目录
[🔹N:1 模型](#🔹N:1 模型)
[🔹1:1 模型](#🔹1:1 模型)
[🔹M:N 模型](#🔹M:N 模型)
[🔹 直观类比(餐厅例子 🍴)](#🔹 直观类比(餐厅例子 🍴))
[1. 为什么要有 GMP 模型?](#1. 为什么要有 GMP 模型?)
[2. 设计思想](#2. 设计思想)
[(4)负载均衡(work stealing)](#(4)负载均衡(work stealing))
[3. GMP 的运作机制(简化版流程)](#3. GMP 的运作机制(简化版流程))
[4. 设计优点](#4. 设计优点)
什么是线程?
-
定义 :线程是操作系统中 CPU 调度的基本单位。
-
特点:
-
一个进程里可以有多个线程(多线程)。
-
同一进程的线程共享内存空间(代码段、堆、全局变量),但有自己的栈和寄存器。
-
切换开销比进程小,因为线程之间共享资源,不需要切换整个内存环境。
-
👉 可以把 线程比作"一栋房子里的人",大家共用厨房、厕所(共享内存),但每个人有自己的卧室(私有栈)。
✅ 一个线程分为"内核态"线程和"用户态"线程
✅ 一个"用户态线程"必须要绑定一个"内核态线程",但是CPU并不知道有"用户态线程"的存在,它只知道它运行的是一个"内核态线程"(Linux的PCB进程控制块)。
✅ 所以我们细分一下:内核线程依然叫"线程(thread)" ,用户线程叫"协程(co-routine)".
🔹N:1 模型
⚠️ N个协程绑定1个线程,优点就是协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点,1个进程的所有协程都绑定在1个线程上(用户态切换 → 快速、低开销)
⚠️缺点:
- 某个程序用不了硬件的多核加速能力
- 一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
🔹1:1 模型
⚠️定义:每一个用户态线程(或协程 API 封装的"线程")对应一个内核线程。
⚠️特点
-
操作系统直接负责调度。
-
可以充分利用 多核 CPU(因为多个内核线程可以分布到不同的 CPU 核心上)。
-
阻塞不会影响其他线程(每个任务独立对应一个内核线程)。
⚠️缺点
-
内核线程很重:
-
创建/销毁线程需要内核参与,开销大。
-
内核线程栈通常是 MB 级别内存,不适合大规模并发(成千上万个线程很快耗光内存)。
-
-
切换成本高(上下文切换涉及内核态 ↔ 用户态)。
✅使用场景
- C/C++、Java(原生
Thread)、Python 的threading→ 本质都是 1:1 模型。
🔹M:N 模型
⚠️定义:M 个用户态协程(goroutines、async tasks 等)可以映射到 N 个内核线程上,由运行时调度器决定怎么分配。
⚠️特点
-
结合了 N:1 和 1:1 的优点:
-
协程轻量,能支持大规模并发。
-
内核线程少量但可多核利用。
-
-
如果某个协程阻塞,调度器可以把其他协程调度到别的线程继续运行。
-
切换时大部分还是用户态完成,开销低。
⚠️缺点
-
实现复杂:运行时必须自己写调度器(比如 Go 的 G-M-P 模型)。
-
需要特别处理系统调用/阻塞操作,否则阻塞会拖垮整个线程。
✅使用场景
-
Go 的 goroutine(典型的 M:N)。
-
Erlang 进程。
-
早期 Java 的 "green threads"(后来废弃)。
🔹 直观类比(餐厅例子 🍴)
-
N:1:一个服务员(线程)要照顾所有顾客(协程),快是快,但他一旦去厕所(阻塞),全场没人服务。
-
1:1:每个顾客配一个服务员,很豪华(并行),但成本高。
-
M:N:有 N 个服务员(线程),每个服务员手里有 M 个顾客任务(协程),一旦一个顾客卡住,其他顾客可以被别的服务员服务。
什么是进程?
👉 可以把 进程比作"一栋独立的房子",有自己的水电煤气(资源)。
-
定义 :进程是操作系统中 资源分配的基本单位。
-
组成:一个进程包含了运行的程序代码、数据(堆/栈)、文件句柄、内存空间等。
-
特点:
-
每个进程有自己独立的 内存地址空间。
-
进程之间相互隔离,一个进程崩溃不会直接影响另一个。
-
进程间通信(IPC)需要特殊机制,比如管道、消息队列、共享内存、socket。
-
什么是协程?
协程(Coroutine) 是一种比线程更轻量级的执行单元,可以看作是"用户态的线程"。
特点:
-
可挂起/恢复:协程可以在执行过程中主动挂起,把 CPU 让给别人;之后再从挂起的位置恢复执行。
-
用户态调度:协程的切换通常不依赖操作系统,而是由语言运行时或框架调度。
什么是调度器?
调度器(Scheduler)
在计算机系统里,调度器就是一个 负责分配和安排任务运行的组件 。
简单来说:
调度器决定 "什么时候、在哪个 CPU(或线程)上、运行哪个任务"。
为什么需要调度器?
多进程/线程时代有了调度器需求
单进程时代不需要调度器
Goroutine调度器的GMP模型的设计思想
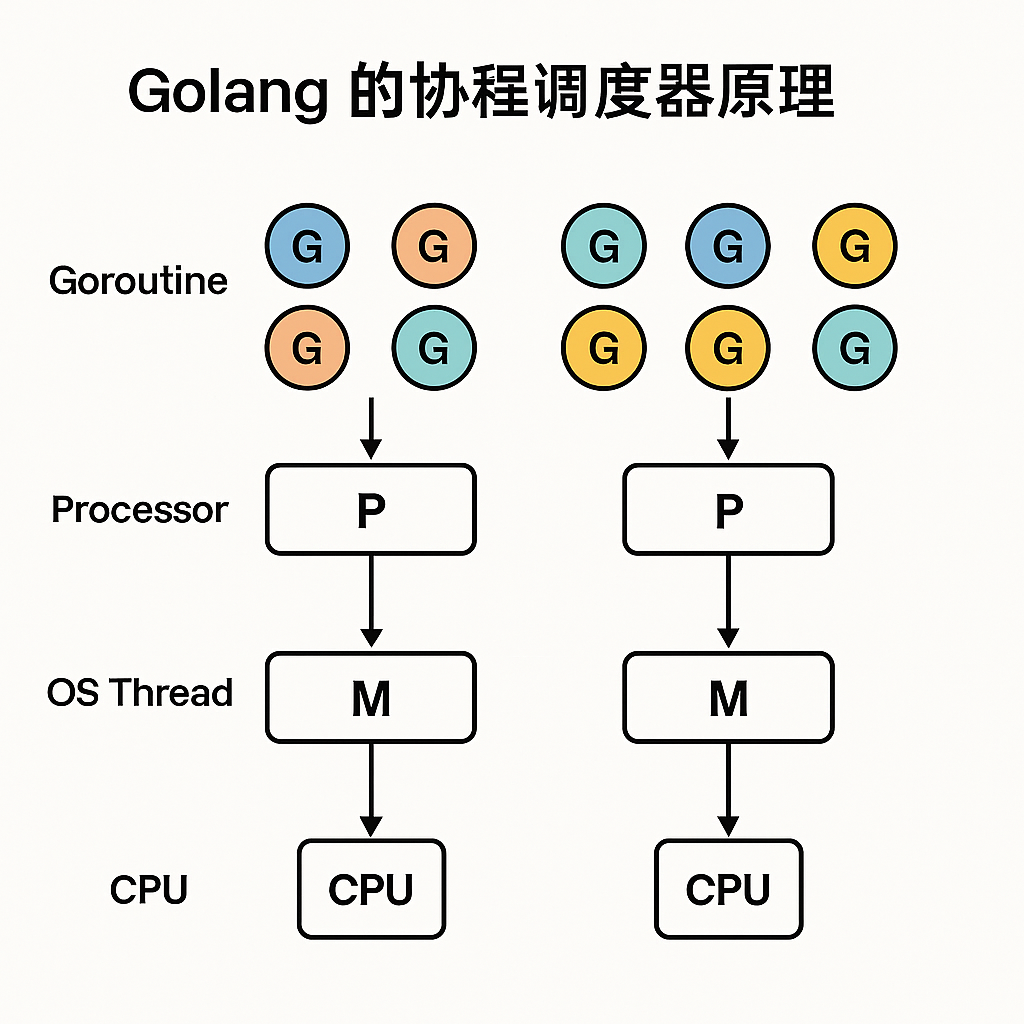
1. 为什么要有 GMP 模型?
Go 设计之初的目标是:
-
提供 简单易用 的并发编程方式(
go func()就能开协程)。 -
能支持 高并发(百万级 goroutine)。
-
充分利用多核 CPU,同时避免传统线程池/事件循环的缺点。
早期的调度器只有 G(goroutine)和 M(内核线程) ,所有 goroutine 都放到一个全局队列里 → 会出现 锁竞争严重、性能差。
于是 Go 1.1 引入了 P(Processor,逻辑处理器) ,形成了 GMP 三要素:
-
G(Goroutine):要执行的任务。
-
M(Machine):内核线程,真正跑在 CPU 上。
-
P(Processor):调度的核心,维护 goroutine 队列,绑定 M 决定执行哪些 G。
2. 设计思想
GMP 模型的设计思想可以概括为几条:
(1)减少全局锁竞争
-
每个 P 维护一个 本地 goroutine 队列。
-
调度时优先从自己的队列里取 G,不用抢全局锁。
-
只有本地队列空了才去全局队列/偷别的 P 的任务。
👉 这样避免了多线程频繁争抢全局锁。
(2)充分利用多核
-
P 的数量 = GOMAXPROCS(可由用户设置,默认=CPU 核心数)。
-
每个 P 绑定一个 M,P 的队列里的 goroutine 就能分布在多个核心上运行。
-
保证 goroutine 调度能横向扩展。
👉 解决了 N:1 模型无法利用多核 的缺陷。
(3)避免阻塞拖垮全局
-
如果一个 goroutine 在 M 上做阻塞 syscall(比如 I/O),M 会卡住。
-
Go 的调度器会让 P 把队列转交给别的空闲 M,保证其他 goroutine 继续执行。
-
阻塞的 M 等系统调用返回时,可以重新加入调度。
👉 避免了 一个阻塞拖死所有协程 的问题。
(4)负载均衡(work stealing)
-
如果某个 P 的队列空了,就会 随机偷取别的 P 一半的任务。
-
这样避免部分 CPU 核心闲置,而另一些过载。
👉 保证任务分布均衡。
3. GMP 的运作机制(简化版流程)
-
开一个 goroutine → 放进某个 P 的队列。
-
P 从队列里取出一个 G,让绑定的 M(线程)执行它。
-
如果 G 阻塞 → 调度器把 P 转移给其他 M,避免卡死。
-
如果某个 P 空了 → 去全局队列/其他 P 队列偷任务。
4. 设计优点
-
轻量调度:大部分调度在用户态完成,快速。
-
多核利用:P 的数量和 CPU 核心绑定,能高效利用硬件。
-
避免阻塞:调度器能感知阻塞,把其他 G 转移走。
-
负载均衡:work stealing 保证多线程公平利用。
-
透明性 :开发者不需要关心调度,直接写
go func()就行。