和命令执行。
因此,所有命令都是绝对串行、一个接一个执行的。MULTI 事务中的命令在 EXEC 时也是作为一个整体,被单线程顺序执行,不会被任何其他命令打断。
所以,Redis 的事务天然具备了最高级别的隔离性------串行化隔离(Serializable)。你完全不用担心在 Redis 事务执行过程中会遇到脏读、不可重复读或幻读的问题。
***Consistency (一致性),***就是数据的正确性。它保证数据永远符合所有预先定义好的规则(比如总额守恒、余额不为负、用户唯一等)。由数据库的约束机制和应用程序的正确逻辑共同保证。有数据库的约束,也有程序员自己定义的规则。
***Durability (持久性)***一旦事务成功提交(Commit),它对数据库所做的更改就是永久性的,因为要安全的写到硬盘里面。所以即使突然断电,修改也存在。
数据类型,
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
字符串 string
哈希 hash
列表 list
集合 set
有序集合 sorted set / zset
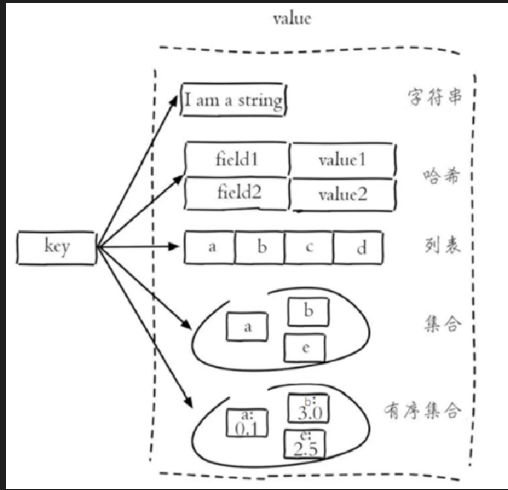
field的意思是成员变量
常用命令
根据value类型分类
字符串
SET key value 设置指定key的值
GET key 获取指定key的值
SETEX key seconds value 设置指定key的值,并将 key 的过期时间设为 seconds 秒。EX 是 Expiration(过期)的缩写。先执行 SET key value 再执行 EXPIRE key seconds 也能达到同样的效果,但 SETEX 具有原子性。
SETNX key value 只有在 key 不存在时设置 key 的值
两次用setnx(nx的含义是not exists)之后,第二次不会成功

哈希H
Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令:
HSET key field value 将哈希表 key 中的字段 field 的值设为 value
HGET key field 获取存储在哈希表中指定字段的值
HDEL key field 删除存储在哈希表中的指定字段
HKEYS key 获取哈希表中所有字段
HVALS key 获取哈希表中所有值
HGETALL key 一次性获取指定 Hash 键的所有字段和值。
HSCAN key cursor MATCH pattern COUNT count,COUNT count指的是每次返回几个元素,但是可能或多或少,但大体上会符合这个数量级。分批次迭代获取
面试题目,HGETALL还是HSCAN
"在我们的大型应用中,有一个Redis Hash存储了海量的用户元数据。如果我们需要完整地遍历这个Hash,应该使用HGETALL还是HSCAN?请解释你的选择。"
必须使用HSCAN,绝对禁止使用HGETALL。
一、 为什么绝对不能使用 HGETALL
"我首先解释为什么HGETALL是危险的,主要体现在三个层面:
服务端阻塞 风险:Redis采用单线程Reactor模型处理命令。HGETALL会一次性序列化整个Hash并返回。如果这个Hash有几十万个字段,这个操作会长时间独占Redis主线程,导致期间所有其他请求被阻塞,引发服务雪崩。
网络带宽 瓶颈:巨大的响应数据包会瞬间占满网络带宽。在一个1Gbps的网络中,传输一个1GB的响应需要至少8秒,这很容易导致客户端连接超时。
客户端内存 压力:客户端必须分配一块足够大的连续内存来装载整个响应。对于一个包含百万级字段的Hash,这很容易导致客户端应用程序内存溢出(OOM)而崩溃。
"总结来说,HGETALL只适用于字段数量极少(比如几十上百个)的场景,例如读取一个用户对象的缓存。对于'海量元数据'这种描述,使用它是灾难性的。"
二、 为什么 HSCAN 是唯一的正确选择
"HSCAN命令通过基于游标的迭代器完美解决了上述所有问题。它的核心优势是实现了增量式、批量的数据获取。
工作原理:
它每次调用只返回一小部分数据(例如100或1000个字段)。
同时返回一个游标(Cursor),客户端用这个游标进行下一次调用,直到游标返回0,表示迭代结束。
如何解决 HGETALL 的问题:
无服务端阻塞 :每次HSCAN操作耗时极短,不会对Redis主线程造成显著压力,不影响其他请求。
网络流量平滑:数据被分成多个小包在网络上传送,避免了带宽峰值。
客户端内存安全:客户端在任何时刻都只需要处理一个批次的数据量。它可以在处理完当前批次后(例如写入文件或数据库),再获取下一批,内存占用始终保持在一个很低的水平。
高级用法:
它支持COUNT参数来建议每批返回的数量,让我们能在迭代效率和单次请求开销之间做权衡。
它甚至支持MATCH参数,允许在迭代过程中基于模式匹配字段名,实现了过滤功能。
"因此,HSCAN的本质是一种'流式处理',它将一个庞大的操作分解为许多个无害的小操作,这是分布式系统中处理大数据的基本设计模式。"
三、 实践举例与注意事项
"在实际编码中,我们会这样使用它(以Python为例):
python
cursor = 0
all_data = {} # 如果必须全量存储,仍需要内存。但通常我们处理完一批就丢弃。
while True:
分批获取,count根据实际情况调整
cursor, data_batch = redis_client.hscan('huge_hash_key', cursor=cursor, count=500)
process_data(data_batch) # 立即处理这一批数据,而非堆积
if cursor == 0:
break
"同时,我需要指出HSCAN的两个重要特性:
弱一致性:在多次请求的间隔中,数据可能被其他客户端修改,可能会看到重复字段或看不到新字段。这对大多数统计、导出类任务是可接受的,但不能用于要求强一致性的场景。
COUNT是提示值:COUNT参数只是一个建议,Redis每次返回的数量可能不完全吻合,这是为了服务端效率的优化。"
四、 知识延伸
"这个问题其实有一个知识体系,HSCAN属于Redis SCAN家族的一员。对应的还有:
SCAN:替代危险的KEYS *命令,用于迭代数据库中的所有键。
SSCAN:替代危险的SMEMBERS命令,用于迭代大Set。
ZSCAN:用于迭代大的Sorted Set。、
(注:Redis 的 List 结构没有直接的、名为 LSCAN 的命令。
为什么 List 没有 SCAN 系列的迭代命令?
SCAN, SSCAN, HSCAN, ZSCAN 这些命令主要针对的是 "集合类" 数据结构(Set, Hash, Sorted Set)。这些结构的共同点是元素是无序的(或按分数排序,而非插入顺序)且需要通过模式匹配(MATCH)来查找。
而 List 是一个有序序列,它的元素是通过索引位置(index) 来访问的。这种线性结构使得遍历它的方式与其他集合类型有根本性不同。对于 List,最自然的遍历方式就是使用索引分块读取,这正是 LRANGE 命令所做的工作。
"它们都共)享同样的设计哲学:在任何分布式系统或数据库操作中,都应避免单次操作处理大量数据 ,分批次迭代是保障系统弹性和稳定性的基石。"
总结
"所以,回到您的问题:对于海量用户元数据的Hash,HSCAN是唯一安全、可靠且专业的选择。我的决策基于对Redis架构的理解和对生产环境稳定性的敬畏。"
为什么这个回答是"完美的"?
结构清晰:先否定错误选项并深入解释原因,再提出正确方案并阐述其优势,最后升华到设计原则。
深度剖析:不仅回答了"用什么",更深入解释了"为什么",体现了原理级理解。
体现经验:提到了生产环境中才会遇到的问题(网络、内存、阻塞),表明有实战经验。
严谨全面:指出了方案的局限性(弱一致性)和注意事项(COUNT参数),思维非常严谨。
展现知识体系:由点及面,延伸到SCAN家族和分布式系统设计原则,展示了广阔的技术视野。
这个回答会让面试官觉得你不仅会用Redis,更真正理解它,具备设计高性能、高稳定性系统的能力。
列表L
列表操作命令
事实上,把列表想象成一种队列
LRANGE key start stop 获取列表指定范围内的元素


stop写成负一,可以代表列表的末尾
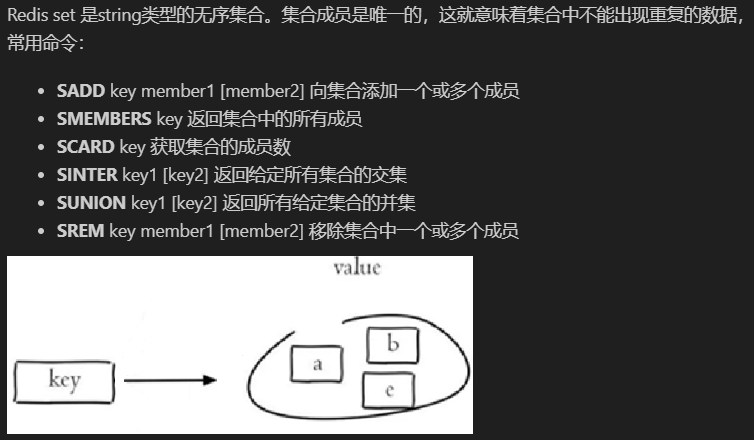
集合 S
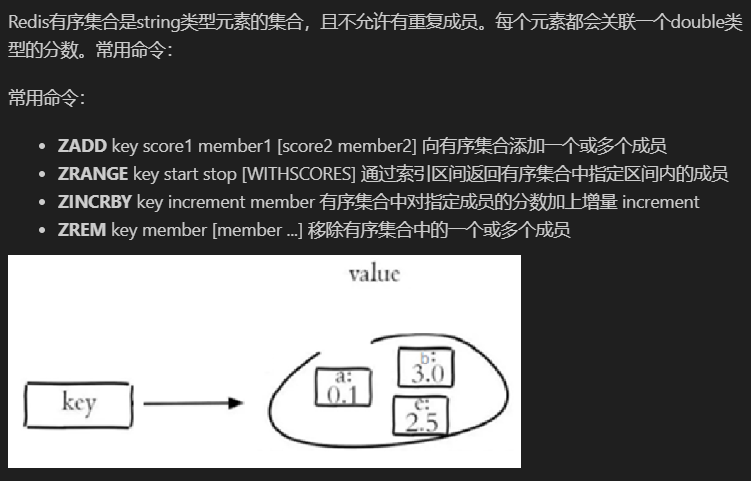
有序集合
Sorted Set,简称 ZSet,理解为一种特殊的集合,它在保持元素唯一性的同时,为每个元素关联了一个分数(score),并按照这个分数进行排序。
Redis的通用命令
是不分数据类型的,都可以使用的命令:
KEYS pattern 查找所有符合给定模式( pattern)的 key。(不能在生产环境中使用keys !Redis 是单线程的。当执行 KEYS * 时,Redis 需要遍历整个数据库中的所有 key,然后一次性将结果返回。)
EXISTS key 检查给定 key 是否存在
TYPE key 返回 key 所储存的值的类型
DEL key 该命令用于在 key 存在是删除 key
EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
在Java中操作Redis

String
关于这里,为什么Redis对应的是String,而这里的参数还是Object
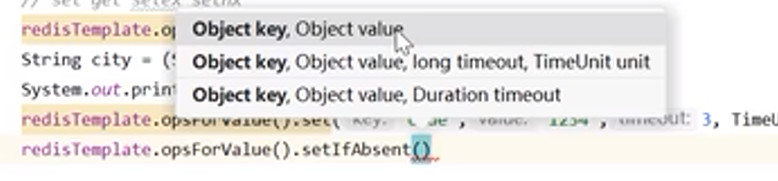
原因是 ,这里给任意类型,最终他都会把这个对象进行一个序列化,最终转成Redis中的String来存储
SpringDataRedis客户端
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中

序列化器
默认JdkSerializationRedisSerializer
这个序列化器底层使用的是 Java 原生的对象序列化机制 (ObjectOutputStream)。
关键就在这里:Java 原生序列化在将对象转换为字节流时,会将对象的类名、字段结构、字段值 等所有信息一起写入字节流。
最终存入 Redis 的,是一串包含完整类型信息的特殊二进制数据。
自定义GenericJackson2JsonRedisSerializer
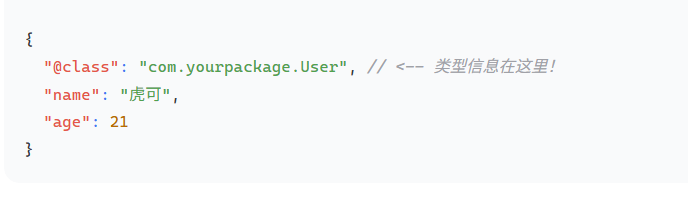
这个序列化器会使用 Jackson 库将 Java 对象转换为 JSON 字符串。
GenericJackson2JsonRedisSerializer 会在生成的 JSON 中加入一个特殊的 @class 属性,用来存储完整的类名。
java
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer =
new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}但是class信息显然会多占内存开销,所以怎么办?如下
统一的String序列化器,手动完成对象的序列化和反序列化
SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
个人理解,当序列化反序列化的时候全部按照String来。
java
@Autowired
private StringRedisTemplate stringRedisTemplate;
// JSON序列化工具
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testSaveUser() throws JsonProcessingException {
// 创建对象
User user = new User("虎哥", 21);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入数据
stringRedisTemplate.opsForValue().set("user:200", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:200");
// 手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println("user1 = " + user1);
}注
java
User user = new User("虎哥", 21);
String json = mapper.writeValueAsString(user);这段代码执行后,json中的字符串内容将是
java
{"name":"虎哥","age":21}