数据库中间件ShardingSphere v5.2.1
文章目录
- [数据库中间件ShardingSphere v5.2.1](#数据库中间件ShardingSphere v5.2.1)
- [一 概述](#一 概述)
-
- [1 数据库的瓶颈](#1 数据库的瓶颈)
- [2 优化的手段](#2 优化的手段)
- [3 主从复制](#3 主从复制)
- [4 读写分离](#4 读写分离)
- [5 分库分表](#5 分库分表)
-
- [5.1 背景](#5.1 背景)
- [5.2 垂直分片](#5.2 垂直分片)
- [5.3 水平分片](#5.3 水平分片)
- [6 ShardingSphere简介](#6 ShardingSphere简介)
- [二 ShardingSphere-JDBC讲解](#二 ShardingSphere-JDBC讲解)
-
- [1 读写分离实现](#1 读写分离实现)
-
- [1.1 基于Docker搭建MySQL主从](#1.1 基于Docker搭建MySQL主从)
-
- [1.1.1 部署结构](#1.1.1 部署结构)
- [1.1.2 主节点配置](#1.1.2 主节点配置)
- [1.1.3 从节点1配置](#1.1.3 从节点1配置)
- [1.1.4 从节点2配置](#1.1.4 从节点2配置)
- [1.1.5 主从复制测试](#1.1.5 主从复制测试)
- [1.2 ShardingSphere-JDBC实现读写分离](#1.2 ShardingSphere-JDBC实现读写分离)
-
- [1.2.1 创建SpringBoot项目](#1.2.1 创建SpringBoot项目)
- [1.2.2 添加依赖](#1.2.2 添加依赖)
- [1.2.3 创建实体](#1.2.3 创建实体)
- [1.2.4 创建Mapper](#1.2.4 创建Mapper)
- [1.2.5 配置读写分离](#1.2.5 配置读写分离)
- [1.3 读写分离测试](#1.3 读写分离测试)
- [1.4 负载均衡算法](#1.4 负载均衡算法)
-
- [1.4.1 常见负载均衡算法](#1.4.1 常见负载均衡算法)
- [1.4.2 事务情况测试](#1.4.2 事务情况测试)
- [1.4.3 负载均衡策略配置](#1.4.3 负载均衡策略配置)
- [2 分库分表实现](#2 分库分表实现)
-
- [2.1 基于Docker搭建垂直分表环境](#2.1 基于Docker搭建垂直分表环境)
-
- [2.1.1 部署结构](#2.1.1 部署结构)
- [2.1.2 创建容器](#2.1.2 创建容器)
- [2.1.3 创建数据库](#2.1.3 创建数据库)
- [2.2 ShardingSphere-JDBC实现垂直分表](#2.2 ShardingSphere-JDBC实现垂直分表)
-
- [2.2.1 创建实体类](#2.2.1 创建实体类)
- [2.2.2 创建Mapper](#2.2.2 创建Mapper)
- [2.2.3 垂直分片配置](#2.2.3 垂直分片配置)
- [2.2.4 垂直分片测试](#2.2.4 垂直分片测试)
- [2.3 ShardingSphere-JDBC实现水平分表](#2.3 ShardingSphere-JDBC实现水平分表)
-
- [2.3.1 部署结构](#2.3.1 部署结构)
- [2.3.2 修改数据表结构](#2.3.2 修改数据表结构)
- [2.3.3 分布式序列ID介绍](#2.3.3 分布式序列ID介绍)
- [2.3.4 配置分布式序列ID](#2.3.4 配置分布式序列ID)
- [2.3.5 分布式序列ID测试](#2.3.5 分布式序列ID测试)
- [2.3.6 水平分表配置](#2.3.6 水平分表配置)
- [2.3.7 水平分表测试](#2.3.7 水平分表测试)
- [2.4 ShardingSphere-JDBC实现水平分库](#2.4 ShardingSphere-JDBC实现水平分库)
-
- [2.4.1 部署结构](#2.4.1 部署结构)
- [2.4.2 创建容器](#2.4.2 创建容器)
- [2.4.3 创建表](#2.4.3 创建表)
- [2.4.4 水平分库配置](#2.4.4 水平分库配置)
- [2.4.5 水平分库测试](#2.4.5 水平分库测试)
- [2.5 分片后存在的问题](#2.5 分片后存在的问题)
-
- [2.5.1 多表关联查询-绑定表](#2.5.1 多表关联查询-绑定表)
- [2.5.2 字典表问题-广播表](#2.5.2 字典表问题-广播表)
- [三 ShardingSphere-Proxy讲解](#三 ShardingSphere-Proxy讲解)
-
-
- [与 ShardingSphere-JDBC 的区别](#与 ShardingSphere-JDBC 的区别)
- [1 基于Docker安装ShardingSphere-Proxy](#1 基于Docker安装ShardingSphere-Proxy)
-
- [1.1 上传MySQL驱动](#1.1 上传MySQL驱动)
- [1.2 新增配置文件server.yaml](#1.2 新增配置文件server.yaml)
- [1.3 创建容器](#1.3 创建容器)
- [1.4 测试](#1.4 测试)
- [2 读写分离实现](#2 读写分离实现)
-
- [2.1 数据源配置](#2.1 数据源配置)
- [2.2 程序访问](#2.2 程序访问)
- [3 分库分表实现](#3 分库分表实现)
-
- [3.1 垂直分表实现](#3.1 垂直分表实现)
- [3.2 水平分表实现](#3.2 水平分表实现)
- [3.3 水平分库实现](#3.3 水平分库实现)
- [3.4 绑定表实现](#3.4 绑定表实现)
- [3.5 广播表实现](#3.5 广播表实现)
-
- [四 项目集成ShardingSphere](#四 项目集成ShardingSphere)
-
-
- [1 主节点配置](#1 主节点配置)
- [2 从节点配置](#2 从节点配置)
- [3. 创建statement_db数据库](#3. 创建statement_db数据库)
- 4.创建Proxy服务器
- [5. 程序访问测试](#5. 程序访问测试)
-
一 概述
1 数据库的瓶颈
- 随着业务的增多,单机的数据库是连接数有限的,当应用程序的请求比较多的情况下,数据库的连接数就不够用了,就会出现访问缓慢的情况。
- 表数据量过大,有些查询命中不了索引从而导致全表扫描;维护索引的效率也随着数据量大到一定量级后指数级下降;新增修改数据的速度会下降很多。
2 优化的手段
- 缓存: 对于一些经常查询但是修改频率不高的数据或者一些对实时性要求并不高的数据,我们可以用缓存装起来,然后请求过来的时候,可以减少请求落入到数据库中,从而减轻对数据库端的压力
- MQ: 对于突如其来的流量的高峰,如果没有任务措施处理,请求可能会把数据库直接打奔溃,可以利用MQ做流量的缓冲,达到削峰填谷效果,从而保护数据库。
- 读写分离: 对于一个系统来说,大部分情况都是读多写少,可以采取主从的架构,然后把写请求和读请求分离,如果读压力依然比较大的情况,可以增加从的节点从而拓展读的能力.
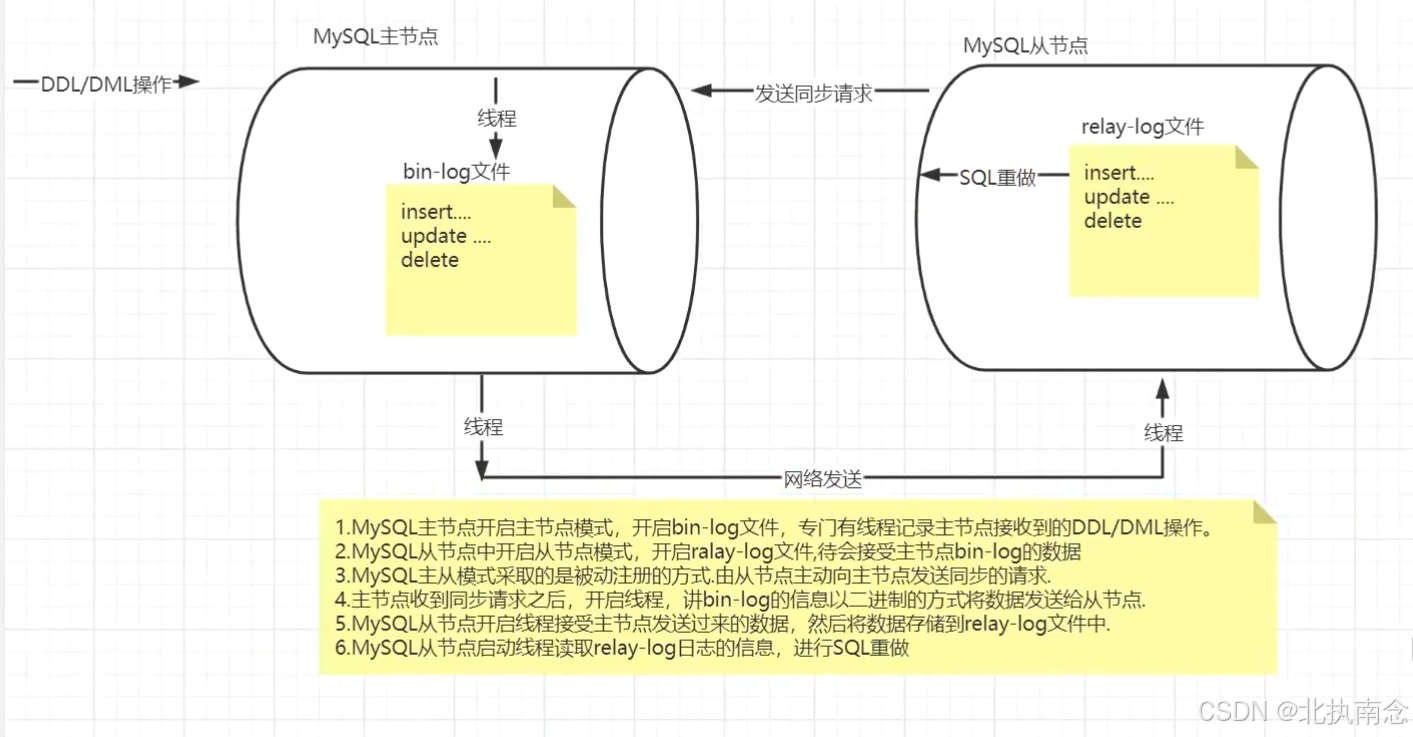
- 分库分表: 当单张表的数据量比较大,比如达到1000w的情况下,我们在操作这张表或者这个库的时候,压力都会比较大,所以我们会考虑将数据进行分片,也就是分库分表,将一个数据库的读写压力分担到多个数据库中。3 主从复制
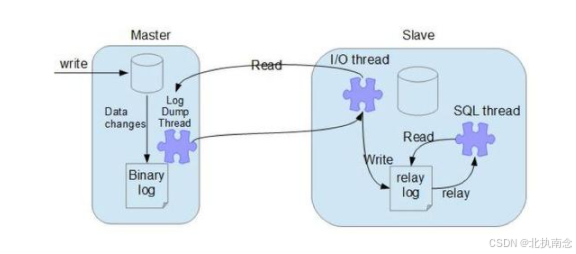
工作原理:
主库会生成一个 log dump 线程,用来给从库 I/O 线程传 Binlog 数据。
从库的 I/O 线程会去请求主库的 Binlog,并将得到的 Binlog 写到本地的 relay log (中继日志)文件中。
SQL 线程,会读取 relay log 文件中的日志,并解析成 SQL 语句逐一执行。
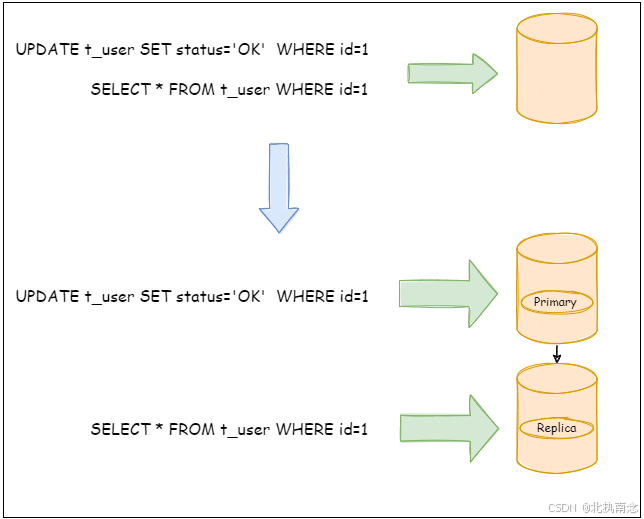
4 读写分离
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。
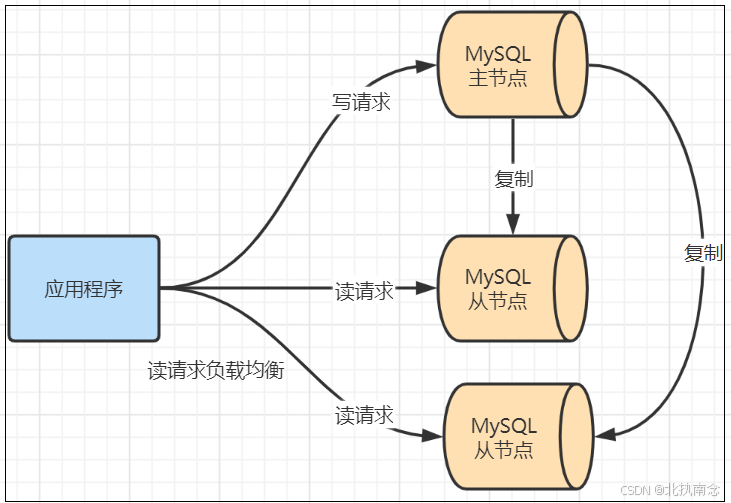
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。
5 分库分表
5.1 背景
传统的将数据集中存储至单一节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
- 从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降; 同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
- 从可用性的方面来讲,服务化的无状态性,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。 而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
- 从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。 数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
5.2 垂直分片
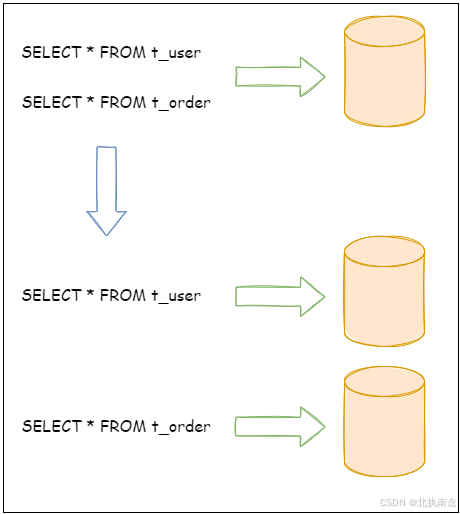
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
5.3 水平分片
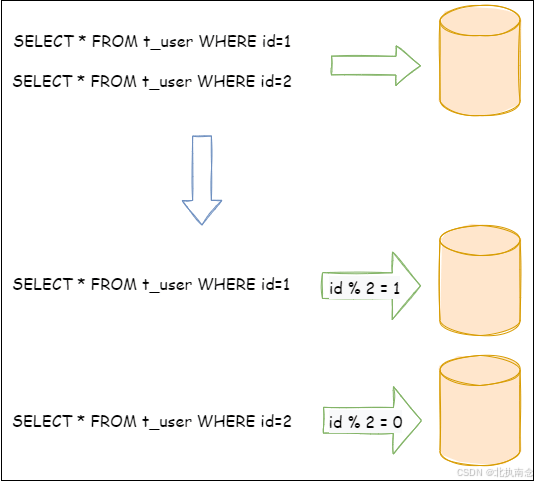
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
6 ShardingSphere简介
Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 ShardingSphere,2020年4⽉16⽇正式成为 Apache 软件基⾦会的顶级项⽬。
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
ShardingSphere目前主要是由ShardingSphere-JDBC和ShardingSphere-Proxy所组成,接下来我们就针对这两款产品给同学们讲解如何使用。
二 ShardingSphere-JDBC讲解
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
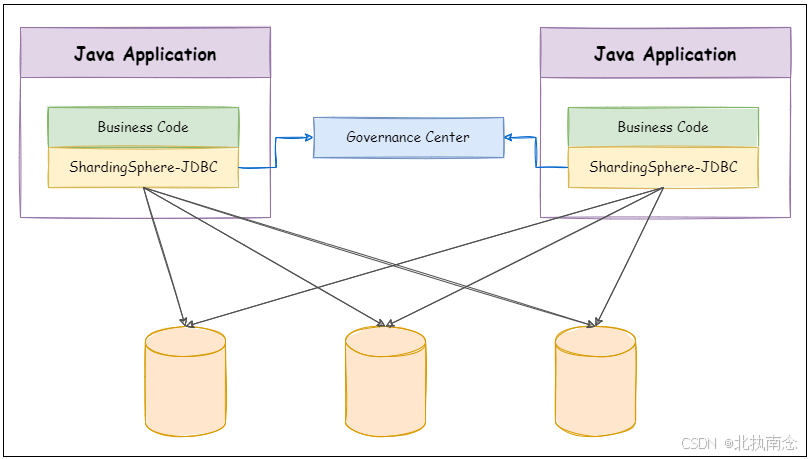
我们要实现读写分离的前提是数据库先实现了读写分离,所以接下来我们就先把读写分离的环境搭建一下。
1 读写分离实现
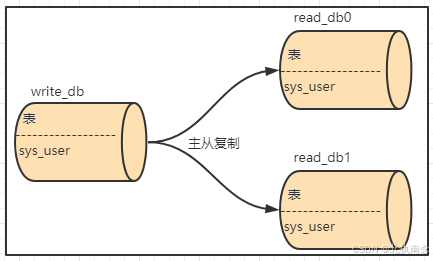
1.1 基于Docker搭建MySQL主从
1.1.1 部署结构
1.1.2 主节点配置
-
新增主节点配置文件
shellmkdir -p /wolfcode/mysql/write_db/conf vi /wolfcode/mysql/write_db/conf/my.cnf新增内容如下
shell[mysqld] # 服务器唯一id,注意在集群不要出现一样的 server-id=1 binlog_format=STATEMENT log-bin=master-bin log-bin-index=master-bin.index -
启动MySQL主节点
shelldocker run -d --name write_db -p 3306:3306 \ -v /wolfcode/mysql/write_db/conf:/etc/mysql/conf.d \ -v /wolfcode/mysql/write_db/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=WolfCode_2017 \ mysql:8.0.27 -
进入master容器,并登录MySQL
shell#进入容器 docker exec -it write_db /bin/bash #在容器内登录MySQL mysql -uroot -pWolfCode_2017 -
主机中查询master状态
shellmysql>SHOW MASTER STATUS;显示结果如下:

-
在MySQL内部创建slave同步账号
sql-- 创建slave用户 mysql> CREATE USER 'slave_user'@'%'; -- 设置密码 mysql> ALTER USER 'slave_user'@'%' IDENTIFIED WITH mysql_native_password BY 'WolfCode_2017'; -- 授予复制权限 mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%'; -- 刷新权限 mysql> FLUSH PRIVILEGES;
我们需要配置两台读节点服务器,以下是两台服务器的配置:
1.1.3 从节点1配置
-
新增从节点配置文件
shellmkdir -p /wolfcode/mysql/read_db0/conf vi /wolfcode/mysql/read_db0/conf/my.cnf新增配置信息如下:
shell[mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin -
启动从节点
shelldocker run -d --name read_db0 -p 3307:3306 \ -v /wolfcode/mysql/read_db0/conf:/etc/mysql/conf.d \ -v /wolfcode/mysql/read_db0/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=WolfCode_2017 \ mysql:8.0.27 -
进入从节点容器,并登录MySQL
shell#进入容器 docker exec -it read_db0 /bin/bash #登录MySQL mysql -uroot -pWolfCode_2017 -
进入MySQL,执行命令
shellmysql> CHANGE MASTER TO MASTER_HOST='192.168.202.200', MASTER_USER='slave_user',MASTER_PASSWORD='WolfCode_2017', MASTER_PORT=3306, MASTER_LOG_FILE='master-bin.000001',MASTER_LOG_POS=156; -
启动从节点并查看状态
shell#启动从节点 START SLAVE; #查看从节点状态 SHOW SLAVE STATUS \G
需要拉倒Slave_IO_Running和Slave_SQL_Running这两个属性的值为true才表示主从复制成功
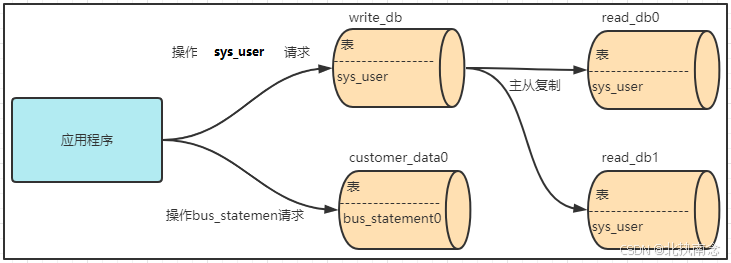
1.1.4 从节点2配置
-
新增从节点配置文件
shellmkdir -p /wolfcode/mysql/read_db1/conf vi /wolfcode/mysql/read_db1/conf/my.cnf新增配置信息如下:
shell[mysqld] server-id=3 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin -
启动从节点
shelldocker run -d --name read_db1 -p 3308:3306 \ -v /wolfcode/mysql/read_db1/conf:/etc/mysql/conf.d \ -v /wolfcode/mysql/read_db1/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=WolfCode_2017 \ mysql:8.0.27 -
进入从节点容器,并登录MySQL
shell#进入容器 docker exec -it read_db1 /bin/bash #登录MySQL mysql -uroot -pWolfCode_2017 -
进入MySQL,执行命令
shellmysql> CHANGE MASTER TO MASTER_HOST='192.168.202.200', MASTER_USER='slave_user',MASTER_PASSWORD='WolfCode_2017',MASTER_PORT=3306, MASTER_LOG_FILE='master-bin.000001',MASTER_LOG_POS=156; -
启动从节点
shell#启动从节点 START SLAVE; #查看从节点状态 SHOW SLAVE STATUS\G
1.1.5 主从复制测试
在主节点中执行以下SQL,在从节点中查看数据库、表和数据是否已经被同步
sql
CREATE DATABASE db_user;
USE db_user;
CREATE TABLE `sys_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`login_name` varchar(30) NOT NULL COMMENT '登录账号',
`user_name` varchar(30) DEFAULT '' COMMENT '用户昵称',
`phone_number` varchar(11) DEFAULT '' COMMENT '手机号码',
`password` varchar(50) DEFAULT '' COMMENT '密码',
`salt` varchar(20) DEFAULT '' COMMENT '盐加密',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='用户信息表';
INSERT INTO `sys_user` VALUES (1, 'admin', '管理员', '15888889999', '1a9afbc60137abc3ed4ee54dd16bdabc', 'f28344');1.2 ShardingSphere-JDBC实现读写分离
1.2.1 创建SpringBoot项目
1.2.2 添加依赖
xml
<dependencies>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
</dependencies>1.2.3 创建实体
java
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@TableName("sys_user")
@Data
public class SysUser {
@TableId(type = IdType.AUTO)
private Long id;
private String loginName;
private String userName;
private String phoneNumber;
private String password;
private String salt;
}1.2.4 创建Mapper
java
import cn.wolfcode.shardingjdbc.domain.SysUser;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface SysUserMapper extends BaseMapper<SysUser> {
}1.2.5 配置读写分离
数据源配置 :: ShardingSphere (apache.org)
properties
# 配置真实数据源
spring.shardingsphere.datasource.names=write_db,read_db0,read_db1
# 配置第 1 个数据源
spring.shardingsphere.datasource.write_db.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.write_db.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.write_db.jdbc-url=jdbc:mysql://192.168.202.200:3306/db_user
spring.shardingsphere.datasource.write_db.username=root
spring.shardingsphere.datasource.write_db.password=WolfCode_2017
# 配置第 2 个数据源
spring.shardingsphere.datasource.read_db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.read_db0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.read_db0.jdbc-url=jdbc:mysql://192.168.202.200:3307/db_user
spring.shardingsphere.datasource.read_db0.username=root
spring.shardingsphere.datasource.read_db0.password=WolfCode_2017
# 配置第 3 个数据源
spring.shardingsphere.datasource.read_db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.read_db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.read_db1.jdbc-url=jdbc:mysql://192.168.202.200:3308/db_user
spring.shardingsphere.datasource.read_db1.username=root
spring.shardingsphere.datasource.read_db1.password=WolfCode_2017
# 打印SQL
spring.shardingsphere.props.sql-show=true读写分离 :: ShardingSphere (apache.org)
properties
# 写库数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.static-strategy.write-data-source-name=write_db
# 读库数据源列表,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.static-strategy.read-data-source-names=read_db0,read_db11.3 读写分离测试
读写测试
java
import cn.wolfcode.shardingjdbc.domain.SysUser;
import cn.wolfcode.shardingjdbc.mapper.SysUserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class ShardingJdbcApplicationTests {
@Autowired
private SysUserMapper sysUserMapper;
/**
* 写请求测试
* 观看是否write_db,read_db0,read_db1是否有数据
*/
@Test
public void testInsert(){
SysUser user = new SysUser();
user.setLoginName("stef");
user.setUserName("史蒂夫");
user.setPhoneNumber("13000000001");
user.setPassword("3bc4191ab19247847baefafe01a0eeb5");
user.setSalt("7dc302");
sysUserMapper.insert(user);
}
/**
* 读请求测试
* 查看日志是否在从数据库中获取数据
*/
@Test
public void testRead(){
for (int i = 0; i < 5; i++) {
List<SysUser> sysUsers = sysUserMapper.selectList(null);
sysUsers.forEach(System.out::println);
System.out.println("============================================");
}
}
}默认情况,读请求是在从节点中轮询的访问.
1.4 负载均衡算法
ShardingSphere 内置提供了多种负载均衡算法,具体包括了轮询算法、随机访问算法和权重访问算法,能够满足用户绝大多数业务场景的需要。此外,考虑到业务场景的复杂性,内置算法也提供了扩展方式,用户可以基于 SPI 接口实现符合自己业务需要的负载均衡算法。
1.4.1 常见负载均衡算法
负载均衡算法 :: ShardingSphere (apache.org)
- 轮询负载均衡算法
- 类型:ROUND_ROBIN
- 说明:事务内,读请求路由到 primary,事务外,采用轮询策略路由到 replica。
- 随机负载均衡算法
- 类型:RANDOM
- 说明:事务内,读请求路由到 primary,事务外,采用随机策略路由到 replica。
- 权重负载均衡算法
- 类型:WEIGHT
- 说明:事务内,读请求路由到 primary,事务外,采用权重策略路由到 replica。
- 需要给replica设置权重数值
1.4.2 事务情况测试
注意: 在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚
java
/**
* 无事务测试
* 查看日志: 写请求发送到write_db,读请求发送到read_db中
*/
@Test
public void testWithoutTransactional(){
//先进行插入
SysUser user = new SysUser();
user.setLoginName("lucy");
user.setUserName("露西");
user.setPhoneNumber("13000000002");
user.setPassword("a491f284859c6789cef2bd9e77319e2b");
user.setSalt("0d0a40");
sysUserMapper.insert(user);
//在进行查询
System.out.println("============================================");
List<SysUser> sysUsers = sysUserMapper.selectList(null);
sysUsers.forEach(System.out::println);
}
/**
* 有事务测试
* 查看日志: 写请求发送到write_db,读请求发送到write_db中
*/
@Test
@Transactional
public void testTransactional(){
//先进行插入
SysUser user = new SysUser();
user.setLoginName("jack");
user.setUserName("杰克");
user.setPhoneNumber("13000000003");
user.setPassword("7455358315f4e2f2584543f1f170dc6d");
user.setSalt("aa475b");
sysUserMapper.insert(user);
//在进行查询
System.out.println("============================================");
List<SysUser> sysUsers = sysUserMapper.selectList(null);
sysUsers.forEach(System.out::println);
}1.4.3 负载均衡策略配置
读写分离 :: ShardingSphere (apache.org)
properties
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.load-balancer-name=alg_round_robin
# 轮询负载均衡算法
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round_robin.type=ROUND_ROBIN
# 随机负载均衡算法
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
# 权重负载均衡算法
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
# 权重负载均衡算法属性配置
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.read_db0=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.read_db1=42 分库分表实现
2.1 基于Docker搭建垂直分表环境
2.1.1 部署结构
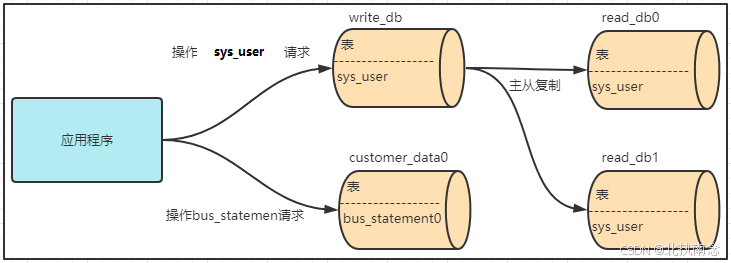
2.1.2 创建容器
shell
docker run -d \
-p 3309:3306 \
-v /wolfcode/mysql/customer_data0/conf:/etc/mysql/conf.d \
-v /wolfcode/mysql/customer_data0/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=WolfCode_2017 \
--name customer_data0 \
mysql:8.0.272.1.3 创建数据库
sql
CREATE DATABASE customer_data;
USE customer_data;
CREATE TABLE `bus_statement` (
`statement_no` bigint NOT NULL AUTO_INCREMENT COMMENT '结算单编号',
`customer_name` varchar(255) DEFAULT NULL COMMENT '客户姓名',
`customer_phone` bigint DEFAULT NULL COMMENT '客户联系方式',
`actual_arrival_time` datetime DEFAULT NULL COMMENT '实际到店时间',
`service_type` bigint DEFAULT NULL COMMENT '服务类型【维修/保养】',
`status` int DEFAULT '0' COMMENT '结算状态【消费中0/已支付1】',
`total_amount` decimal(10,0) DEFAULT '0' COMMENT '总消费金额',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`info` varchar(255) DEFAULT NULL COMMENT '备注信息',
PRIMARY KEY (`statement_no`) USING BTREE
) COMMENT='结算单';2.2 ShardingSphere-JDBC实现垂直分表
2.2.1 创建实体类
java
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.math.BigDecimal;
import java.util.Date;
@TableName("bus_statement")
@Data
public class Statement {
@TableId(type = IdType.AUTO)
private Long statementNo;//结算单编号
private String customerName;//客户姓名
private Long customerPhone;//客户联系方式
private Date actualArrivalTime;//实际到店时间
private Integer serviceType;//服务类型(
private Integer status;//结算状态
private BigDecimal totalAmount;//总消费金额
private Date createTime;//创建时间
private String info;//备注信息
}2.2.2 创建Mapper
java
import cn.wolfcode.shardingjdbc.domain.Statement;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface StatementMapper extends BaseMapper<Statement> {
}2.2.3 垂直分片配置
-
新增数据源
properties# 配置真实数据源 spring.shardingsphere.datasource.names=write_db,read_db0,read_db1,customer_data0 # 配置第 4 个数据源 spring.shardingsphere.datasource.customer_data0.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.customer_data0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.customer_data0.jdbc-url=jdbc:mysql://192.168.202.200:3309/customer_data spring.shardingsphere.datasource.customer_data0.username=root spring.shardingsphere.datasource.customer_data0.password=WolfCode_2017 -
添加垂直分片配置
数据分片 :: ShardingSphere (apache.org)
properties# 标准分片表配置(数据节点) # spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值 # 值由数据源名 + 表名组成,以小数点分隔。 # <table-name>:逻辑表名 spring.shardingsphere.rules.sharding.tables.bus_statement.actual-data-nodes=customer_data0.bus_statement
2.2.4 垂直分片测试
java
@Autowired
private StatementMapper statementMapper;
@Test
public void testVerticalShardingWrite(){
//插入用户数据
SysUser user = new SysUser();
user.setLoginName("tom");
user.setUserName("汤姆");
user.setPhoneNumber("13000000004");
user.setPassword("5356b70eb3bde91e63239a9c6a56774b");
user.setSalt("46f429");
sysUserMapper.insert(user);
//插入结算单数据
Statement statement = new Statement();
statement.setCustomerName("程家乐");
statement.setCustomerPhone(13010000001L);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(0);
statement.setStatus(0);
statement.setTotalAmount(new BigDecimal(588));
statement.setInfo("无");
statementMapper.insert(statement);
}
@Test
public void testVerticalShardingRead(){
//查询用户数据
List<SysUser> sysUsers = sysUserMapper.selectList(null);
sysUsers.forEach(System.out::println);
System.out.println("=============================================");
//查询结算单数据
List<Statement> statements = statementMapper.selectList(null);
statements.forEach(System.out::println);
}2.3 ShardingSphere-JDBC实现水平分表
当单表数据量变得越来越多的时候,对这张表的操作性能都会比较慢,我们可以采取水平分表的方式,将数据分散到多张表中存储.
2.3.1 部署结构
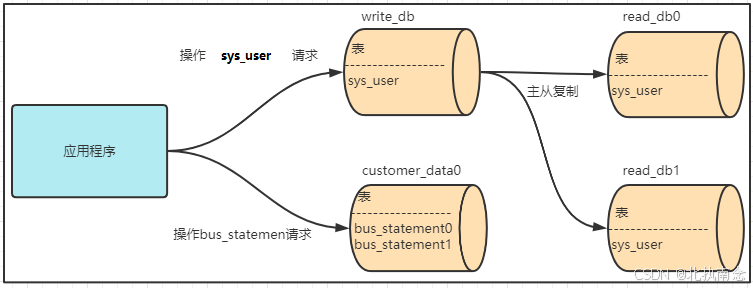
2.3.2 修改数据表结构
我们进行分表之后,数据库中的结算单编号不能使用数据库自增.
sql
USE customer_data;
DROP TABLE IF EXISTS bus_statement;
CREATE TABLE `bus_statement0` (
`statement_no` bigint NOT NULL COMMENT '结算单编号',
`customer_name` varchar(255) DEFAULT NULL COMMENT '客户姓名',
`customer_phone` bigint DEFAULT NULL COMMENT '客户联系方式',
`actual_arrival_time` datetime DEFAULT NULL COMMENT '实际到店时间',
`service_type` bigint DEFAULT NULL COMMENT '服务类型【维修/保养】',
`status` int DEFAULT '0' COMMENT '结算状态【消费中0/已支付1】',
`total_amount` decimal(10,0) DEFAULT '0' COMMENT '总消费金额',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`info` varchar(255) DEFAULT NULL COMMENT '备注信息',
PRIMARY KEY (`statement_no`) USING BTREE
) COMMENT='结算单';
CREATE TABLE `bus_statement1` (
`statement_no` bigint NOT NULL COMMENT '结算单编号',
`customer_name` varchar(255) DEFAULT NULL COMMENT '客户姓名',
`customer_phone` bigint DEFAULT NULL COMMENT '客户联系方式',
`actual_arrival_time` datetime DEFAULT NULL COMMENT '实际到店时间',
`service_type` bigint DEFAULT NULL COMMENT '服务类型【维修/保养】',
`status` int DEFAULT '0' COMMENT '结算状态【消费中0/已支付1】',
`total_amount` decimal(10,0) DEFAULT '0' COMMENT '总消费金额',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`info` varchar(255) DEFAULT NULL COMMENT '备注信息',
PRIMARY KEY (`statement_no`) USING BTREE
) COMMENT='结算单';2.3.3 分布式序列ID介绍
对于 MySQL 而言,一个表中的主键 id 一般使用自增的方式,但是如果进行水平分表之后,多个表中会生成重复的 id 值。那么如何保证水平分表后的多张表中的 id 是全局唯一性的呢?
如果还是借助数据库主键自增的形式,那么可以让不同表初始化一个不同的初始值,然后按指定的步长进行自增。例如有3张拆分表,初始主键值为1,2,3,自增步长为3。
当然也有人使用 UUID 来作为主键,但是 UUID 生成的是一个无序的字符串,对于 MySQL 推荐使用增长的数值类型值作为主键来说不适合。
不同互联网公司也有自己内部的实现方案。雪花算法是其中一个用于解决分布式 id 的高效方案,也是许多互联网公司在推荐使用的。
SnowFlake 雪花算法
SnowFlake 中文意思为雪花,故称为雪花算法。最早是 Twitter 公司在其内部用于分布式环境下生成唯一 ID,在2014年开源。

雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
- 最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
- 接下来 41 位存储毫秒级时间戳,2^41/(100060 6024365)=69,大概可以使用 69 年。
- 再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
- 最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
2.3.4 配置分布式序列ID
修改bus_statement表的实际节点映射
暂时先指向其中一个表,测试分布式序列是否成功
properties
spring.shardingsphere.rules.sharding.tables.bus_statement.actual-data-nodes=customer_data0.bus_statement0数据分片 :: ShardingSphere (apache.org)
分布式序列算法 :: ShardingSphere (apache.org)
properties
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.bus_statement.key-generate-strategy.column=statement_no
spring.shardingsphere.rules.sharding.tables.bus_statement.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法配置
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE2.3.5 分布式序列ID测试
java
/**
* 插入数据,查看数据库中bus_statement0的statementNo是否有值
*/
@Test
public void testSNOWFLAKE(){
//插入结算单数据
Statement statement = new Statement();
statement.setCustomerName("程家乐");
statement.setCustomerPhone(13010000001L);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(0);
statement.setStatus(0);
statement.setTotalAmount(new BigDecimal(588));
statement.setInfo("无");
statementMapper.insert(statement);
}2.3.6 水平分表配置
修改bus_statement表的实际节点映射
properties
spring.shardingsphere.rules.sharding.tables.bus_statement.actual-data-nodes=customer_data0.bus_statement0,customer_data0.bus_statement1如果节点比较多的情况,我们的配置可以使用行表达式标识符简化成如下配置:
properties
spring.shardingsphere.rules.sharding.tables.bus_statement.actual-data-nodes=customer_data0.bus_statement$->{0..1}数据分片 :: ShardingSphere (apache.org)
分片算法 :: ShardingSphere (apache.org)
取模分片算法
类型:MOD , 可配置属性:
| 属性名称 | 数据类型 | 说明 |
|---|---|---|
| sharding-count | int | 分片数量 |
哈希取模分片算法
类型:HASH_MOD , 可配置属性:
| 属性名称 | 数据类型 | 说明 |
|---|---|---|
| sharding-count | int | 分片数量 |
做水平分表需要选定一个分片的字段,我们选择结算单编号statement_no作为分片字段
properties
# 分片列名称:指定了分片列是statement_no字段,根据那个字段插入到那张表中
spring.shardingsphere.rules.sharding.tables.bus_statement.table-strategy.standard.sharding-column=statement_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.bus_statement.table-strategy.standard.sharding-algorithm-name=alg_mod
# 分片算法类型:该算法类型是MOD(取模算法)
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片数量为 2,意味着数据会被分散到 2 个分表中,根据statement_no字段进行求模运算
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=2 2.3.7 水平分表测试
java
/**
* 观察数据库中数据插入分布情况
*/
@Test
public void testTableShardingInsert(){
for (int i = 10; i < 15; i++) {
Statement statement = new Statement();
statement.setCustomerName("测试用户"+i);
statement.setCustomerPhone(13010000000L+i);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(0);
statement.setStatus(0);
statement.setTotalAmount(new BigDecimal(588));
statement.setInfo("无");
statementMapper.insert(statement);
}
}
/**
* 观察数据是否都查询出来了
*/
@Test
public void testTableShardingRead(){
List<Statement> statements = statementMapper.selectList(null);
statements.forEach(System.out::println);
}2.4 ShardingSphere-JDBC实现水平分库
当数据量越来越多,即使做了分表的操作,对应单个数据库的压力可能会比较大,所以我们需要继续优化,将数据分散到多个数据库中进行存储.
2.4.1 部署结构
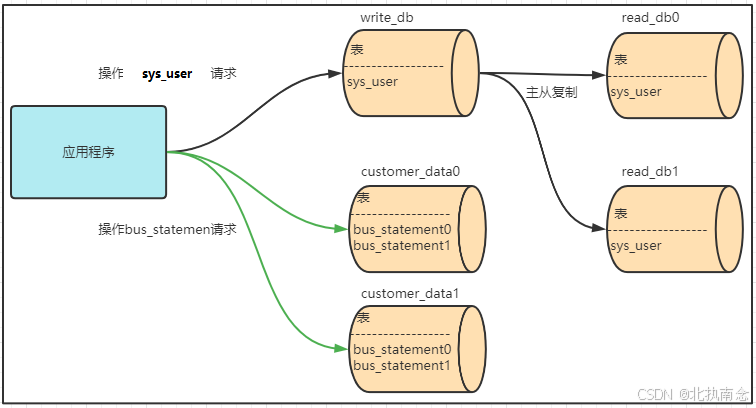
2.4.2 创建容器
shell
docker run -d \
-p 3310:3306 \
-v /wolfcode/mysql/customer_data1/conf:/etc/mysql/conf.d \
-v /wolfcode/mysql/customer_data1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=WolfCode_2017 \
--name customer_data1 \
mysql:8.0.272.4.3 创建表
sql
CREATE DATABASE customer_data;
USE customer_data;
CREATE TABLE `bus_statement0` (
`statement_no` bigint NOT NULL COMMENT '结算单编号',
`customer_name` varchar(255) DEFAULT NULL COMMENT '客户姓名',
`customer_phone` bigint DEFAULT NULL COMMENT '客户联系方式',
`actual_arrival_time` datetime DEFAULT NULL COMMENT '实际到店时间',
`service_type` bigint DEFAULT NULL COMMENT '服务类型【维修/保养】',
`status` int DEFAULT '0' COMMENT '结算状态【消费中0/已支付1】',
`total_amount` decimal(10,0) DEFAULT '0' COMMENT '总消费金额',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`info` varchar(255) DEFAULT NULL COMMENT '备注信息',
PRIMARY KEY (`statement_no`) USING BTREE
) COMMENT='结算单';
CREATE TABLE `bus_statement1` (
`statement_no` bigint NOT NULL COMMENT '结算单编号',
`customer_name` varchar(255) DEFAULT NULL COMMENT '客户姓名',
`customer_phone` bigint DEFAULT NULL COMMENT '客户联系方式',
`actual_arrival_time` datetime DEFAULT NULL COMMENT '实际到店时间',
`service_type` bigint DEFAULT NULL COMMENT '服务类型【维修/保养】',
`status` int DEFAULT '0' COMMENT '结算状态【消费中0/已支付1】',
`total_amount` decimal(10,0) DEFAULT '0' COMMENT '总消费金额',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`info` varchar(255) DEFAULT NULL COMMENT '备注信息',
PRIMARY KEY (`statement_no`) USING BTREE
) COMMENT='结算单';2.4.4 水平分库配置
添加数据源
properties
# 配置第 5 个数据源
spring.shardingsphere.datasource.customer_data1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.customer_data1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.customer_data1.jdbc-url=jdbc:mysql://192.168.202.200:3310/customer_data
spring.shardingsphere.datasource.customer_data1.username=root
spring.shardingsphere.datasource.customer_data1.password=WolfCode_2017修改数据源配置
properties
# 配置真实数据源
spring.shardingsphere.datasource.names=write_db,read_db0,read_db1,customer_data0,customer_data1修改bus_statement表的实际节点映射
properties
spring.shardingsphere.rules.sharding.tables.bus_statement.actual-data-nodes=customer_data$->{0..1}.bus_statement$->{0..1}水平分库配置
数据分片 :: ShardingSphere (apache.org)
分片算法 :: ShardingSphere (apache.org)
做水平分库需要选定一个分片的字段,我们选择用户手机号码customer_phone作为分片字段,因为我们在使用系统的时候,会根据用户的手机号码来查询该客户的结算单,我们希望把同一个手机号码的用户的结算单信息放在同一个库中,这样根据手机号码查询的时候,避免了多个数据库都同时查询,只在一个数据库中查询,性能更好些.
properties
# 分片列名称
spring.shardingsphere.rules.sharding.tables.bus_statement.database-strategy.standard.sharding-column=customer_phone
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.bus_statement.database-strategy.standard.sharding-algorithm-name=alg_inline
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline.props.algorithm-expression=customer_data$->{customer_phone % 2}2.4.5 水平分库测试
建议测试之前,把表中的数据清除,以免影响观察数据.
java
/**
* 查看是否按照手机号码将数据分片到两个数据库中了
*/
@Test
public void testDatabaseShardingInsert(){
for (int i = 0; i < 5; i++) {
Statement statement = new Statement();
statement.setCustomerName("张珊珊");
statement.setCustomerPhone(1302000001L);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(0);
statement.setStatus(0);
statement.setTotalAmount(new BigDecimal(588));
statement.setInfo("结算单"+i);
statementMapper.insert(statement);
}
for (int i = 5; i < 10; i++) {
Statement statement = new Statement();
statement.setCustomerName("陈婷婷");
statement.setCustomerPhone(1302000002L);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(1);
statement.setStatus(0);
statement.setTotalAmount(new BigDecimal(688));
statement.setInfo("结算单"+i);
statementMapper.insert(statement);
}
}
/**
* 查看是否都将两个库两张表的数据都查询出来了.
*/
@Test
public void testDatabaseShardingRead(){
List<Statement> statements = statementMapper.selectList(null);
statements.forEach(System.out::println);
}2.5 分片后存在的问题
2.5.1 多表关联查询-绑定表
部署结构
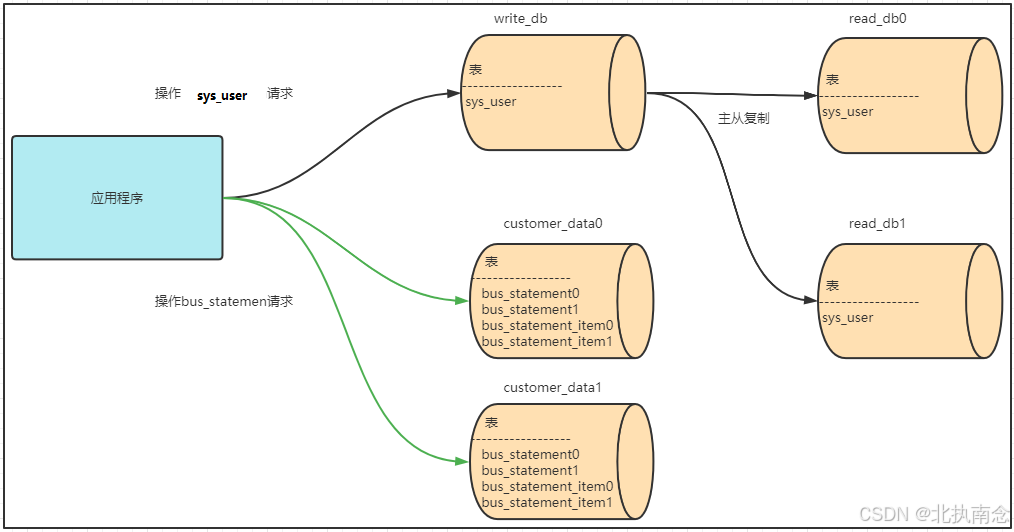
在customer_data0、customer_data1服务器中分别创建两张结算单详情表bus_statement_item0、bus_statement_item1
同一个用户的结算单表和结算单明细表中的数据都在同一个数据源中,避免跨库关联,因此这两张表我们使用相同的分片策略。那么在bus_statement中我们也需要创建statement_no和customer_phone这两个分片键
sql
CREATE TABLE `bus_statement_item0` (
`statement_item_no` bigint NOT NULL COMMENT '结算单明细ID',
`statement_no` bigint DEFAULT NULL COMMENT '结算单编号',
`customer_phone` bigint DEFAULT NULL COMMENT '客户手机号码',
`item_id` bigint DEFAULT NULL COMMENT '服务项ID',
`item_name` varchar(255) DEFAULT NULL COMMENT '服务项名称',
`item_price` decimal(10,2) DEFAULT NULL COMMENT '服务项价格',
`item_quantity` int DEFAULT NULL COMMENT '购买数量',
PRIMARY KEY (`statement_item_no`) USING BTREE
) COMMENT='结算单明细';
CREATE TABLE `bus_statement_item1` (
`statement_item_no` bigint NOT NULL COMMENT '结算单明细ID',
`statement_no` bigint DEFAULT NULL COMMENT '结算单编号',
`customer_phone` bigint DEFAULT NULL COMMENT '客户手机号码',
`item_id` bigint DEFAULT NULL COMMENT '服务项ID',
`item_name` varchar(255) DEFAULT NULL COMMENT '服务项名称',
`item_price` decimal(10,2) DEFAULT NULL COMMENT '服务项价格',
`item_quantity` int DEFAULT NULL COMMENT '购买数量',
PRIMARY KEY (`statement_item_no`) USING BTREE
) COMMENT='结算单明细';创建实体
java
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.math.BigDecimal;
@TableName("bus_statement_item")
@Data
public class StatementItem {
@TableId(type=IdType.AUTO)
private Long statementItemNo;//结算单明细编号
private Long statementNo;//结算单编号
private Long customerPhone;//用户手机号码
private Long itemId;//服务项ID
private String itemName;//服务项名称
private BigDecimal itemPrice;//服务项价格
private int itemQuantity;//购买数量
}创建Mapper
java
import cn.wolfcode.shardingjdbc.domain.StatementItem;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface StatementItemMapper extends BaseMapper<StatementItem> {
}新增bus_statement_item表映射的节点配置
properties
spring.shardingsphere.rules.sharding.tables.bus_statement_item.actual-data-nodes=customer_data$->{0..1}.bus_statement_item$->{0..1}新增bus_statement_item的分布式序列ID配置
properties
spring.shardingsphere.rules.sharding.tables.bus_statement_item.key-generate-strategy.column=statement_item_no
spring.shardingsphere.rules.sharding.tables.bus_statement_item.key-generate-strategy.key-generator-name=snowflake新增bus_statement_item水平分表配置
properties
# 分片列名称
spring.shardingsphere.rules.sharding.tables.bus_statement_item.table-strategy.standard.sharding-column=statement_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.bus_statement_item.table-strategy.standard.sharding-algorithm-name=mod新增bus_statement_item水平分库配置
properties
# 分片列名称
spring.shardingsphere.rules.sharding.tables.bus_statement_item.database-strategy.standard.sharding-column=customer_phone
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.bus_statement_item.database-strategy.standard.sharding-algorithm-name=alg_inline测试插入数据
java
@Autowired
private StatementItemMapper statementItemMapper;
@Test
public void testInsertAssociatedData(){
Statement statement = new Statement();
statement.setCustomerName("张珊珊");
statement.setCustomerPhone(1302000001L);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(0);
statement.setStatus(0);
statement.setInfo("漆面修复");
statementMapper.insert(statement);
for (int j = 0; j <3 ; j++) {
StatementItem item = new StatementItem();
item.setStatementNo(statement.getStatementNo());
item.setCustomerPhone(statement.getCustomerPhone());
item.setItemName("明细项"+j);
item.setItemPrice(new BigDecimal(58));
item.setItemQuantity(2);
statementItemMapper.insert(item);
}
statement = new Statement();
statement.setCustomerName("陈婷婷");
statement.setCustomerPhone(1302000002L);
statement.setActualArrivalTime(new Date());
statement.setCreateTime(new Date());
statement.setServiceType(1);
statement.setStatus(0);
statement.setInfo("汽车日常保养");
statementMapper.insert(statement);
for (int j = 0; j <3 ; j++) {
StatementItem item = new StatementItem();
item.setStatementNo(statement.getStatementNo());
item.setCustomerPhone(statement.getCustomerPhone());
item.setItemName("明细项"+j);
item.setItemPrice(new BigDecimal(88));
item.setItemQuantity(2);
statementItemMapper.insert(item);
}
}现在我们需要让结算单和结算单明细表进行关联操作
添加查询方法
java
@Mapper
public interface StatementMapper extends BaseMapper<Statement> {
@Select({"SELECT ",
"s.statement_no,",
"s.customer_name,",
"sum(i.item_quantity * i.item_price ) as totalAmout ",
"FROM " ,
"bus_statement s ",
"LEFT JOIN bus_statement_item i ON (s.statement_no = i.statement_no ) ",
"GROUP BY s.statement_no"})
List<Map<String,String>> getStatementTotalAmount();
}测试关联查询
java
@Test
public void testGetStatementTotalAmount(){
List<Map<String, String>> list = statementMapper.getStatementTotalAmount();
list.forEach(System.out::println);
}查看控制台日志,可以发现日志中打印8个SQL。这种情况下关联的查询会产生笛卡尔积
sql
Actual SQL: customer_data0 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement0 s LEFT JOIN bus_statement_item0 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data0 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement1 s LEFT JOIN bus_statement_item0 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data0 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement0 s LEFT JOIN bus_statement_item1 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data0 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement1 s LEFT JOIN bus_statement_item1 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data1 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement0 s LEFT JOIN bus_statement_item0 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data1 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement1 s LEFT JOIN bus_statement_item0 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data1 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement0 s LEFT JOIN bus_statement_item1 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC
Actual SQL: customer_data1 ::: SELECT s.statement_no, s.customer_name, sum(i.item_quantity * i.item_price ) as totalAmout FROM bus_statement1 s LEFT JOIN bus_statement_item1 i ON (s.statement_no = i.statement_no ) GROUP BY s.statement_no ORDER BY s.statement_no ASC 因为我们分库分表的规则都是一致的,如果结算单表数据在bus_statement0,那么对应的结算单明细表就应该在bus_statement_item0表. 所以以下的组合是没有必要,关联查询不到数据的.
shell
bus_statement0----bus_statement_item1
bus_statement1----bus_statement_item0绑定表:指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
配置绑定表
properties
spring.shardingsphere.rules.sharding.binding-tables[0]=bus_statement,bus_statement_item配置完绑定表后再次进行关联查询的测试,此时发现只会发4个SQL了
2.5.2 字典表问题-广播表
部署结构
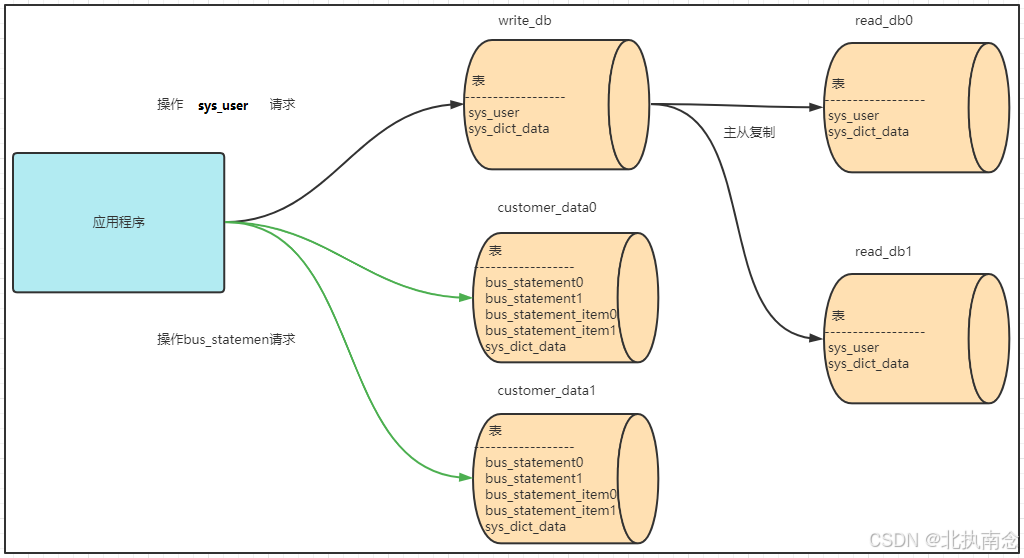
在每个数据源中数据及结构都是一致,且需要和其他的业务表进行关联操作的表,例如:字典表。
广播表具有以下特性:
(1)插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
(2)查询操作,随机从一个节点获取
(3)可以跟任何一个表进行 JOIN 操作
创建广播表
在write_db,customer_data0,customer_data1服务器中分别创建t_dict表
sql
CREATE TABLE `sys_dict_data` (
`id` bigint NOT NULL COMMENT '字典编码',
`label` varchar(100) DEFAULT '' COMMENT '字典标签',
`value` varchar(100) DEFAULT '' COMMENT '字典键值',
`type` varchar(100) DEFAULT '' COMMENT '字典类型',
`remark` varchar(500) DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='字典数据表';创建实体类
java
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@TableName("sys_dict_data")
@Data
public class DictData {
@TableId(type = IdType.ASSIGN_ID)
private Long id;//主键
private String label;//字典标签
private String value;//字典键值
private String type;//字典类型
private String remark;//备注
}创建Mapper
java
import cn.wolfcode.shardingjdbc.domain.DictData;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface DictDataMapper extends BaseMapper<DictData> {
}配置广播表
properties
#数据节点可不配置,默认情况下,向所有数据源广播
spring.shardingsphere.rules.sharding.tables.sys_dict_data.actual-data-nodes=readwrite_ds.sys_dict_data,customer_data$->{0..1}.sys_dict_data
# 广播表
spring.shardingsphere.rules.sharding.broadcast-tables[0]=sys_dict_data测试广播表
java
/**
* 当我们插入的时候,会往所有数据源中插入新数据
*/
@Test
public void testInsertDictData(){
DictData dictData = new DictData();
dictData.setLabel("维修");
dictData.setValue("0");
dictData.setType("si_service_catalog");
dictData.setRemark("服务类型维修");
dataMapper.insert(dictData);
dictData = new DictData();
dictData.setLabel("保养");
dictData.setValue("1");
dictData.setType("si_service_catalog");
dictData.setRemark("服务类型保养");
dataMapper.insert(dictData);
}
/**
* 查询的时候会随机在其中一个数据源中获取数据
*/
@Test
public void testSelectDictData(){
List<DictData> dicts = dataMapper.selectList(null);
dicts.forEach(System.out::println);
}三 ShardingSphere-Proxy讲解
ShardingSphere-Proxy 定位为透明化的数据库代理端(中间代理),通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
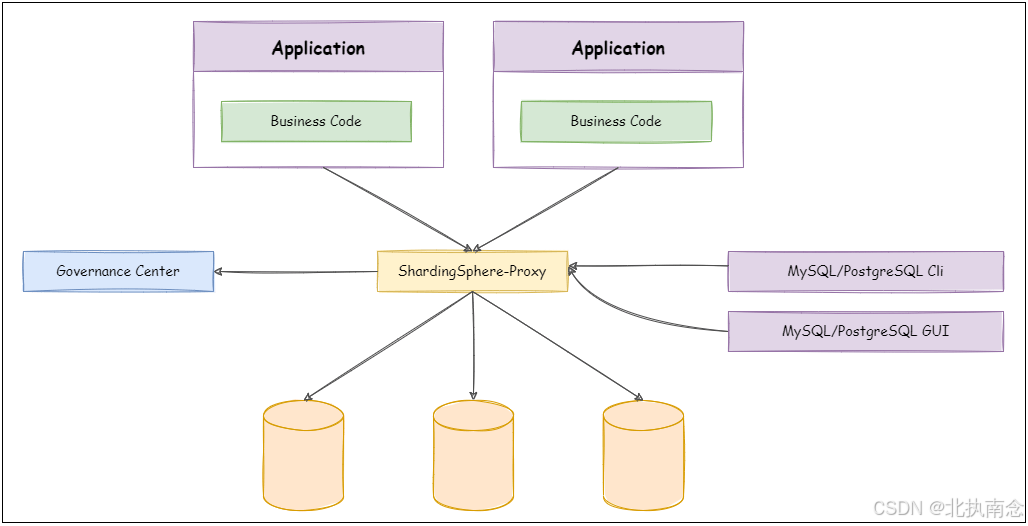
与 ShardingSphere-JDBC 的区别
| 特性 | ShardingSphere-JDBC | ShardingSphere-Proxy |
|---|---|---|
| 接入方式 | 作为 Jar 包嵌入应用 | 独立服务,应用通过网络连接 |
| 语言支持 | 仅 Java | 多语言(支持数据库协议即可) |
| 性能 | 无网络开销,性能好 | 有网络转发开销 |
| 部署复杂度 | 嵌入应用,分散部署 | 独立部署,集中管理 |
1 基于Docker安装ShardingSphere-Proxy
1.1 上传MySQL驱动
使用二进制发布包 :: ShardingSphere (apache.org)
将MySQL驱动上传至/wolfcode/mysql/proxy/ext-lib目录
shell
# 创建目录
mkdir -p /wolfcode/mysql/proxy/ext-lib
mkdir -p /wolfcode/mysql/proxy/conf1.2 新增配置文件server.yaml
shell
vi /wolfcode/mysql/proxy/conf/server.yaml权限 :: ShardingSphere (apache.org)
yaml
rules:
- !AUTHORITY
users:
- root@%:root
provider:
type: ALL_PRIVILEGES_PERMITTED
props:
sql-show: true1.3 创建容器
使用 Docker :: ShardingSphere (apache.org)
shell
docker run -d \
-v /wolfcode/mysql/proxy/logs:/opt/shardingsphere-proxy/logs \
-v /wolfcode/mysql/proxy/conf:/opt/shardingsphere-proxy/conf \
-v /wolfcode/mysql/proxy/ext-lib:/opt/shardingsphere-proxy/ext-lib \
-e ES_JAVA_OPTS="-Xmx256m -Xms256m -Xmn128m" \
-e PORT=3311 \
-p 3311:3311 \
--name sharding-proxy \
apache/shardingsphere-proxy:5.2.11.4 测试
在任意MySQL客户端通过命令行进行访问,默认的账号密码是root/root
shell
# 远程登录
mysql -h192.168.202.200 -P3311 -uroot -proot2 读写分离实现
2.1 数据源配置
新增读写分离配置文件
shell
vi /wolfcode/mysql/proxy/conf/config-business.yaml新增日志配置文件
shell
vi /wolfcode/mysql/proxy/conf/logback.xml新增内容如下:
xml
<?xml version="1.0"?>
<configuration>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%-5level] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="file"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/opt/shardingsphere-proxy/logs/proxy.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/opt/shardingsphere-proxy/logs/%d{yyyy-MM-dd}.zip</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>[%-5level] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="org.apache.shardingsphere" level="info" additivity="false">
<appender-ref ref="console" />
</logger>
<logger name="com.zaxxer.hikari" level="error" />
<logger name="com.atomikos" level="error" />
<logger name="io.netty" level="error" />
<root>
<level value="info" />
<appender-ref ref="console" />
<appender-ref ref="file" />
</root>
</configuration> 新增数据源配置
数据源配置 :: ShardingSphere (apache.org)
可参考资料中的config-business-v1.yaml
yaml
databaseName: business_db
dataSources:
write_db:
url: jdbc:mysql://192.168.202.200:3306/db_user?serverTimezone=UTC&useSSL=false
username: root
password: WolfCode_2017
read_db0:
url: jdbc:mysql://192.168.202.200:3307/db_user?serverTimezone=UTC&useSSL=false
username: root
password: WolfCode_2017
read_db1:
url: jdbc:mysql://192.168.202.200:3308/db_user?serverTimezone=UTC&useSSL=false
username: root
password: WolfCode_2017读写分离 :: ShardingSphere (apache.org)
新增读写分离配置
yaml
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
staticStrategy:
writeDataSourceName: write_db
readDataSourceNames:
- read_db0
- read_db1
loadBalancerName: alg_random
loadBalancers:
alg_random:
type: RANDOM重启容器
sh
docker restart sharding-proxy查看实时日志
sh
tail -f -n 20 /wolfcode/mysql/proxy/logs/proxy.log2.2 程序访问
我们基于之前的项目,修改配置文件,不在项目设置shardingJDBC的配置信息,新增数据源指向proxy的服务器,建议将之前的测试数据删除掉.
-
修改application.properties文件,配置数据源
properties# 数据库四要素(连接的是Proxy的地址) spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.202.200:3311/business_db?serverTimezone=GMT%2B8&useSSL=false spring.datasource.username=root spring.datasource.password=root #Mybatis日志 mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl -
测试
- 运行testInsert()方法查看数据是否有插入
-
运行testRead()方法查看是否有数据打印
-
启动错误
App connection Shardingsphere-proxy fails · Issue #18482 · apache/shardingsphere · GitHub
我们启动的时候,会可能会出现这样的错误信息
Unknown system variable 'query_cache_size'我们需要在server.yaml中添加属性配置.
yamlprops: proxy-mysql-default-version: 8.0.11
3 分库分表实现
3.1 垂直分表实现
在config-business.yaml中新增数据源
可参考资料中的config-business-v2.yaml
yaml
dataSources:
customer_data0:
url: jdbc:mysql://192.168.202.200:3309/customer_data?serverTimezone=UTC&useSSL=false
username: root
password: WolfCode_2017新增分布式序列ID配置和垂直分片配置
yaml
rules:
- !SHARDING
tables:
bus_statement:
actualDataNodes: customer_data0.bus_statement0
keyGenerateStrategy:
column: statement_no
keyGeneratorName: alg_snowflake
keyGenerators:
alg_snowflake:
type: SNOWFLAKE重启容器
shell
docker restart sharding-proxy访问测试
- 运行testVerticalShardingWrite()查看bus_statement0和sys_user表中是否插入数据
- 运行testVerticalShardingRead()查看是否能查询到两个库两张表的数据
3.2 水平分表实现
修改配置config-business.yaml,新增水平分表配置
可参考资料中的config-business-v3.yaml
yaml
rules:
- !SHARDING
tables:
bus_statement:
actualDataNodes: customer_data0.bus_statement$->{0..1}
keyGenerateStrategy:
column: statement_no
keyGeneratorName: alg_snowflake
tableStrategy:
standard:
shardingColumn: statement_no
shardingAlgorithmName: alg_mod
keyGenerators:
alg_snowflake:
type: SNOWFLAKE
shardingAlgorithms:
alg_mod:
type: MOD
props:
sharding-count: 2重启容器
访问测试
- 运行testTableShardingInsert()方法,查看数据是否在bus_statement0和bus_statement1中分别存储
- 运行testTableShardingRead()方法,查看数据能查询到bus_statement0和bus_statement1的数据
3.3 水平分库实现
修改配置config-business.yaml,新增水平分库配置
可参考资料中的config-business-v4.yaml
yaml
databaseName: business_db
dataSources:
customer_data1:
url: jdbc:mysql://192.168.202.200:3310/customer_data?serverTimezone=UTC&useSSL=false
username: root
password: WolfCode_2017
rules:
- !SHARDING
tables:
bus_statement:
actualDataNodes: customer_data$->{0..1}.bus_statement$->{0..1}
keyGenerateStrategy:
column: statement_no
keyGeneratorName: alg_snowflake
databaseStrategy:
standard:
shardingColumn: customer_phone
shardingAlgorithmName: alg_inline
tableStrategy:
standard:
shardingColumn: statement_no
shardingAlgorithmName: alg_mod
keyGenerators:
alg_snowflake:
type: SNOWFLAKE
shardingAlgorithms:
alg_mod:
type: MOD
props:
sharding-count: 2
alg_inline:
type: INLINE
props:
algorithm-expression: customer_data$->{customer_phone % 2}重启容器
shell
docker restart sharding-proxy访问测试
- 运行testDatabaseShardingInsert()方法,查看是否按照手机号码将数据分片到两个数据库中了
- 运行testDatabaseShardingRead()方法,查看是否都将两个库两张表的数据都查询出来了.
3.4 绑定表实现
修改配置config-business.yaml,新增bus_statement_item分库分表配置
可参考资料中的config-business-v5.yaml
yaml
rules:
- !SHARDING
tables:
bus_statement_item:
actualDataNodes: customer_data$->{0..1}.bus_statement_item$->{0..1}
keyGenerateStrategy:
column: statement_item_no
keyGeneratorName: alg_snowflake
databaseStrategy:
standard:
shardingColumn: customer_phone
shardingAlgorithmName: alg_inline
tableStrategy:
standard:
shardingColumn: statement_no
shardingAlgorithmName: alg_mod修改Statement的主键生成策略
因为ShardingProxy在新增完之后并没有返回主键值,所以我们关联插入的时候在Item中无法设置statement_no的值,会导致无法对bus_statement_item进行分库分表,我们使用MyBastisPlus的雪花算法
java
@TableName("bus_statement")
@Data
public class Statement {
//使用MyBatisPlus的雪花算法ID
@TableId(type = Idccpe.ASSIGN_ID)
private Long statementNo;//结算单编号
......
}初始化测试数据
- 运行testInsertAssociatedData()方法,插入测试数据
查看日志
shell
tail -f -n 20 /wolfcode/mysql/proxy/logs/proxy.logs查询测试
- 运行testGetStatementTotalAmount()关联查询数据
查看日志发现是发送了8条SQL
修改配置config-business.yaml,新增绑定表配置
yaml
rules:
- !SHARDING
bindingTables:
- bus_statement,bus_statement_item重启容器
shell
docker restart sharding-proxy查询测试
- 运行testGetStatementTotalAmount()关联查询数据
查看日志发现是发送了4条SQL
3.5 广播表实现
修改配置config-business.yaml,新增广播表配置
可参考资料中的config-business-v6.yaml
yaml
rules:
- !SHARDING
tables:
sys_dict_data:
actualDataNodes: readwrite_ds.sys_dict_data,customer_data$->{0..1}.sys_dict_data
broadcastTables:
- sys_dict_data测试
- 运行testInsertDictData()查看是否在所有的数据源中插入数据了
- 运行testSelectDictData()查看是否查询到字典数据了
四 项目集成ShardingSphere
我们使用ShardingProxy的方式对数据库做优化,实现读写分离,对bus_statement和bus_statement_item做分库的操作.
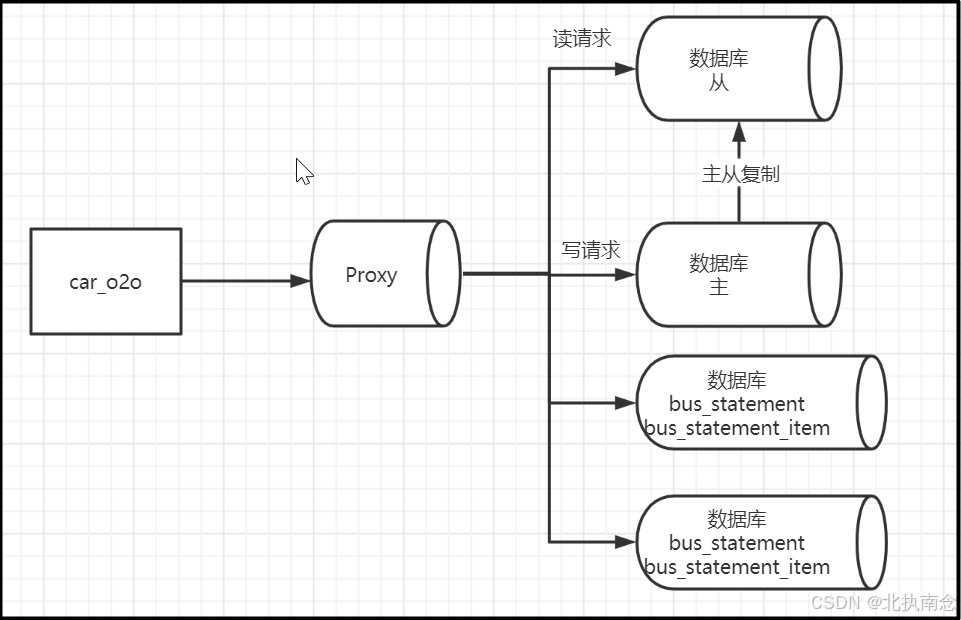
1 主节点配置
-
新增主节点配置文件
shellmkdir -p /wolfcode/mysql/write_db/conf vi /wolfcode/mysql/write_db/conf/my.cnf新增内容如下
shell[mysqld] # 服务器唯一id,注意在集群不要出现一样的 server-id=1 binlog_format=STATEMENT log-bin=master-bin log-bin-index=master-bin.index -
启动MySQL主节点
shelldocker run -d --name write_db -p 3307:3306 \ -v /wolfcode/mysql/write_db/conf:/etc/mysql/conf.d \ -v /wolfcode/mysql/write_db/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=WolfCode_2017 \ mysql:8.0.27 -
进入master容器,并登录MySQL
shell#进入容器 docker exec -it write_db /bin/bash #在容器内登录MySQL mysql -uroot -pWolfCode_2017 -
在MySQL内部创建slave同步账号
sql-- 创建slave用户 mysql> CREATE USER 'slave_user'@'%'; -- 设置密码 mysql> ALTER USER 'slave_user'@'%' IDENTIFIED WITH mysql_native_password BY 'WolfCode_2017'; -- 授予复制权限 mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%'; -- 刷新权限 mysql> FLUSH PRIVILEGES;
2 从节点配置
-
新增从节点配置文件
shellmkdir -p /wolfcode/mysql/read_db/conf vi /wolfcode/mysql/read_db/conf/my.cnf新增配置信息如下:
properties[mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin -
启动从节点
shelldocker run -d --name read_db -p 3308:3306 \ -v /wolfcode/mysql/read_db/conf:/etc/mysql/conf.d \ -v /wolfcode/mysql/read_db/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=WolfCode_2017 \ mysql:8.0.27 -
进入从节点容器,并登录MySQL
shell#进入容器 docker exec -it read_db /bin/bash #登录MySQL mysql -uroot -pWolfCode_2017 -
进入MySQL,执行命令
shellmysql> CHANGE MASTER TO MASTER_HOST='192.168.202.200', MASTER_USER='slave_user',MASTER_PASSWORD='WolfCode_2017', MASTER_PORT=3307, MASTER_LOG_FILE='master-bin.000003',MASTER_LOG_POS=156; -
将car_o2o.sql的数据表导入到主节点中
3. 创建statement_db数据库
创建statement_db0数据库
shell
docker run -d --name statement_db0 -p 3309:3306 \
-v /wolfcode/mysql/statement_db0/conf:/etc/mysql/conf.d \
-v /wolfcode/mysql/statement_db0/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=WolfCode_2017 \
mysql:8.0.27创建statement_db1数据库
shell
docker run -d --name statement_db1 -p 3310:3306 \
-v /wolfcode/mysql/statement_db1/conf:/etc/mysql/conf.d \
-v /wolfcode/mysql/statement_db1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=WolfCode_2017 \
mysql:8.0.27- 将bus_statement和bus_statement_item表分别导入到statement_db0和statement_db1数据库中
4.创建Proxy服务器
将MySQL驱动上传至/wolfcode/mysql/proxy/ext-lib目录
shell
# 创建目录
mkdir -p /wolfcode/mysql/proxy/ext-lib
mkdir -p /wolfcode/mysql/proxy/conf新增配置文件server.yaml
shell
vi /wolfcode/mysql/proxy/conf/server.yaml
yaml
rules:
- !AUTHORITY
users:
- root@%:root
provider:
type: ALL_PRIVILEGES_PERMITTED
props:
sql-show: true
proxy-mysql-default-version: 8.0.11修改config-car_o2o.yaml,上传到/wolfcode/mysql/proxy/conf中.
创建容器
shell
docker run -d \
-v /wolfcode/mysql/proxy/logs:/opt/shardingsphere-proxy/logs \
-v /wolfcode/mysql/proxy/conf:/opt/shardingsphere-proxy/conf \
-v /wolfcode/mysql/proxy/ext-lib:/opt/shardingsphere-proxy/ext-lib \
-e ES_JAVA_OPTS="-Xmx256m -Xms256m -Xmn128m" \
-e PORT=3311 \
-p 3311:3311 \
--name sharding-proxy \
apache/shardingsphere-proxy:5.2.1