链接:https://github.com/vinayakumarr/Network-Intrusion-Detection
docs:网络入侵检测
本项目专注于构建和评估多种机器学习模型 用于网络入侵检测。
它处理原始网络流量数据,训练深度学习架构(如CNN、LSTM及其混合模型)以及传统算法,并严格评估其性能以识别恶意活动。
该系统设计用于处理二分类 (攻击/正常)和多分类入侵场景。
可视化
章节
- 分类任务配置(二分类vs多分类)
- 数据加载与预处理
- 传统机器学习模型
- 深度前馈神经网络(DNN)模型
- 纯卷积神经网络(CNN)模型
- 循环神经网络(RNN)模型(LSTM/GRU/SimpleRNN)
- CNN-LSTM混合模型
- 模型训练生命周期(Keras)
- 性能评估与报告
第一章:分类任务配置(二分类与多分类)
欢迎来到网络入侵检测(NID)
想象我们是繁忙数字城市的安保人员,职责是识别试图入侵的可疑或危险行为。但在抓捕入侵者之前,我们需要明确要检测的威胁类型。
本章将教会我们的"安保"模型理解需要回答的问题类型:是简单的"是/否,攻击与否?"问题,还是更复杂的"这是哪种攻击?"多选题?这一选择从根本上改变了模型最终决策过程的设计方式。
什么是分类任务?
在网络入侵检测中,我们的目标通常是对网络活动进行分类。这意味着接收输入数据(如网络流量特征)并将其分配到特定类别或"类"。例如,我们可能希望将网络连接分类为:
正常(一切正常)攻击(存在恶意行为)
或者更具体地分类为:
正常DoS(拒绝服务攻击)Probe(漏洞扫描)R2L(远程到本地攻击)U2R(用户到root攻击)
模型处理这些不同类型问题的方式就是"分类任务配置"。
二分类:是非题
二分类是最简单的分类类型,只有两种可能的结果或类别 。可以理解为"真"或"假"的问题。在我们的NID项目中,通常意味着区分正常流量和攻击流量。
二分类配置方法
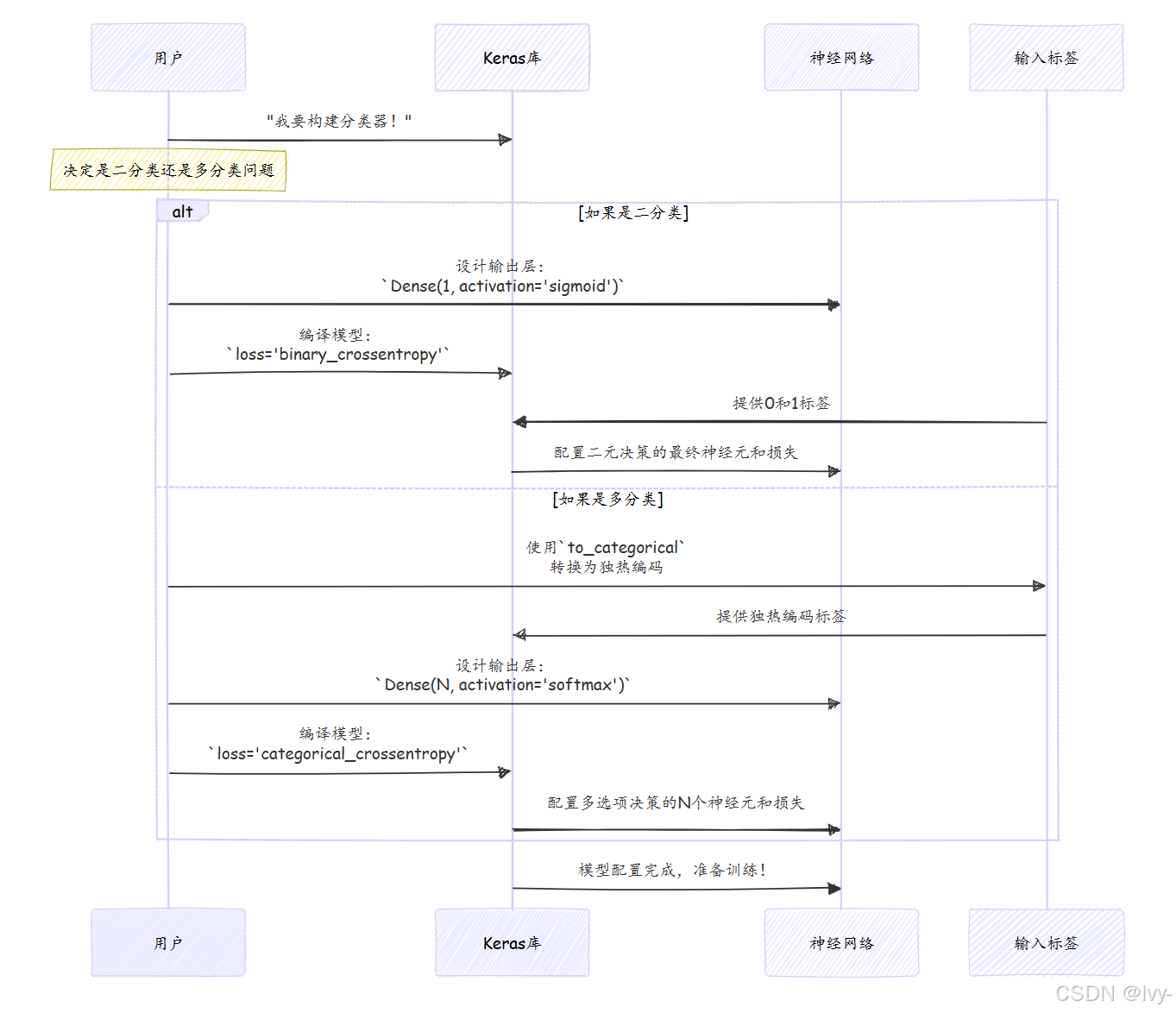
构建神经网络(我们将大量使用的模型类型)时,需要告诉其最后一层如何进行这种二元决策。
- 输出层神经元数量 :由于只有两种结果,最后一层只需要一个神经元,输出单个值。
- 激活函数 :该神经元使用
sigmoid函数,将任意数值压缩到0到1之间,可解释为输入属于"正类"(如"攻击")的概率。例如输出0.8表示80%可能是攻击。 - 损失函数 :训练时,模型需要衡量预测的"错误"程度。二分类使用
binary_crossentropy,完美比较预测概率(0到1)与实际标签(0或1)。
二分类代码示例
以下是Keras(流行深度学习库)中的简化配置示例,类似配置可见于KDDCup 99/CNN-LSTM/binary/cnn1.py等文件。
python
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
# ...(其他网络层)...
# 二分类关键输出层:
model.add(Dense(1, activation="sigmoid"))
# 编译模型,指定二分类损失函数:
model.compile(loss="binary_crossentropy",
optimizer="adam",
metrics=['accuracy'])说明:
Dense(1, activation="sigmoid"):创建具有1个神经元和sigmoid激活函数的输出层loss="binary_crossentropy":使用二分类交叉熵计算训练效果
多分类:多选题
多分类指超过两种可能结果或类别 的情况。如同多选题有多个选项(A、B、C、D、E)。在我们的NID项目中,可能将流量分为正常、DoS、Probe、R2L和U2R共五类。
多分类配置方法
多分类模型需要对数据准备和输出层设计进行调整。
1. 数据准备:独热编码
多分类模型的标签需要转换为独热编码格式,因为输出层将单独预测每个类的概率。
例如原始数字标签:0=正常,1=DoS,2=Probe等。独热编码将其转换为0和1的列表:
正常(0)→[1, 0, 0, 0, 0]DoS(1)→[0, 1, 0, 0, 0]Probe(2)→[0, 0, 1, 0, 0]
数字1的位置表示类别。
使用Keras的to_categorical示例:
python
from keras.utils.np_utils import to_categorical
import numpy as np
raw_labels = np.array([0, 1, 4, 0, 2]) # 0=正常,1=DoS,4=U2R
num_classes = 5 # 总类别数(正常+4种攻击)
one_hot_labels = to_categorical(raw_labels, num_classes=num_classes)
print("原始标签:", raw_labels)
print("独热编码标签:")
print(one_hot_labels)输出:
css
原始标签: [0 1 4 0 2]
独热编码标签:
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 0. 0. 1.]
[1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0.]]2. 多分类模型配置
与二分类类似,输出层和损失函数需要调整。
- 输出层神经元数量 :需要N个神经元,N为总类别数(如5类)。每个神经元对应一个类别。
- 激活函数 :使用
softmax函数,将所有N个神经元的输出转换为概率分布(总和为1)。例如五类输出可能是[0.1, 0.7, 0.05, 0.05, 0.1],表示第二类(DoS)概率70%。 - 损失函数 :使用
categorical_crossentropy,专为多分类概率分布设计。
多分类代码示例
配置可见于KDDCup 99/CNN-LSTM/multiclass/cnn1.py等文件。
python
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.utils.np_utils import to_categorical
num_classes = 5 # 示例:正常,DoS,Probe,R2L,U2R
model = Sequential()
# ...(其他网络层)...
# 多分类关键输出层:
model.add(Dense(num_classes, activation="softmax"))
# 编译模型,指定多分类损失函数:
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=['accuracy'])说明:
Dense(num_classes, activation="softmax"):输出层有N个神经元,softmax确保输出为概率分布loss="categorical_crossentropy":适用于比较预测概率分布与独热编码标签
二分类与多分类配置对比
关键差异总结:
| 特性 | 二分类(如正常/攻击) | 多分类(如正常,DoS,Probe...) |
|---|---|---|
| 问题类型 | 两个明确类别 | 超过两个明确类别 |
| 输出层神经元 | 1 | N(类别数量) |
| 输出层激活函数 | sigmoid |
softmax |
| 损失函数 | binary_crossentropy |
categorical_crossentropy |
| 标签编码 | 0或1(单值) |
独热编码(如[0,1,0,0,0]) |
| 类比 | 是非题 | 多选题 |
技术实现:Keras如何应用配置
在Keras中定义和编译模型时,实质上是指导库如何设置神经网络的最后部分及评估性能。
结论
理解二分类与多分类的区别是构建有效NID模型的基础第一步。我们已学会根据问题是两种还是多种结果来配置模型的输出层和选择合适的损失函数,也了解了如何使用独热编码准备多分类任务的标签。
现在我们知道如何定义模型要回答的"问题类型",下一步是准备实际训练数据。下一章将深入探讨如何为这些分类任务加载和准备网络流量数据。